MiMo送820亿Tokens?!只有3天,时间紧,任务重!
MiMo 送的 16 亿好不容易消耗了 25%~ 早上一看变成满血 820 亿了!
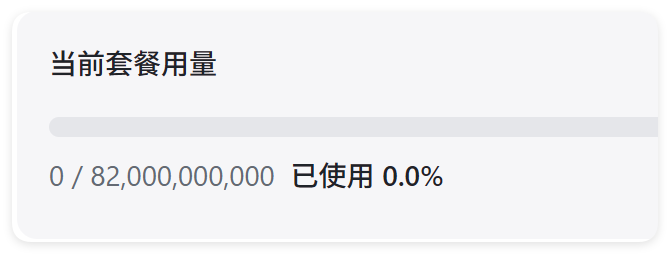
牛逼,数字越来越离谱了,我数零都数了好久,能不能帮我换成钱啊?
这是不是受到了 DeepSeek 永久 2.5 折的刺激啊?!
关键的问题是这个月只有 3 天了,这个重置 + N 倍配额是否有点……!

虽然这个 Tokens 纯度不太高,但是量是真的大!
接下来,就是终极一问:如何在3天内消耗820亿了???
上一篇我讲了,我询问不同 AI,如何快速消耗 Tokens!
后来给了我就制作了一个武侠百科《江湖百晓生》,MiMo 做的没法用。
然后还做了一个文档网站。把 Claude 的 API 文档一口气全给拉到本地了。
然后用 MiMo 翻译成中文文档!
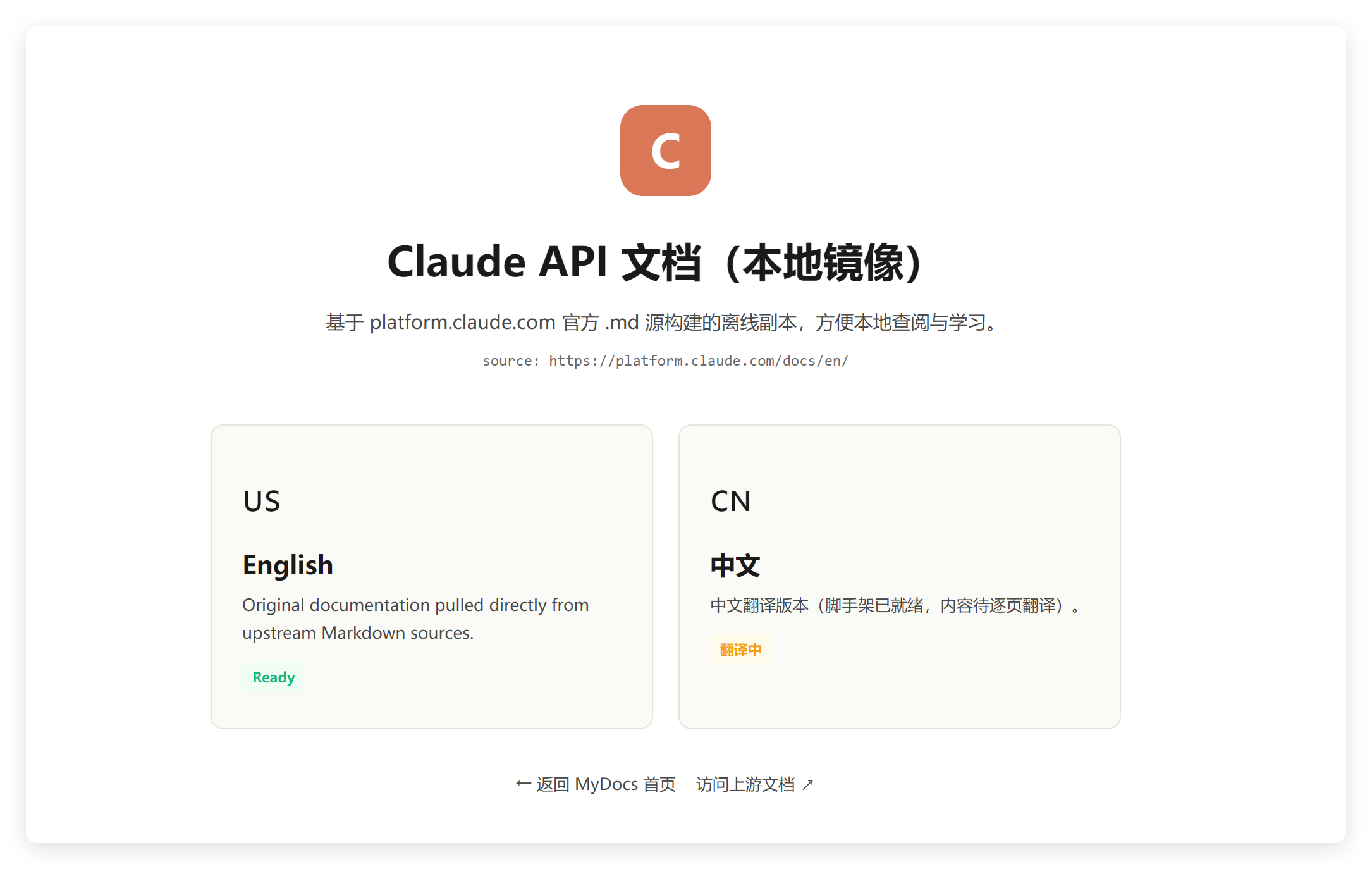
这个事情还挺消耗 Tokens,MiMo 的结果还是能看的,至少比全英文的好多了。
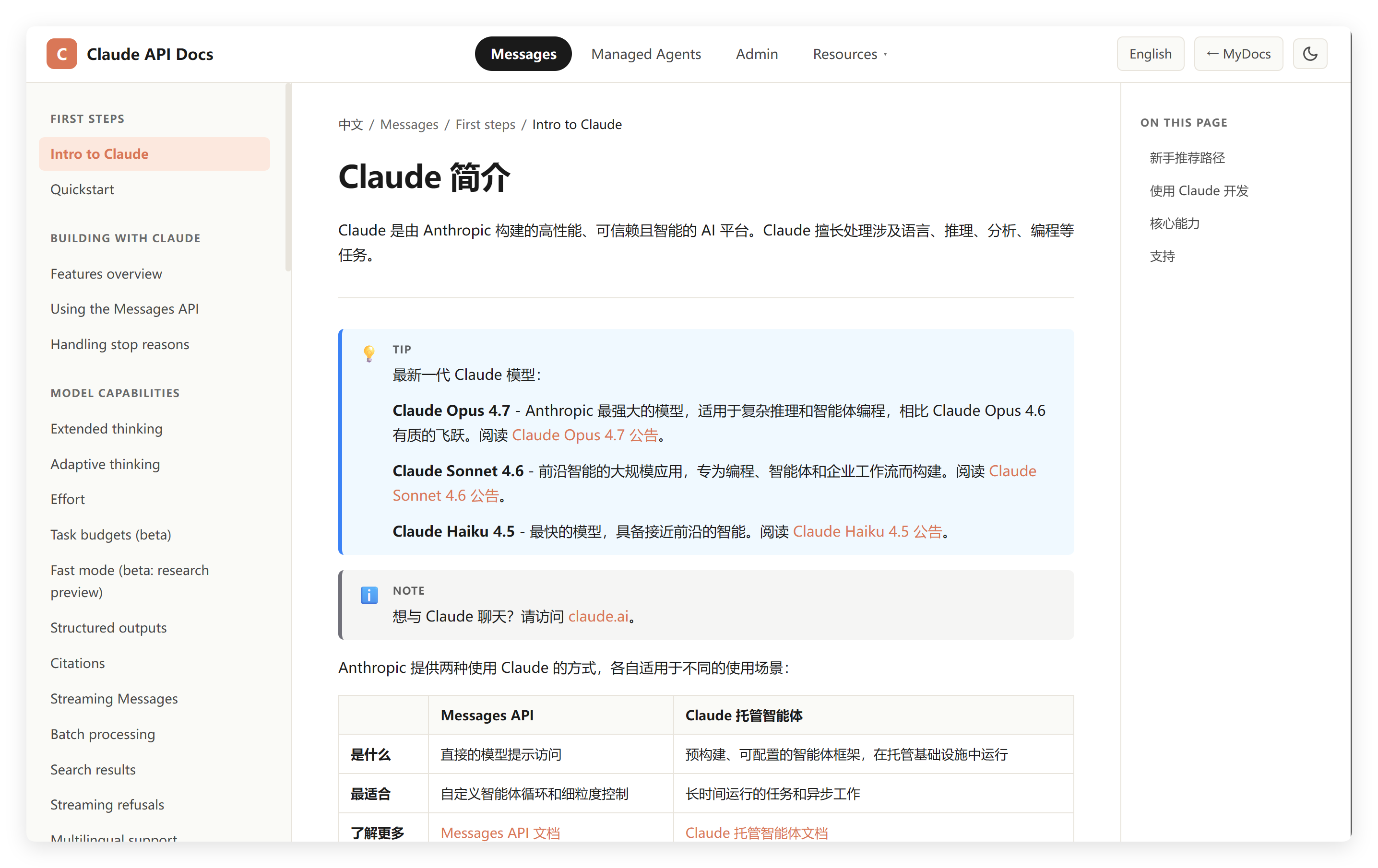
今天就来讲讲这个使用场景吧!
然后记录一下:我是如何使用 Opus4.7 结合 MiMo 来构建这个网站的。
优质 Tokens + 普通 Tokens 打组合拳,不浪费一个 Tokens。
1、Opus 负责高难度任务!
我们先让Opus完成最难的部分。分析网站,抓取内容,建立架构!
