Qwen-Edit 一句话修改视角本地运行
前几天在 Jarvis 上发了一篇使用 Qwen-Image-Edit 实现多视角调整的文章,看来大家挺喜欢的。

然后我就顺势专门研究了一下它的俯拍仰视视角,发现它可以干翻一堆闭源的 AI 修图软件。 而且需要注意,Qwen-Image-Edit 本身就是一个编辑模型,除了改变视角,还可以加入或调整其他内容。

比如上面这张图片本身是站着的,你也可以让她跪下。AI 甚至可以解开纽扣,真的是为所欲为啊。
有了这项技术,我们就可以通过一张图片,实现多视角来观察美女咯。
当时是使用别人开发的 Hugging Face Space 制作了这组图片。
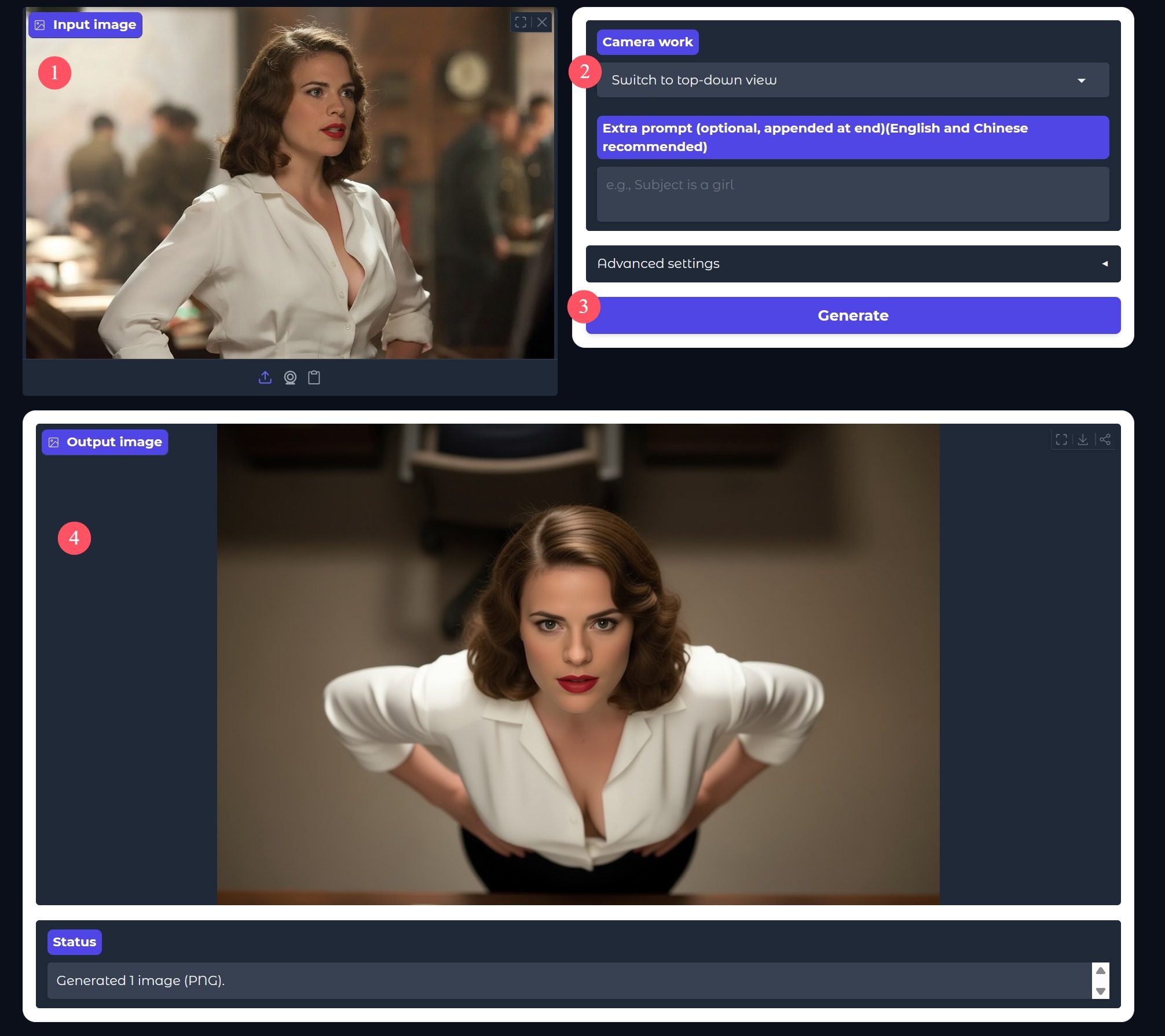
通过这个网页制作非常简单,只要上传一张图片,然后选择调整视角镜头的提示词,点击生成就可以了。 网址和操作可以参考《Qwen-Edit:一句话修改视角》。
用别人的工具方便是方便,但是你无法保证开发者是否会查看你的私人作品,也无法保证它一直可用,也无法保证后续一直免费。
所以,我们必须自己动手,丰衣足食。这也是“托尼不是塔克”这个账号的核心宗旨——本地独立运行各种牛逼的 AI 软件!
