手把手教你玩声音克隆GPT-SoVITS,入手难度低,相似度高!
上星期看到一个听起来非常牛的AI声音克隆项目。

整个周末都在研究,从实践的结果来看,确实不错。
用了这个项目之后,感觉之前推荐的两个…突然不香了。
先来感受一下实测结果:
虽然时间仓促,素材也一般,但是最终效果还是挺好的。
音色保持得很好,也没机械音,杂音,外国口音。
这样的项目必须分享一下。
接下来,我会先简单介绍一下这个项目,然后做一个详细的使用教程。
这个项目的名字叫GPT-SoVITS,主页的一句话介绍是:
1分钟的语音数据也可以用来训练一个优秀的TTS(文本到语音)模型!(少量样本声音克隆)
细说呢,具有以下特征:
- 零样本文本到语音(TTS)
输入5秒的声音样本,即刻体验文本到语音转换。
- 少样本TTS
仅需1分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持
支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
- WebUI工具
集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和GPT-SoVITS模型。
开源项目能做到这四点已经非常强了!
下面结合官方资料和我的实操经验,来给大家演示一下这个项目的使用方法。
我尽量写得详细一点。
一方面方便大家学习,一方面就当是做笔记,巩固知识。
环境准备
Linux用户可以看GitHub主页。
这里主要介绍Windows系统的使用。
所以,你必须要有一个Win10+的操作系统。
另外配一张显存8G+ 的英伟达显卡。
软件安装
可以自己创建conda来安装,也可以使用“预打包文件” 。
为了尽量降低难度,这里使用预打包文件。我会在文末提供!
获取压缩包GPT-SoVITS-beta.7z后,使用解压软件解压即可。
预训练模型
目前,预打包文件里还没有包含所有模型,所以除了这个主体软件外,还需要下载一些模型。
这些模型包括ASR模型,UVR5模型, GPT-SoVITS 预训练模型,我会一并放在网盘里。
启动软件
上面的准备工作完成之后,把预训练模型放在pretrained_models文件夹里面。