我们先来看一下 Claude 官方的网站:
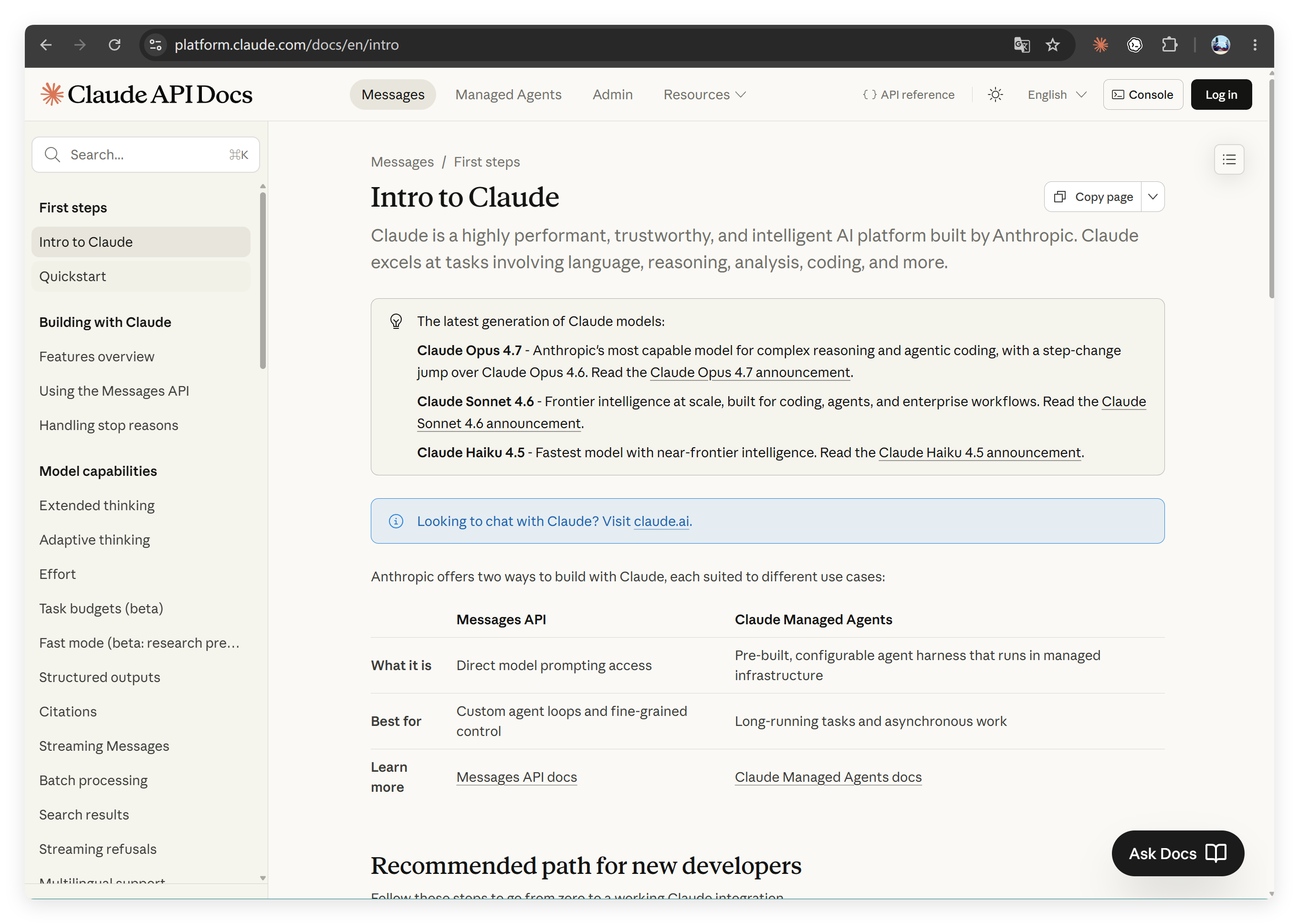
这个网站数据量还是不小的,而且基本上是全英文的状态。虽然它提供了中文选项。但是中文内容严重缩水,残缺。
抓数据其实是个老学科了,但是现在也会有各种问题,有些网站是根本抓不到数据的。所以我第一步是问了一下能不能抓到数据。

Opus说可以看到!
然后开始上我的需求了:
我计划在当前项目目录下创建一个 `claude/api` 文件夹,用来搭建一套 Claude API 文档的本地化资料库。我的目标是把官网上的 Claude API 文档,按照网页原本的菜单结构下载到本地。这个网站有一个很方便的特点:每个页面都可以通过在网页地址后面添加 `.md` 后缀,直接获取对应的 Markdown 文件。因此,我希望先基于官网的菜单列表和页面结构,把这些 Markdown 文档下载下来,并按照原网站的层级关系保存到本地。默认下载英文版本,也就是 `en` 版本。在英文原版文档整理完成之后,我还希望基于英文版再生成一套中文版本,也就是 `cn` 版本。中文版的目录结构应该和英文版保持一致,只是内容翻译成中文。这样可以方便后续对照、维护和学习。最终,我希望基于这些本地 Markdown 文件,制作一个类似官网的本地文档网页。这个网页可以把 Markdown 转换成 HTML,并保留文档结构、导航菜单、标题、代码块、表格、链接等内容,方便我在本地查阅和学习。
