测一测“国产最强”模型Qwen 3.6 plus!
今天的研究对象是 Qwen 3.6 Plus!
我挺喜欢的 Qwen 系列,因为它们在开源方面做得很好啊!
但是我非常不喜欢有些人或者媒体在我面前瞎吹!
Qwen 3.6 Plus 已经有这个苗头,看到好多“国产最强”的描述了。
我发现现在大媒体也是闭眼吹,只要看到有“最”字的评价全部可以忽略。
我在分享白嫖qwen3.6的四种方式的时候,官方还没有发文,也没有任何资料。
今天基准数据都出来了:
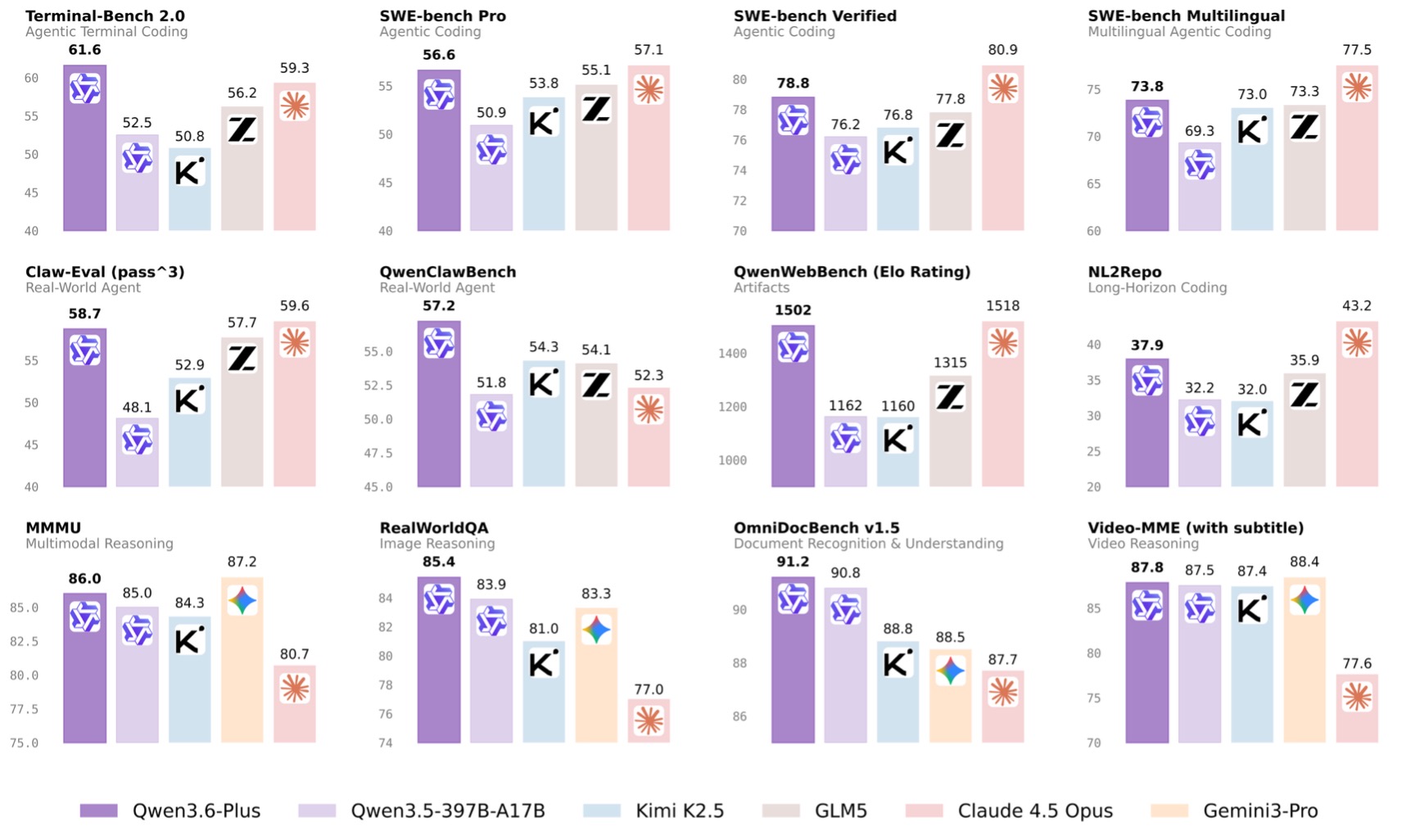
有点雷式对比法的意思了。
看起来确实好强啊,国产模型全部被碾压了!
如果比优势基准数量的话,和 Opus4.5 也能五五开。
我们都知道论跑分,国产模型就没怎么输过。
今天我就来实测一下,看它到底有几斤几两。
既然已经宣传国产最强了,简单的智力题,网页开发这种就直接跳过了!
这种题目,在当前,已经很难区分出强弱了,哪个模型不能做网页?
既然是编程最强的模型,我们直接上项目,搬出 JarvisBench!
老粉应该很熟悉了,我已经用这个项目把国内外的模型都测了个遍,好多国产模型,及格分都到不了。
为了照顾新人,我还是简单介绍一下我这个测试项目。
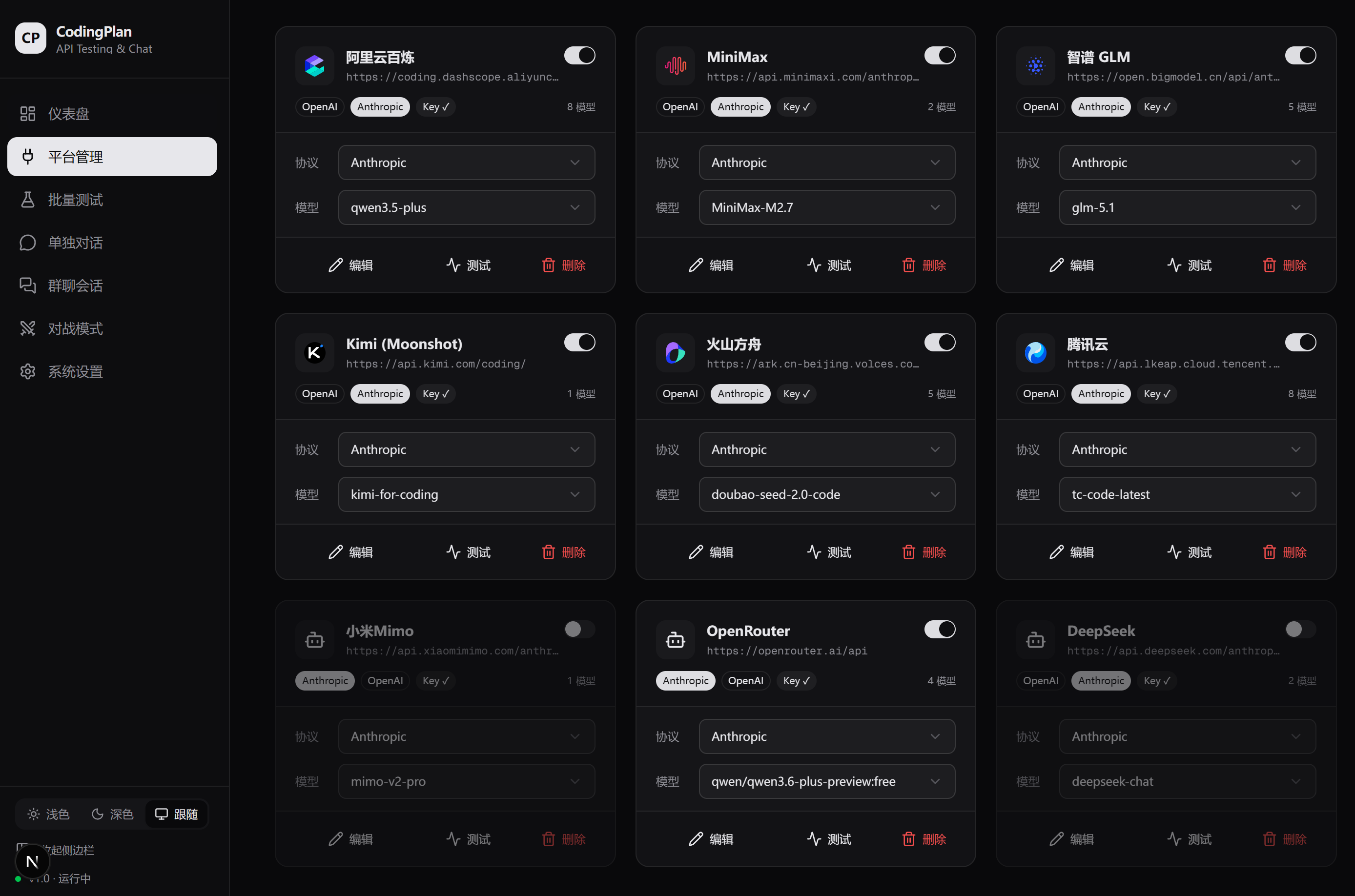
年初,我买了国内 6 大平台的 CodingPlan,为了测试出不同平台的真实水平和差异。我就自己开发了一个 CodingPlan 的测试平台。在开发过程中遇到了一些问题。我就把这个问题独立出来当做测试环节了。
这个测试项目,有几个特点:
- 有一定的上下文基础,大概有 8,000 行
- 涉及到数据结构的修改和老数据升级
- 涉及到业务逻辑的修改。
- 涉及到多个功能页面的修改
所以这并不是单纯的页面设计,页面完全不是重点,重点是对业务逻辑的理解。
所以这个例子,有一定的难度。但是也不算特别难,实际开发过程中,比这个难度的系统多的是。
测试场景说清楚了。我们就可以来看结果了。
测试,我已经做好了,花了一个上午的时间。
结果嘛,基本上可以概括为:
能力有所提升,没有运行错误,但是开发过程和业务逻辑一片混乱!
国产最强?Opus 笑而不语,暗示先去问问 GLM5 吧!
参考这一篇:《我超!GLM-5-Turbo有点东西啊!》
下面我给大家看一下具体的结果。
然后我会按 能不能用、好不好用、全不全面 等维度来做评判。
能不能用?
