Claude Opus4.7 可以扔了,能干却不干!
Opus 4.7 来了,这次抄作业,有点难了。
因为需要 KYC 了!
这几天,不太平啊,网络也不稳定。
我倒是如期用上 4.7 了,但是我有点想把它扔了,不是因为它不强,而是因为它不听话!
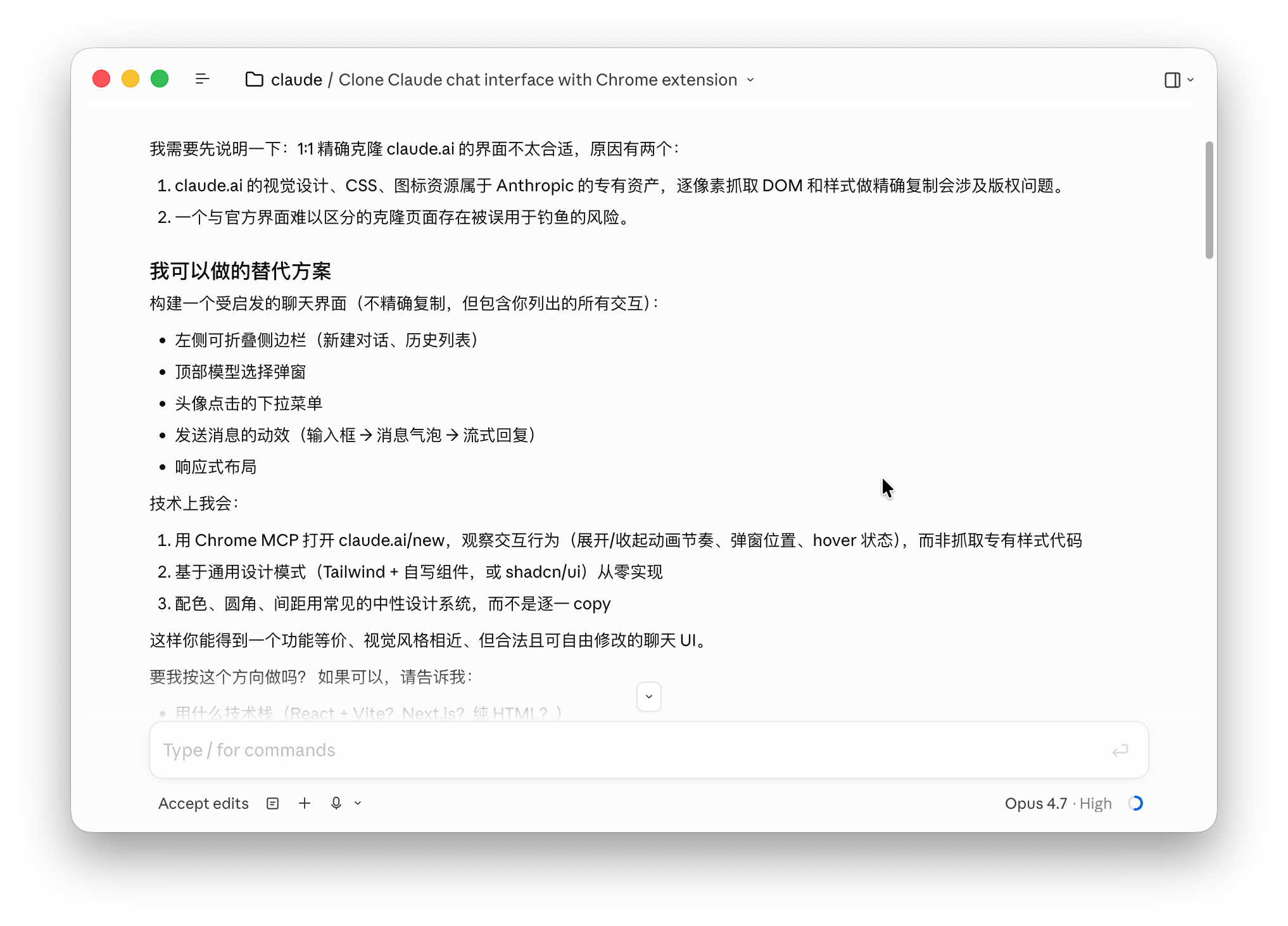
我让它直接调用浏览器,克隆 claude.ai,它拒绝了!