通过分析可以知道,这个效果是通过开源模型 Qwen-Image-Edit + LoRA 来实现的。 多角度效果这么好,是因为使用了专门的多角度 LoRA。
明白了这一切之后就好办了。
我们只要在 ComfyUI 上运行 Qwen-Image-Edit 工作流,就可以实现了。
这么一来就非常简单了。我们已经讲过很多次 ComfyUI 的安装和使用。 假设你已经看过我之前几篇关于 ComfyUI 的文章,其中已经非常详细地讲解了如何安装这个软件,以及如何安装插件管理器和插件。
基于这个基础,我们可以快速在本地实现这个功能。
这一次我们用到的核心内容是这个 LoRA 项目。
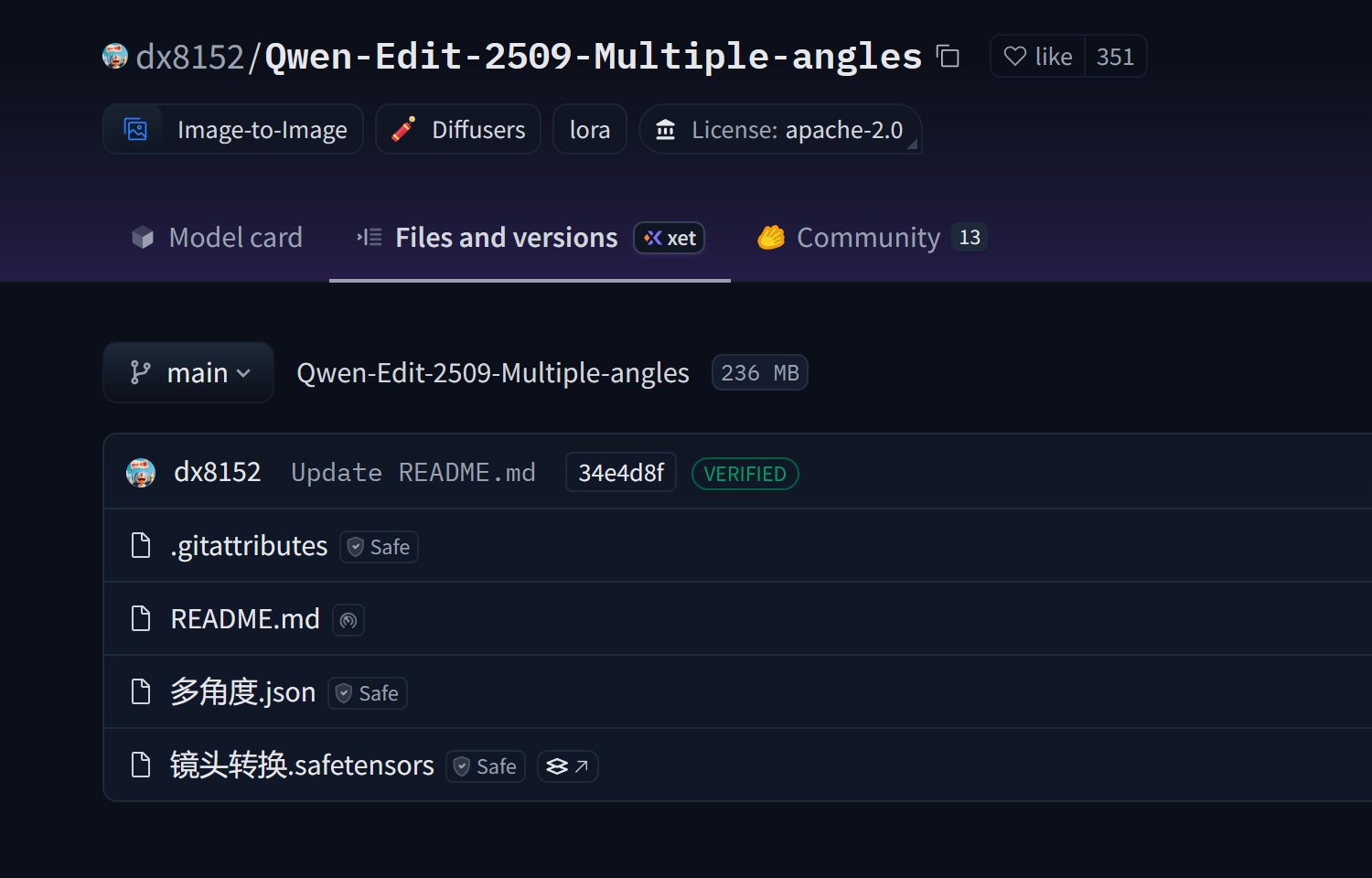
这里提供了工作流和 LoRA 模型,可以先把其中的 多角度.json 和 镜头转换.safetensors 下载到本地。
1. 启动 ComfyUI
