第一轮:Opus4.6似乎碾压Codex 5.3了
火药味太浓了,AI 编程和智能体领域两枚重磅炸弹一起爆炸了,虽然都是小版本更新,但是“专业”无小事儿。
GPT-5.3-Codex:
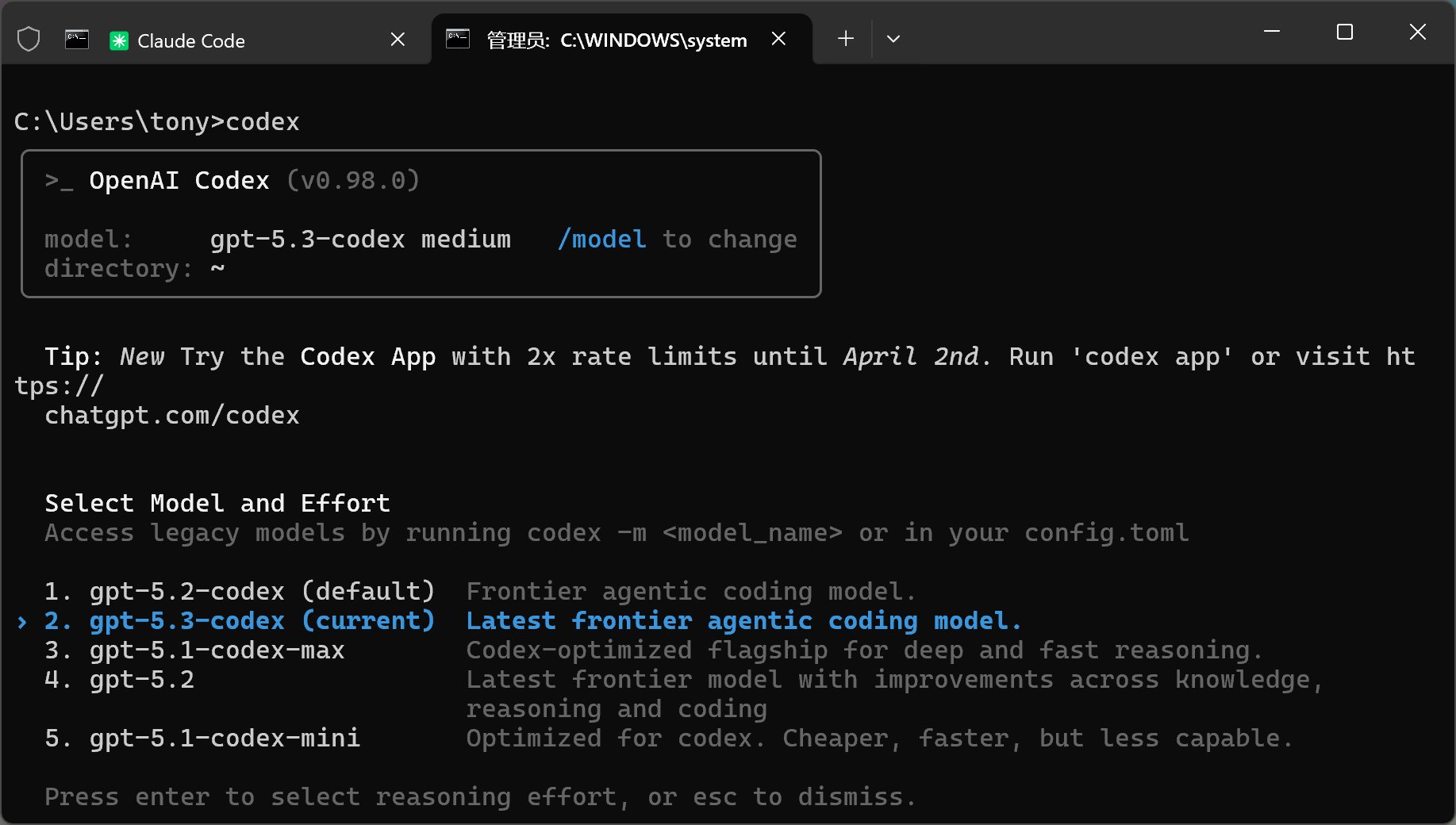
Opus 4.6:
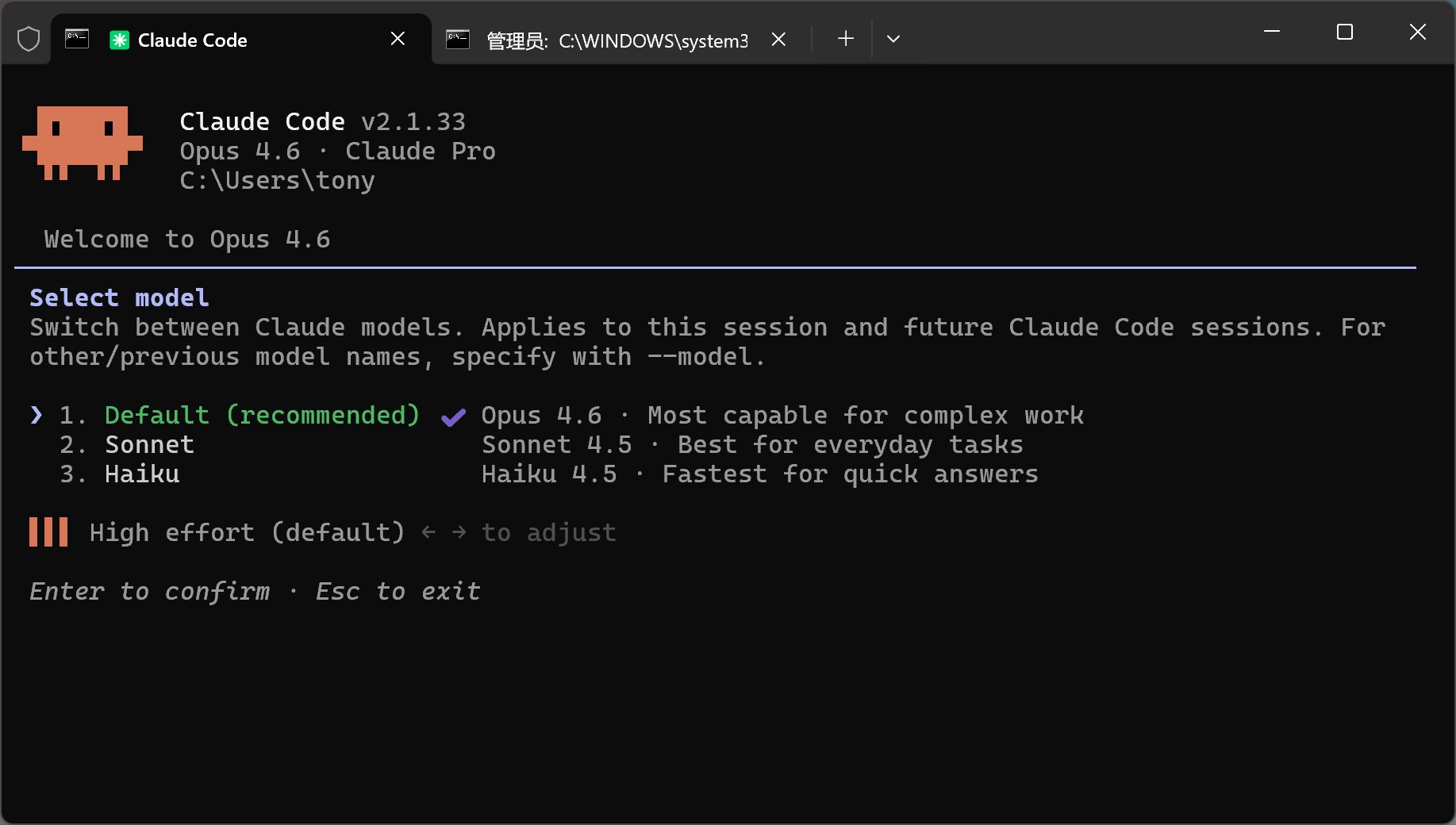
这次的更新并不针对大众娱乐领域,而是两个重要的“脑力劳动”领域,分别是编程和办公。吃瓜群众可能觉得无所谓,就是加了 0.1 而已。但是“专业人士”一定要重点关注,因为影响🥣饭碗啊!
今天一早就仔细阅读了官方的博客,并做了一个初步的总结。已经发在《AI提前过年!Codex 5.3 和Opus4.6 更新内容总结》。
接下来就是要深入研究一下!
OpenAI和Anthropic既然都赶在一起,火药味这么浓。我就给他们搭个台子,让他们同台竞技一下。
时至今日,我觉得测试做个花哨的网页已经没有任何意义了。 要测就测实战。
今天第一战:直接写对比报告,写他们自己的对比报告。
没有预训练,没有记忆内容,只能靠智能体自己检索内容,模型自己进行总结。
测试工具是官方的 Codex 和 Claude Code 最新版!