然后找一个人的声音素材,大概一分钟左右即可,放在Voice文件夹里面。
我这里用的是Kevin老师分享的娜娜的声音。
一切就绪之后,点击go-webui.bat启动!
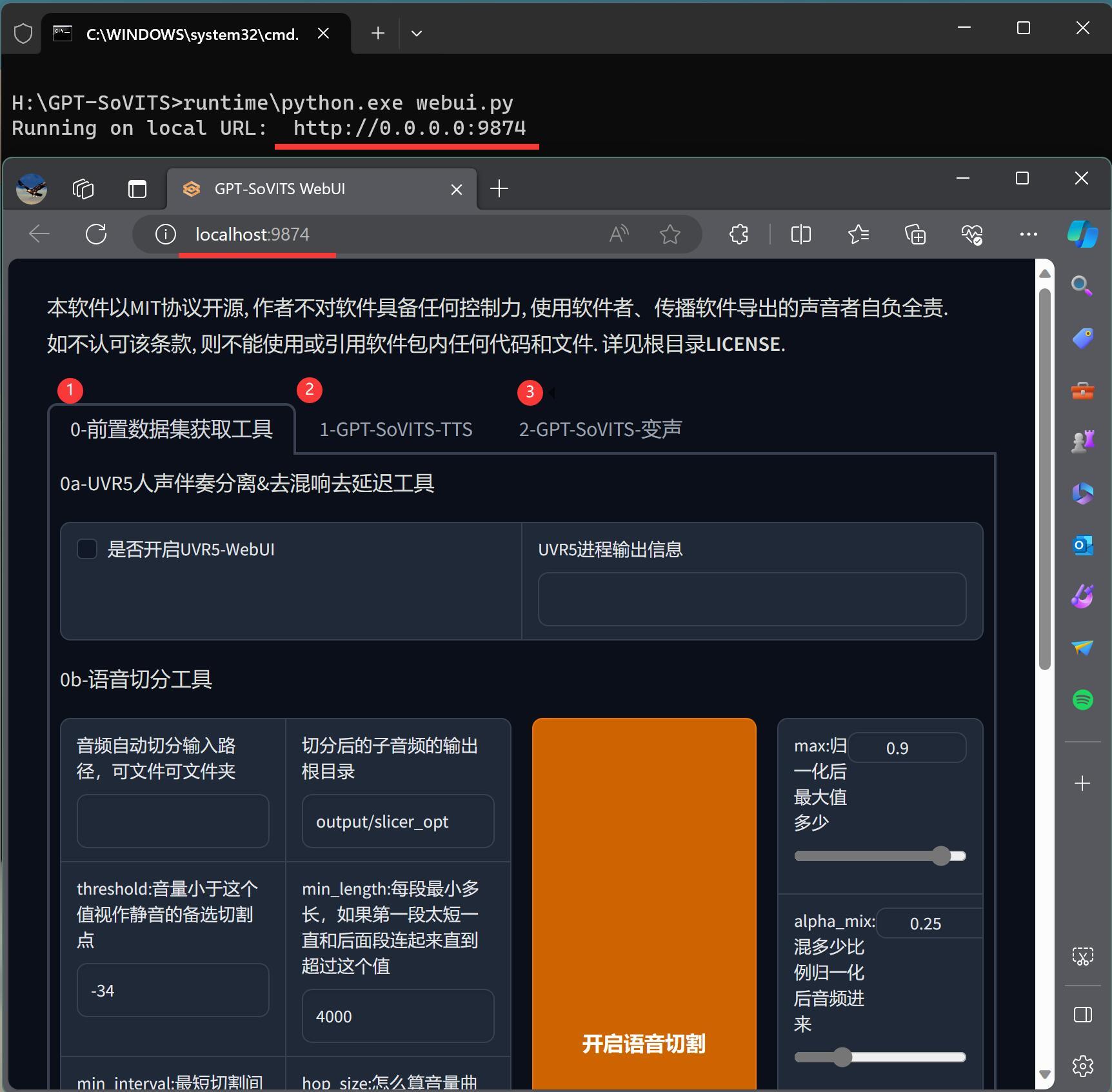
启动成功后会自动打开浏览器。
界面上主要分了3个标签页。
①前置数据处理
②声音合成(1-GPT-SoVITS-TTS)
③变声(2-GPT-SoVITS-变声)
前置数据处理,主要是来做声音分离,切割等工作。
比如你的声音有背景音乐,并且比较长。通过这一步就可以获取只有人声的一段一段的声音。
声音合成,主要是指把文字转换成声音。
这个环节又可以细分为三个步骤,A-数据格式化,B-微调训练,C-推理。
变声,指的是给出一段声音,改变这个声音的音色。目前该功能还在施工中!
零样本克隆
文章开始的时候说了,这个项目可以用5秒声音,进行0样本克隆。这个零样本主要是指的是无需训练,直接使用,参考声音还是需要的。
下面先来演示这个功能。
首先是按如下步骤,打开推理(合成声音)页面。