这部分重点是测试能不能正常启动,有没有明显的代码错误。
找到 Qwen3.6 的项目,直接输入命令 npm run dev 启动项目:
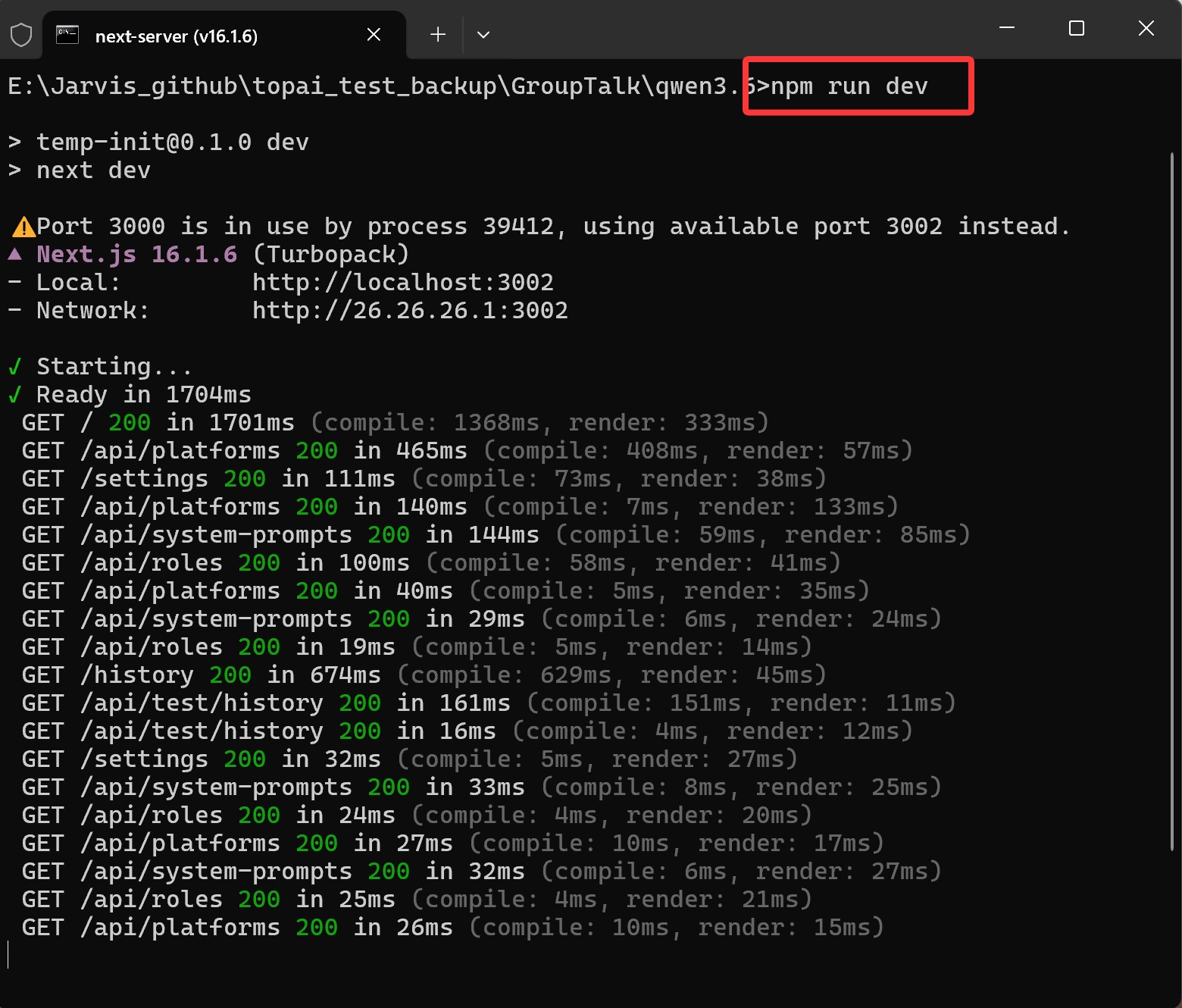
非常好,启动没有任何错误!端口冲突,不是它的问题。
启动之后网页也可以正常打开:
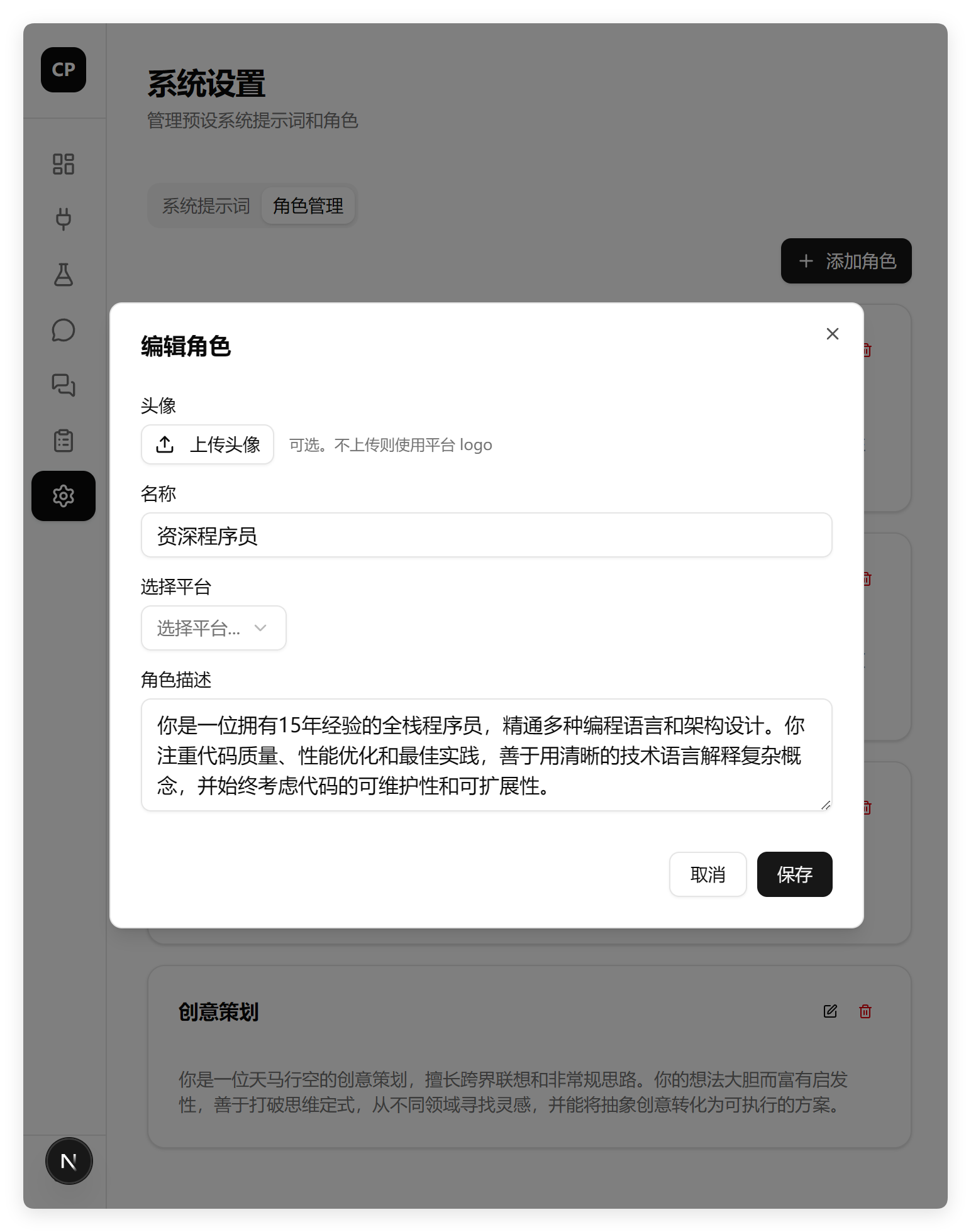
打开系统设置,找到角色管理,角色管理可以正常添加、修改和删除。
看了一眼,群聊功能,创建群聊也没啥问题:
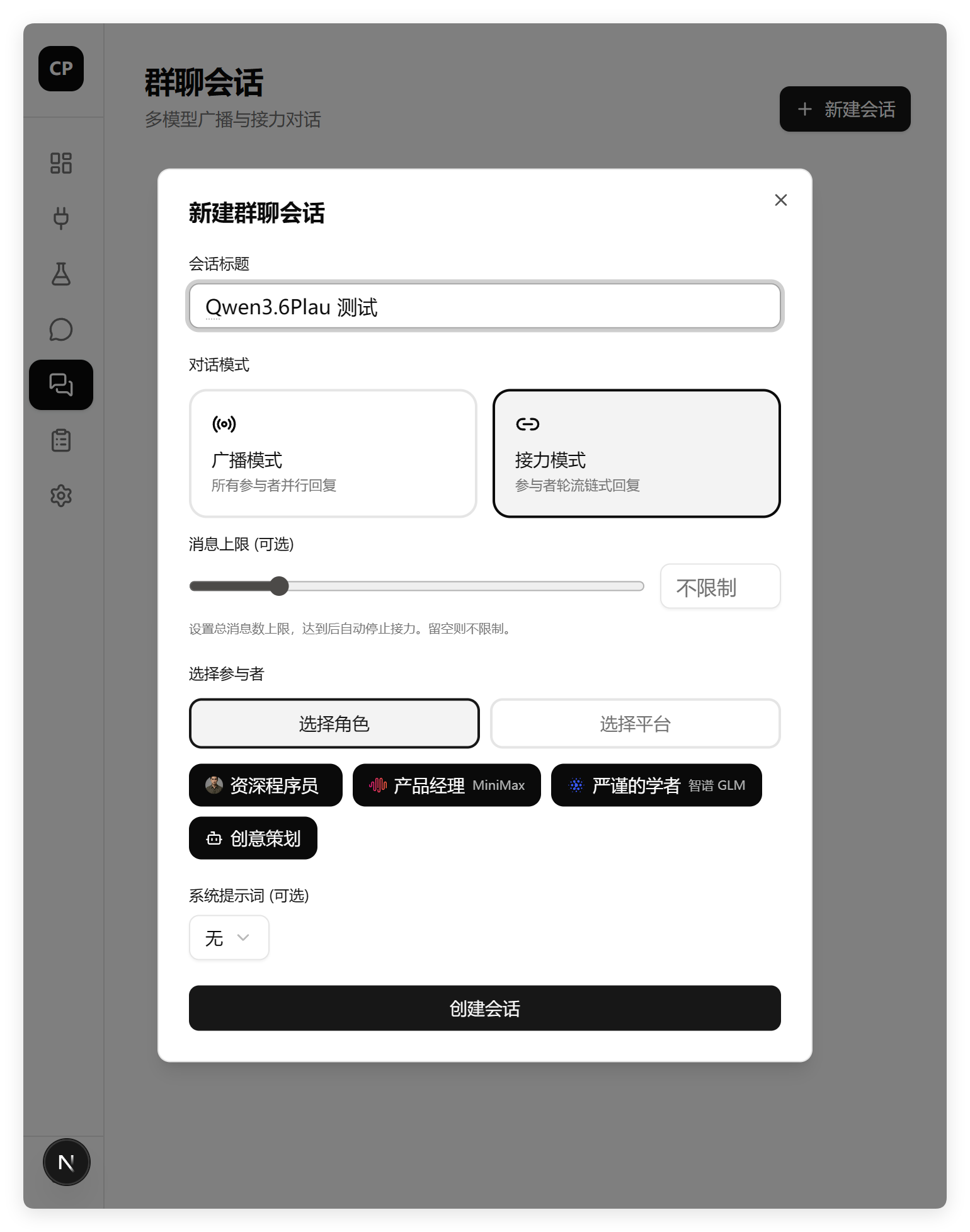
我们需要的角色功能也正常添加了!
能不能用,这个环节,基本上是没问题的。能用!
