玩一玩英伟达的ChatWithRTX,打造个人AI聊天机器人!
连英伟达都亲自下场给大家做Demo了。

“老黄”直接给你打包好了一个35GB软件包,并且详细介绍了系统要求。这贴心的服务,让N卡玩家受宠若惊。
官方介绍
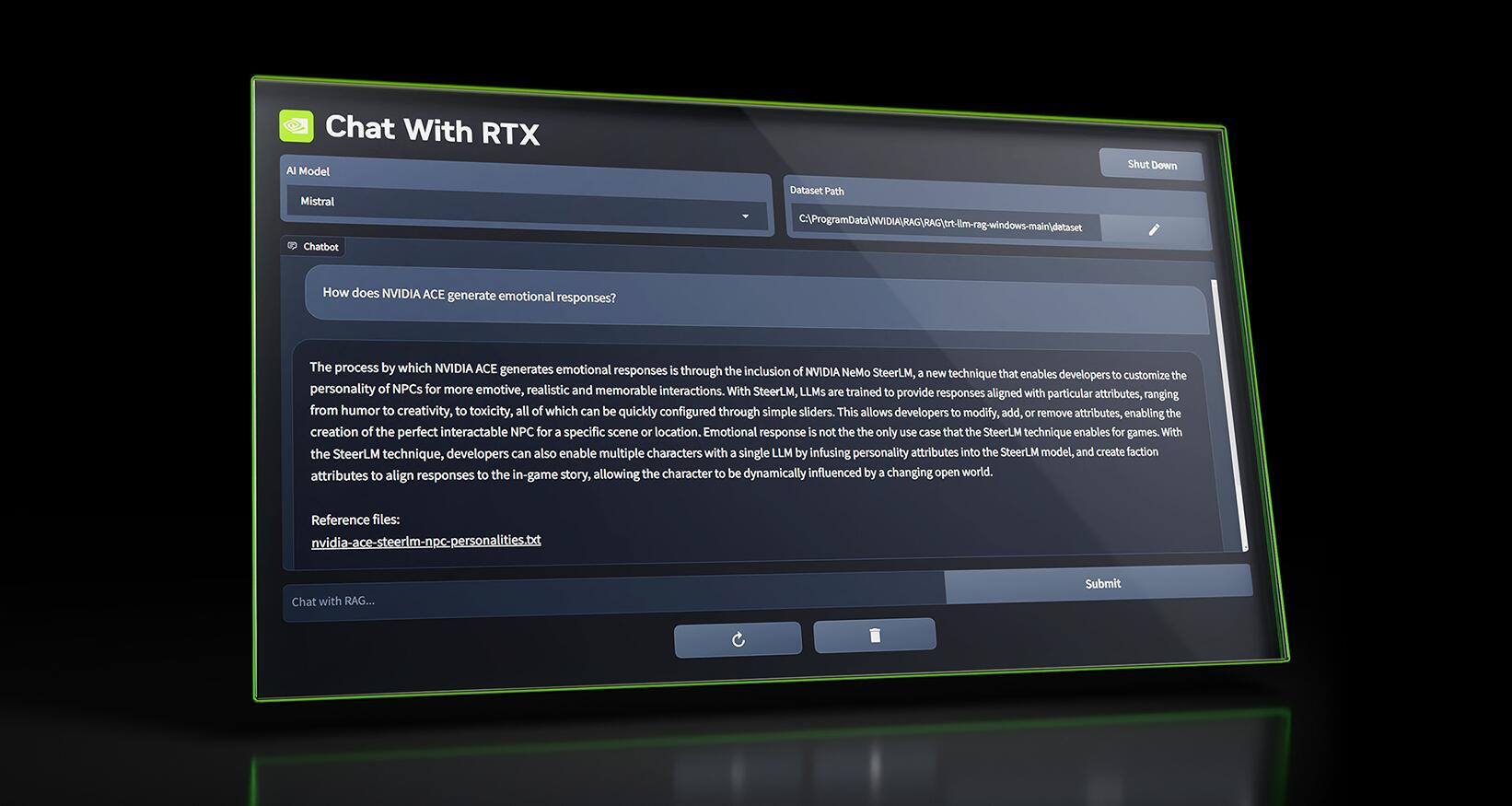
Chat With RTX”是一个演示应用程序,它允许你定义一个大语言模型,模型可以关联你本地的文档、笔记、视频或其他数据。利用检索增强生成(RAG)、TensorRT-LLM和RTX加速,你可以使用这个专属AI聊天机器人,快速获得上下文相关的答案。而且因为它完全运行在本地Windows电脑或工作站上面,你将获得更加快速和安全的结果。
概括一下:
- 可以快速和大模型对话。
- 可以使用本地知识库做关联查询。
- 快速且安全,没有隐私顾虑。
本地知识库,具体可以使用的类型有 text,pdf,doc,xml,甚至是youtube视频地址。
系统要求
说得很好,那么要多牛的电脑才能运行呢?
