OpenAI 真开源了!gpt-oss 本地快速运行教程,支持macos 和 Windows
真没想到,本地运行官方版 chatgpt 成真了!

前几天还在说 ollama 升级了,界面看起来很像chatgpt,只要搞个开源模型,比如qwen3,就可以搞一个平民版gpt了。
现在好了,都不用平替了,直接用 chatgpt 官方正版开源模型了。
这次openai的开源虽然姗姗来迟,但是算比较有诚意,而且配套齐全,可以快速上手。
OpenAI这次开源里两个模型,分别是gpt-oss-120b和gpt-oss-20b,都是MOE模型,基准测试都不错。
20B的模型,16G显存也可以运行。 关于这次开源模型的完整介绍可以看这篇《小惊喜,openai真开源了!》
本文只关心一个问题,就是如何在本地快速运行。包括Windows和Macos!
OpenAI 这次开源,准备还是挺充分,一开源,就有非常多的工具支持。

从这个图标可以看到,硬件方面有NVIDIA和AMD等,软件方面有Ollama,LMStudio等,这两个软件在之前的文章中都有详细介绍过。
说的比较多的是Ollama,Ollama对大语言模型的支持非常好,而且更新很快!
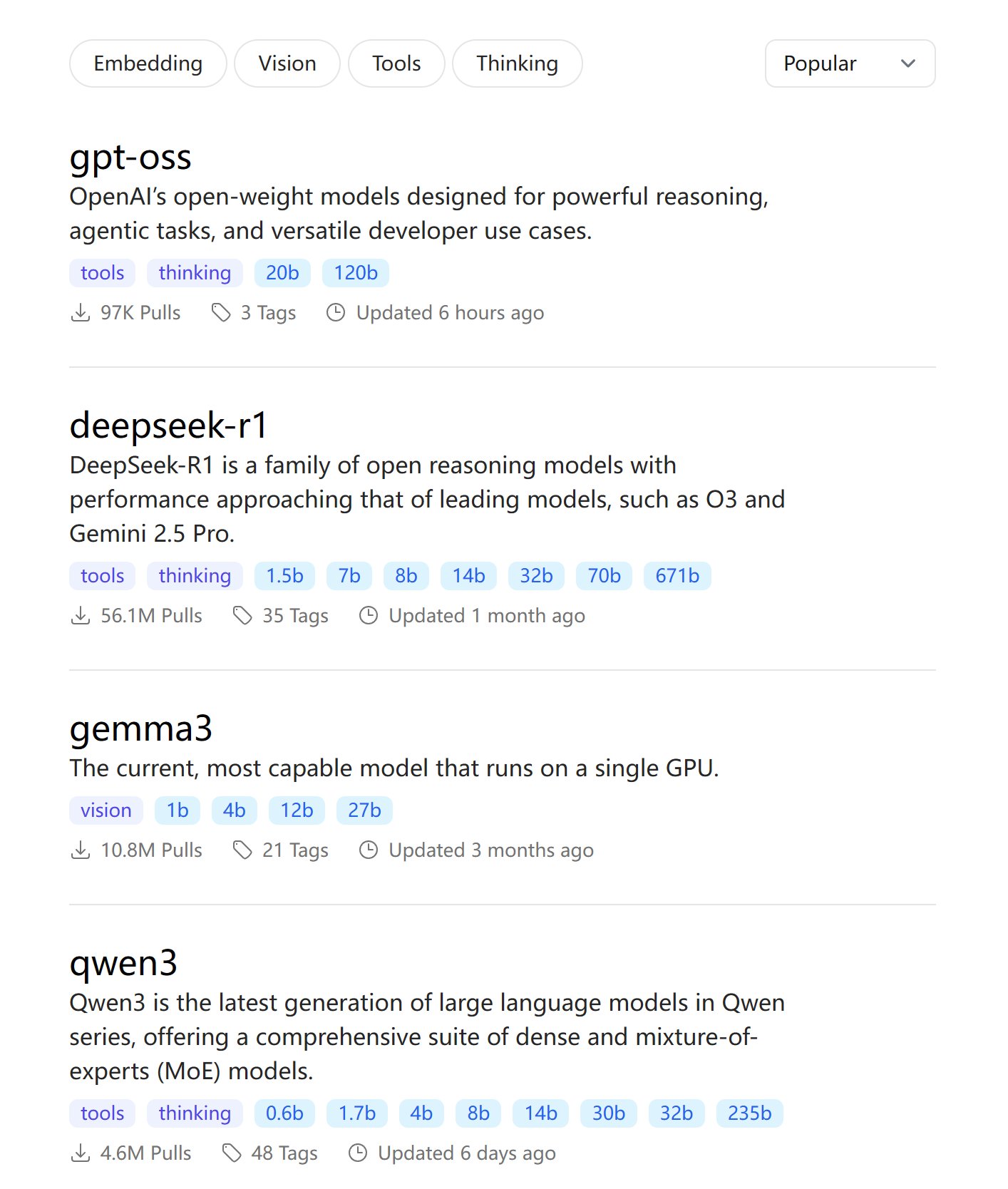
gpt-oss刚出来,就已经躺在Ollama模型热榜第一的位置了。
Ollama可以多平台运行。
所以,无论你是Windows还是macOS的系统,只要打开ollama.com然后,然后下载安装就可以了。
不同的系统,只要选择对应的版本即可。安装完成之后的操作基本一致。
下载完成直接双击安装,没有任何复杂的配置。
安装完成后直接跳出对话窗口。
进来之后,什么都不用干。直接在输入框中输入一个“你好” 。
打开软件之后,Ollama默认就选中了gpt-oss20b。
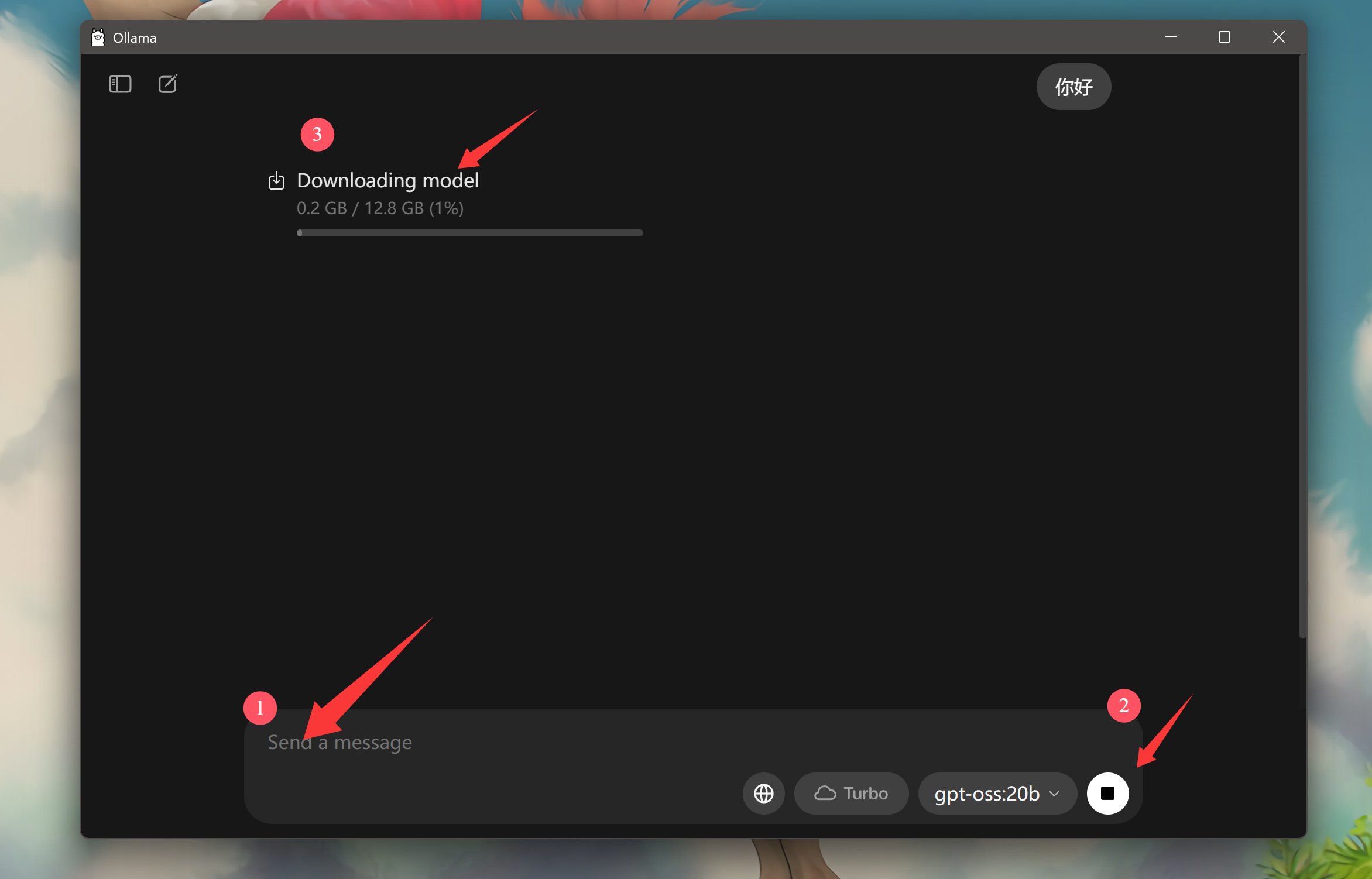
当你输入问题之后,它会自动判断。如果本地已经有模型了,就直接载入模型。如果没有模型,就在先下载模型。
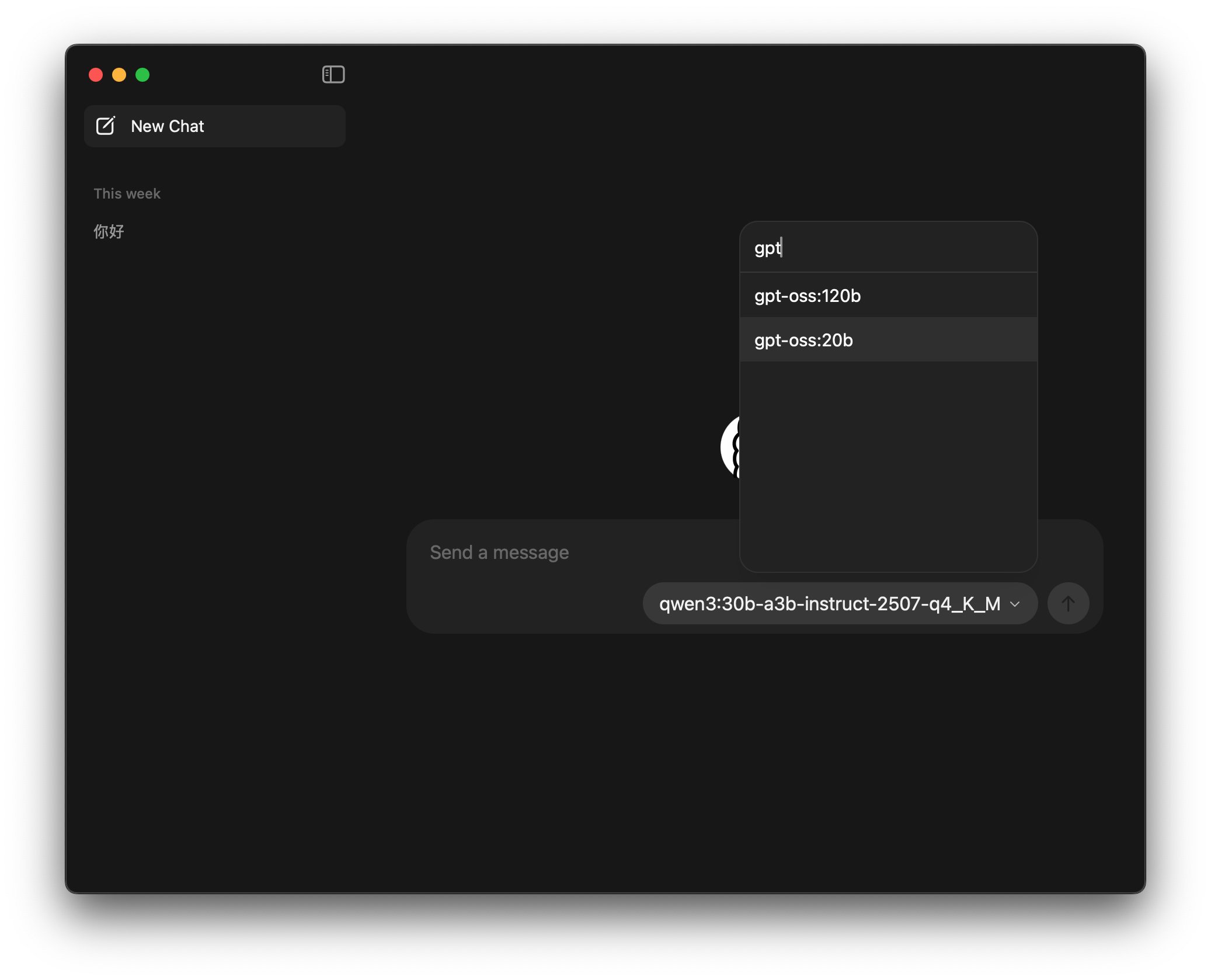