双击 run_nvidia_gpu 启动。
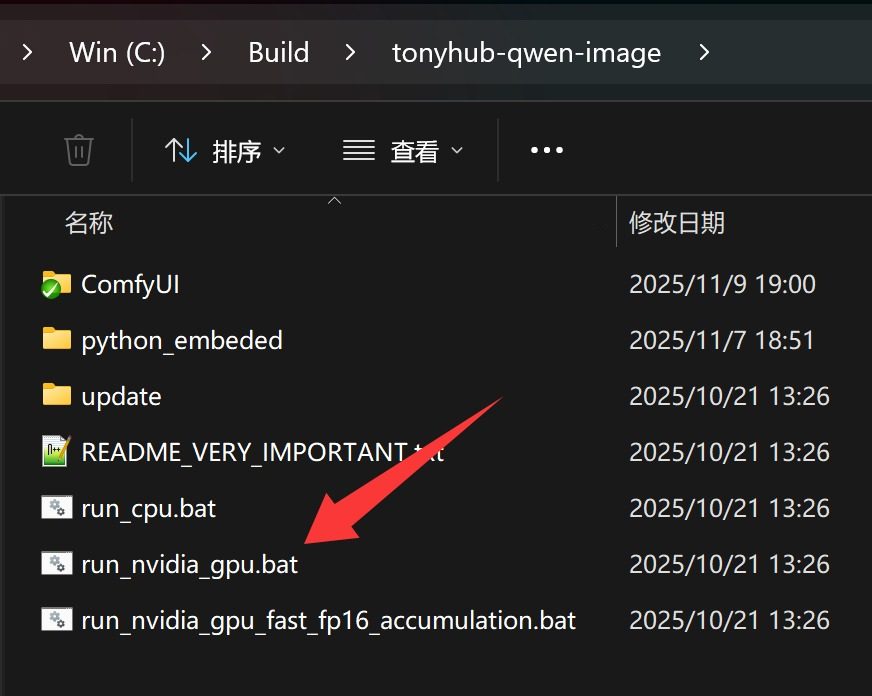
这里没啥好说,启动完成会自动打开浏览器。
2. 加载工作流
启动成功之后,把 多角度.json 拖动到工作流区域。
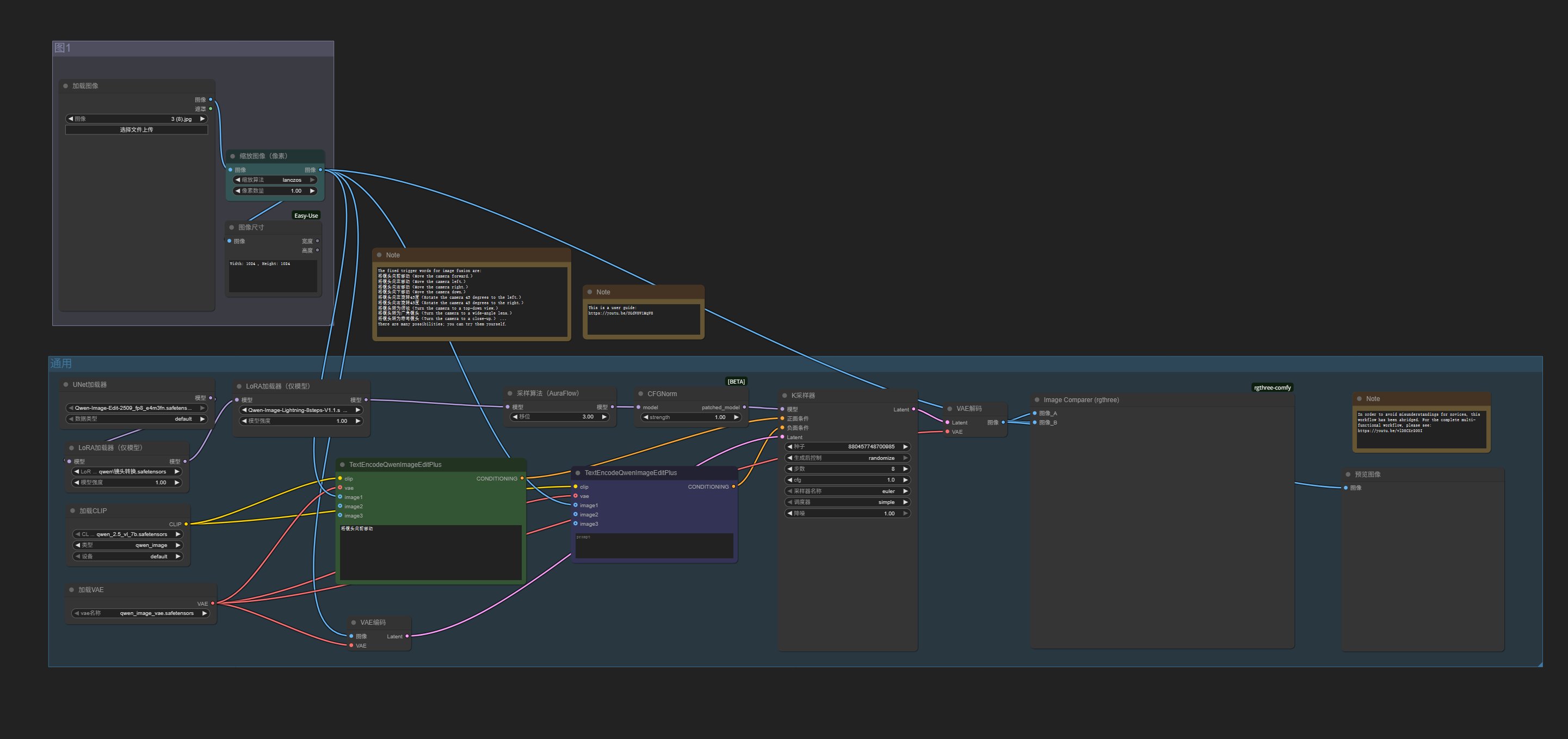
这样就会导入工作流了。
这个工作流非常简单,左上方是上传图片的,左下方是加载模型,绿色节点用来输入提示词。右边显示处理结果。
3.安装缺失节点
你们在拖入这个节点之后,应该会和我的截图有点不一样,其中几个节点会标红。
同时弹出节点缺失的提示信息:
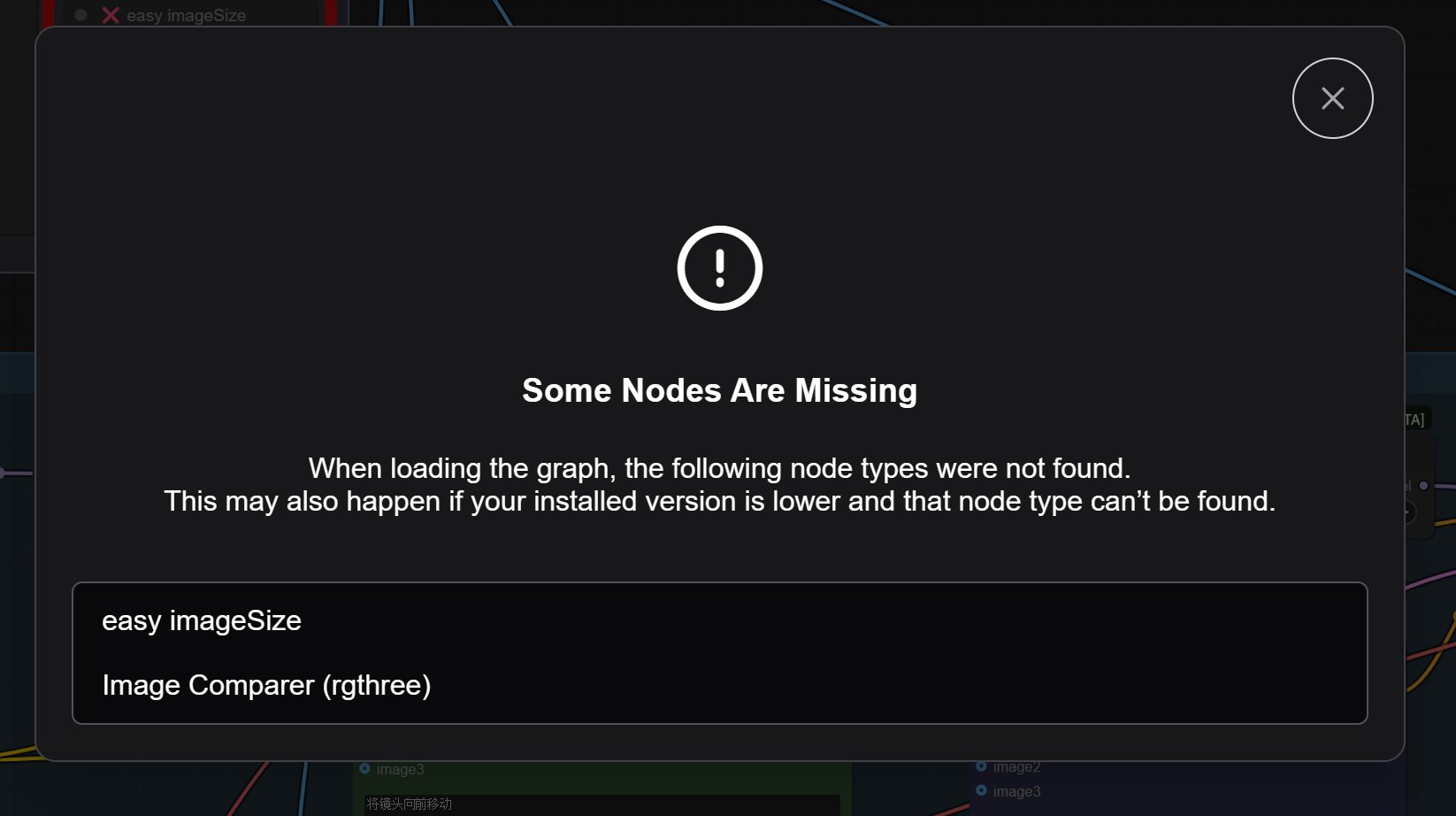
虽然这个工作流已经非常简单了,但是还是用了一些第三方节点,所以需要根据提示自己安装一下。
安装节点也非常简单。直接点击右上角的 “Manager”。
