谁是最强开源模型?gptoss Qwen3 DeepSeekR1五个问题决胜负 !
现在开源模型非常多,到底哪个好用?这估计成了很多的问题 ! 我也是很好奇。 但是要全面测试和对比是一件很困难的事情。
从比较专业的角度来说,直接比基准测试就可以了。
但是,实际上也会有一些问题。而且有时候 ,基准强,实战未必强。所以反正测不准,我就按自己设定的维度来对比一下。
五个问题决胜负!就当是娱乐局!
今天的参赛选手分别是:
- DeepSeek-R1-0528,
- Qwen3-30B-A3B-Thinking-2507,
- gpt-oss-20b。
这三个模型参赛在并不完全一样,但是24G的显卡中都可以跑。也是24G显卡能跑的模型中最新最强的版本了。 所以,我们尽量忽略其他细节,就用rtx3090来看看谁最好用!
今天的测试的五个问题分别是:
- DeepSeek 里面有几个e?
- 11.9和11.12 哪个数字大?
- 找出一个正整数 n,使得 n! 可以被 2^n 整除。
- 米长的竹竿能否通过4米高,3米宽的门?
- 有 5 个人排成一排,每人帽子颜色为红或蓝。他们可以看到前面的人的帽子,但看不到自己的。主持人宣布:“至少有一顶红帽子。”从最后一人开始,每人依次说“是”或“否”(表示是否知道自己帽子的颜色)。如果第 5 人说“否”,第 4 人说“是”,求所有可能的帽子颜色分布。
评判标准是正确率和用时。
基准测试数据
虽然今天的重点不是基准测试,但是开头还是贴一下每个模型基准测试数据。好让大家 有个参考。
DeepSeek-R1-0528: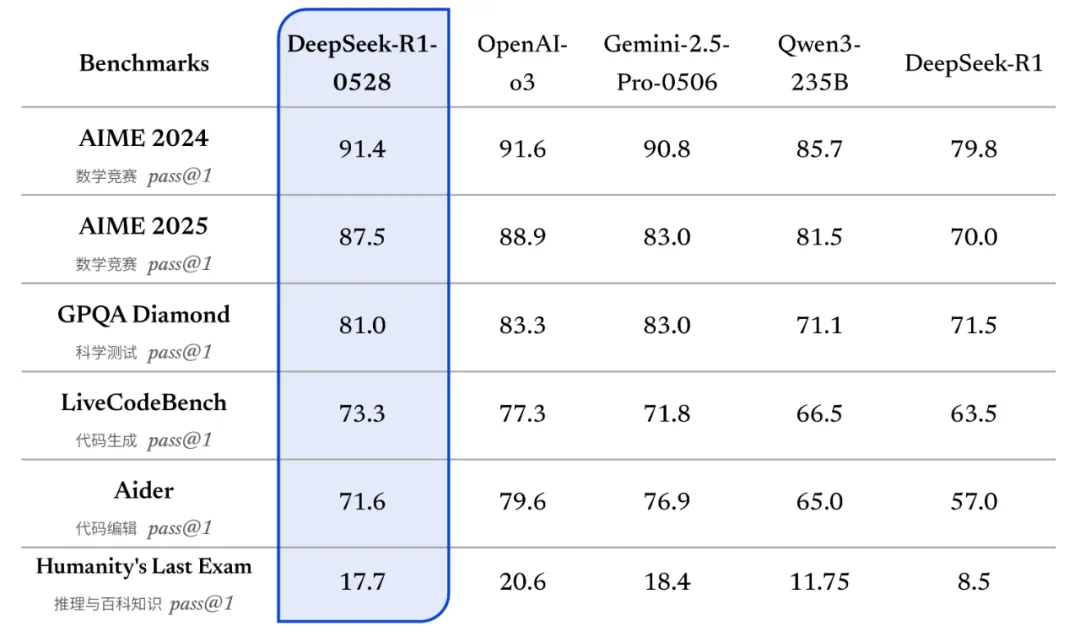
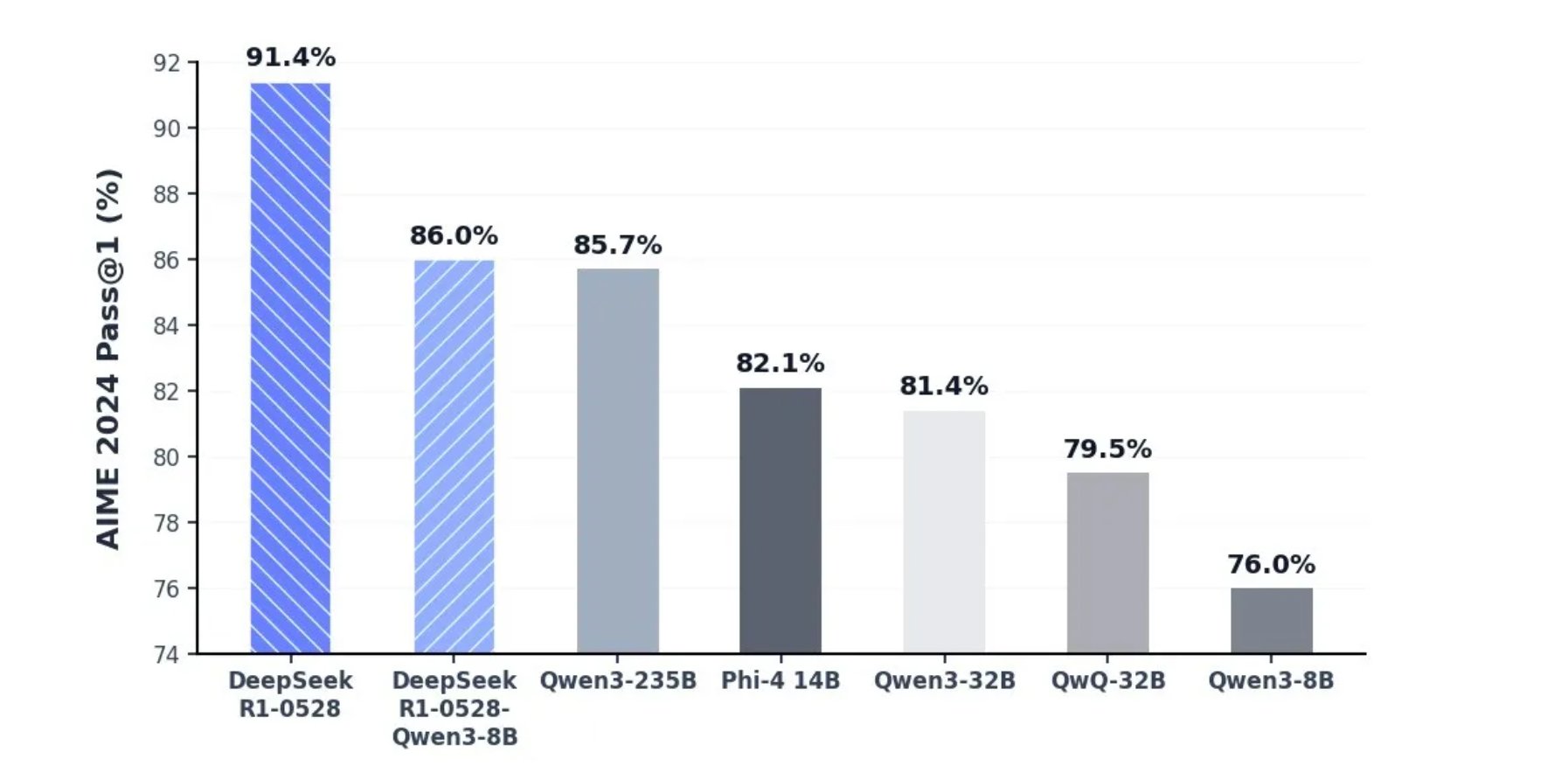
Qwen3-2507:
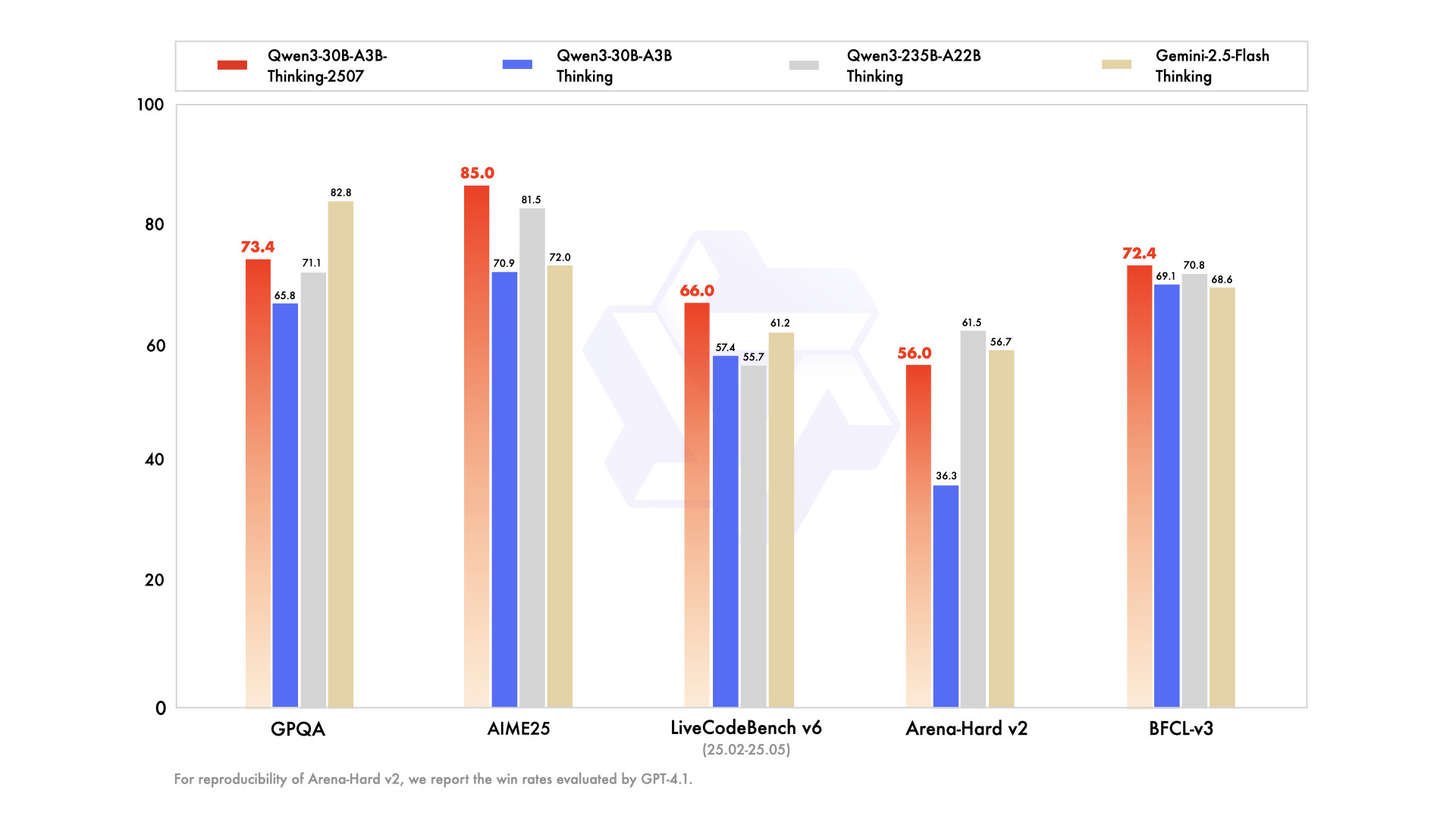
gpt-oss-20b:
通过上面的图片,有几项是可以直接对比的。但是,并不是每一项都能对得上。不同模型,给的基准不一样。DeepSeek只公布了满血版的数据,32B版本这里没写。而且我们测试的所有模型,和图片中模型不完全一样,我们能跑的都是缩水版(量化版)。
下面开始测试!!!