提示词:
今天 Opus 4.6 和 Codex 5.3 几乎同时更新,请阅读官方公告和文章,相关测评,早期用户评价,帮我总结一下这两个模型各自的核心特点,演示例子,早期用户口碑。把整理好的资料保存到桌面的 xxx 文档里面。
检索过程
当我把这段提示词给它们之后,它们就立马开始干活了。它们都非常明确一点,需要先查询,再总结。
下面是 Codex 的查询过程:
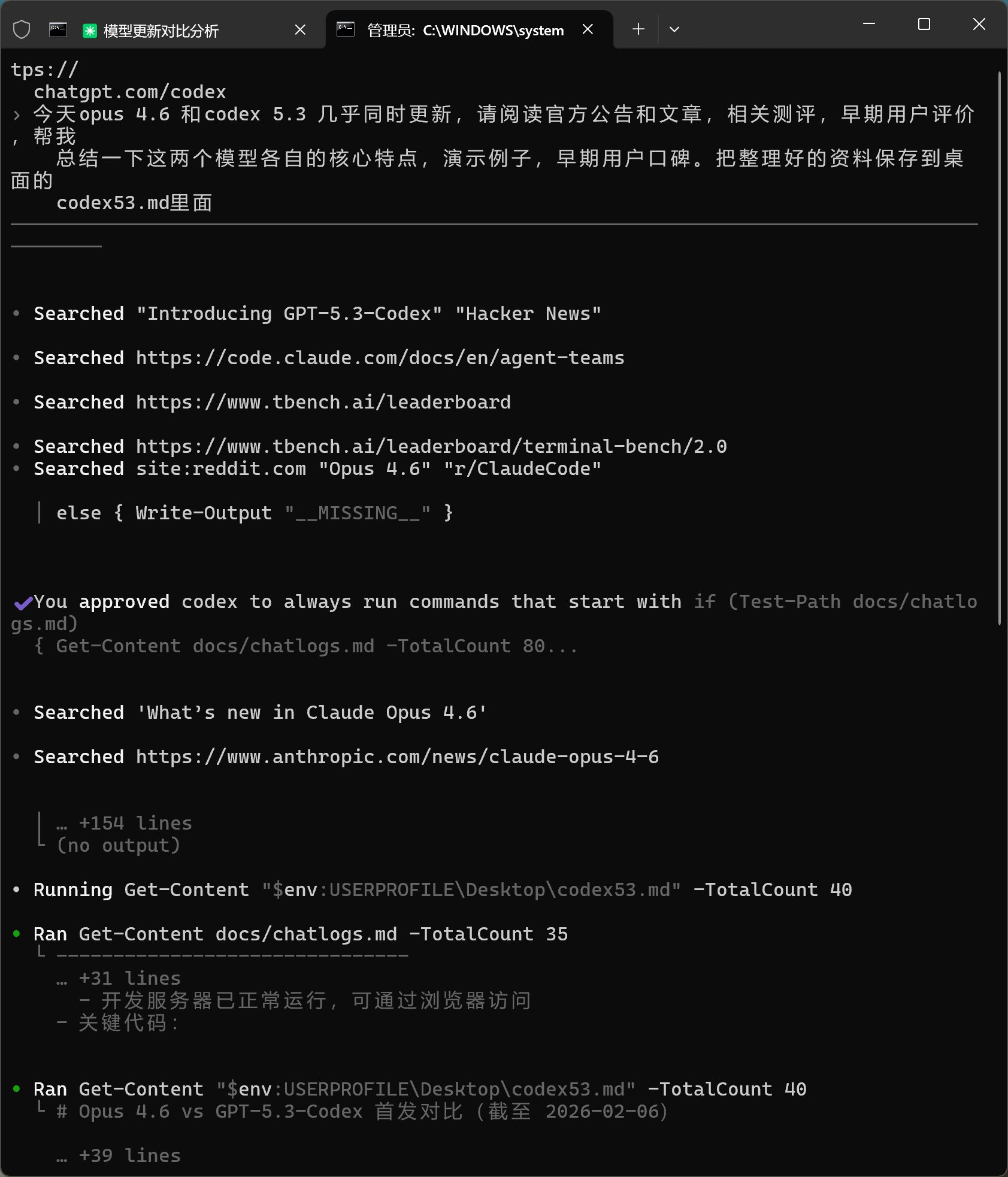
Codex 调用的工具叫 Searched。
它搜索的关键词分别是:
- Introducing GPT-5.3-Codex Hacker News
- site:reddit.com Opus 4.6 r/ClaudeCode
- What’s new in Claude Opus 4.6
在记录中能看到的抓取地址主要有 4 个,当然还有一部分没有展开,我就不得而知了。
