GLM-OCR:开源玩家又有福了!
一夜之间,大家都开始卷 OCR 了么?
28 日,DeepSeek 发布了 DeepSeek-OCR 2。
29 日,百度发布了 PaddleOCR-VL-1.5。
没过几天,智谱发布了 GLM-OCR。
全都是奔着小巧又能打而去的。而且都是开源的,可以立马集成到自己的项目中。
今天来看看新鲜出炉的 GLM-OCR!
看起来很不错哦,0.9B 各项指标都这么高?
OCR 是什么?
OCR 是 Optical Character Recognition(光学字符识别) 的缩写,是一种把图像(照片/扫描件/PDF)中的文字自动 识别并转成可编辑、可搜索文本 的技术。它核心包含两个步骤:
- 文字检测:定位图像中哪里有文字
- 文字识别:识别字符内容并输出文本
现代 OCR 基于深度学习,对不同字体、复杂排版、表格、公式甚至手写文本都有支持。应用广泛于文档数字化、票据识别、身份证识别、档案管理等场景。
GLM-OCR 是什么?
GLM-OCR 是一个多模态 OCR(光学字符识别)模型,专门用于复杂文档的理解与识别,基于 GLM-V 编码器–解码器架构构建。它的核心由三部分组成:在大规模图像–文本数据上预训练的 CogViT 视觉编码器、一个带有高效 Token 下采样的轻量级跨模态连接器、以及 GLM-0.5B 语言解码器。
核心特性
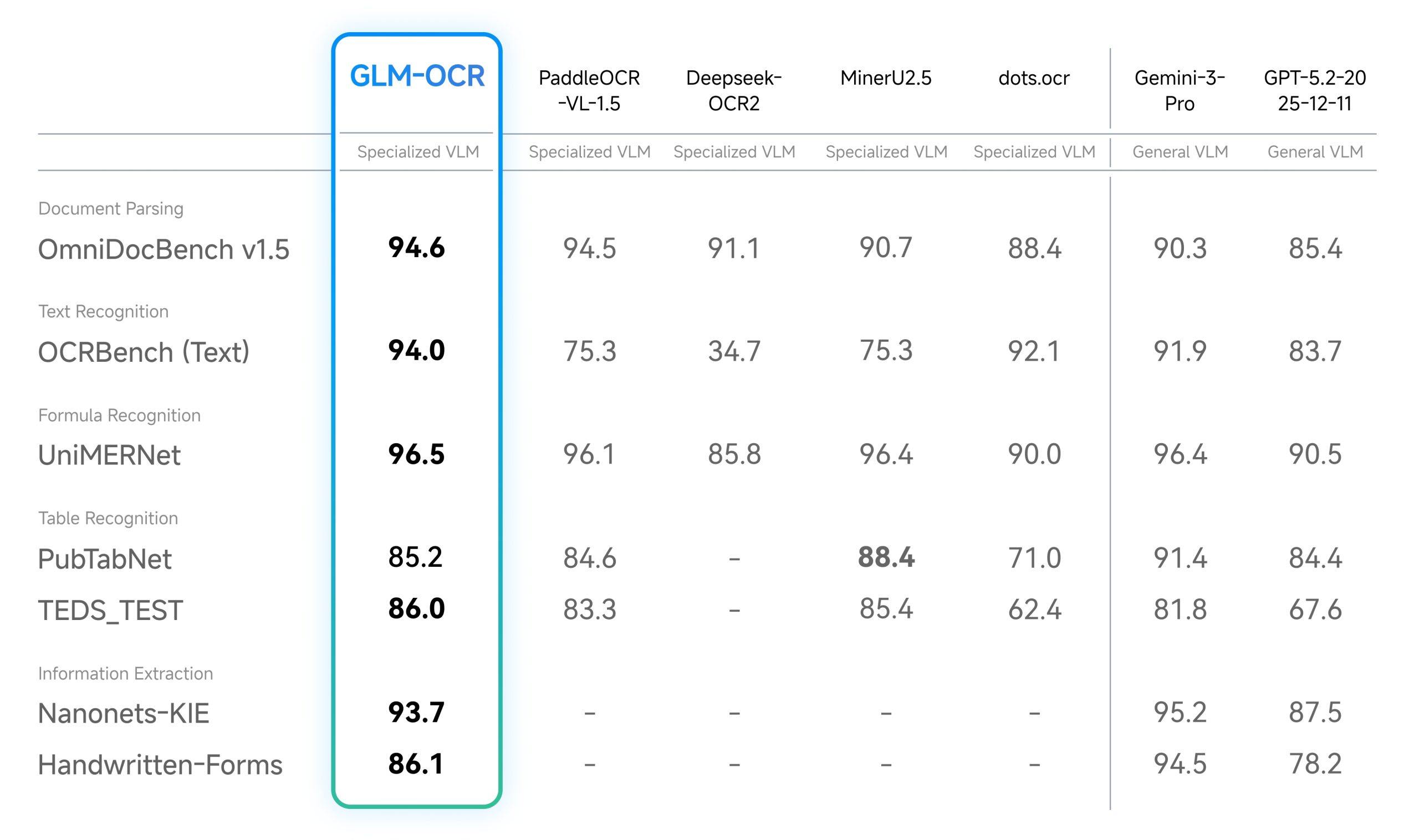