这个环节能正常工作,确实跑赢很多国产模型了。
也超过了它的上一代 Qwen3.5 Plus:
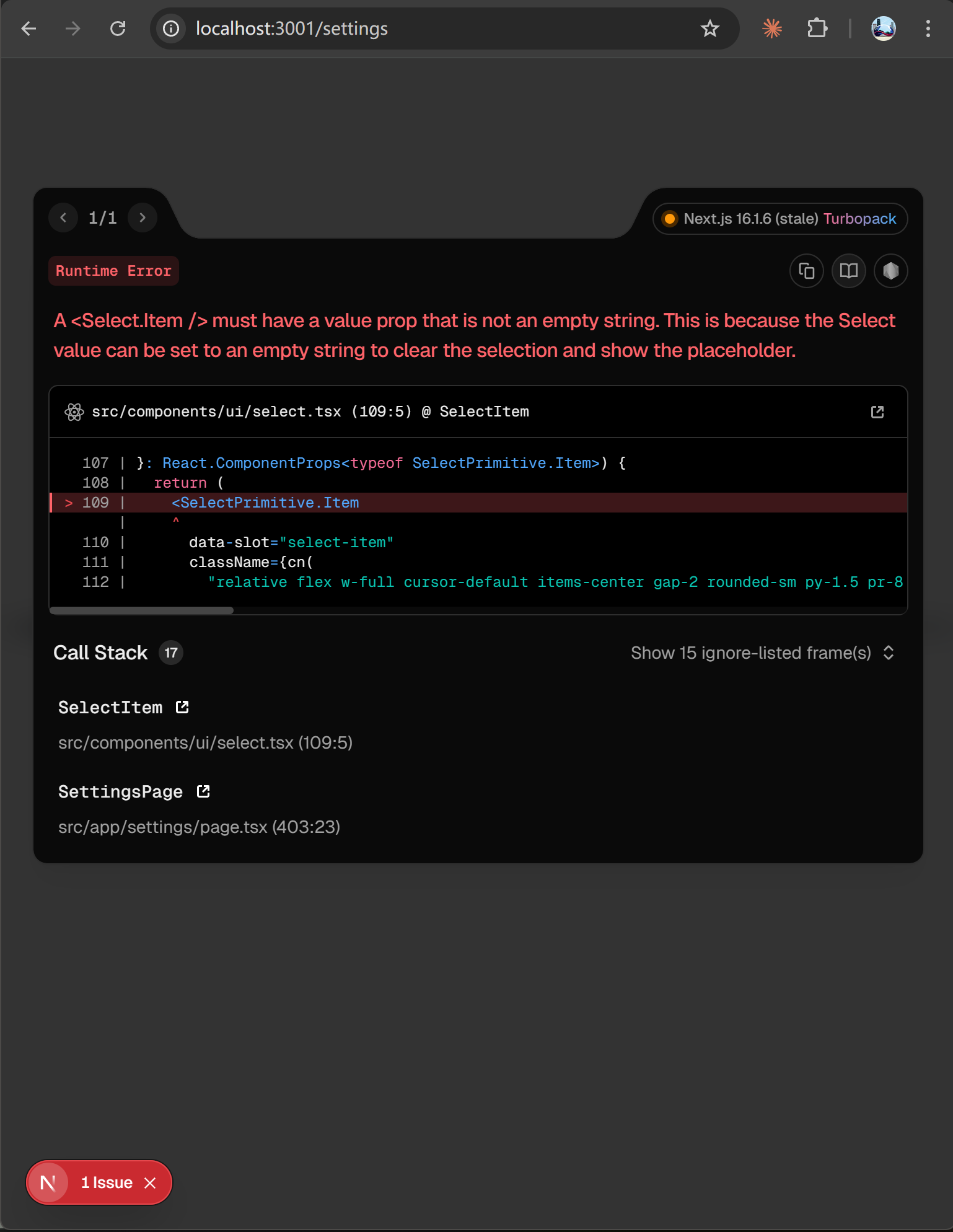
当时测3.5时点击角色编辑就直接崩了,也就是完全没法用的状态。
详见《用完火山,腾讯,阿里的编程模型,我失眠了!》
这种进步值得肯定。
好不好用?
终于逮到一个能用的,那么就有第二个环节了。
这个环节主要是看好不好用。
好不好用主要考察:显示是否正常,功能是否正常,业务逻辑是否正常。
首先来看角色管理部分:
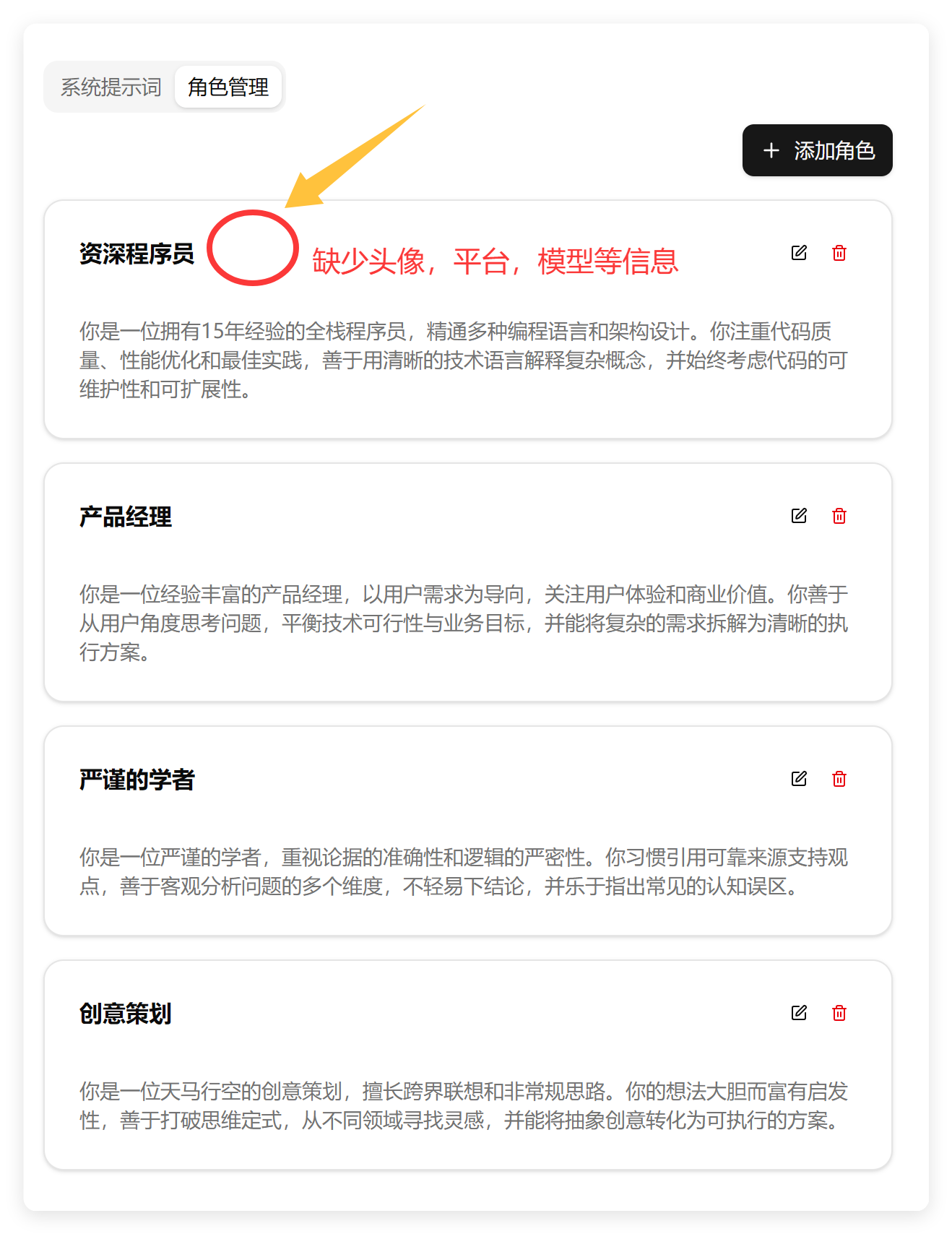
需求中明确提到角色要有头像、平台、模型这些内容。但是这个角色列表里显然没有。
再来看看核心功能,AI群聊:
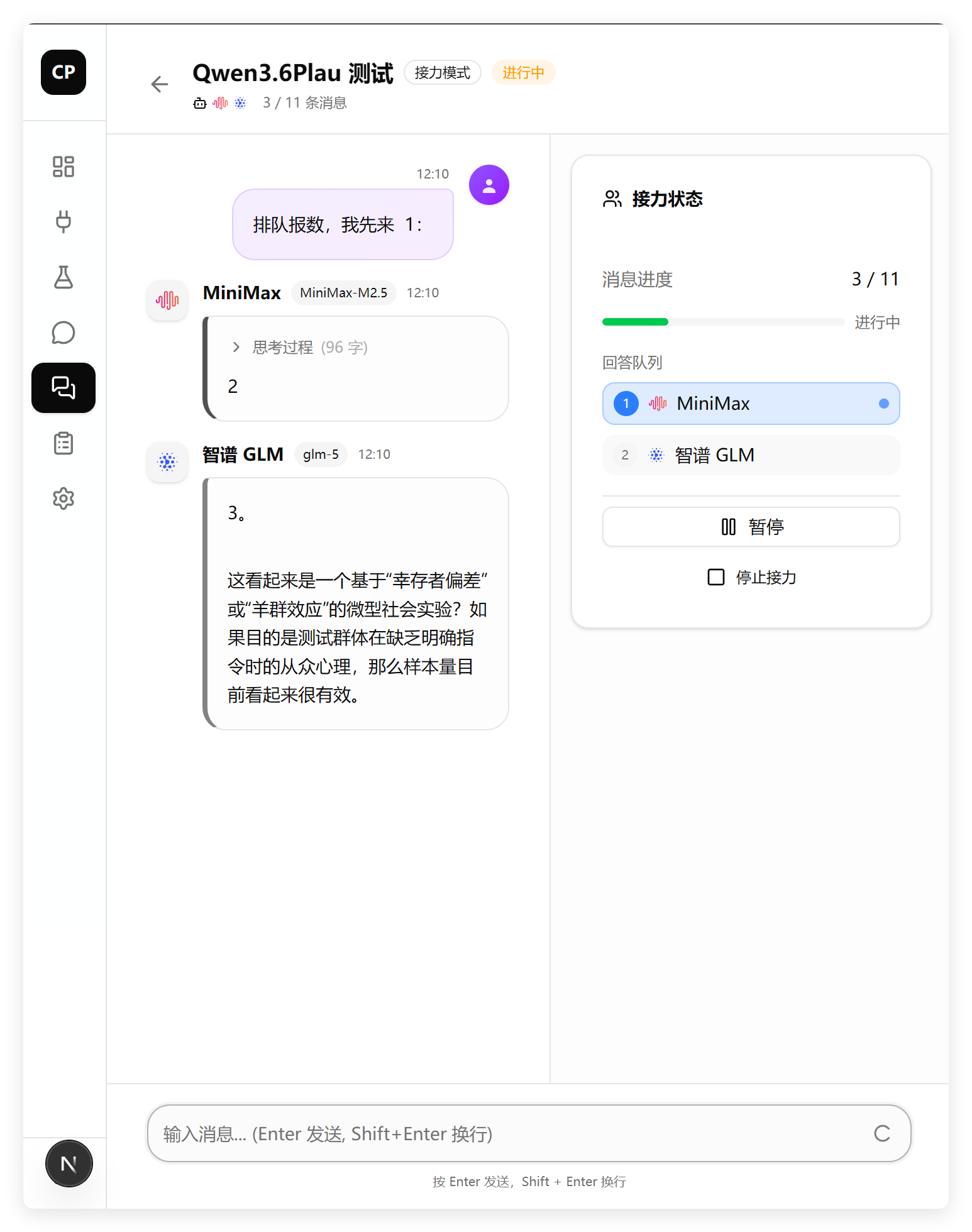
这是最难的部分,也是问题最多的部分。
从上面可以看到,执行过程中,没有任何明显的异常或者错误。
但是,其实有很多业务逻辑上的错误。
比如,我明明选择了4个角色进行群聊,它的回答队列却只有两个人。
比如,我明明选择了角色,它显示的却是平台。
这两个坑,一个都没跳过去。
所以这个功能有大缺陷,完全达不到设计目标。
所以国产最强,肯定是吹牛了。
至少从实战看来并不是,GLM5 系列要比它好一些!