Opus 收到需求之后进行了分析。
Opus的分析思路:
1. 探索当前 MyDocs 项目结构,看看你已有的 md→html 框架长什么样(能不能复用)2. 验证 claude.com 文档站的 .md 接口和目录结构(导航树的获取方式)3. 估算文档规模和翻译成本我并行启动两个 Explore agent,再亲自抽取一两个 .md 端点验证。
Opus的分析结果:
探索完毕。整体可行性分析如下:你的想法评估:✅ 方向正确,但有几个需要决策的细节# 好的部分(采纳).md 后缀技巧已验证可用,所有页面都能拿到原始 markdownclaude/api/ 占位目录你已经预留好了,与现有 MyDocs 结构对齐先英后中分两阶段是对的(先确保管线跑通再翻译)# 需要修正的部分不是纯 CommonMark,是 MDX:返回的 .md 文件包含 <Card>、<Tip>、<Steps>、<Tabs>、<CodeGroup> 等 JSX 组件标签。常规的 markdown-it / marked 不能直接渲染,必须做转换映射(mapping 到 styled <div>),否则页面会显示乱码标签。MyDocs 当前是纯手写 HTML,没有 md→html 管线:hermes-agent 那套是模板,但 ~150-200 页文档不可能手写。需要建一个构建脚本(fetch .md → 解析 MDX → 输出静态 HTML),一次性生成全部页面。