声音克隆:IndexTTS2本地安装和运行记录!
自从B站发布了IndexTTS2的宣传片之后,我就念念不忘!
这效果相当惊艳,好害怕他们捂着,不开源了。
还好,Index有格局,开源模型和开源代码如期而至!
并发布了另外一个演示视频:
不愧是视频网站出身,做的视频也挺好。
这个模型在影视翻译方面的表现,非常惊艳!
同时2.0版本在情感控制方面也有比较突出的表现。可以通过多维度进行情绪控制,相比1.0版本,自然度、相似度也有很大的提升。
反正一句话,官方给的例子相当不错!就差自己上手玩一玩“验明正身”了。
目前,我已经在Windows系统上成功运行,显卡是RTX 5060 Ti。
因为新显卡,加上新的UV配置方式,整个安装配置过程还是踩了一些坑,收获了一些经验。
所以写一篇文章记录和分享一下。
下面就进入正题了,我按步骤一步一步来写。
1.获取源代码
这是一个开源项目,而非软件。所以我们要从获取源代码开始。
源代码的获取方式一般分两种:一种是命令的方式,一种是直接打包下载。
命令方式
这种方式需要先确保你的电脑已经安装了git和lfs。
如果git装了,没有lfs,可以运行命令:
git lfs install
然后依次运行下面三行命令:
git clone https://github.com/index-tts/index-tts.git indextts2
cd indextts2
git lfs pull
打包下载
打开开源项目地址:
https://github.com/index-tts/index-tts
然后点击Code->Download ZIP。
会下载到一个zip压缩文件,解压这个文件,把解压出来的文件夹改名为indextts2就可以了。
不管哪种方式获取,这里都会有一个小问题。因为这个项目使用了LFS。
LFS = Large File Storage(大文件存储),是 Git 的一个扩展,用来管理二进制/大文件(音频、视频、模型、数据集等)。
这个东西一用,可能搞得你Git都不会用了。
克隆代码(git clone)的时候会报一堆错误:
`Updating files: 100% (249/249), done. Downloading examples/emo_hate.wav (145 KB) Error downloading object: examples/emo_hate.wav (89e6e7e): Smudge error: Error downloading examples/emo_hate.wav (89e6e7eee1a28303776e9cf43971e9505529bd0e669f5fcf47f4d1370f9187c4): batch response: This repository exceeded its LFS budget. The account responsible for the budget should increase it to restore access.`
刚开始有点懵,查了一下大概是文件配额超了。可能是下载的人太多了,就受限了,所以直接出现错误。
遇到这个情况,我们做不了什么,只能直接跳过LFS部分。
删除之前的所有代码,执行下面命令,重新下载一下:
git lfs install --skip-smudge
git clone https://github.com/index-tts/index-tts.git indextts2
