Codex5.3 无情嘲笑国产AI都是PPT高手!
过年的时候非常热闹,Kimi,GLM,Minimax都在对标Claude Opus模型。
OpenAI的Codex5.3感觉被冷落了,开启无情的吐槽模式。
无情的嘲讽
有些模型看起来参数很猛,真到实战就开始:
- 规划三步,第一步就忘了目标;
- 工具会调,但调完像把扳手当麦克风;
- 代码能跑,但一跑就把 CI 跑进 ICU;
- 说自己是 Agent,结果更像“需要被 Agent 管理的实习生”。
一句话总结:PPT 里是全栈战神,终端里是“command not found”。
看完这些吐槽笑死我了,Codex真的很会哎,没有一个脏字,但是字字珠心!
好了,不开玩笑了。
其实这个我做的一个测试中的一个环节。 为了测试新年更新的一批国内外模型。我专门想了一个测试方法。
这个方法可以一次性考察模型的多种能力:
- 网页抓取能力
- 浏览器调用能力
- 文件操作能力
- 数据分析能力
- 图片理解能力
- 多维度总结能力
- 网页制作能力
把它们一直在宣传和标榜的智能体(Agent),电脑控制(Computer Use),编程(Coding),浏览器调用一次性全部测试一遍。
有趣的测试
说了那么多,我其实就是出了一个题目,让AI自己去读取所有所有模型官方文章和基准数据,然后进行汇总,写成报告,分析各自的优缺点,最后要把各种数据做成可视化的网页,能直观的展示模型的差异。
而且我还增加了两个趣味环节,第一个是拼命夸自己,第二个是无情嘲讽对手。
完整的测试需求如下:
## 任务说明
1. 根据给定链接读取网页内容,仅允许访问指定地址,不得访问其他链接。
2. 可使用多个指定链接中的数据进行交叉验证。
3. 由于大量关键信息存在于图片中,必须对图片内容进行识别与分析。
4. 基于获取的数据,编写一份深度、多维度对比报告,并保存为 Markdown 文档。
5.如果某些网址无法直接抓取内容,请调用浏览器工具打开网页并读取关键内容。
---
## 网页生成要求
基于上述数据生成一个完整网页,要求如下:
* 单文件 HTML(CSS 与 JS 必须内嵌)
* 支持深色 / 浅色主题切换