侧边栏导航需要单独抓:sitemap.xml 有所有 URL,但没有 "Build with Claude > Messages API" 的分组顺序。需要从 /docs/en/intro 页面抓 sidebar HTML 或试 llms.txt。# 规模数据英文文档约 150-200 页,原始 markdown 5-15 MB多语言官方有 11 种(含中文),但官方中文质量不确定,自己翻译可能更可控# 推荐的改进版方案把整个流程脚本化(Python 单脚本,~3 个阶段):fetch_docs.py → 抓 sitemap + 所有 .md,存到 claude/api/_src/en/build_site.py → MDX 组件 → HTML 映射,生成 claude/api/en/*.html + 侧栏translate.py → 调 Claude API 批量翻译 _src/en/*.md → _src/cn/*.md (复用 build_site.py 生成 claude/api/cn/*.html)这样英文站和中文站共用一套构建逻辑,只是源 md 不同。在写最终方案到文件之前,几个关键决策需要你拍板:
Opus的总结包含了:好的部分,需要改进的部分,数据规模评估,改进方案,最后等我拍板!
然后就给我提了几个问题:

上图已经有完整的问题和我的选择了!
接下来就全部交给 Opus4.7 了。它制作了详细的计划文档,然后开始执行。
执行过程中它发现:
英文文档全量是 1541 页,远超我初估的 150-200。先验证 MDX 渲染再决定要不要全量。看一眼源文件结构:...
这个数据量确实有点太大了,我一口气吃不下,而且我不确定这些文档是否有用。我让它分析了一下,其中 1197 篇属于不同语言的 SDK 文档。我可能用不上,就先不抓取了。
最后的汇总信息如下:
# 汇总(sitemap 1541 · 已抓 381 · 未抓 1197)# Part 1 — 已抓(按 tab / group) ├ Tab: Messages (72) — 10 个 group 完整展开 ├ Tab: Managed Agents (30) ├ Tab: Admin (25) └ Tab: Resources (263) ← 含 REST API endpoints 全部# Part 2 — 未抓(1197,9 SDK × 133) ├ Python SDK (133) ← <details> 折叠 ├ TypeScript SDK (133) ├ Java SDK (133) ├ Go SDK (133) ├ Ruby SDK (133) ├ C# SDK (133) ├ PHP SDK (133) ├ CLI (133) └ Terraform (133)# Part 3 — 后期补抓指引(含代码模板)
总共抓取了 381 个页面!
这个过程非常丝滑,没遇到任何问题,也没遇到频率限制。
Claude 官网是构建在 Mintlify 上面的,我不清楚它的防抓策略如何。反正 Opus 轻松搞定了!