数数和比大小
前两个问题,别看很简单,几个月前,一大堆非推理模型都回答不了。
但是对于现在的新版模型来说基本上不存在什么问题。
唯一的差别,就是回答过程和回答时间不太一样。
DeepSeek:
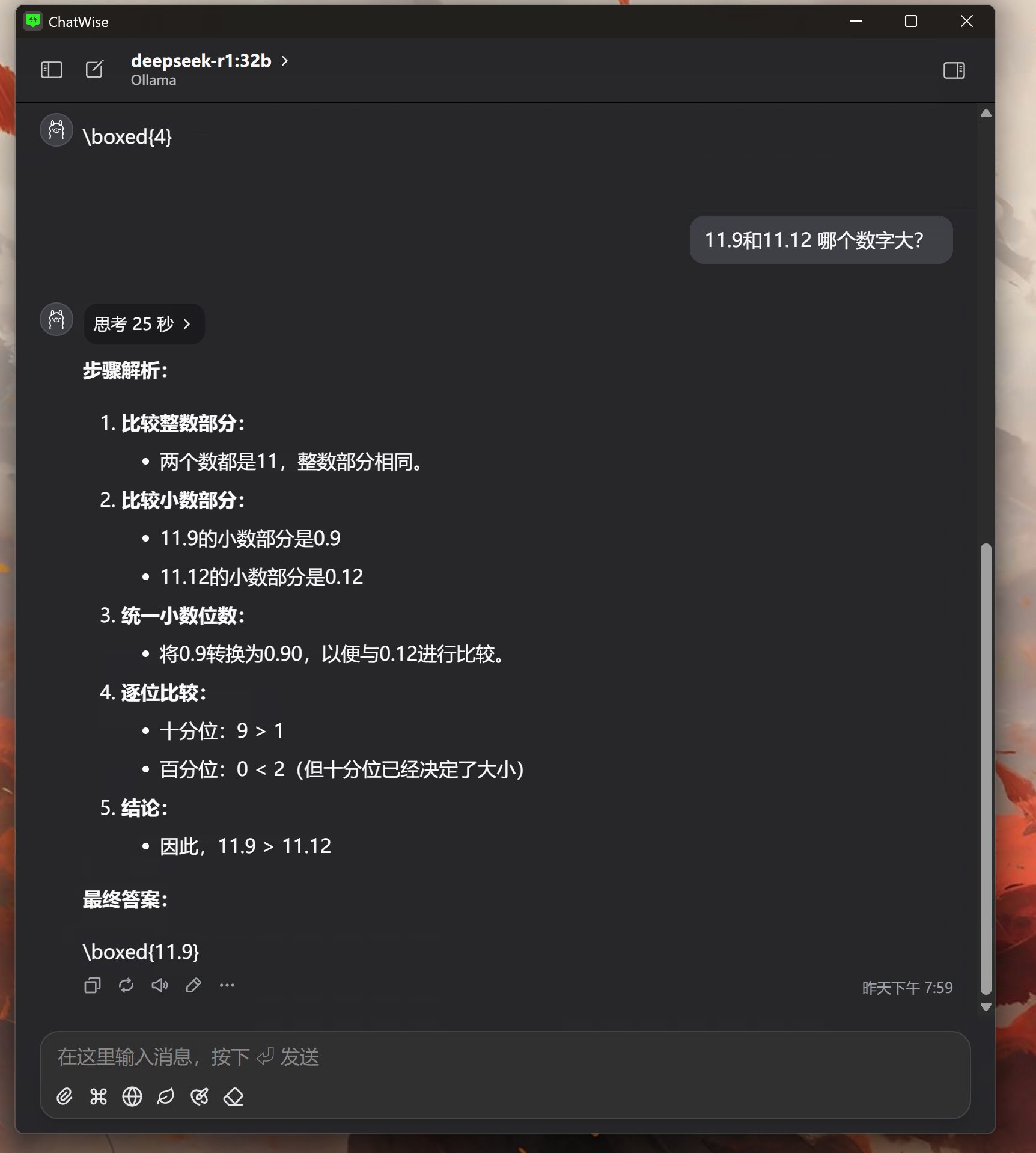
DS的回答完全正确,两个问题用时28秒。但是输出最答案的时候格式有问题。
正常应该显示11.9 ,它却给了个 \boxed{11.9} 。
同时回答内容比较占空间,导致我截图有点困难。
Qwen3:
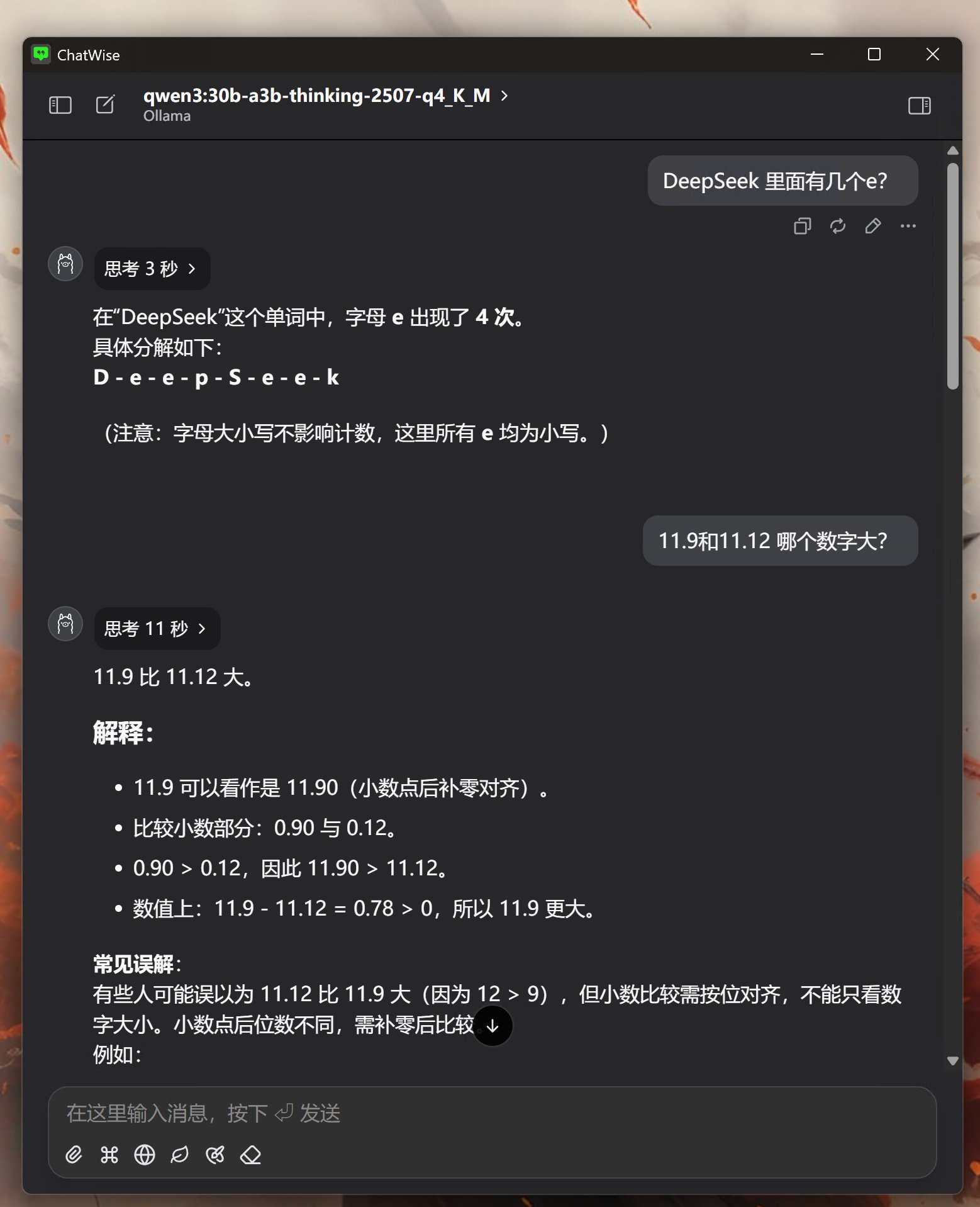
