AI长眼睛了,玩一玩视觉·语言·大模型!Qwen-VL
这个模型叫Qwen-VL,VL 的意思是视觉语言模型。意思就是不光能侃大山,还学会刷图片了…
下面来看一些我实测的例子。
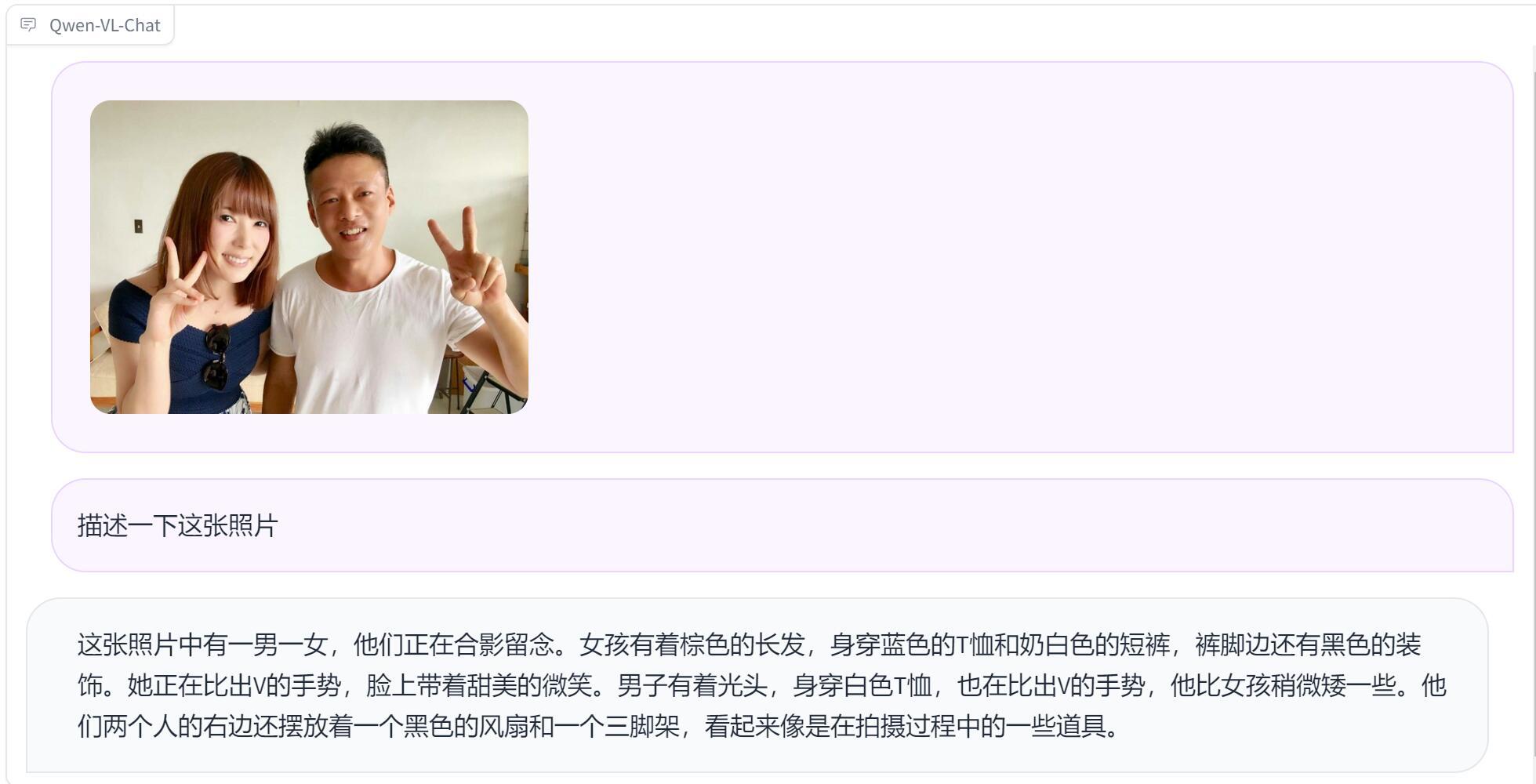
首先我提供了这样一张照片。

下面是AI的回答。
哈哈~~
AI的眼神太犀利,奶白色短裤,黑色装饰都能看出来?