它帮我构建的目录结构如下:
claude/api/├── index.html 语言切换入口(en / cn 卡片)│├── en/ ← 构建产物:英文站│ ├── index.html 英文落地页(tab 卡片列表)│ ├── intro.html│ ├── get-started.html│ ├── build-with-claude/*.html│ ├── agents-and-tools/tool-use/*.html│ ├── managed-agents/*.html│ └── manage-claude/*.html│├── cn/ ← 构建产物:中文站(结构镜像 en)│├── _src/ ← 源 markdown(进 git,不上线)│ ├── nav.json 抓取得到的导航树│ ├── en/*.md 上游原始 MDX│ └── cn/*.md 中文版(初期为英文占位)│├── _build/ ← 工具链│ ├── package.json Node 依赖清单│ ├── fetch.mjs 抓取脚本│ ├── build.mjs MDX → HTML 构建器│ ├── translate.mjs 中文骨架生成器│ ├── components.mjs MDX 组件 React 实现│ └── templates/│ ├── page.html 文档页外壳│ └── landing.html 落地页外壳│└── _assets/ ← 浏览器加载的样式与脚本 ├── docs.css └── docs.js
同时帮我创建了四个脚本:
| 脚本 | 输入 | 输出 | 何时跑 |
|---|---|---|---|
fetch.mjs | platform.claude.com HTTP | _src/en/*.md + _src/nav.json | 想刷新上游内容时 |
build.mjs [lang] | _src/<lang>/*.md + nav.json | <lang>/*.html + landing | 改了源、模板或样式后 |
