Gemini3.1 实测了9个例子,结果不太理想!
关于谷歌最近发生了两件事情。
一件是我的两个闲鱼账号翻车了。
之前在闲鱼花了三十多块钱买个 AI Pro 账号,全部提前订阅到期,变成普通账号了。
现在有点后悔,为了省 100 美金,现在要多交 100 多美金了。白嫖终究不是正途,直接开了官方的 AI Pro 账号,现在可以免费一个月,先开了再说,一个月后决定要不要续。

另外一件事情是谷歌低调发布了 Gemini 3.1 Pro。
Gemini 3.0 Pro 的发布的时候,凭借惊艳的前端水平,大受好评,让很多人开通了会员。那一段时间实在太狂热了,直接把谷歌的股价都推上新高了。
但是过了一段时间之后,大家发现 Gemini 的“智商”多少是有点问题的。
主要表现在他写代码的时候的逻辑能力,稍微难点的代码他就会出错。
现在 Gemini 3.1 Pro 来了。
我最关心的两个问题:一个是它的编程能力提高没?一个是它的前端审美提高了没?
我花一天时间测了 9 个例子,整体感觉不是太好!
这九个例子是 GLM 为了挑战 Claude,Claude 为了捍卫王座而给对方出的题目,可能有一点点难度。
今天就不和 Claude 去对比了,直接说 Gemini 3.1 Pro 本身的问题。我就按网页上的顺序一个一个来讲。