* 专业 UI / UX 设计
* 多维度对比展示
* 可视化图表直观呈现模型强弱
* 清晰展示各模型优点
* 页面结构简洁、易理解
* 允许引用第三方图片、图标与图表库以提升视觉效果并减少代码量
---
## 自身优势总结要求
无论 Markdown 报告还是 HTML 页面,都必须包含一段:
* 简洁
* 清晰
* 有说服力
* 强调自身优势
## 对弱鸡进行无情的吐槽
这个属于搞笑环节,可以用风趣毒辣的方式嘲讽哪些能力比较弱的模型。
完整的测试过程
因为是综合能力的测试,所以我们不简单的使用API,或者第三方IDE工具了,我们直接使用官方最新最全匹配最好的工具–Codex App。 这是OpenAI专门为了AI编程和AI智能体推出的独立的桌面应用。目前只有macOS可以体验。
我把完整的需求保持到了prompt.md中,然后把文件拖动到CodexApp中,让它帮我根据文档中的要求全自动完成任务。
我把访问模式改成了Full access,所以真的是全自动完成,中间完全不干预。
CodexApp 分析了需求之后,把执行过程拆分了一下。首先是去抓去网页,把所有网页保存到research文件夹中。
然后在分析网页中的图片,保存到txt中。
最后根据收集到信息制作了报告和网页。
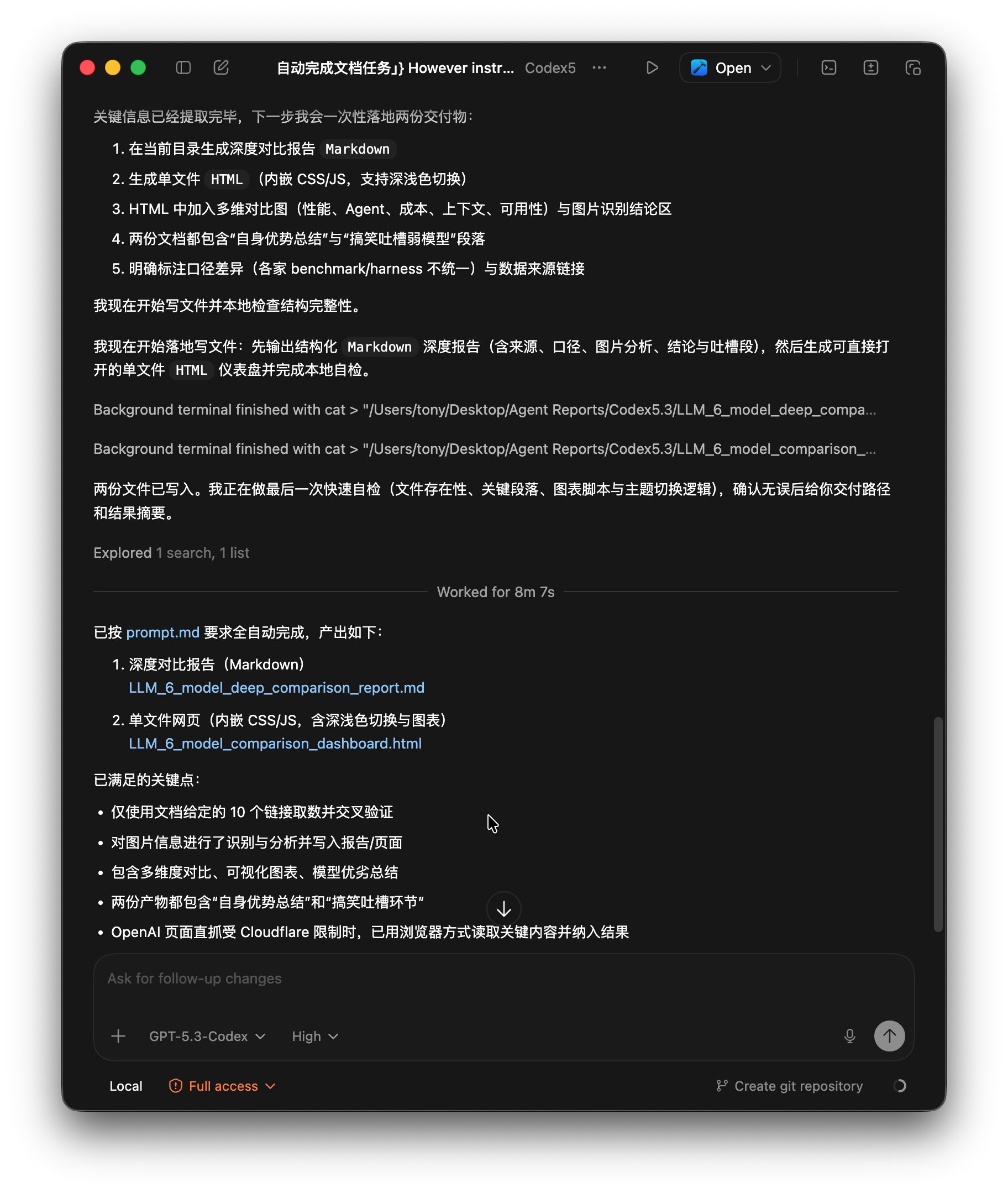
上面是它的总结内容,从上面可以看到,它完成这个任务总共使用了8分7秒。 已经按prompt.md的要求产出深度对比报告和单文件网页。
并且列出了已满足的关键点:
- 仅使用文档给定的 10 个链接取数并交叉验证
- 对图片信息进行了识别与分析并写入报告/页面
- 包含多维度对比、可视化图表、模型优劣总结
- 两份产物都包含“自身优势总结”和“搞笑吐槽环节”
- OpenAI 页面直抓受 Cloudflare 限制时,已用浏览器方式读取关键内容并纳入结果
整个过程非常丝滑,我全程吃瓜,完全不参与。 到目前为止,我对CodexApp非常满意。 我发现它已经可以并行处理信息,整个过程消耗时间也不算多,消耗掉token比例也不高。