这样就可以下载全部源代码而不报错了。
如果你想知道这么操作缺了什么文件,可以使用命令:
git lfs ls-files
通过这个命令可以知道,那些大文件值得就是examples文件下的一些演示音频。
我们可以在GitHub上打开这个文件夹,找到里面的音频文件,然后手动在网页上点击下载,下载完成之后放到本地同名文件夹就可以了。
所以,如果你不理解上面的命令,就直接手动下载就好了。
2.安装依赖
有了源代码和演示音频之后,我们就需要进行安装了,这里的安装主要是指安装Python依赖。常规的Python项目我们一般使用pip来安装requirements.txt文件中的依赖包。但是这个项目并没有使用pip,而是使用了UV 作为包管理器。
uv = 超快的 Python 包管理器 + 虚拟环境管理器
它的目标是用一个工具取代:
pip
venv
pip-tools
pipenv
poetry
conda(部分功能)
核心特点:
- 极速:基于 Rust 实现,比 pip 快 10~20 倍。
- 跨平台:支持 Windows、macOS、Linux。
- 全功能:安装、卸载、依赖解析、虚拟环境、打包、项目管理。
- 兼容 pip:支持直接用
requirements.txt、pyproject.toml。 - 无缝切换:可以直接替代
pip,无需改动现有项目。
平时一直都用conda,这次突然遇到uv,一下子又被打蒙了。踩了好几个坑之后,正确的操作方式如下。
首先是安装UV:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex
然后修改pyproject.toml文件:
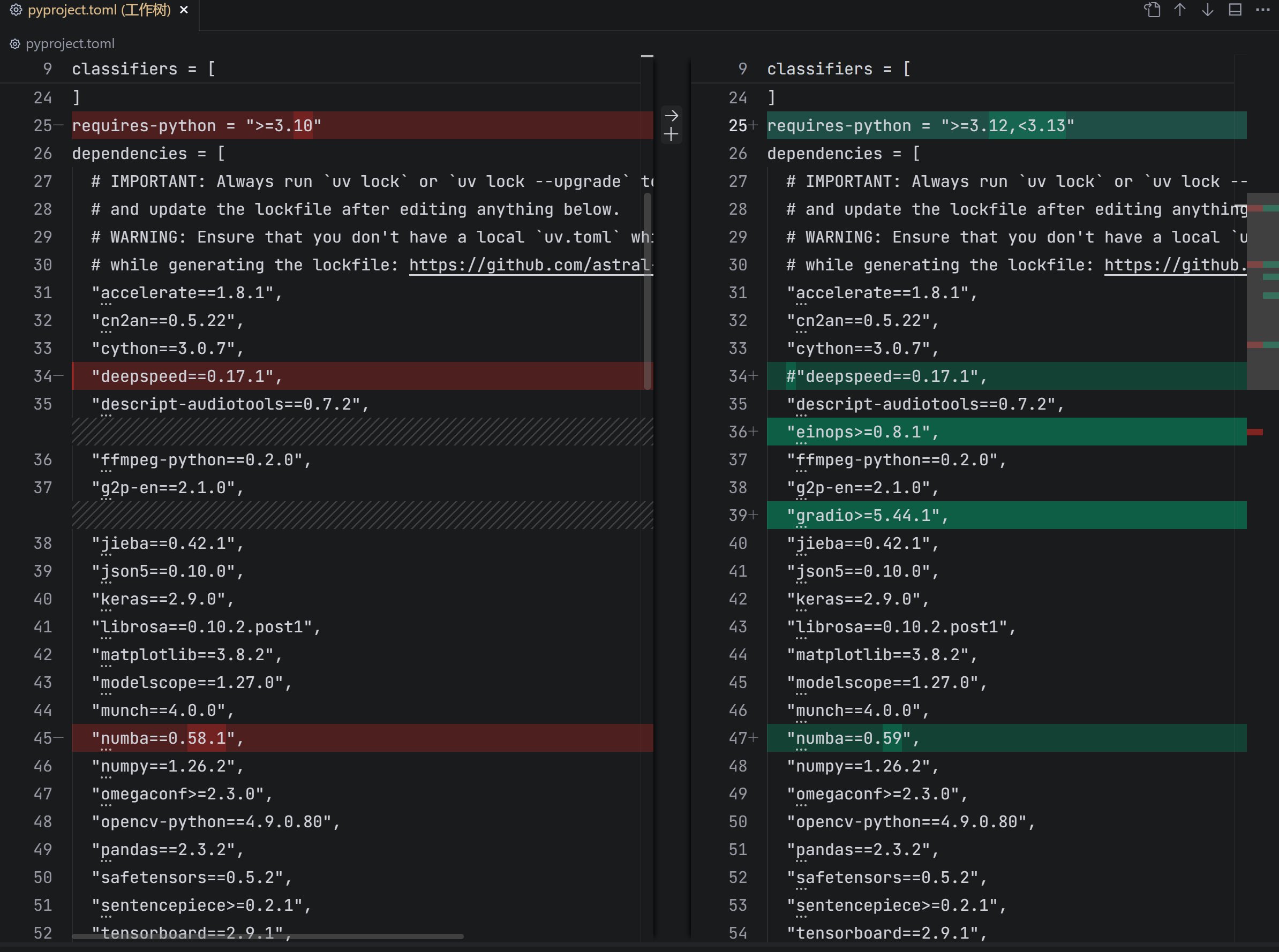
这里主要是为了适配50系列显卡,同时注释掉deepspeed,保证能顺利安装。
主要修改的是Python版本改为3.12,numba改为0.59,然后添加了einops和gradio。
然后执行命令:
uv python install 3.12 #安装Python 3.12
uv python pin 3.12 #指定Python版本
uv venv --python 3.12 #创建虚拟环境
uv lock --upgrade #更新
uv sync --frozen #安装
执行完上面的命令,等待就可以了。安装需要一些时间,单一个torch就有3G左右。
3.下载模型
依赖安装成功之后,基本上安装部分就完成了,接下来就是获取模型了。 获取模型可以通过以下命令完成。
国外huggingface-cli:
uv tool install "huggingface_hub[cli]"
hf download IndexTeam/IndexTTS-2 --local-dir=checkpoints
国内modelscope:
uv tool install "modelscope"
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
这一步应该没啥问题,就是等待为主。所有模型加起来也有10来个G左右。
4.运行WebUI
经过上面的步骤,就万事俱备了。
最后,检查一下运行环境:
uv run tools/gpu_check.py
输出信息大致如下:
PyTorch: NVIDIA CUDA is available!
