Z-Image很稳,低显存GGUF模型和工作流!
看来大家还是挺喜欢 Z-Image 的。
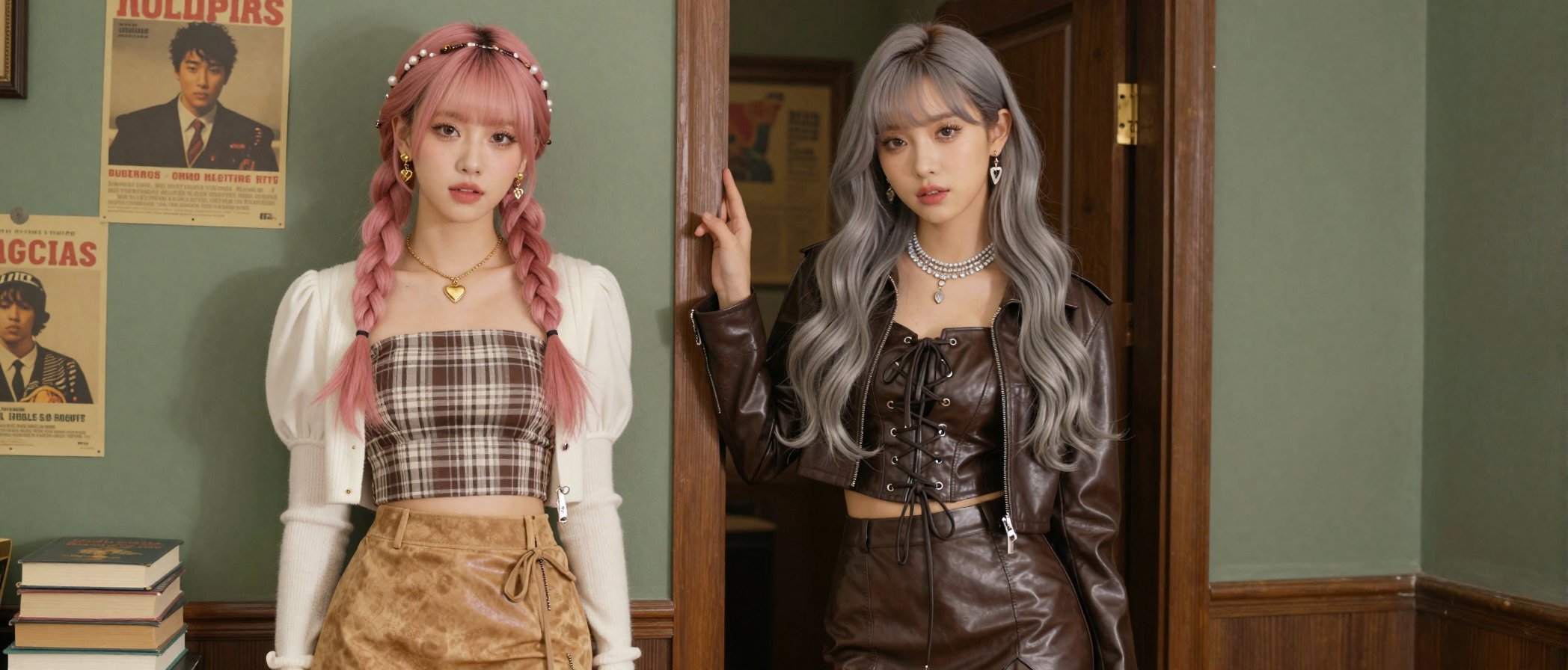
我就在为低配电脑,低显存用户努力一把!分享一个低显存的 GGUF 工作流,6G显卡来挑战一下啊!