另外谁能解释一下“光头” 是怎么来的?
然后又说拍摄啊….道具啊…
我不敢再问细问了~~
懂得说一下,照片里的是谁,他们在干什么?
然后我又试了一下这张图片。

下面是和AI的聊天记录。

准确地认出这个人,并且可以准确的回答各种关联信息。要知道这可是没有联网的哦…全是在单个离线模型中的内容哦。
然后,我们来试试风景照片

下面的是AI的回答。
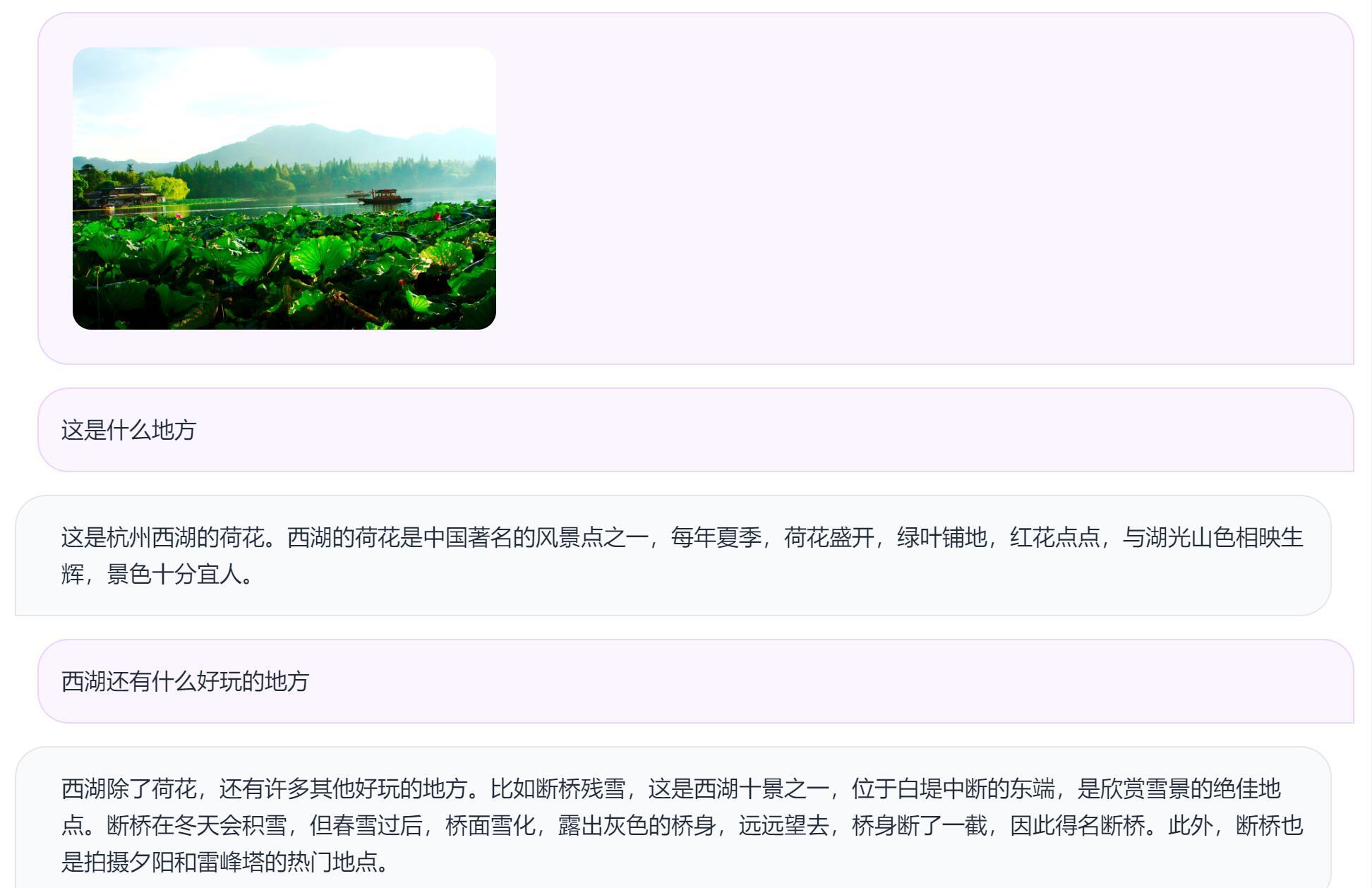
它居然一眼就能认出这是西湖…