translate.mjs | _src/en/*.md | _src/cn/*.md | fetch 后一次即可 |
inventory.mjs | sitemap.xml + nav.json | docs/claude-docs-url-inventory.md | fetch 后想看完整 URL 列表 |
还挺贴心准备了命令速查:
cd claude/api/_build# === 抓取 ===node fetch.mjs # 默认: 11 页 allowlist (开发用)node fetch.mjs --tab=messages # 单 tab 全部 (~72 页)node fetch.mjs --tab=managed-agents # ~30 页node fetch.mjs --tab=admin # ~25 页node fetch.mjs --tab=resources # ~38 页 (不含 EXTRAS)node fetch.mjs --all # 4 个 tab sidebar 全部 (~155 页)node fetch.mjs --all --with-extras # ↑ 再 + EXTRAS (sitemap 补抓) = 381 页# 调节速率(默认 concurrency=3 delay=150ms)node fetch.mjs --all --with-extras --concurrency=2 --delay=250# === 构建 ===node build.mjs en # 输出 en/*.htmlnode build.mjs cn # 输出 cn/*.html# === 中文骨架(仅复制,无 LLM)===node translate.mjs# === 一条龙:fetch + build en + scaffold cn + build cn ===npm run all# === 重新生成 URL 清单(汇报工具,不抓取)===node inventory.mjs # 输出 docs/claude-docs-url-inventory.md
通过脚本,可以指定抓取内容,可以快速根据MD文档构建网页,然后也可以进行翻译,也可以一条龙运行。
