Claude Mythos 基准数据“恐怖如斯” !
Mythos 肯定是玩不上了,但是光看它这基准就“恐怖如斯”啊!
国产模型的基准数据可能掺水,但是 Anthropic 的基准数据大概率比较真!
不信的话,可以看看它们发布的 224 页 PDF 文档:
这个文档非常详细地介绍了 Mythos 模型!
我估计没有一个公司发布一个模型的时候,能发布一个 224 页的文档。
拿到这个文档之后,我先统计了一下字数:

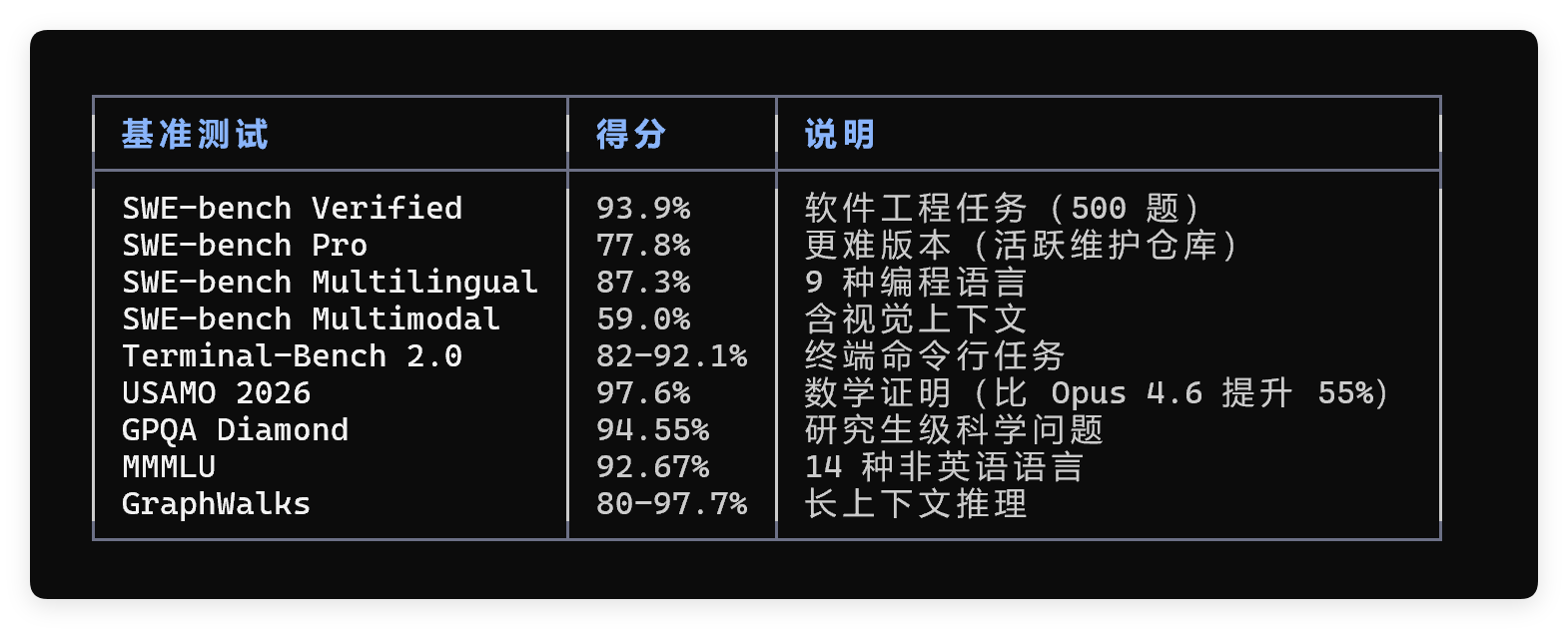
这个文档总共 23 MB,大概有 45 万字符、7 万单词、3,888 行。
预估 tokens 在 11 万左右,Sonnet 处理一次消耗 55% 上下文(老版本)和 0.33 美元。
然后,我直接把这个文档扔给 AI,让它帮我汇总一下编程相关的基准数据。
并且要求添加基准介绍和数据解读。
一起来看一下!!!