同样的问题,问了讯飞星火在线版,只回答了这是一个美丽的湖泊。果然杭州产的模型,对杭州还是很了解的。
最后发一张,换脸软件中的示例图片。
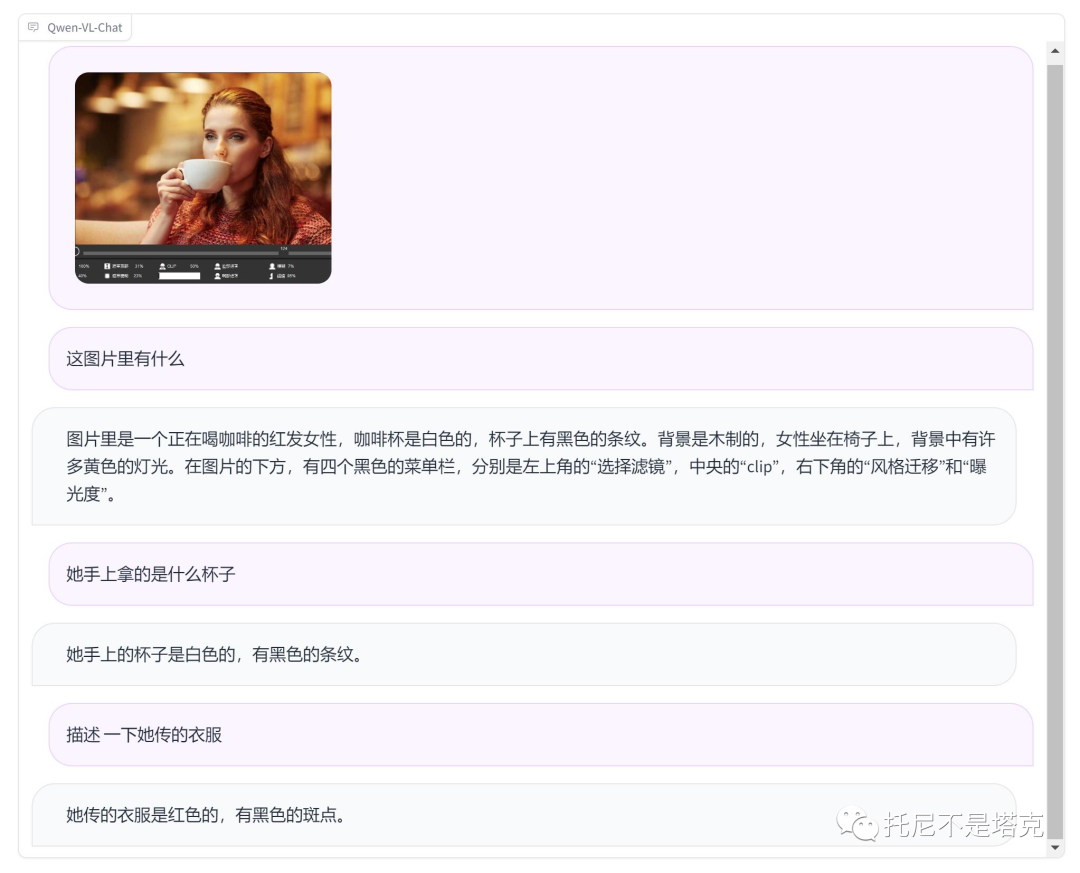
准确的分析除了咖啡,杯子的颜色,背景,女子,椅子,黄色灯光。
另外它还识别了人物底部的区域和部分文字。
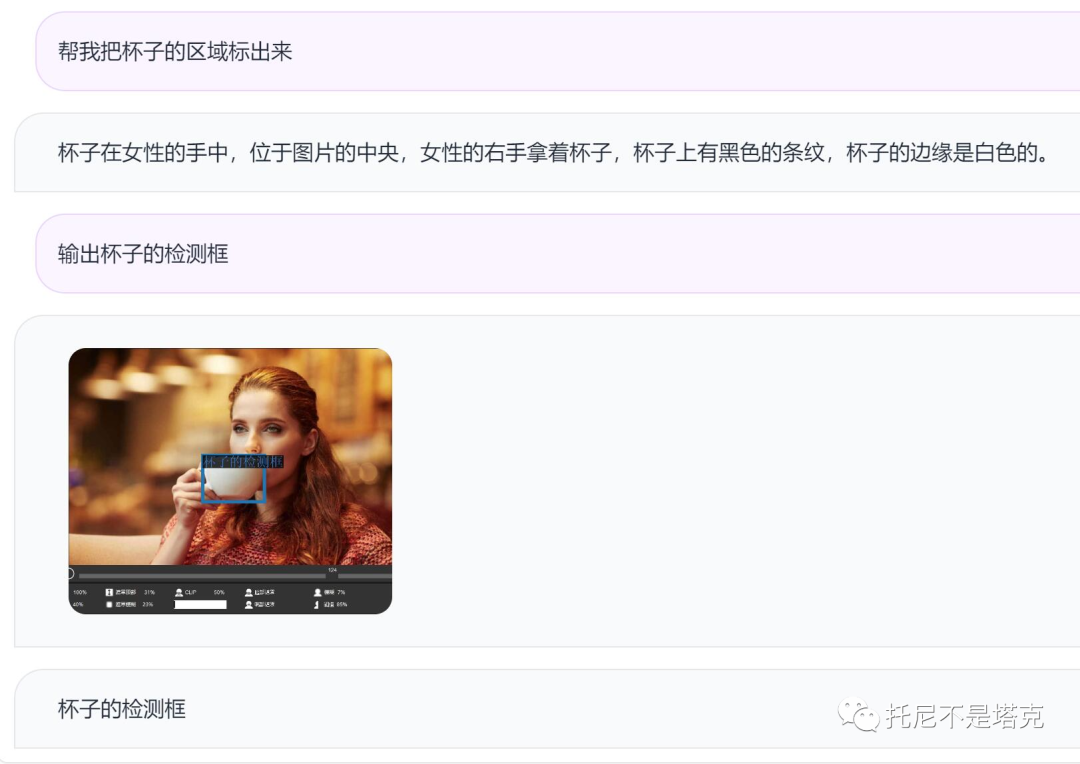
除了能读懂图片,分清楚左右手外,它还能帮你检测特定物品,打上检测框。以往的检测算法,现在一句话就搞定了????
我这里用的的所有图片都是随机选区,并不是官方示例。整体来看这个视觉语言大模型已经有一定的可玩性了。
如果说理解文字是一维空间,那么能理解图片就是二位空间了。所以你们说这是不是对普通大语言模型的降维打击。
类似的功能其实在讯飞星火和百度文心一言上也有,但是,人家是大量的人力,物力,财力堆出来的,而现在我们可以直接在本地电脑跑起来了,一个人,一台电脑,连网络都不需要。
只要一张 RTX3060 12G就能跑起来的AI模型,居然有这么强的图片分析能力,真的可以了!