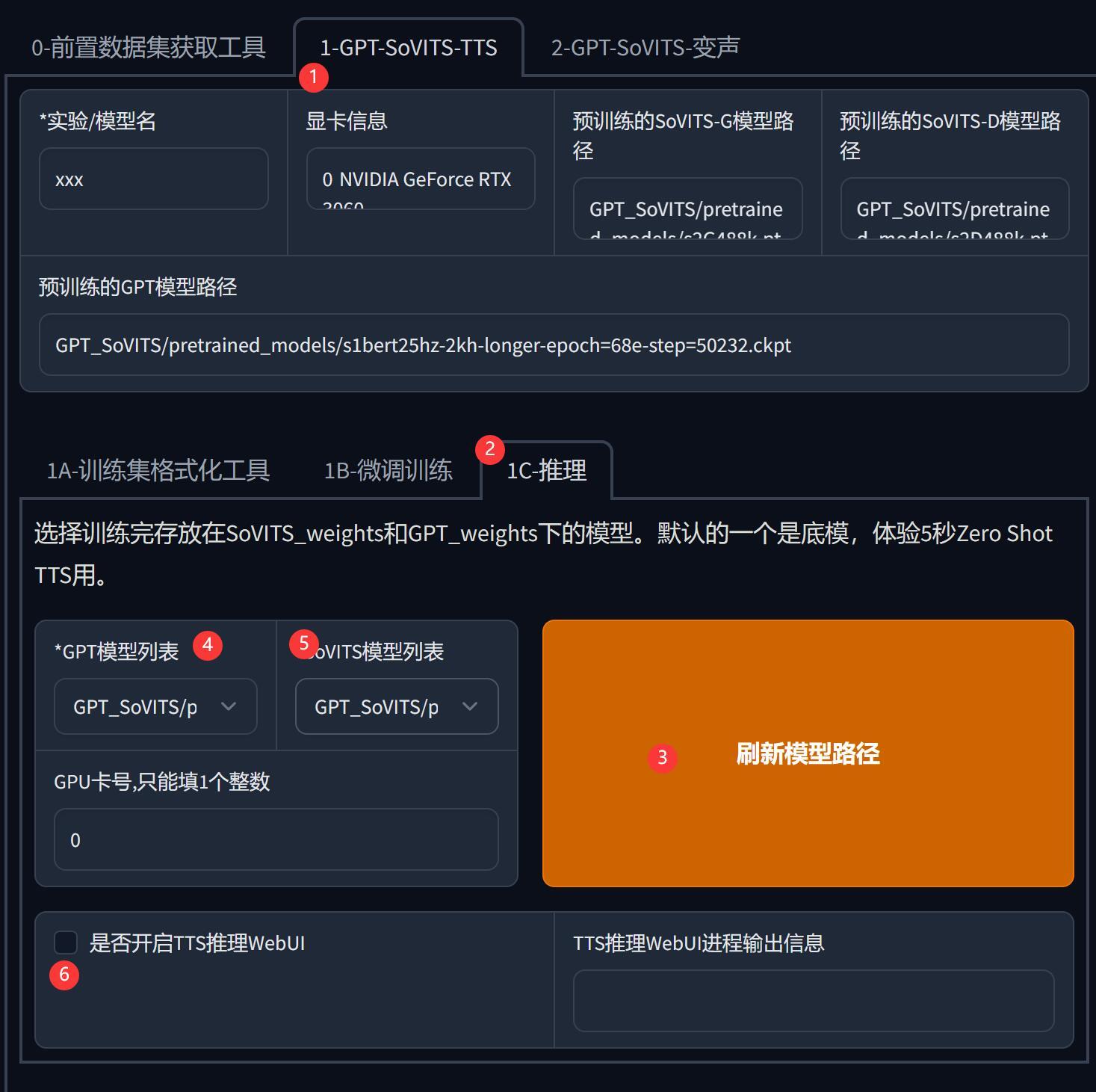
① 选择1-GPT-SoVITS-TTS
② 选择1C-推理
③ 刷新模型路径
④ 设置GPT模型
⑤ 设置SoVITS模型。
⑥ 勾选启动web UI。
这里设置的模型,就是我们放的预训练模型。
勾选之后,就会打开一个新的网页。
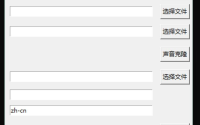
在新的推理页面中,按如下步骤设置。
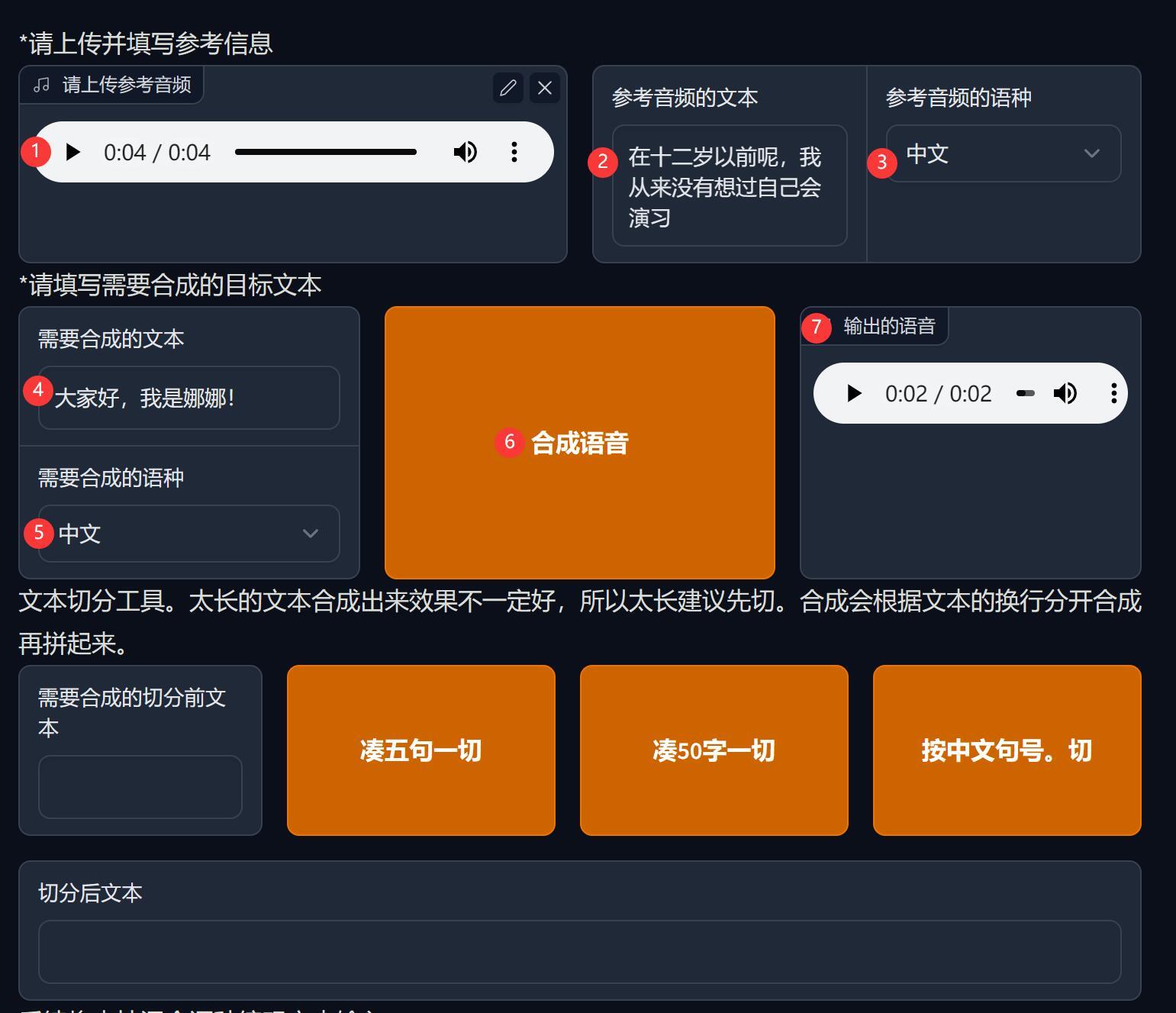
① 上传参考声音,就是你要克隆模仿的声音,几秒钟即可。
② 参考音频的文本,就是说话的内容。
③ 参考音频的语种,就是说话人的语言
④ 需要合成的文本,就是你想让他说什么话。
⑤ 合成语种,看合成文本,是中文就选中。
⑥ 点击 合成语言 按钮
⑦ 查看输出语音,就是合成结果。
注意:
这里的参考声音,不用太长,截取几秒钟的声音就好了。参考文本和语言要和声音严格对应。
合成内容和语言,可以是中文,英文,日语。