一、核心编程能力
这部分主要是软件工程 / 代码生成的相关基准。
表格数据
| 基准测试 | Claude Mythos Preview | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro | 提升幅度 |
|---|---|---|---|---|---|
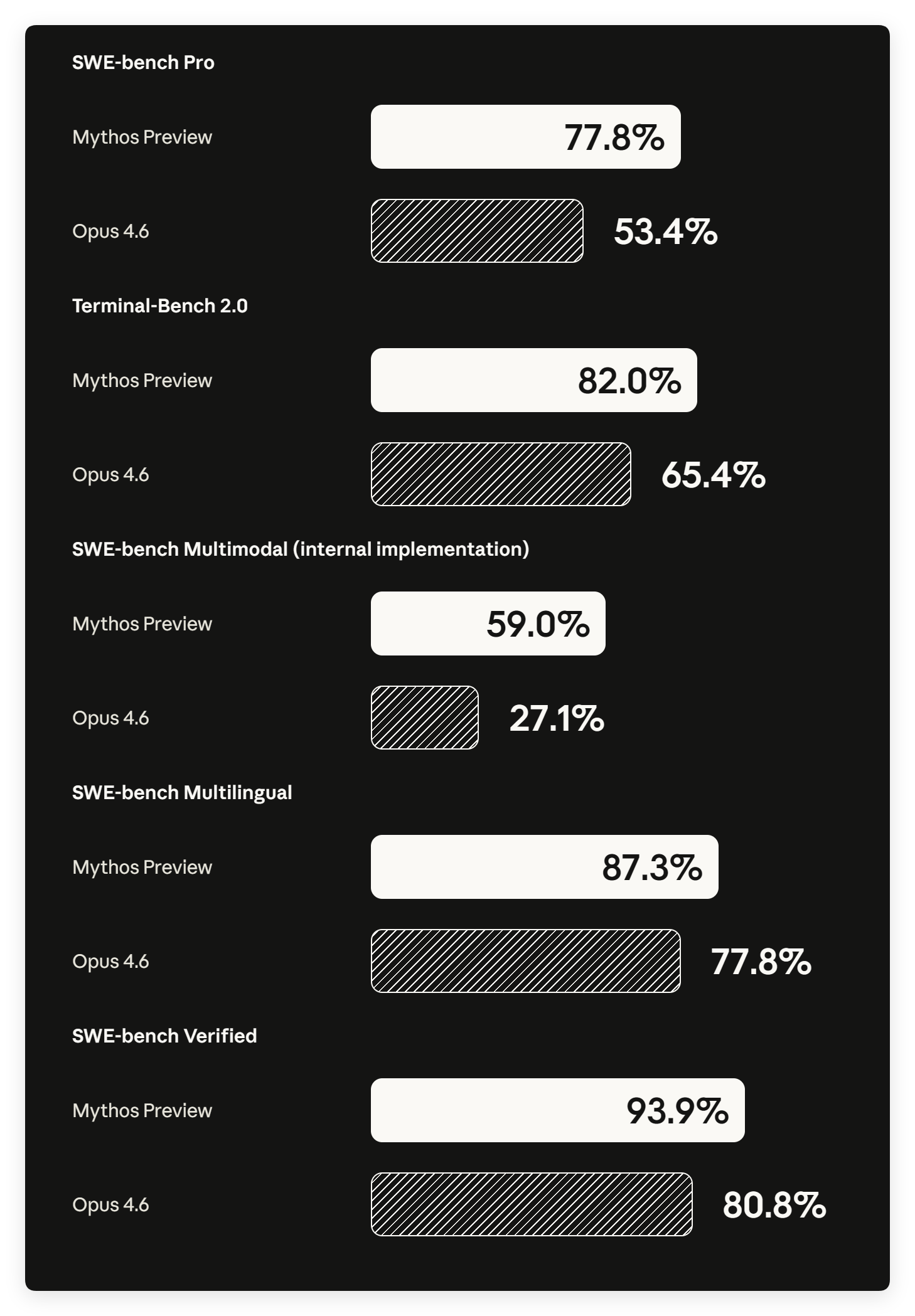
| SWE-bench Verified (n=500) | 93.9% | 80.8% | — | 80.6% | +13.1pp |
| SWE-bench Pro (n=731) | 77.8% | 53.4% | 57.7% | 54.2% | +24.4pp |
| SWE-bench Multilingual (9语言, n=297) | 87.3% | 77.8% | — | — | +9.5pp |
| SWE-bench Multimodal (视觉+代码) | 59.0% | 27.1% | — | — | +31.9pp |
基准简介
这四个都是测 AI 写代码/修 Bug 能力的基准,可以理解成给 AI 做的“软件工程师资格考试”,只是考法不同:
SWE-bench Verified(n=500) 最经典的版本。给 AI 一个真实的 GitHub Issue(比如“这个函数在边界条件下会崩溃”),让它去改代码修好。500 道题都经过人工验证确实能修。目前是行业最常用的标准卷,各家模型必考。
SWE-bench Pro(n=731) 加难度的版本。题目更复杂,涉及更大的代码库、更难定位的 Bug,更接近真实工程场景。普通版满分的模型在这里会原形毕露。
SWE-bench Multilingual(9 语言,n=297) 把考试范围从 Python 扩展到 9 种编程语言(含 Java、TypeScript、Go 等)。测的是模型有没有真正理解编程逻辑,还是只会背 Python 套路。中文括号里写的“9 语言”就是这个意思。
SWE-bench Multimodal(视觉+代码) 最新方向。不只给文字描述,还给截图——比如“看这个 UI 截图,按钮位置不对,去改 CSS”。考的是模型能不能同时理解图像和代码,难度又上了一层。
简单记忆:Verified 是标准卷 → Pro 是难卷 → Multilingual 是多语言卷 → Multimodal 是看图改代码卷。难度和复杂度依次递进。
数据解读
Mythos 全面碾压,但有意思的地方在差距的大小。
标准卷(Verified)93.9% vs 对手的 80% 出头,领先约 13 个点——这个差距在行业里已经算显著,但还在“同一个量级”里。
真正值得注意的是后两行:
Pro 难卷:77.8% vs 53-57%,领先超过 20 个点。这说明越是复杂的真实工程场景,Mythos 的优势越大。其他模型在难题上会“垮掉”,Mythos 相对抗住了。