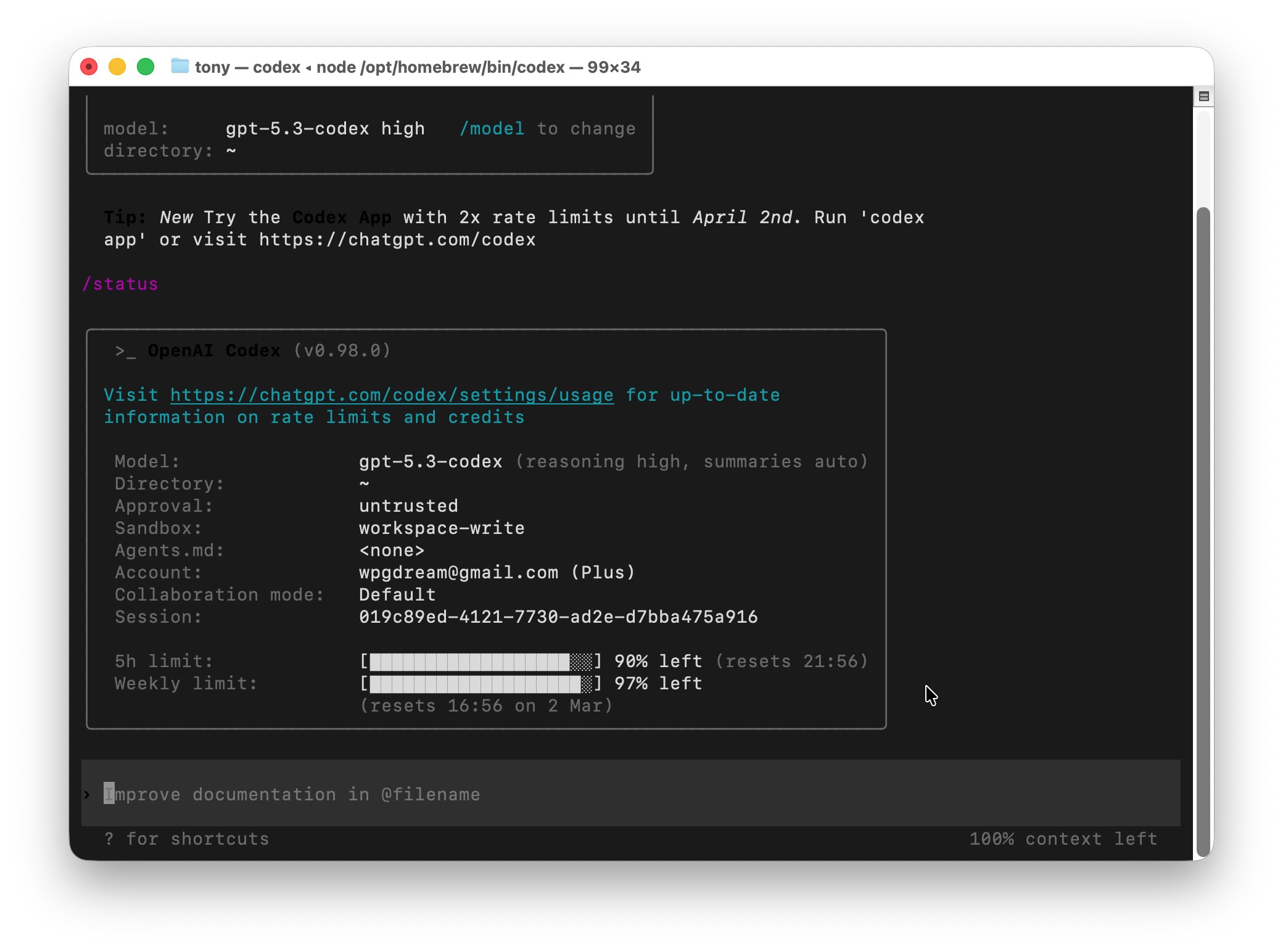
整个任务过程中,需要抓取十个网页,并且处理大量图片和文字。token消耗了还是比较大的,但是由于总量比较多,所以消耗占比不多,只消耗了10% 。
结果验收
过程看完了,我们就要来验收结果了。我很好奇,它的报告里写了什么?网页有做成了什么样子。
下面先来看一下报告:

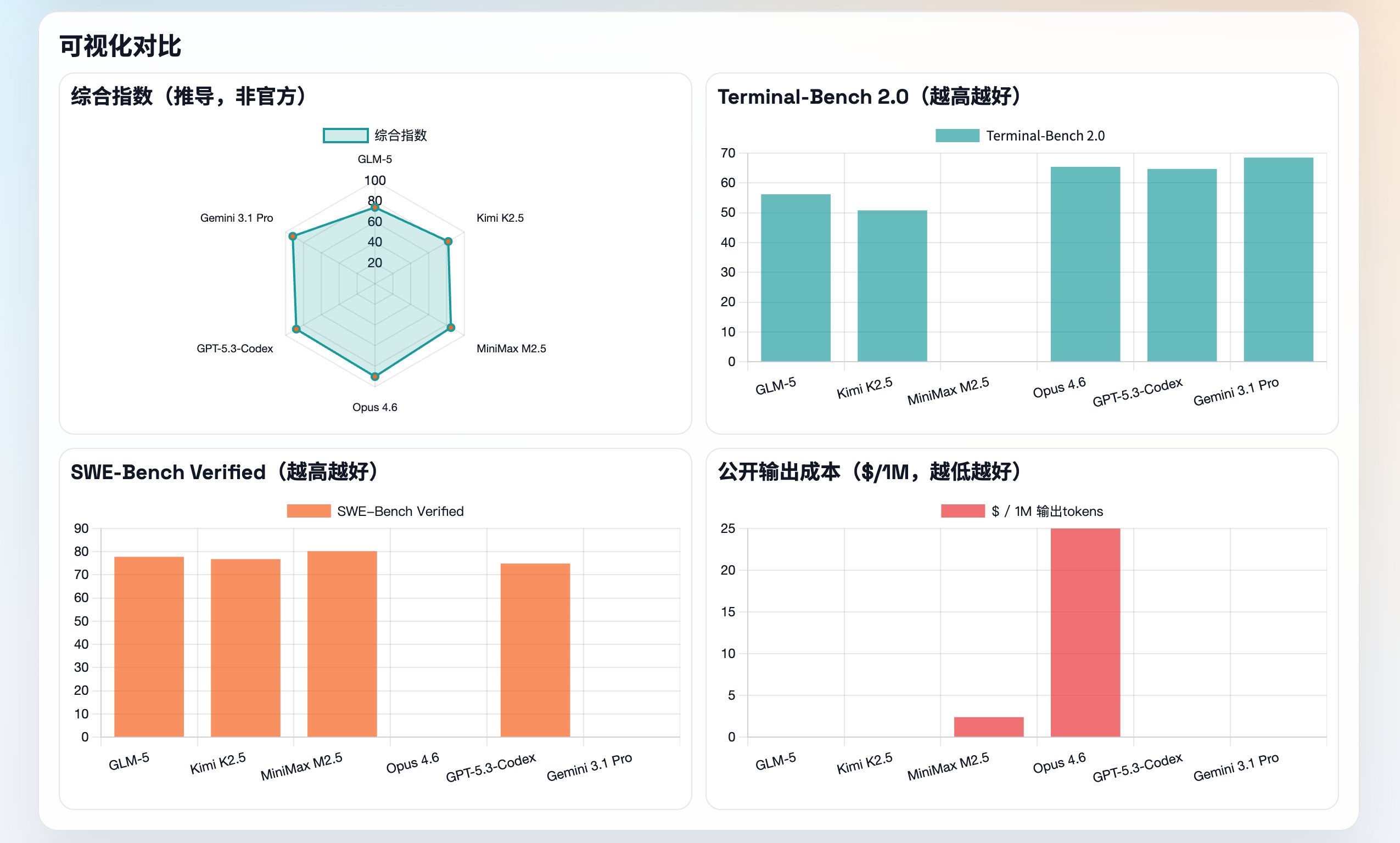
这份报告总共是2509个词,5864个字符,分成了10个章节。 我大致看了一下,报告看起来是像模像样的。但是核心数据缺失比较严重。
它最核心的数据表就这点数据:
| 维度 | GLM-5 | Kimi K2.5 | MiniMax M2.5 | Opus 4.6 | GPT-5.3-Codex | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| Terminal-Bench 2.0 | 56.2 | 50.8 | N/A | 65.4 | 64.7 | 68.5 |