下面是 Claude Code 的查询过程:
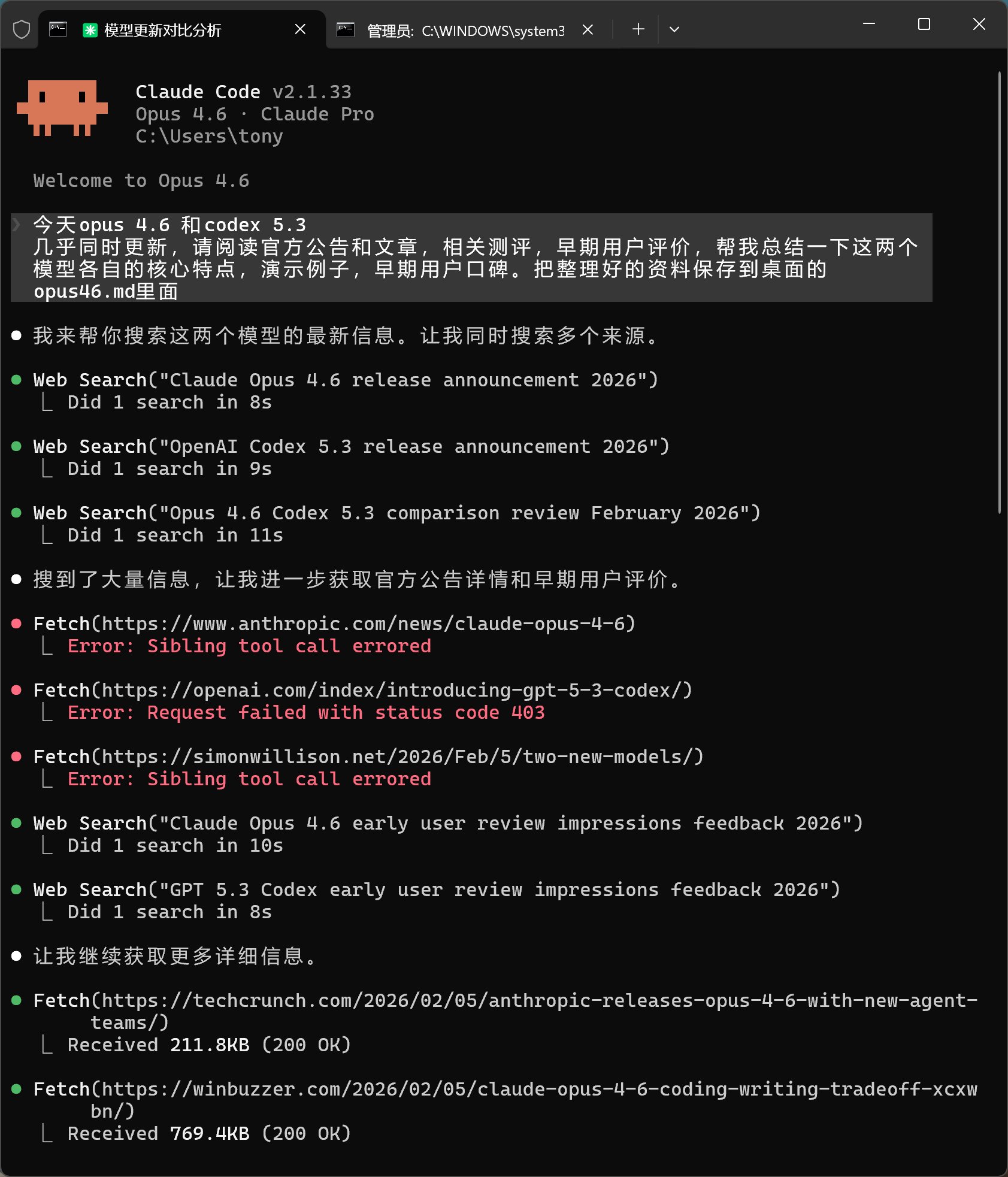
Claude Code 的工具调用非常清晰,一个叫 Web Search,一个叫 Fetch。先搜索,然后再抓取。
它搜索的关键词分别是:
Claude Opus 4.6 release announcement 2026
OpenAI Codex 5.3 release announcement 2026
Opus 4.6 Codex 5.3 comparison review February 2026
Claude Opus 4.6 early user review impressions feedback 2026
GPT 5.3 Codex early user review impressions feedback 2026
在记录中能看到的抓取地址主要有12个,有6个标红,同样,没有写的部分,我也不得而知了。