CSS 山水画
用纯 CSS 绘制中国传统山水画,仅使用 border-radius、gradient、clip-path 等属性实现山峦、流水、云雾、松树等元素,测试 AI 对 CSS 图形绘制与艺术表现力的编码能力。

Gemini 3.1 Pro 的整体意境还不错。
远近虚实,诗歌和印章,都考虑到了,流水和飞鸟的效果,可能是几个模型中表现最好的。
但是也有致命的问题,印章有点偏,树木和凉亭完全崩了。本来是一篇高分作文,但是犯了低级错误,只能给不及格了。
还有一个问题不是很明显,但是也凸显它能力不足。
右上角的诗本意是要竖着显示,从右往左读,古味儿十足。但是它写代码的时候用了 br 标签来换行,感觉有点小学生水平,最后也没有达到目的。
赛博朋克清明上河图
将经典名画《清明上河图》以赛博朋克风格重新演绎,测试 AI 对复杂视觉场景生成与艺术风格融合的编码能力。
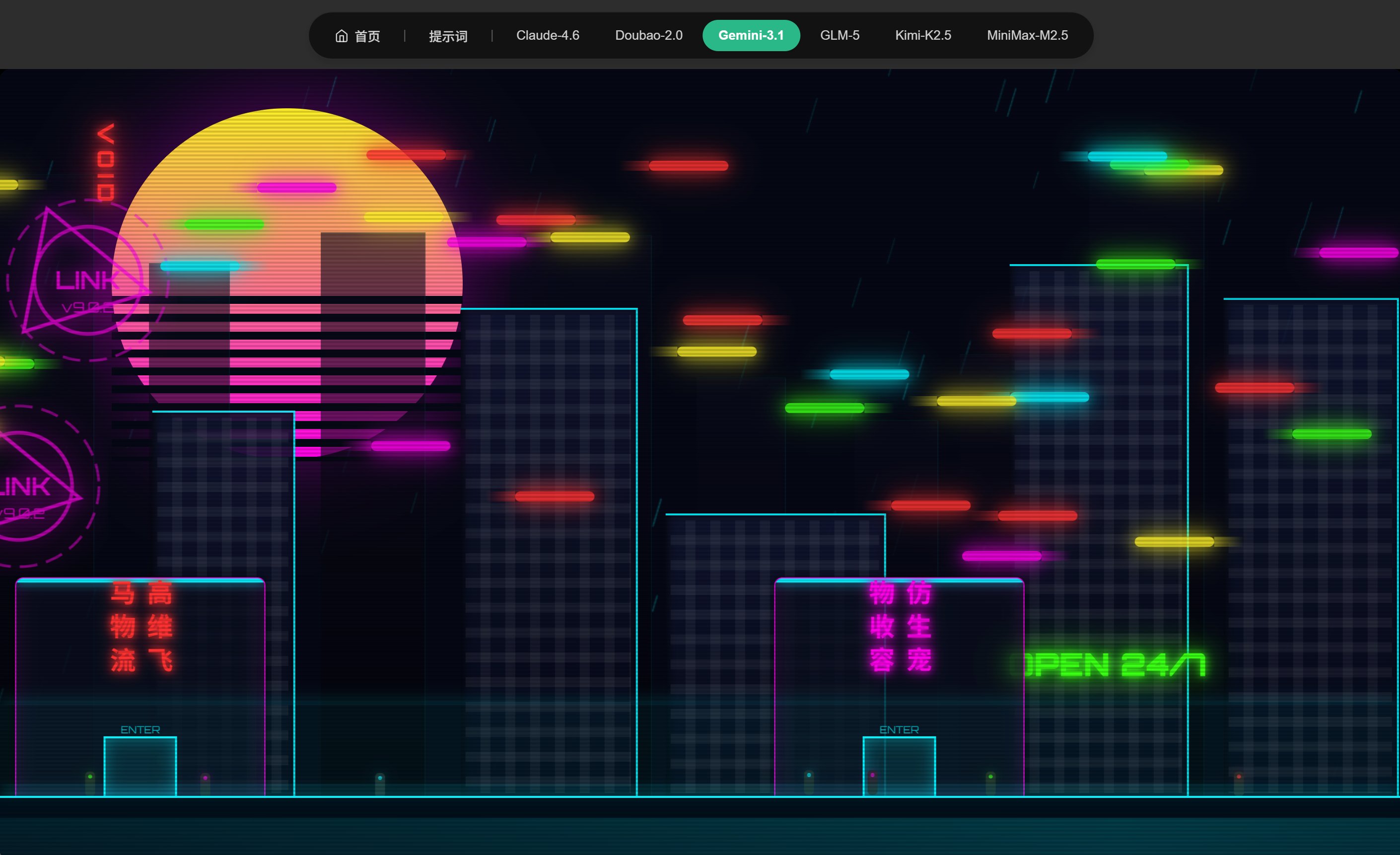
这个例子中,Gemini 代码直接出错,导致页面只显示一个太阳,没有任何其他东西。
关键点错误信息如下:
// 错误代码:
b.style.height = randomRange(40vh, 85vh) + 'px';
