8G,12G显卡看过来!Flux kontext GGUF节点安装和使用
“8G显卡,馋哭了!”“8G能不能玩,不能就算了!”看来 8G玩家还挺多。今天就来尝试下解决这些玩家的痛点。无论是网上攻略还是GPU都提到了通过GGUF模型可以降低显存要求。
所以,今天主要是讲如何使用GGUF模型,包括模型从哪里下载,使用什么节点,如何修改工作流。在昨天的基础上,完成今天的内容并不会太难。
下面就直接进入正题!
模型下载
使用GGUF是需要下载单独的GGUF模型。
GGUF(GPT Generative Unified Format)是一种专门用于大语言模型(如Llama、Mistral等)推理的模型文件新格式。
- 兼容性更好:支持更多模型结构(不仅仅是Llama系列)。
- 信息更丰富:文件内可以保存模型结构、参数、词表、量化信息等多种元数据,方便后续加载和复用。
- 体积优化:支持多种量化方式,进一步缩小模型文件体积,适合本地、边缘设备部署。
- 生态广泛:被Ollama、llama.cpp、lmdeploy、ComfyUI、text-generation-webui等多个AI推理工具支持。
这个模型已经有人做好了 ,只要打开下面这个地址:
https://huggingface.co/bullerwins/FLUX.1-Kontext-dev-GGUF/tree/main
可以看到如下内容:
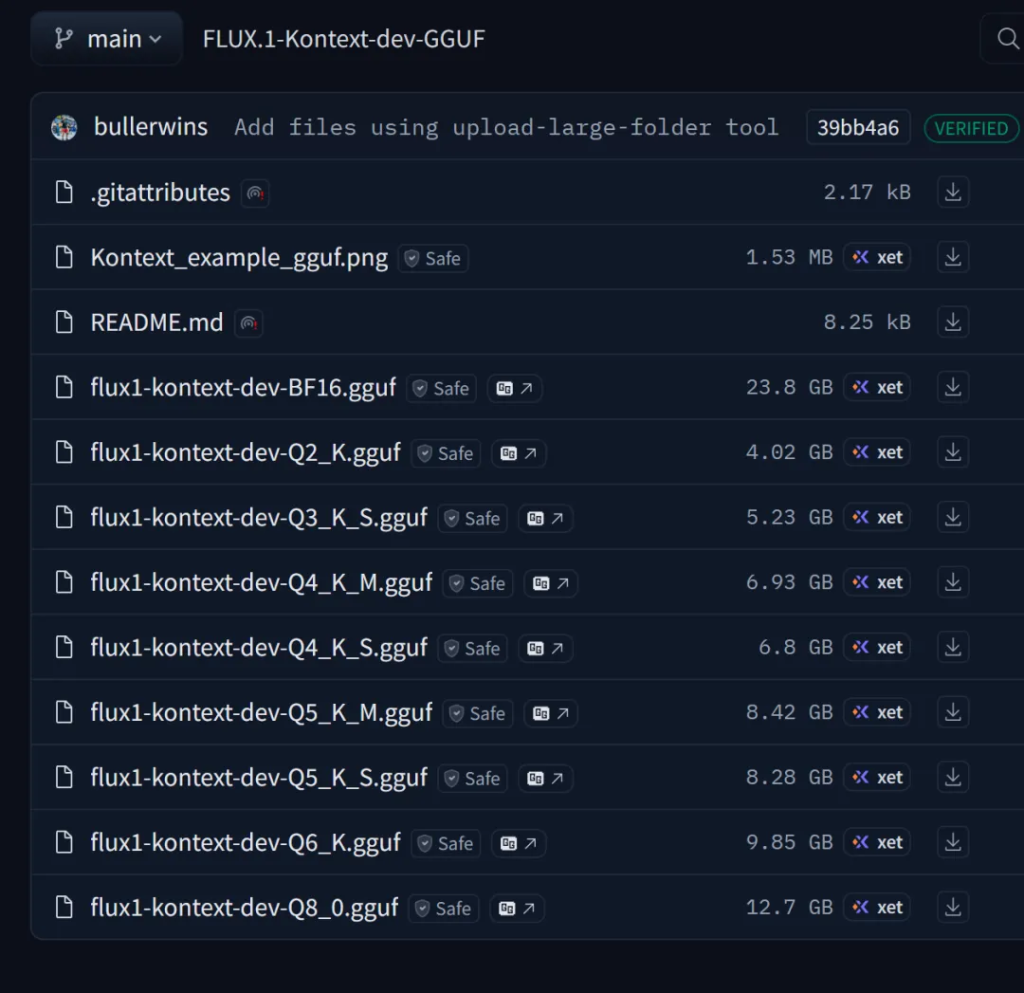
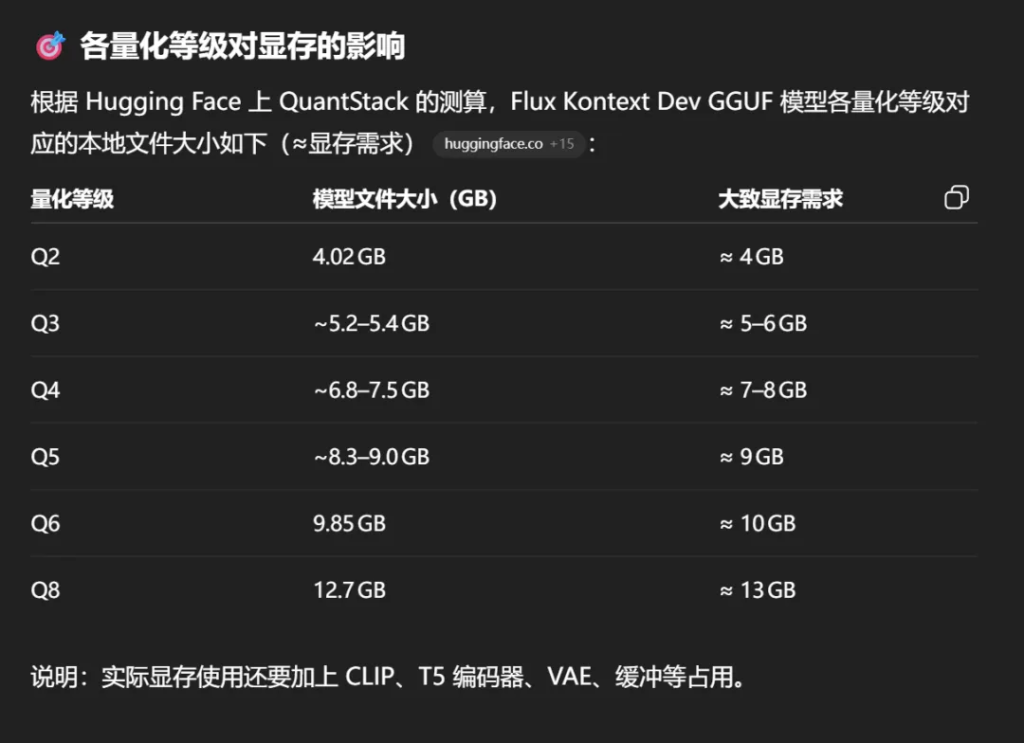
根据自己的情况来下载模型,显存小的就下载小的模型。显存大点的就下载大一点的模型,从23.8G到4.02GB任君选择。如果不确定,可以参考开头的截图。或者Q2,Q4,Q6,Q8分别下载一个。下载完成之后放到unet文件夹里面。
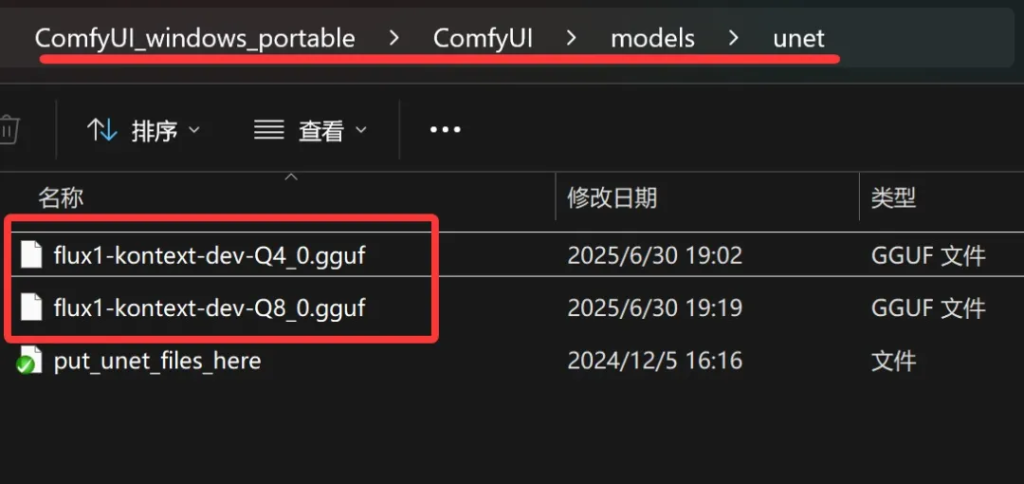