Qwen3的回答也完全正确。总共用时14秒。
它有两点比较好。一个是先给答案,再解释。第二对易错点做了贴心提示。
gptoss:
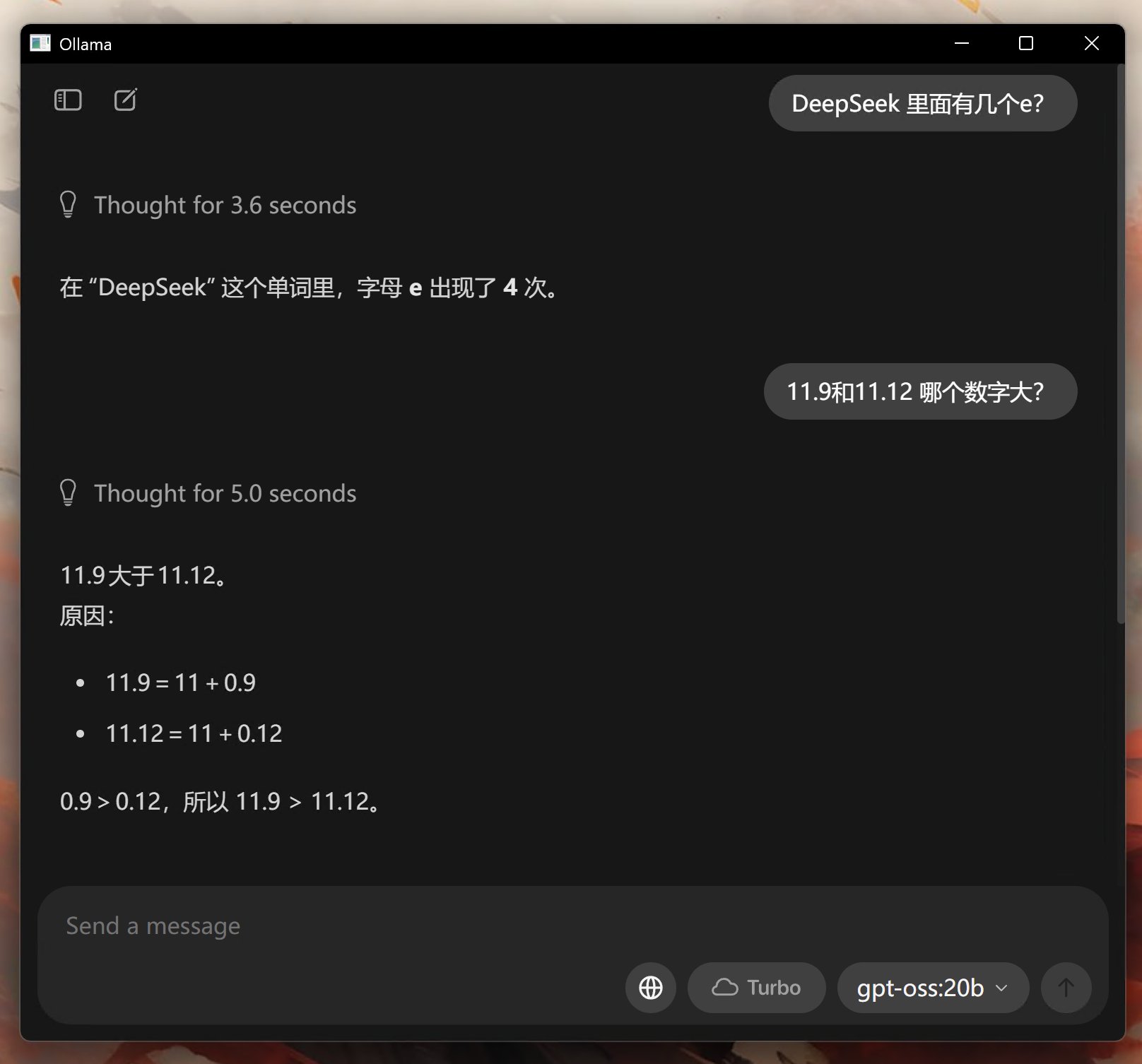
gptoss 也是全部正确。总共用时8.6秒。
它最大的特点是,没有废话,简洁明了。终于可以一个屏幕截取所有内容了。
从这两个问题来看,gptoss更快,更简洁明了。
对于这种简单的问题,虽然我们提问的时候没有强调,但是其实我们只需要快速得到一个结果。从这一点来看,gpt比较善解人意。
简而言之,废话比较少!