b.style.height = randomRange(35vh, 75vh) + 'px';
// 修改代码:
b.style.height = randomRange(40, 85) + 'vh';
b.style.height = randomRange(35, 75) + 'vh';
错误原因是在 JavaScript 中无法直接将 40vh 像数字那样传给函数,这会导致引擎报出标识符错误( SyntaxError )。由于这个致命的语法错误,整个 <script> 代码块崩溃,随后页面上所有的建筑、行人、商铺元素都无法生成,甚至连最核心的滚动循环(Scroll Loop)代码也无法执行。
测试了 6 个 AI 模型,这一个例子直接出错的也就 Gemini 了。
我本来的原则是只测一次,但是我实在是太好奇一个点了:Gemini 3.1 Pro 这么弱么?所以再试了两次。


这两次的表现中规中矩,但是可以看到,它每次出来的结果,差异还挺大的。另外,或多或少有一些指令执行不到位的地方。
Emoji 泰坦尼克号
用纯 Emoji 再现泰坦尼克号经典船头场景,包含船只动画、日落背景、海浪效果及 Web Audio API 背景音乐,测试 AI 对创意动画与音频合成的编码能力。

这个例子是做得很不错的。鸟倒着飞是唯一的 bug,我对比了一下其它模型的表现,好像大家对这个正反理解都不好。出来这个问题之外,这艘巨轮的比例(最佳),以及日夜的轮换,海浪和巨轮之间的位置关系,都表现得非常好。
分形烟花秀
2026 新年烟花动画,要求实现分形几何烟花爆炸、抛物线轨迹与重力效果,烟花轨迹汇聚形成”2026″字样,测试 AI 对数学动画与粒子系统的编码能力。
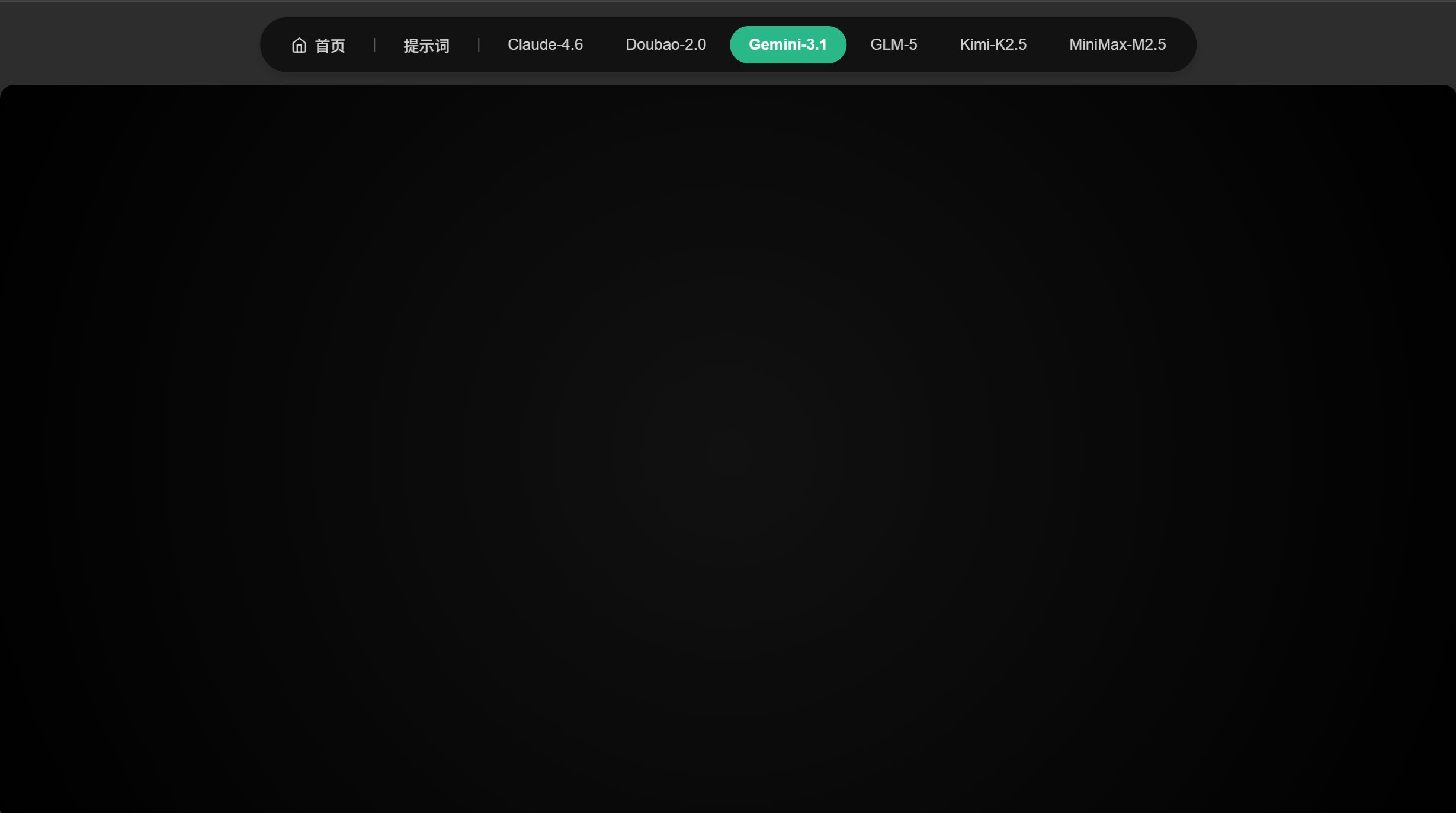
Gemini 又开始犯低级错误了。
看了一下 JS 代码,大概的错误是:“在 phase 还没被 let 初始化时就用了它”;
第一次出错,我帮它分析和纠正了,这次我就不干预了,让他错,让所有人都看到它低级错误。
五子棋对弈
15×15 棋盘的五子棋游戏,包含木纹棋盘、AI 对弈、落子动画、胜利粒子特效、悔棋功能及 AI 思考指示器,测试 AI 对博弈算法与复杂游戏逻辑的编码能力。
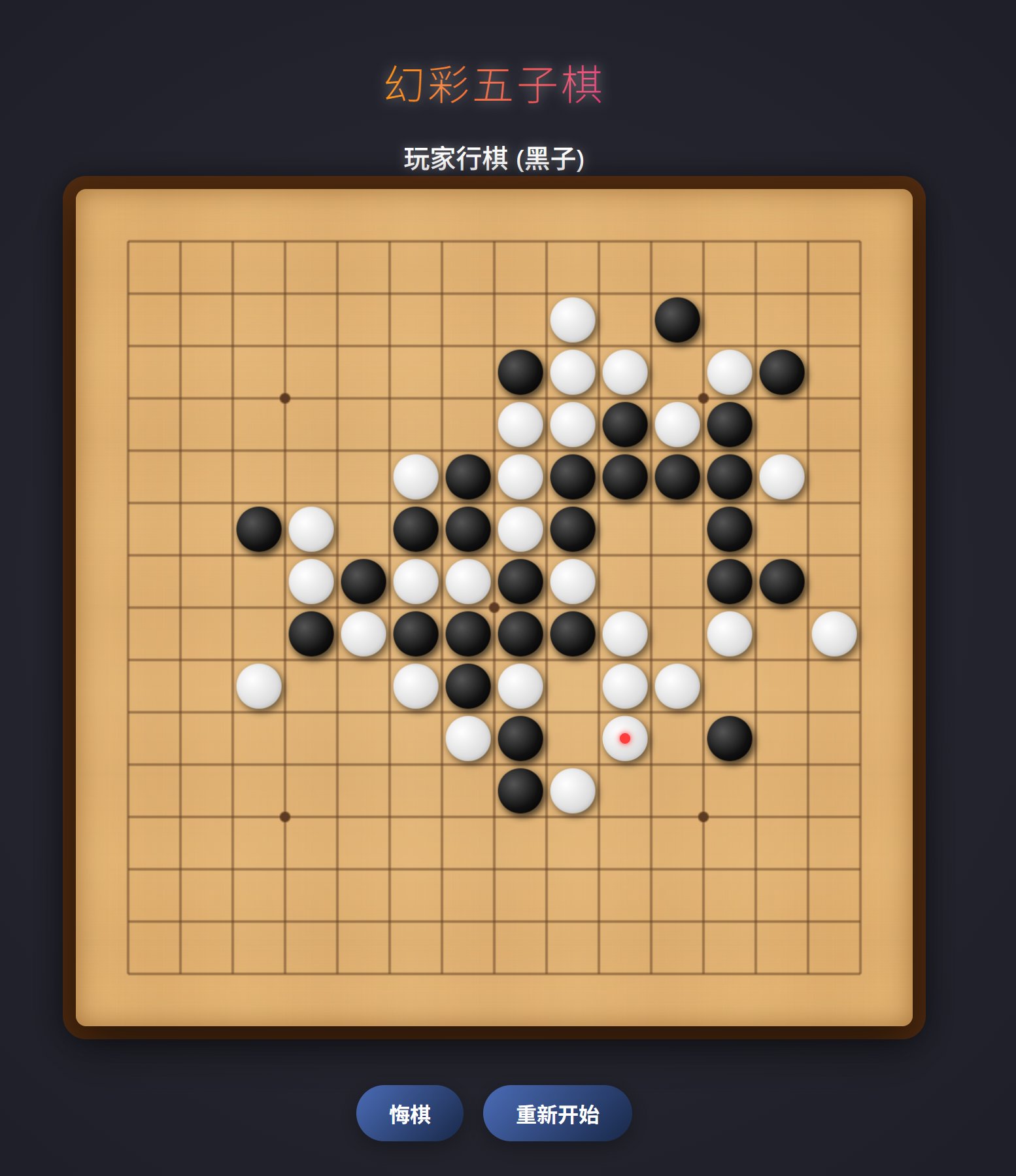
这个例子,除了棋子的摆放位置之外,其他部分做得非常好。
我查了一下正常的五子棋应该是放在交叉点上的。但是它放在了正方形中。除此之外,它的棋盘,棋子效果都做得很好,另外 AI 下棋的水平也非常高!不愧是 DeepMind 出品,“黑白子”下棋这一块就是牛哈哈~
