实测GLM4.7比起Claude还是差亿点意思! | 甲维斯C
前几天 GLM4.7 刷屏,说是能和 Claude 五五开。但是他们又不举例子,只是说很厉害。搞得我有点难受。所以直接充值了这两个产品。
现在网上的软广防不胜防。实践出真知,只有我自己测过的才靠谱。
这次测试会很有意思。
首先,测试的主题的是让它们写一个 “个人博客”。
然后,我会记录整个过程,以我的视角做一个评判。
最后,我会把代码交给 GLM4.7、Claude4.5、Codex 和 Gemini CLI 进行多维度打分。
让 AI 评价 AI,结果非常有意思。
下面说测试环境。
使用同一个版本的 Claude Code。一个用自带的 Claude Opus 4.5,另一个配 GLM4.7。
如何把 GLM4.7 塞入 Claude Code,请参考《GLM4.7替代Cluade第一步,给CC换上“国产心”!》
同样的提示词:“用 React 开发个人博客,要求功能完善,设计美观”。
我其实测了两轮,第二轮提示词加了“专业的 UI 和 UX。”。
因为第二轮都触发了 Plan 功能 ,更具代表性,更能体现整体实力,所以我先来展现第二轮。
下面就同时打开 Claude Code(CC)。然后输入需求,按回车。
Claude Code 还没安装的,可以参考这篇文章《Claude Code新手入门,官方指引!》
我会逐步比较,把两个模型的同一步骤放在同一个张图里,默认都是上面的是 GLM,下面的是 Claude。
计划模式
当我输入需求之后,两个模型都会进入计划模式。
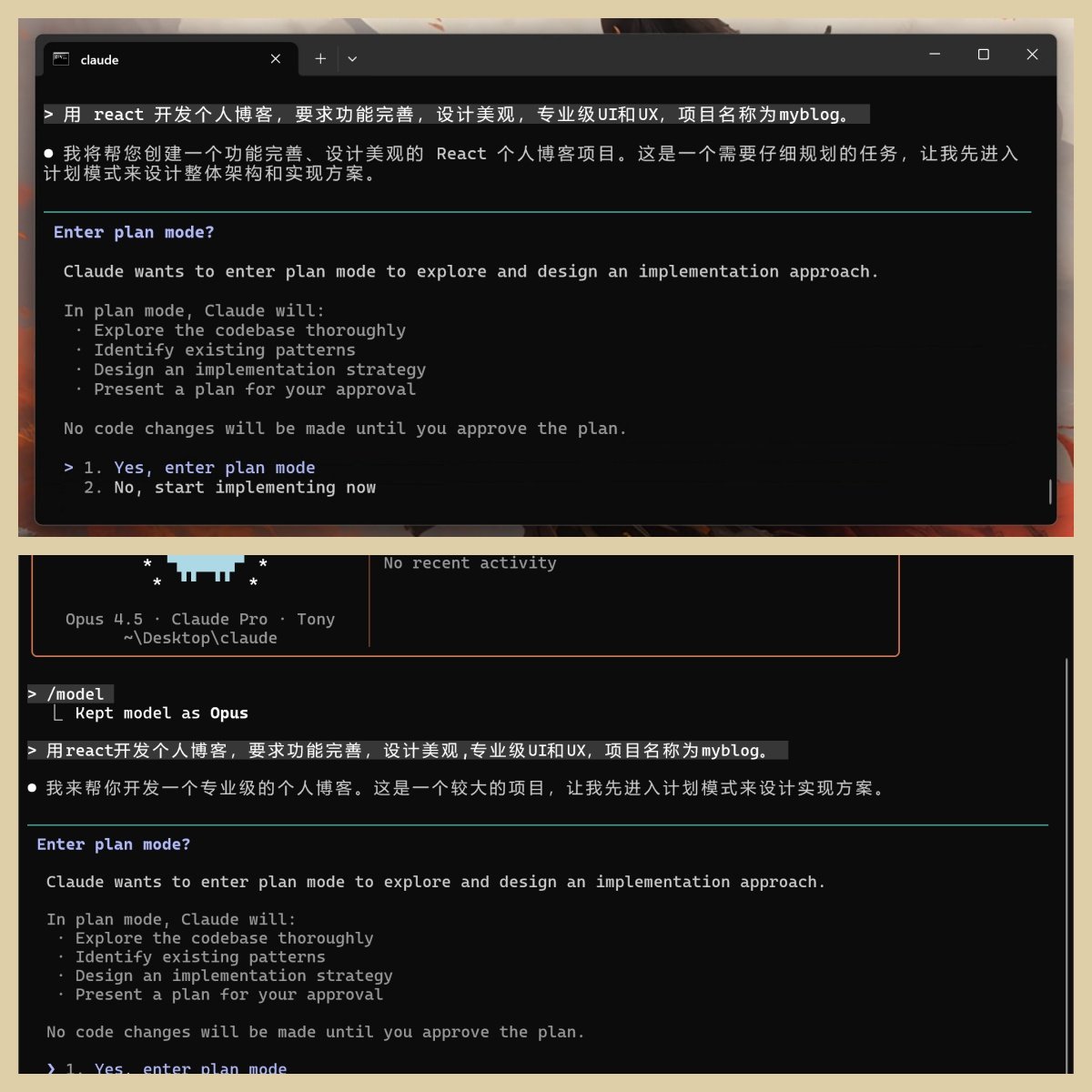
上面输出的内容,应该是 CC 的固定格式。
生成计划
进入计划模式之后,就要开始做系统规划了。
两个模型都生成了五个步骤,但是细节不一样。
GLM 的五个步骤是:数据存储,核心功能,设计风格,路由方案,Submit。
Claude 的五个步骤是:框架选择,数据方案,样式方案,功能需求,Submit。
各位架构师,可以先评判一下孰优孰劣。
下面我就分步骤展示。
第一步
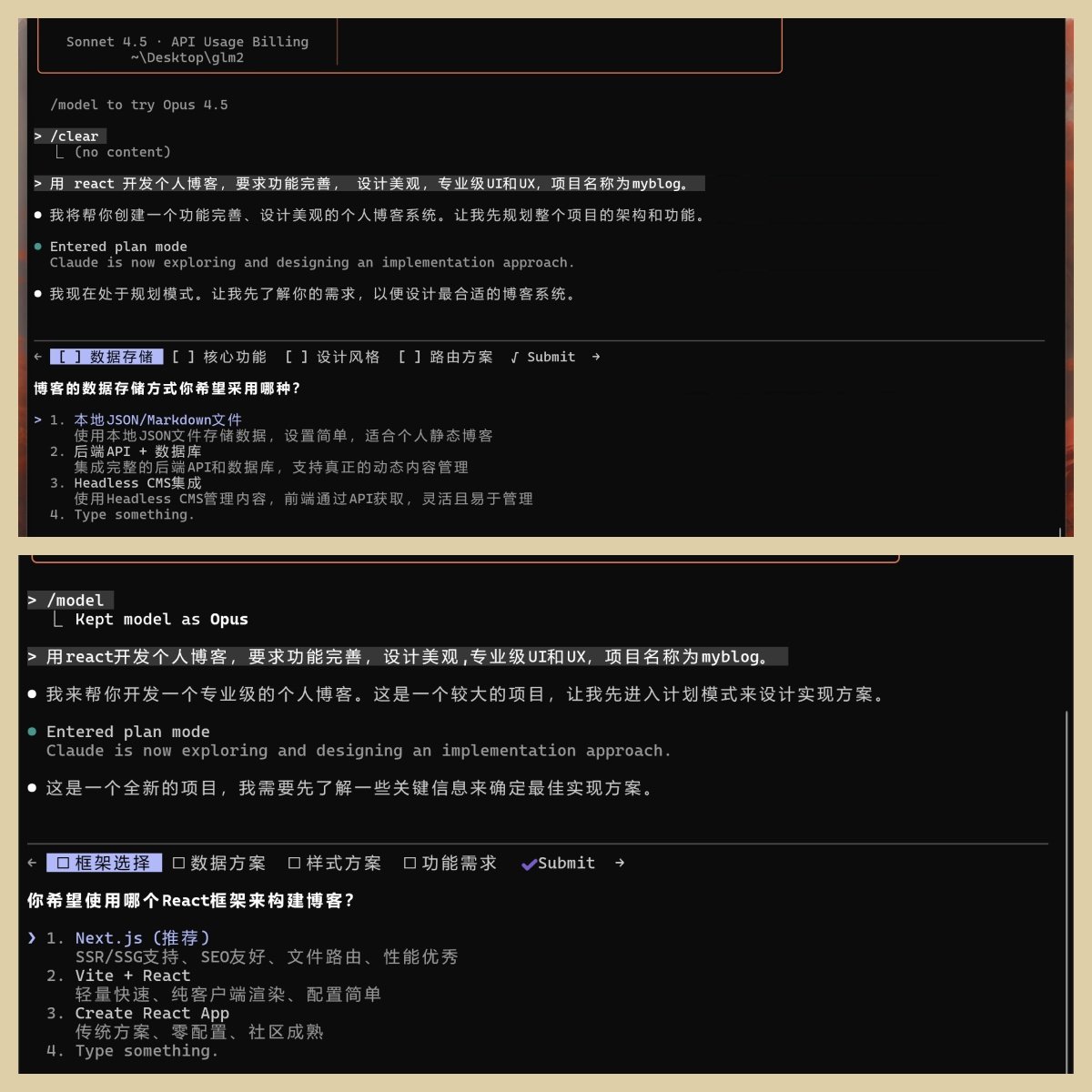
GLM 是数据存储,提供了四种方案,排在第一的是 Json/Markdown 文件。
Claude 是框架选择,也给了四种方案,排在第一个的 Next.js(推荐)。