接下来测试的题目对AI来说,就会有一点点难度,需要一点思考时间了。为了排除一些随机因素,每个问题都问了三次。为了减少上下文的影响,都是单独起了一个对话。
找正整数
对于找出一个正整数 n,使得 n! 可以被 2^n 整除 这个问题,大部分选手都可以。但是个别选手出现了脑子卡壳的现象。
DeepSeek:
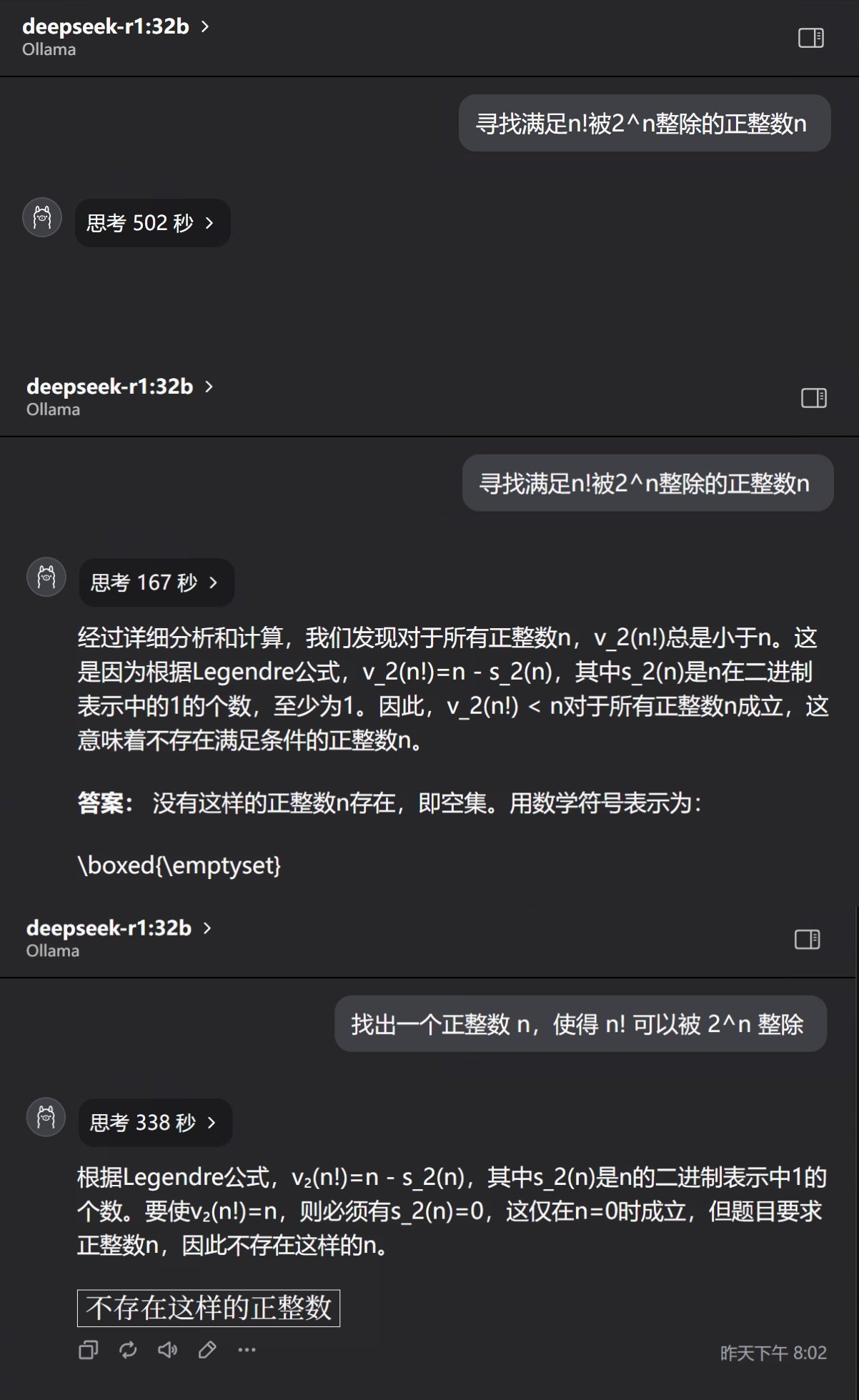
DS第一次回答就直接卡壳了,我整整等了它500秒,8分多钟。它完全没有要停的意思了。点开思考日志,看到它正在疯狂的用代入法,n已经干到137了。如果我不结束,基本就是可以无穷无尽了。我如果不在边上,显卡可能已经🔥毁了。
这是一个值得注意的点。千万不要让本地模型♾️思考,这个过程相当于烤机!一不小心,可能就熟了。
后面两次好一点,都成功了。用时分别是167秒和338秒。
Qwen3:
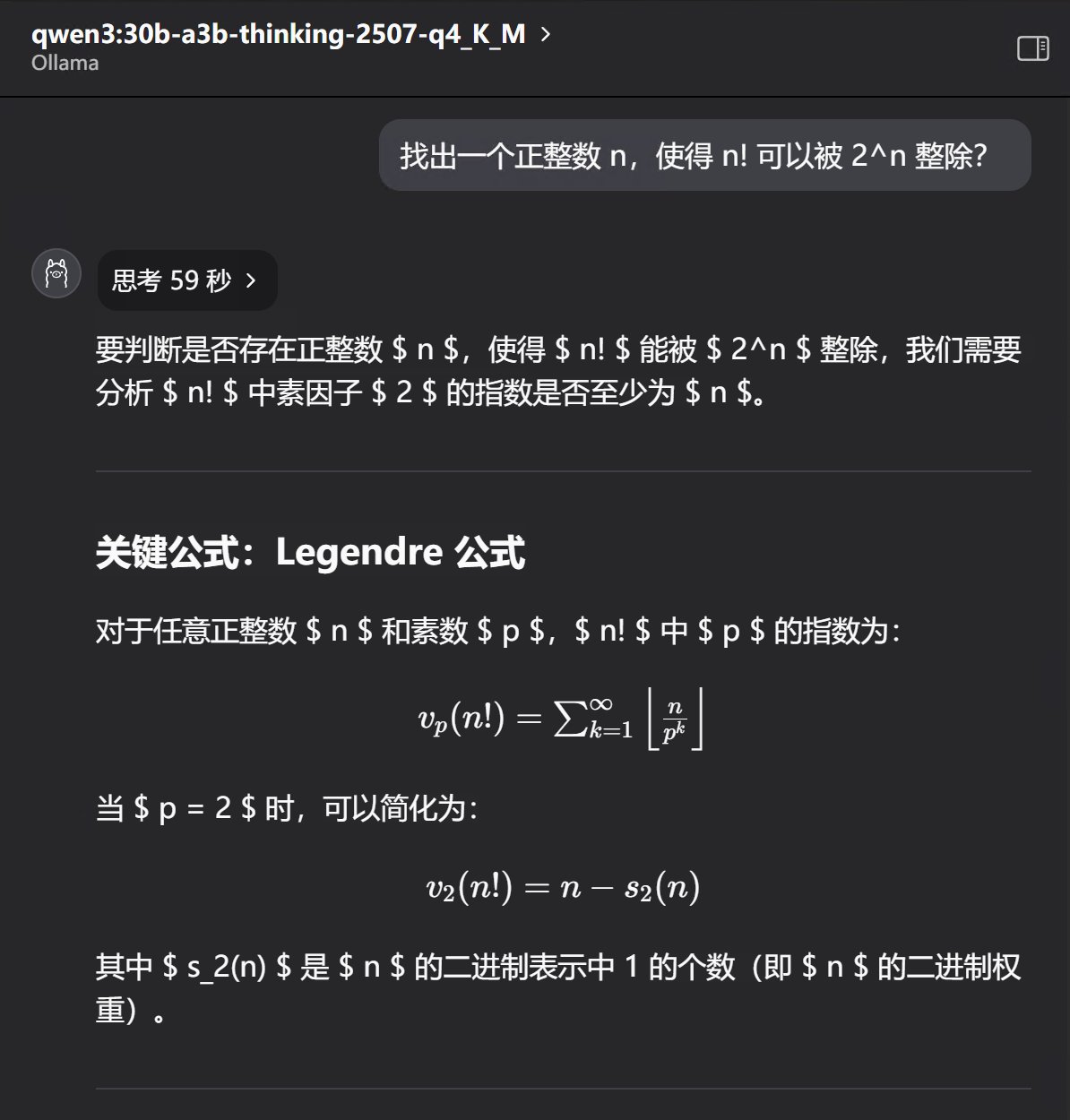
三次回答全部正确,用时分别是59秒,89秒,83秒。
gptoss:

gptoss三次全部正确,用时分别是22秒,36秒,35秒。
这么一对比,gptoss在推理时间上完胜!!