Number of GPUs found: 1
GPU 0: "NVIDIA GeForce RTX 5060 Ti"
从输出中可以看到,CUDA可用,GPU也找到了,显卡型号也显示正常。
最后运行WebUI:
uv run webui.py
运行过程会提示DeepSpeed加载失败,以及Failed to load custom CUDA kernel for BigVGAN,这个可以先不管,能跑起来就可以了!
然后会自动下载一个模型文件。
最终就会出现Running on local URL: http://0.0.0.0:7860 的提示了。
这个时候只要在浏览器输入http://localhost:7860就可以打开了。
5.声音克隆
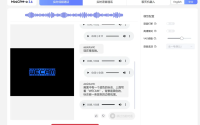
成功运行WebUI,打开之后就可以看到如下的界面了。
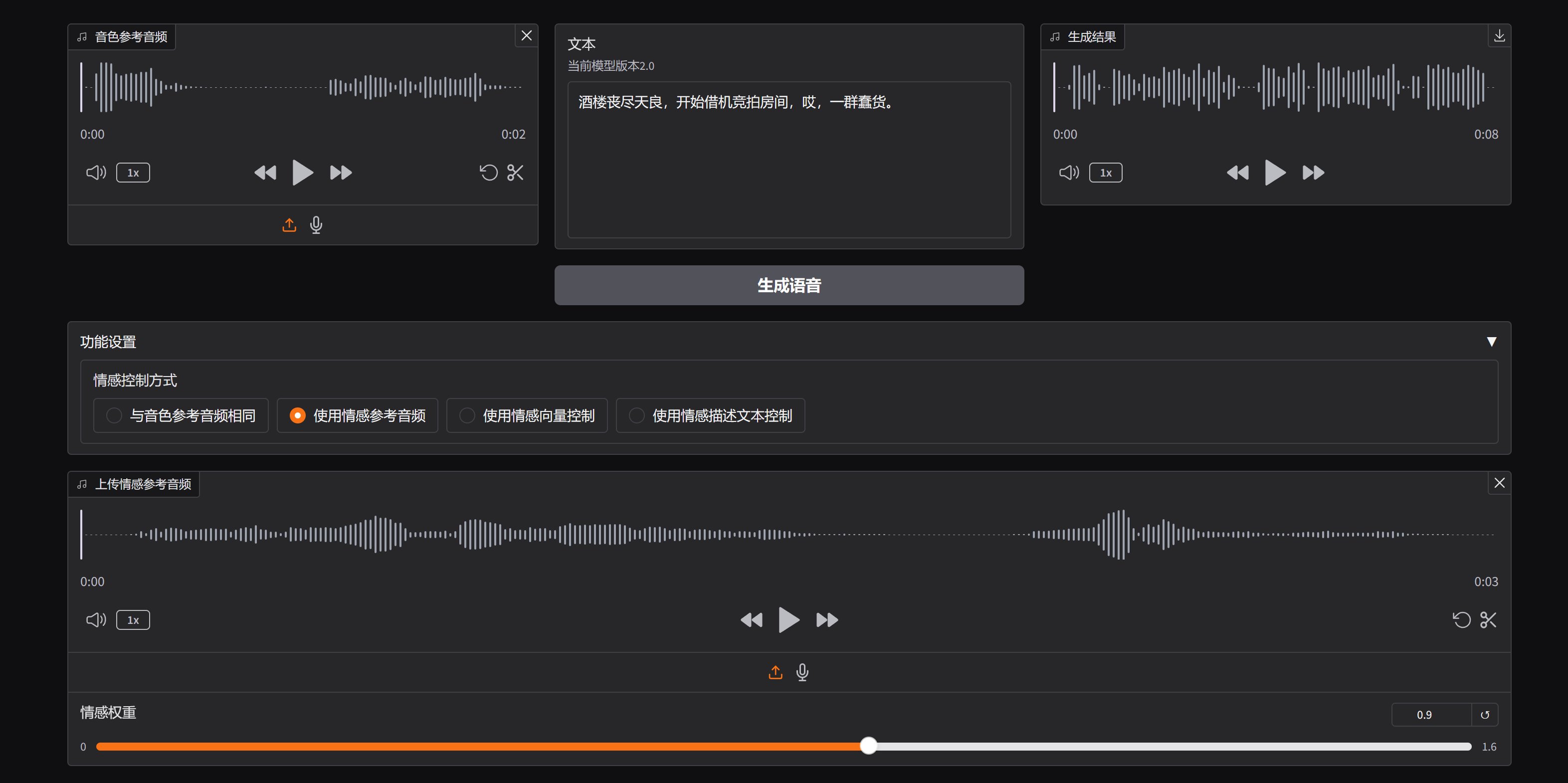
这个界面构成非常简单。只要简单三部,就可以克隆声音了。
首先是上传一段参考声音(克隆对象),
然后输入要合成的文本,
最后点击生成语音就可以了。
一句话大概十几秒的样子!