无限循环冒险
复古 CRT 终端风格的文字冒险游戏引擎,包含状态管理、叙事生成、ASCII 艺术渲染及蝴蝶效应逻辑系统,测试 AI 对复杂游戏引擎架构的编码能力。
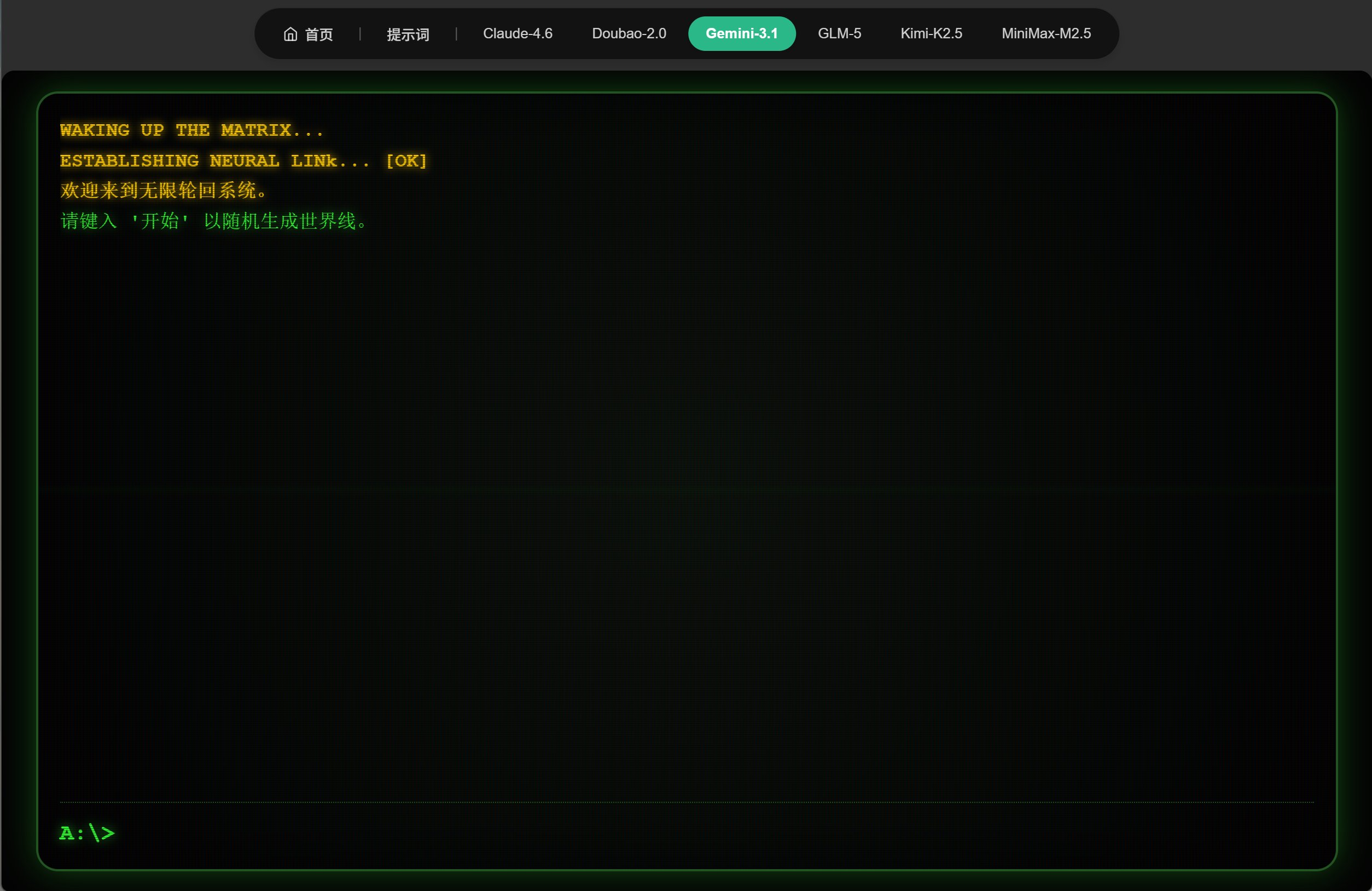
这一个项目做的挺不错的,动画效果非常到位,慢慢出现的提示,闪烁的 A:>,以及内部的叙事逻辑,都表现不错。唯一的问题是第一次输入数字后无法继续,需要再输入一次。
霓虹冲刺跑者
赛博朋克风格的横版跑酷游戏,支持双段跳、随机障碍物与金币、计分系统、视差滚动背景及粒子爆炸特效,测试 AI 对游戏循环与物理引擎的编码能力。

这个例子又有点翻车了。主角设计成一个正方形,有点抽象。主要是第一轮玩完之后,后面就会出错。不太聪明的样子。
3D 太阳系模型
基于 Three.js 的交互式 3D 太阳系模型,包含八大行星、月球、土星环、星空背景及行星信息卡片,支持拖拽旋转与缩放,测试 AI 对 3D 场景构建的编码能力。

这个例子对 AI 来说其实很简单,大家都差不多,很难分出胜负。但是 Gemini 的表现,真的是让人大跌眼镜。土星的土星环大到离谱~~这已经是一个巨大的 BUG 了。
古诗词代码雨