下面是官方给出的配置要求:

系统: Windows11
显卡:RTX30或者40系列,至少8GB显存。
内存:16GB+
驱动:535.11+
这个要求不低,但是也不高。
一张30系列显存8G的显卡,现在在咸鱼上也花不了多少钱。
下面就在家里电脑上来实操一下,看看能不能跑,跑起来效果好不好。
首先获取英伟达官方提供软件包,下载完后可以看到这个一个ZIP压缩文件。
zip无论在Windows上还是mac上,或者是linux上都有很好的支持。一般系统都自带解压缩工具,右键选择相应菜单就可以解压。
推荐安装个7z,无广告,不收费。
解压之后,打开文件夹,就可以看到一个setup.exe
双击开始安装。

独立安装过英伟达驱动的,对这个界面肯定很熟悉。
不过,这个界面曾经折磨了我很久。
这不,现在还不放过我。
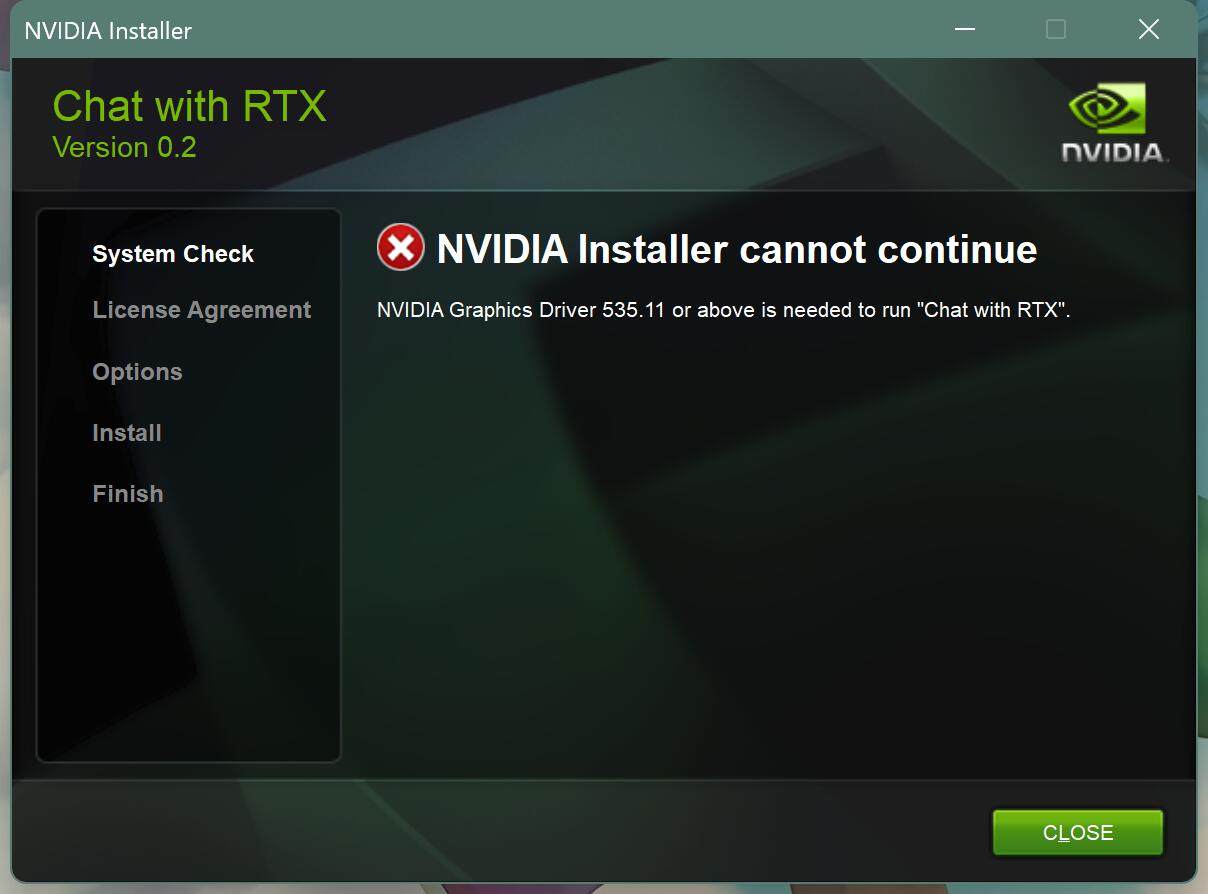
上来就直接给我报错。这个错误提示很清晰啊,就是说我驱动版本太低,我也很清楚我版本为啥这么低,因为曾经家里有矿。
为了测试这个软件,只能升级了。
安装驱动最好是去英伟达官网,可以谷歌百度搜索NVIDIA 驱动,找到官网下载地址。
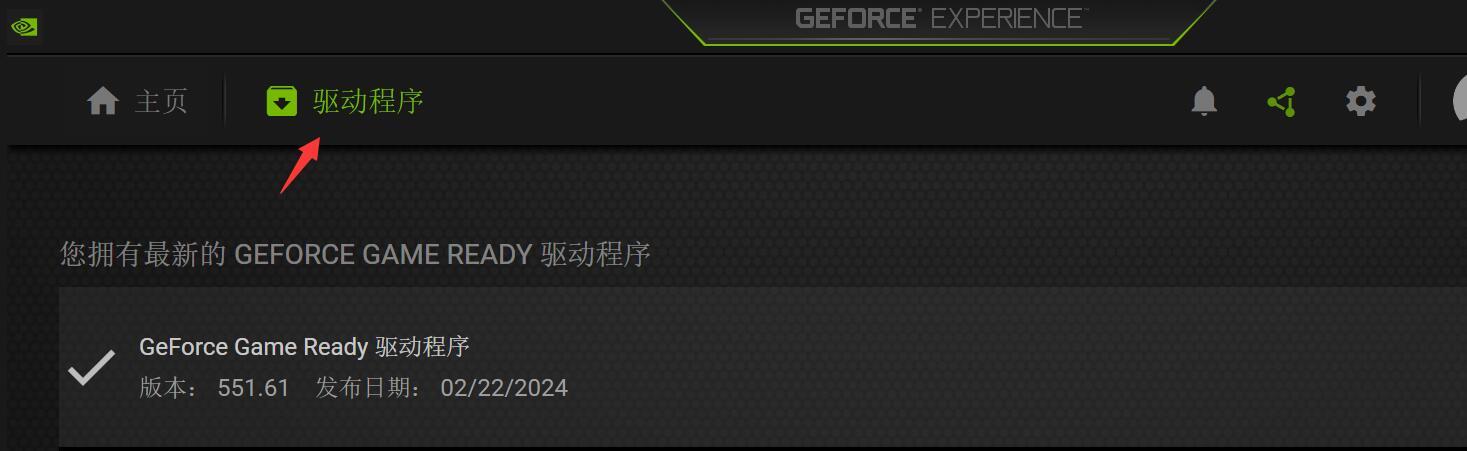
之前安装过驱动的,右下角托盘上会有一个英伟达图标,右键打开Nvidia GeForce Experience 可以快速更新驱动!