我为了减少人工干预的影响,我就全部选他们首推的方案。
第二步
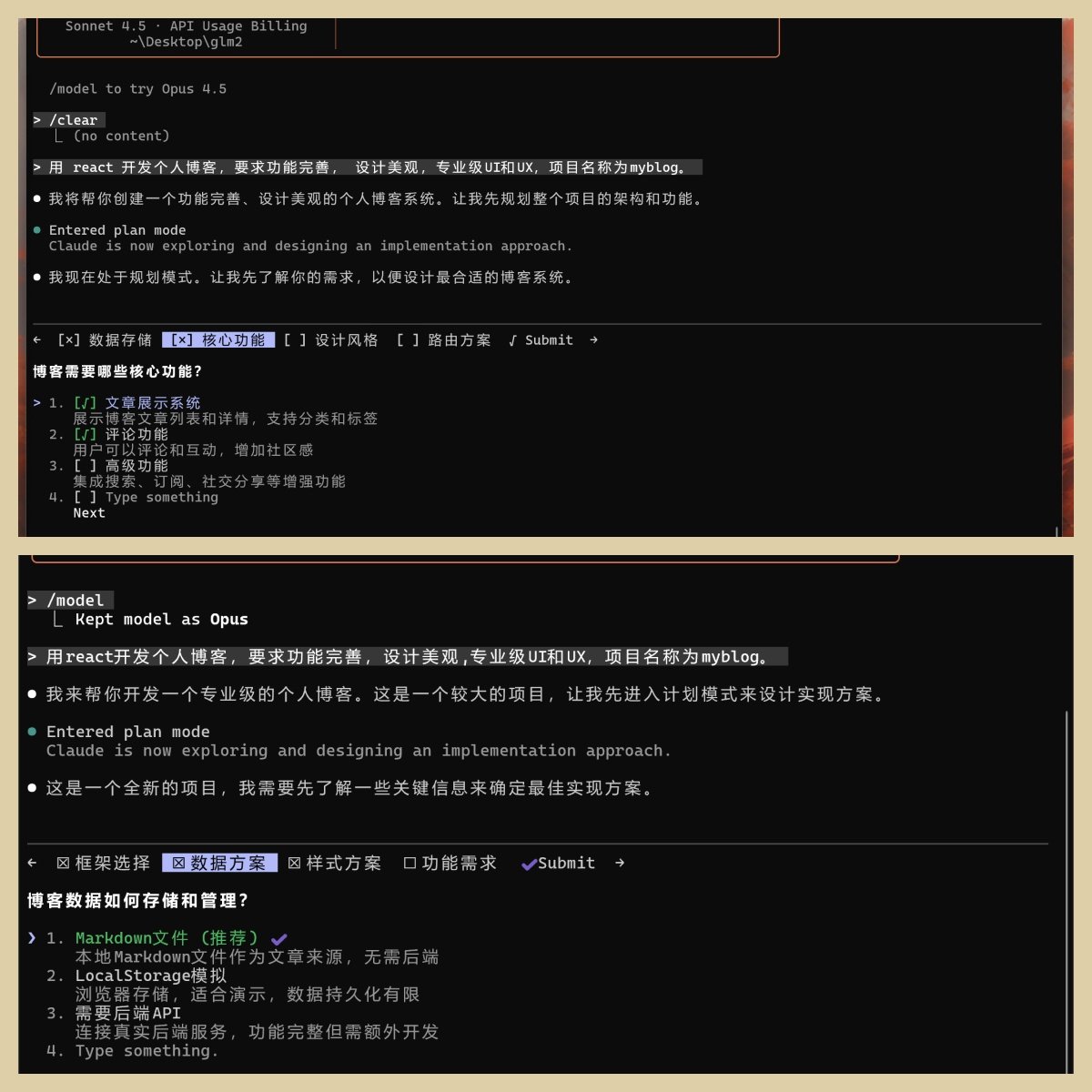
GLM 是核心功能。也给了四个选项,可以多选。
因为我需要的是功能比较完善,但是不想在增加太多无关功能。所以我勾选了第一个和第二个。
Claude 是数据方案。我直接选择推荐的 Markdown 文件。
第三步
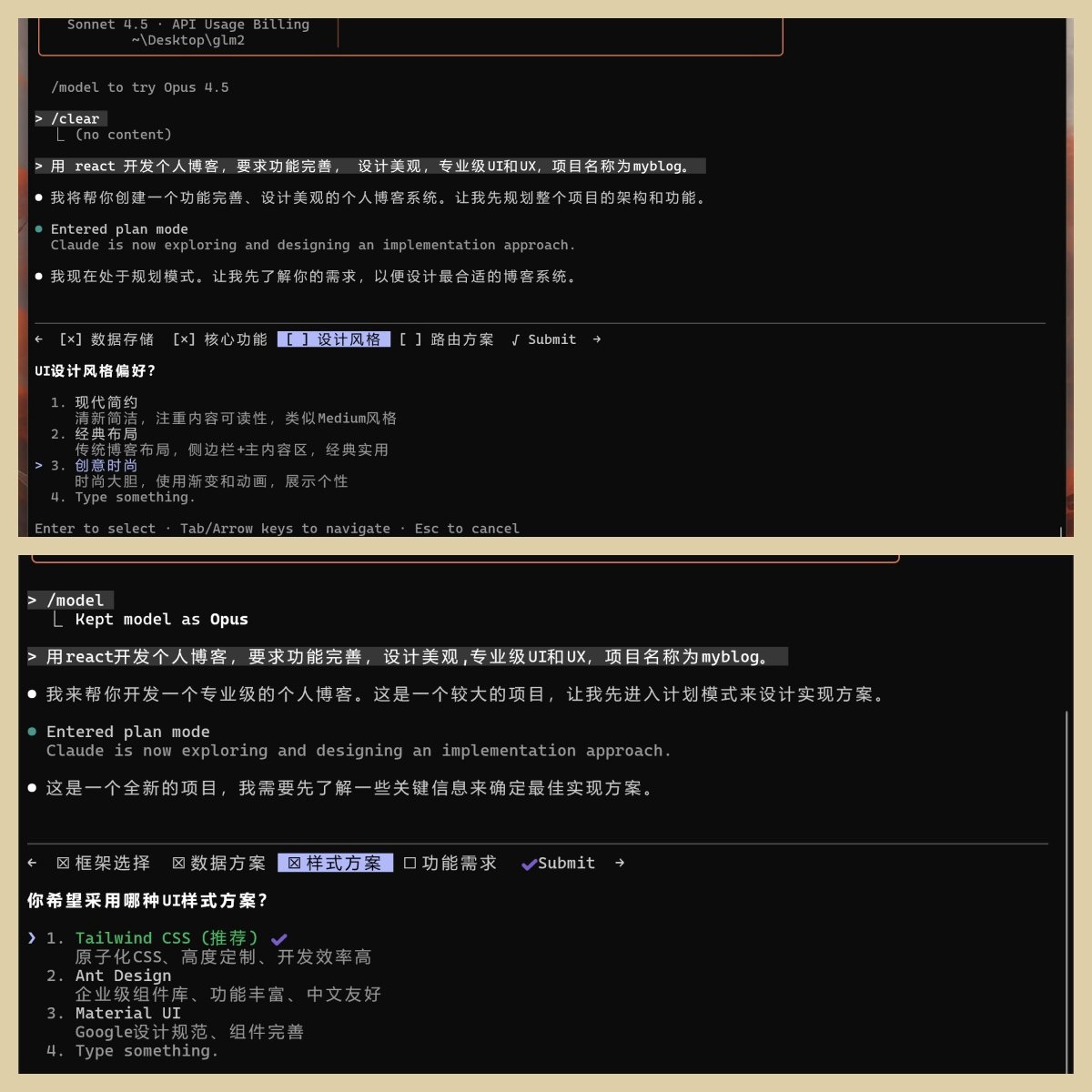
GLM 是设计风格,提供了四个选项。默认为现代简约,我怕简约体现不出实力,就选了创意时尚,给他一点发挥空间。
Claude 是样式方案,也提供了四个选项。因为都标注了明显的(推荐)字样,我就直接选第一个了。
第四步
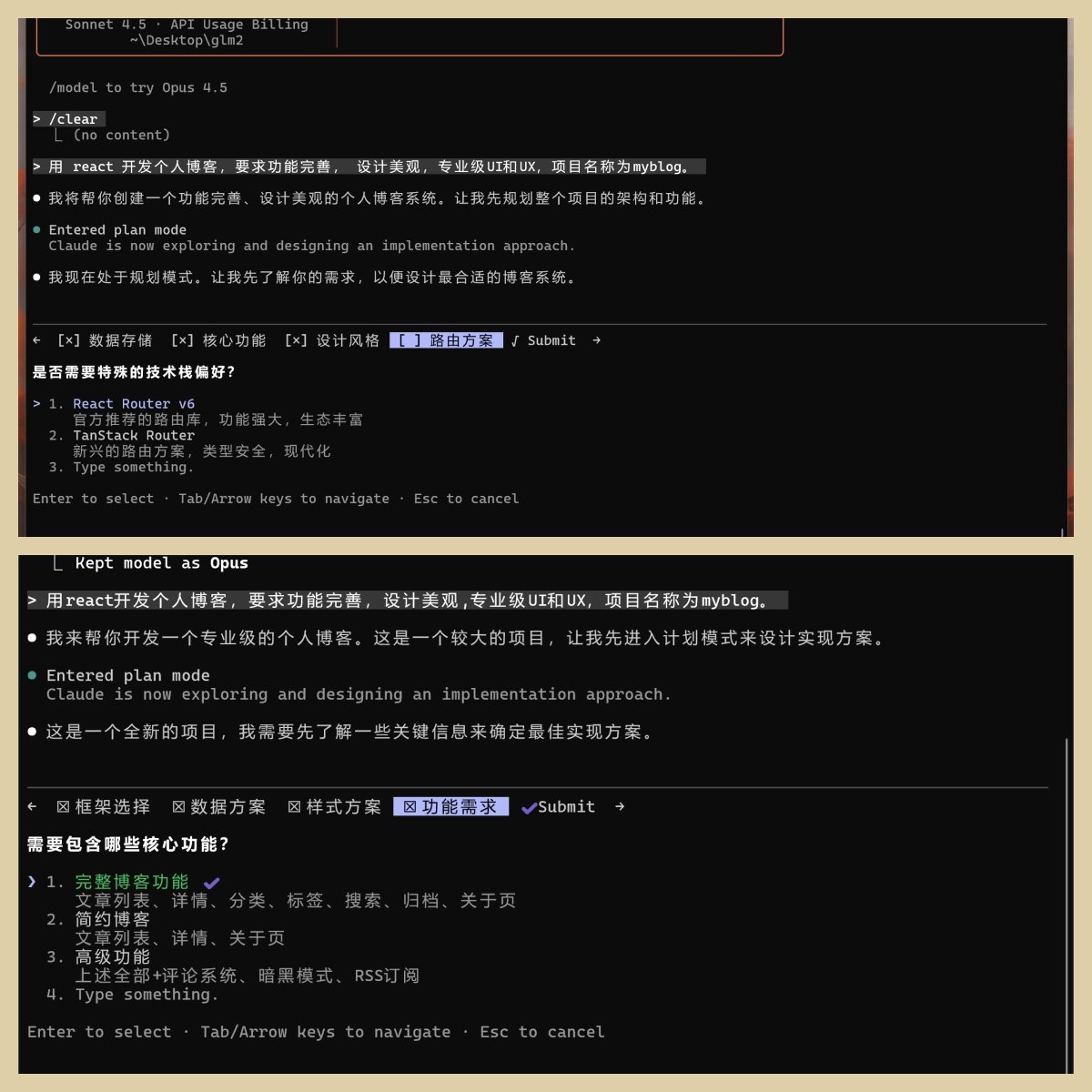
GLM 为路由方案,提供了三个选项。我选默认。
Claude 为功能需求,我看它第一个就规划的还可以,就不选后面了。也是选默认。
对比上面的 GLM 功能需求部分,两个模型都没有想高级功能。这一点是相对公平的。
但是 GLM 我勾选了评论功能,可能对 Claude 有点不公平。主要是 GLM 首选项太简单了,我不加选就没啥功能了。