经过上面的操作呢,就可以通过几秒钟的声音,快速克隆了。
少样本克隆
使用上面的方式克隆声音,非常快,操作也简单,但是效果就很一般。
为了提升效果,我们就需要自己训练一个声音模型。
自己训练模型需要准备一段1分钟的素材,长一点当然更好。
然后需要对素材进行前置处理和格式化。
然后开始微调模型,微调成功之后就可以使用我们自己的模型进行推理合成了。
前置数据处理
这一步的主要作用有三个,一个是提取人声,一个是音频切分,还有一个是自动语音识别。
由于我的声音素材本来就是人声,所以UVR5这一步就不需要了。
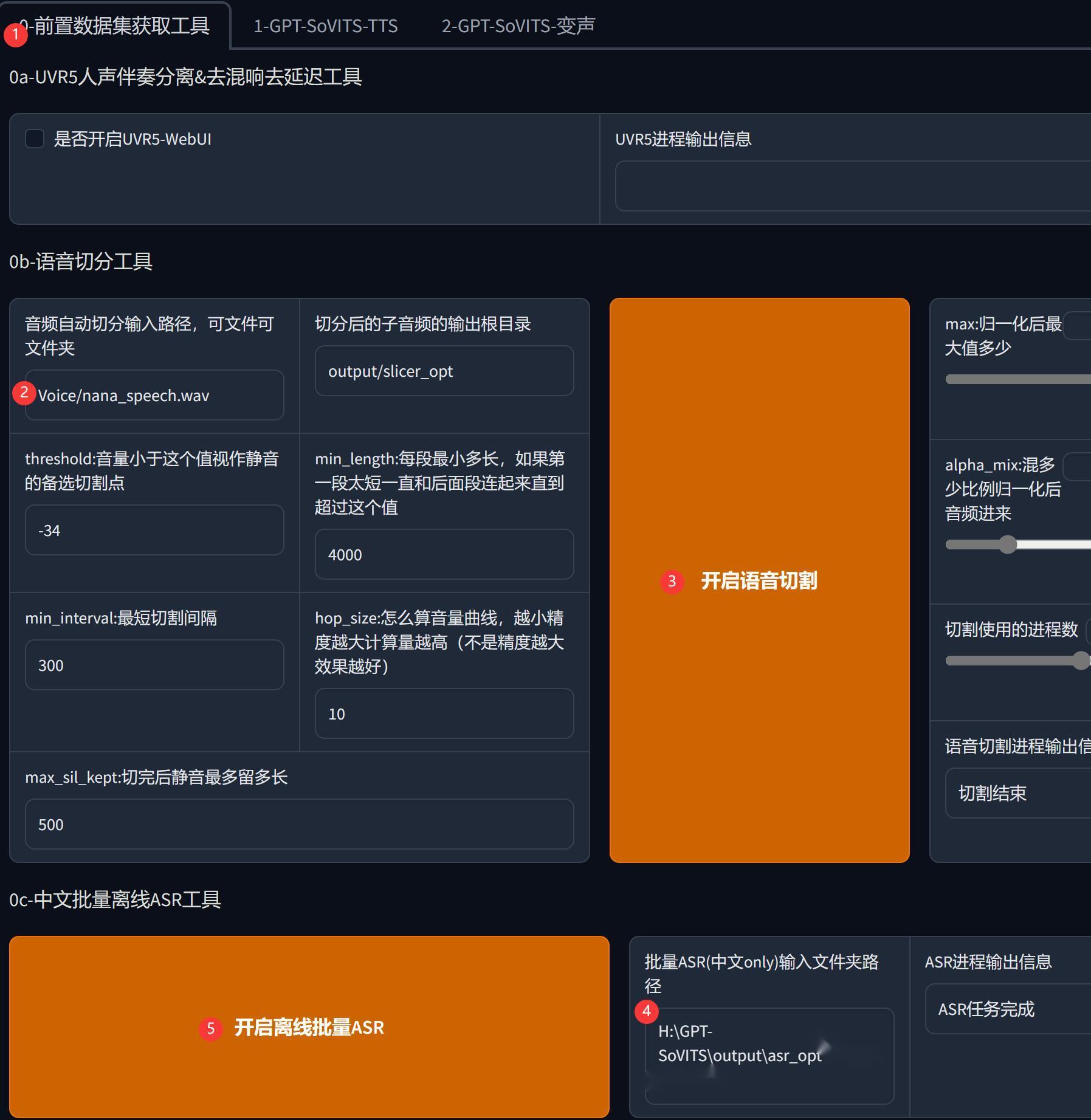
直接按①②③的步骤进行语音切分,设置好④处的路径,按⑤开始把声音识别成文字。
②里面的路径,是指相对路径。
我把声音放在了Voice文件夹里面。
所以这里的路径就是Voice/nana_speech.wav
④里面的路径,是一个绝对路径。
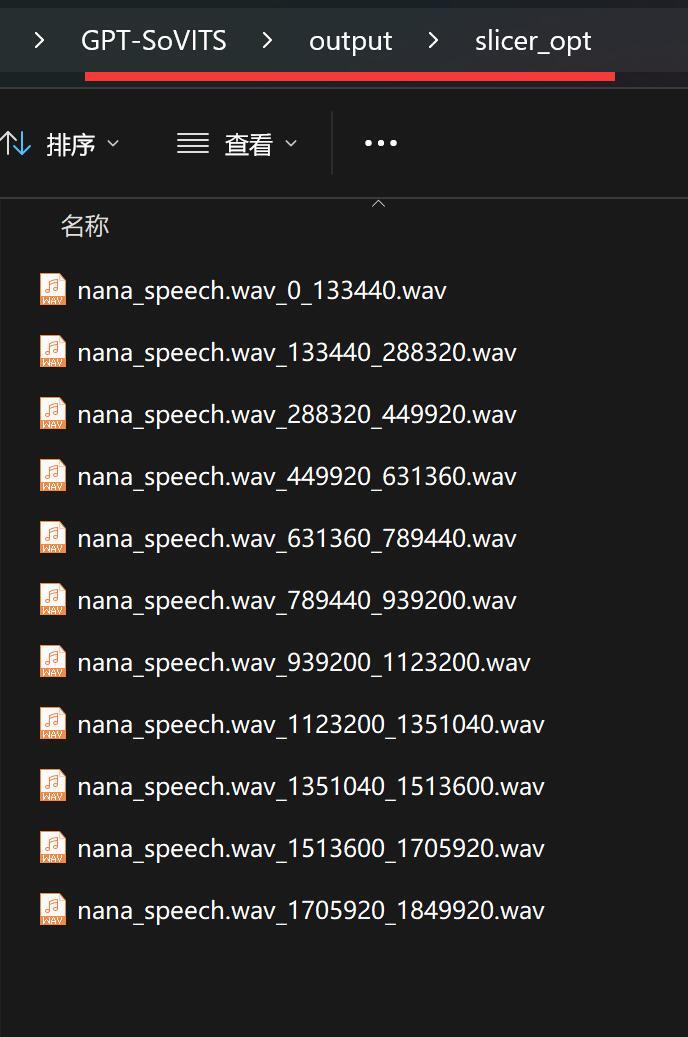
