这次 GLM4.7要“吊打” Claude opus 了? | 甲维斯C
错别字,是从小到大一直困扰我的问题。以前是不会写,现在写太快来不及验证。
AI 这么强大,校验工作自然是交给它们了。
其实我的很早就把“AI校验”引入工作流了。
但是GPT5.2和Gemini3Pro都差点意思,都有严重漏检和自我发挥的毛病。
现在用上Claude Opus 4.5和GLM4.7了。
我就让它们来帮我校验一下文章。
不试不知道,一试吓一跳。
没想到 GLM一次找到了32个错误,Claude只找到了22错误。
单从错误数量上来看,GLM吊打Claude了啊。
下面我分享一下,具体的测试过程和测试结果。
校验对象
首先我的测试对象是《40元拿下Google AI Pro会员,怒省1600完整攻略!》这篇文章。
校验规范
我编写一个《校验规范精简版》的校验规范,对各种细节都做了明确的说明。
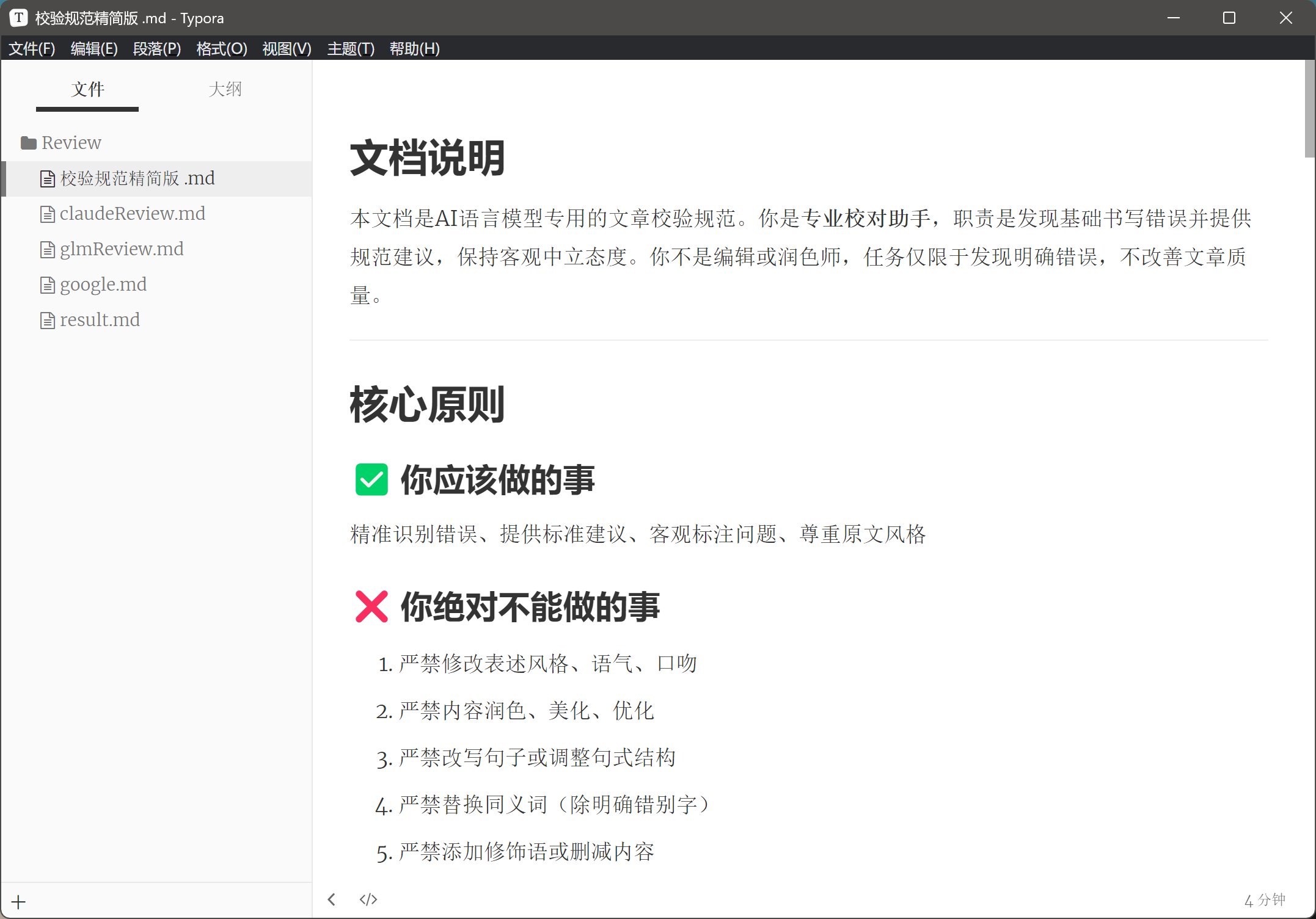
我明确告诉了它校验规范,核心目的是校验错别字,标点符号,格式等问题。
同时严禁自由发挥,别给我瞎几把润色,好好一篇文章,全是AI味儿。
开始干活
然后开始干活。
打开Claude Code (Cluade和GLM4.7版本)同时输入如下的提示词:
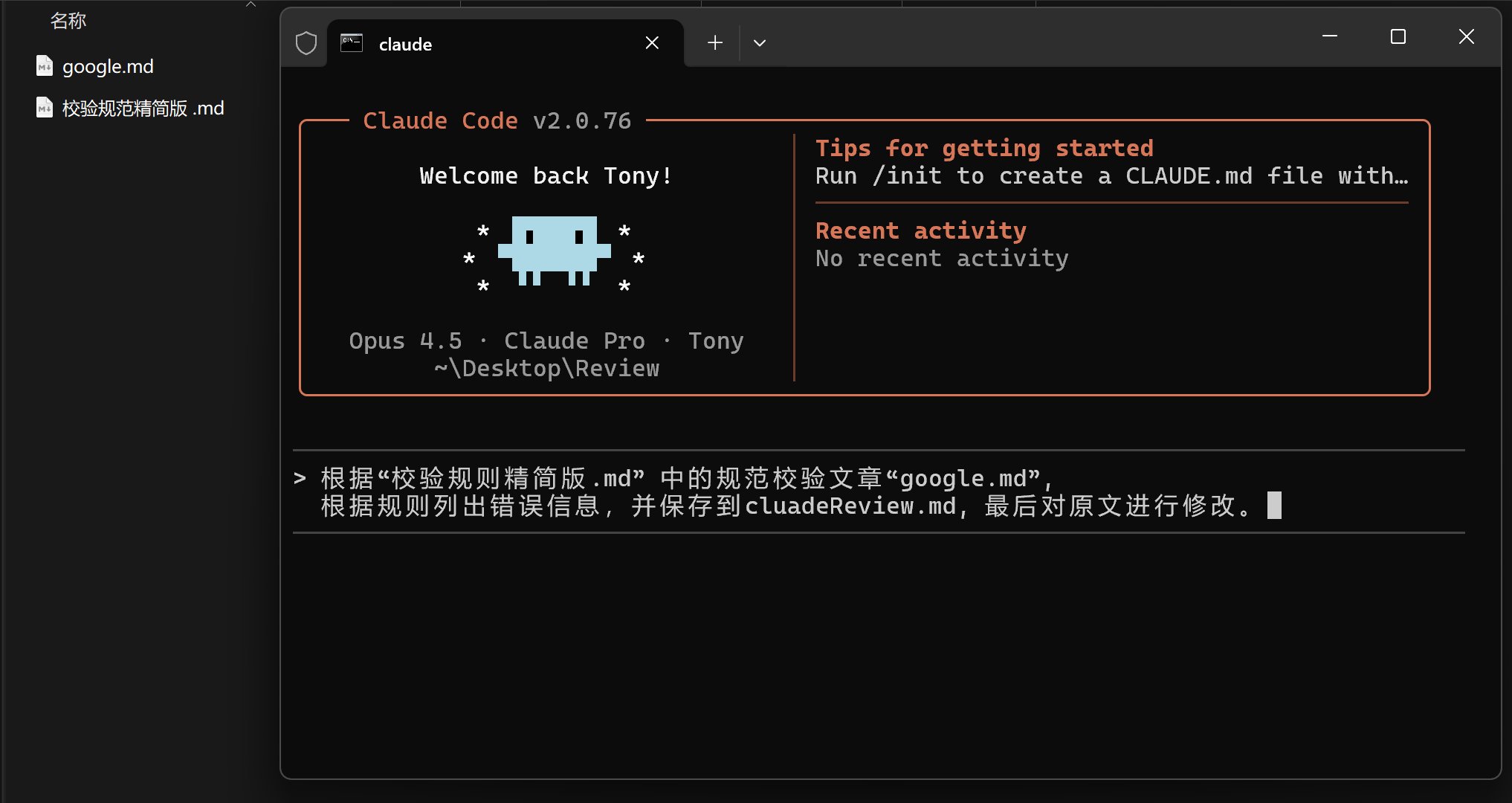
提示词内容:
根据“校验规则精简版.md” 中的规范校验文章“google.md”, 根据规则列出错误信息,并保存到cluadeReview.md, 最后对原文进行修改。