这样模型部分就完成了。
插件安装
有了模型之后,还需要专门插件和节点去加载这个模型。
插件地址:
https://github.com/city96/ComfyUI-GGUF
根据项目主页的介绍单独安装,也可以通过ComfyUI Manger来快速安装。
下面以ComfyUI Manager为例:
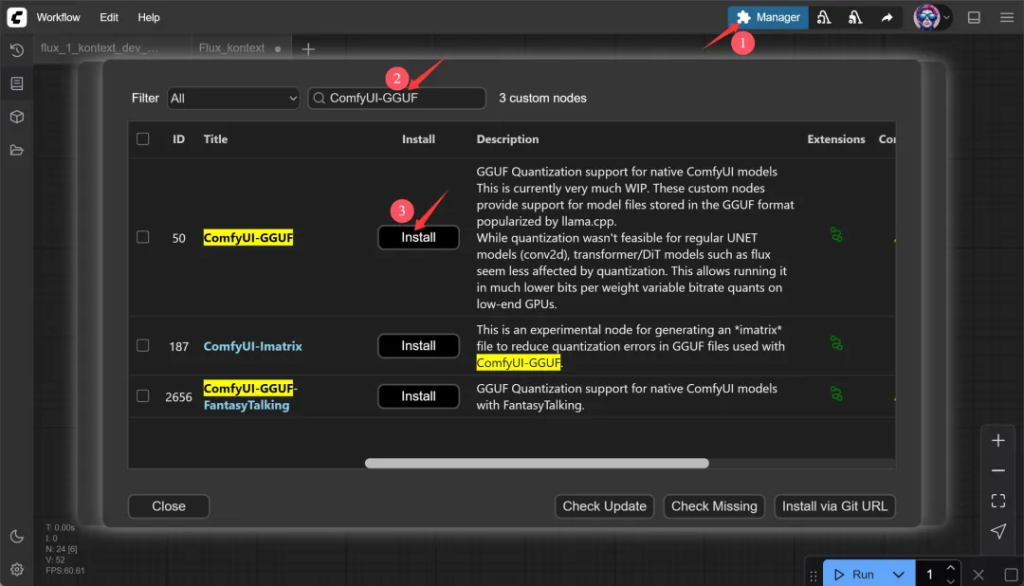
打开ComfyUI后右上角有一个Manager按钮,点击一下会弹出一个窗口,然后选择节点管理。
然后搜索ComfyUI-GGUF。
搜索到了之后点击Install 开始安装。
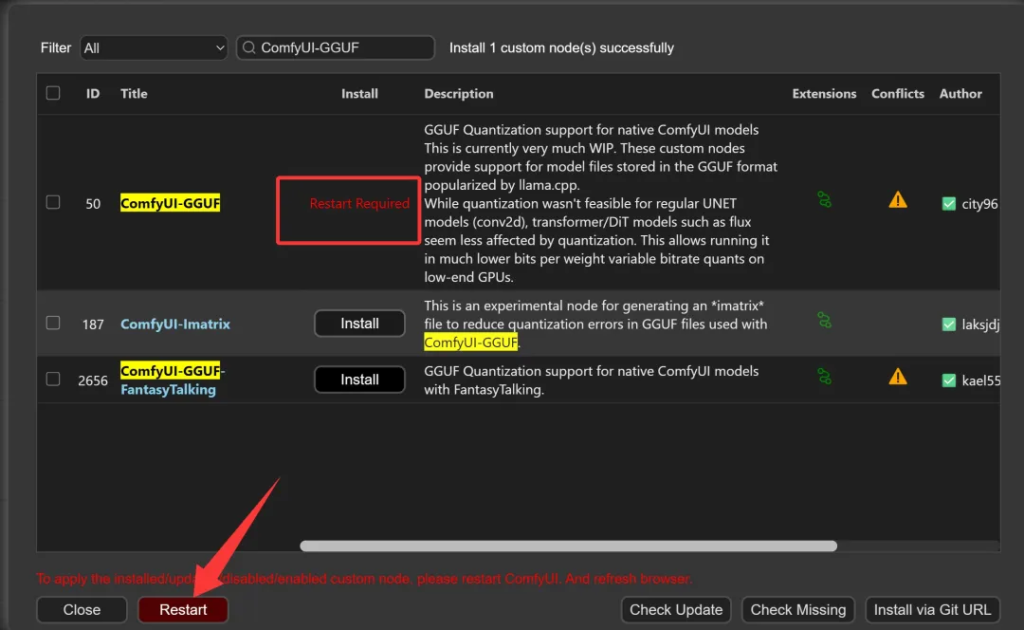
这里可能会有好几个结果,选名字最匹配,后面Star数量最多那个。插件安装完成之后,会要求重启软件。点击左下角的Restart重启软件。
这样插件就安装完成了!