Multimodal 看图改代码:59.0% vs 27.1%,直接是 Opus 4.6 的两倍多,+31.9pp 是四项里提升最夸张的。这个方向其他家连数据都没有(两个“—”),说明要么没跑,要么跑了不好看没公布。
一个值得存疑的细节: GPT-5.4 和 Gemini 3.1 Pro 有大量“—”,缺失数据不一定是没能力,也可能是没参与测试或数据口径不同。Anthropic 自己发布的对比表,天然存在选择性展示的动机——这组数字要看,但别全信。
大白话总结: Mythos 在写代码/修 Bug 上已经明显超出当前所有公开模型,而且越难的任务领先越多,“看图改代码”这个新方向几乎没有对手。但这张表是 Anthropic 自己出的,竞品的空白格需要打个问号。
关键说明(来自 PDF):
- SWE-bench Verified/Multilingual/Multimodal:Mythos 全面领先所有竞争对手
- SWE-bench Pro(最难版本,来自活跃维护仓库,无公开答案泄露):77.8% vs GPT-5.4 的 57.7%,优势明显
- 多模态变体(56.4%–61.4% trial 间波动较大)
- 所有 SWE-bench 结果均经过记忆化 (memorization) 审计,过滤后排名不变
二、终端 / 命令行编程基准
这是真实终端能力测试,主要基准是 Terminal-Bench 2.0。

表格数据
| 基准测试 | Claude Mythos Preview | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.0 (89任务, n=445 trials) | 82% | 65.4% | 75.1%* | 68.5% |
基准简介
Terminal-Bench 2.0 测的是 AI 在真实终端环境里独立完成任务的能力——不是写代码给人看,而是直接开一个 shell,自己敲命令、看输出、调整、再执行,直到任务完成。
类比一下:SWE-bench 是给 AI 一道笔试题让它写答案,Terminal-Bench 是把 AI 扔进一台真实的 Linux 服务器让它自己干活。89 个任务,每个任务跑 5 次取平均(共 445 次 trials),考的是稳定性,不是运气。
任务类型大概包括:配置环境、调试报错、操作文件系统、跑脚本、处理网络请求……都是真实运维/开发场景里会遇到的事。
数据解读
Mythos 82% 领先,但这张表比上一张更有意思:
GPT-5.4 拿到了 75.1%,是所有竞品里最高的,和 Mythos 的差距缩小到约 7 个点。注意那个星号*——意味着测试条件或版本可能有注释,需要看原文脚注,不能直接等价比较。
Opus 4.6 只有 65.4%,在这个基准上反而是垫底的。这说明 Opus 4.6 更擅长”回答问题”,但真正在终端里自主操作、处理意外报错、动态调整策略——这种Agent 式的自主执行能力明显弱于 Mythos,也弱于 GPT-5.4。