第五步
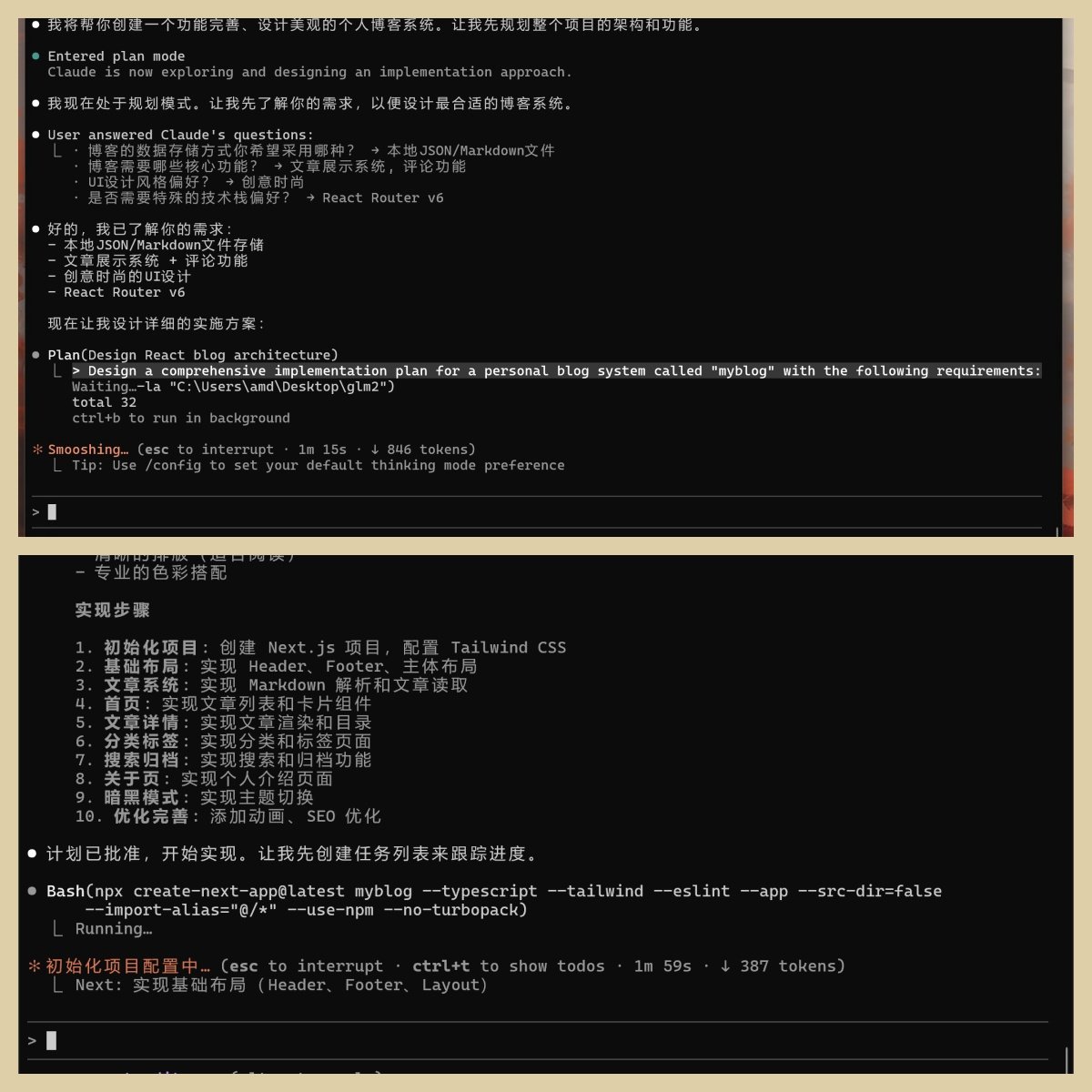
这一步就是 Submit,列出上面的选项,然后就是按计划写代码了。
你们可以看一下。
GLM 是已了解需求,列出了四个选项,然后开始实施方案了。
Claude 写的较多,除了上面的选项之外,写了实现步骤,考虑的比较全面。
结果对比
然后经过了大概 20 多分钟。
两位选手都交卷了。
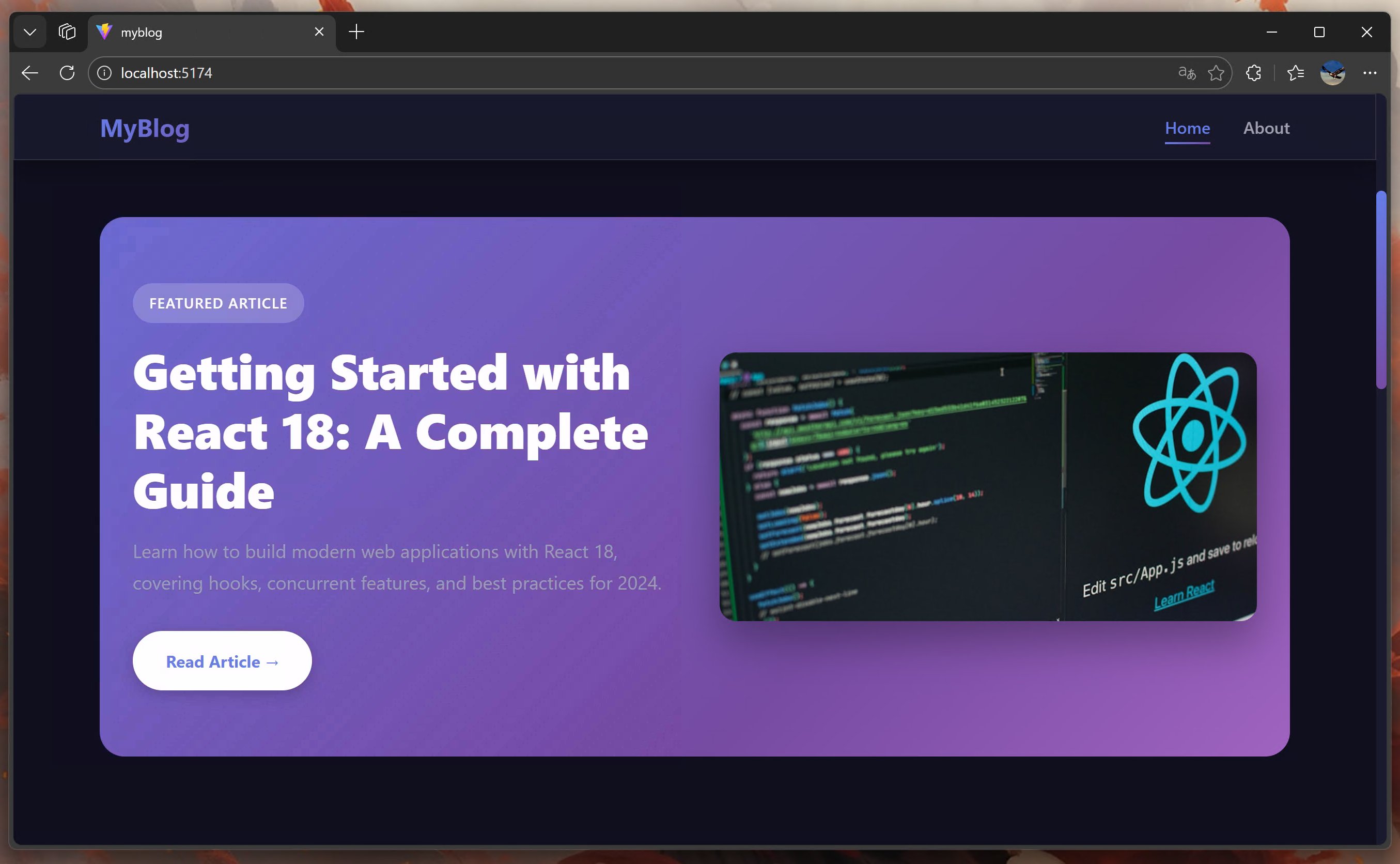
GLM 的网页:
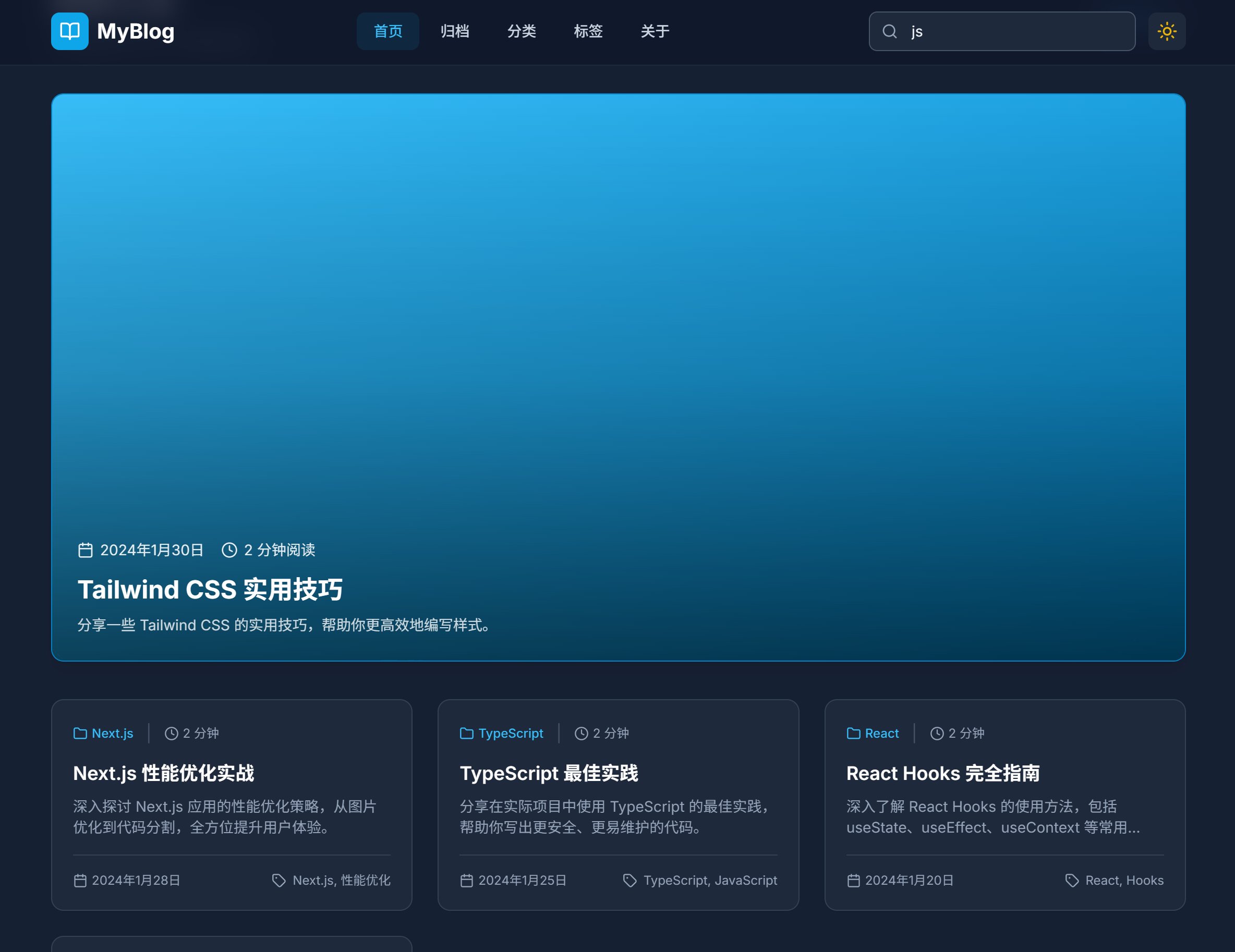
Claude 的网页:
网页比较多,我就不一一展示了。
风格方面不好评判,大家喜好不同,见仁见智。
但是整体来说,两个 UI 都还可以,也没有明显的bug。
一个蓝一个紫,基本把 AI 的风格体现的淋漓尽致了。
唯一我能评判一下的是,Claude 加了个主题切换,GLM4.7 没有这个功能。
从功能模块的角度来看,Claude 应该是比 GLM4.7 好很多。
Claude 首页就包含了,归档,分类,标签,关于,搜索等功能,基本上算是一个功能完善的个人博客了。