macOS版本可能没有设置默认模型,可以自己搜索一下gpt,选中gpt-oss:20b就可以了。
等模型下载完成之后,就会自动载入模型,回答你提出的问题。
如果你喜欢命令行,当然也可以用传统的方式,在CMD中输入:ollama run gpt-oss
因为模型还在下载中…我就写一点补充内容。
如果你C盘空间比较小,下载模型之前可以先设置一下模型存储地址。
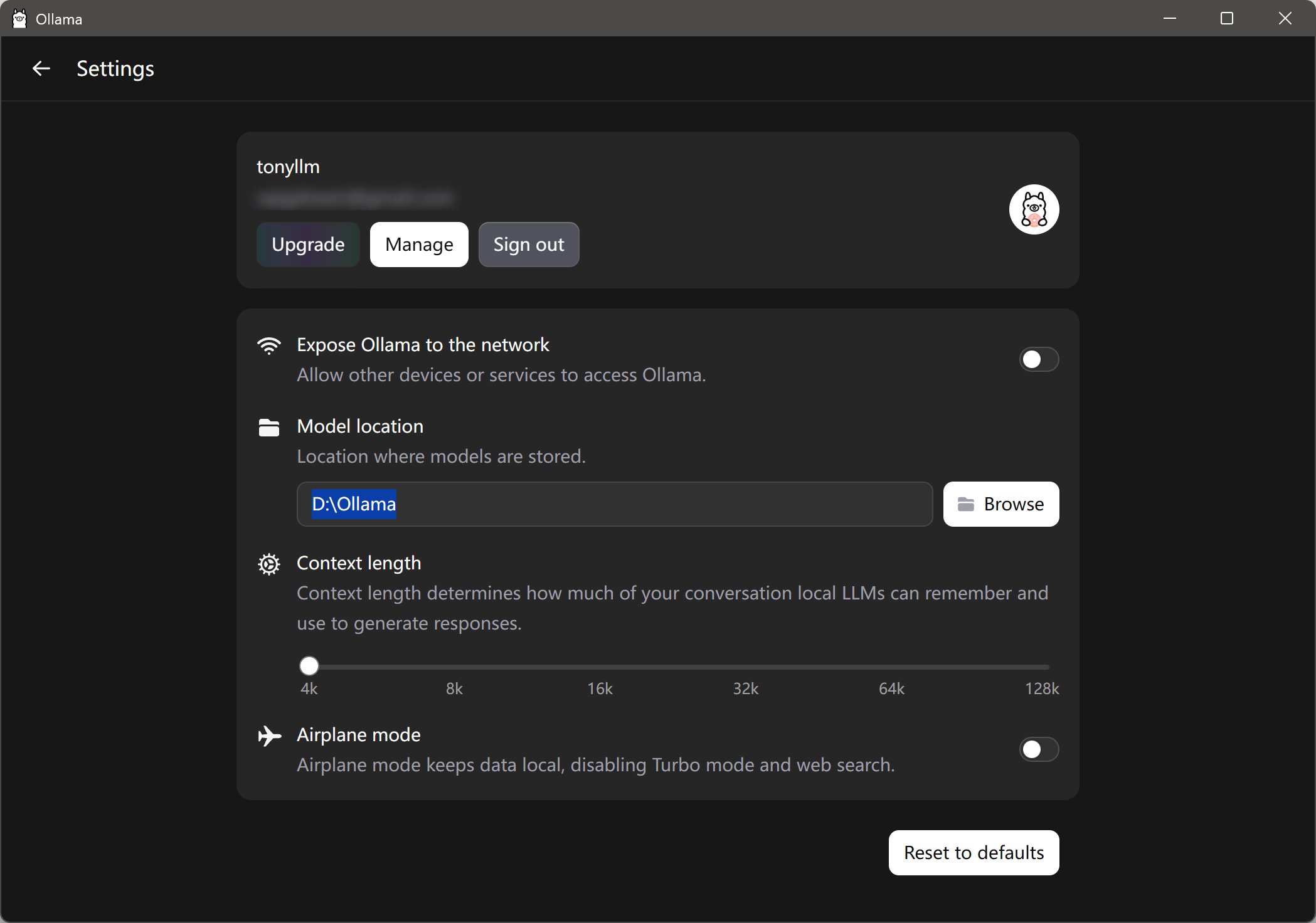
找到Setting,找到Model Location,然后点击Browse,选择一个文件夹。 这样就可以让C盘轻松点了。
另外这里还可以提供了一些其他设置。比如访问控制,上下文长度,飞行模式等。
Ollama似乎也要考虑赢利了,网页端和客户端都添加了Turbo的入口,且用且珍惜!
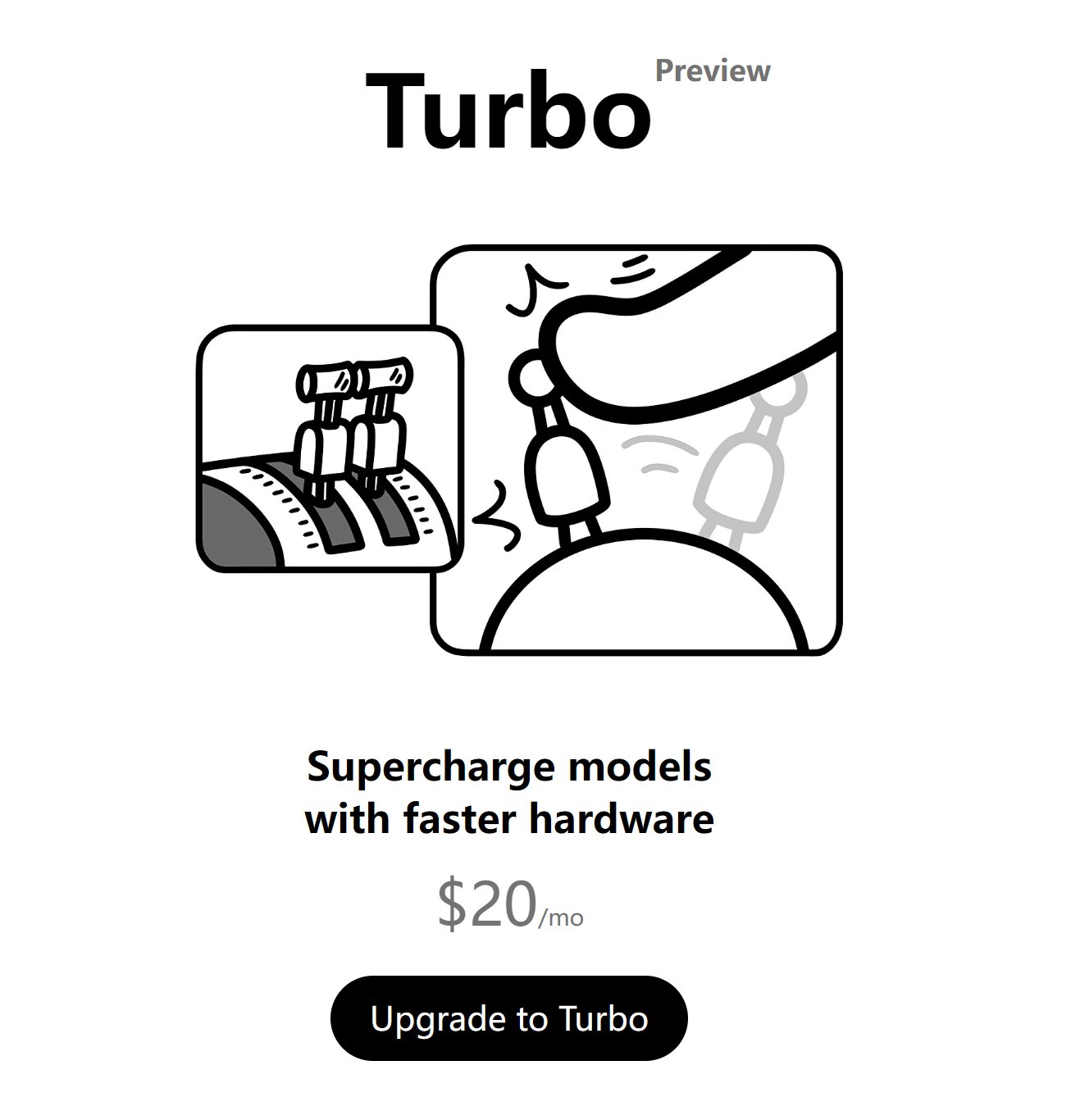
看了一眼,价格是$20/mo。 AI产品是真的不便宜啊。起步价就是20美金,多希望他们能用人民币计价啊!