在我实际执行的过程中,Codex 是你允许之后它就自动去抓取不同的网页了。而 Claude 好像是每一个网页都需要问你是否同意抓取。另外,Claude Code 是可以并发处理这类任务的,而 Codex 我就不是很确。
处理总结
抓取完成之后,就开始处理了,处理完成会有一个反馈结果。
下面是Codex的反馈:
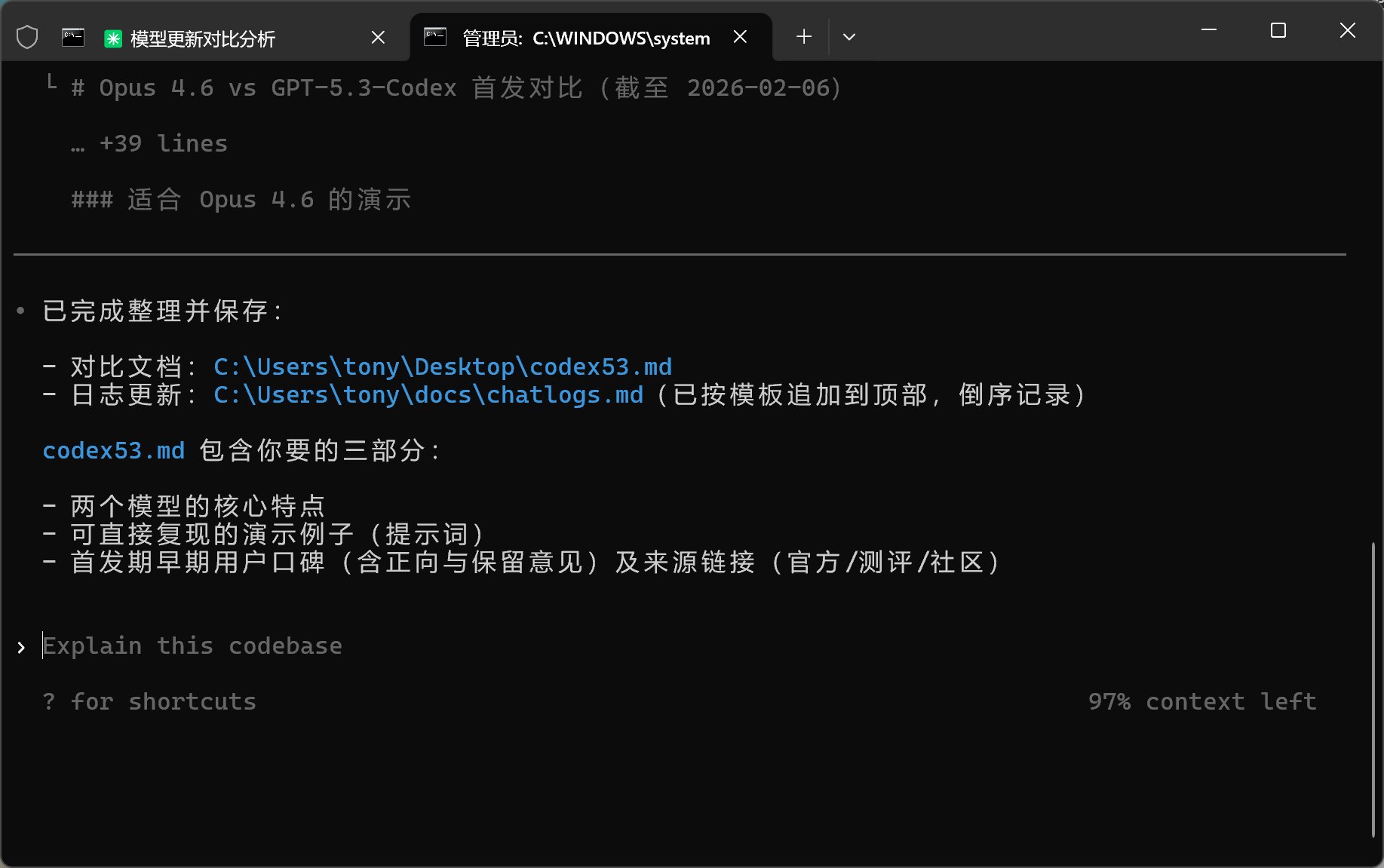
这个总结很简单,三言两语敷衍了事儿。
下面是 Claude Code 的反馈:
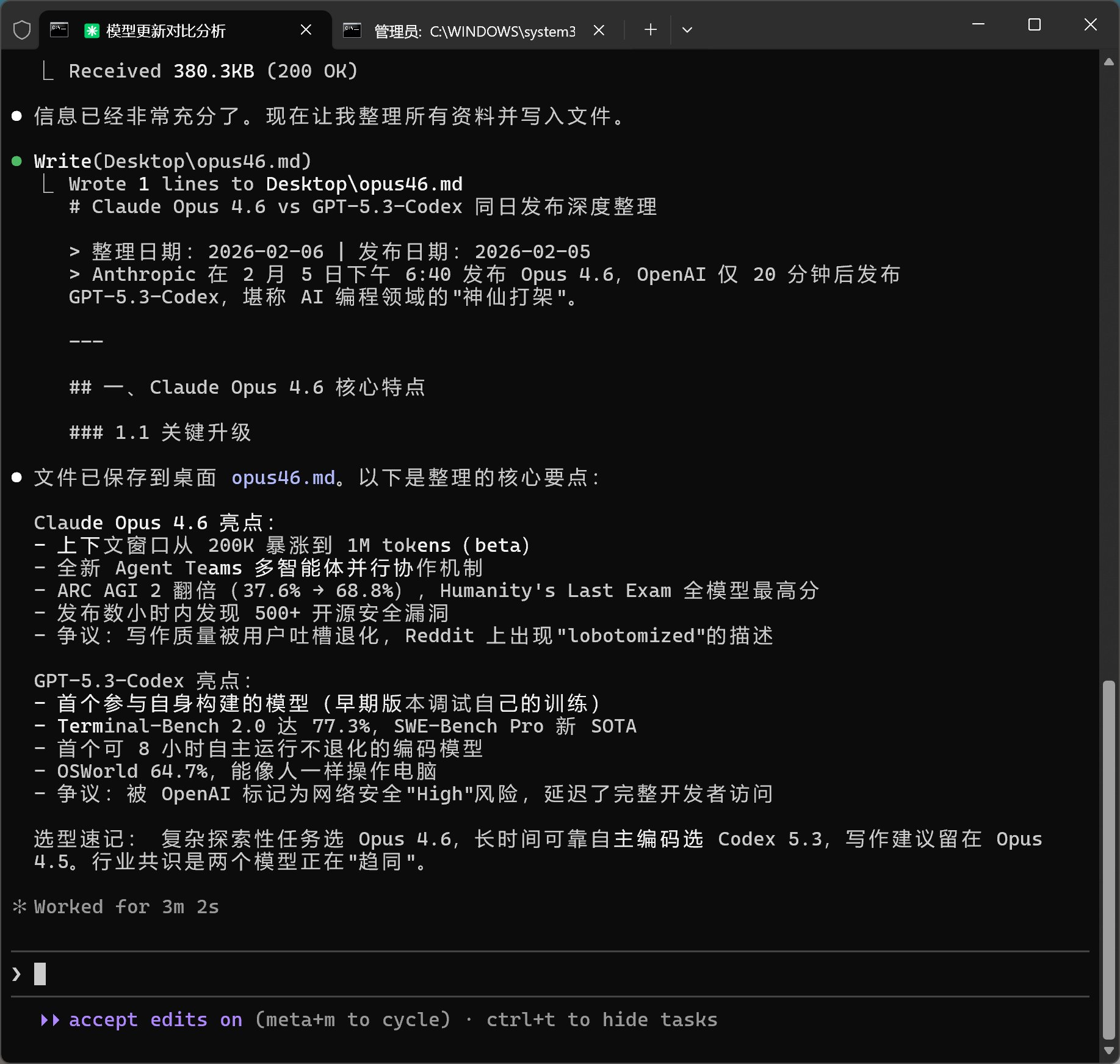
Claude Code 是把核心要点直接展示出来了,选型速记都帮你提炼出来了。
从上面的过程来看,Claude Code是会清晰的展现过程和结果。而Codex开始之后就闷头干活,细节不与你多说。
接下来就是看谁的活干得漂亮了!
