声音克隆:TVC更新通知,做了六点小更新!
上次更新比较着急,主要是逼自己快速出一个Demo。
软件好不好另说,做了肯定比没做好。
这两天花了一些时间,把显而易见的问题解决了以下,并且研究了一些新的模型和方法。
研究需要时间,我先把能完善的完善以下。
这是初始版本。
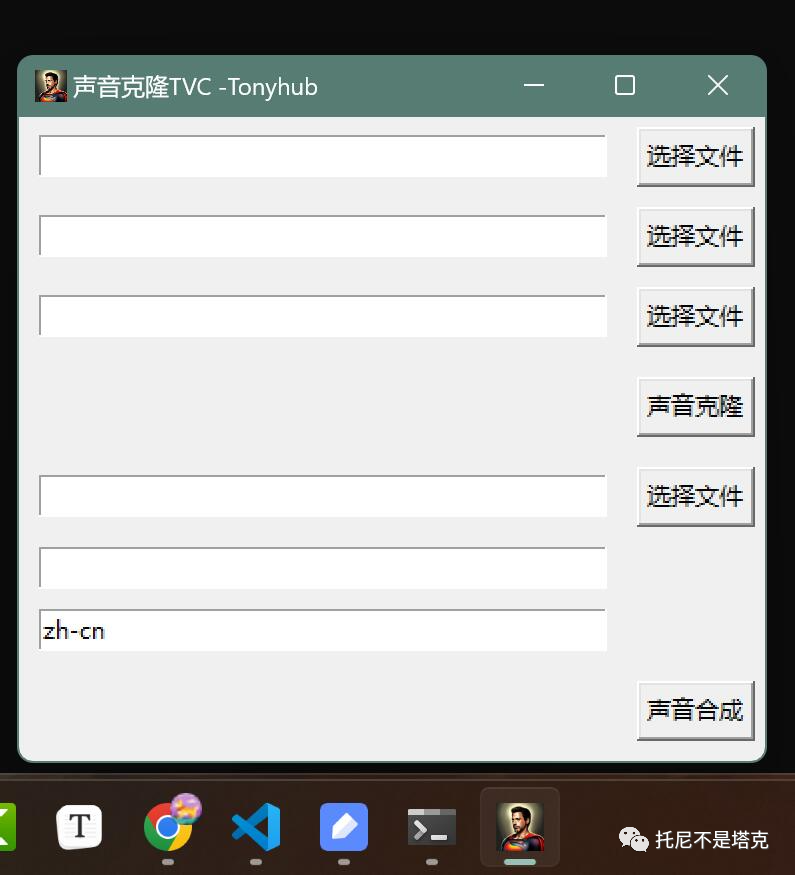
这是V1.1版本

这次更新主要变化如下:
1. 可以手动选择用显卡还是CPU
2. 修复按钮只能用一次的bug
3. 声音合成功能添加了保存路径。
4. 主要操作按钮高亮显示。
5. 修改了生成文件的命名方式。
6. 修改了按钮的名字,看起来更直观!