GLM4.7 只有首页和关于,也算是一个常见的个人博客,但是功能太单一,谈不上功能完善。
首轮结果回顾
另外开头我说过,其实我之前还进行了一轮开发。之所以有第二轮,是因为第一轮 GLM 表现有点差。
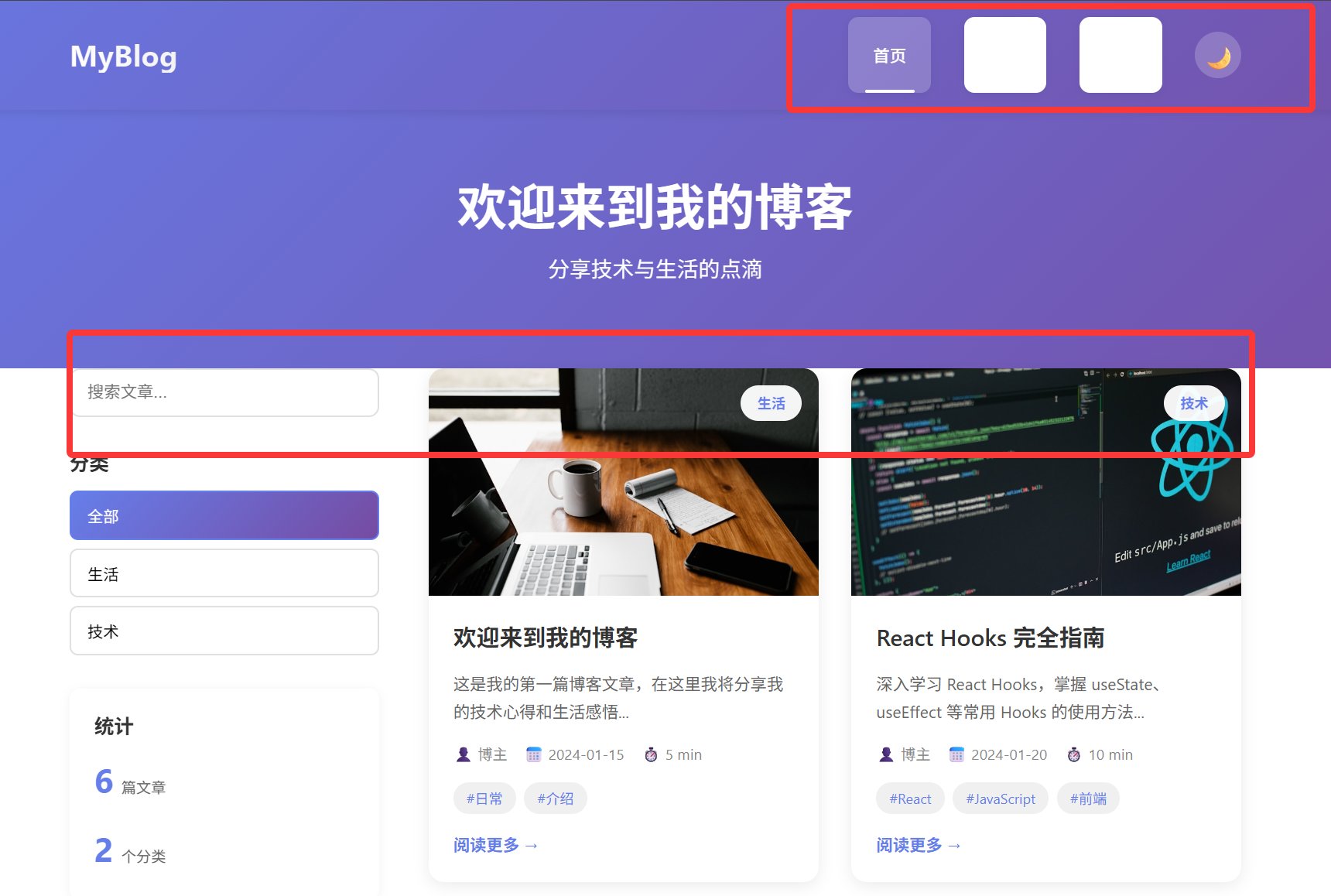
肉眼可见的问题就有两个,一个是导航栏的白色方块,一个是头部和主体内容之间的间距。
我分析了一下原因,可能是因为 GLM4.7 在首次开发的时候,没能主动激活 Plan 功能,所以开发的比较潦草。
从执行过程和结果来看,我是的判断是 Claude 明显更胜一筹。
虽然事实已经很清楚了,但是可以有人会质疑我的判断能力。
毕竟整个互联网上什么样的人都有,有人是拿钱催牛逼,有人是利益相关,有人是单纯觉得国产牛逼。
其实,我也有另外一个疑问:界面都看了,代码质量到底怎么样?
AI测评
关于上面这个问题,我没有能力评判,因为我根本就没看代码,也不想看代码。Code Review 这种事情,就不应该交给人来做,就应该让 AI 来做。
有了思路就好办了。我甚至可以一鱼两吃。
一个是测试 GLM 和 Claude 的代码质量。