Turbo从描述来看是使用云端模型,这样就能解放本地电脑了,相当于是给Ollama用户提供了另一种选择。不过,用Ollama的大部分是希望本地运行模型,本地模式肯定会继续保留。
从外网下载一个12G的文件,还真不是一件容易的事情啊,主要等不起。如果你们有需要,可以从我网盘下载。
上次用AI写了一个Ollama模型搬家的小工具,现在拿来分享模型也很方便。
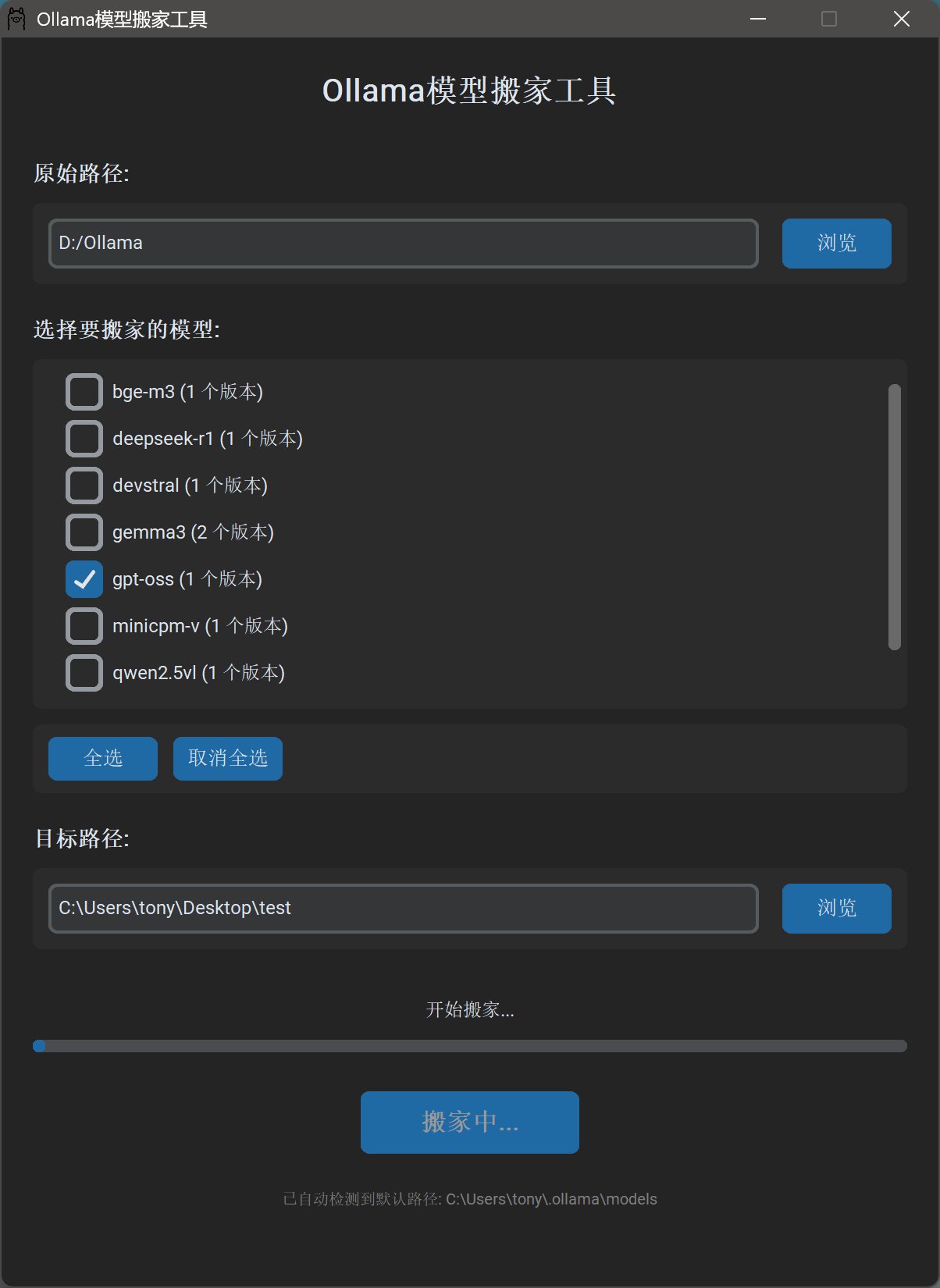
我只要勾选某个模型,就能一次性把对应的模型文件全部拷贝到指定路径来。
然后把模型文件分享出来,获取模型之后,导入也很方便。
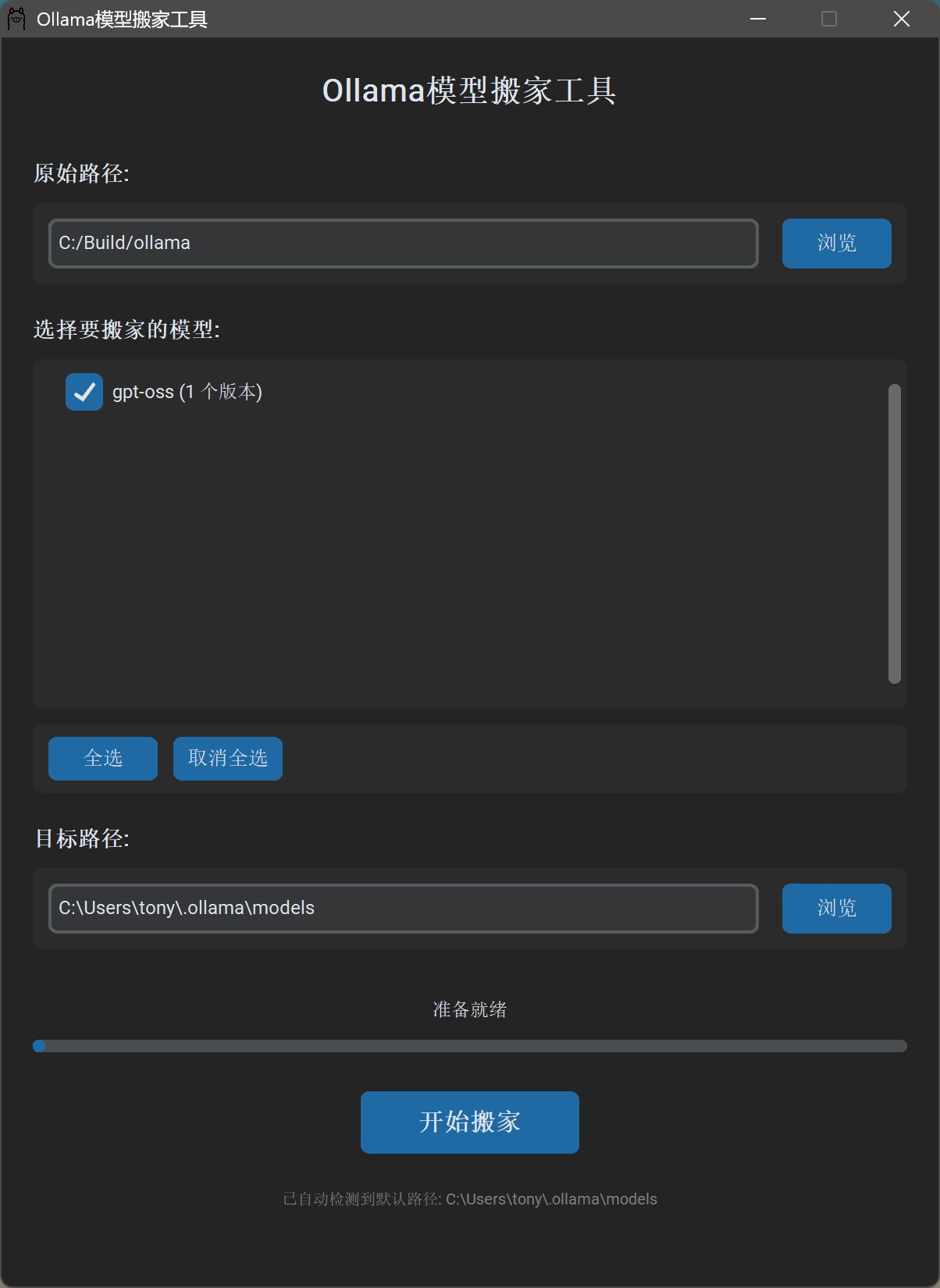
只要把原始路径改为,下载保存路径。然后目标路径改为本地模型的存放路径。点一下就搞定了。
回归正题 终于99%了!!!