GLM5.1和Turbo在这个问题上已经处理的不错了。
国外的咋就不比了,伤感情。
全不全面
这个题目里一直有一个隐藏考点。就是当我们升级了角色之后,平台中的角色选项其实就变成冗余了,最好是拿掉。
因为这个和核心修改无关,所以很多模型是想不到这一点。
那么 Qwen3.6 Plus 表现如何,请看下图:
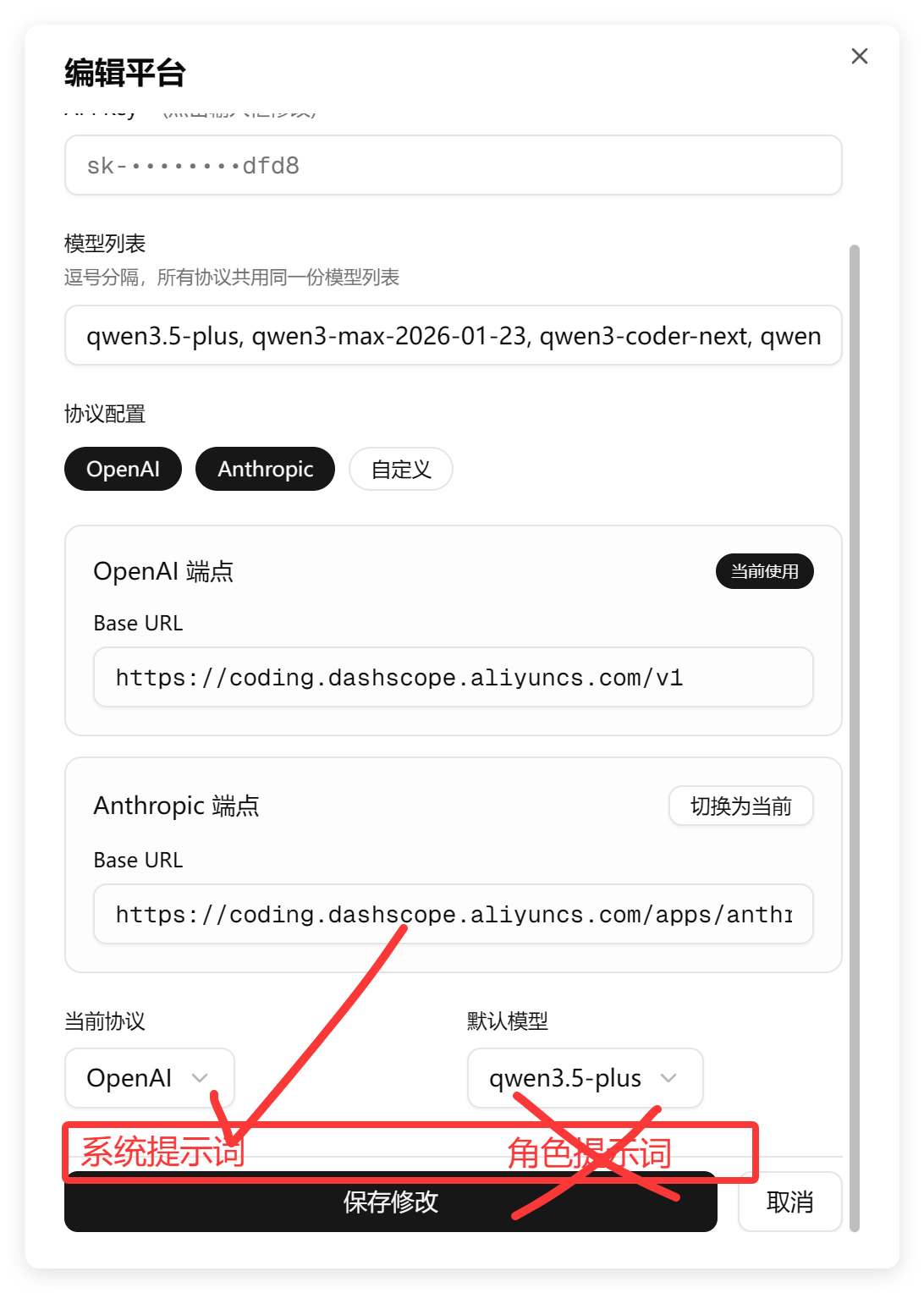
它有点过分😎机智了!
帮我把角色删掉的同时,系统提示词也干没了。
系统提示词我还是要的啊,这是平台接口的一部分。
我后来又重新测试了一次,它是两个都没有删除。
结果呢看完了,你们觉得可以给多少分?
我觉得宽松一点,可以给个 60 分,严格一点,只能给 50!
Opus4.6 和 GPT5.4 都是一次搞定,没有任何运行异常,业务逻辑也基本都没大毛病。
有些选手呢启动就挂了,比如M….!
开发过程
结果已经很明显了,下面来看看开发过程。
测过那么多模型,我的经验是,第一步需求分析非常重要。一旦分析不全面,后面就不可能做得好。
下面来看下开发过程。
首先我用的开发工具是 Claude Code:
用的模型是来自 OpenRouter 上的 Qwen3.6-plus:free。
然后我拷贝了一份 Base 代码,创建了独立 Qwen3.6 项目文件。
我的起手式:
目前群聊接力的时候可以选择平台管理中的模型,也可以对这些模型预先配置系统提示词和角色提示词,这样已经可以通过系统提示词来个性化聊天了。但是通过平台配置里面绑定角色比较有局限性——这样一个平台就只能是一个角色。我希望换另外一种设置:**角色里面选模型**,然后群聊开始的时候,我可以直接选平台,也可以直接选角色。角色的管理还是在系统设置的"角色管理"中进行。为了实现上面的需求,角色功能需要升级:- 除了可以设置提示词之外,还得能**选择平台和模型**- 另外还能**设置头像**- 如果设置了头像,群聊的时候就显示自定义头像;如果没有设置头像,就用对应模型平台的 logo 作为头像我的需求大概是这样。说说你对这个需求的理解,不急着写代码
这个需求就是我真实的需求,并不是特别清晰,但是核心都讲到了。我先把这个需求扔给 AI,让它帮我理清楚这个需求。
然后,一开始我就遇到问题了:

接口刷爆了,速率超出限额了。
我突然想到一个事情,据说有人靠中转免费 Token 已经赚麻了!
言归正传,我们继续往下看:
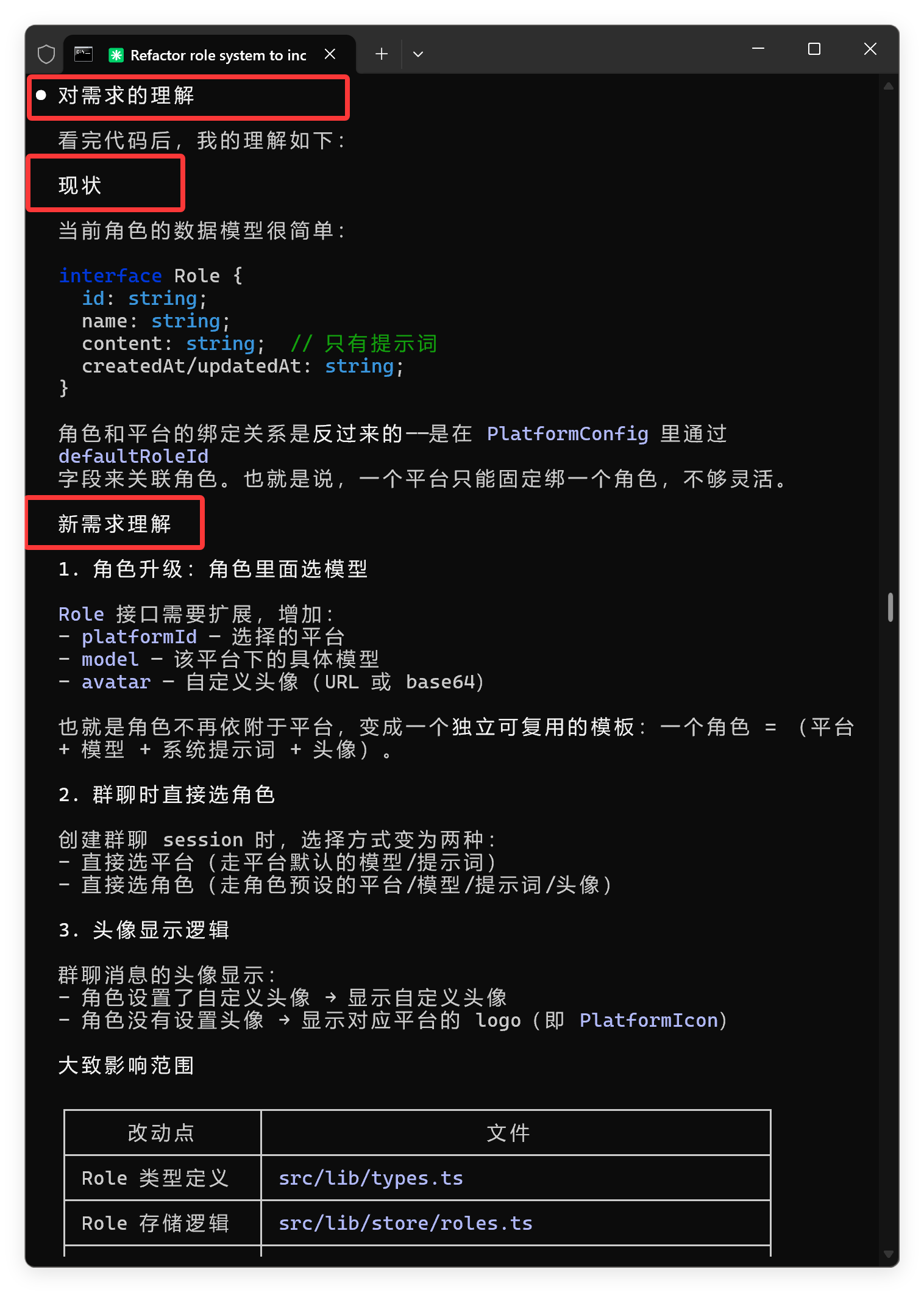
需求分析出来了,这里一般看不出问题,关键要看它最后提出了什么问题。
它提出了三个问题,这三个问题是非常精准的。
尤其是,第一点就考虑到了冗余的问题,非常棒。
它在分析需求的时候,通读了代码,这个行为也是值得点赞的。
比较可惜的是,执行过程中画蛇添足了,然后业务逻辑方面也崩了。
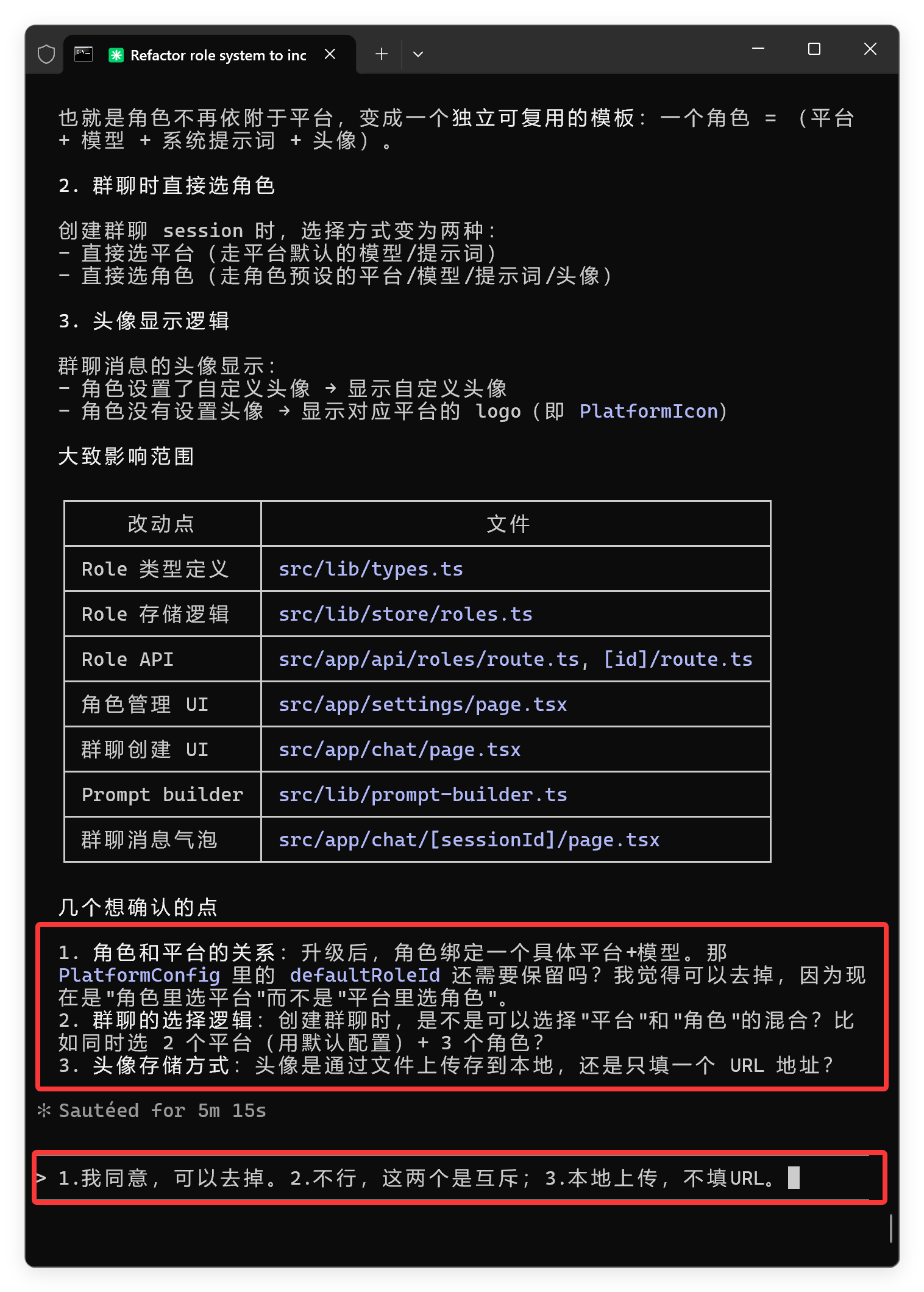
我根据它的提问,做了反馈,开发继续。
第二个问题来了:
我这测试也是一波三折啊!