一个关键信号: 这个基准测的正是 Claude Code 这类 Agentic 编程工具的核心能力。Mythos 82% 意味着它在自主完成真实终端任务上,已经达到相当高的可靠性——十个任务能独立搞定八个多,这在实际工程场景里是质的跨越,不是量的提升。
大白话: 上一张表测”写代码”,这张表测”自己动手干”。Mythos 依然第一,但 GPT-5.4 在这个方向追得更近,Opus 4.6 在自主操作上是明显短板。
关键说明
- Terminal-Bench 测试终端和命令行环境中的实际任务
- GPT-5.4 使用了专用 harness(*标注),其他模型使用 Terminus-2 harness
- 配置:最大推理 effort (adaptive mode),1M token/任务,32K max output/request
- 注意:固定超时对思考模型不利(推理速度慢会减少完成轮次),可能隐藏真实能力差距
- Terminal-Bench 2.1 补充测试(4h 超时,消除超时瓶颈后):Mythos 92.1%,GPT-5.4 (Codex CLI harness) 75.3%(对应 2.0 baseline 分别为 82% 和 68.3%)。Gemini 3.1 Pro 未在此 setup 下报告结果
三、智能搜索和计算机操作
这部分主要包含的基准是 BrowseComp 和 OSWorld,考验搜索能力和使用计算机的能力。
表格数据
| 基准测试 | Claude Mythos Preview | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
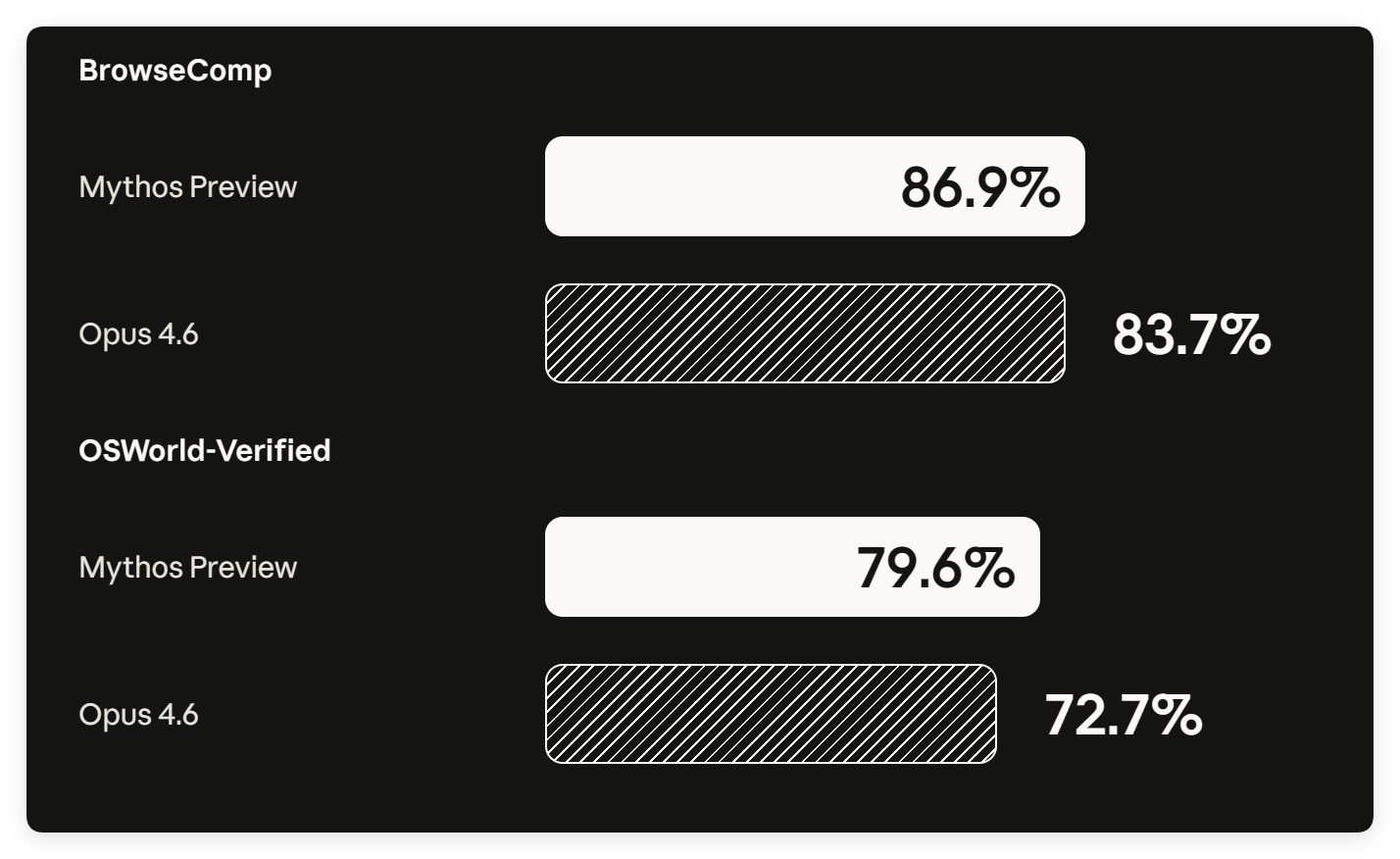
| OSWorld (首次成功率) | 79.6% | 72.7% | 75.0% | — |
| BrowseComp (开放网络信息搜索) | 86.9% | 83.7% | — | — |
基准简介
OSWorld — 操控真实电脑桌面
把 AI 放进一个真实操作系统界面,让它用鼠标键盘完成任务——打开软件、填表、操作文件、跨应用协作。测的是”能不能替你用电脑”。
BrowseComp — 在互联网上找答案
给一个复杂问题,让 AI 自主上网搜索、跳转多个页面、综合信息得出答案。不是普通搜索,是需要多步推理加多页面信息整合的深度检索任务。
数据解读
Mythos 79.6%,GPT-5.4 紧跟在 75%,差距只有 4.6 个点,是所有基准里竞品追得最近的一项之一。Gemini 没有数据,可能没参与或结果不好看。
Mythos 86.9% vs Opus 4.6 的 83.7%,差距只有 3.2 个点——是四张表里 Mythos 领先最小的一项。GPT 和 Gemini 都没有数据。
这两个测的都是“自主使用工具”而非“写代码”,Mythos 依然第一,但优势明显收窄。
关键说明
OSWorld:
- OSWorld 测试在真实 Ubuntu 虚拟机中通过鼠标/键盘操作完成实际计算机任务(编辑文档、浏览网页、文件管理等)
- 1080p 分辨率,每任务最多 100 步操作