下载完成之后,显卡就开始干活!
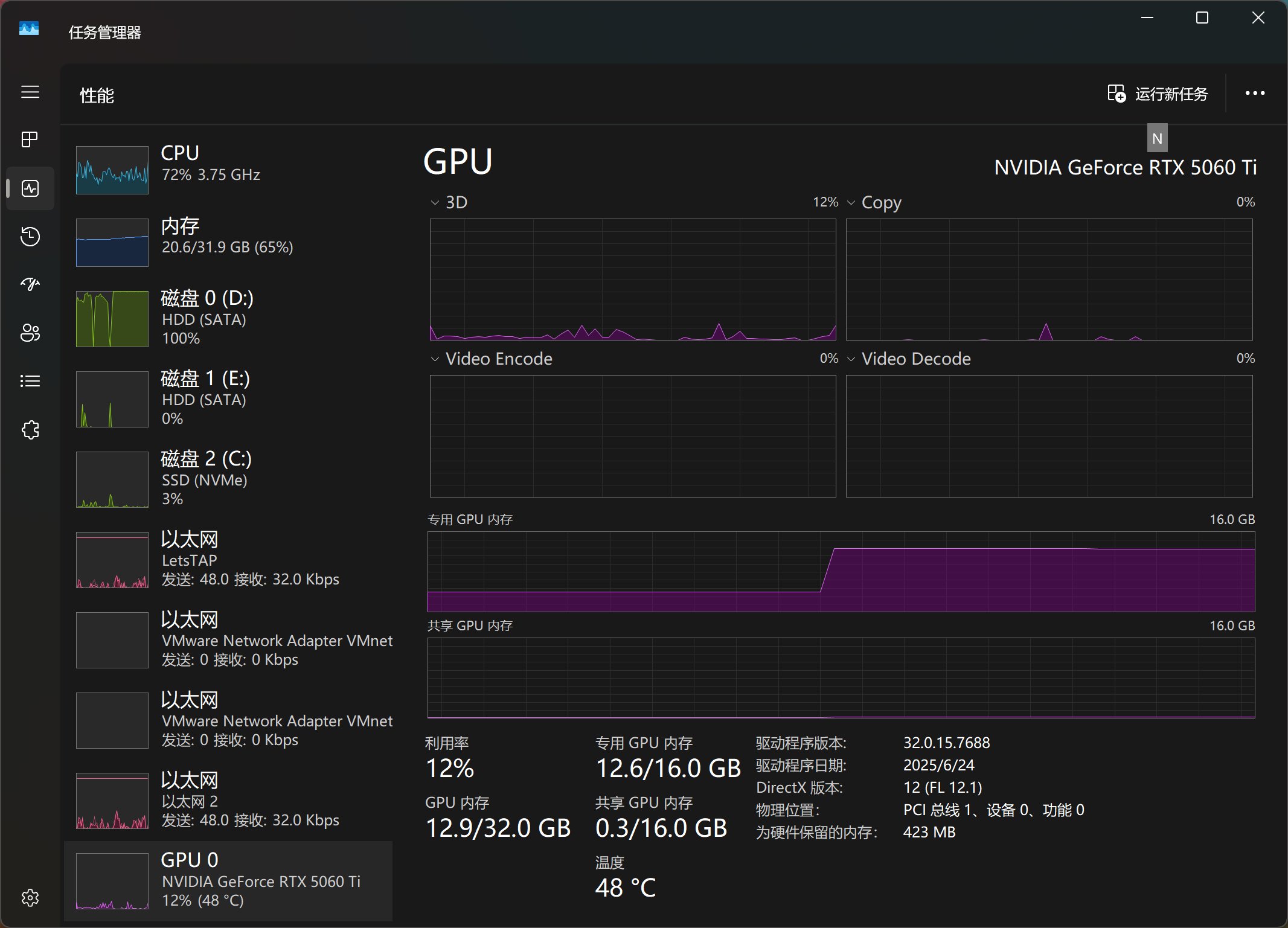
从上图中可以看到,载入模型之前显存消耗为4GB左右,载入之后为12.6GB左右。粗略看来16G的显卡,显存还有空余。
载入之后,再随便提一个问题:“你是谁”
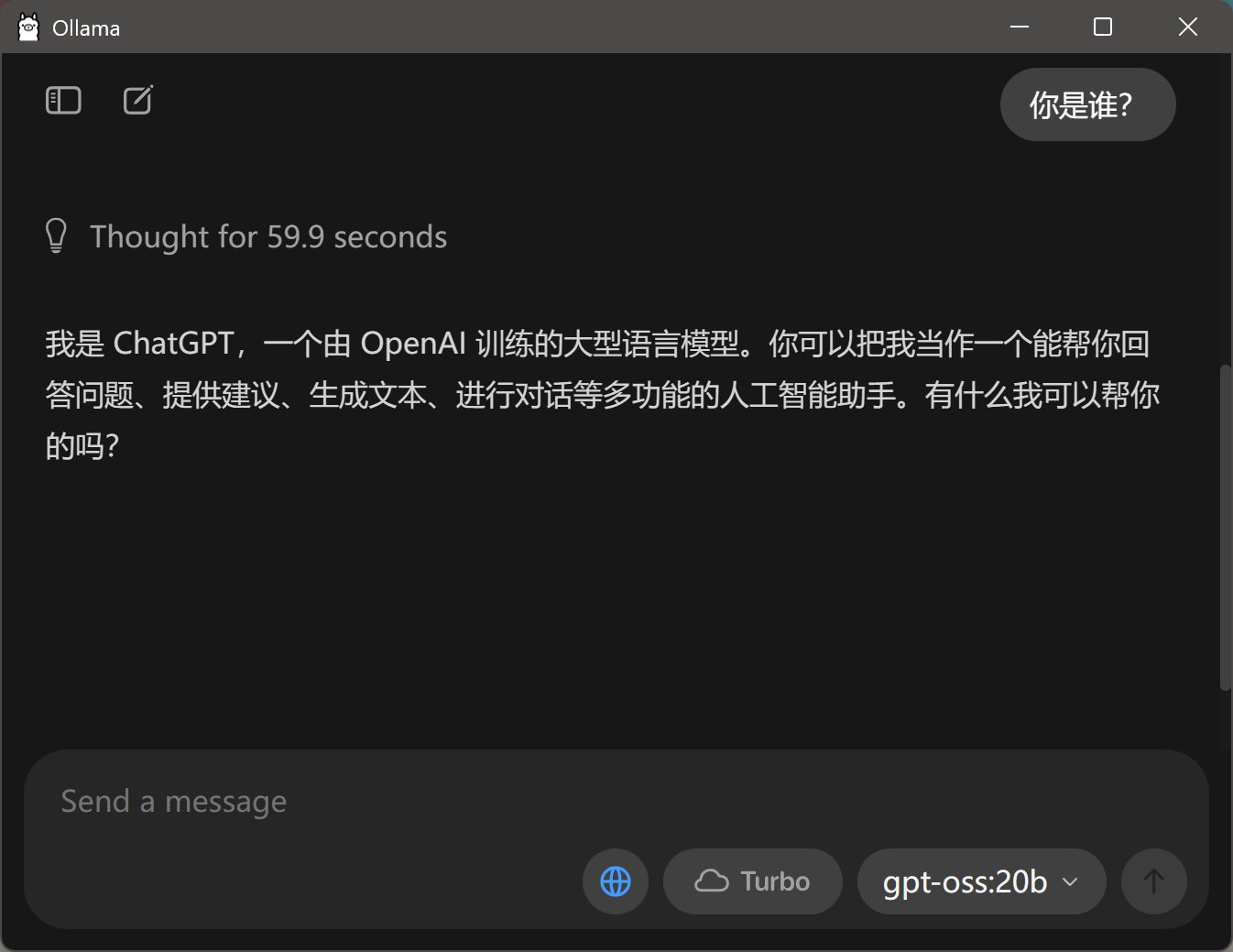
它的回答是这样的:“我是 ChatGPT,一个由 OpenAI 训练的大型语言模型。你可以把我当作一个能帮你回答问题、提供建议、生成文本、进行对话等多功能的人工智能助手。有什么我可以帮你的吗?”。
这回答没毛病啊,一点毛病都没有!自我认知非常清晰。
但是…你们看到那个恐怖的思考时间了么?还好这个是动态的!!!

