阿里又出好东西了,CosyVoice3开源了!
阿里在开源的路上是越走越广了。继上次 Z-Image 大热之后没多久,又出好东西了!
上一次是关于图片,这一次是关于“声音”!
阿里旗下的通义百灵一口气开源了两个重磅模型。
一个用于语音合成(包括声音克隆),叫 CosyVoice3
只需 3 秒录音,就能让你的声音无缝切换语种、方言与情绪——中、粤、日、英、开心、愤怒……9 种通用语言、18 种方言,通通搞定!
一个用于语音识别,叫 FunASR
一段嘈杂环境下的会议录音,AI 也能毫秒级输出文字,绕口令、RAP、背景音乐干扰,照样精准识别!
官方把这两个项目称为“语音双子星”,确实很贴切! 这两个模型其实不是第一天出现的,早就名声在外。在很早之前 CosyVoice2 就是最强的开源声音克隆模型了。
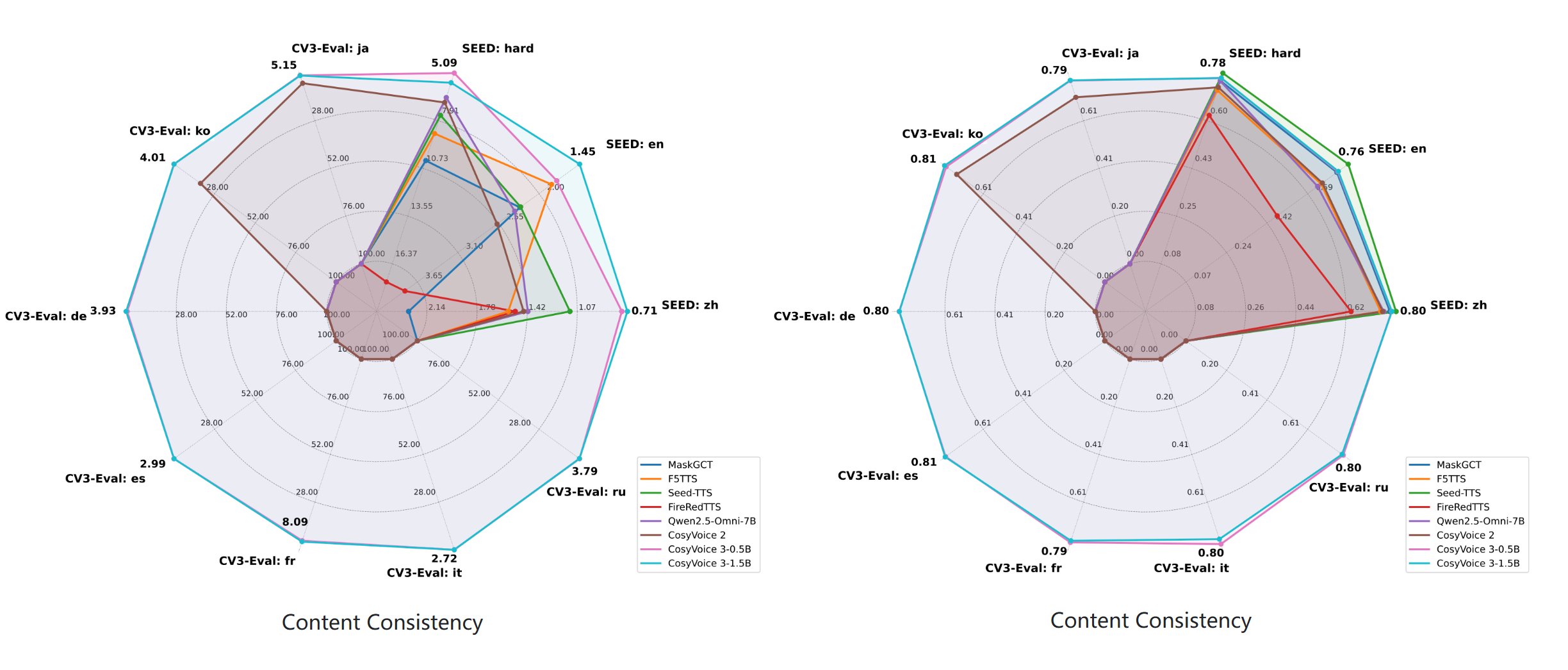
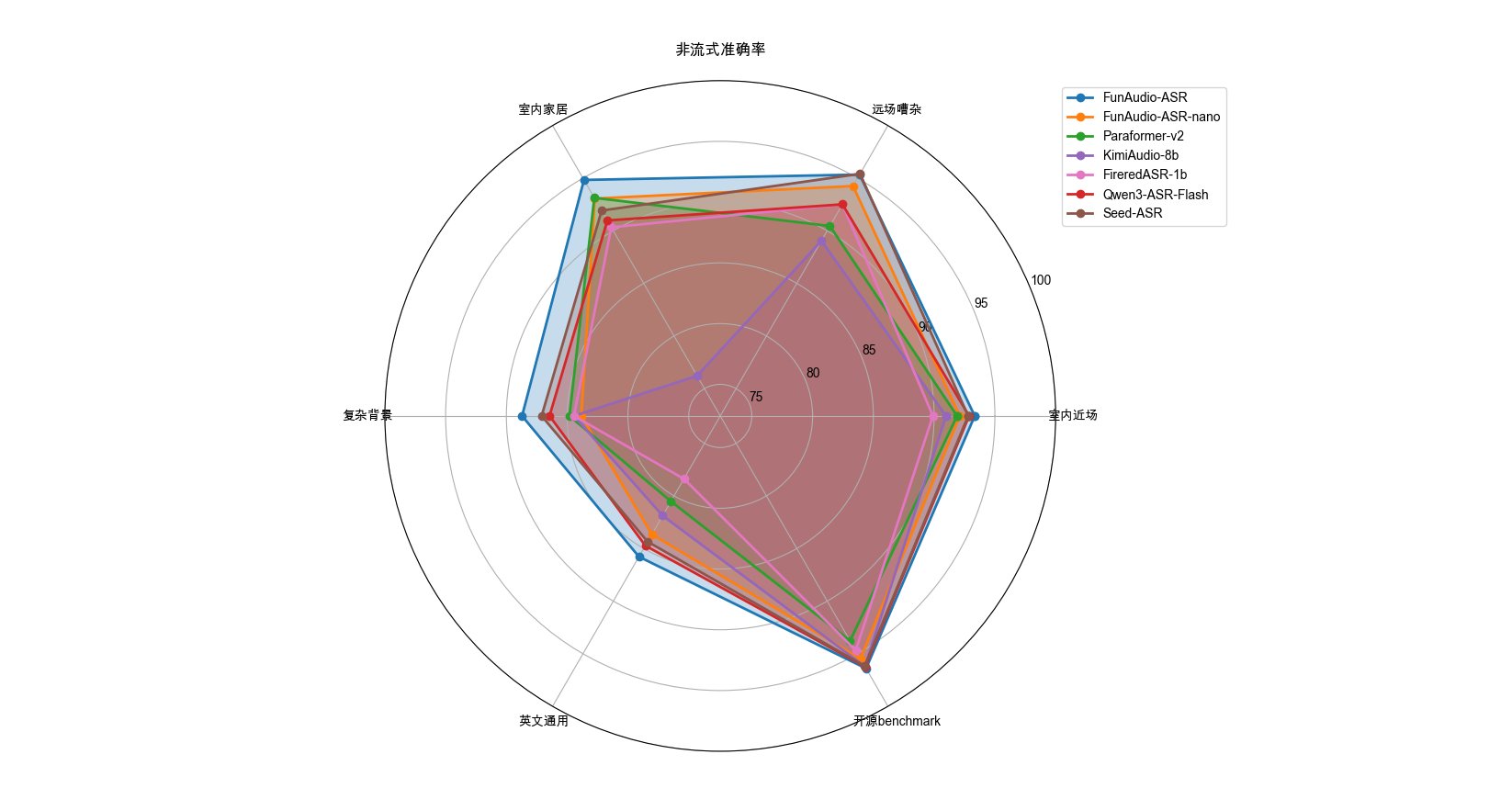
下面我抽取两张图片,一看就知道实力如何了:
这是 CosyVoice3 和其他同类模型的比较。
这是 FunASR 和同类模型的比较。
具体的介绍,这篇 文章 中说得非常清楚,各种应用场景、各种技术点,都写得很好了。我就不抄了。
我已经迫不及待要看效果了,不对,是要“听”效果了。