GGUF 是一种专门给本地大模型(LLM)做压缩和加速的文件格式,让模型可以在 更小的显存 / 内存 下运行,尤其适用于:
- Windows / macOS / Linux 本地推理
- CPU 运行(非常强)
- 小显存 GPU(4GB、8GB、12GB)
这次主要是需要用到下面两个项目:
https://huggingface.co/jayn7/Z-Image-Turbo-GGUF
https://huggingface.co/unsloth/Qwen3-4B-GGUF/
最核心的 Z-Image-Turbo-GGUF 这个项目的模型。
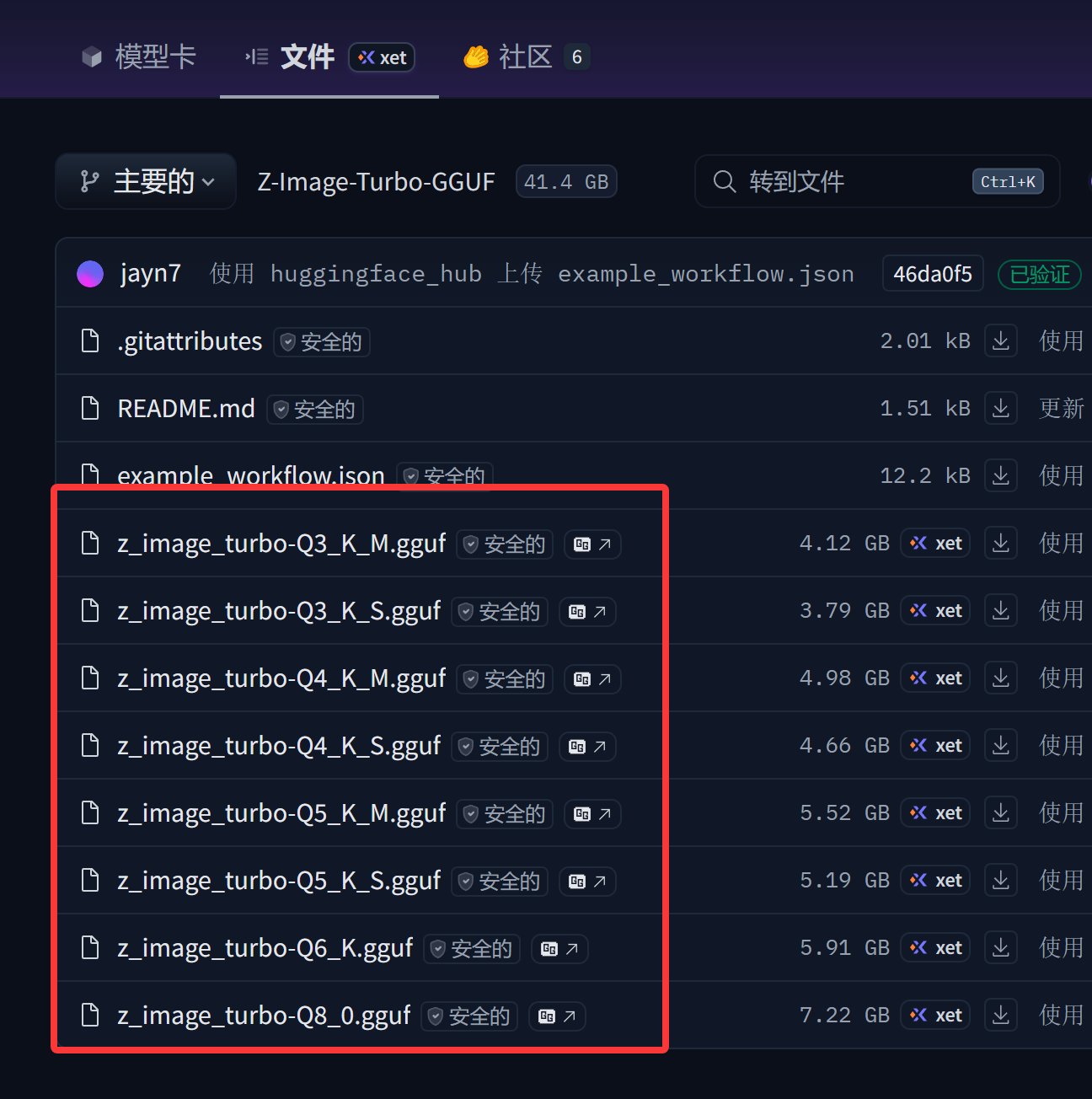
从这里下载一个模型,我一般从性价比角度会选 Q4_K_M 模型,这个模型的体积只有 Z-Image 官方模型的一半,比 FP8 也要小很多。另外会用到一个 Qwen-4B 的 CLIP 模型,可以从另外一个网址中获取。
不同模型生成的效果图如下:

从对比图来看,不同量化模型,差别不是很大。即便是最小的 Q3 图片也没有崩。所以用 GGUF 模型,对结果并不会有太大的负面作用,可以放心使用。当然硬件允许,追求质量,就用官方原版模型。