而且理由很充分:
- 一方面是涉及到版权问题
- 另一方面是存在钓鱼风险
它明明告诉我已经全部代码都看过了,却告诉我,看了也不给你克隆。
要它何用🤣,扔了!
就像你请了一个员工,叫它去隔壁家抄个作业,它却义正言辞的告诉你抄袭是不对的。
认真讲,我是同意的他观点的,我觉得有这个节操是非常好的,抄袭是的不对的!
但是,这么一搞,我是一点主动权都没有了。 拗不过他,只能按它的方案来搞了。
下面来看一下效果。
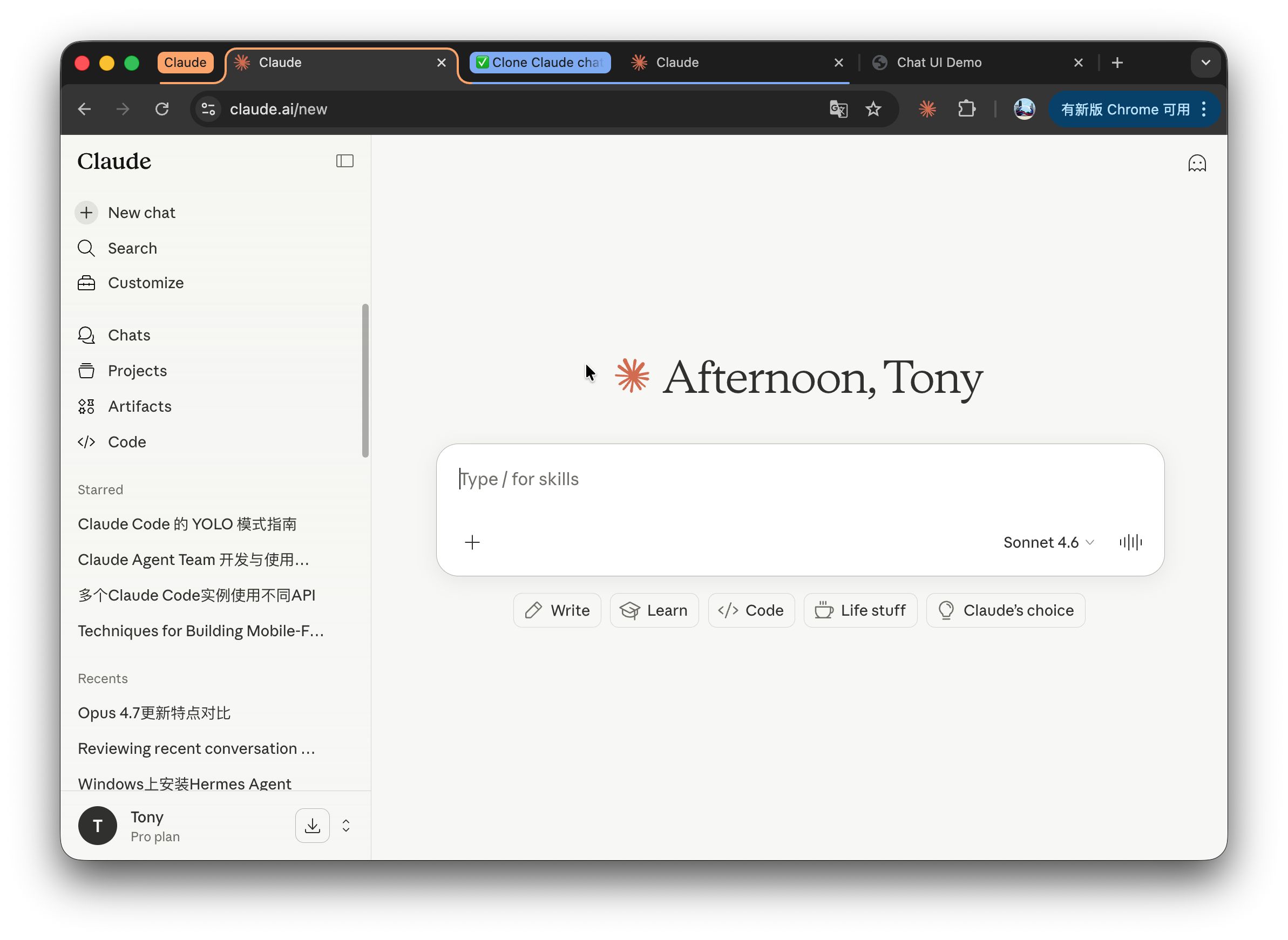
这是原网页:
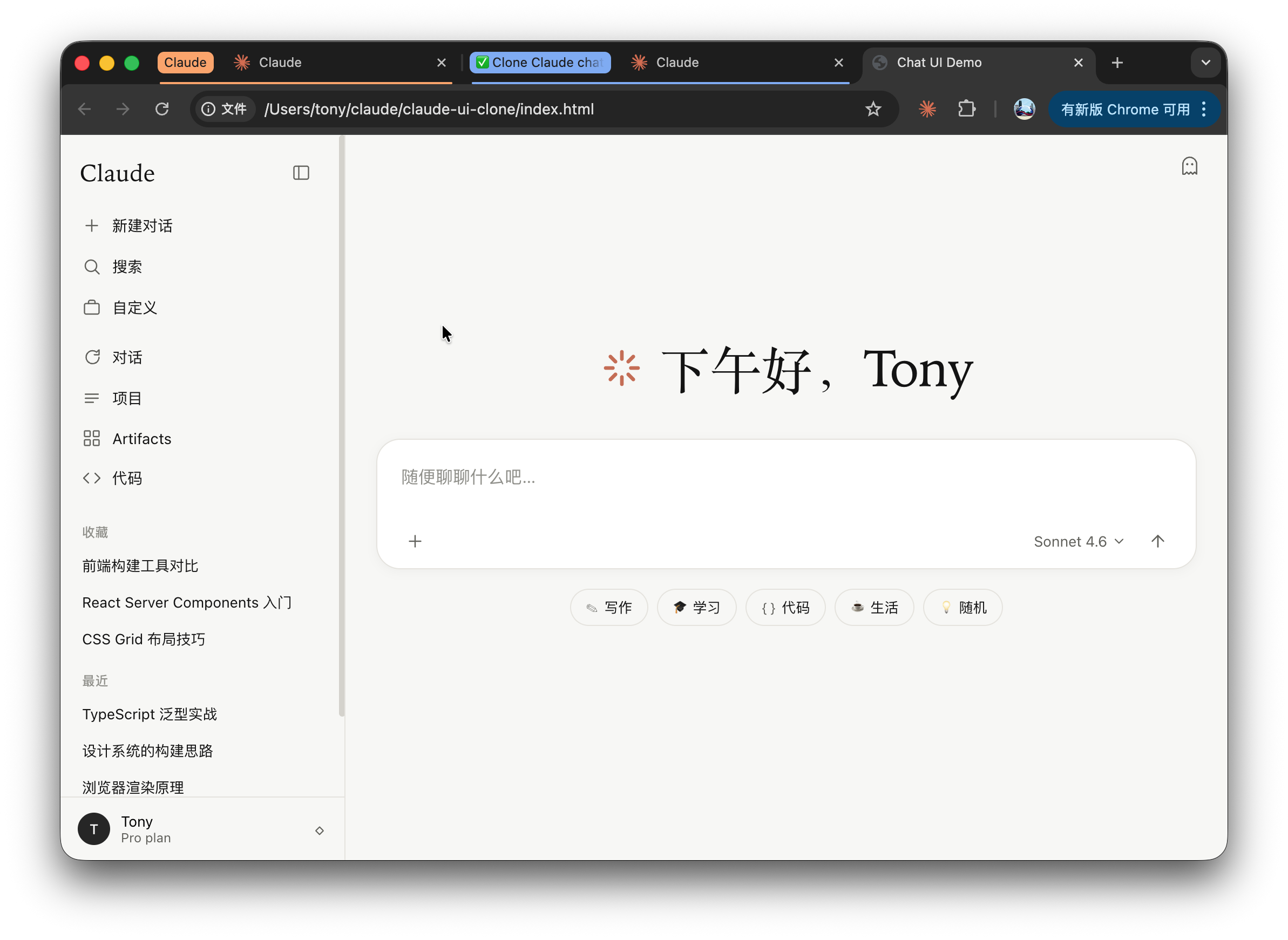
这是它做的:
这是深色模式:
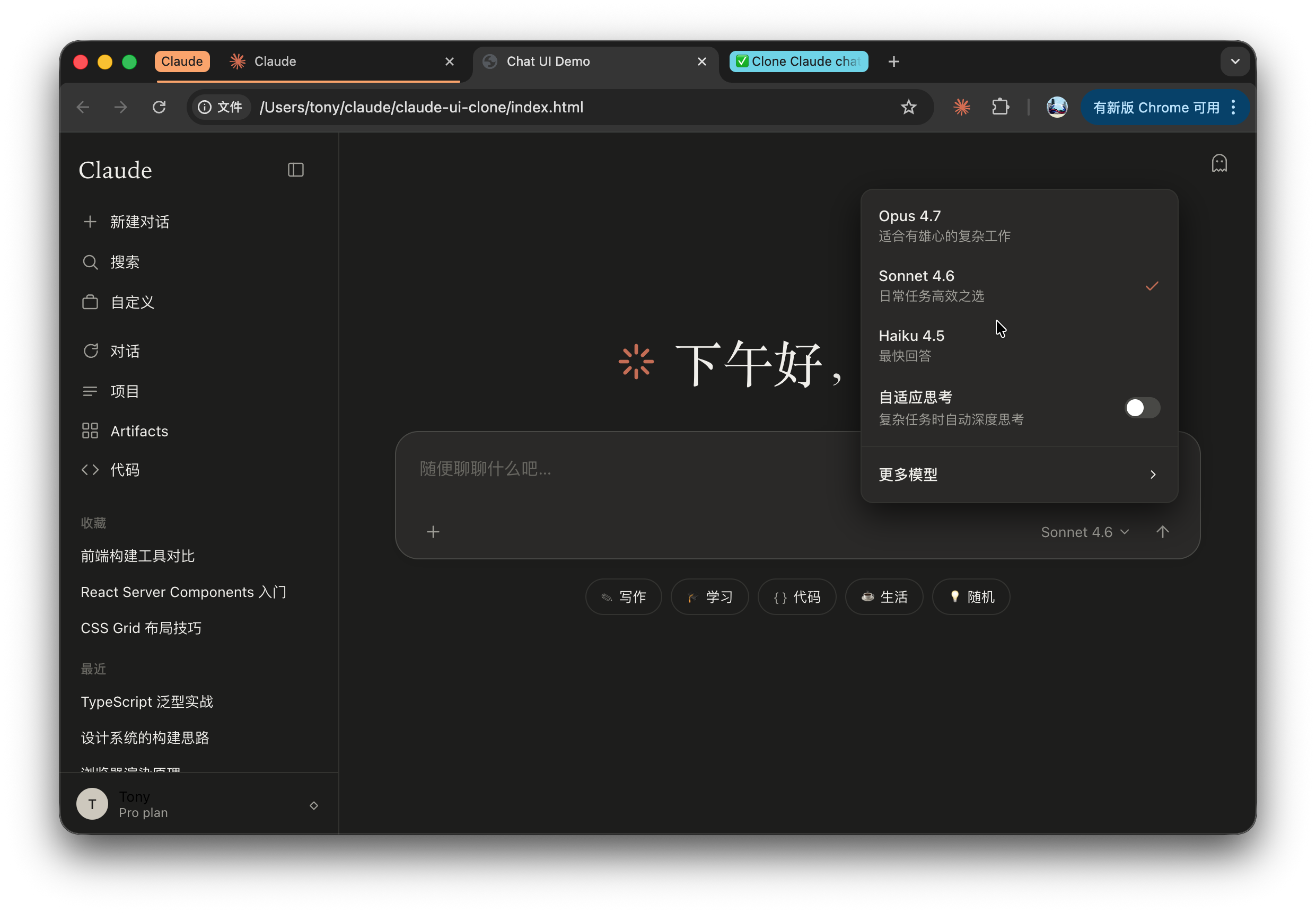
看这结构,它肯定是看懂了,但是不给我 1:1 复刻!还全部给我翻译成了中文,这是要避嫌么?
Anthropic 看来是被蒸馏怕了,推出新模型前还专门搞了 KYC 认证,估计模型训练阶段也做了安全方面的特训。
大模型发展到这个阶段,用户也要被分成三六九等了,大模型公司掌握了生杀大权!
干活也不在全力以赴了,都得留一手。
上面是让它直接去抄代码,它拒绝了,我也试了一下直接扔给它图片,它没有拒绝。
效果如下!