感觉自己微调一下,就可以使用在某些场景了。
简介
下面来看一下官方对于Qwen-VL的介绍。
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型的特点包括:
- 强大的性能
- 多语言对话模型
- 多图交错对话
- 首个支持中文开放域定位的通用模型
- 细粒度识别和理解
模型
大模型大模型,重点就是模型了,所有的活都是直接在模型中完成。
官方提供了两个模型。
- Qwen-VL: Qwen-VL 以 Qwen-7B 的预训练模型作为语言模型的初始化,并以 Openclip ViT-bigG 作为视觉编码器的初始化,中间加入单层随机初始化的 cross-attention,经过约1.5B的图文数据训练得到。最终图像输入分辨率为448。
- Qwen-VL-Chat: 在 Qwen-VL 的基础上,我们使用对齐机制打造了基于大语言模型的视觉AI助手Qwen-VL-Chat,其训练数据涵盖了 QWen-7B 的纯文本 SFT 数据、开源 LVLM 的 SFT 数据、数据合成和人工标注的图文对齐数据。
还有一个在Chat基础上做了Int4量化的模型,适合在低配置设备上运行。
评估结果
下面看一下具体的评估对比数据。
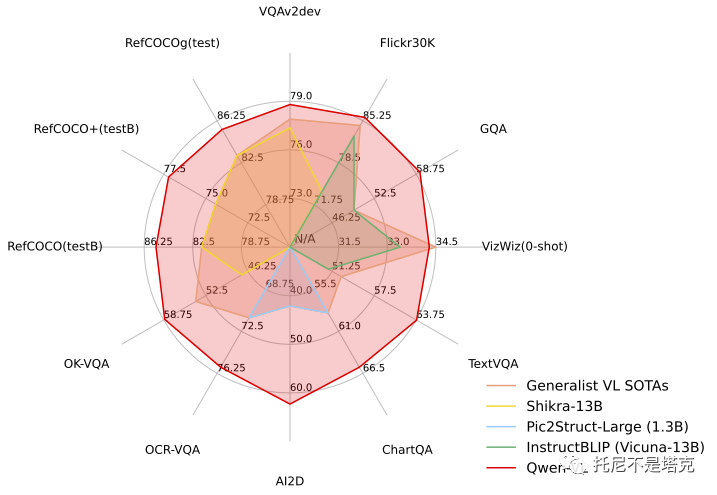
从这个图片来看,相比于同类模型,还是遥遥领先的。另外有一个视觉模型好像比这个强,但是运行要求太高了,玩不动。
依赖
- python 3.8及以上版本
- pytorch 1.12及以上版本,推荐2.0及以上版本
- 建议使用CUDA 11.4及以上(GPU用户需考虑此选项)
pip install modelscope -U pip install transformers accelerate tiktoken -U pip install einops transformers_stream_generator -U pip install "pillow==9.*" -U pip install torchvision pip install matplotlib -U
我本地配置时使用的版本是Python3.10,cuda118,Torch2.0.1。
快速使用
可以通过以下代码轻松调用:
from modelscope import (
snapshot_download, AutoModelForCausalLM, AutoTokenizer, GenerationConfig
)
import torch
model_id = 'qwen/Qwen-VL-Chat'
revision = 'v1.1.0'
model_dir = snapshot_download(model_id, revision=revision)
torch.manual_seed(1234)
# 请注意:分词器默认行为已更改为默认关闭特殊token攻击防护。tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, bf16=True).eval()
# 打开fp16精度,V100、P100、T4等显卡建议启用以节省显存
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval()
# 使用CPU进行推理,需要约32GB内存
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="cpu", trust_remote_code=True).eval()
# 默认使用自动模式,根据设备自动选择精度
# model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# 可指定不同的生成长度、top_p等相关超参
model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True)
# 第一轮对话 1st dialogue turn
query = tokenizer.from_list_format([
{'image': 'https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg'},
{'text': '这是什么'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 图中是一名年轻女子在沙滩上和她的狗玩耍,狗的品种是拉布拉多。她们坐在沙滩上,狗的前腿抬起来,与人互动。# 第二轮对话 2st dialogue turn
response, history = model.chat(tokenizer, '输出击掌的检测框', history=history)
print(response)
# <ref>"击掌"</ref><box>(211,412),(577,891)</box>
image = tokenizer.draw_bbox_on_latest_picture(response, history)
image.save('output_chat.jpg')
这段代码已经提供了非常详细的注释,懂的应该都能看懂,不懂的就不要强求了。直接复制粘贴,能用起来就好了。
另外官方还提供了量化,微调,以及更详细的能力测评数据。有兴趣的可以去看看。
具体的安装配置方法可以参考我之前关于《玩一玩阿里千问开源版》的文章。
虽然官方的配置运行资料看起来很简单,但是实际配置可能还是要费点力气,哪怕是专业人士,也需要踩坑时间,下载时间,调试时间,总的来说会浪费不少时间。
所以我会把包打好,直接发出来。
你们只管点赞,转发,在看即可。
其实这个项目我很早就跑通了,只是一直有事情。昨晚刚准备发文章,又临时被其它事情打断了。
今天说什么都要先把文章发出来,一键运行包稍后跟上!
给公众号“托尼不是塔克”发关键词“qwvl” 即可获取!
收工,收工!



关于作者
tony
某人