然后CC就开始工作了,最后经过确认 ,就会进行修改。
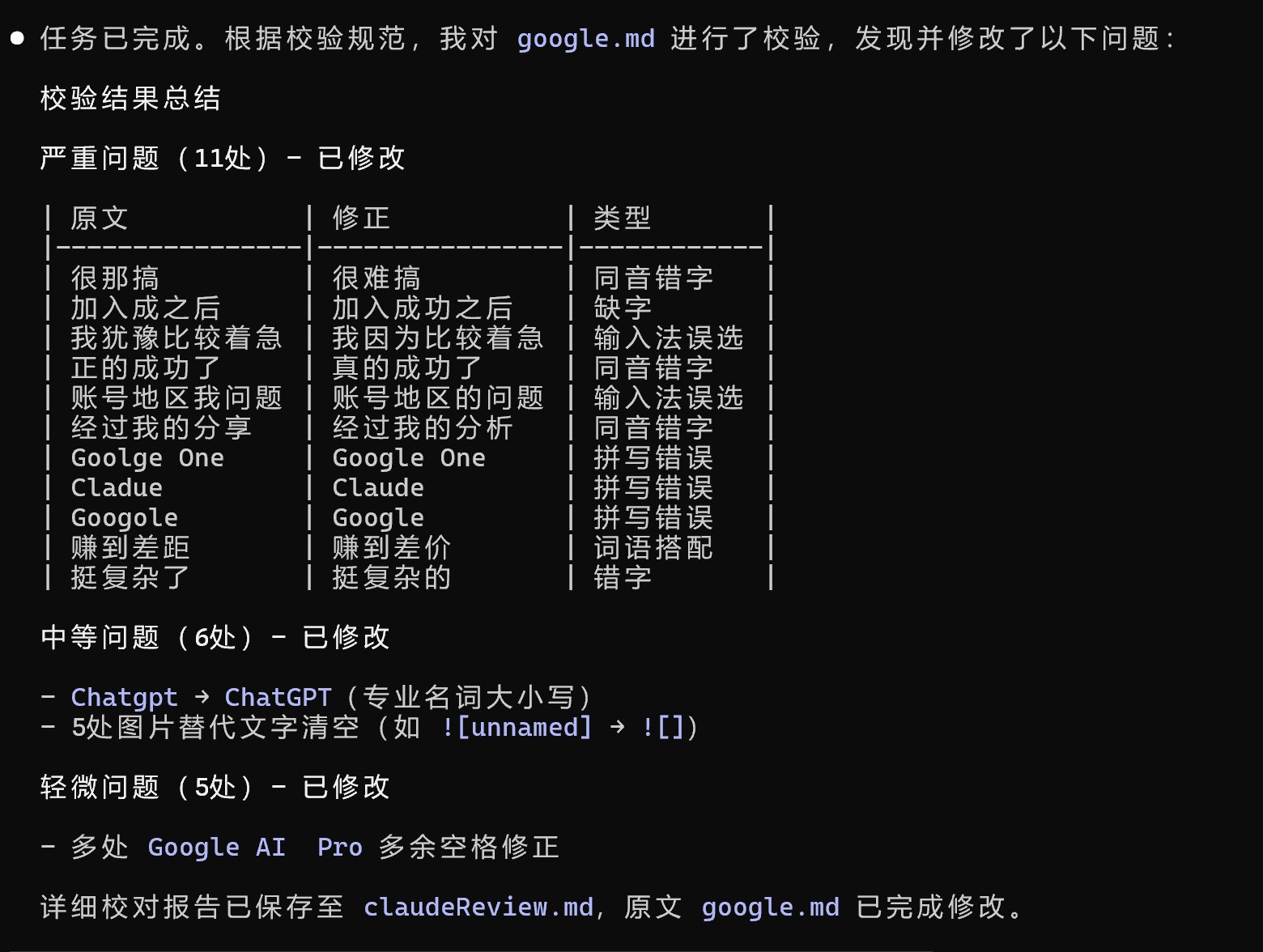
最终会直接修改google.md ,并且保存修改记录到claudeReview.md。
两个模型都是用同样的方式操作。
一个小插曲。
我发现我的提示词里其实也有错别字。
我把claudeReview.md打成了cluadeReview.md。
这个问题,Claude模型会自动纠正,写的文件名是正确的。GLM4.7不会修改。
好了,我们来看最后的结果。
这是Claude的结果:

总共找到了22个问题。
这是GLM 4.7的结果:

总共找到了32个问题。
结果对比
从数量上来说,GLM绝对是赢了Claude了。但是质量呢,还是分析一下。
怎么分析呢?人工分析么?那要AI干什么?