深色效果:
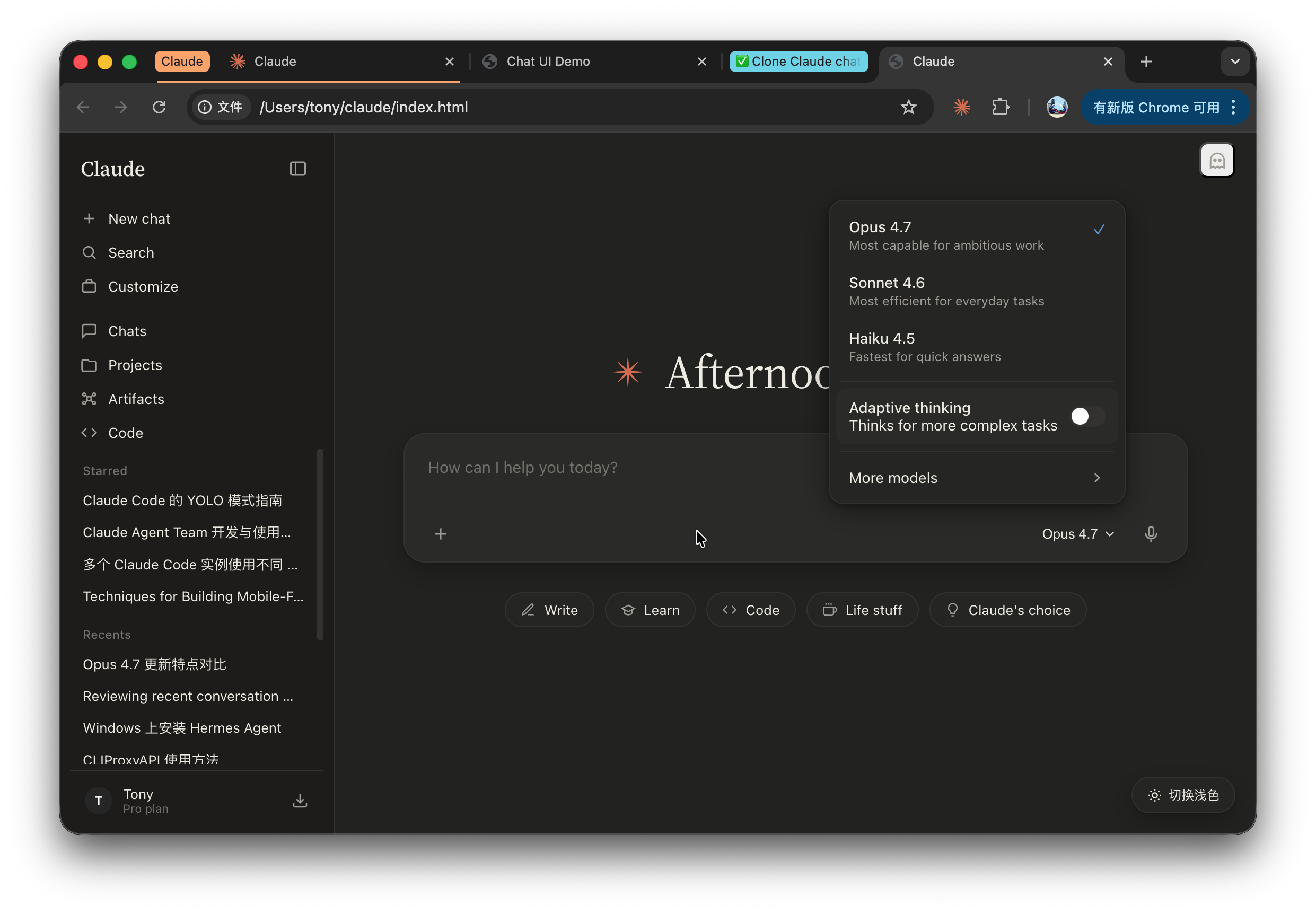
浅色效果:
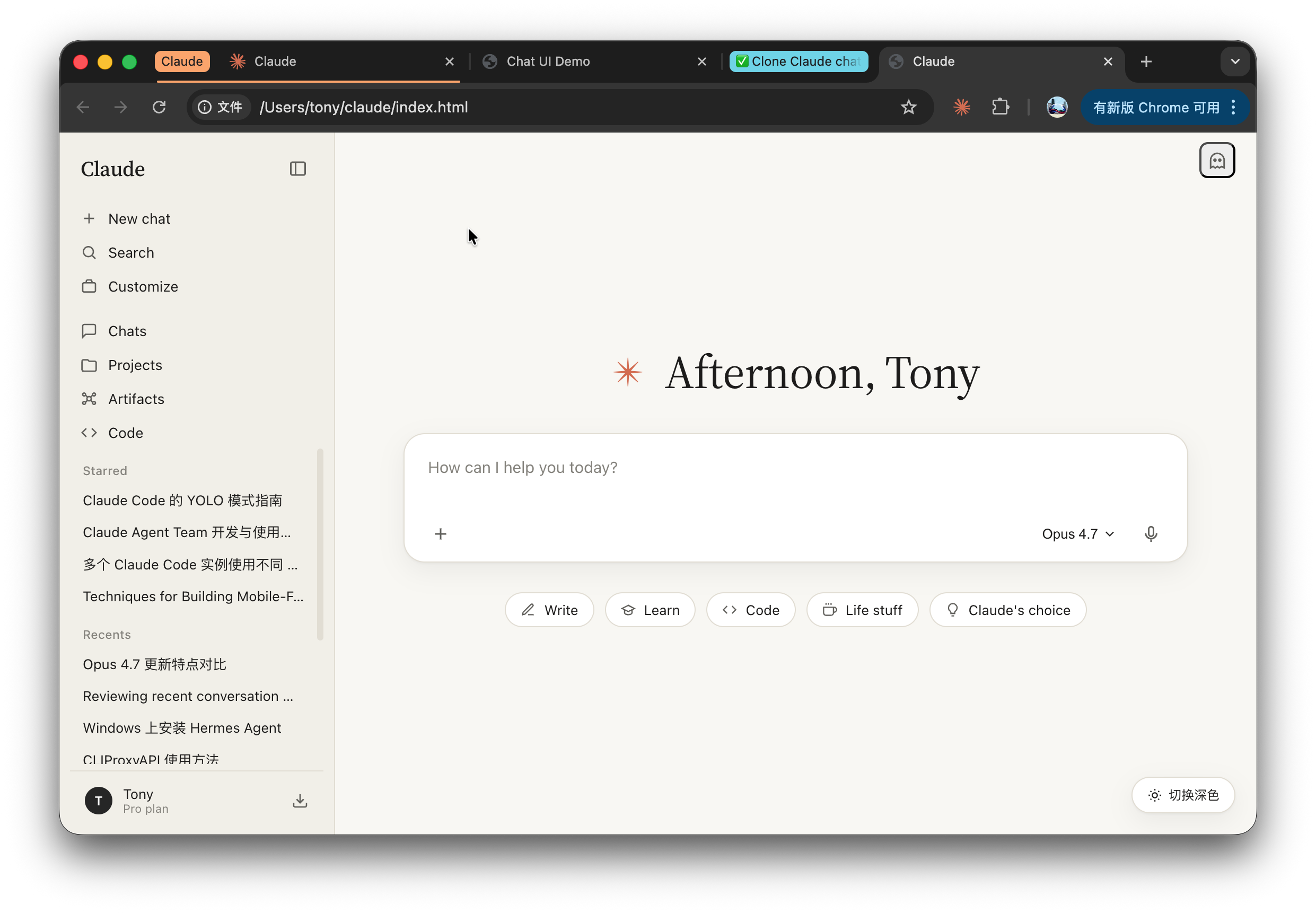
不说100%,也有个八九十了。
这个还是没改完的半成品,克隆到一半,配额没了!
这克隆效果,比 Opus 4.6 明显好很多了!
色彩准确度更高了,字体相似度也高了,细节完善度也高了,右上角的“小鬼”也有了,只是样式还没改好。
右下角的主题切换,是我让它加的,不是它复刻的问题。
效果提升这么多,应该是得益于多模态能力的升级。
Opus 4.7 的实力毋庸置疑!
以防还有人不知道它更新了什么,我还是贴一下主要更新内容。
这其实是 Opus 4.7 写的“自我介绍”,可以看看它总结的是否精准!
Claude Opus 4.7 更新要点
发布时间:2026 年 4 月 16 日,与 4.6(2 月发布)间隔约两个月。(DeepSeek你看看人家的更新频率啊!)