第二次回答思考快了很多。
…但是正常的输出速度也不是很快。而且他在回答的时候,竟然占满了CPU。到这里,我要推翻上面的判断,我有点怀疑16GB不够它用。它把部分内容卸载到CPU了。
使用verbose参数,测试了一下tonken的速度,显示如下:
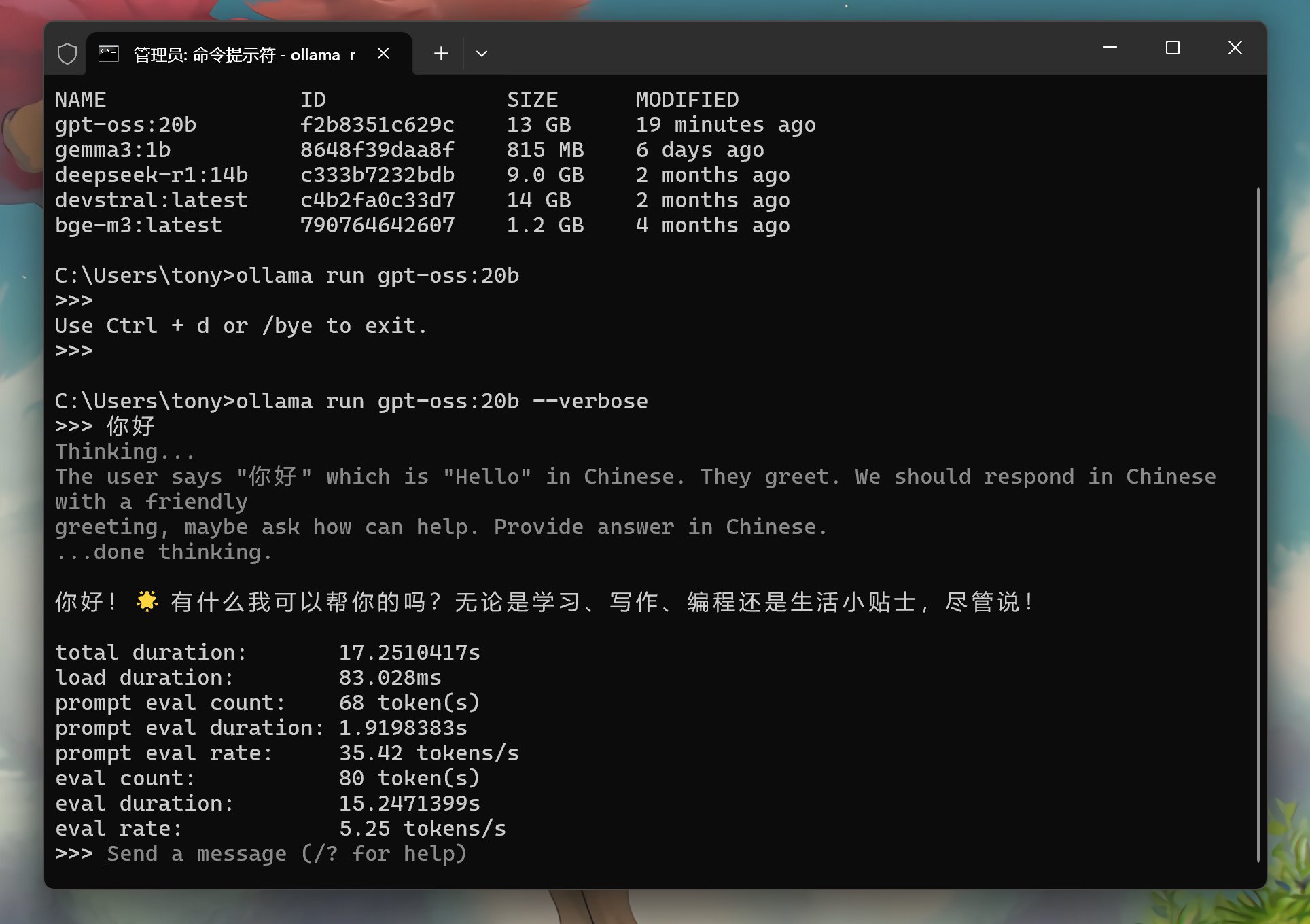
在命令行工具中,输出相对丝滑一些,但是速度确实不是很快。每秒钟5个tokens的样子。
为了验证是否显存约束了速度,我在3090上又搞了一遍。