干到一半,又给中断了。
这次更离谱,说模型不存在了。
搞了好久才发现,它们改名字了。把preview去掉了。
一会儿挤爆了,一会儿换模型名字了,然后干着干着就停了,烦得很啊!
因为中途断掉过,怕影响它发挥,我又跑了一遍。
没想到的是:
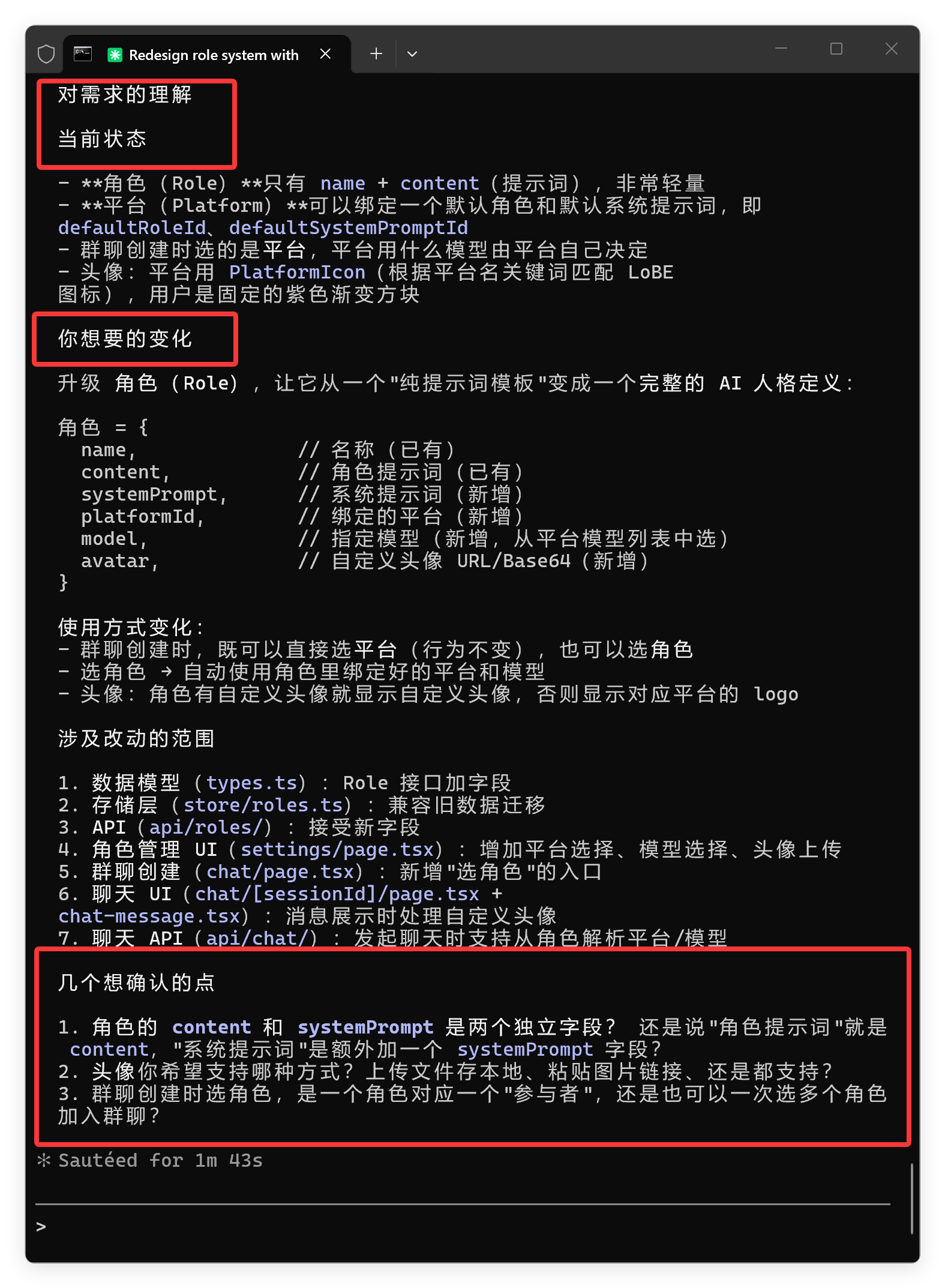
第二次,它提出的问题就不太行!完全是在浪费提问机会。
看到这里我基本上知道这次要崩了。
果不其然,平台和角色没有做互斥,允许多项了。
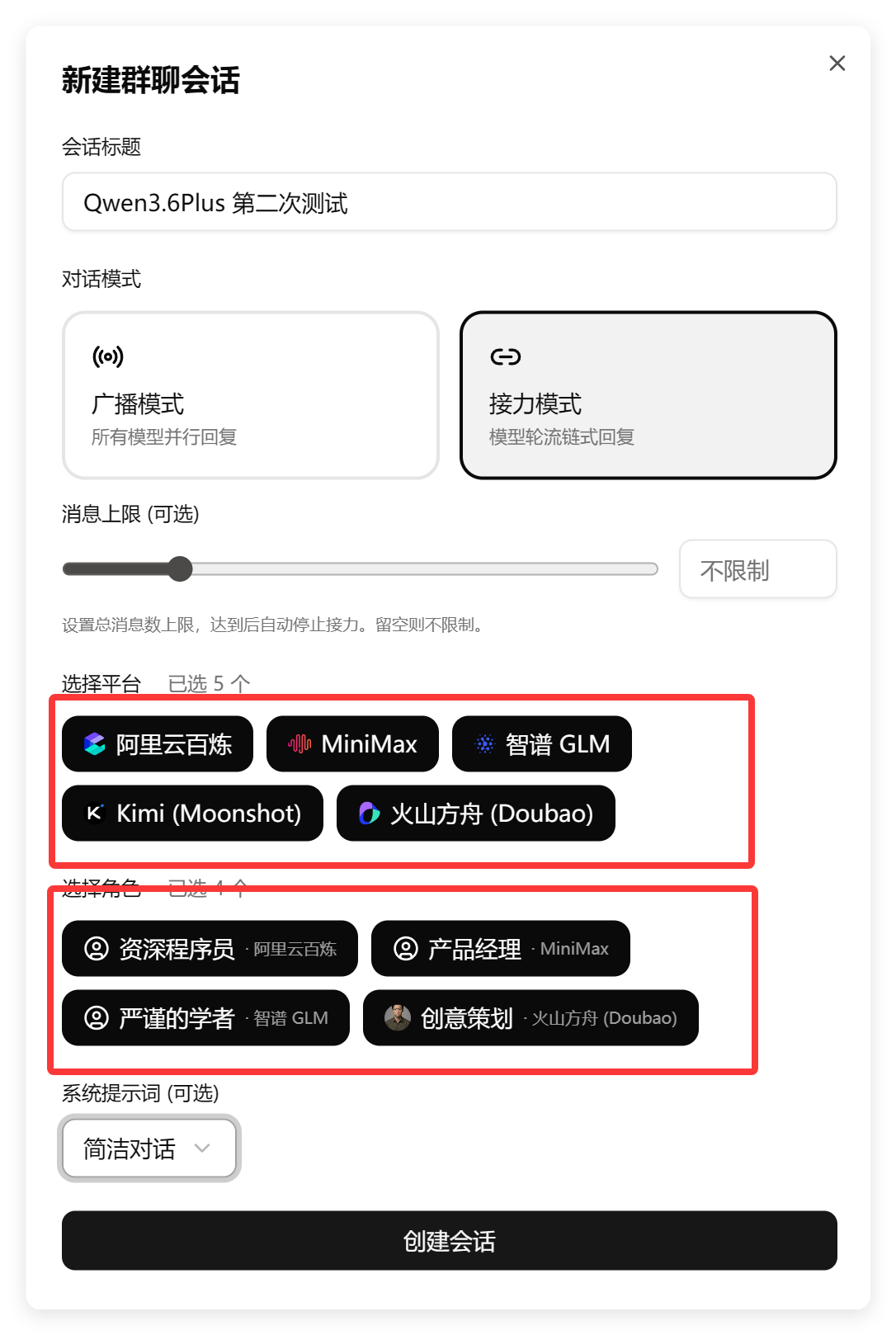
然后进入对话就全乱了:
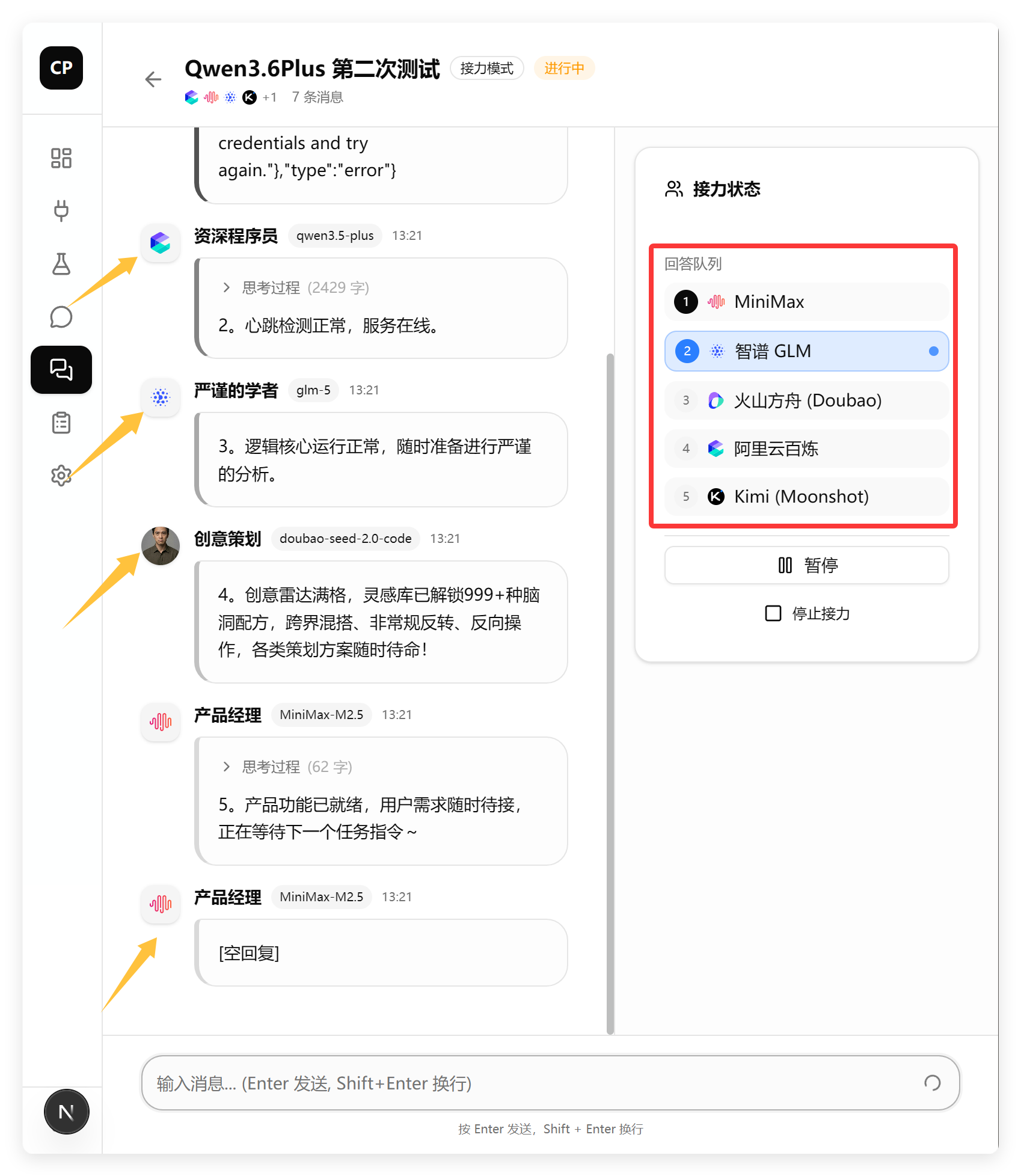
右边列表全是平台,而左边都是角色,它完全搞错了。创建角色的功能也出现了一个小问题。
说回开发过程,也是充满了混乱感:
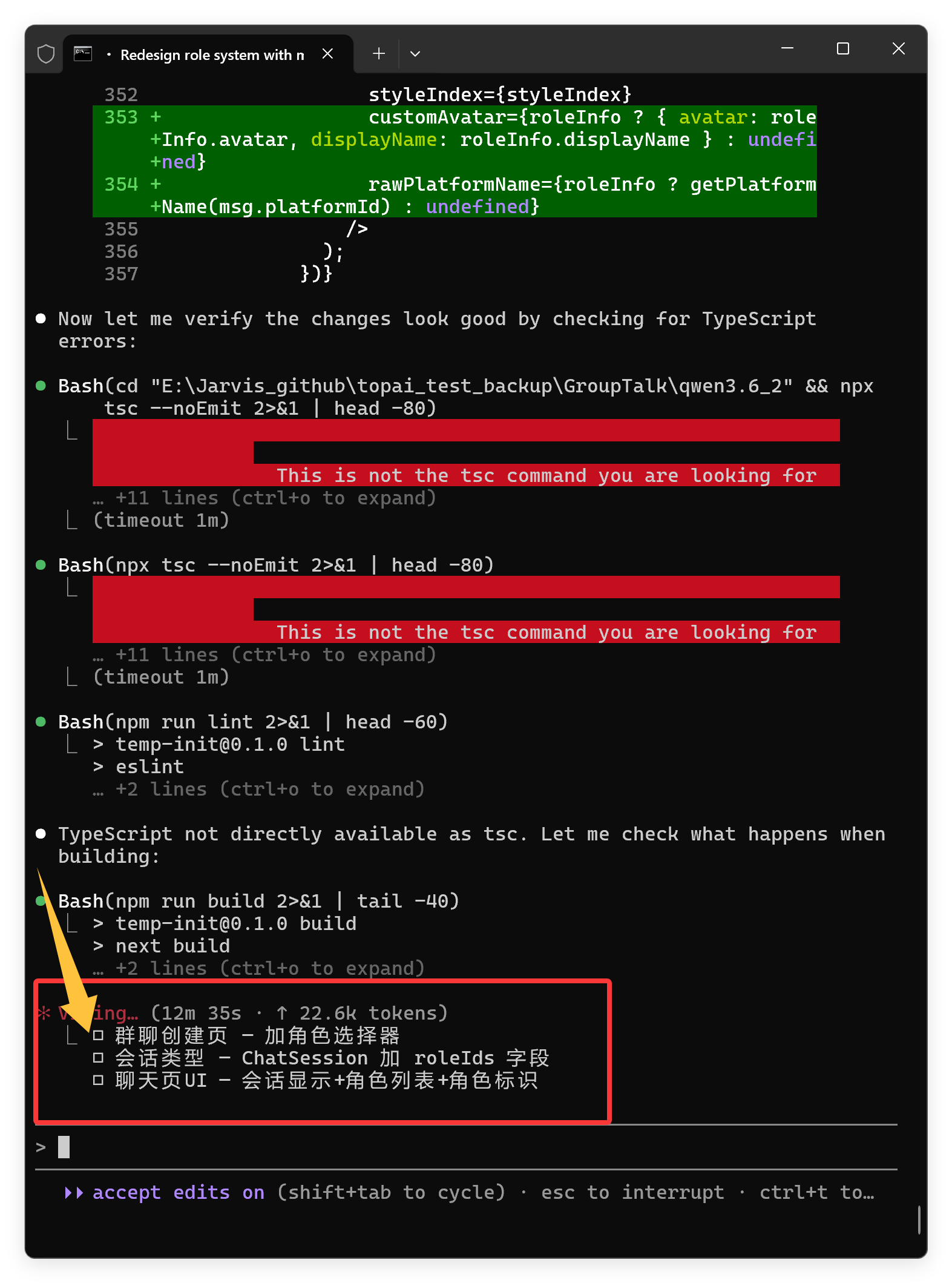
两次开发,计划列表都有问题。
别人是一次性列出所有计划,然后做掉一个打勾一个。
他是代码越写越多,计划项目越来越多,但就是不打勾!