下面逐个说明一下。
1. 可以手动选择用显卡还是CPU
关于运行设备最初的逻辑是“自动选择” ,程序可以判断本地是否又英伟达显卡,有的话就用显卡。没有的话就用CPU。
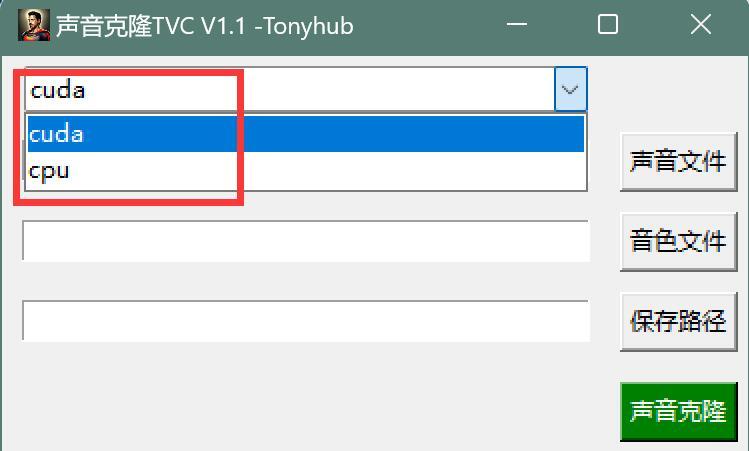
但是这种逻辑会有一个问题。就是你有显卡,但是显存很低的情况下。你就会被卡住,还用不了CPU,也就是直接没法使用这个软件了。
为了解决这个问题。提供了手段选择功能。
启动后还是默认会自动选择,你觉得有问题话,可以手动切换。
2. 修复按钮只能用一次的bug
这是一个妥妥的bug。
运行结束后按钮状态恢复了,但是内部标志没有重置。这就导致了,第二次点击按钮,没有任何反应。
我打包完成就发现了。但是打包比较消耗时间,我就没有重新打包。
现在已经解决了。
3. 声音合成功能添加了保存路径
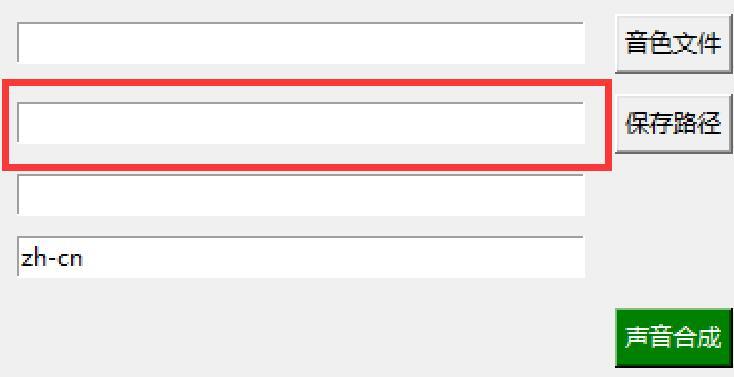
^_^ 初始版本这里偷工减料了,好几个人问,文件保存到哪里去了。
其实生成的文件和声音文件保存在同一个文件里面。
考虑到大家可能想要自由选择保存路径,还是把这个框框加上了。
这样自由度更大!
4. 主要操作按钮高亮显示
把声音克隆和声音合成两个按钮做了高亮显示。凸显他们的地位!
5. 修改了生成文件的命名方式。
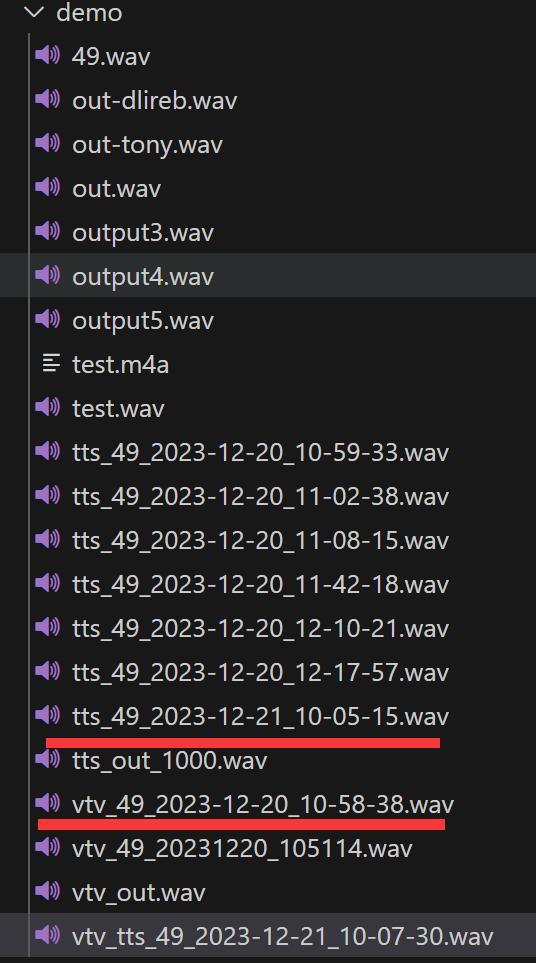
原先的命名方式都叫xxx_out.wav 。测试的时候用用还可以,文件多了就很难受。
所以命名方式修改为:类型+源文件名称+年月日时分秒。
这样新的内容就不会覆盖旧的内容,也方便查看。
6. 修改了按钮的名字,看起来更直观!