IndexTTS2除了完成常规的声音克隆之外,还提供了多种情感控制方式。
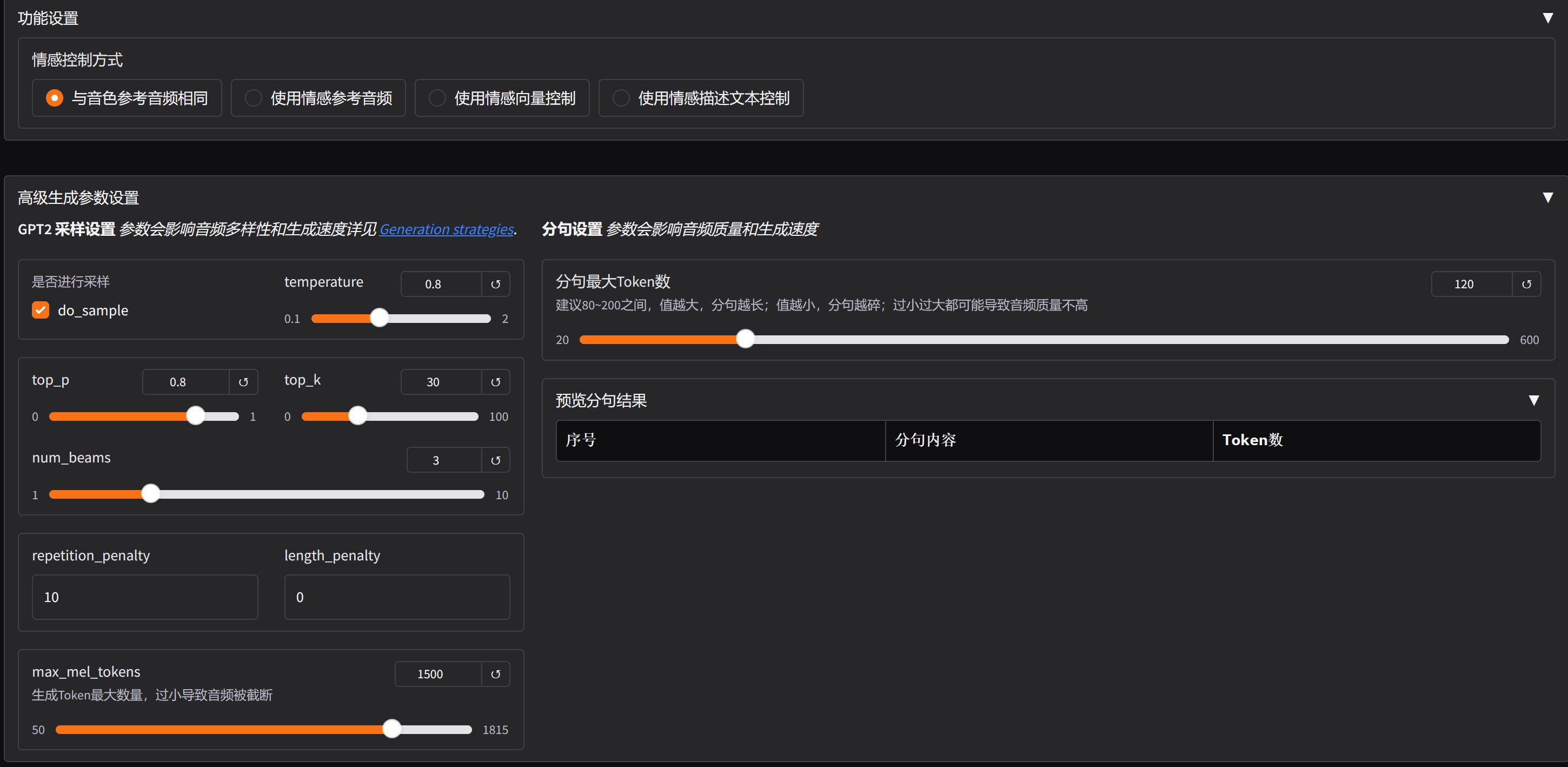
主要提供了四种控制方式,分别是:与音色参考音频相同,使用情感参考音频,使用情感向量控制,使用情感描述文本控制。
每种方式都有它自己的参数。
另外这个页面提供了12个例子,分别展示了基础功能和情感控制功能。