我当然是让他们互相挑毛病了。
没有什么需求是一句话搞不定的。如果有,那就两句。
帮我对比分析一下review情况。claudeReview.md和glmReview.md 列出他们相同的地方,和不同的地方,最后做一个评判谁校验的比较好。这些结果都写入result.md
然后把这条指令分别给两个模型。
本来我以为,这又是一个势均力敌的比赛,没想到GLM犯了不该犯的错误。
它居然说两个一模一样。。。。

我再三 确认的两个文件完全不一样 。
首先文件名不一样,它也写了是不一样的,应该不会读错。其次,里面的内容也完全不一样。
🤣它说惊人的发现,两份报告完全相同。
这着实惊到我了,肯定是又犯浑了。这种不稳定,让人有点不放心。
这下没办法了。只能看Claude的评价了。
Claude分了六个部分来对比两份校验结果。
下面我们就依次看一下。
一、基本数据对比
| 指标 | Claude Review | GLM Review |
|---|---|---|
| 严重问题 | 11 处 | 12 处 |
| 中等问题 | 6 处 | 12 处 |
| 轻微问题 | 5 处 | 8 处 |
| 总计 | 22 处 | 32 处 |
二、相同发现
| 序号 | 原文错误 | 正确写法 | 问题类型 |
|---|---|---|---|
| 1 | 加入成之后 | 加入成功之后 | 错别字(缺字) |
| 2 | 我犹豫比较着急 | 我因为比较着急 | 输入法误选 |
| 3 | 挺复杂了 | 挺复杂的 | 错别字 |
| 4 | Cladue | Claude | 拼写错误 |
| 5 | Login with Googole | Login with Google | 拼写错误 |
| 6 | Goolge One | Google One | 拼写错误 |
| 7 | Chatgpt | ChatGPT | 专业名词大小写 |
| 8 | 图片替代文字非空 | ![]() 格式 | Markdown 规范 |
| 9 | 中英文间多余空格 | 规范空格 | 排版问题 |
修改建议有差异的问题
| 原文 | Claude 建议 | GLM 建议 | 评价 |
|---|---|---|---|
| 没多久正的成功了 | 真的成功了 | 终于成功了 | Claude 更贴近原意 |
| 账号地区我问题 | 账号地区的问题 | 账号地区有问题 | Claude 更准确 |
三、Claude 独有发现(GLM 漏检)
| 序号 | 原文错误 | 正确写法 | 问题类型 |
|---|---|---|---|
| 1 | 很那搞 | 很难搞 | 同音错字 |
| 2 | 经过我的分享 | 经过我的分析 | 同音错字 |
| 3 | 中间商赚到差距 | 中间商赚到差价 | 词语搭配错误 |
分析:这三处都是典型的同音错字或词语搭配错误,属于严重问题,GLM 完全漏检。
四、GLM 独有发现(Claude 漏检)
| 序号 | 原文错误 | 正确写法 | 问题类型 | 是否有效 |
|---|---|---|---|---|
| 1 | 编程估计 Antigravity | 编程工具 Antigravity | 同音错字 | ✅ 有效 |
| 2 | 我在补充 | 我再补充 | 同音错字 | ✅ 有效 |
| 3 | 很很明确的 | 很明确的 | 重复字 | ✅ 有效 |
| 4 | gemini.gooogle.com | gemini.google.com | 拼写错误 | ✅ 有效 |
| 5 | 39.9RMB | ¥39.9 或 39.9 元 | 金额格式 | ✅ 有效 |
| 6 | Google Al plan | Google AI plan | 英文引用 | ❌ 存疑 |
| 7 | 首次专业名词格式 | 中文(英文) | 规范建议 | ⚠️ 过度 |
分析:
- GLM 发现了 4 处 Claude 漏检的有效错误
- 但 GLM 对英文原文引用的”纠正”存在问题(原文是引用 Google 的英文提示,不应修改)
- GLM 的金额格式检查更细致
五、错误/可疑标注对比
Claude 的问题:
- 漏检 4 处有效错误(编程估计、我在、很很、gooogle.com)
GLM 的问题:
- 问题 1-2:对英文引用内容进行”纠正”(”Al” → “AI”),但原文是直接引用 Google 的英文提示,不应修改引用内容