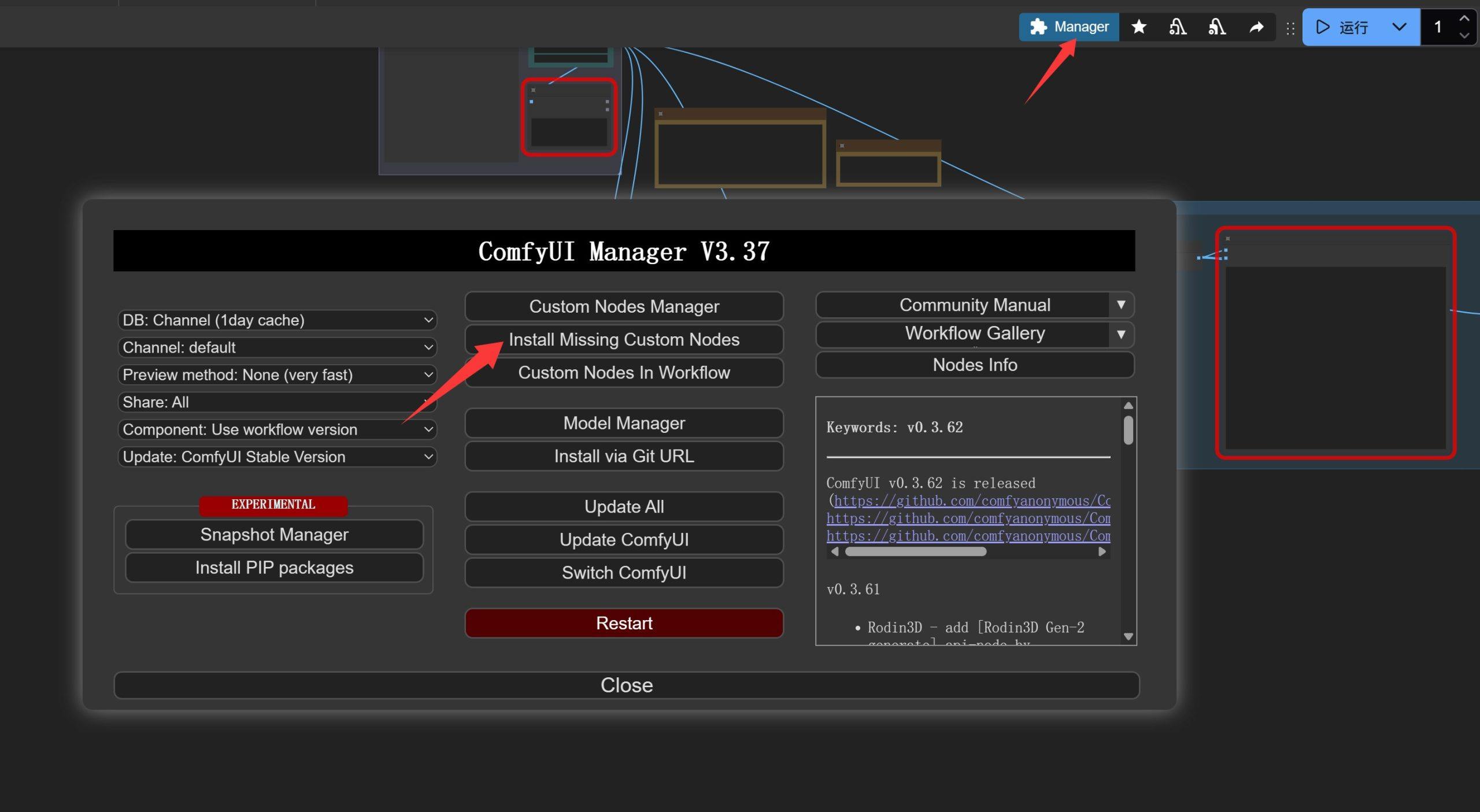
在弹出的窗口中点击 “Install Missing Custom Nodes” 查看缺失的节点。
勾选缺失节点,点击 Install 进行安装。
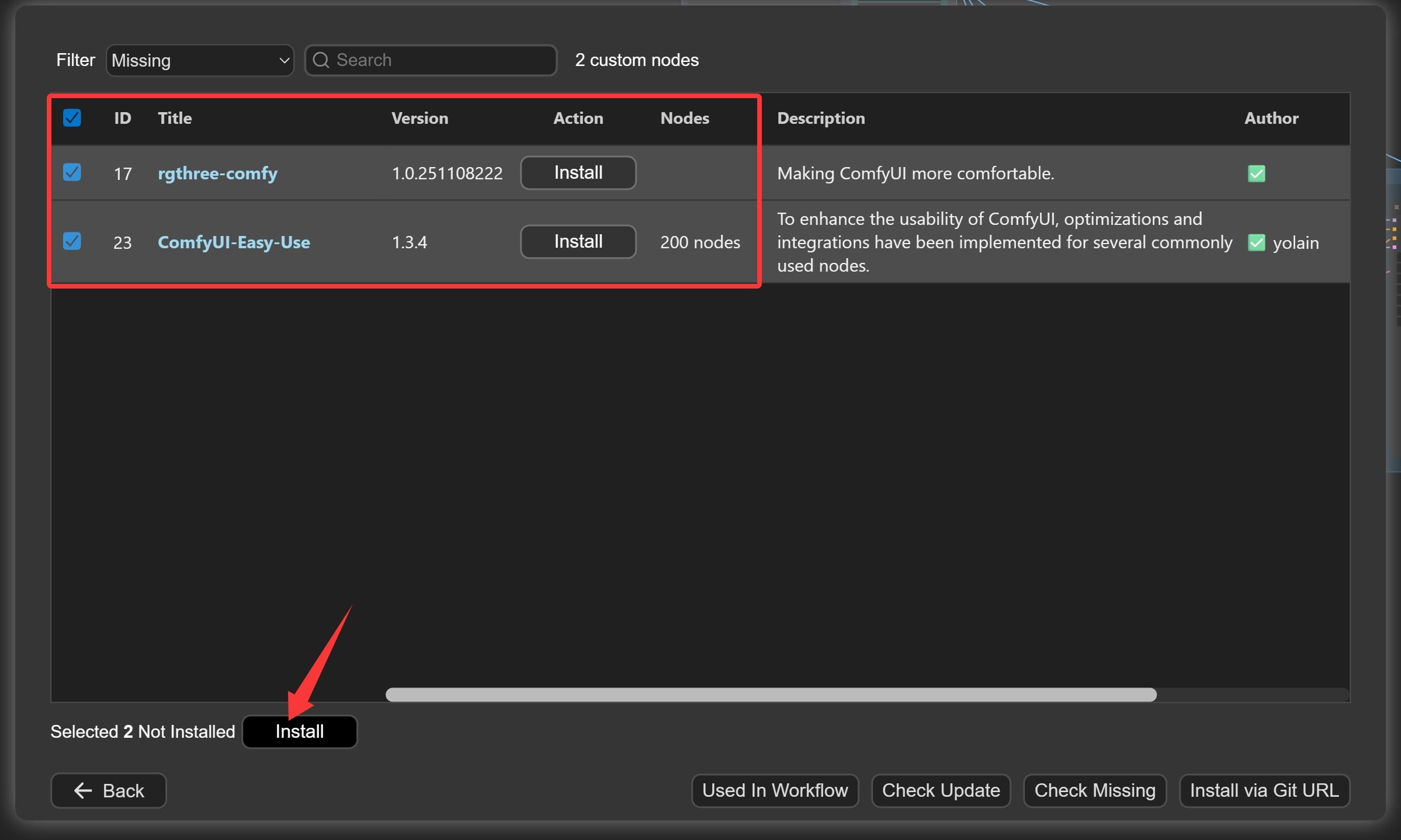
安装完成之后,记得重启软件。
因为节点非常简单,所以只要网络通畅,安装不会遇到难搞的问题。
4.下载模型
节点安装完成之后,就可以下载所需的模型了。
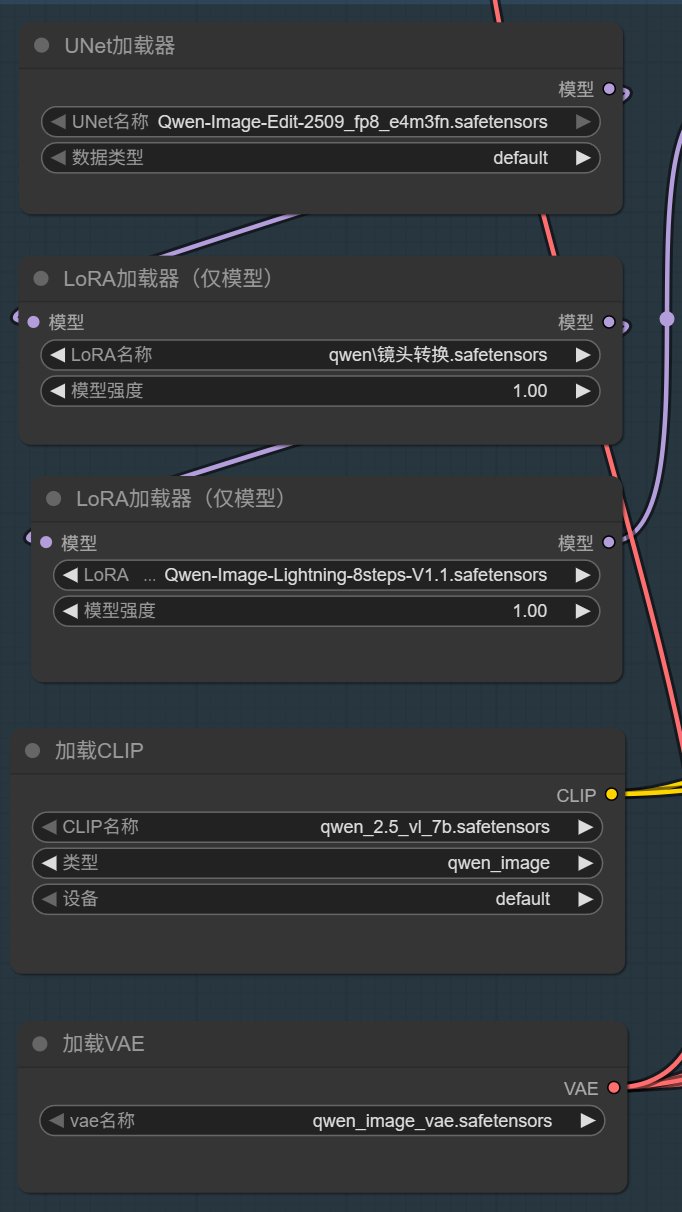
这里主要是用到了五个模型,模型的具体名称和放置路径如下:
ComfyUI/
└─ models/
├─ diffusion_models/
│ └─ Qwen-Image-Edit-2509_fp8_e4m3fn.safetensors
│
├─ lora/
│ ├─ 镜头转换.safetensors