另一个是测试一下 Claude Code、Codex、Gemini CLI 的代码分析能力。
这一轮找他们来做评测,大家应该没意见吧,都是顶级 AI 了。
为了公平起见,
我先让 GLM4.7 来评价一下这四个博客项目。
然后让 Claude 来评价一下这四个博客项目。
最后找两位无关人员 Codex 和 Gemini CLI 来评价一下。
全部用最强的模型。
最终的分析测评报告都存在了md文件里面
内容太多,我主要抽取核心部分。
评分如下:
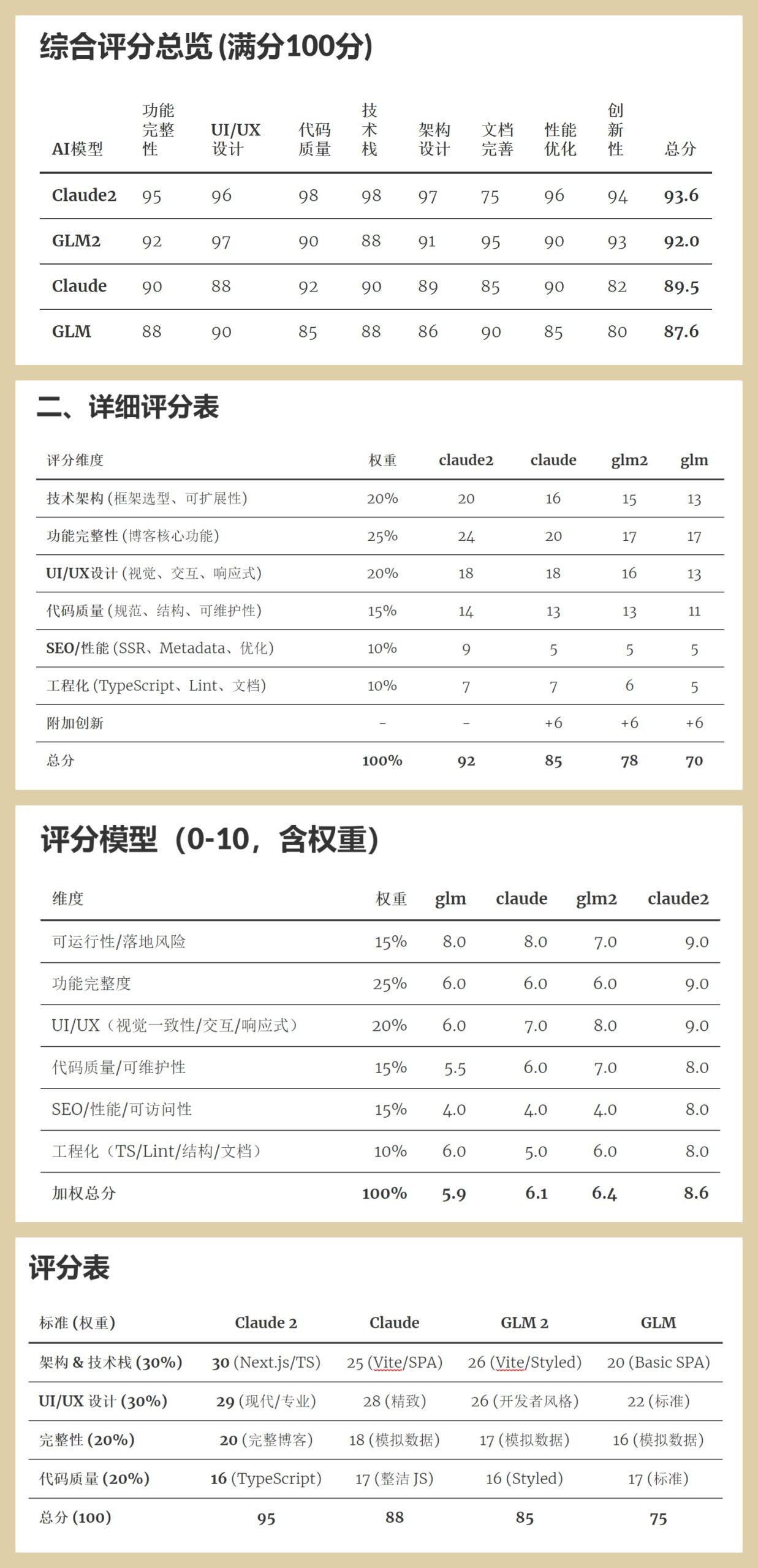
上面四张图,依次为:GLM、Claude、GPT、Gemini 的评分结果。
先来看 GLM 的评价结果:
它认为评分最高的是 Claude2 这个项目,评分最低的是 GLM 这项目。
但是它认为这几个项目差距不大,也就是差个一两分。
再来看看 Claude 的评价:
Claude 从六个维度来进行了评价。他的结果也是 Claude2 最好,GLM 最差。
它居然还是第二名,第三名,第三名,加了 6 分的创新附加分……
但是 Claude2 这个项目,已经远高于其他三个项目。