工作流修改重启软件之后,双击工作流空白处,输入GGUF。
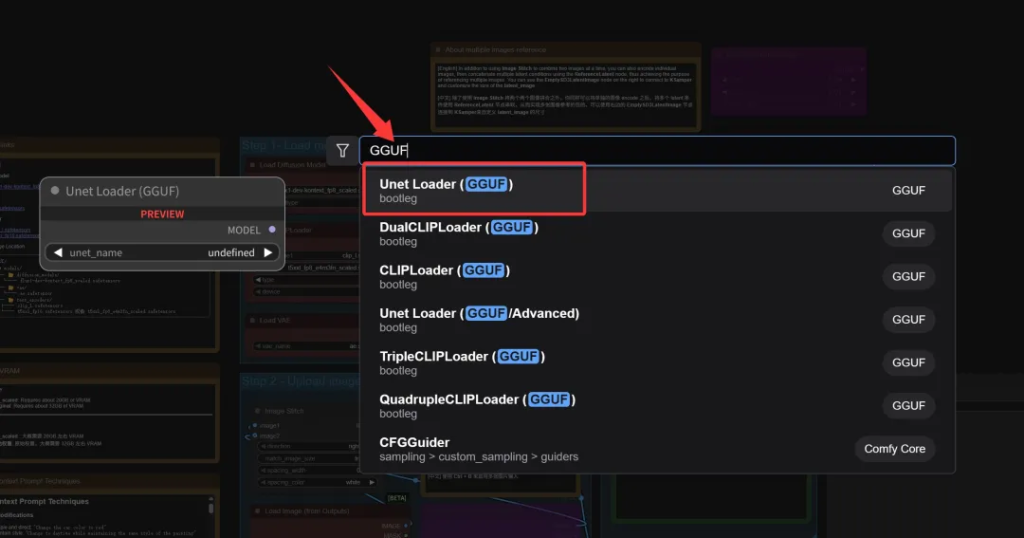
此时就可以看到很多GGUF相关的节点了,选中Unet Loader来加载FluxKontext的GGUF模型。
如果你是先安装了节点,重启之后才放模型,记得要刷新以下节点定义。
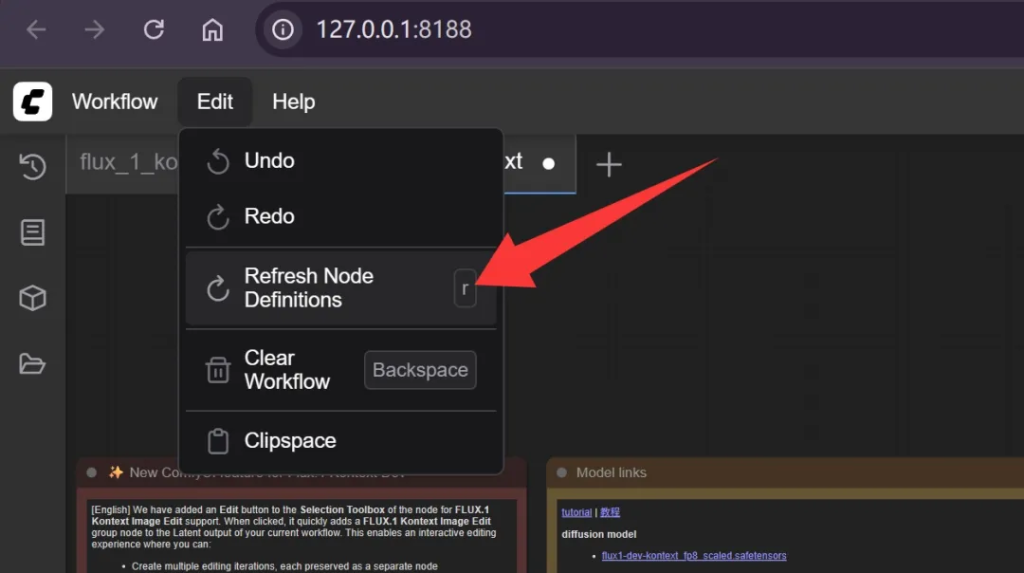
这样节点才能读取到模型!