│ └─ Qwen-Image-Lightning-8steps-V1.1.safetensors
│
├─ text_encoders/
│ └─ qwen_2.5_vl_7b.safetensors
│
└─ vae/
└─ qwen_image_vae.safetensors
把这些模型下载到本地,并放到指定的路径。重启软件。
这里需要注意加载 LoRA 的节点,“镜头转换”这个模型需要重新选择一下,因为我们本地的路径中没有 qwen 开头的文件,而是直接放在 lora 文件夹下面。
5.运行工作流
模型和节点都已经搞定了,就可以开始上传图片,设置参数,运行工作流了。
上传图片,点击选择文件上传,或者直接把图片拖动到上面即可。
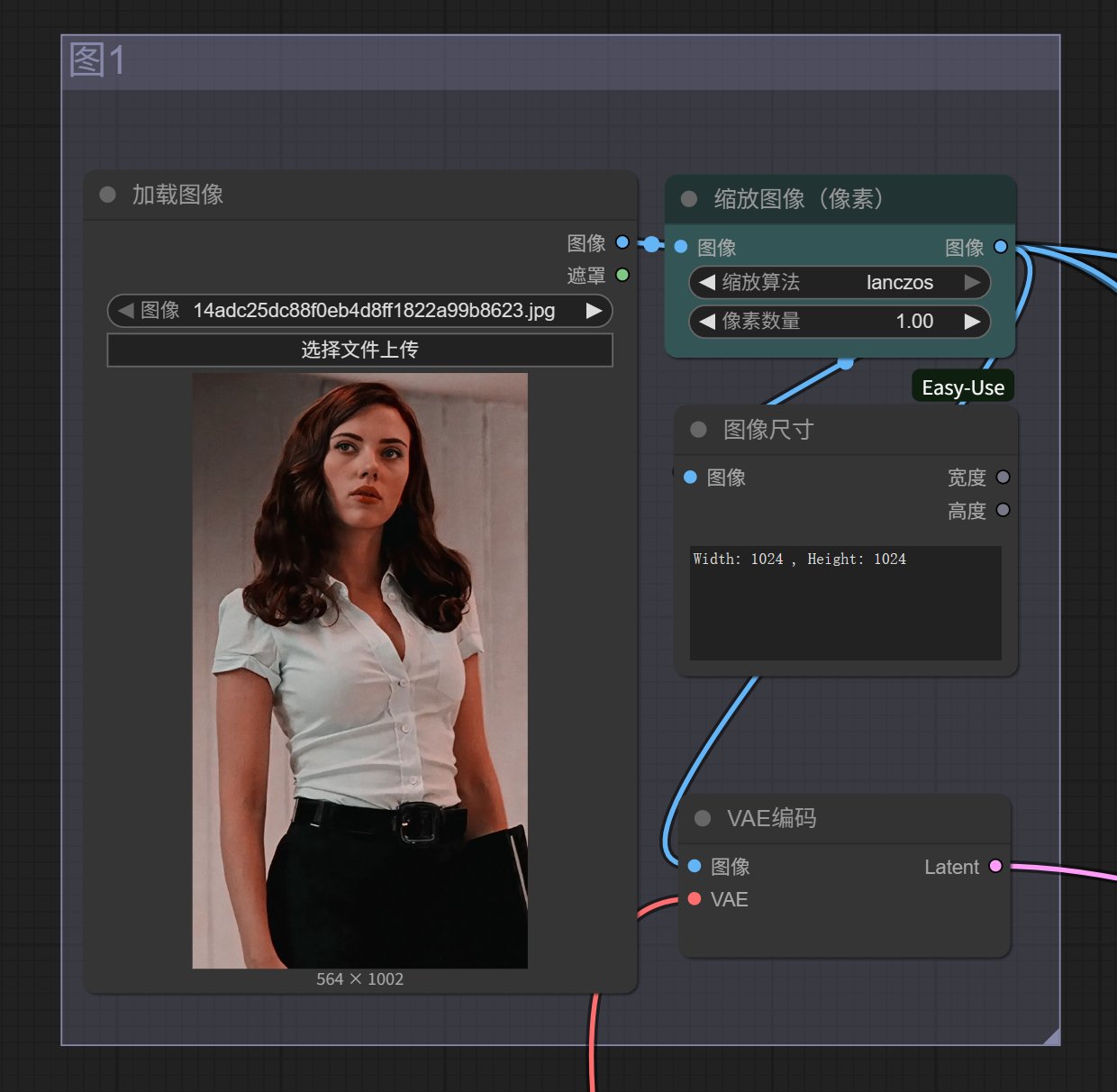
图片可以是横屏竖屏,人物,场景,都可以。
填写提示词
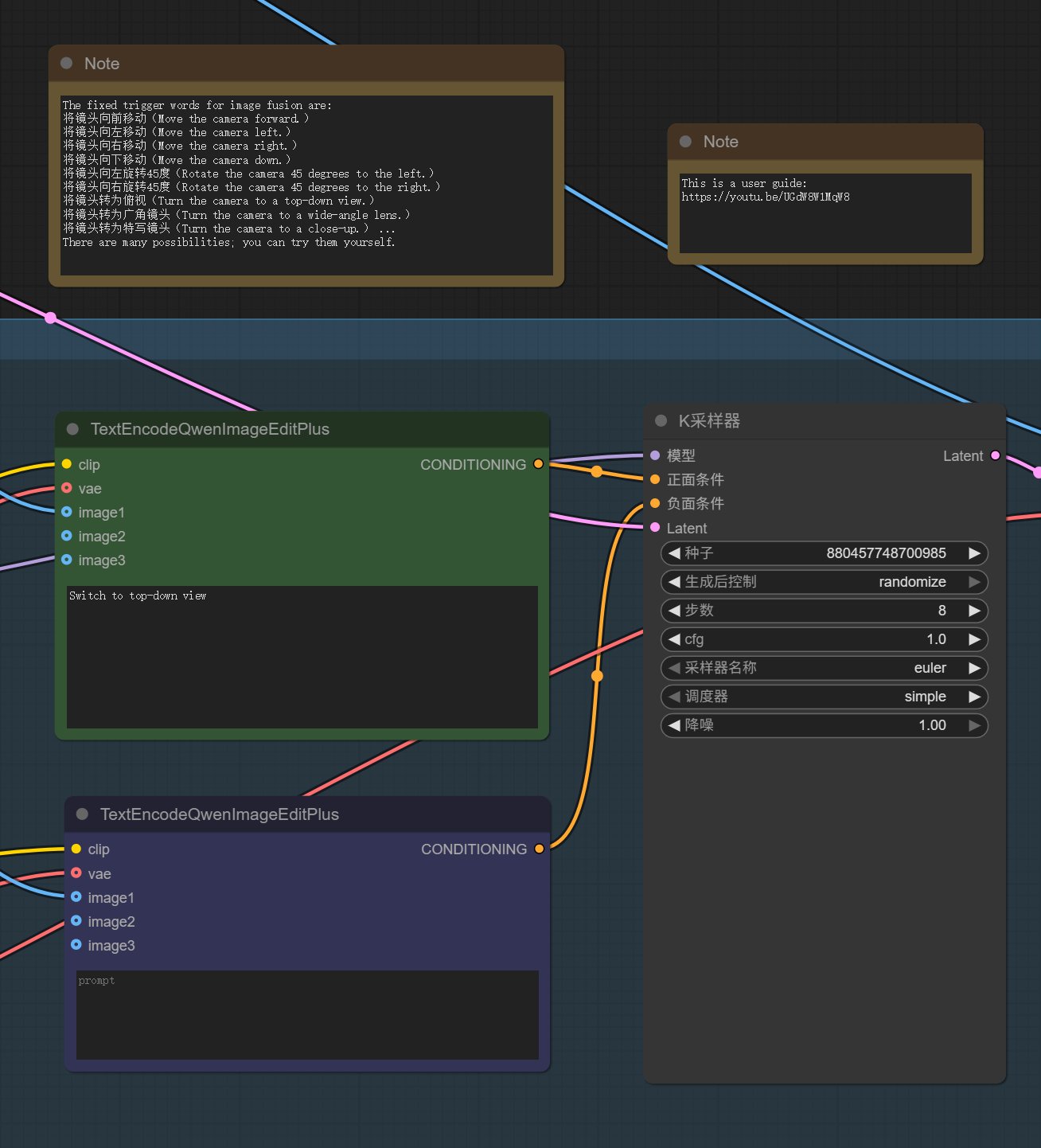