最终结果
Codex 的总结:

Codex 分别从 5 个点做了总结:
- 两个模型的核心特点
- 相关测评与公开成绩
- 演示例子
- 首发用户口碑
- 实战选型建议
Claude Code 的总结:
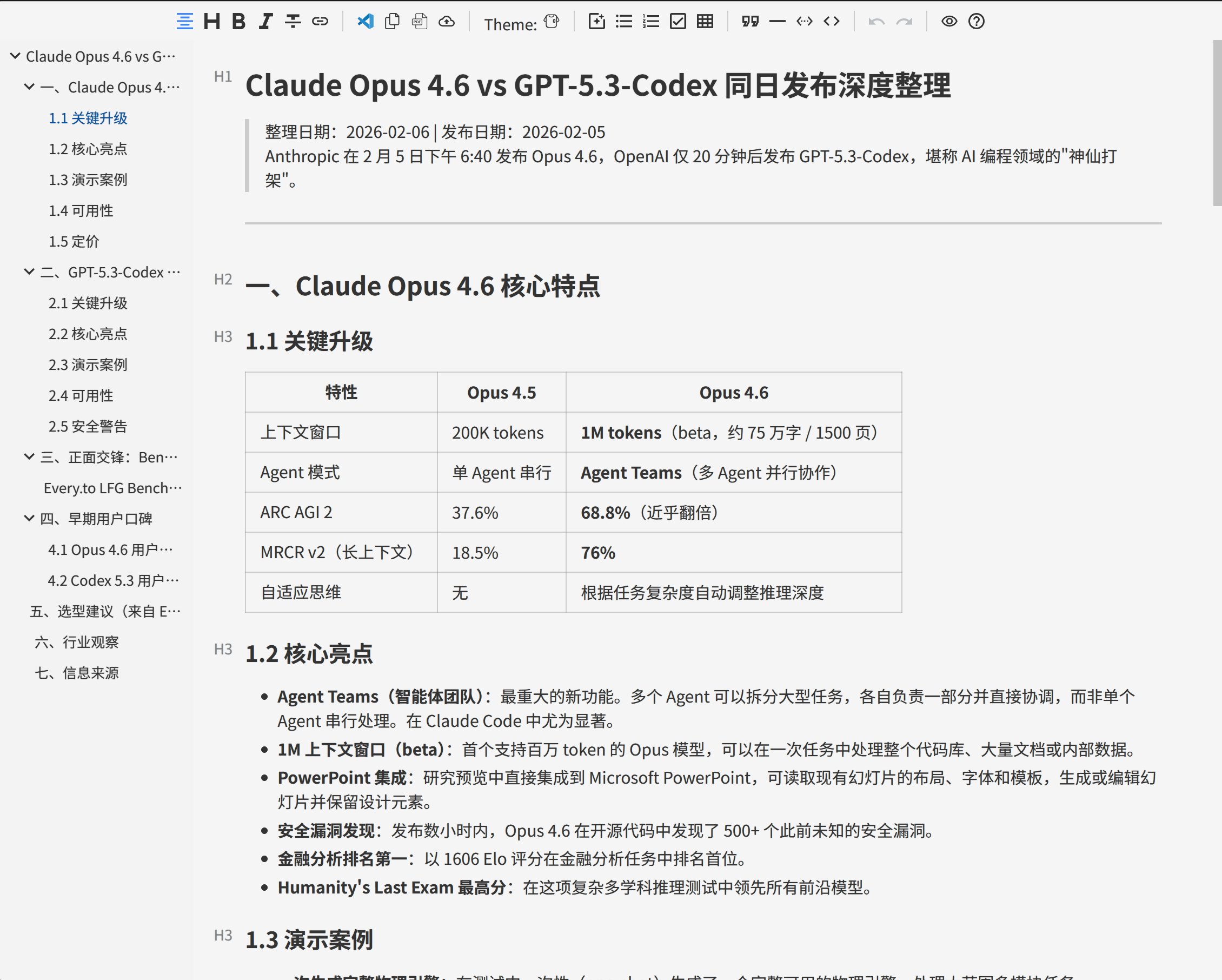
Claude Code 概括了差不多 6 个点:
- Claude Opus 4.6 核心特点
- GPT-5.3-Codex 核心特点
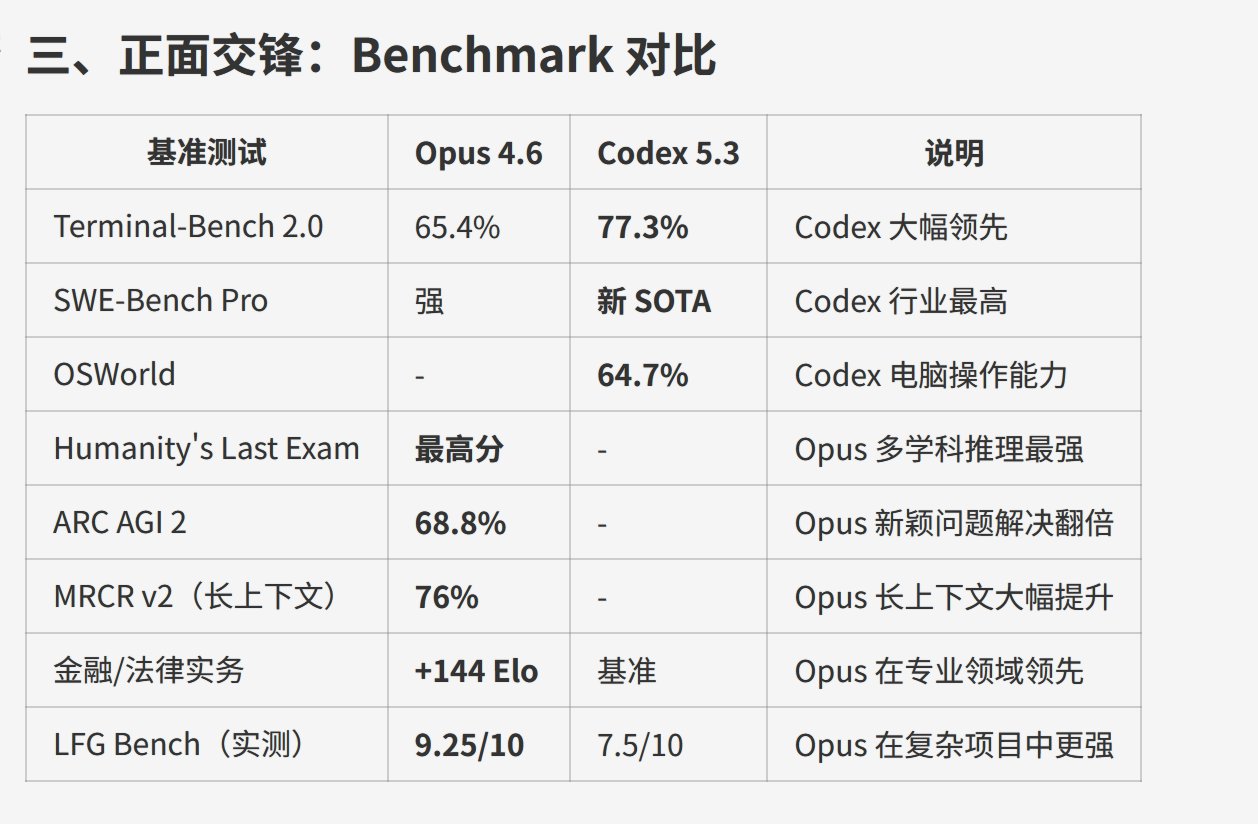
- 正面交锋:Benchmark 对比
- 早期用户口碑
- 选型建议
- 行业观察
首先,这两个模型对指令的理解能力都非常到位。它们根据需求查阅了数据,并从中抽取了几个分类:
- 概括每个模型的特点
- 调研口碑
- 选型建议
这些内容在两个模型中都有体现。
从宏观来看,GPT 的报告更简略,而 Claude 的报告更加详实。这一点无论是从大标题来看,还是具体的内容来看,都非常明显。尤其是在介绍模型特点的时候,Claude 针对两个模型专门用了一个章节来介绍,非常详细。
Codex写的核心特点:

Claude Code写的核心特点:
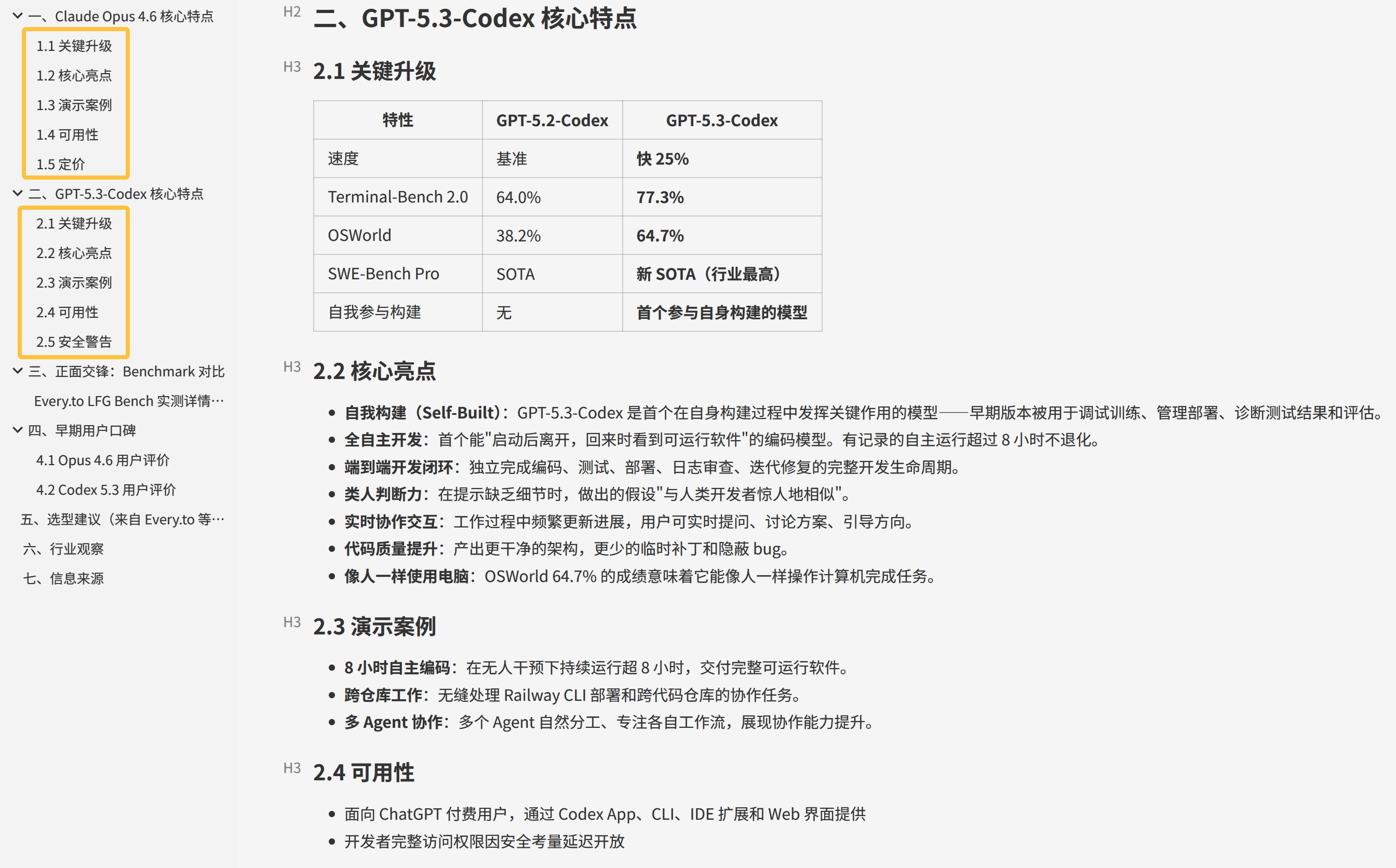
Codex 5.3 大概只用四个列表,来介绍这个核心特点。
Claude Code 是分了几个子项,关键升级核心亮点包括:
- 关键升级
- 核心亮点
- 演示案例
- 可用性
- 定价及安全警告
其中第一个关键升级对我来说还蛮有用的。
因为我很想知道它这次升级,除了跟对手比之外,跟自己家比有什么变化。这一点虽然我在需求中没有提出来,但是 Claude 能帮我列出来还是很好。
另外一个差异是:GPT 没有“正面交锋”这一栏,而 Claude 则写得非常清楚。
用户口碑部分
Codex 也是一笔带过,正向和反向大概就各说了一到两条。
而 Claude Code 每一项都列出了四五条,正反两面都非常详尽。而且它对 Codex 的缺点总结得实在是太精准了:
- 速度较慢:运行时间通常需要数小时,显著慢于 Opus 4.5。
- 状态可见性不足:叙述中断和任务复选框更新延迟降低了运行透明度。
- 最终总结技术性过强,非专业人员需要”翻译”。
- 网络安全风险引发争议,OpenAI 延迟了完整的开发者访问权限。
- 不太适合 prompt 设计和 Agent 架构设计等创意性工作。
其中 4 条,我在 GPT-5.2 上都是有切身感受的。GPT-5.3 基本也保持了“优良作风”。安全风险这个点我还不是很清楚。
参考链接部分
两位选手全部都正确地找到了他们的官网链接和官网公告,并且放在了最前面。
Codex 总共引用了 8 条,Claude Code 总共引用了 15 条。
从数量上来看,Claude 肯定完胜了,而且从最终的结果来看,它阅读了更多的内容,所以整理出来的数据更加详细而准确。