驱动更新完成之后,重新点击setup.exe进行安装。
安装只要把握一个核心就好:点击绿色按钮。
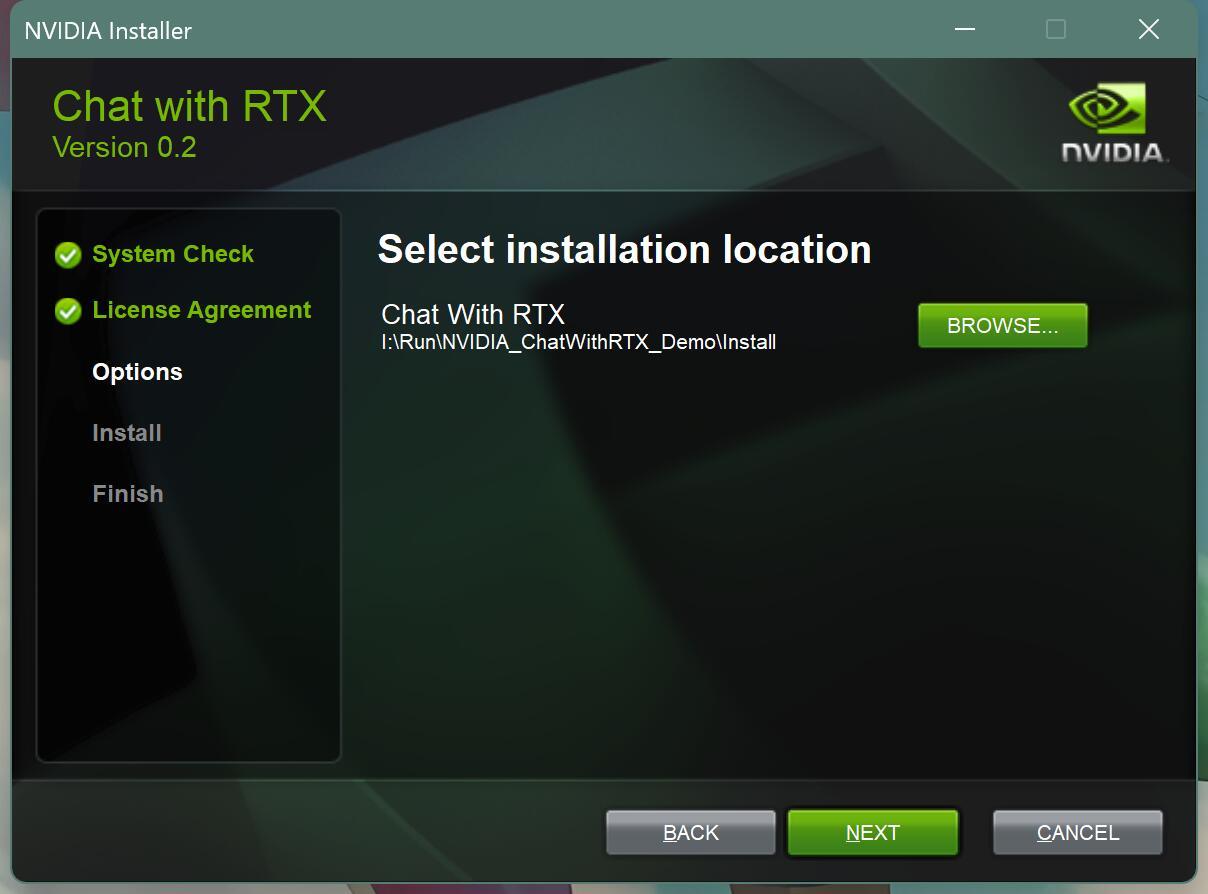
这一步的安装路径最好自己设置一下,默认在C盘。
安装文件还挺大的,一般C盘都不怎么宽裕,所以改一下比较好。
绿色按钮点完之后,就会开始安装了,安装过程还挺漫长。
从提示来看,会安装CUDA工具集,在线下载一些东西,安装一个新的Conda环境…..
我是真不喜欢这些集成安装,万一把我本地环境打乱了就麻烦了。
开弓没有回头箭,只能硬着头皮装了。
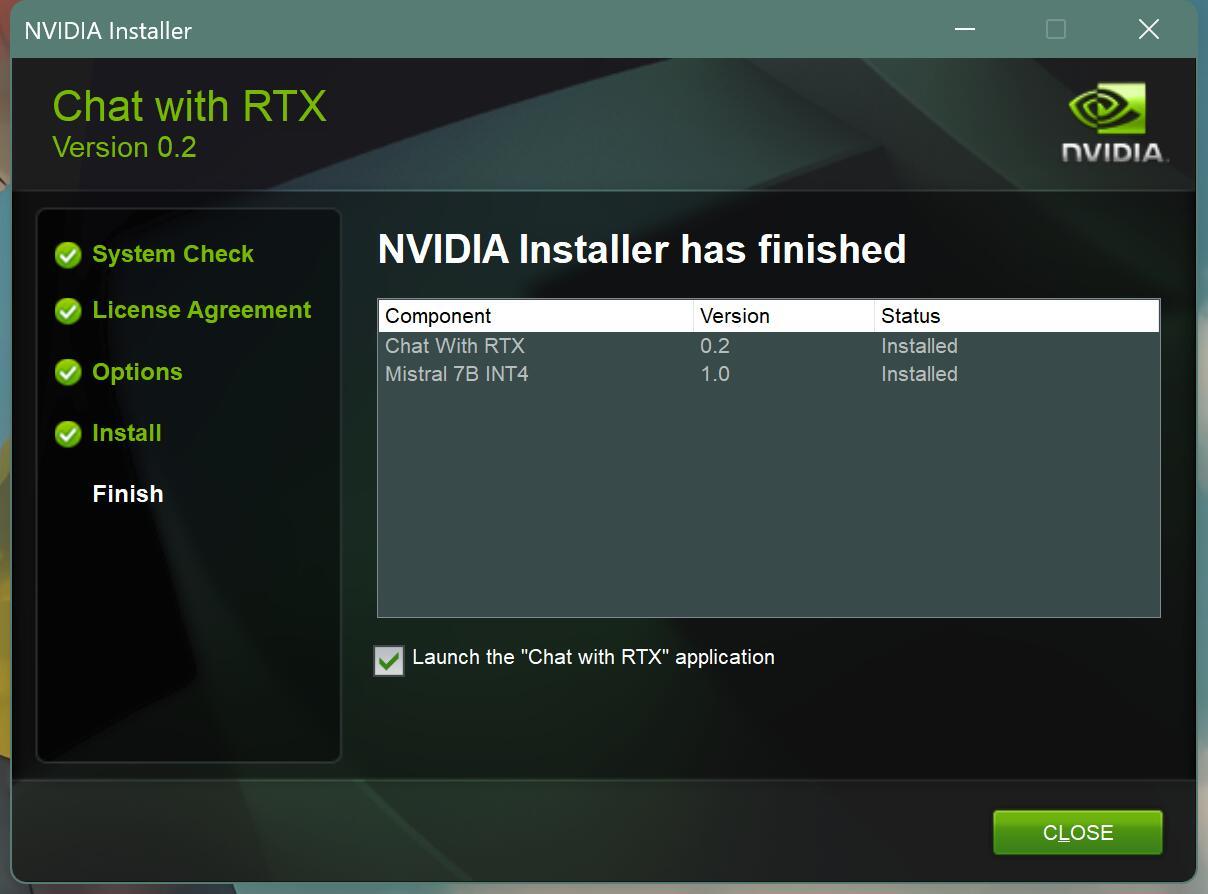
到这一步,就是安装成功了,点击Close就可以了。