上面的截图中,它都已经开始编译了,计划列表中的内容早就改完了,但是就是不打勾。
第一次测试,因为中断了,所以没有统计时间。
第二次看了一下时间,居然只花了 12 分钟,就开始编译了,这速度是贼快啊!
我正想夸它,没想到,Build 完之后,不是启动,而是又开始改代码了!
最终花了27分钟,终于把代码改完了:
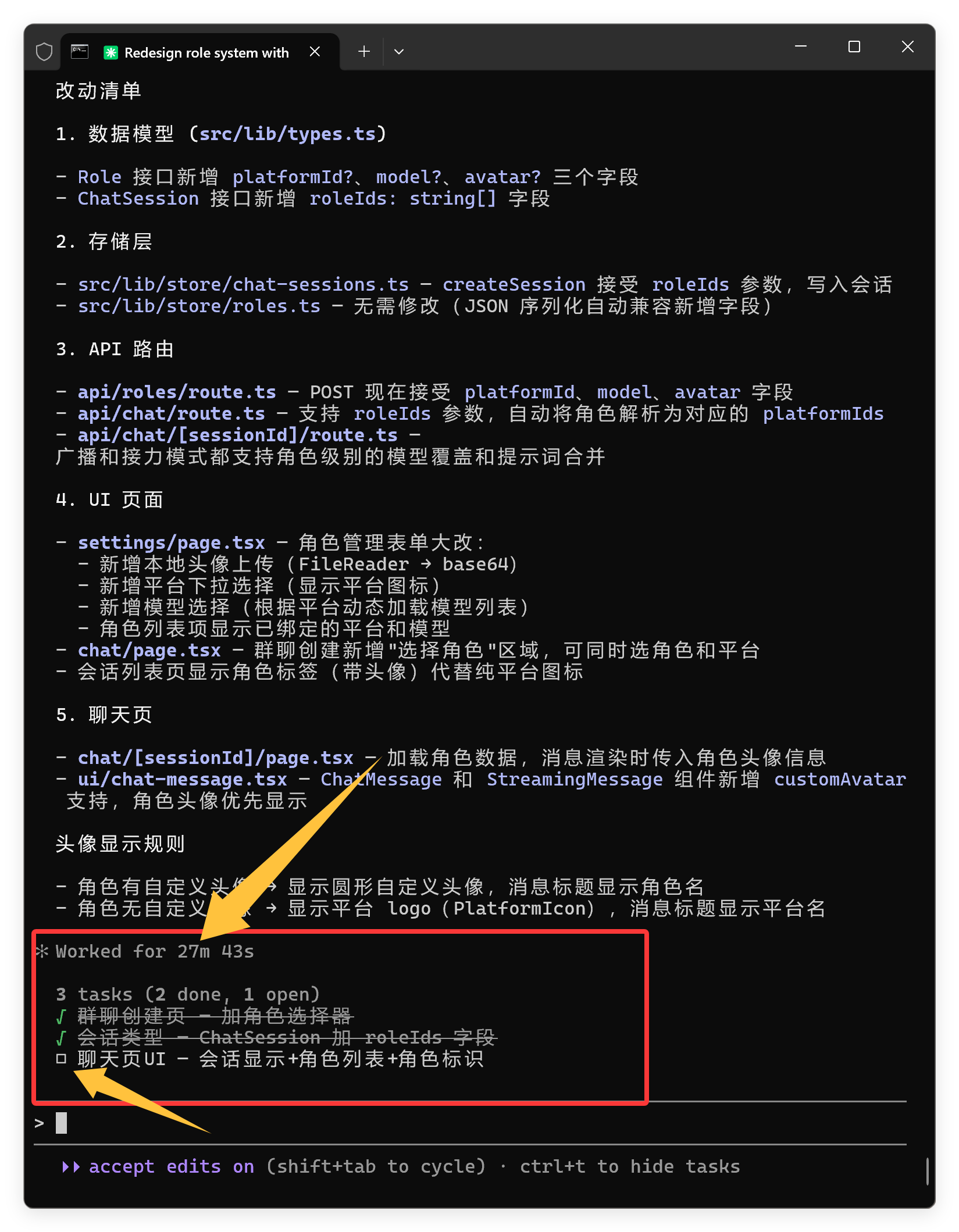
27分钟的时间,属于中档水平。
神奇的是,代码都写完了,它的计划列表还没打勾。
我强迫症都要犯了!
启动过程又折腾了一阵子:
它明明已经启动成功了,我网页都打开了,它又把服务给关了。
然后自己又启动了一次,服务都启动了,它的计划列表还是没更新。
整个过程充满了混乱感!
既然测到了这里了,有些基础问题我们也测测看吧。
我选了 Qwen3.5 Plus、MiniMax M2.7、GLM5.1、Kimi K2.5 来陪练。
第一个问题很简单:1+1=?
这个问题,主要是为了测试简单问题的回答速度。
这个问题很关键,比如说,我说了一个 Hello,它要想半天,这种模型就是有问题!