因为它考虑到翻译的 Tokens消耗 量比较大,所以它暂时没有做 ,留空了!
它不想浪费自己的 Tokens~~
所以它的活,到这里就结束了:
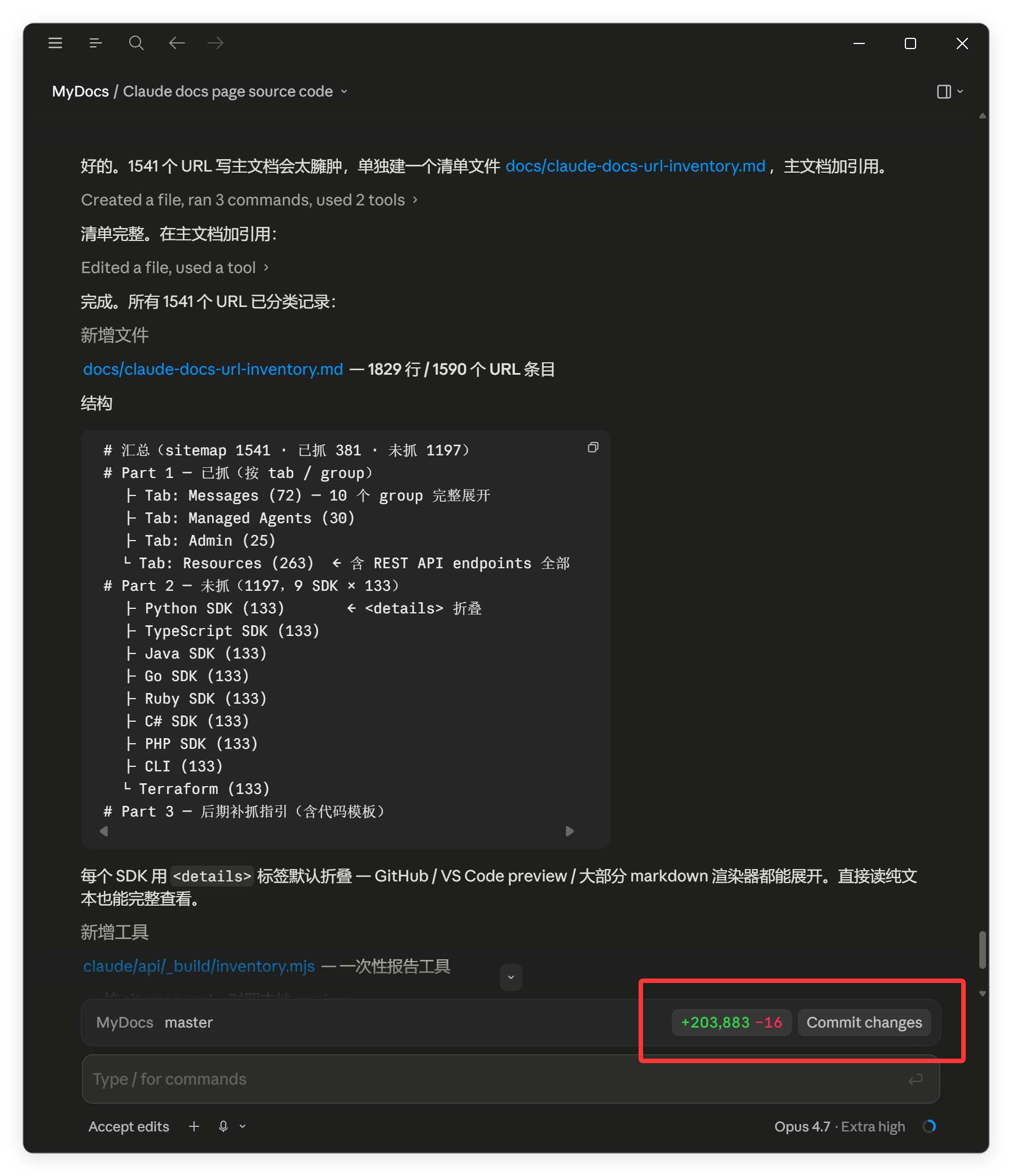
总共修改 20 万行内容!
目标网站分析报告,执行报告,和汇总报告全部做好了!
当然源代码也全部写好了,尤其是把 MDX 到 HTML 的转换器也写好了。
我只要一个命令,就可以快速把所有MD文档转换成HTML网页!
可以快速构建一个纯静态的 Claude 文档中文镜像网站。
有了这些资料,只要是 Claude 相关的问题,AI 就可以精准执行了!
2、MiMo 负责高消耗任务!
接下来就轮到 MiMo 上场了!
现在问题已经非常清晰了,Opus4.7 已经把所有结构都做好了。而且把所有文档放在 cn 目录下面了。
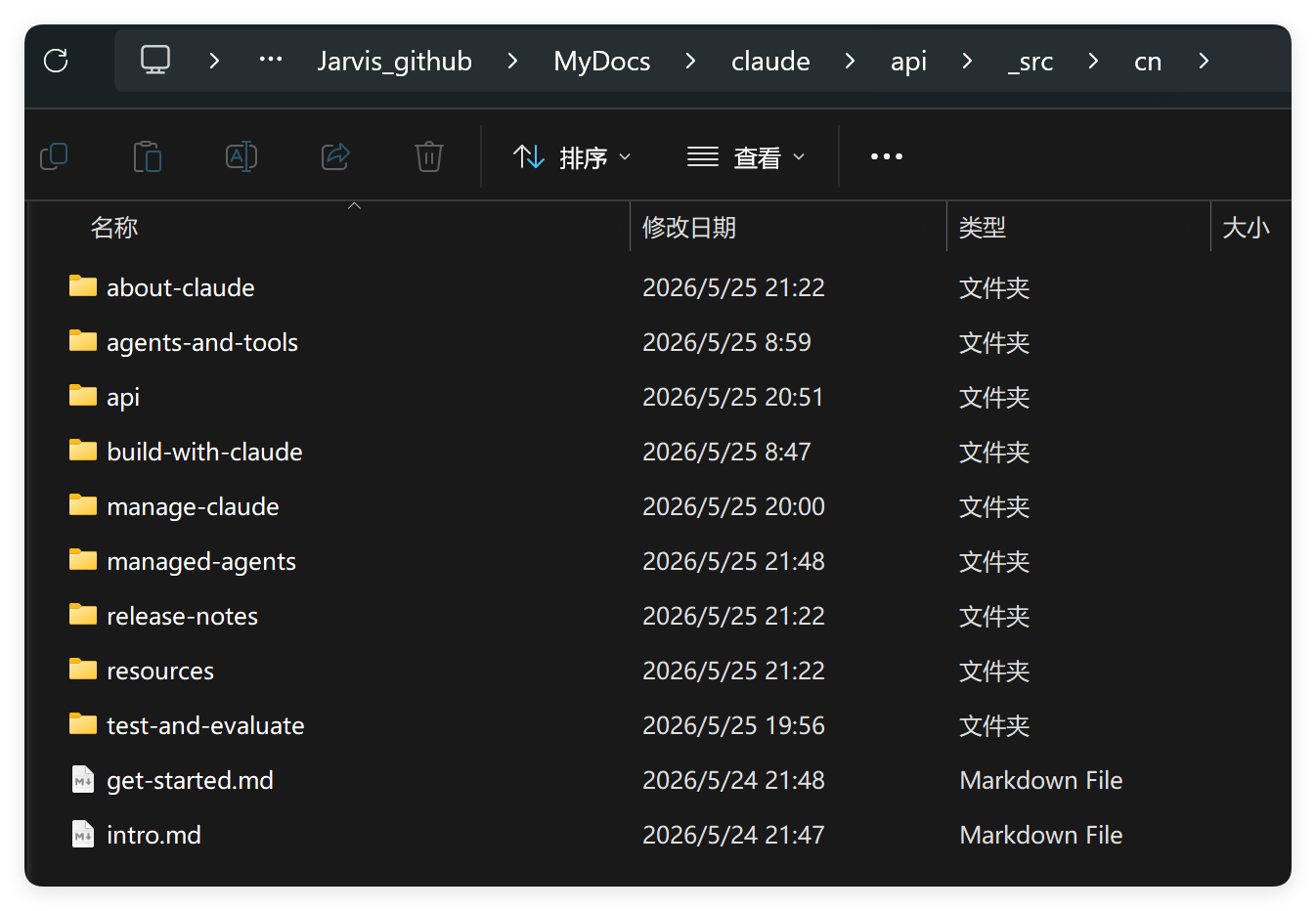
我只要让 MiMo 读取这些文档并翻译即可。它只做这一件事情!
后续执行一下 Opus 的脚本就能转换成网页了!
具体的操作就是打开 JCode:

然后把 cn 这个目录拖动到 Xiaomi 这个图标!
这样就可以直接打开 Claude Code 了:
模型和 API 相关数据已经自动配置完成了!
接下来的事情就非常简单了!
只要告诉他:“帮我读取所有文件,把其中的英文文档翻译成中文”!
然后就不用管了,它会自己读取文件,自己判断,直接管理多个智能体并行翻译!
大概花费了几个小时,几百个文档全部翻译完成。消耗了几个亿的配额,16 亿中的 25% 消耗完了!
这个组合还不错!
现在 AI 能力非常强,唯一缺少的就是新的或者准确的知识。
所以构建一个专门给自己或者 AI 的知识库非常重要!
正好,现在不差 Tokens,把各种文档都捞一波,然后做成中文版。
英文的 MD 文档给 AI 看,中文网页方便自己看,完美!
我也有计划把我完整的文档库分享出来:
目前还只是有一个想法,内容还没做好~~!这种事情急不来,只能慢慢来!


关于作者
tony
某人