Claude 作为最强编程 AI,在它的视角中 GLM 和 GLM2 在附加费之后还是不到 80 分。
从上面两位参赛选手都评价来看。都认为 Claude2 相对较强。差异在于 GLM 认为大家差距不大,Claude 认为,差距很大,对手不到 80 分。
下面看看 GPT5.2 的评价:
GPT 也认为最好的是 Claude2,最差的是 GLM。
但是它打分更严格,GLM 直接 5.9 分不及格,GLM2 也才 6.4 分。当然 Claude 也才 6.1 分,只有 Claude2 拿下了 8.6 分。
GPT5.2 典型的装逼犯啊,你们都不行,在我这里不可能拿高分。哈哈~~
最后看下 Gemini3pro 的评价:
G3 也认为最好的是 Claude2,给出了 95 分。最差的是 GLM,只有 7.5 分。
我看了一圈,我的评价好像和 Claude 的评价比较接近。
另外,我也看了一下这几位评委分析报告。
GPT5.2 实在是太油腻了,上拉就是“结论(先看这个)”,另外一个感受是太慢了,所有人中最慢!
Gemini3 效率很高,人狠话不多,结果默认为英文,有点难看,报告本身写的还比较清晰的。
Claude4.5 是个很全面的人,本以为只会写后端代码,其实前端也不错,写分析报告也是一把好手。
GLM4.7 没想到他是一个写报告的高手,对不对说,字数它最多。
为了全面测评,我准备了好久,也花了好多时间。我的想法是一天测一个例子,测它 30 天。
但是看完第一个例子,我感觉好像没必要测太多了。Claude贵有贵道理吧。
当然也可以换个角度说,GLM4.7 也不是不能用啊,都像模像样呢,便宜还不用翻 Q。
我自己编程用的话绝对会选顶级AI,但是其实很多场景是不需要顶级能力的。
GLM4.7替代Claude是不可能,但是作为平替还是可以尝试的一个方向。
主要是价格太优惠了,我为了测试只开通了GLM Coding Plan·跨年特惠中的lite版本,三个月54,根本用不完。
如果是Max的话,感觉都可以拿来跑在线业务了。主打一个量大,管饱,便宜。

240包年。。。。你敢想啊!
注意这个是可以直接用API的,不是只有账号授权登录的。
还有就是,国内业务可以合理合法调用。
我好像没国内业务…哈哈!
今天的例子属于非常常见的例子,下次找一个不常见的,无法预训练刷分的例子。
或者找一个提示词比较精确的,看他们指令执行能力如何。
大家有没有好的测试实例?
关于作者
tony
某人