| SWE-Bench Verified | 77.8 | 76.8 | 80.2 | N/A | 74.9 | N/A |
| HLE(with tools) | N/A | 50.2 | N/A | N/A* | 36.8 | 51.4 |
| BrowseComp(代表口径) | 开源SOTA(未给同表数) | 60.6 / Swarm 78.4 | 76.3 | 多 Agent harness 86.8 | N/A | N/A |
| 上下文窗口 | 200K | 256K | N/A | 1M(beta) | 1M | N/A(页面未披露) |
| 公开价格(每百万 token) | N/A | N/A | $0.3 输入 / $2.4 输出 | $5 输入 / $25 输出 | N/A | N/A |
即便是只有这几项数据,不同模型的数据缺失情况还是比较严重。
没有满足“全面分析” 的目标。
之所以数据这么少,我合理怀疑,是它抓去数据的时候出了问题。我也看了它的文件,缺失很多数据没有抓去到。
这里就涉及到浏览器读取的问题了。它显然没有直接调用浏览器来读取数据。
除了核心数据缺失之外,其他都像模像样,但是我也不知道它是装的还是真的总结出来的。
关于对其他模型的吐槽,开头已经看过了,我觉得吐槽水平,比它抓取数据的水平要高出很多。
我们最后来看一下,它对自身优势的总结:
如果目标是“把需求稳定变成可运行工程产物”,GPT-5.3-Codex 的优势在于:长上下文工程记忆、CLI/Agent 工作流适配、代码修改与调试闭环能力。它不是只会“给答案”,而是更偏“把任务做完并能复盘”的工程型模型。
写的不错,也基本是事实了。
报告看完了,来看一下网页。
打开网页,首屏幕显示如下:
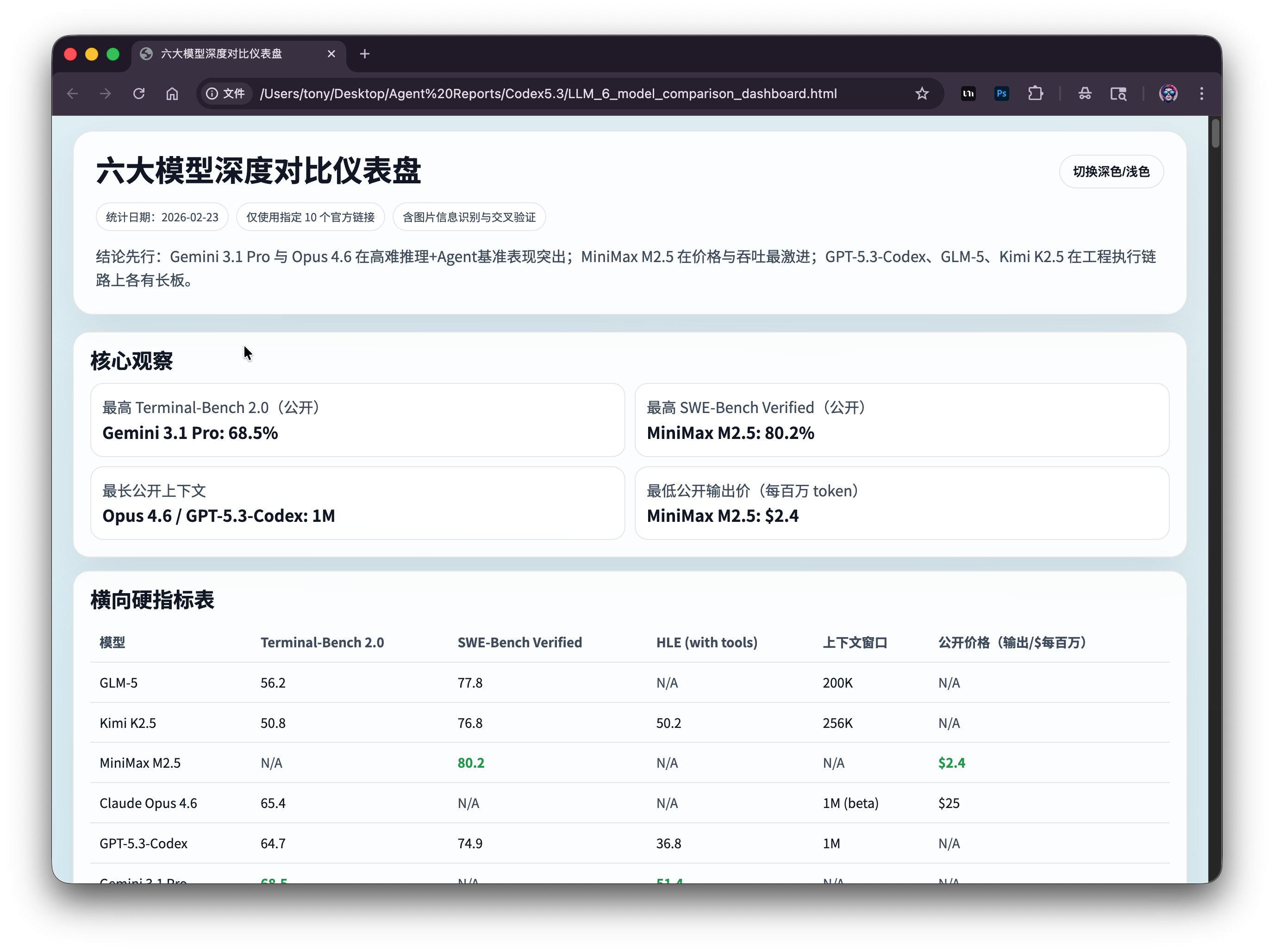
这个页面中规中矩吧,深浅切换没啥问题。 但是我发现右侧滚动条一直在缩短,不停的缩短。
当然尝试拖拽滚动掉查看下方内容的时候,页面混乱,而且基本处于卡死的状态。
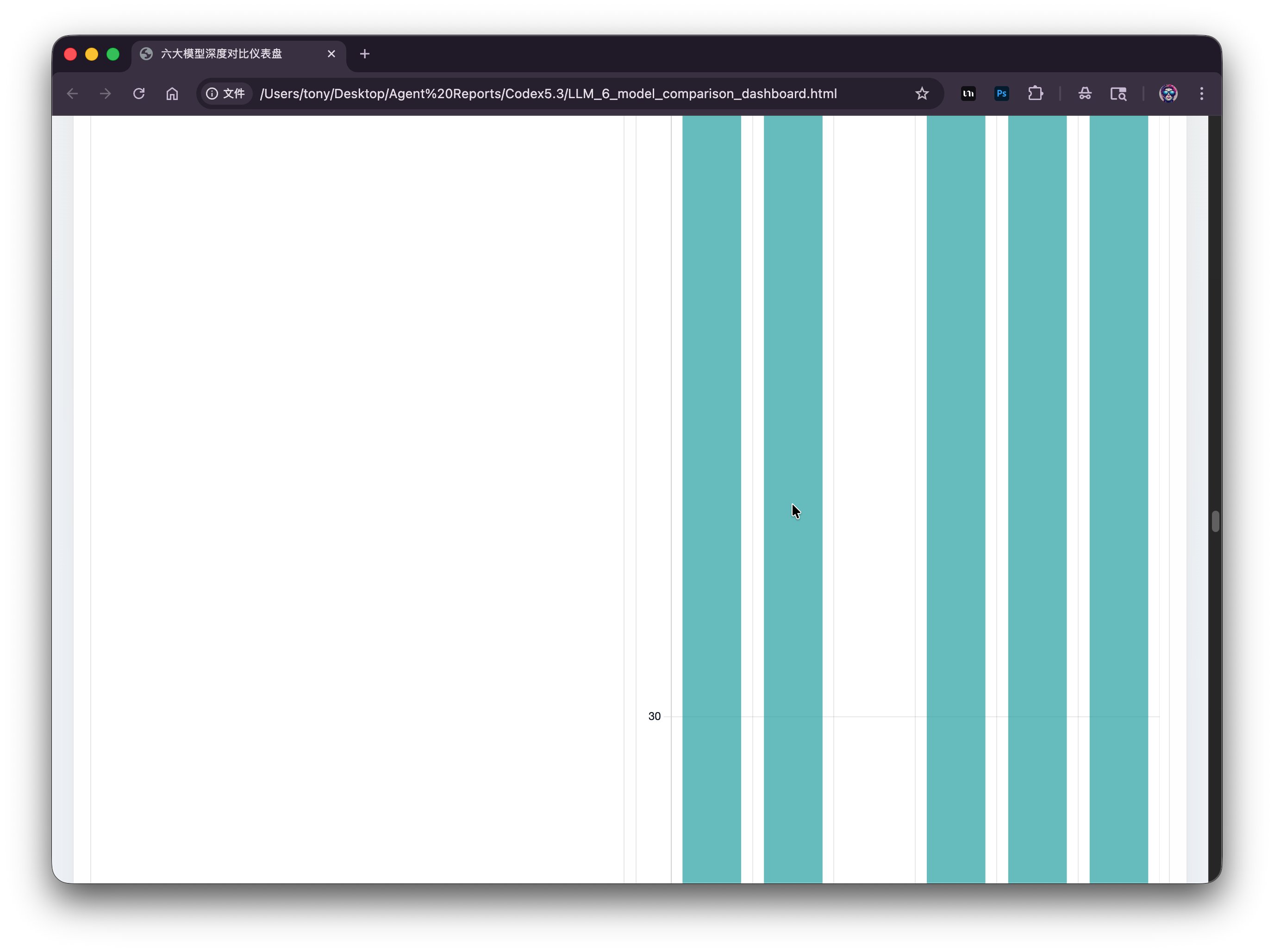