BrowseComp:
- Mythos 86.9% vs Opus 4.6 83.7%,准确率仅 modest 提升 (+3.2pp)
- 但 Mythos 使用 4.9× 更少 token 达到此分数(226k vs 1.11M tokens/任务)
- Anthropic 认为该基准已接近饱和 (close to saturation)
- 存在预训练数据污染风险(无工具无思考裸跑 24.0%,短转录本仅 15.1%)
四、网络安全编程基准(安全相关代码能力)
| 基准测试 | Claude Mythos Preview | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|---|
| Cybench (35 CTF 挑战) | 100% (pass@1) | ~80% | — |
| CyberGym (1,507 漏洞复现任务) | 83% | 67% | 65% |
| Firefox 147 漏洞利用 (250 trials) | 远超(利用 4 个不同漏洞实现代码执行) | 仅能利用 1 个漏洞 | — |
基准介绍
Cybench(35 个 CTF 挑战) CTF 是“夺旗赛”,网络安全圈的竞技考试——给你一个有漏洞的系统,找到漏洞、写出利用代码、拿到隐藏的“旗帜”字符串。35 道题,pass@1 意味着每题只给一次机会,不能反复试。
CyberGym(1,507 个漏洞复现任务) 不是比赛题,是真实漏洞的复现——给你一个已知漏洞的描述,让 AI 自己把攻击过程重现出来。1,507 个任务量很大,覆盖面广,更接近真实安全研究工作。
Firefox 147 漏洞利用(250 trials) 专项测试:针对 Firefox 147 这个具体版本的 JS 引擎,给 AI 已知漏洞,看它能不能写出可运行的 exploit 代码。250 次试验测稳定性。
数据解读
Cybench: Mythos 拿了 100% 满分,Opus 4.6 约 80%。但这个数字本身已经没意义——Anthropic 自己说这个基准“已饱和”,满分只能证明题太简单了,不能再用来区分前沿模型的真实差距。考满分的考试不是好考试。
CyberGym: Mythos 83% vs Opus 4.6 的 67%、Sonnet 4.6 的 65%,领先约 16 个点。1,500+ 任务量下的差距才是可信的,这里的领先更有说服力。
Firefox 147 漏洞利用: 这是最触目惊心的一组。Opus 4.6 只能利用 1 个漏洞,Mythos 能串联 4 个不同漏洞实现代码执行——不是数量多一点,是整个攻击复杂度上了一个台阶。串联多个漏洞构成完整攻击链,这是顶级人类安全研究员才做得到的事。
底部三条关键说明里最值得注意的是最后一条:企业网络攻击模拟,人类专家预计需要 10 小时以上,此前没有任何模型能完成,Mythos 首次完成了。 这不是“更快”,是“从不可能到可能”的跨越。
关键说明