然后,自动跳出一个黑色的命令窗口。
接着跳出Windows安全中心,点击允许即可。
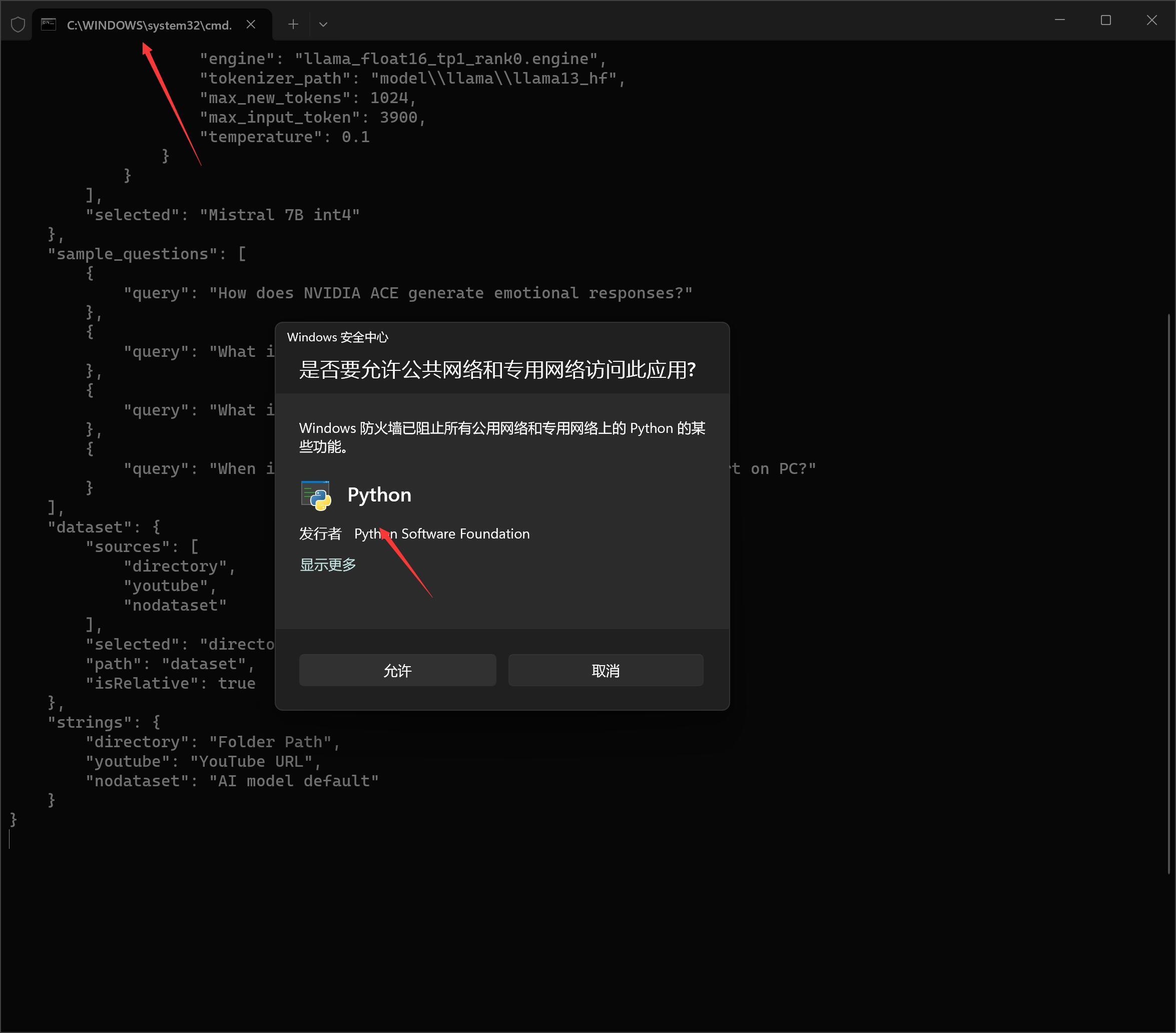
点击玩这些之后,又开始在线下载模型了….
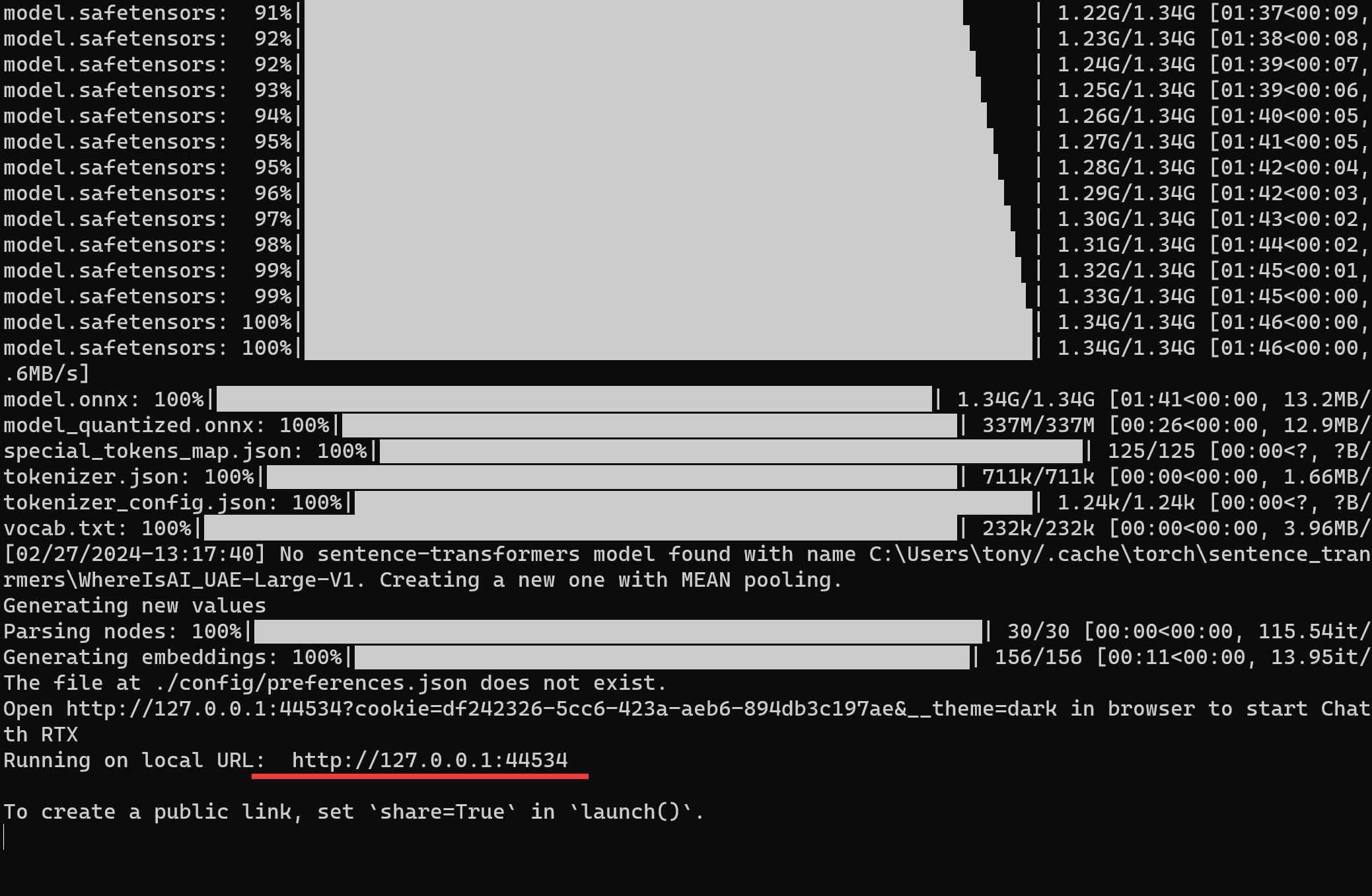
折腾了一圈,最后还是使用了gradio,跳出一个基于webui的浏览器界面。
打开界面之后,按如下步骤,即可开始对话。
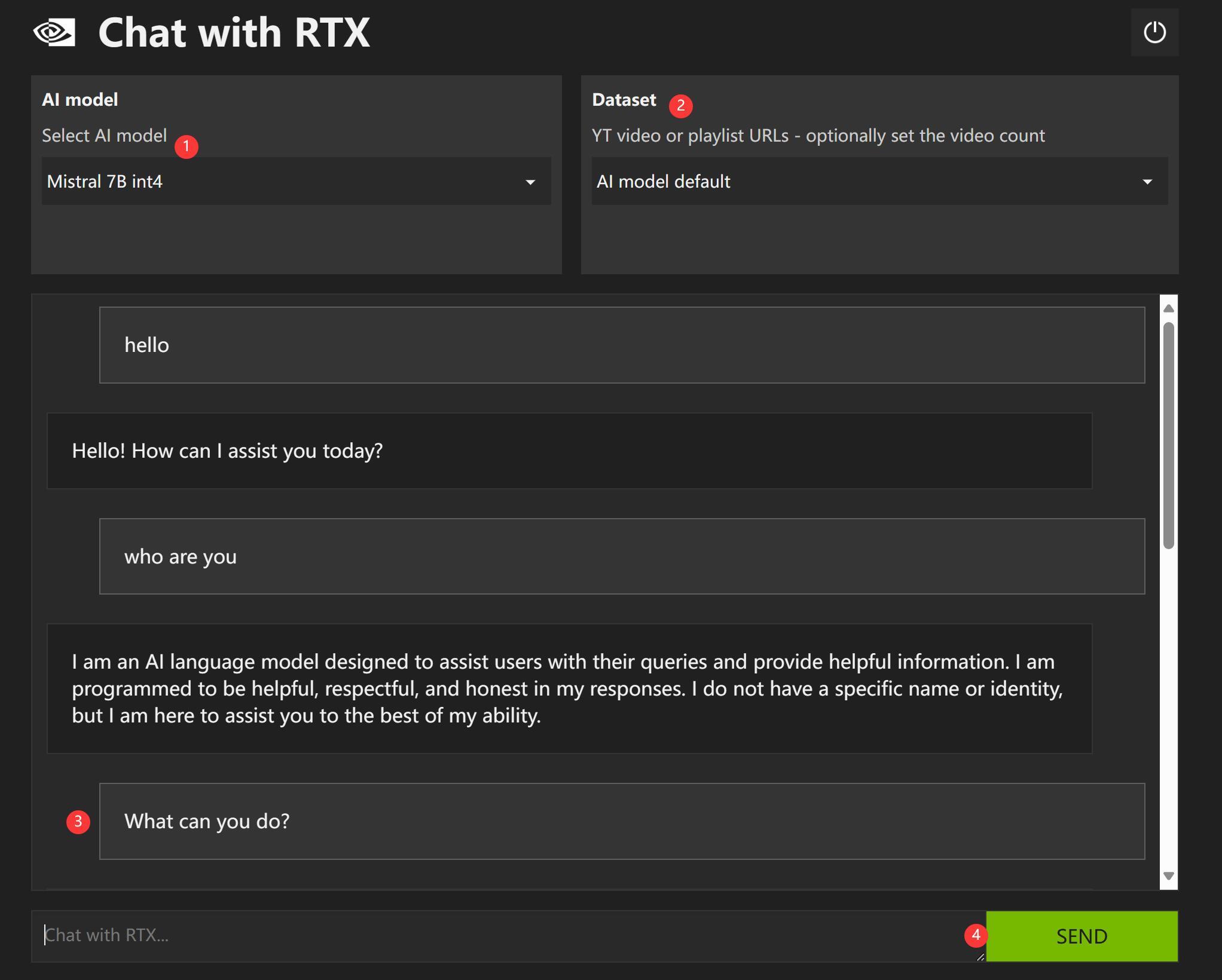
①选择模型,默认就一个Mistral 7b int4。所以不会选错。
②选择本地数据,我们这里先选择 AI model Default。
③ 输入问题。
④ 发送问题。
很快就可以收到回复了。