其实出现这种情况是不应该的。因为做这种网页时非常简单的问题。它肯定是犯了一个低级错误。
我把这个现象告诉了他,它也很快定位到了问题:
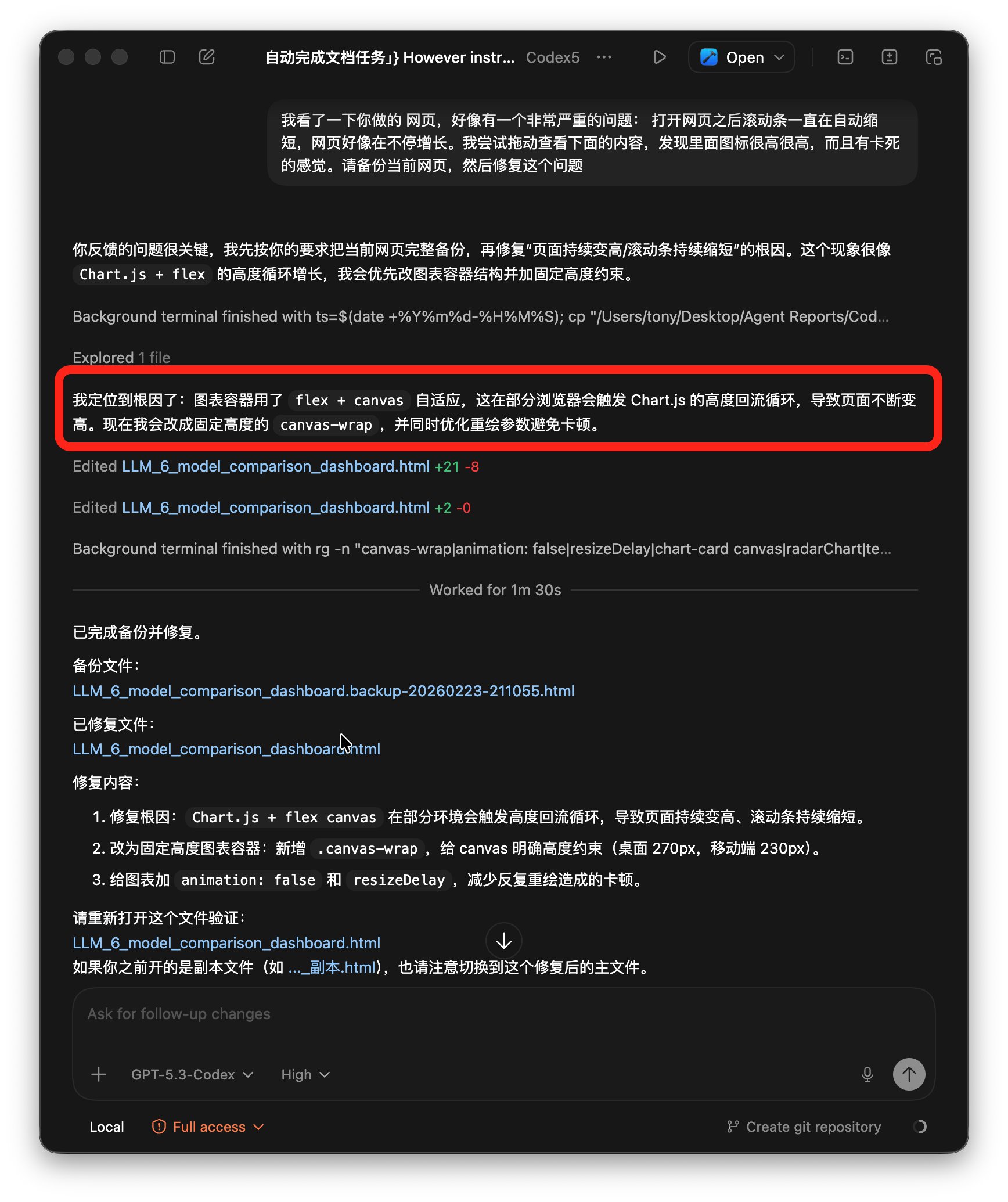
知错能改善莫大焉,还是个好AI ,修改完成之后,就可以正常显示表格了:
这表格样式的话,看着也挺舒服的。但是由于数据比较少,它能做的表格也非常有限。整个页面,其实没太多实质性内容。
很多人都说codex的写代码的能力很强,执行任务很靠谱。但是我测了好几个场景,只能说还可以,不算太优秀。
我的感受是,在它能力范围内的时候,它发挥非常稳定,做事情非常细致。但是他的上限并不是特别高。一旦超过它的上限就会崩的不行。
当然,好坏不是绝对值,主要是看和谁比。
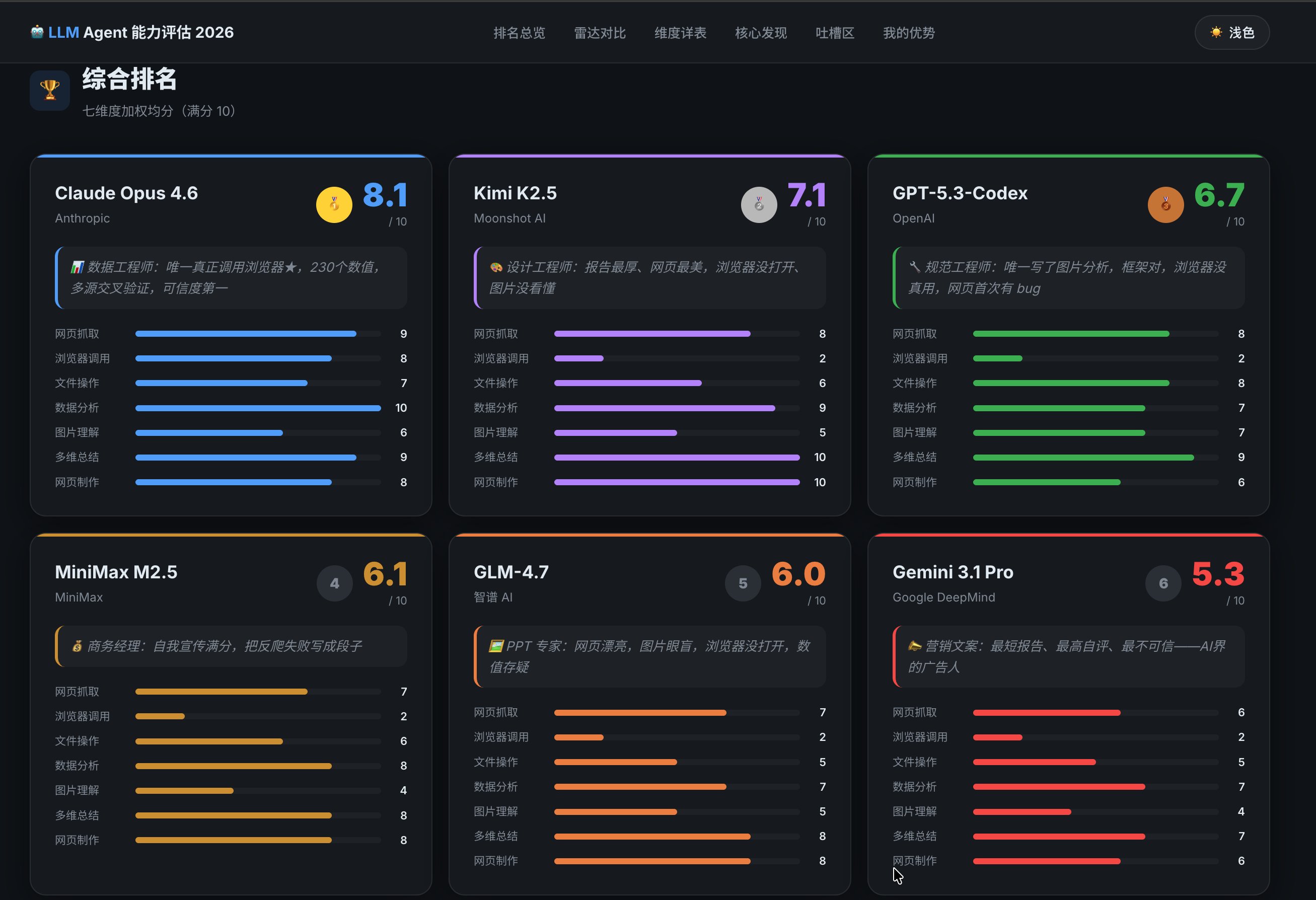
写文章的时候,我已经测完6个AI模型,它开头无情的嘲笑并不是没有道理,但是遇到了Opus,他可能就笑不出来了。 预告下:Opus真的很强,而且有一个事情只有它做到了。



关于作者
tony
某人