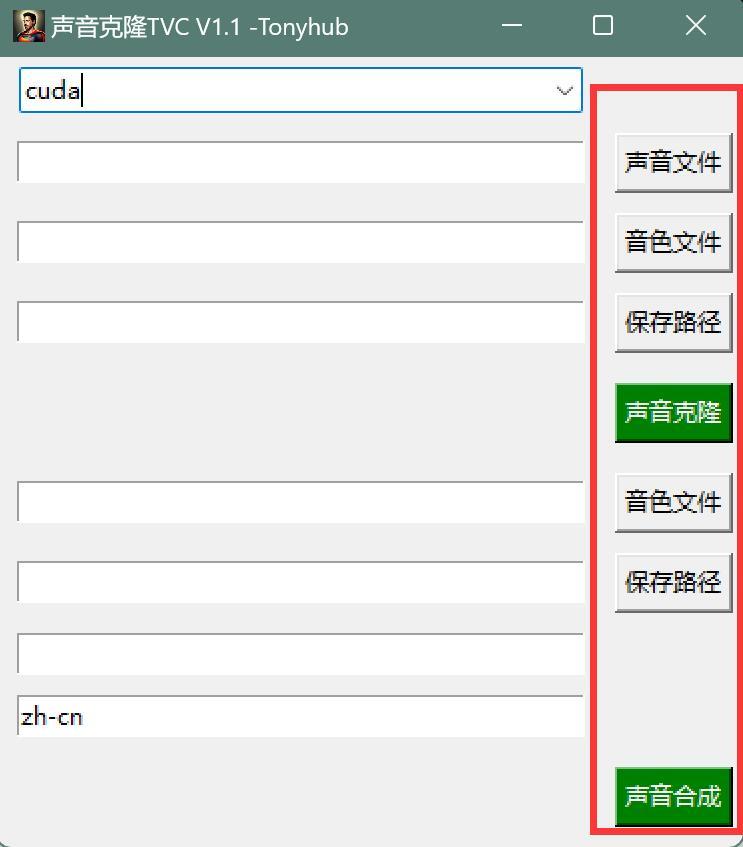
原先的按钮名字都是统一的,不看说明,完全不知道干嘛。现在做了一些修改,这样看起来清楚一点。
这个ui框架比较简单,调整布局比较麻烦,也没有类似placeholder这样文本框初始提示。先这么用着,后面再优化了。
使用方法
有人说,不会用,我就再介绍一下。
软件主要是两个功能,一个是声音克隆,有点类似于变声器。
一个是声音合成,就是把文字变成声音,同时克隆声音。
声音克隆的操作步骤如下:
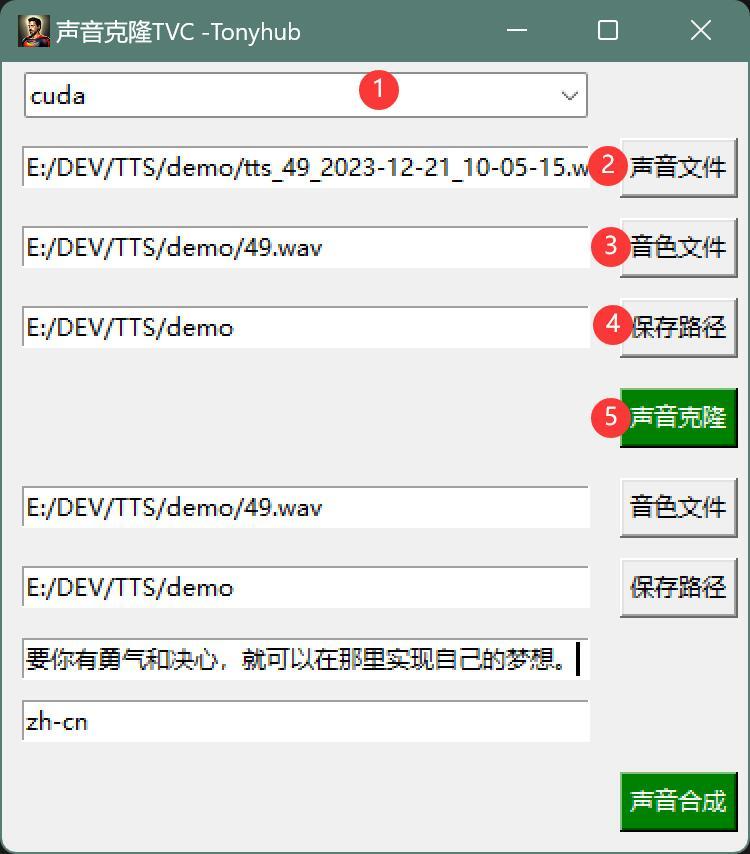
①选择设备
②选择声音文件
③选择音色文件
④设置保存路径
⑤开始克隆声音。
声音文件指的是正常声音,比如你自己声音。
音色文件指的是要克隆的声音,比如张三的声音
经过处理之后,你的声音就会变成张三的声音。
声音合成的操作步骤如下:
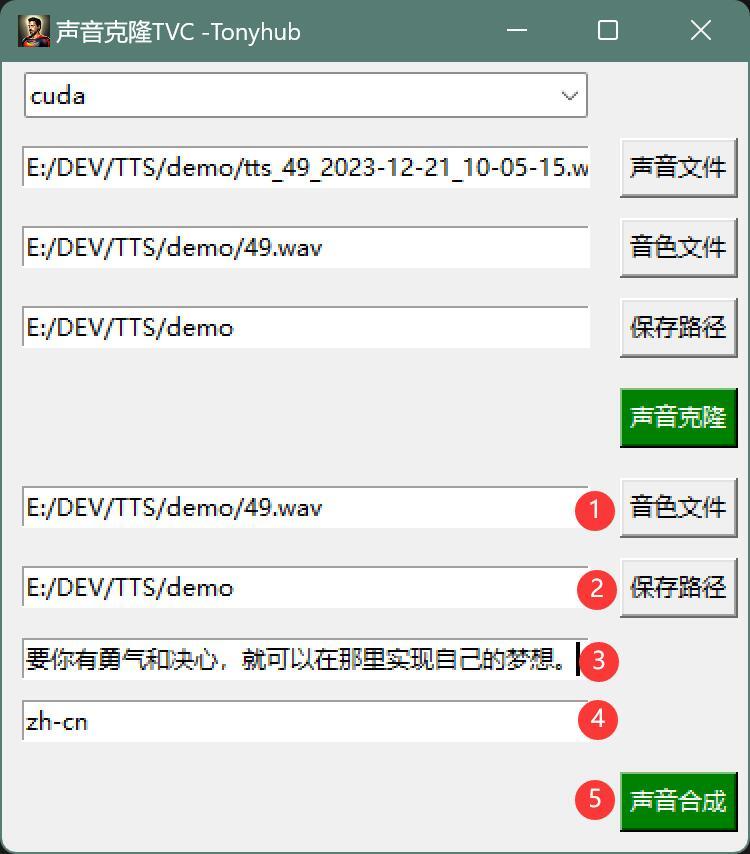
①选择音色文件
②设置保存路径
③输入文字内容
④设置合成语言
⑤开始声音合成
这里的音色文件,就是你要克隆的声音,就是一个参考声音。
最终合成的声音会参考这个声音。
硬件消耗和合成时间
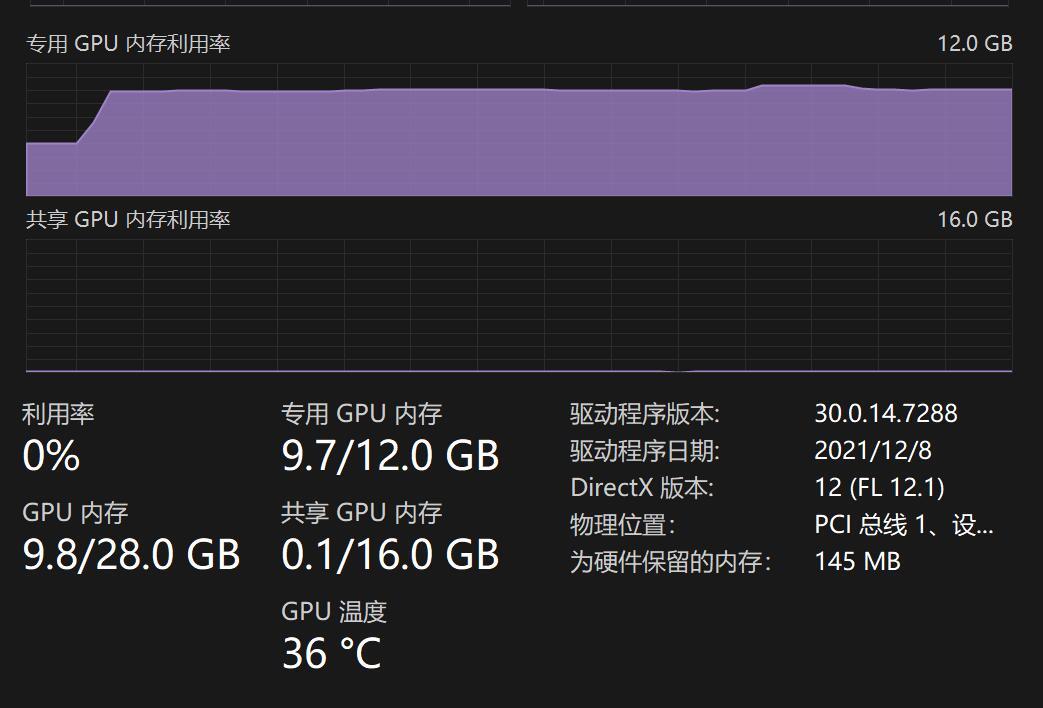
声音克隆这个部分,显存的消耗会随着音频增长而增加。
如果声音过长会导致显存溢出,就是爆显存(out of memory)。有人反馈1分钟就会爆,我自己在3060上测试了1分19秒的视频,大概消耗9.7G。