1. 业内领先的识别性能 在权威的文档解析基准 OmniDocBench V1.5 上得分 94.62,综合排名第一。在文本识别、公式识别、表格识别和信息提取四个关键领域全部超越了多款专门的 OCR 模型,性能接近 Gemini-3-Pro 的水平。
2. 针对真实场景深度优化 在代码文档、复杂表格、手书体识别、多语种文本、印章识别和发票提取等六个核心实战场景中均表现优异。即使面对复杂版面、多种字体或图文混排内容,识别精度也能保持出色。
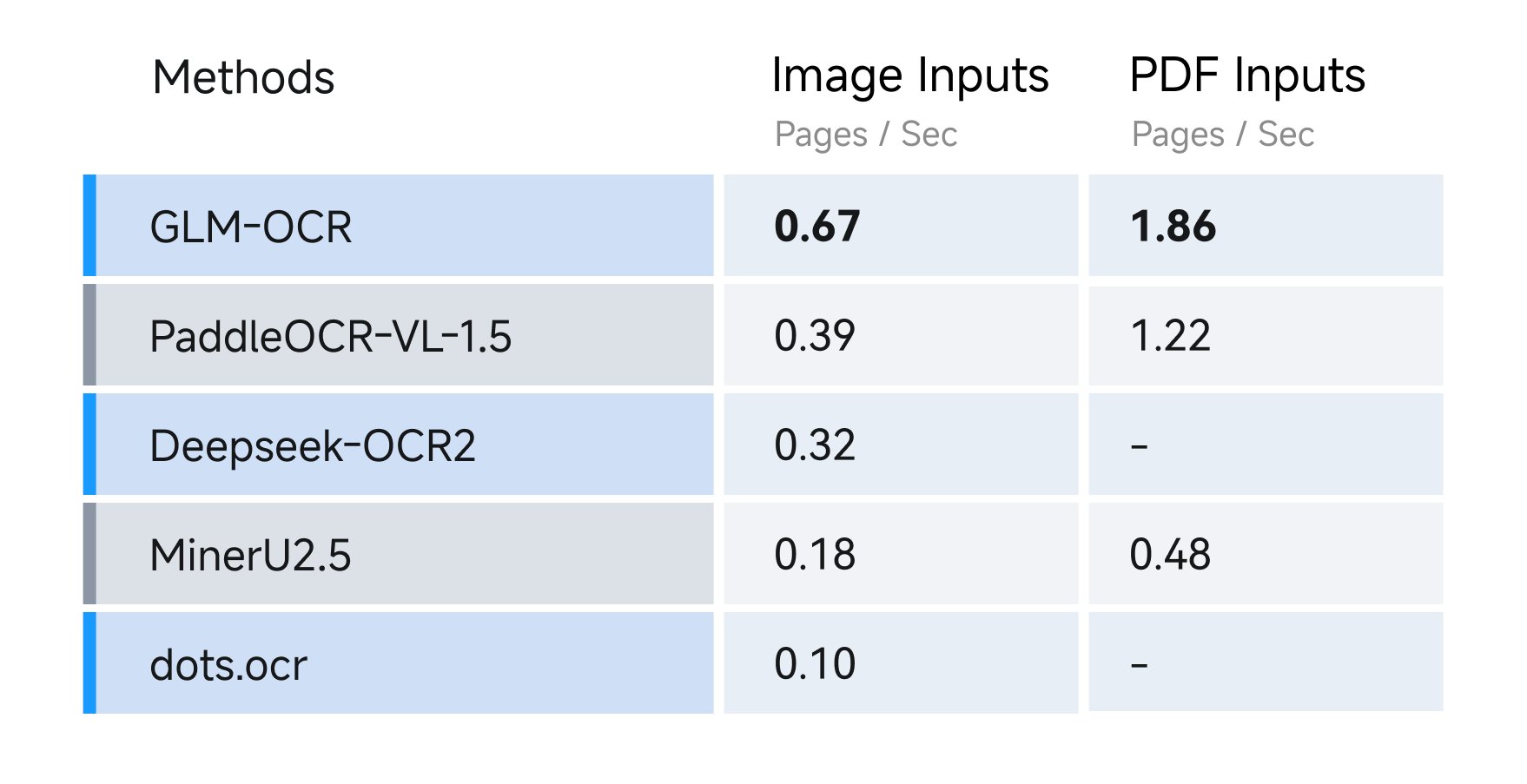
3. 高效且低成本 仅 0.9B 参数,支持 vLLM、SGLang 和 Ollama 部署,显著降低推理延迟和计算开销。