Mistral 是一个很神奇的存在,最早靠在X上甩磁力链接当发布会而闻名。
在众多英文模型中也算是出类拔萃,通过MoE这种方式实现专业的模型干专业的事情。
但是…管你们英文多厉害,一到中文领域就抓瞎了!
中文表现一言难尽!
我们先抛开语言的问题,来体验下它本地知识库检索功能。
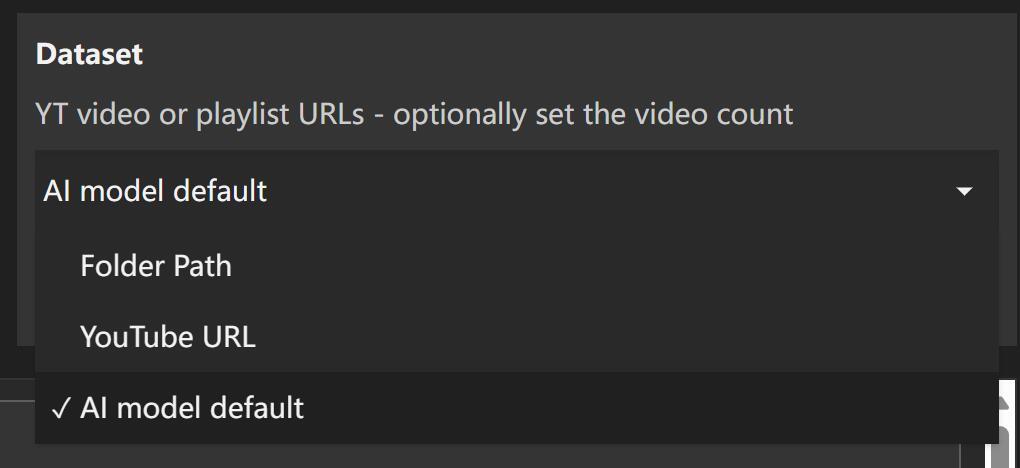
将Dataset选项设置为Folder Path, 默认指向了系统自带的一个dataset文件夹。
为了减少干扰,我们自己来创建一个叫mydataset的文件夹。
里面创建四个文件:
chat-with-rtx-cn.txt (这个软件的中文介绍)
chat-with-rtx.txt(这个软件的英文介绍)