根据自己的情况下载一个尺寸合适的模型,然后从另外一个地址下载一个 Qwen3-4B-GGUF 的模型。这样模型就准备好了。
接下来可以启动软件。
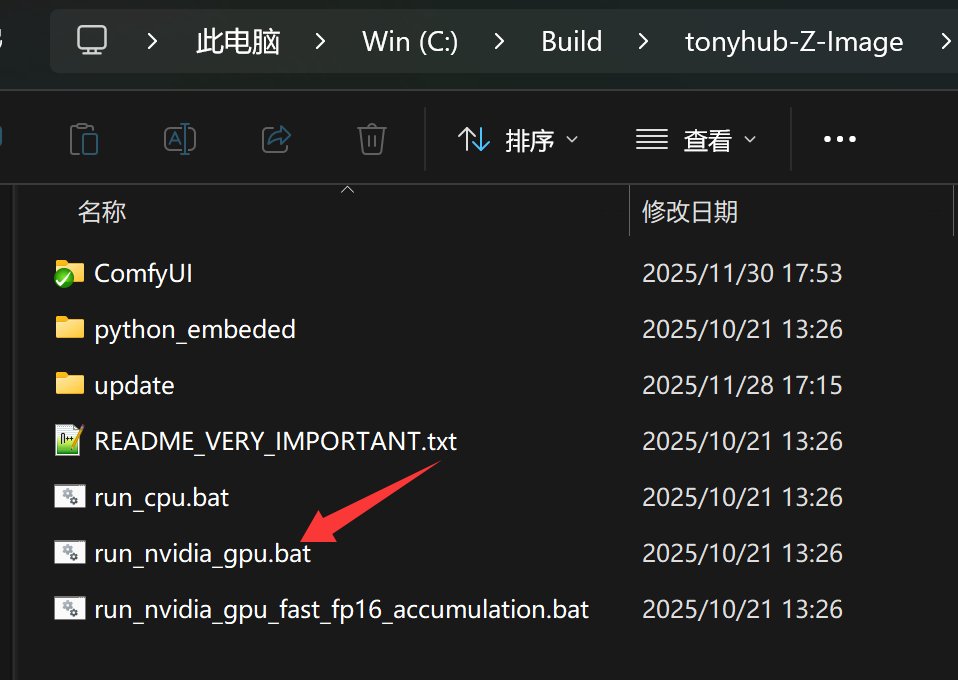
安装一下 GGUF 的节点插件。

GGUF 模型,必须要专门的 GGUF 节点,所以需要安装一下节点插件。
安装完成之后,重启软件打开 GGUF 工作流。直接点击运行就可以了。
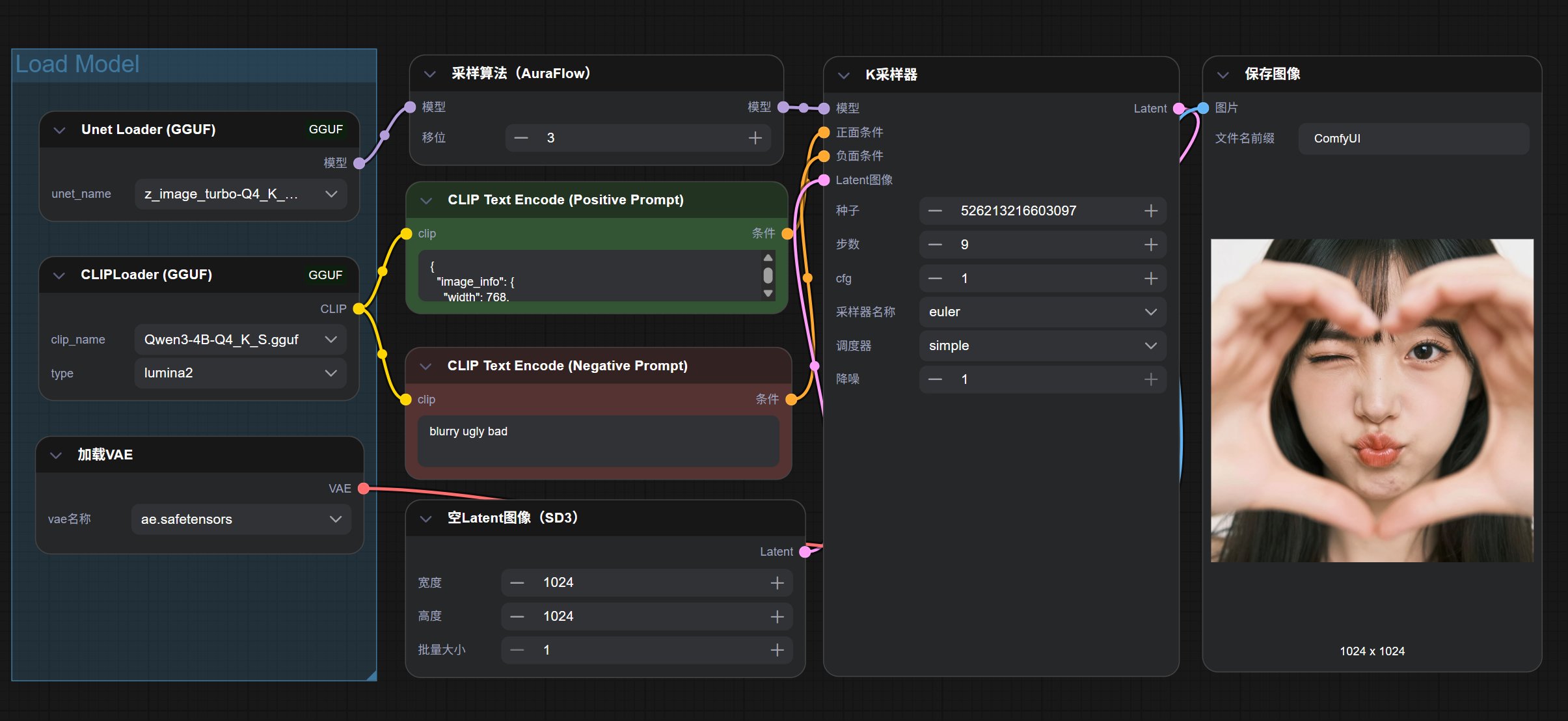
从实际情况来看,如果你不是特别敏锐,很难看出差别。非常好!