语音切分完成之后,会在slicer_opt文件夹下面生成多个声音文件。
相对路径:output>slicer_opt
ASR语音识别完成之后,会在asr_opt下面保存一个.list的文件。
相对路径:output>asr_opt
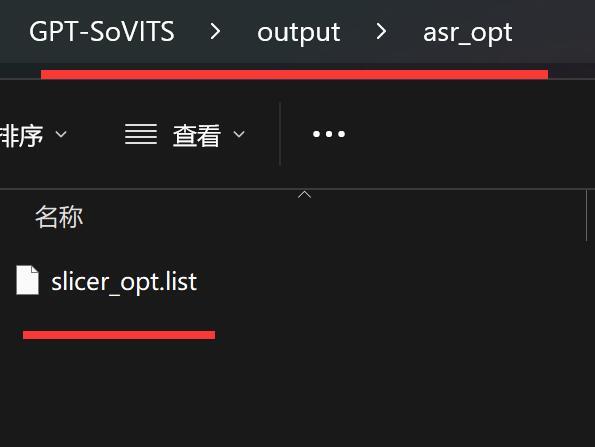
这是一个文本文件,包含了音频文件路径,语言,语音内容。
训练数据格式化
前置处理完成之后,就可以进行预格式化处理了。
按如下步骤进行设置。
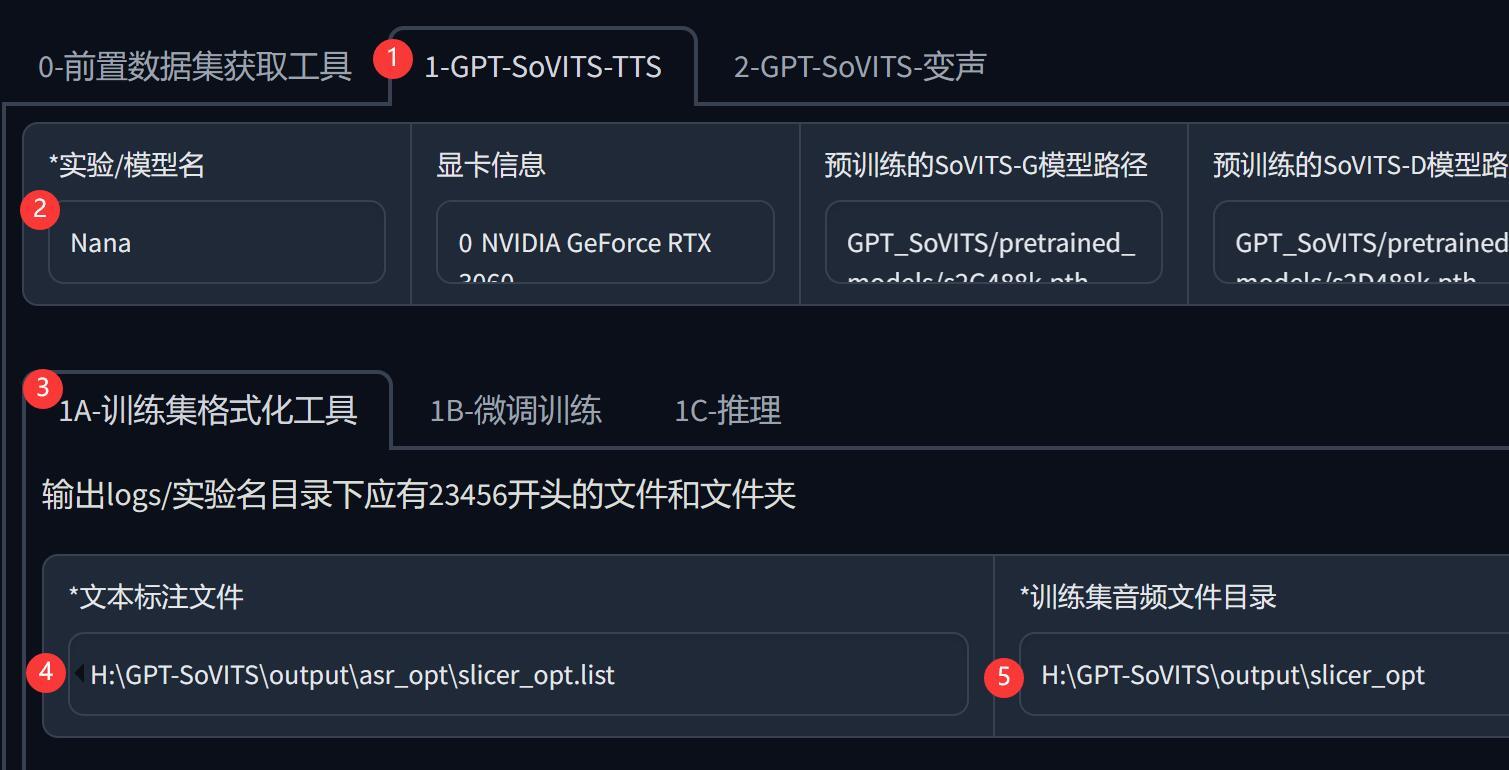
②处的模型模型字,主要是为了方便辨认和记忆,并没有特殊的要求。
④处的路径,就是上一步生成的.list文件的路径。
⑤处的路径,是上一步生成的声音文件的路径。
设置好之后,点击页面上的“一键三连” 按钮,程序就会按要求自动生成训练素材了。
生成的内容,可以在logs里面找到。
相对路径:logs>nana
打开这个文件夹,可以看到2,3,4,5,6的标识。具体是什么含义并不重要,只要看到有这些文件生成,就证明这一步已经完成了。
微调训练