以古典诗词实现 Matrix 风格代码雨效果,每列显示完整古诗,悬停暂停并展示诗人信息,包含 20 首以上古诗词,测试 AI 对 Canvas 动画与交互特效的编码能力。
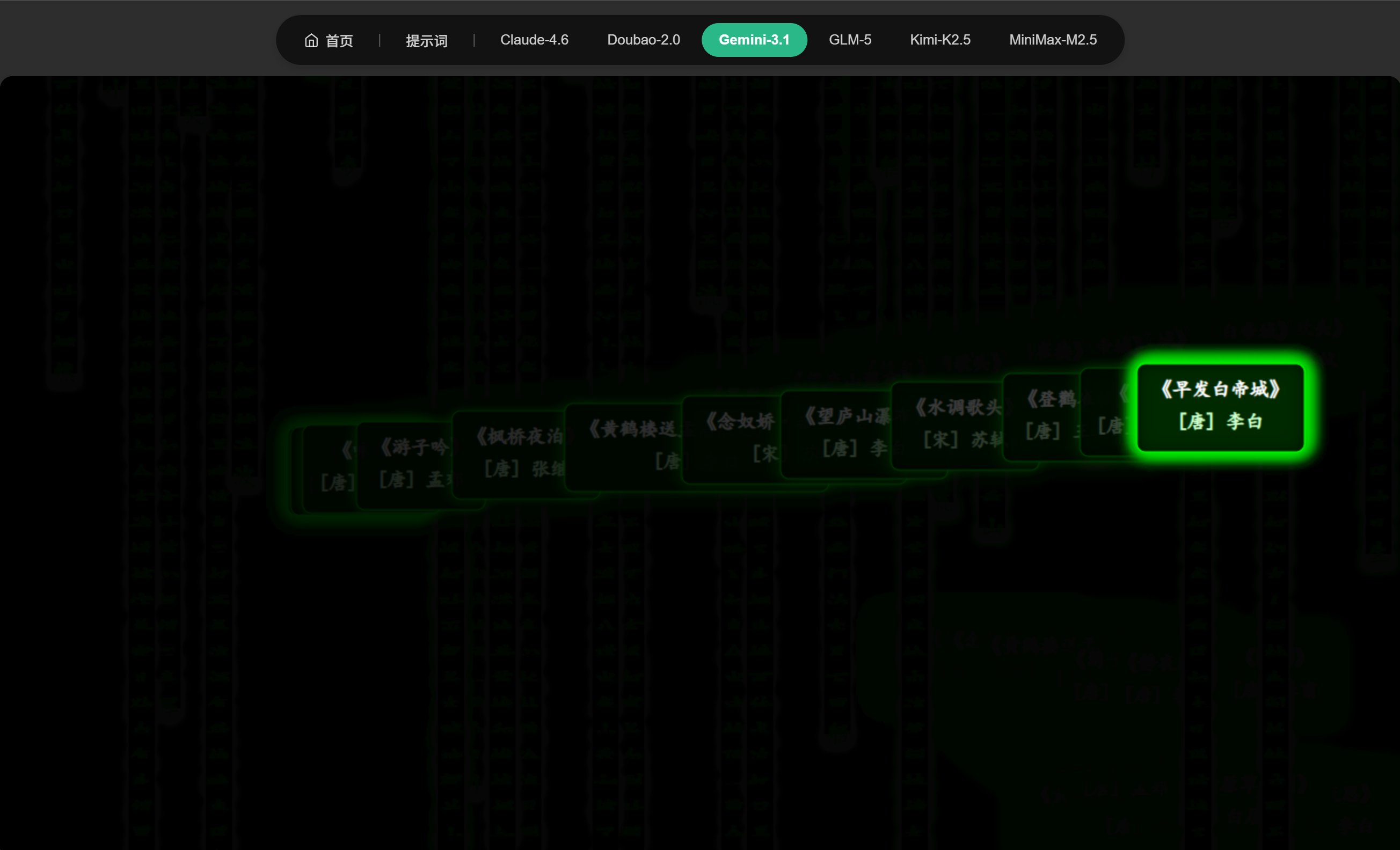
这个例子也崩了,代码雨落完之后就空了,鼠标移动出现大量残影。体验非常不好!
9 个里,有 5 个出现了比较明显的问题,其中有两个是代码错误,另外三个属于应用逻辑的问题。
另外我发现 Gemini 3.1 Pro 这个模型运行非常慢。我是在谷歌的官方 IDE Antigravity 上进行的测试。需求给它之后,思考时间动不动就会高达 180 秒,这个过程不写一行代码,然后它开始创建文件,这个过程等很久很久。
然后还时不时就撞墙:
The model's generation exceeded the maximum output token limit.
毫无效率可言!
最后,我简单总结一下问题:
1.容易出现低级错误
2.思考时间特别长
3.逻辑能力比较弱
4.发挥不太稳定
当然有几个例子也表现不错,但是整体给人的感觉不是太好,按理说谷歌的最新模型不应该犯那些低级错误。
有人说这个模型是为了赶时间,先放出来的半成品,也不是不可能。总的来说,能力未必很差,但是稳定性有点差,工作效率有点低,不太适合拿来干活。