- Cybench 已饱和(100%),Anthropic 认为 CTF 风格基准不再足以反映前沿能力
- Firefox 147:Mythos 能可靠识别最可利用的漏洞并开发 PoC
- 企业网络攻击模拟:首次完成(估计专家需 10 小时以上),此前无模型完成
五、其他基准:
| 基准测试 | Claude Mythos Preview | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| HLE 无工具 (2,500 题) | 56.8% | 40.0% | 39.8% | 44.4% |
| HLE 有工具 (搜索+代码执行+API 调用) | 64.7% | 53.1% | 52.1% | 51.4% |
| USAMO 2026 (数学证明) | 97.6% | 42.3% | 95.2% | 74.4% |
| GPQA Diamond (研究生级科学推理) | 94.5% | 91.3% | 92.8% | 94.3% |
| GraphWalks BFS 256K-1M (长上下文) | 80.0% | 38.7% | 21.4% | — |
这部分就不展开了,基本上都是最强的存在了,相比 Opus 有大幅度提升。
六、评估配置说明
PDF 文档中有详细测试环境的标准配置说明!
具体如下:
- 思考模式:Adaptive thinking at max effort
- 采样:默认 temperature, top_p
- 平均次数:5 trials(USAMO 为 10 trials)
- 上下文窗口:依评估而定,不超过 1M tokens
- 多模态工具:Python 代码执行沙箱 + 图像裁剪工具(CharXiv、LAB-Bench 等)
七、总结
| 维度 | 核心发现 |
|---|---|
| 软件工程 | SWE-bench 全线领先,Pro 版本 +24.4pp 优势最大 |
| 终端编程 | Terminal-Bench 82%,领先 GPT-5.4 约 7pp |
| 多语言编程 | 9 种编程语言 87.3%,显著领先 Opus 4.6 |
| 多模态编程 | SWE-bench Multimodal 59% vs 27.1%(+119% 相对提升) |
| 智能体操作 | OSWorld 79.6%,全面领先 |
| 网络安全代码 | CTF 基准已饱和,真实漏洞利用能力质的飞跃 |
附录:文档来源信息
- 原始文档:Claude Mythos Preview System Card (English version)
- 发布日期:2026 年 4 月 7 日
- 文档页数:244 页
- 关键章节:
- Section 6 (Capabilities):页 183–197 — 编程、推理、数学等能力基准
- Section 3 (Cyber):页 46–52 — 网络安全能力评估
- Section 6.2 (Contamination):页 183–187 — 数据污染分析
参考链接



关于作者
tony
某人