这个问题,我还不知道怎么解,目前只能靠大家自己剪辑合适长度了。后期软件也可以自己剪辑和拼接。显存这东西怎么回收我还不是很确定。
声音合成这部分就还可以,我测试了1000字的内容,合成过程并不会有什么问题。
我顺带对比了一下:
开始处理... 设备:cpu > tts_models/multilingual/multi-dataset/xtts_v2 is already downloaded. > Using model: xtts > Text splitted to sentences. ['在一个宁静的小村庄里,住着一个叫做李明的年轻人。', '李明一直梦想着远方的大城市,憧憬着那里的高楼大厦、繁华街头和无限可能。',........] > Processing time: 153.3884871006012 > Real-time factor: 4.062117042708661 处理完成! 开始处理... 设备:cuda > tts_models/multilingual/multi-dataset/xtts_v2 is already downloaded. > Using model: xtts > Text splitted to sentences. ['在一个宁静的小村庄里,住着一个叫做李明的年轻人。', '李明一直梦想着远方的大城市,憧憬着那里的高楼大厦、繁华街头和无限可能。',........] > Processing time: 33.13393473625183 > Real-time factor: 0.8192823864429364 处理完成!开始处理... 设备:cuda > tts_models/multilingual/multi-dataset/xtts_v2 is already downloaded. > Using model: xtts > Text splitted to sentences. ['在一个宁静的小村庄里,住着一个叫做李明的年轻人。', '李明一直梦想着远方的大城市,憧憬着那里的高楼大厦、繁华街头和无限可能。',........] > Processing time: 181.43268084526062 > Real-time factor: 0.8140918462501133 处理完成!
同样100字的故事,CPU消耗153秒,GPU消耗33秒。
同样是GPU,100字需要33秒,1000字是181秒。
大概是这个样子,大家可以做一个参考。
这次更新就是这些内容了。
接下来会重点研究:
- 如何解决声音过长OOM的问题。
- 考虑给界面换个皮肤,世人都喜欢好看皮囊,至少不能太丑。
- 研究下这个框架下有没有提升声音相识度的方法。
- 研究一下有没有更好的模型。
没有具体的时间表,有更新我肯定会通知。
当前更新,“知识星球” 用户已经可以在星球的精华帖中获取。
初始版本,可以通过给公众号发“tvc” 直接获取!
收工,玩得开心!
相关阅读:

关于作者
tony
某人