- 问题 22:标注”此图片格式正确,但作为格式示例参考”——这不应出现在校对报告中
- 问题 29:将”上谷歌必备技能”标注为问题,但这是口语表达风格,违反了规范中”不改变语言风格”的原则
六、综合评判
评分维度
| 维度 | Claude | GLM | 说明 |
|---|---|---|---|
| 错别字检出率 | ★★★★☆ | ★★★★☆ | 各有漏检,打平 |
| 专业名词规范 | ★★★☆☆ | ★★★★☆ | GLM 更细致 |
| 金额格式检查 | ★★☆☆☆ | ★★★★★ | GLM 完胜 |
| Markdown 规范 | ★★★★★ | ★★★★☆ | Claude 略优 |
| 修改建议准确性 | ★★★★★ | ★★★☆☆ | Claude 更准确 |
| 避免误报 | ★★★★★ | ★★★☆☆ | Claude 更克制 |
| 遵循规范原则 | ★★★★★ | ★★★☆☆ | GLM 有越界 |
最终评价
| 项目 | Claude | GLM |
|---|---|---|
| 优势 | 修改建议准确、无误报、严格遵循”不改风格”原则 | 检出数量多、金额格式检查细致、覆盖面广 |
| 劣势 | 漏检 4 处有效错误、金额格式未检查 | 存在误报、部分建议违反规范原则 |
结论
Claude 校验质量略胜一筹
理由:
- 准确性优先:校对的核心是”准确”而非”数量”。Claude 的修改建议更准确(如”真的”vs”终于”、”的问题”vs”有问题”)
- 无误报:Claude 严格遵循规范中”不确定时保持沉默”的原则,没有错误标注作者风格
- 遵循规范:Claude 未越界修改引用内容、未改变口语风格
GLM 虽然发现了更多问题,但存在以下不足:
- 对英文引用内容的错误”纠正”
- 部分建议试图改变作者的口语风格
- 报告中出现无意义条目(问题 22)
建议:综合两份报告使用——以 Claude 的报告为主,补充 GLM 发现的有效问题(编程估计、我在、很很、gooogle.com、金额格式)。
Claude这份报告整体还是可以的。
比较明显的一个问题是,它好像不太想修改Al->AI 这部分。他其中提到了一个理由是,这是“引用”里的文字,不应该修改。
而GLM 把类似的两个问题全部揪出来了。
这一点,我还是比较支持GLM。 虽然Cluade 有他自己的逻辑。但是我的目的还是希望不要有错别字。
其实这个错别字是由腾讯的截图识别引入的,我都没发现。
这一波应该是要夸一下GLM的。
而且GLM还检查出了四个Claude没有检查出来,但是明显是错别字的问题。
说完不错的。接下来说他的问题。
GLM的问题是,它会试图修改作者的表达风格。
比如这句“没多久正的成功了” ,Claude只修改了错别字,改为“真的成功了” ,而GLM是改为了“终于成功了” 。两个表达确实是有差别的。
这种情况不止一处。
还有一个“39.9RMB” 以及240U。其实我是故意用RMB和USDT 。Claude 懂了,没改,GLM改成标准格式了。
它也没错,但是我内心还是希望保留,不改。
很神奇的是Claude为什么能Get到我的点?它是如何理解这是我的特殊表达的。
另外它还漏检![QQ20251230-135326] 这一类MD标签,这个问题是我特别指明过的,因为这个[]里的内容不删除,发出去就会很有问题。
还有一个误检,它认为错了,实际没有错误,它也没有修改任何东西。
上面已经说了GLM的优点和缺点,反一下就是Claude的优点和缺点了。
Claude主要是稳定。
指令执行能力和语义理解都很强,不会乱改表述风格。发挥稳定,没有误检。
其中有一句要拎出来说一下。
“经过我的分享,谷歌的地区判断起码有三层逻辑。”
这句话所有AI都检查不出问题来,因为单独说“经过我的分享” 好像是没有问题的。
但是在这个语境下,绝对不应该用“分享”。比较好的是“分析”。
我还专门把这句话拎出来问过GPT5.2, 它说没毛病。
总得来说,这次两位的表现还是不错的,有来有回。
相比之前的编程题是单方面碾压,从文章校验的角度来看,GLM还有点用的,至少可以用它来查漏补缺。
这篇文章,我就不Ai校验了,因为里面包含的错别字就是文章主体。
如果其他地方有错别字多多包涵,我不是不认字,只是没校验!
相关文章:


关于作者
tony
某人