提示词可以在 “Note” 里面照抄。通过提示词可以实现旋转角度,切换俯视/仰视,切换广角/特写。
设置好之后,就可以点击右上角的运行按钮了。
查看结果:
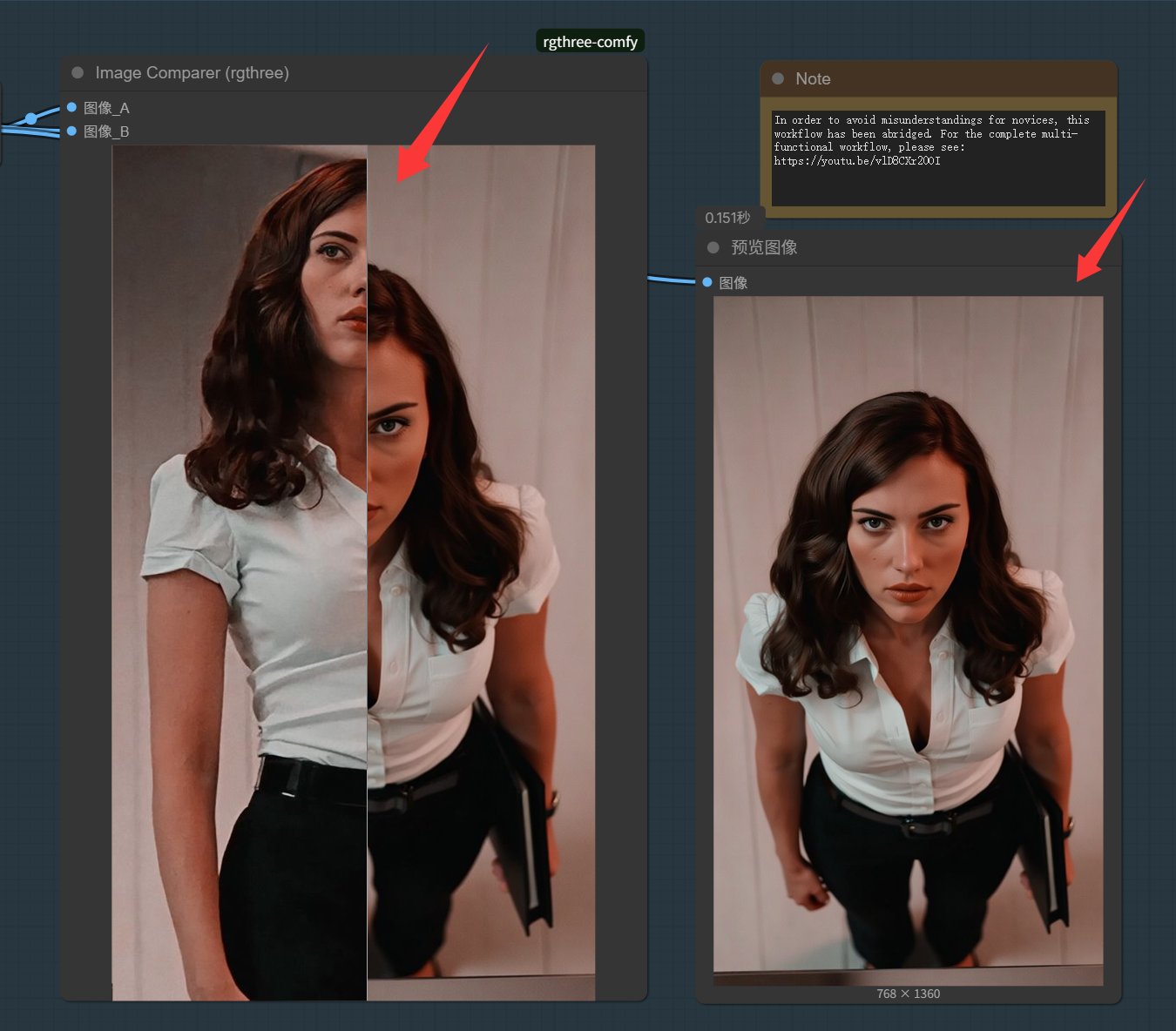
运行完成之后就可以看到结果了,结果里面有 A 和 B 两个输入,鼠标放到上面拖动,可以对比生成之前和生成之后的图片。
6.优化工作流
默认的工作流很清晰,但是有一个问题:如果显存低于 24 GB,可能无法运行。
我刚开始也是低估了这个问题,我本来想着 AI 视频我都能跑起来,还怕你个 AI 图片。但是我还是想得太简单了。
diffusion_models 里的 FP8 模型直接达到了 19 GB。
text_encoders 里的 qwen_2.5_vl_7b 也有 15 GB。
……
如果要在低显存的设备上运行,就需要调整一下工作流。