结果如下:
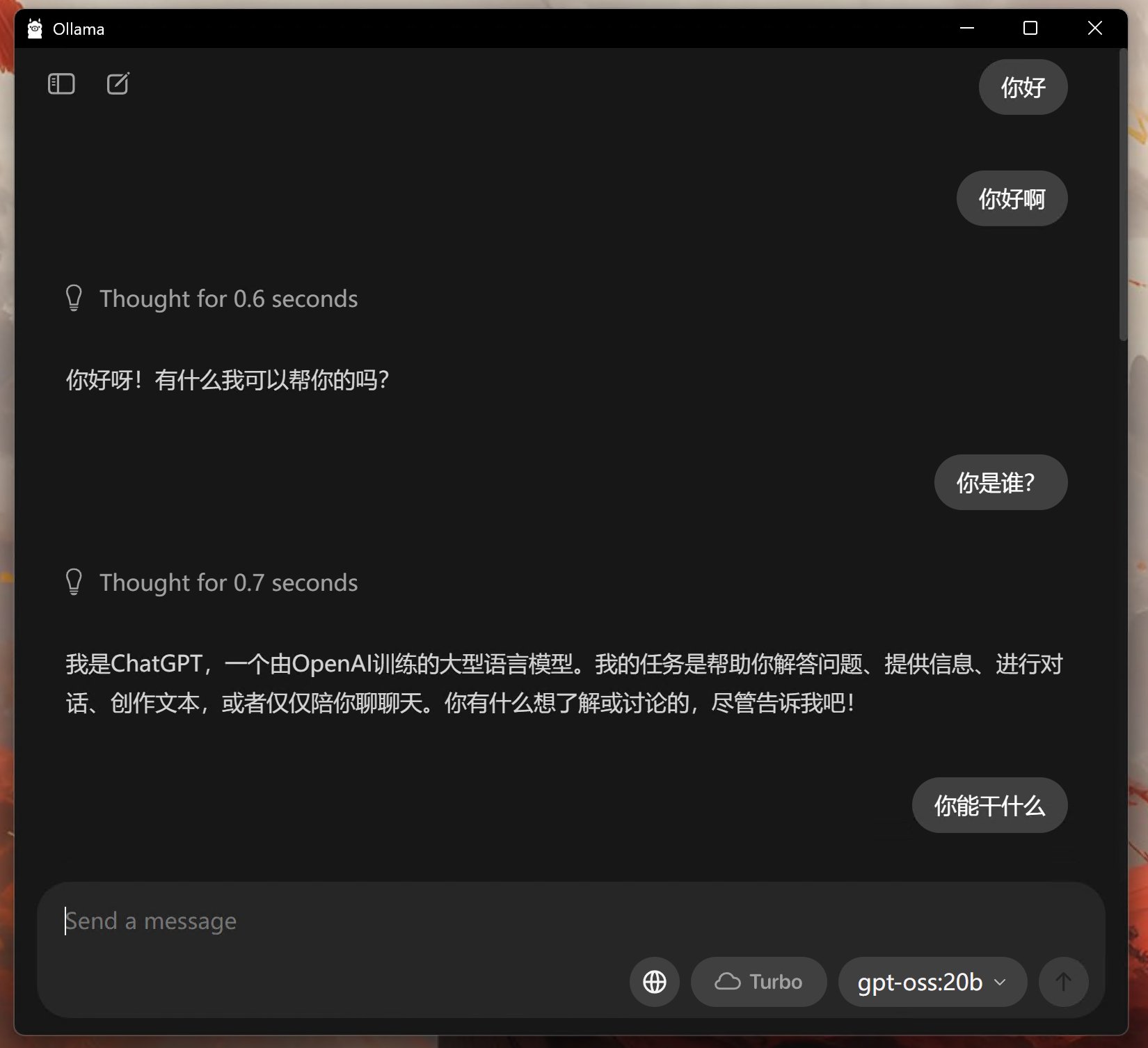
同样的问题,思考过程只有了零点几秒。
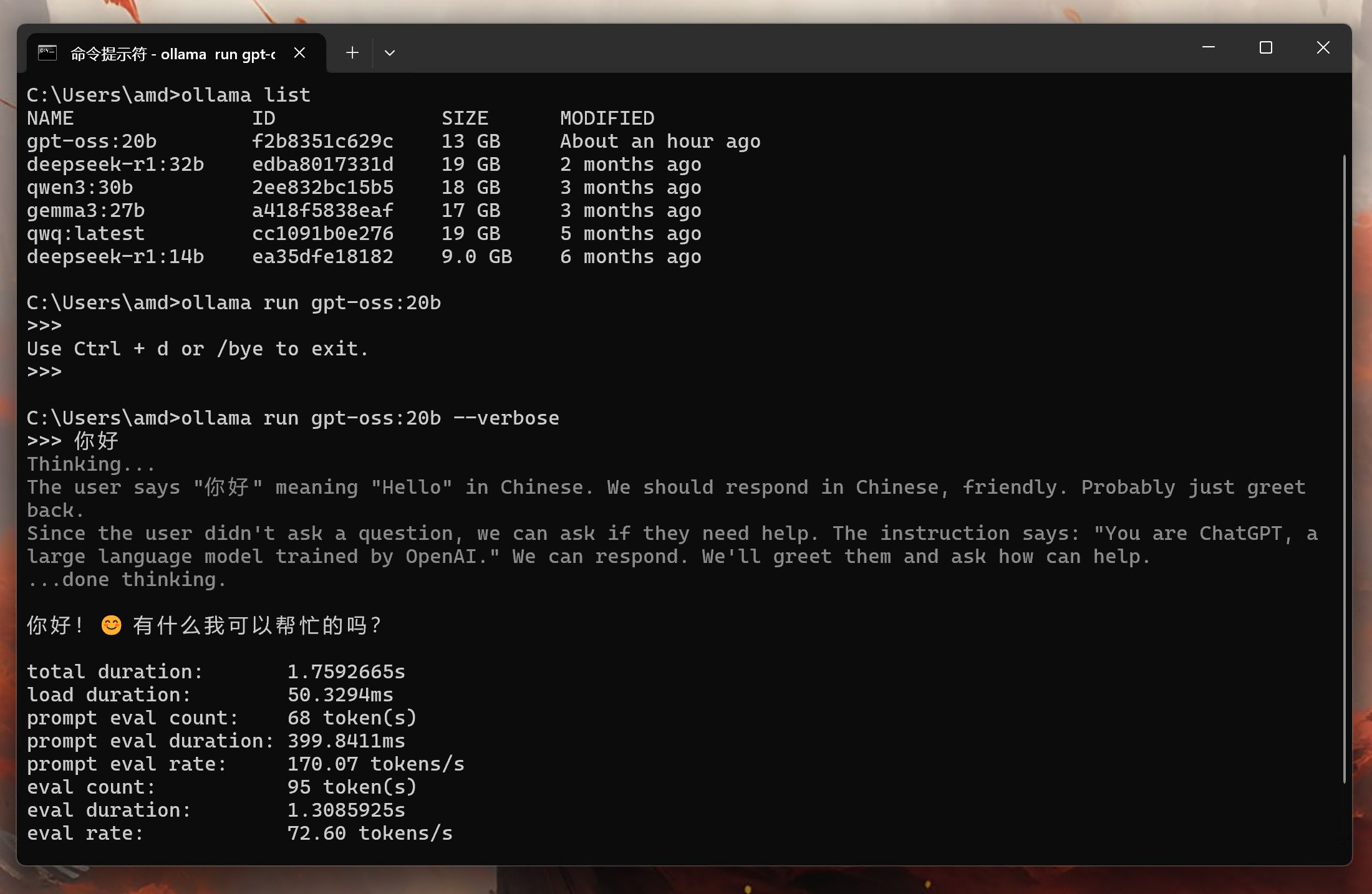
实测速度高达72tokens/s每秒。
这速度简直快到飞起啊! 这个速度应该是比Qwen3 30B快不少。 也就是只要有一张24G显存的显卡,本地运行这个尺寸的gpt-oss,速度会非常快,完全达到了能干活的速度!!