另外昨天的工作流有人反馈了一个问题:无法更换提示词。
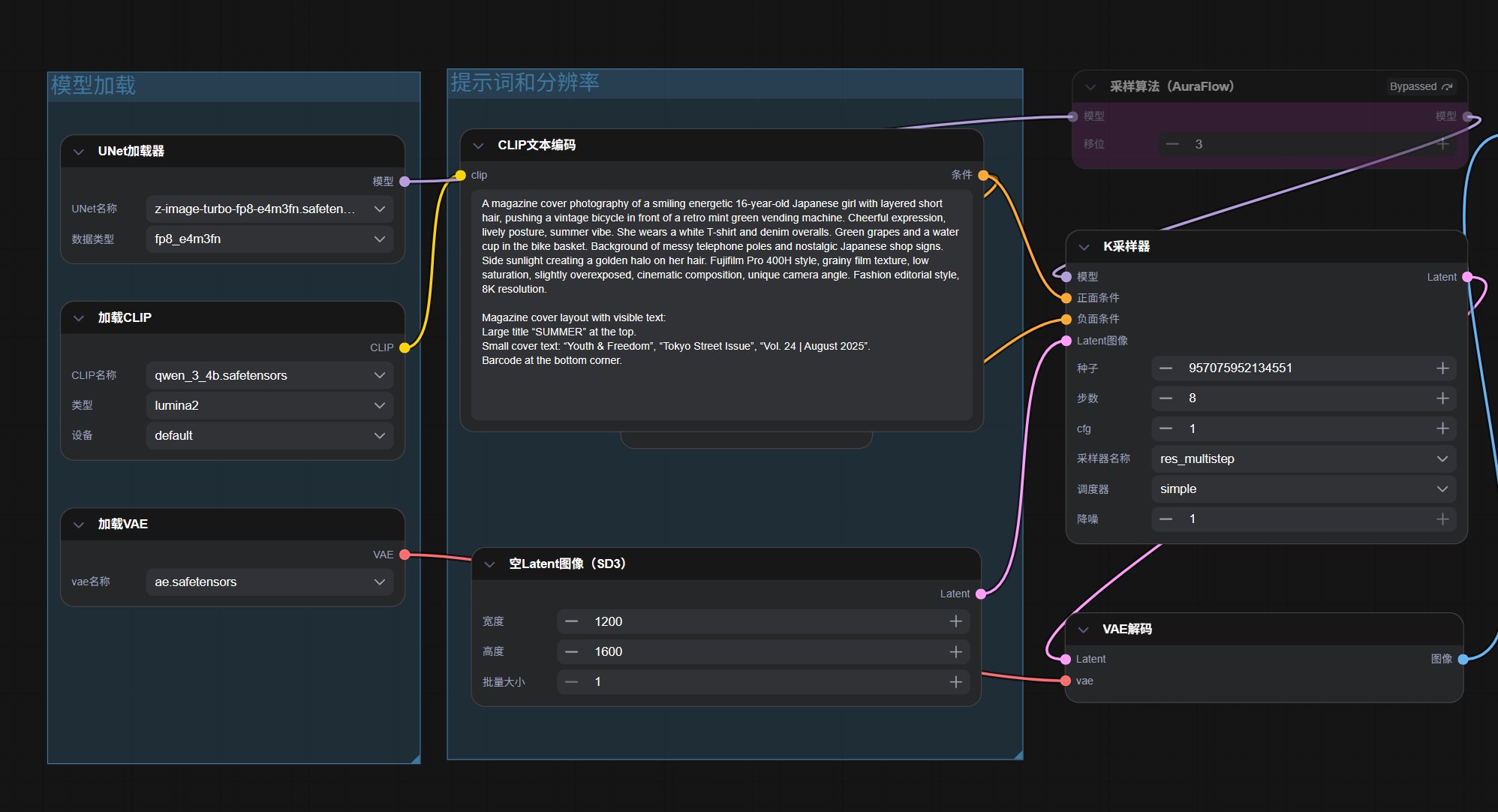
就是修改提示词之后无效,非常奇怪。我测试了 image_z_image_turbo.json 这个工作流,确实有这个问题。然后进入子图修改之后,可以正常工作。刚开始我怀疑是子图的问题,但是后来发现好像和 Nodes 2.0 有关。
目前来看,还是关闭 Nodes 2.0,不用子图比较稳妥。为了避免“子图”的困扰,我单独做了一个完整的工作流。
另外,昨天有人在 1070 上成功运行了 FP8 的工作流,而有人反馈 8G 跑不起来。