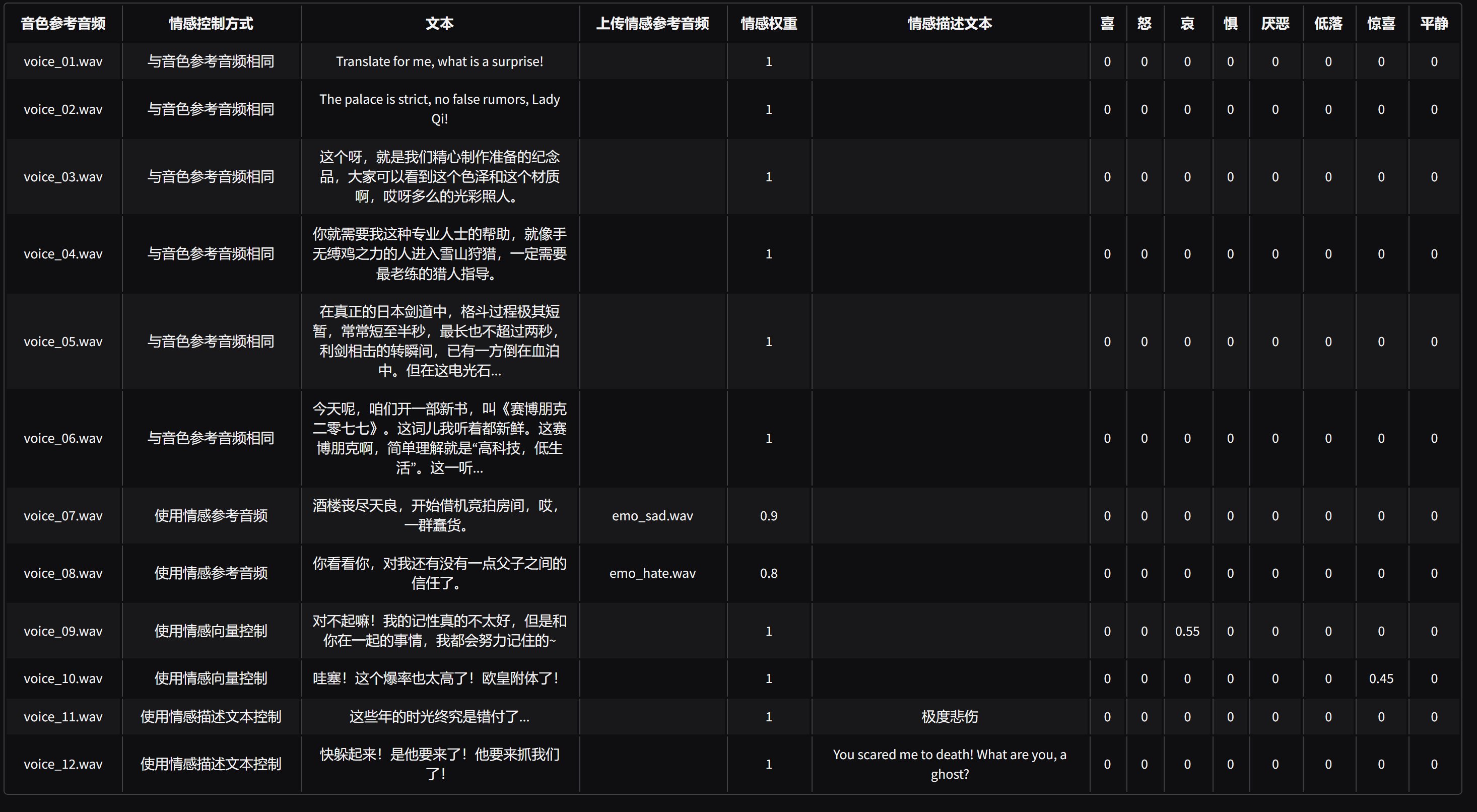
例子1-6为基础的声音克隆,7-12展示了不同类型的情感控制方式。
其中第一个和第二个就是官方例子中《让子弹飞》和《甄嬛传》视频翻译的例子。简单测试来看,官方给的前面几个例子表现都是很不错的,后面的情感控制,由于情绪变化比较大,音色的相似度会减弱。虽然相似度减弱,但是情绪很饱满。
今天只能赶出这部分了,一键运行包稍后!

关于作者
tony
某人