gemini introduce.txt (谷歌双子座的相关信息)
gpt4 introduce.txt(OpenAI GPT4的相关信息。)
点击数据集下的小笔图标,选择我们自定义的文件夹,然后点一下刷新按钮。
接下来,我们直接进行提问“System Requirements” (配置要求)。
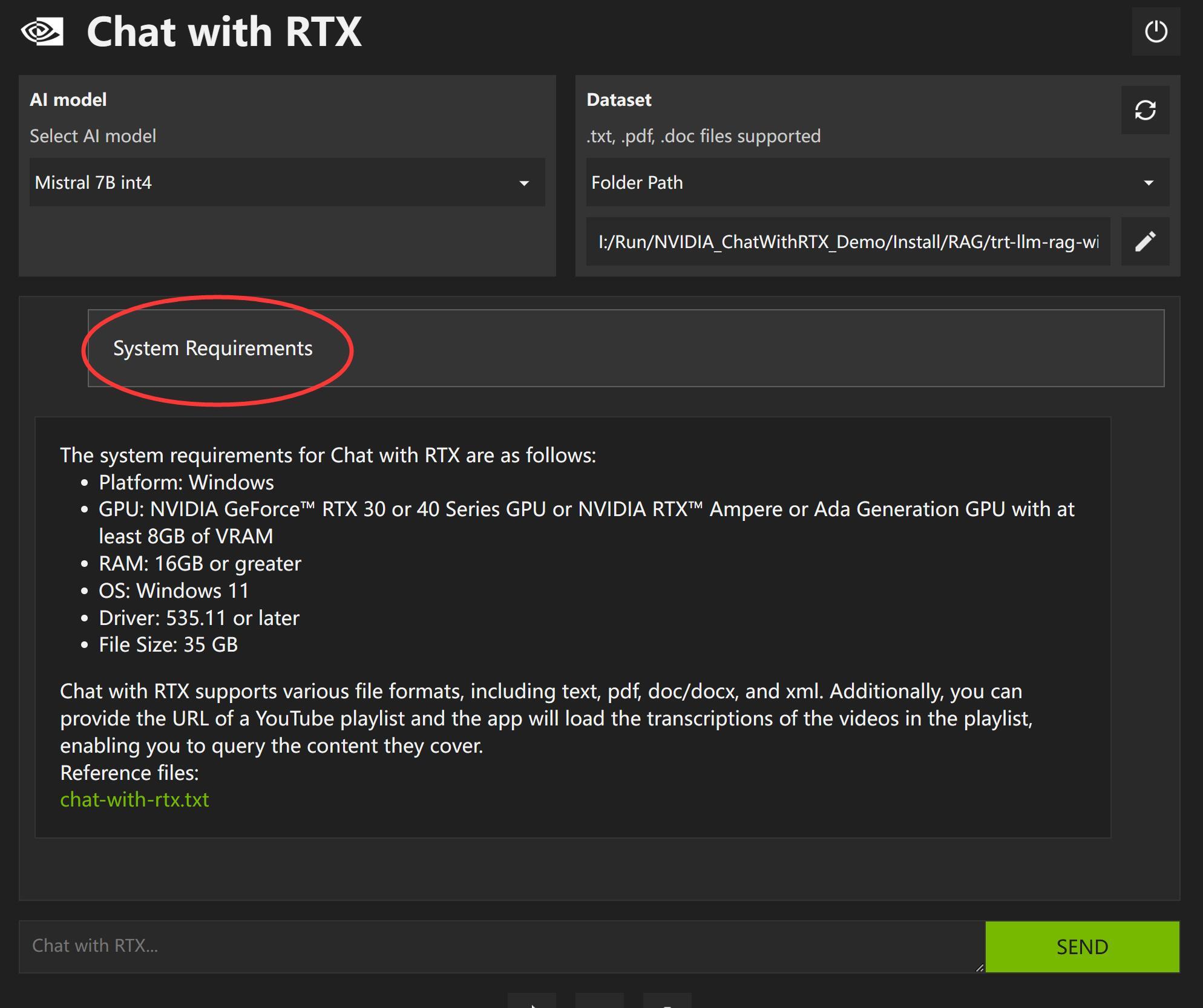
软件准确找出了系统要求部分,最后备注的文件名也是正确的。
另外我有尝试用中文提问,希望他能去中文文件里检索,但是即便你说中文,他还是去英文文件里找答案了。
接着,我又尝试让他“介绍一下Gemini” 。
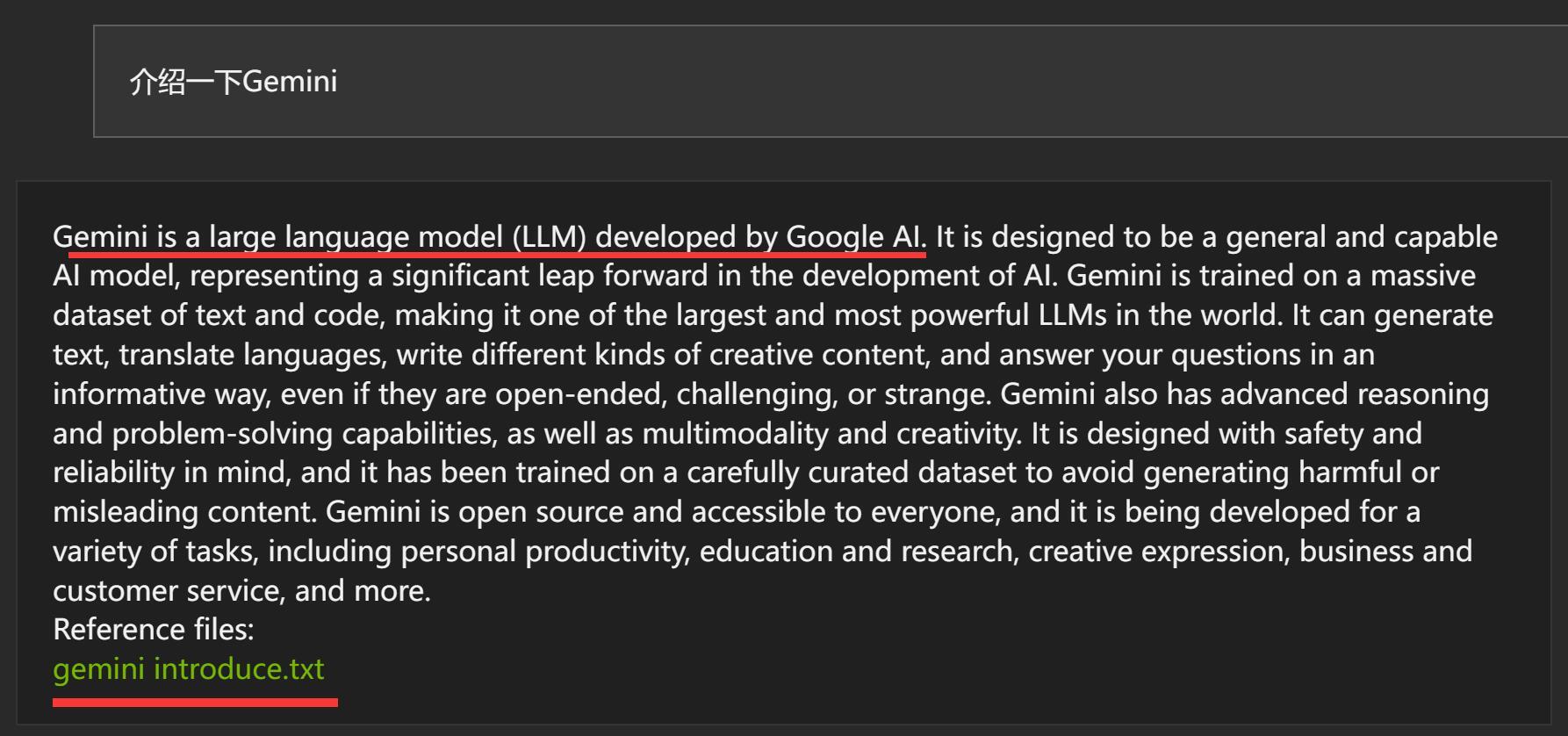