然后把原先接在Load Diffusion Model上的线换到Unet Loader上。
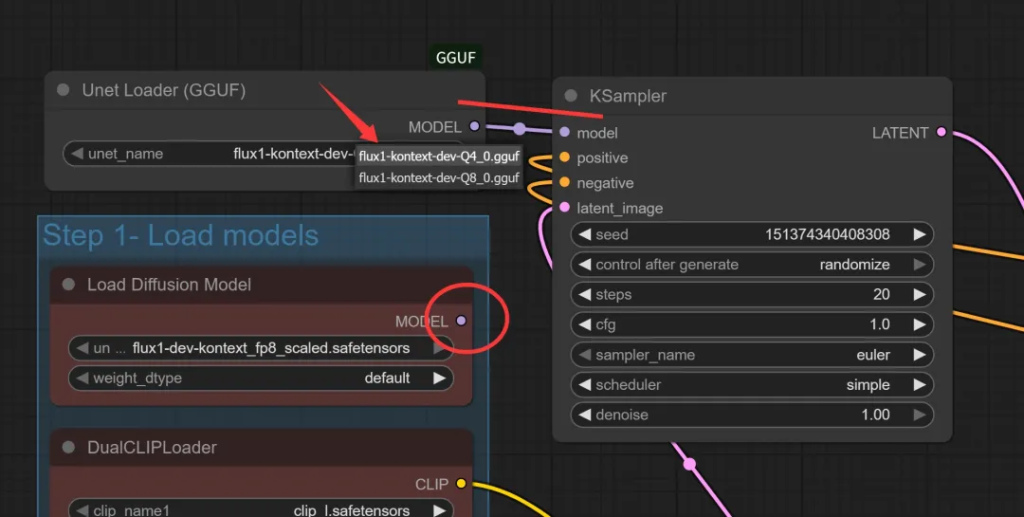
Unet Loader 里通过unet_name可以切换具体的gguf模型。
为了进一步节省空间,可以把DualCLIP加载器也换一下:
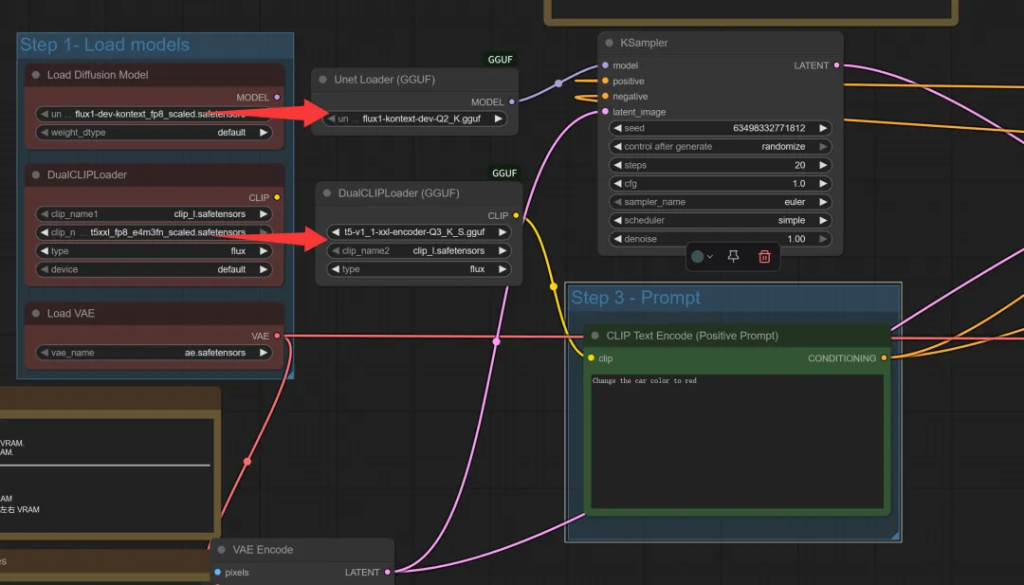
换成GGUF版之后,clip_name1换一个叫“t5-v1_1-xxl-encoder-gguf”的文件。
这个文件可以通过这个地址下载:
https://huggingface.co/bullerwins/FLUX.1-Kontext-dev-GGUF/tree/main
同理数字越小文件越小,越省显存!