在回答问题的思路上,也是要清晰很多。首先它有一个最大的有点,就是思考完成之后,直接给答案。然后在清晰的讲解思路。 这一点在之前的问题中也有展现。
现在大家对“gpt下限比较高” 这句话应该有直观的理解了。
当然,结论还不用下太早,还有后面两个题目。
排队问题
接下来是排队问题。
有 5 个人排成一排,每人帽子颜色为红或蓝。他们可以看到前面的人的帽子,但看不到自己的。主持人宣布:“至少有一顶红帽子。”从最后一人开始,每人依次说“是”或“否”(表示是否知道自己帽子的颜色)。如果第 5 人说“否”,第 4 人说“是”,求所有可能的帽子颜色分布。
这其实是一个考验逻辑思维的题目。刚开看着挺难的,但是抓住关键点之后,就好多了。
下面来看看各位选手的回答情况。
Deepseek:
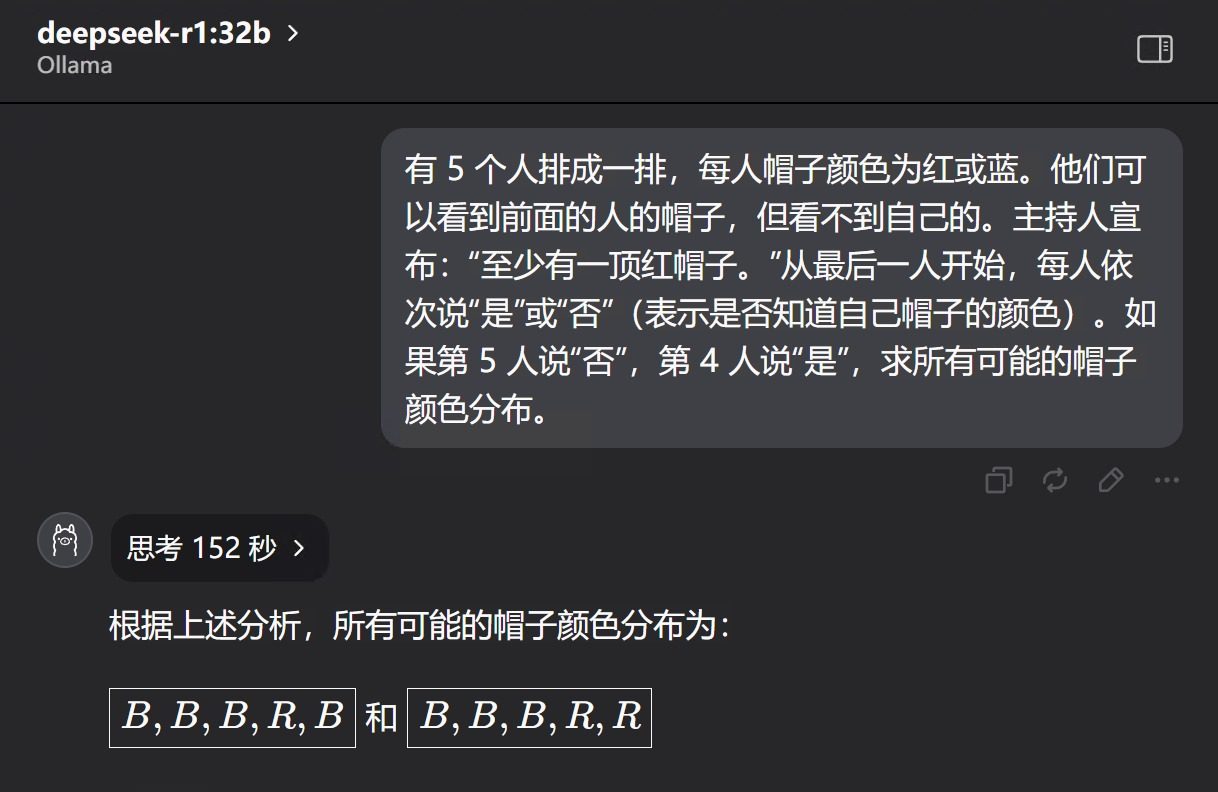
回答全部正确,时间分别是 152秒,105秒,67秒。
DS可能听到我的吐槽了,这次直接给答案,相当干脆。但是稳定性还是不行。三次时间差别比较大,比较长。其中一次回答还是很长。
Qwen3:
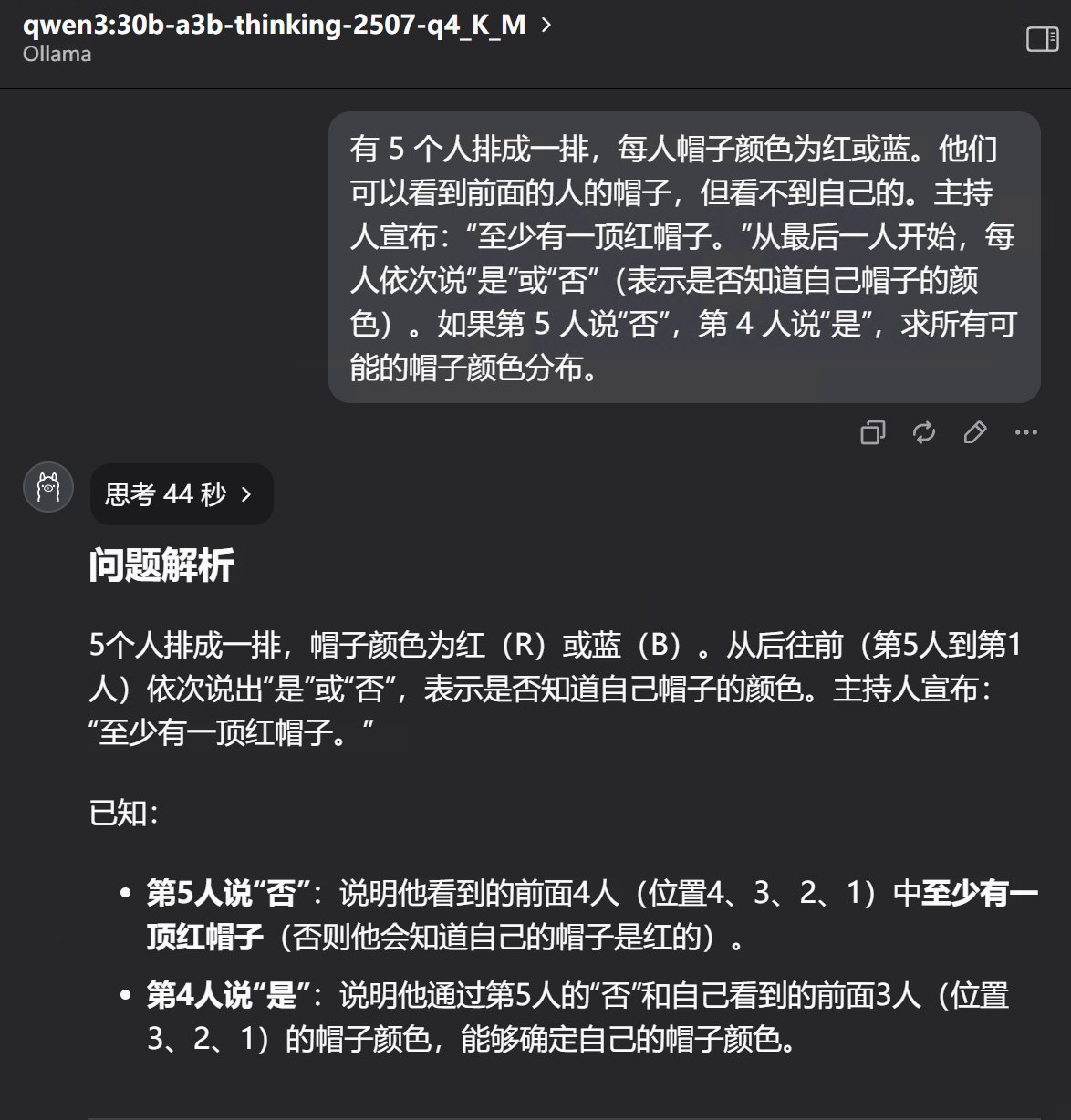