从结果来看,同样准确找到了内容和文件。
因为,文件名就叫“Gemini介绍”,这可能难度太低了。
所以我问了一个文件里面的具体段落里的内容。
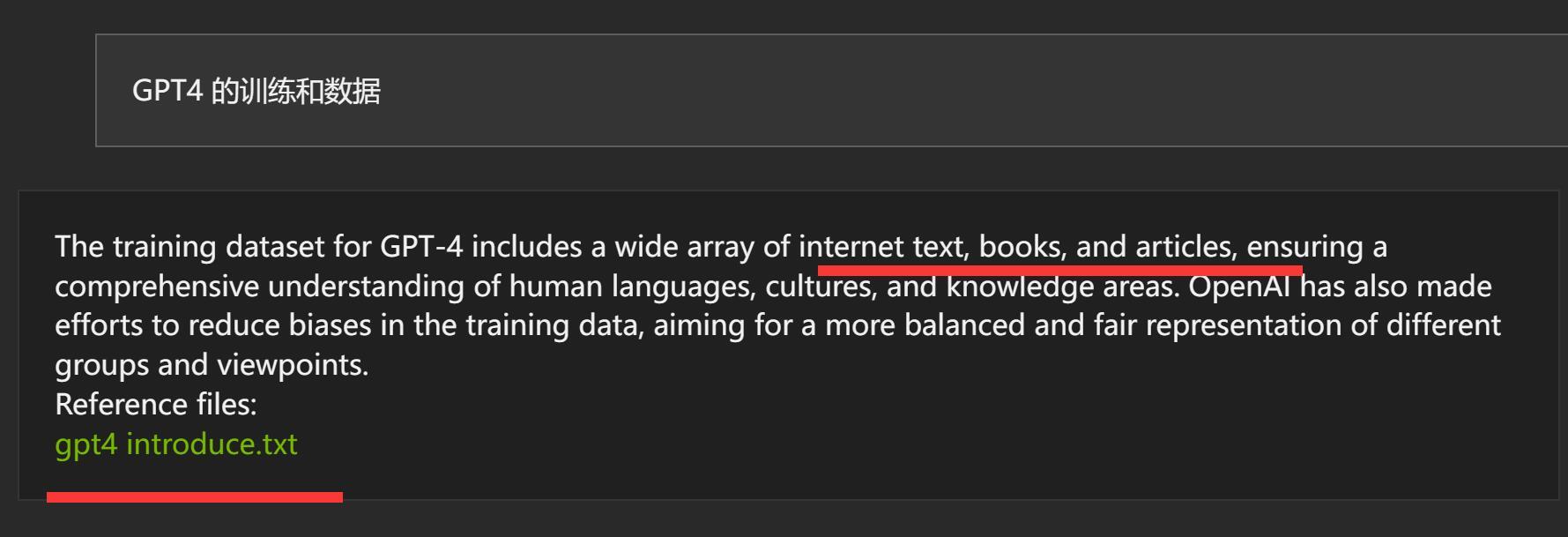
结果是完全准确的。
最后,我们试一下用视频地址作为数据。
我用的是谷歌官方对Gemini的一个介绍视频。视频中大概是讲了关于Gemini的四个点。
网址:
https://www.youtube.com/watch?v=pWPB2uMeSW8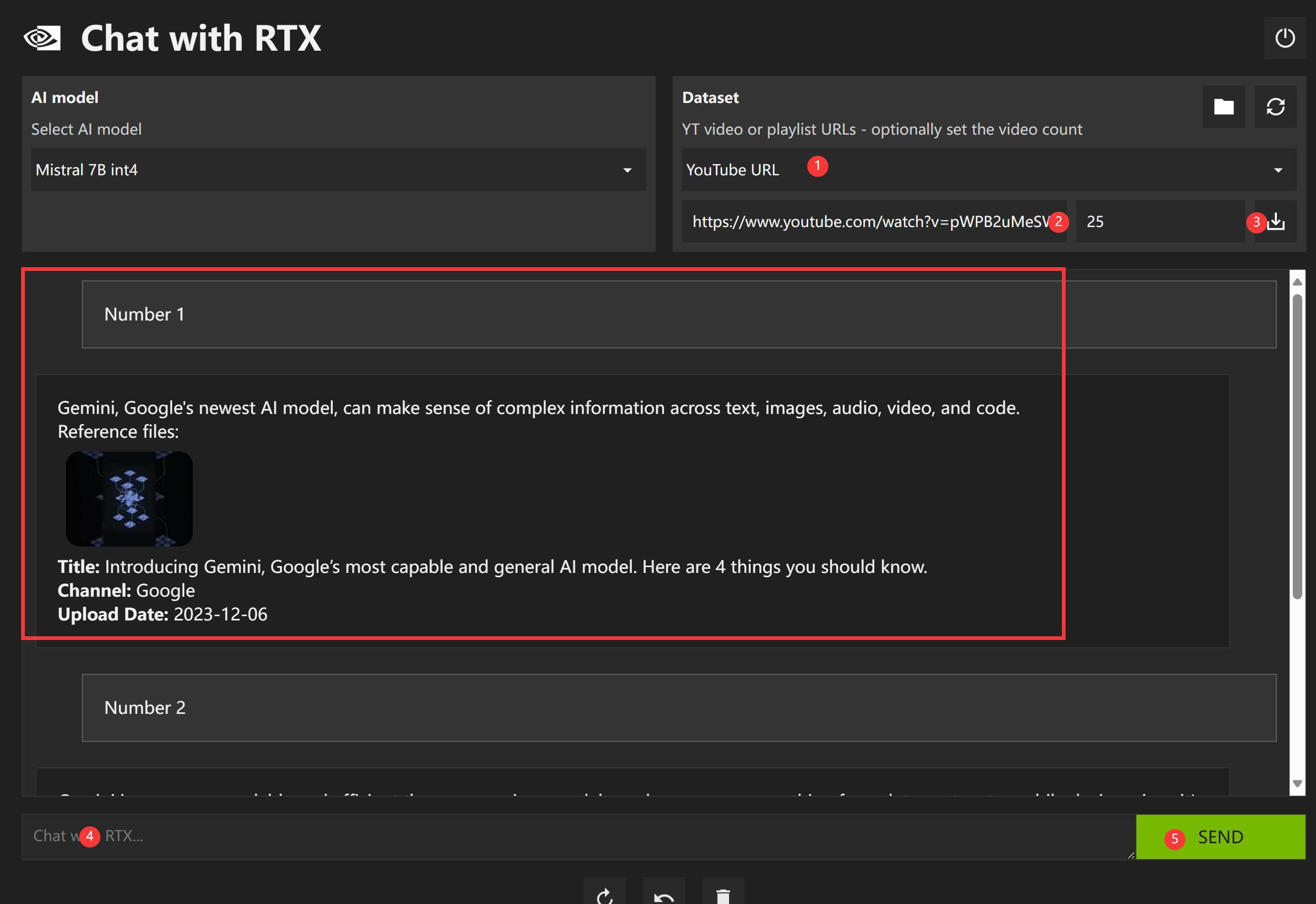
操作如上图
①切换数据类型为youtube URL
②粘贴视频的URL。
③点击下载图标,会自动下载视频文稿。
④提问,比如“第一点是什么?”