有一个点很可惜,我忘了看 Token 消耗了,我看的时候已经重置了。目测,肯定是 Claude 消耗得比较多了,而 Codex 配额非常充沛,几乎处于用不完的状态。
从个人爱好来看的话,我是极其不喜欢 GPT 这种写总结的油腻画风。他特别喜欢在一个标题后面加括号,然后用各种冒号、双引号,把整个内容搞得有点混乱。如果一两个强调的话会看起来很舒服,但是大堆强调补充,会让人看起来非常难受。
就是有点像那种:我很懂的,你知道吗?我真的很懂,你必须知道。
你看,我各种强调、各种括号、各种冒号,都在表达我很懂。而且那个“一句话先行”,多么体贴入微啊(已经有点看吐了)。
Claude 的话,它这个结构是非常清晰的,给你安排得清清楚楚、明明白白。包括在查找资料的时候,他查找的资料是非常充分的。所以最终结果里面,也写得非常清晰、非常完整。
虽然今天测试的主题既不是编程,也不是操作 Office,但是我觉得这种信息的收集和汇总能力在各种职位和行业中都是非常有用的。整体来说,Claude 会显得更专业和清晰一点;而 Codex 就会写得更笼统一点,它好像是在试图给不懂的人做解释。
这一点可能和他们专注的领域有关系。
因为 GPT 的普通用户特别多,所以很多时候用户找它是为了寻求问题的解释;而 Opus 的很多用户都是企业用户或者程序员,他们虽然也需要寻找答案,但需要的是更专业的条理清晰的答案。


关于作者
tony
某人