处理 PDF 时吞吐量可达 1.86 页/秒,处理图片时为 0.67 张/秒,远超同类模型。API 定价统一,仅 $0.03/百万 tokens。
4. 易于使用,完全开源 提供完整的 SDK(支持 Python、Java)和推理工具链,安装简单,几行代码即可调用,方便快速接入生产环境。
主要用途
GLM-OCR 目前覆盖以下四个核心应用场景:
文本识别 — 识别照片、截图、文档、扫描件中的文本内容,支持印刷体、手书体和数学公式,适用于教育、科研和办公等场景。
表格识别 — 识别表格结构和内容,将其转换为 HTML 格式的序列输出,适用于表格数据录入、转换和编辑。
信息结构化 — 从各类卡证、Receipt、表单中提取关键信息,输出结构化的 JSON 数据,适用于金融、保险、政务、法律、物流等行业。
RAG(检索增强生成) — 支持大量文档的高精度识别和解析,输出格式标准化,为下游的 RAG 应用提供稳固的数据基础。
使用举例:
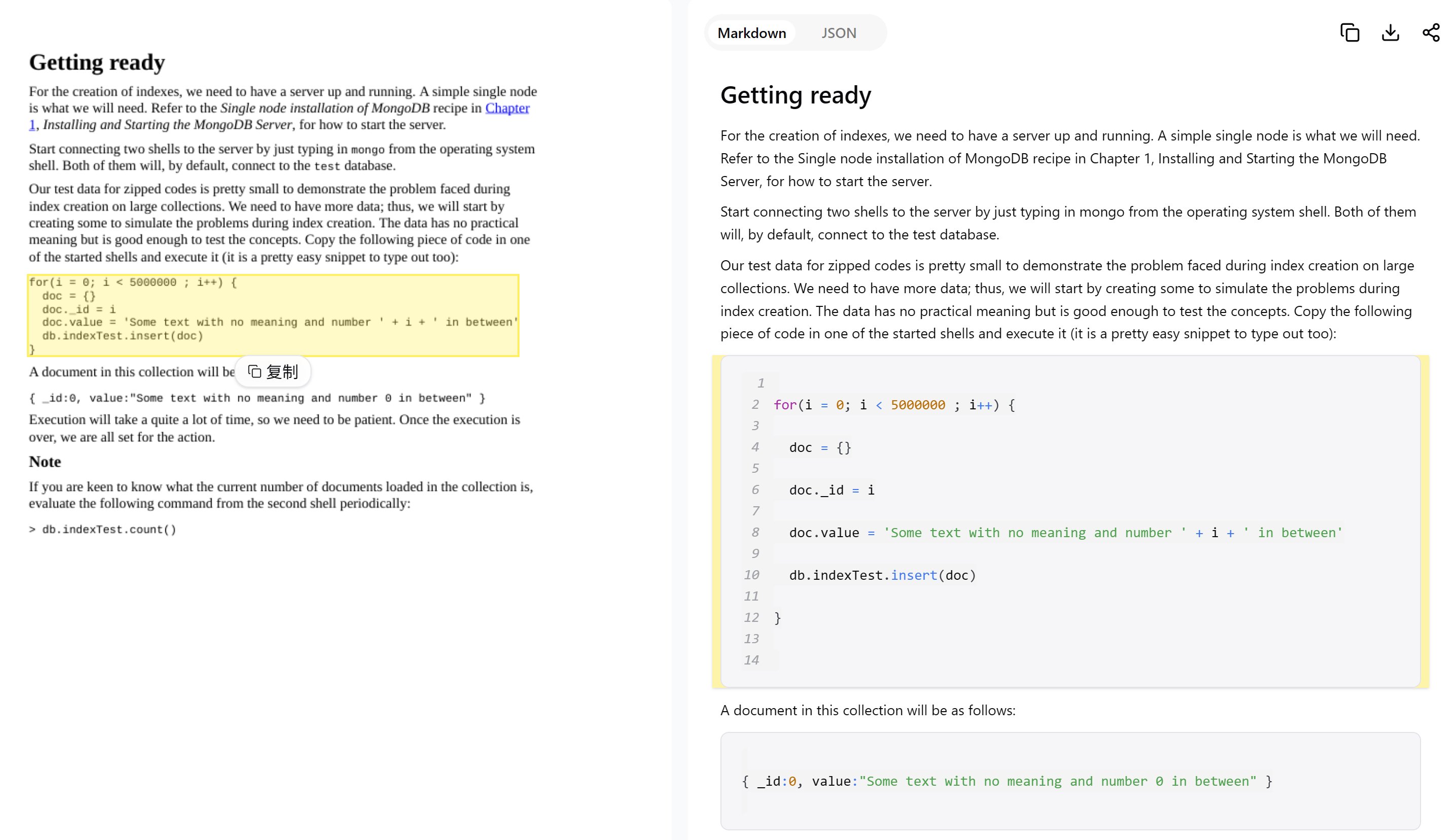
1. 代码块识别 从截图或文档图片中识别出代码内容,精确还原代码结构和语法,适用于开发文档的数字化。
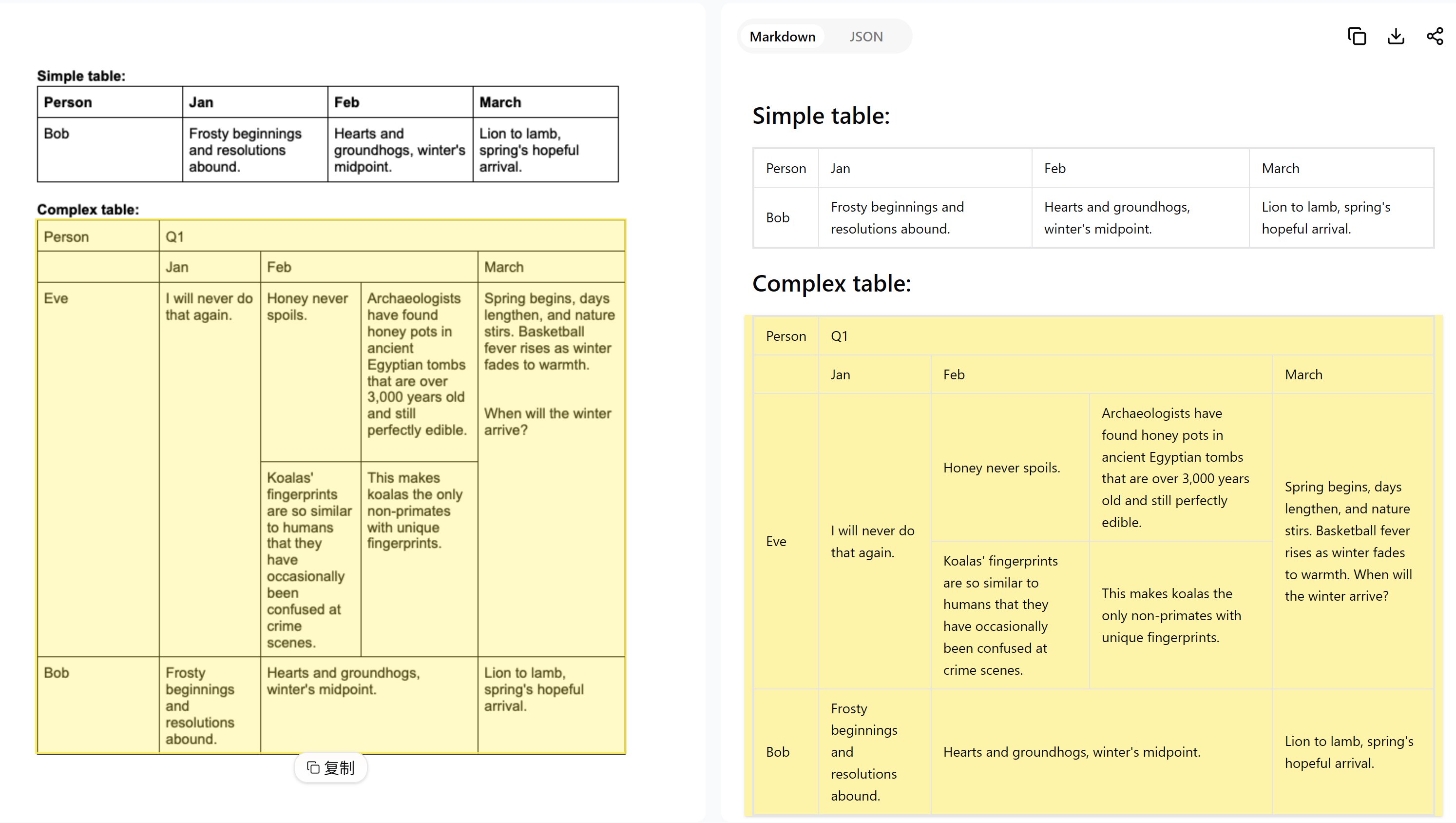
2. 复杂图表内容识别 能够识别复杂图表(如统计图、流程图等)中的文字和结构信息,适用于报告和分析文档的内容提取。