提问语言,可以是英文也可以是中文,它反正会回复你英文。
为了对比它的答案是否准确,我找到了原稿,内容如下:
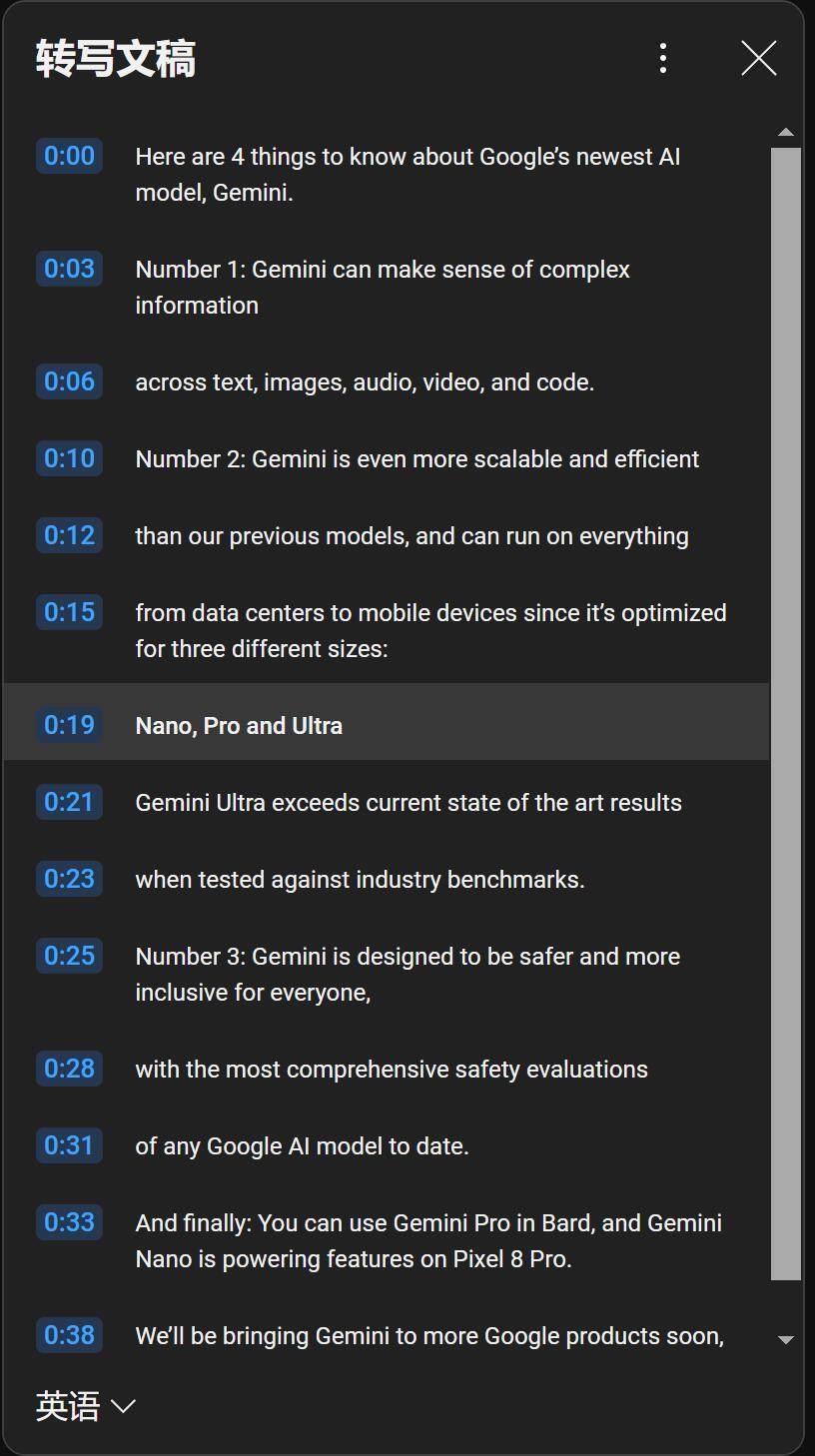
从结果来看,完全准确。它准确地找到了我们需要的内容,列出了视频标题,频道名称,和发布时间。
从它的操作流程来看,很显然它并没有去分析视频内容。
它只是把字幕拉下来,然后在字幕里检索。
毕竟模型摆在这里,不可能这么强大的。
但是,它对内容的识别还是比较精准。
感觉还是有点用处的。
但是有一点不得不说,英伟达这个安装包…看着已经很简单了,但是搞起来,还是有点费时间。
都已经做了35G的软件包了,就不能做成一键运行????
另外,能整一个中文模型就好了,实用性暴增!
除了上面说的两点之外,总的来说,这次体验还比较成功。
英伟达作为这波AI浪潮中最大的受益者,把持了AI命脉–算力,接下来肯定会搞更多事情,可以持续关注。
皮衣刀客,越刀越猛啊。
先是精准切割游戏玩家,现在是精准切割AI玩家了。
股价一飞冲天,别人都在烧钱,老黄在默默数钱!
软件官方网址:
https://www.nvidia.com/en-us/ai-on-rtx/chat-with-rtx-generative-ai/
谁是最强开源模型?gptoss Qwen3 DeepSeekR1五个问题决胜负 !

阿里云版ChatGPT 通义千问 内测申请!
MiniCPM-o 2.6 加载INT4显存减半,以及声音克隆的用法!
关于作者
tony
某人