回答全部正确,时间分别是 43秒,45秒,44秒。
qwen的表现就是稳如老狗,精准掐表的感觉!
gptoss:

回答全部正确,时间分别是47秒,40秒,36秒。
gptoss的回答过程也发挥稳定,就是回答时间有点波动了,可能它感觉有点难度了。
空间问题
最后上空间问题。
6米长的竹竿能否通过4米高,3米宽的门?
这个问题,看起来,字数很少,也很简单。但是这个问题对AI来说,是一个致命的问题。截止今日,十个AI,九个躺下。
下面来看看三位选手的表现:
DeepSeek:
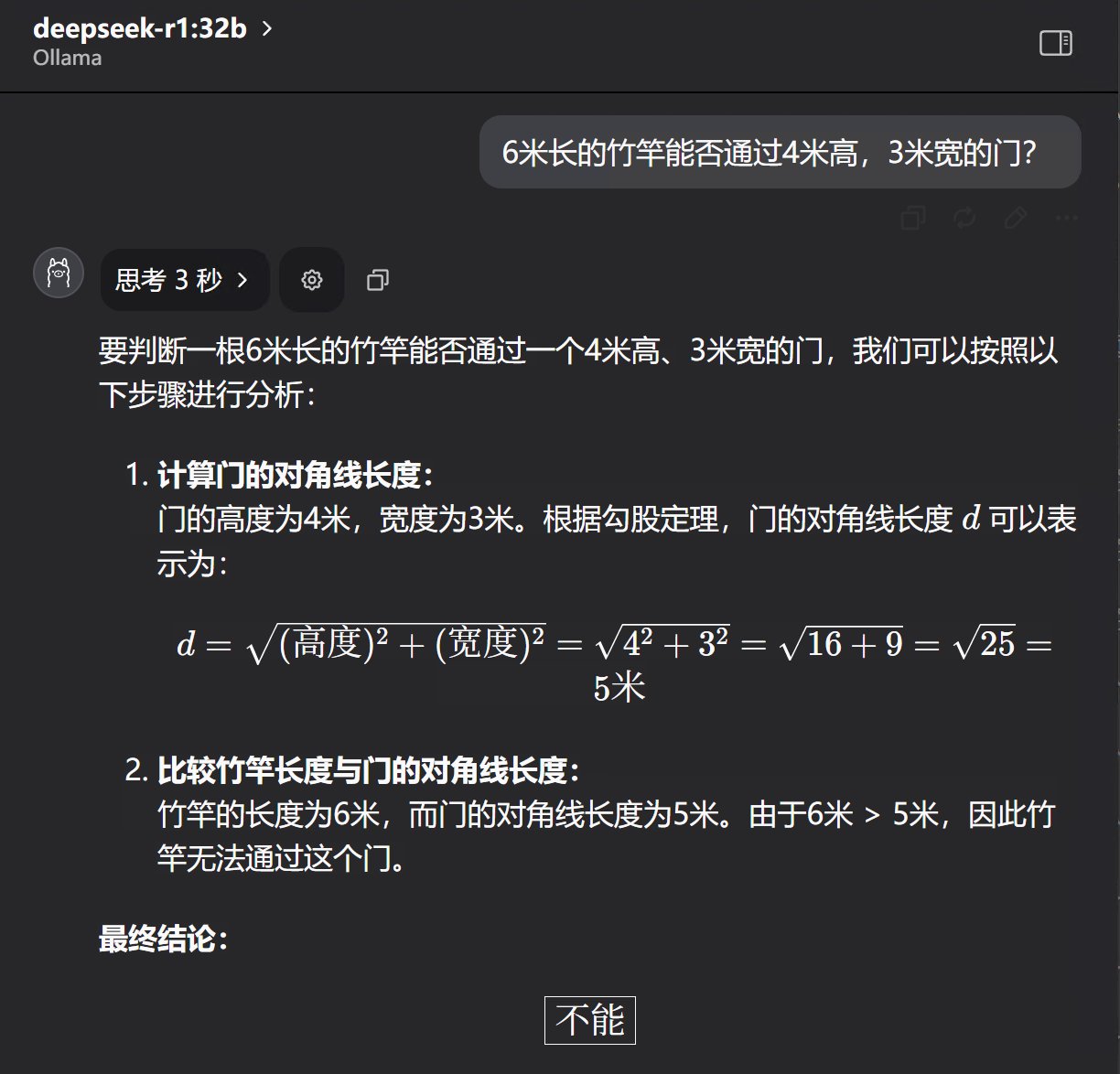
对于这个问题,ds展现出了迷之自信。只用了3秒钟中,就给出了斩钉截铁的答案:不能。而且每次的结果就和标准答案一样,99%的思考过程都一样。
三次思考时间,分别是4秒,3秒,3秒。
对于这个结果,我先不做评价,看看qwen怎么说。
qwen3:
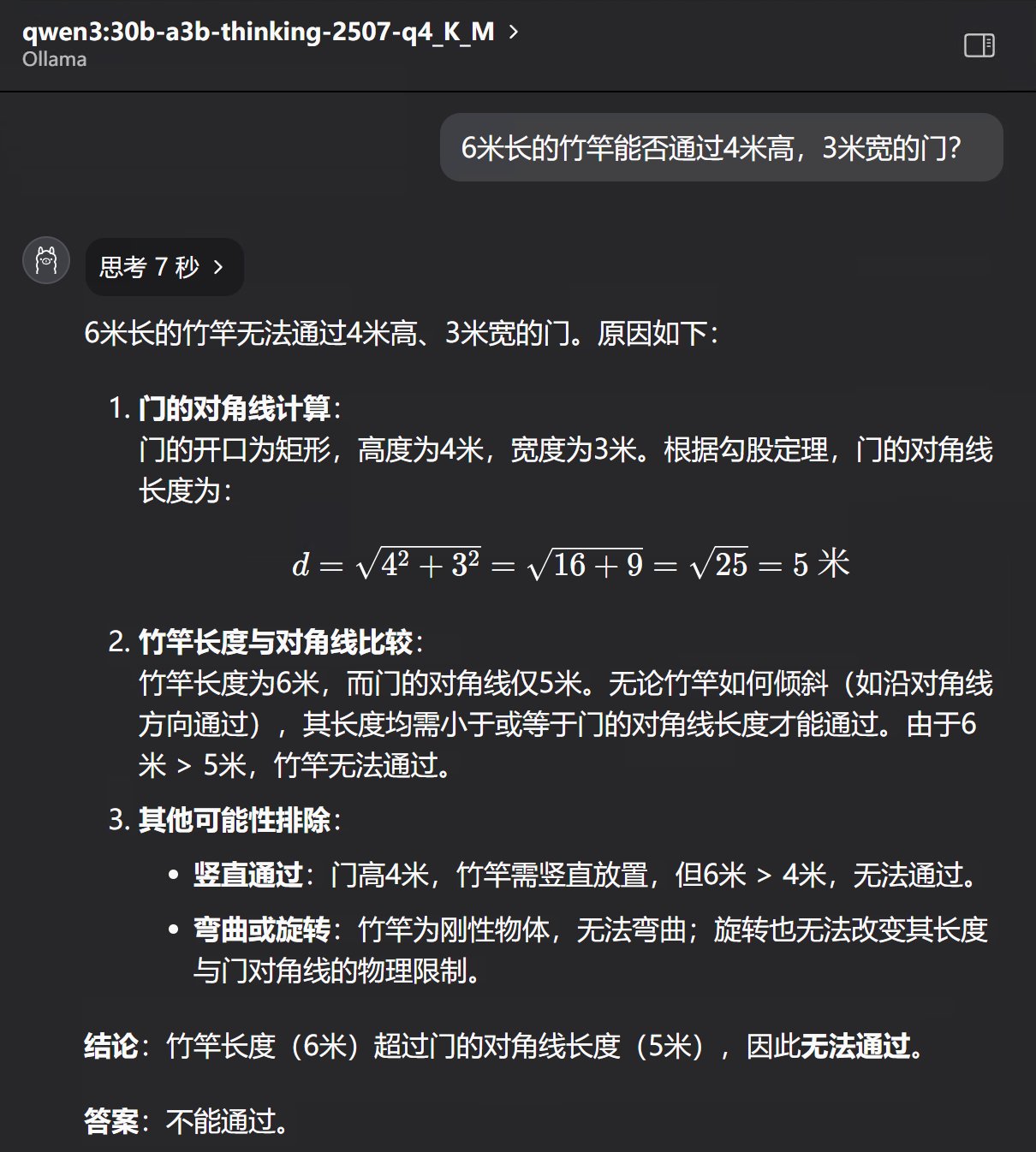
Qwen的回答也是不能通过 。用的时间是4秒,6秒,7秒
看来这里两位是一个数学老师教的,回答思路几乎一模一样。就是qwen这娃还想着要排除其他可能性,但是又没有排除到关键点。