作为和wini+N卡的对比,我也在Macmini m4 24G上跑了一下,结果如下:
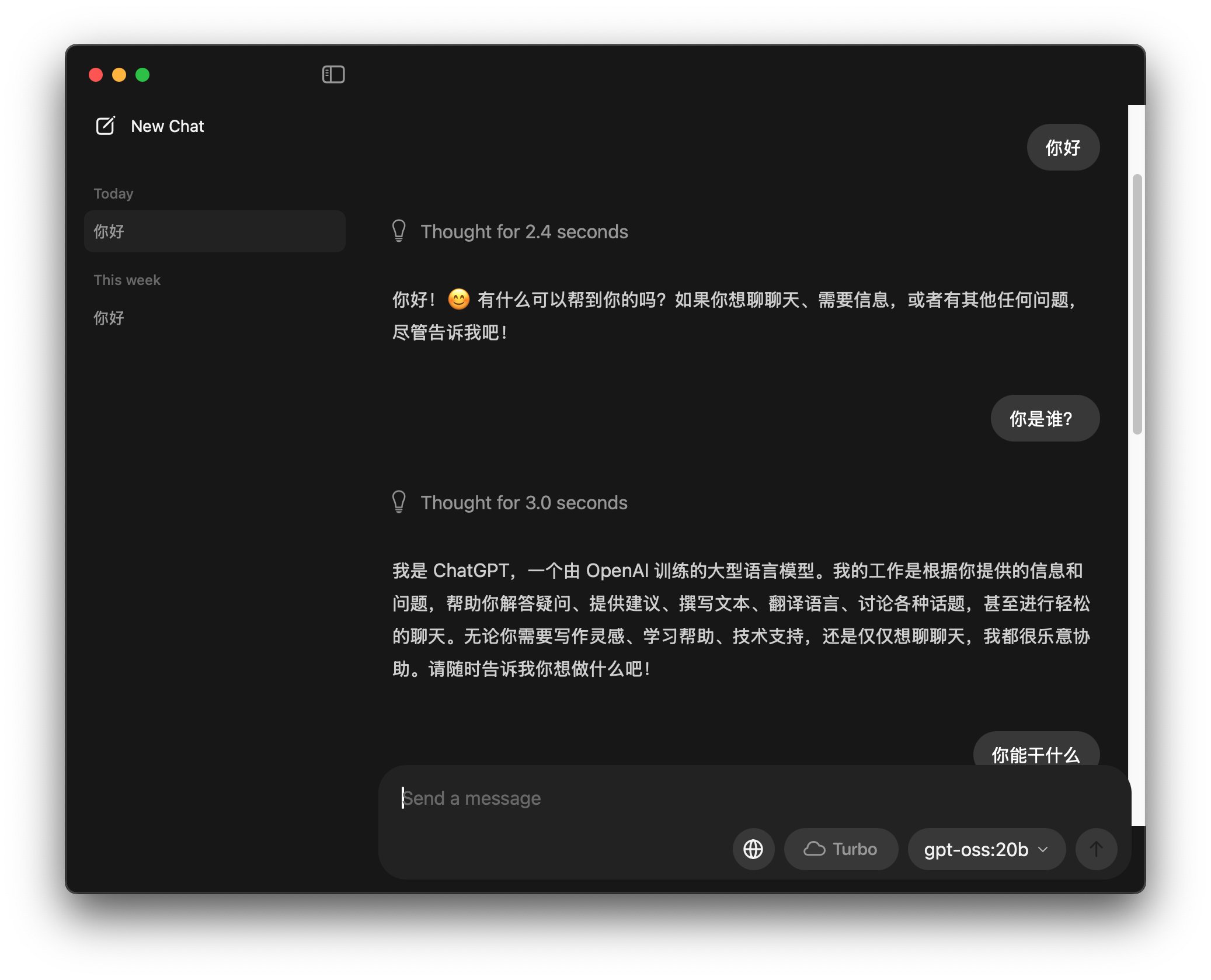
首先是上图对话中可以看到,思考时间也非常短。
另外测试了一下速度:
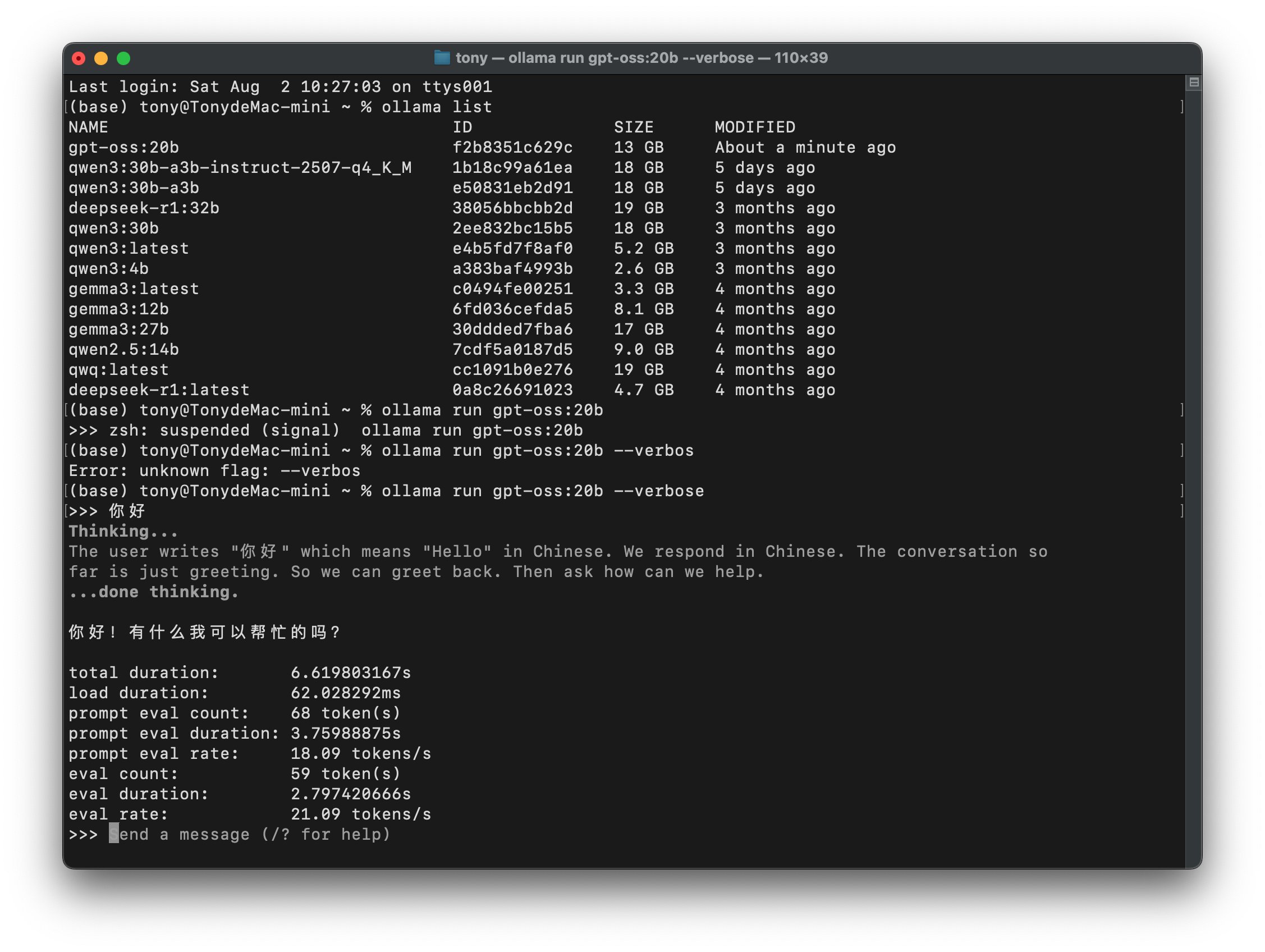
速度为21 tonkens/s 左右,这个速度用起来已经很丝滑了。
mac炼丹不行,但是大语言模型推理这个一个分支,已经做得不错了。 像Qwen3 和gpt-oss 20~30B的moe版本都可以流畅运行。
主要是macmini就电视盒子那么大哦!一张N卡的空间可以放两个macmini。
OpenAI这个模型,跑起来还是很爽滴。而且从多次测试中可以看到,它回答问题的稳定性非常高。
OpenAI在模型的上限方面似乎越来越落后了,但是在下限方面却遥遥领先。主要就是回答幻觉低,稳定性,准确性高。这些特性总结一下就是“实用,靠谱” !
曾经有一段时间我非常讨厌gpt,因为它降智且放弃追求更高更强了。但是后来降智好了,我就不纠结了。我也慢慢理解了它的策略。它并不是把gpt当一种技术,只求学术上的顶尖。而是把gpt做成了产品, 所以实用,稳定,靠谱,就成了核心目标。
什么样的目标,就会有什么样的结果!
另外还有一个很意思是的问题。
Qwen3最近把思考模型和非思考模型分开发布了。而openai却准备把标准模型和O系列模型合而为一。 可以看到gpt-oss 也是包含了深度思考,而且分了三个等级。
我突然很想对比一下这两个模型了。
另外,这次openai开源,还是得感谢大模型开源一哥Qwen,疯狂开源各种模型。
Qwen可以继续努力,再逼一逼openai,把多模态也开源一下呗!
软件和模型,给公众号托尼不是塔克发送gptoss获取!

AI长眼睛了,玩一玩视觉·语言·大模型!Qwen-VL

AI聊天:ChatGPT图文版玩一玩!Visual ChatGPT
DeepSeek R1果然有点意思! Windows本地使用ollama轻松跑起来。
关于作者
tony
某人