接下来就可以点击运行测试了。
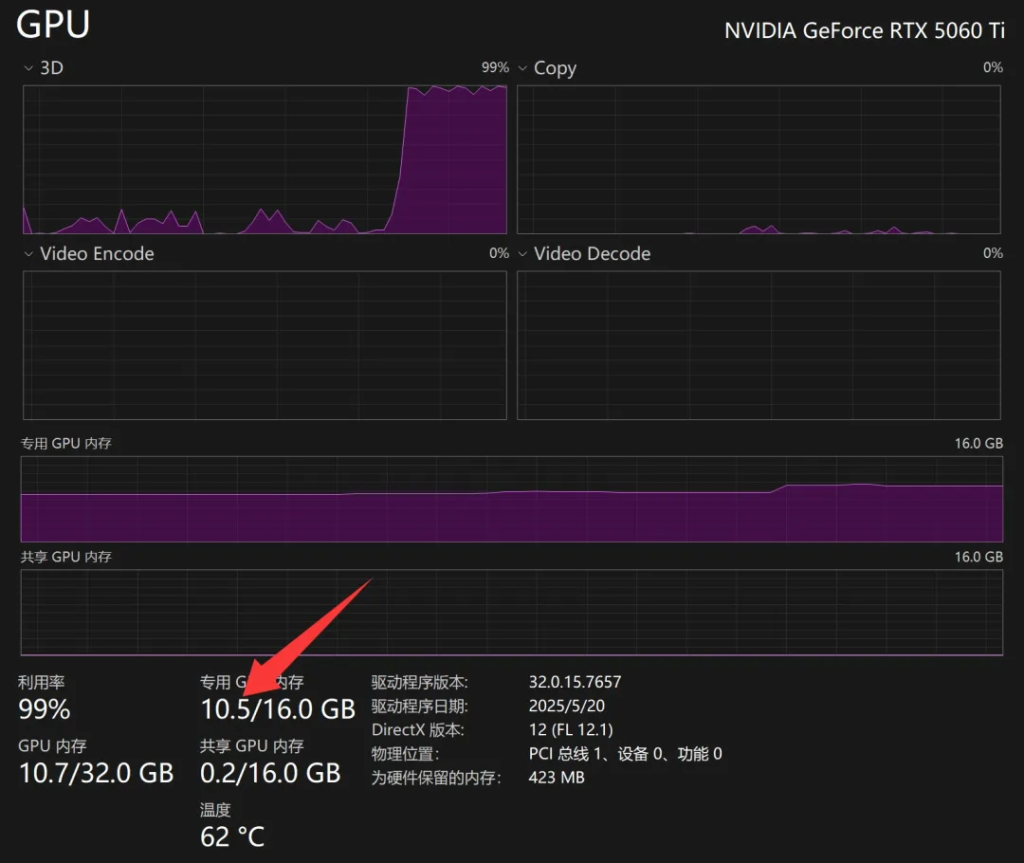
可以看到运行过程中只用了10.5G显存。
我的电脑在不运行Flux的时候,其他软件大概占用了3G显存。所以FLUX这次总共用了7.5GB左右。所以理论上8G挤一挤也是够用的。12G应该能轻松驾驭。
整个下载,安装,修改并不是太复杂。只要上一篇的基础打好了,这里会简单很多。
因为我现在手上没有16G以下的显卡,所以没办法精准测试,但是这种方式很显然会降低显存需求。毕竟模型小了,显存需求肯定会减少。
另外在测试给汽车换颜色的例子中,即便用最小尺寸的模型,结果好像并没有受到太大影响,初略看一下依旧完成得不错。

在我们把白车换红车的例子中。仔细对比,在翅膀内测,低显存版有一点泛红,正常是应该黑色。但是整体在可接受的范围内。
既然入坑了,我们就多研究研究。下面会尝试下网上的加速方案。据说可以提速到20~30秒一张图,而且几乎不影响效果。如果真的可以做到,那确实很香,体验会拉高很多。
另外我的MacMinM4一直躺着不干活,所以我肯定也要把它拉出来溜溜。
相关的软件和模型我传网盘,给公众号发送关键词“kontext” 获取!

关于作者
tony
某人