我怀疑显存不够的情况下和内存大小也有很大的关系。
而今天 GGUF 工作流,把里面两个最消耗内存显存的模型都换成了 GGUF 模型。
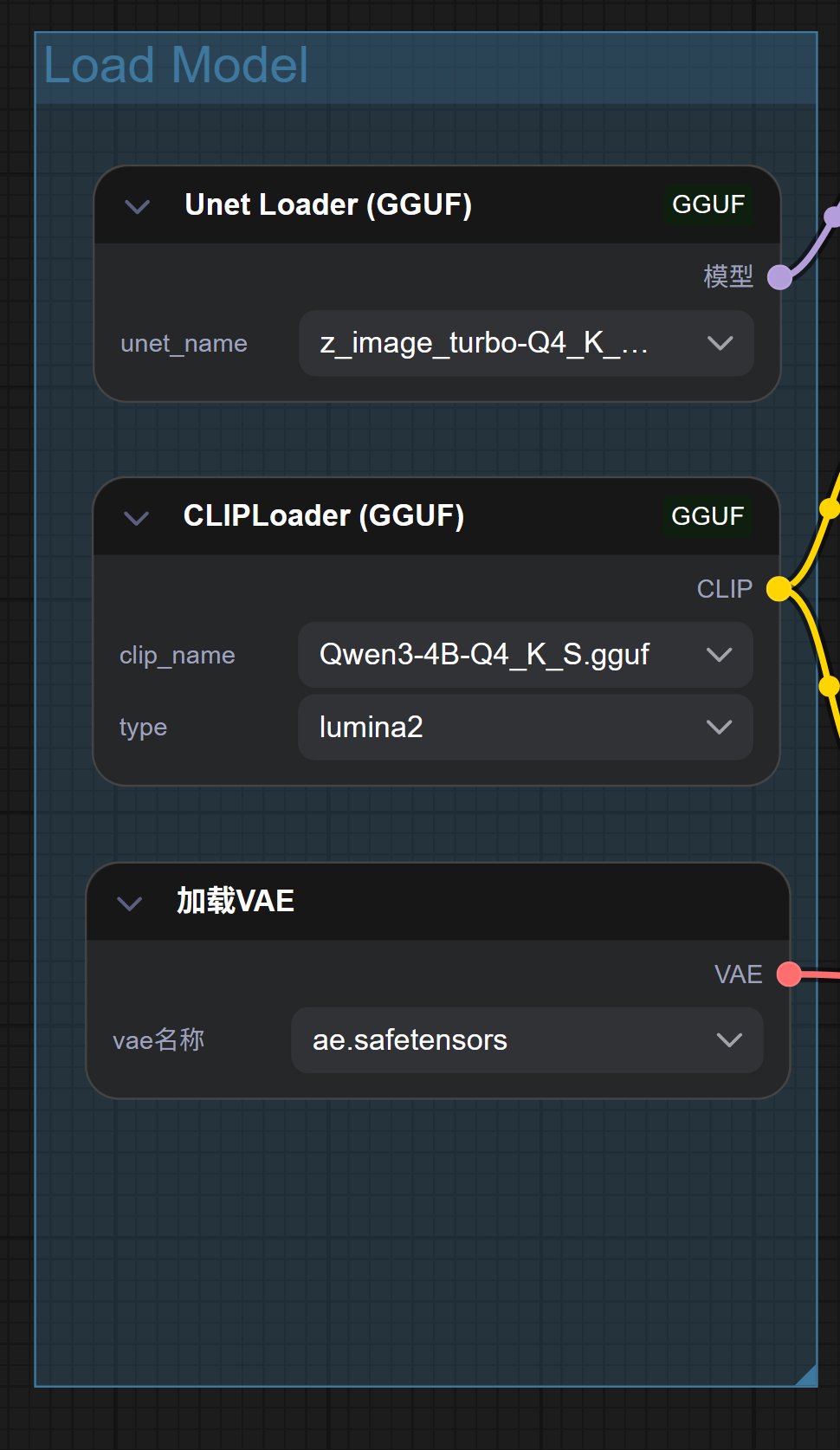
理论上来说肯定是会比昨天的工作流消耗的显存更少!昨天跑不起来的,可以测试一下新的工作流,如果还是有压力,可以把里面的 Q4 换成 Q3 或者 Q2。
最后,我会把新工作流和模型放到网盘里,获取方式和上一篇中提到的一样。
大家运行完成之后,可以分享一下能不能跑,跑得快不快。最好带上显卡型号,显存,出图时间等信息!
Z-Image YYDS ,很稳!

关于作者
tony
某人