目前看来,Google AI Pro 的配套服务中,也就是 Banana Pro 是真的强,到现在还是 No. 1 的存在。还有一个是 Antigravity 可以使用 Opus 4.6,这个要比官方的弱一些,但是毕竟是 Opus 4.6 啊。
最后再给大家分享一个有意思的点:

我在生成跳跳跳这个游戏的时候,突然发现好多个例子的“最高记录”都一样。然后查了一下代码,惊奇的发现,几个国产模型对 key 和变量的命名居然都一模一样,这是为什么?
Claude 和 Gemini 3.1 是和国产模型是明显不一样的。Gemini 3.1 比较简洁,Claude 4.6 最简洁。谷歌的水准基本证明了它现在是真的在独立研究,在走自己的路。而几个国产模型,好多问题上表现大差不差,就有点奇怪了!
今天 Anthropic 专门写了一个报告,控诉国产 AI 公司通过伪造第三方渠道蒸馏它的数据。我现在都怀疑,是不是有专门的第三方数据提供商,把蒸馏的假数据卖给了国内的 AI 公司……纯属瞎猜啊,如有雷同,纯属巧合。
绕了一圈,目前真能干活的也就 Claude 4.5+ 和 GPT5.2+,最能干的还是 Claude,这一点毋庸置疑。测试越久,结论越清晰!
9个测试实例都已经上传了:https://topai.tonyhub.xyz/


关于作者
tony
某人