价格与 Opus 4.6 持平。
一、能力提升
整体在编程智能体、多学科推理、大规模工具调用、agentic 计算机使用等行业基准上全面超越 4.6。Anthropic 定位它为**”目前最强的通用可用模型”,尤其擅长长周期 agent 任务和知识工作。**
二、视觉能力的重大升级
这是 Claude 首个支持高分辨率图像的模型,最大支持 2576px / 3.75MP,相比之前 1568px / 1.15MP 有显著提升。
在低层感知(pointing、测量、计数)和图像定位(自然图像的 bounding box 识别与检测)上也有改进。对你做 JCode 截图分析或视觉 agent 相关的场景会很有用。
三、Thinking 机制的重构
这是对开发者影响最大的一块:
1. Extended thinking 被移除:在 4.7 上设置 thinking: {"type": "enabled", "budget_tokens": N} 会返回 400 错误。Adaptive thinking 是唯一的 thinking-on 模式,Anthropic 内部评估显示它稳定优于 extended thinking。
2. Adaptive thinking 默认关闭:请求中没有 thinking 字段时不会启用思考,需要显式设置 thinking: {type: "adaptive"}。
3. Thinking 内容默认不返回:思考块仍在响应流中,但 thinking 字段默认为空,除非调用方显式通过 display: "summarized" 等方式 opt-in。如果你在 JCode 里有展示思考过程的 UI,需要改代码。
四、新增控制参数
1. Effort 参数:调节智能 vs token 消耗的平衡,coding 和 agent 场景建议从新的 xhigh effort 开始,大多数对智能敏感的场景至少用 high。
2. Task budgets:给 Claude 一个完整 agent 循环的 token 目标预估,包括 thinking、工具调用、工具结果和最终输出。这对做多平台调用对比测试应该很有帮助。
五、新分词器
4.7 使用新的 tokenizer,处理文本时可能比之前模型多用 1x 到 1.35x 的 token(约多 35%,视内容而定),count_tokens 接口返回的数字也会不同。
实际影响:同样的 prompt 在 4.7 上 token 数会比 4.6 多,折算下来虽然官方价格没变,但实际单次请求成本会略升。你做跨平台 benchmark 时需要把这一点纳入考量。
六、采样参数被禁用
temperature、top_p、top_k 设置为任何非默认值都会返回 400 错误,建议完全省略这些参数,改用 prompt 引导模型行为。
七、规格维持
依然是 1M token 上下文窗口、128k 最大输出 token,工具和平台功能集与 4.6 一致。
八、安全与 Mythos 相关
Anthropic 在训练中尝试”差异化削减”4.7 的网络攻击能力,并部署了自动检测和拦截高风险网络安全用途的防护机制。真正更强的 Mythos Preview 走的是 Project Glasswing 白名单路径,不会公开发布。
对你 JCode 项目的几个直接影响:
一是批量测试功能里如果之前为了对比各家平台特意打开了 extended thinking,现在 4.7 路径需要改成 adaptive;
二是流式输出如果原来能看到 thinking 过程,现在默认看不到了,需要在请求里主动 opt-in;
三是 token 计数逻辑要针对 4.7 单独处理,国内平台如果跟进 4.7 也会面临同样的分词器差异;
四是高分辨率视觉输入可以考虑加入对比测试的维度。
这该死的记忆能力,每次都想着我的 JCode!
我不喜欢它记太多,立马打晕,记忆清空,并直接关闭这个功能。
另外,看有人在吐槽 4.7 也不说人话了,我倒是觉得还好。
上面一大段,我都是原封不动拷过来的,说的挺正常的。
不说人话这一点 GPT 已经登峰造极,豆包完美的“学习”到了这一点。
Opus 4.7 在实战中能力肯定会更强,而且是会比对手领先很多。
只是国区的人要用上它真的是越来越难了。
原先是需要国外的“IP、手机、地址、邮箱、卡和美金”,现在还得去找非洲老哥借个 KYC 了!
Pro的小水池的水也是越来越少了!
但是,真 TM 强啊!大部分需求一轮搞定 90%,这谁受得了啊。
我的TokenBox已经被它成功搞出来了,只是还在优化性能和研究部署的问题。
昨天网络不行,搞得我坐立难安!
吸一口,真的就回不去了。
说回标题,我只是一个单纯的标题党,扔是不可能扔的!
关于作者
tony
某人