3. 账单识别 从账单、发票、收据等图片中提取关键信息(如金额、日期、商品名称等),并以结构化的 JSON 格式输出,适用于金融和财务场景。
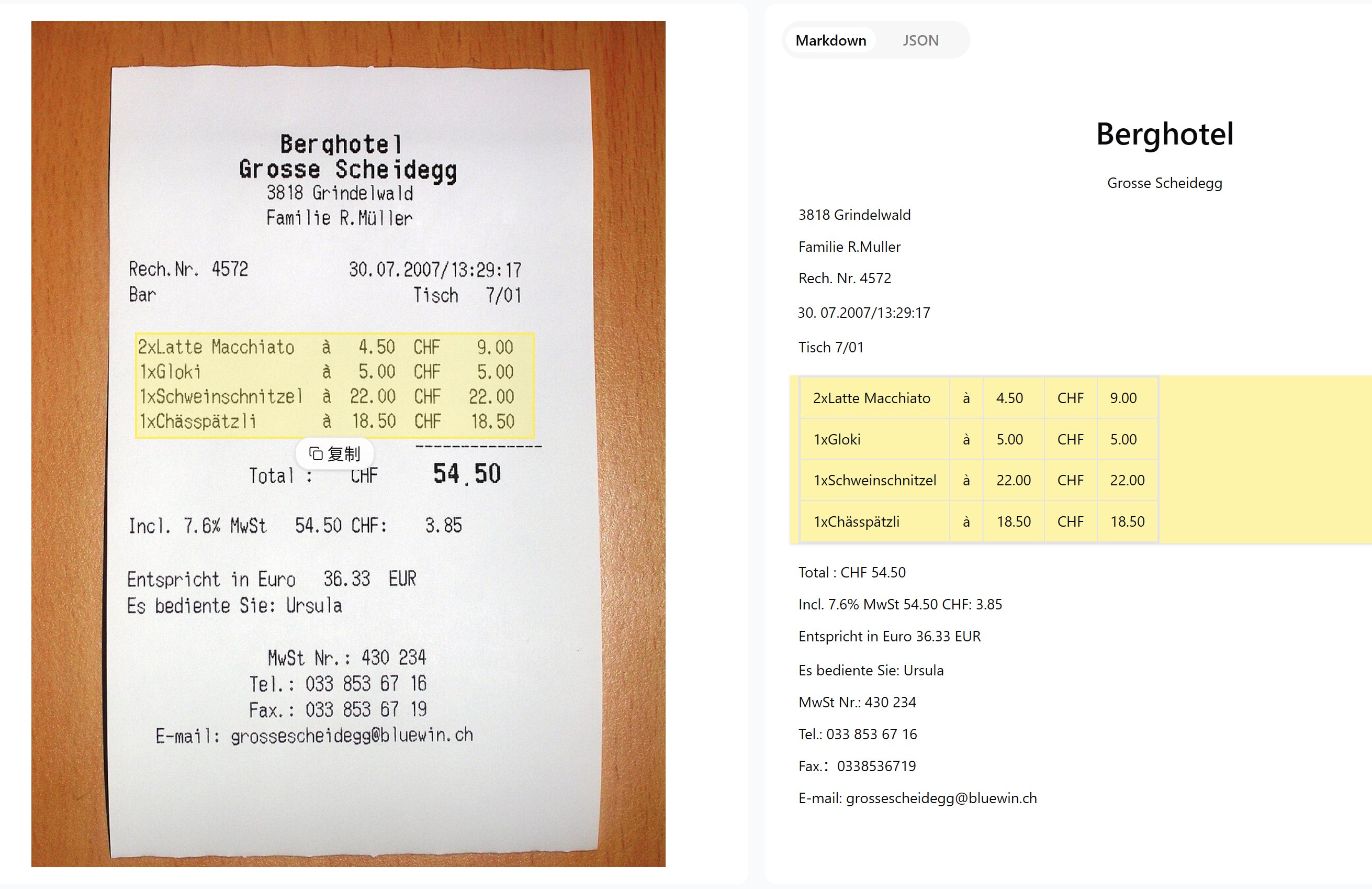
4. 手书体识别 能够识别手写内容,这对于很多 OCR 模型来说都是比较难的任务,GLM-OCR 在这方面也有不错的表现,适用于手写记录数字化的场景。

这四个例子基本覆盖了 GLM-OCR 在实际业务中的典型落地场景。
如果你想深入了解某个场景的用法,也可以参考 Z.AI 文档页面上的快速入门代码,几行就能上手试试。也可以通过 Ollama 直接在本地运行,由于模型非常小,本地运行也非常快。
参考链接
在线体验:
模型下载:
Ollama 模型:

关于作者
tony
某人