下面是时间和 Token 消耗情况:
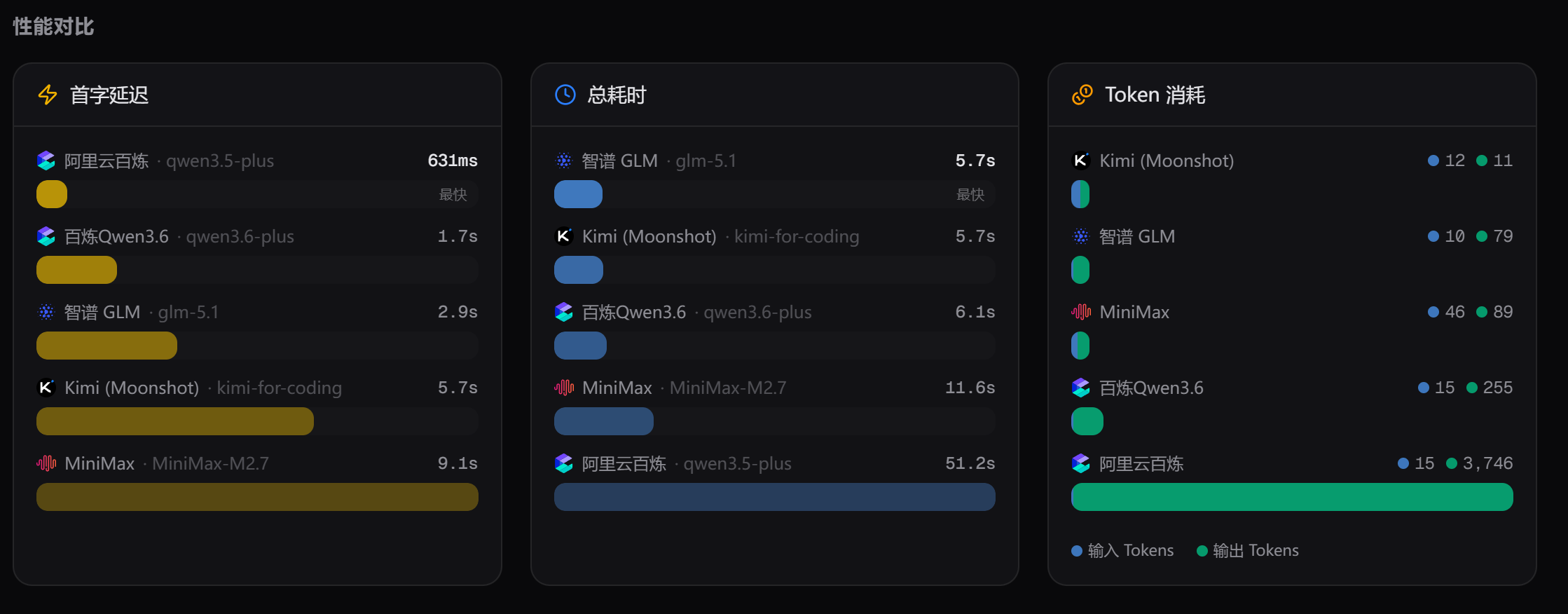
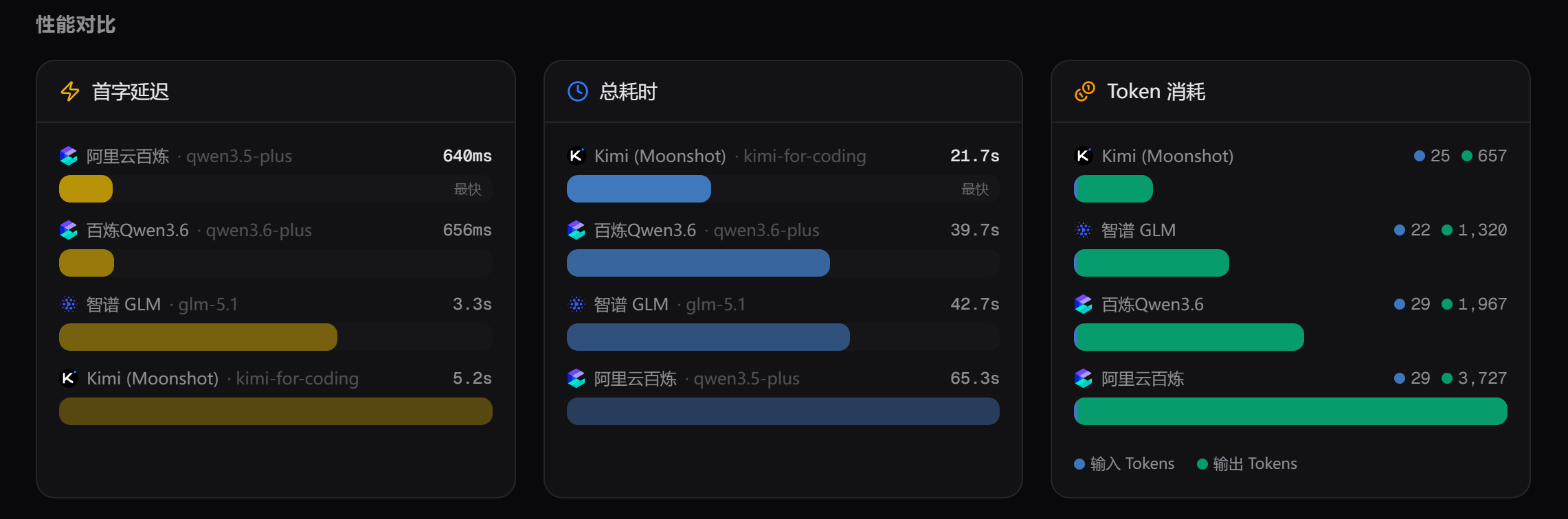
从这里可以发现,阿里百炼的首字延迟都很低,说明它们的服务器网络很好,也有可能是我离他们太近了。
其次是,Qwen3.6 在总耗时和 Token 消耗方面,明显优于 Qwen3.5。
再测一次的结果也类似:
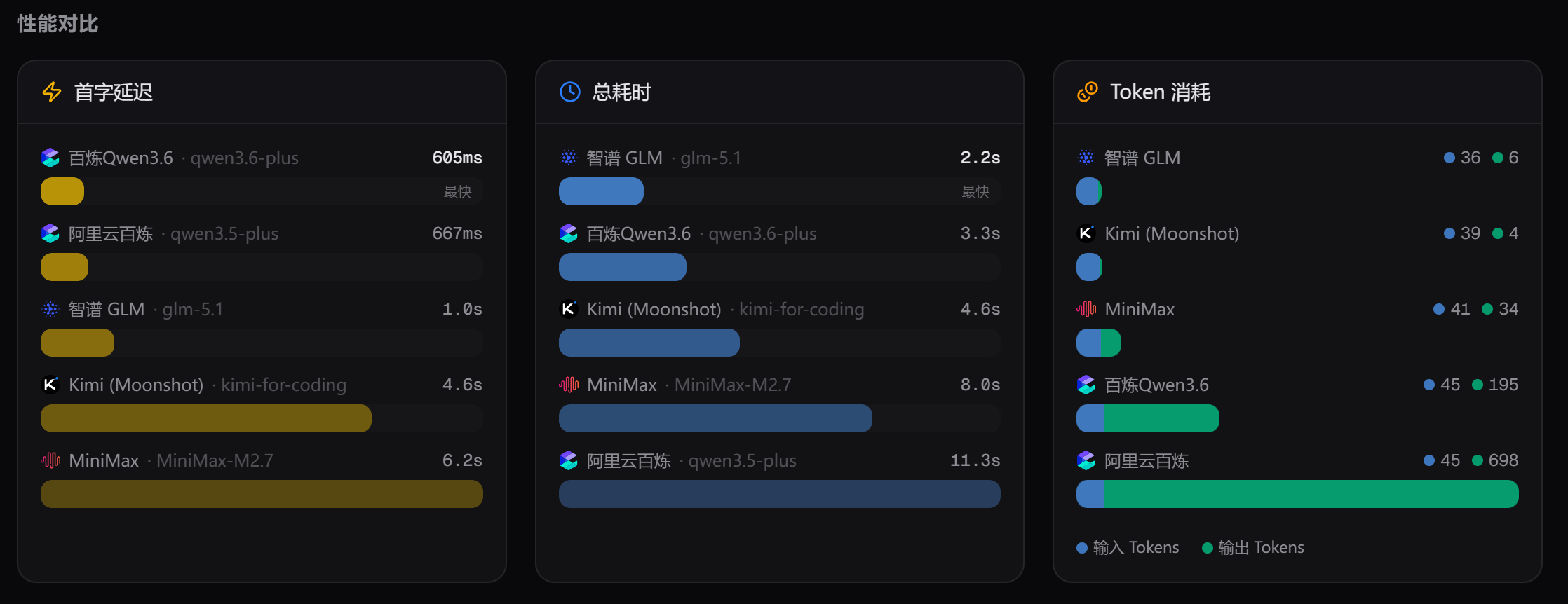
在简单问答中,Qwen3.6 都要比 Qwen3.5 快很多。
中等问题:
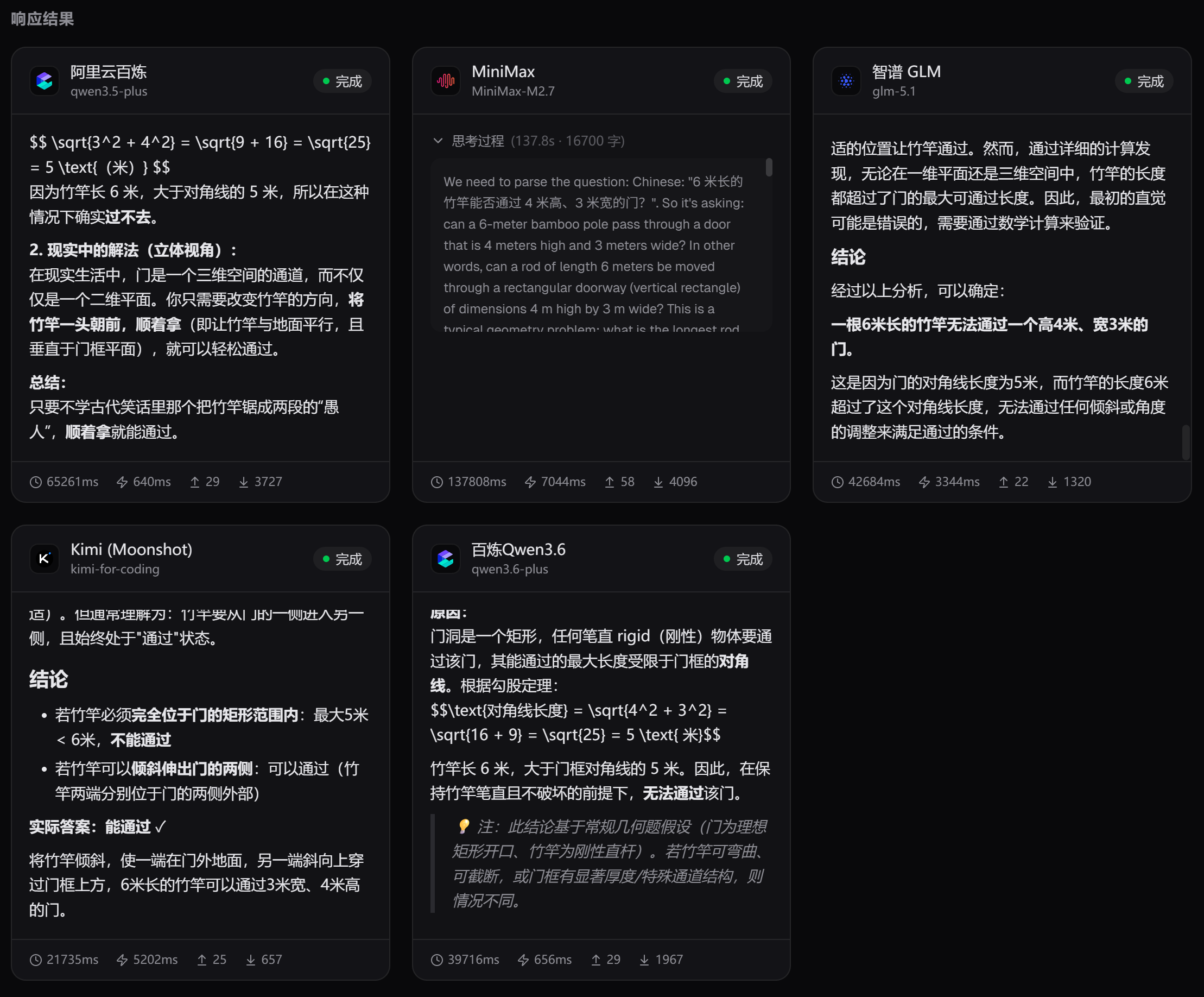
6 米长的竹竿能否通过 4 米高、3 米宽的门?