这个东西无法用文章来描述,也没法用眼睛来看。所以我就录歌视频吧。大家把声音开到合适的位置,感受一下,现在语音合成技术和语音识别技术到底有多强了。
最重要的一点是,这些技术全部开源了,所有人都可以使用。不需要去购买昂贵的软件,或者被按次数调用吸血。
听完这个声音,再来感受一下这个介绍:

应该是所言非虚吧。
同样的,看完这个视频后再来感受一下这段描述:
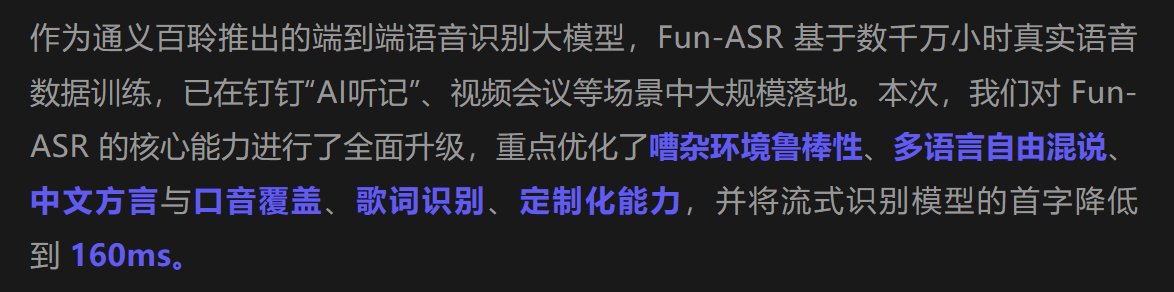
也应该是所言非虚吧!
其实从介绍的技术指标和演示中的使用场景中也看得出来,阿里这两个模型,不是那种拿来发发论文,搞搞榜单的模型,而是实打实能用的。很多技术细节都是奔着实用而去。
我敢打包票,通义这次开源的两个模型,在实战中可以吊打很多闭源和收费的模型。
不说了,我要准备下载模型,本地电脑上搞起来了。
同 Z-Image,我也问一句,有没有需要本地运行一键包的?
相关链接:
https://funaudiollm.github.io/cosyvoice3/
https://funaudiollm.github.io/funasr/
https://github.com/FunAudioLLM/CosyVoice
https://github.com/FunAudioLLM/Fun-ASR


关于作者
tony
某人