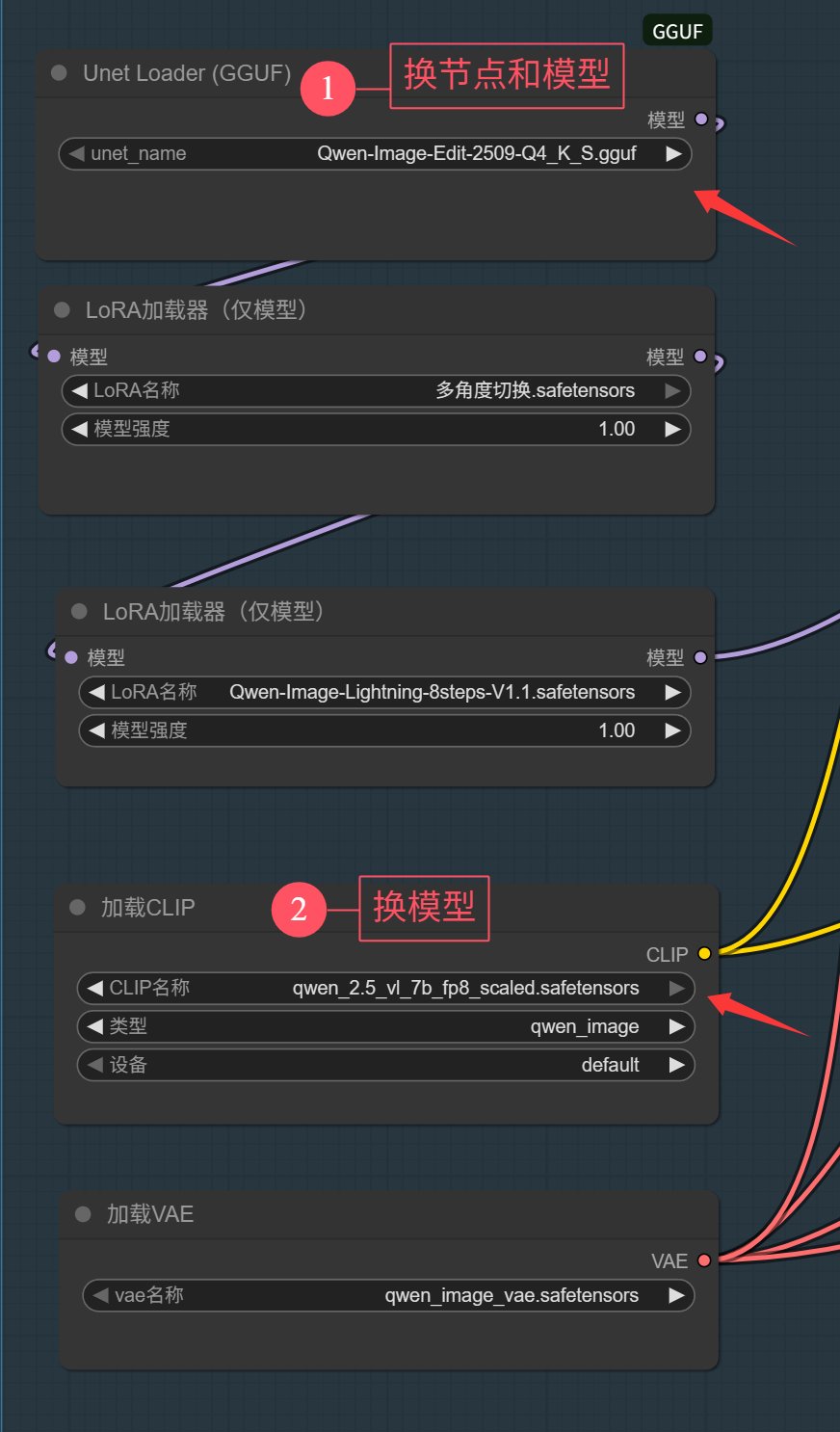
主要调整是:使用 ComfyUI-GGUF 节点和模型,使用 FP8 的 QwenVL 模型。
这里用到了一个自定义节点,所以需要先通过 “Manager” 安装 ComfyUI-GGUF 节点。
然后在工作流空白处双击,输入 GGUF 找到 UnetLoader(GGUF) 这个节点,用这个节点替换原来的 UNet 加载器。
然后将模型切换为 Qwen-Image-Edit-2509-Q4_K_S.gguf,该模型放在 diffusion_models 文件夹里。
换完之后是这样的:
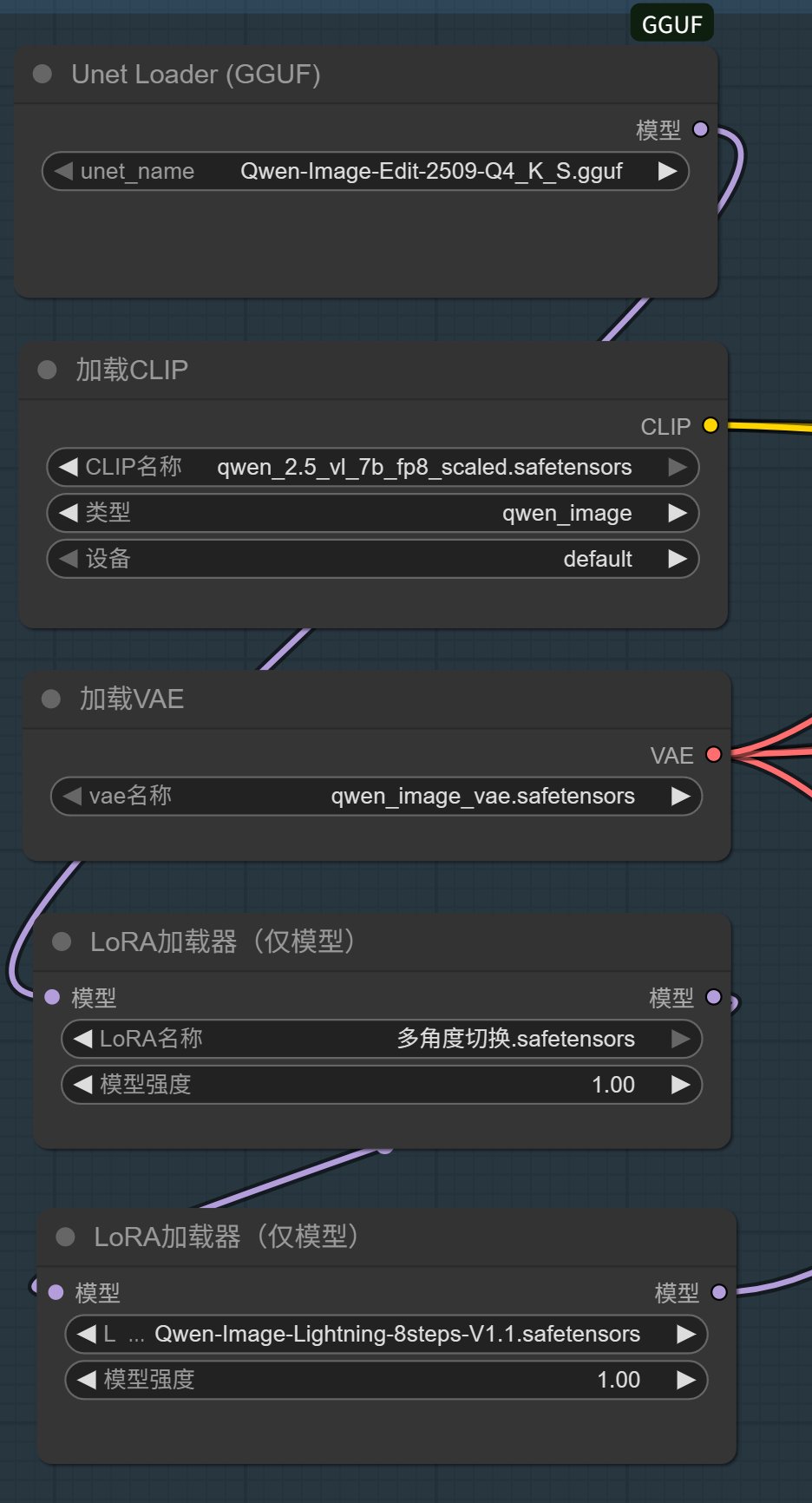
切换完成之后,显存需求就会降低很多。
然后就可以愉快地玩耍了。

轻松拿捏女神的各个角度。
我的几篇文章都是有美女做了演示,主要是方便大家轻松吸收知识。其实这个视角切换功能,有很多更加适合的场景可以使用,比如多角度看建筑、汽车等,也可以生成分镜,或者动漫角色的多视图。因为它的发挥相对稳定,所以实用价值更高。
相关资源和网址
文章中提到的模型和工作流,可以在下面这些网址中获取:
https://huggingface.co/dx8152/Qwen-Edit-2509-Multiple-angles/tree/main
https://huggingface.co/lightx2v/Qwen-Image-Lightning/tree/main/Qwen-Image-Edit-2509
https://huggingface.co/QuantStack/Qwen-Image-Edit-2509-GGUF/tree/main
另外我也会整理好软件,模型,工作流,放在网盘中。
预设获取关键词为“qwen-image-edit”。( 注意可以长按复制,不要傻傻输入这么长的关键词)


关于作者
tony
某人