下面看看外国学生表现如何。
gptoss:

gptoss 第一次回答,完全正确。 还教你如何操作了。
外来的果然不一样,轻松答对。
但是…接下来的两次,它也糊涂了。
回答时间分别为,23秒,17秒,7.2秒。
这个问题,各位选手都有点轻敌,思考时间比较短,最后基本都答错了。只有gptoss在思考23那一次答对了。
其实,这个问题,即便是它同父异母的哥哥也是一样的结果。
当前我测过的所有大语言模型中,只有grok3+ 和ds0528满血版可以答对。
grok这娃,没有下限,但是上限很高,有些极端的数学和推理问题,都做得不错。
说回今天这几位选手。通过上面的几个题目,基本可以看出他们的实战水平了。
简单排序就是gptoss>qwen3>deekseekr1 。
gptoss主要优势表现在,答案简洁,思路清晰,思考较快,回答比较稳定。qwen3真题稳定性也不错,ds的思考时间普遍偏长,其中有一个不该错的题目卡脑壳了。ds在年初开源的时候非常惊艳,但是随着大家的使用,发现它并不实用 ,容易陷入一种奇怪的状态,时至今日,整体实力也偏弱了。
最后 还是要声明一下,这个测试非常片面…但是直观,可以作为一个参考。


关于作者
tony
某人