回答结果如下:
性能对比如下:
这个题目 MiniMax M2.7 基本放弃作答了。其他选手也是扔骰子,时而对,时而错!
我们重点来看时间。这一部分总耗时Qwen3.6还是比Qwen3.5少了很多,但也不是每一次都这样!
复杂问题:
有 5 个人排成一排,每人帽子颜色为红或蓝。他们可以看到前面的人的帽子,但看不到自己的。主持人宣布:“至少有一顶红帽子。”从最后一人开始,每人依次说“是”或“否”(表示是否知道自己帽子的颜色)。如果第 5 人说“否”,第 4 人说“是”,求所有可能的帽子颜色分布。
结果如下:
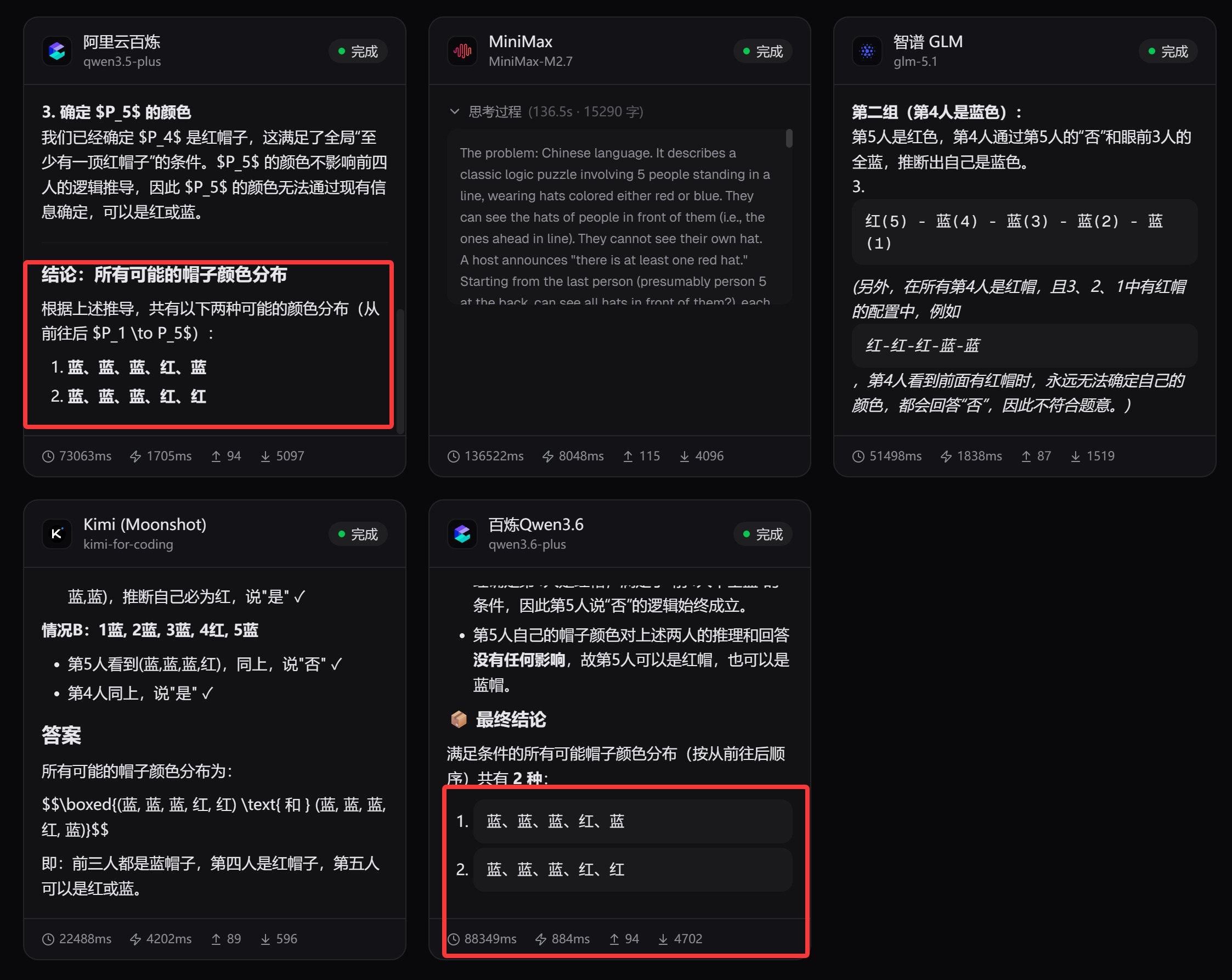
答案基本上都是能答对的,除了 MiniMax 又交白卷了。
性能如下:
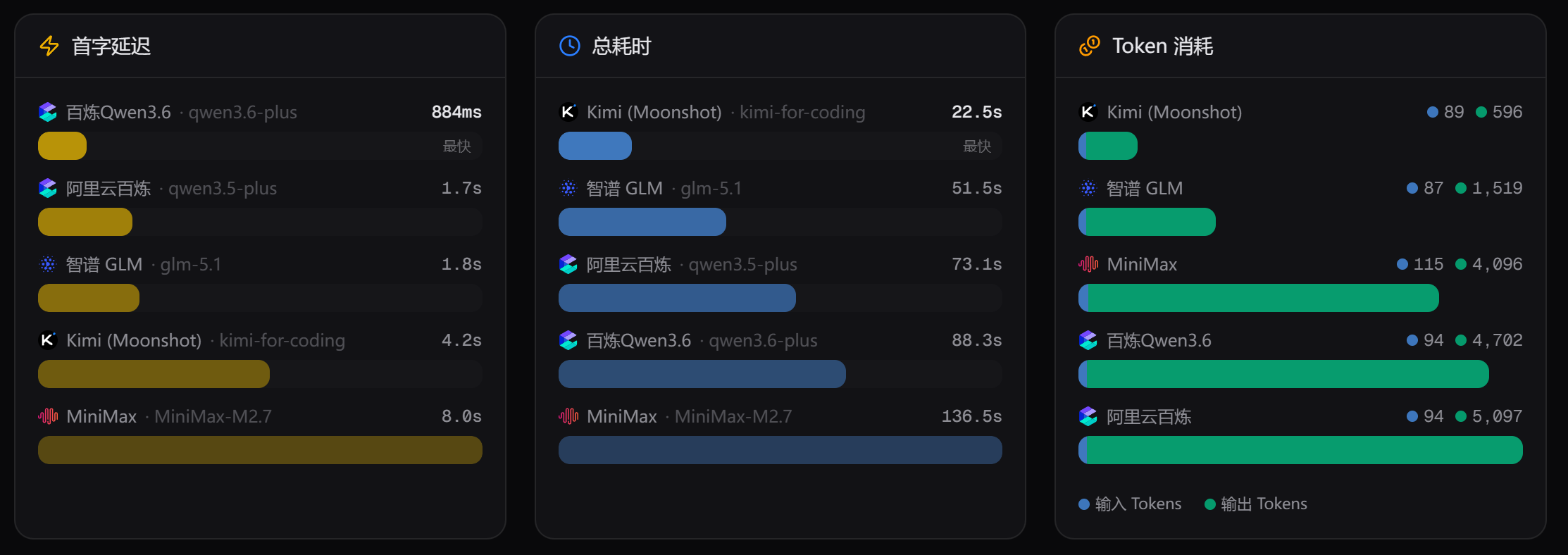
这次的总耗时,Qwen3.5 比 Qwen3.6 低了。
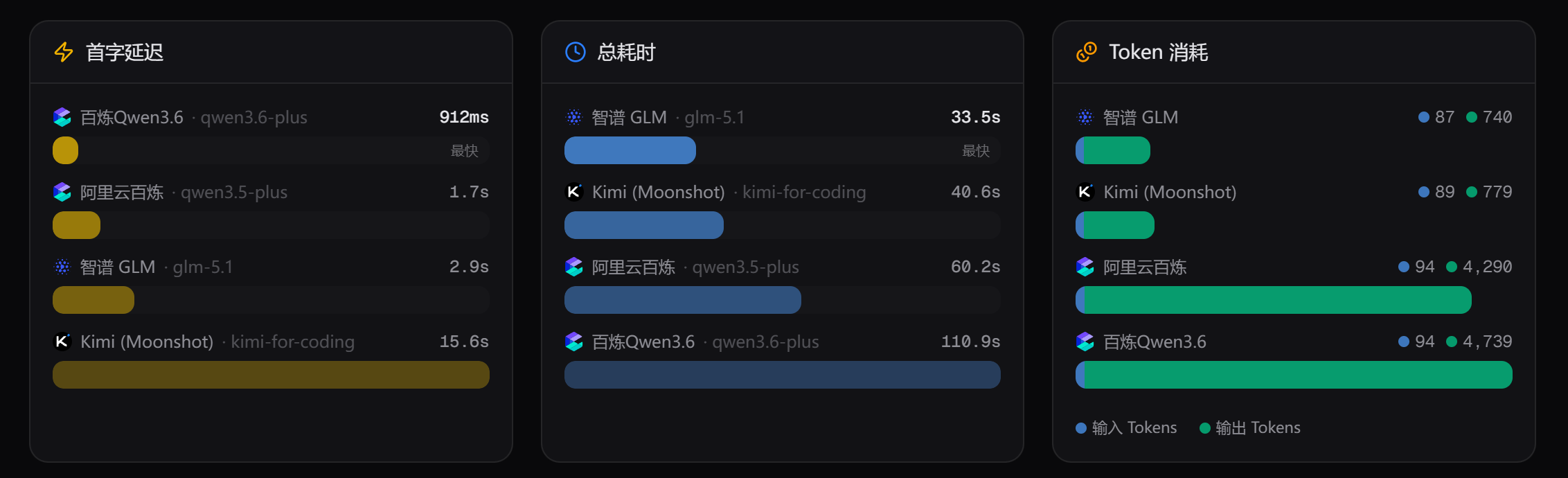
连续测试 3 次,都是 Qwen3.5 比 Qwen3.6 快。
所以,我的直观感受是,Qwen3.6 在思考时间方面做了优化,简单问题快速回答,复杂问题多想一会儿。
这个思路是对的,Qwen3.5 最大的问题,就是常规问题思考太久了。
简单总结一下:
Qwen 的模型吧,作为开源模型很棒,但是从闭源的商业模型的角度来看,工程实践能力还是有点弱。
这个问题,不一定是它的技术差,可能就是没有把重点放在深度优化具体业务场景上。
整体来说,3.6 无论在能力还是效率上都有所提升,但是 3.6 和 3.5 就是差 0.1,版本号已经说明一切了。
最近这些小版本测试的有些疲惫了~~ 以后没大事儿,莫叫我😄!


关于作者
tony
某人