训练素材准备好之后,就可以进行模型训练了,本质上是做微调。
微调界面有不少参数,都不要动。直接默认,按如下步骤运行即可。
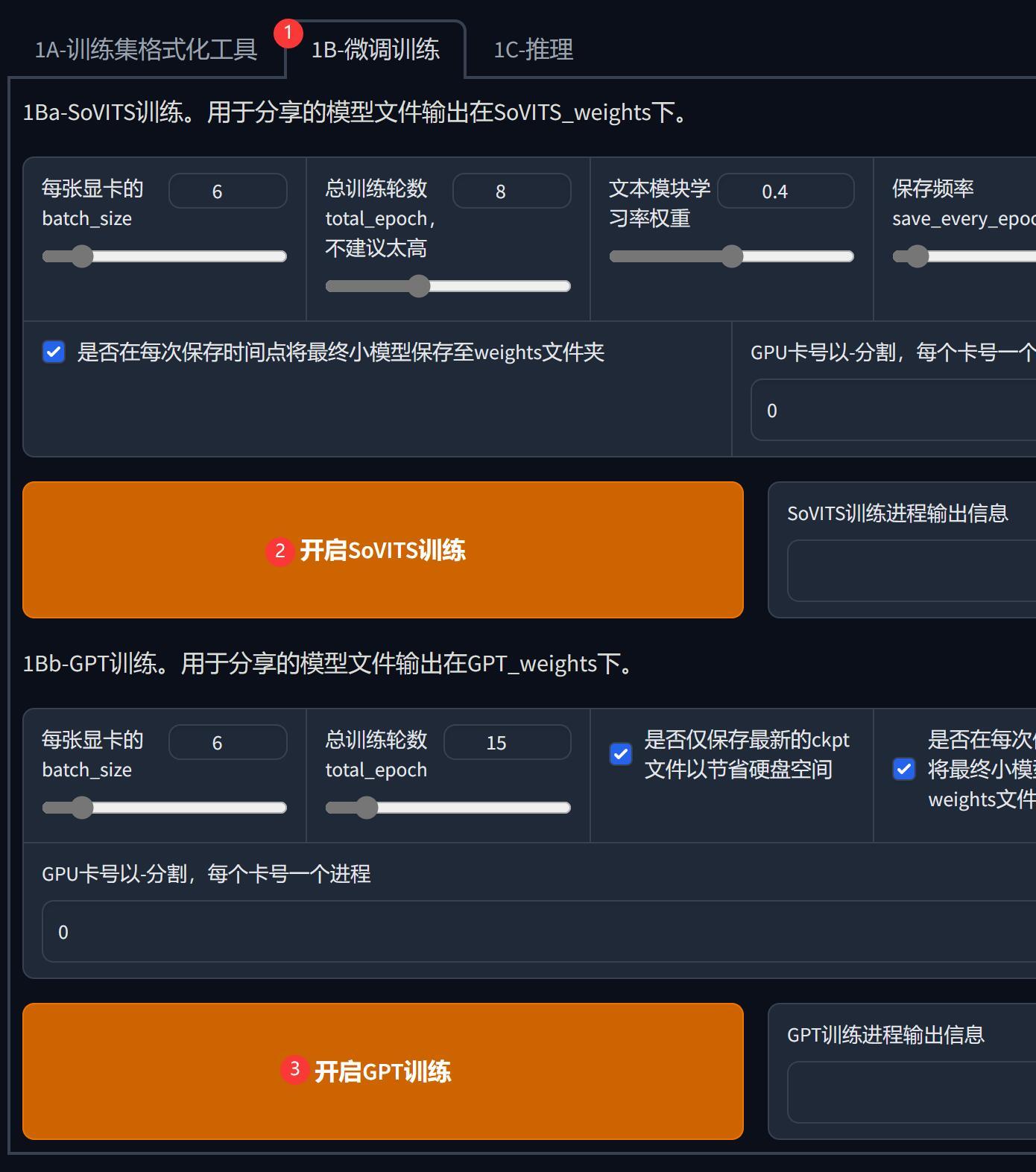
②和③并无先后要求,一个搞完,点击另一个就可以了。完成之后,按钮右边会有提示。
如果显卡比较好,可以把batch_size稍微调高一些。相反,显存不够就调低一些。
训练过程并不是很久,几分钟即可完成。具体速度和素材数量,参数,电脑配置有关。
模型推理
微调完成之后,就可以使用自己的模型进行推理了,也就是合成语音。
这个步骤和上面的零样本克隆一样。唯一的差别就是这次我们用自己的模型。
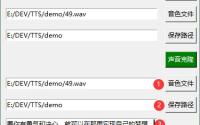
按下图中的步骤设置好参数。
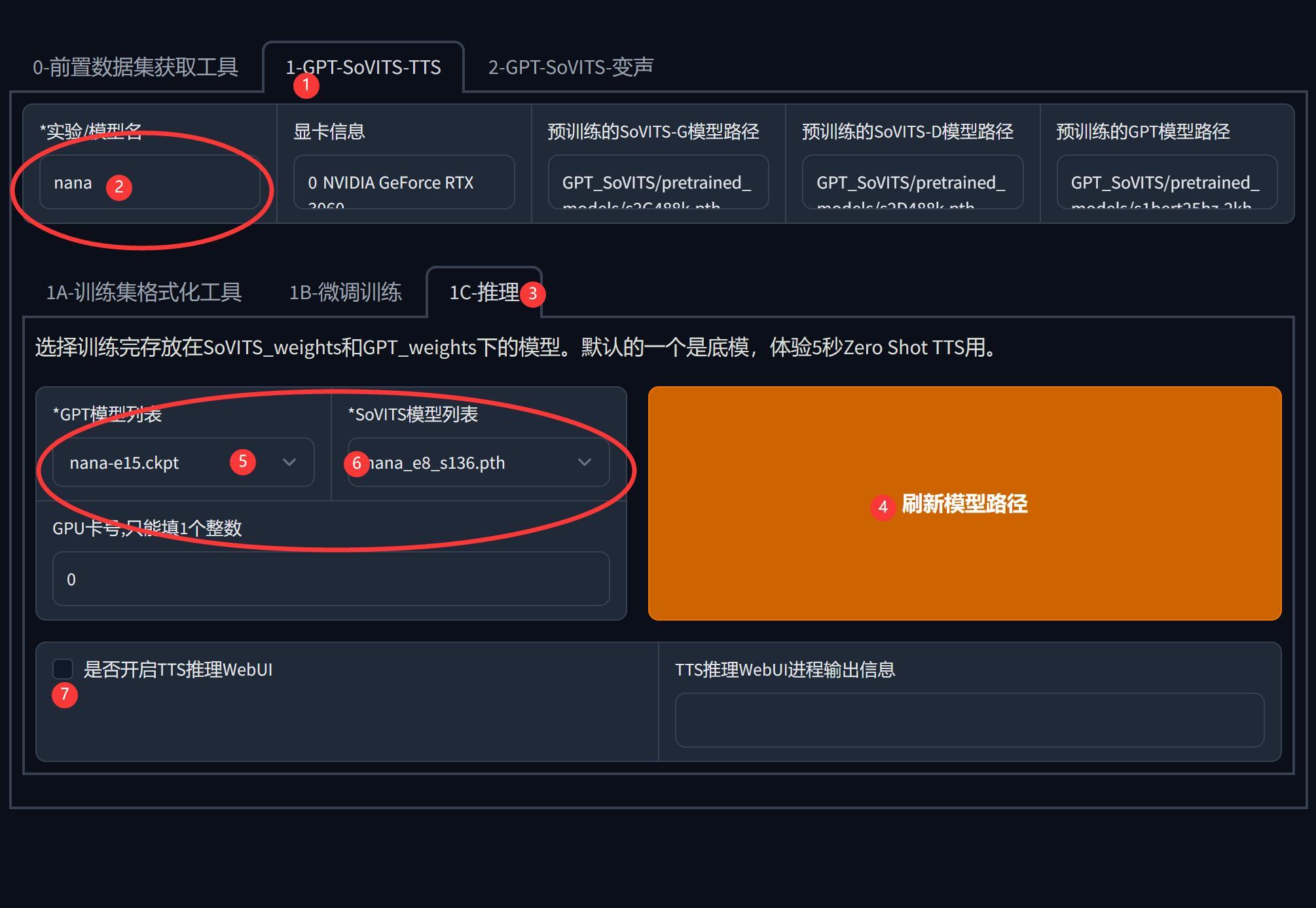
这里主要是设置好②处的模型名称。
记得点击一下④刷新模型,才能在模型列表中找到新的模型。
模型列表中选择nana开头的模型。
最后点一下⑦,打开推理WebUI。
接下来的步骤就和上面零样本克隆一模一样了。
此时,声音克隆效果就会好很多很多了。
以后就不需要再训练模型了,直接合成声音即可。
限于篇幅,人声分离和语音文本校对标注,英语模型训练这些都没有展开说明,有机会再做分享。
最后做点总结啊。
大概在19年左右,就看过声音克隆的项目,但是那个时候简直是…. 制作难度非常高,效果没法听,噪声和机械声啊,假得很。
随着时间的推移,AI的火爆。后来出现了很多语音类项目。
但是依然面临各种各样问题。
要么就是素材要求高,训练难度大,稳定性差,泛化差。
要么就是速度虽然很快,但是效果很拉胯。
整体来说,普通人想做出高质量的声音克隆还是不太容易。
根据GPT-SoVITS的作者介绍,他做这个项目初衷是,做一个开源的,普通人也可以玩转的声音克隆工具。
以我角度来看,他基本做到了。
这工具确实做得不错,应该是我接触到的工具里面,使用相对简单,效果最好的声音克隆工具。
这个项目可以跟一跟,已经有比较大的实用价值了。
预安装包和模型,关注公众号“托尼不是塔克”发送“gptso” 直接获取!
关于作者
tony
某人