国产CodingPlan“玩不起”,玩GPT5.5去了!
难受啊!
最近国产的 CodingPlan 全面收拢,要么转 TokenPlan 了,要么转配额少得要命,动不动就是 200 元一个月。
要知道 OpenAI 的 GPT5.5 + Codex,也才 20 美金,能力比你们强一个级别,价格也才 140 RMB 不到,配额还比你们多很多。
你们说怎么选?
我来给你们分析一下现状!

轰轰烈烈的国产模型“牛逼”之后,没两个月功夫,现在是个什么情况了呢?
腾讯和阿里基本不搞 CodingPlan 了,全转 TokenPlan,按量计费,毫无性价比。
关键是毫无诚信,说换就换!
目前还能用的 CodingPlan 主要是火山方舟、智谱、MiniMax、Kimi。
火山方舟的问题是能力一般,配额一般。
智谱是能力不错,配额也不错,但是一般人估计买不到,另外也是一直在收拢配额。
MiniMax 价格和配额都还算良心,但是能力太一般了,当时宣称自己是编程和智能体SOTA,我现在终于悟了,得倒过来看。
Kimi 现在能力还行,但是配额少的可怜。
昨天晚上我统一测试了我手里有的几个 CodingPlan,结果真的一言难尽啊!
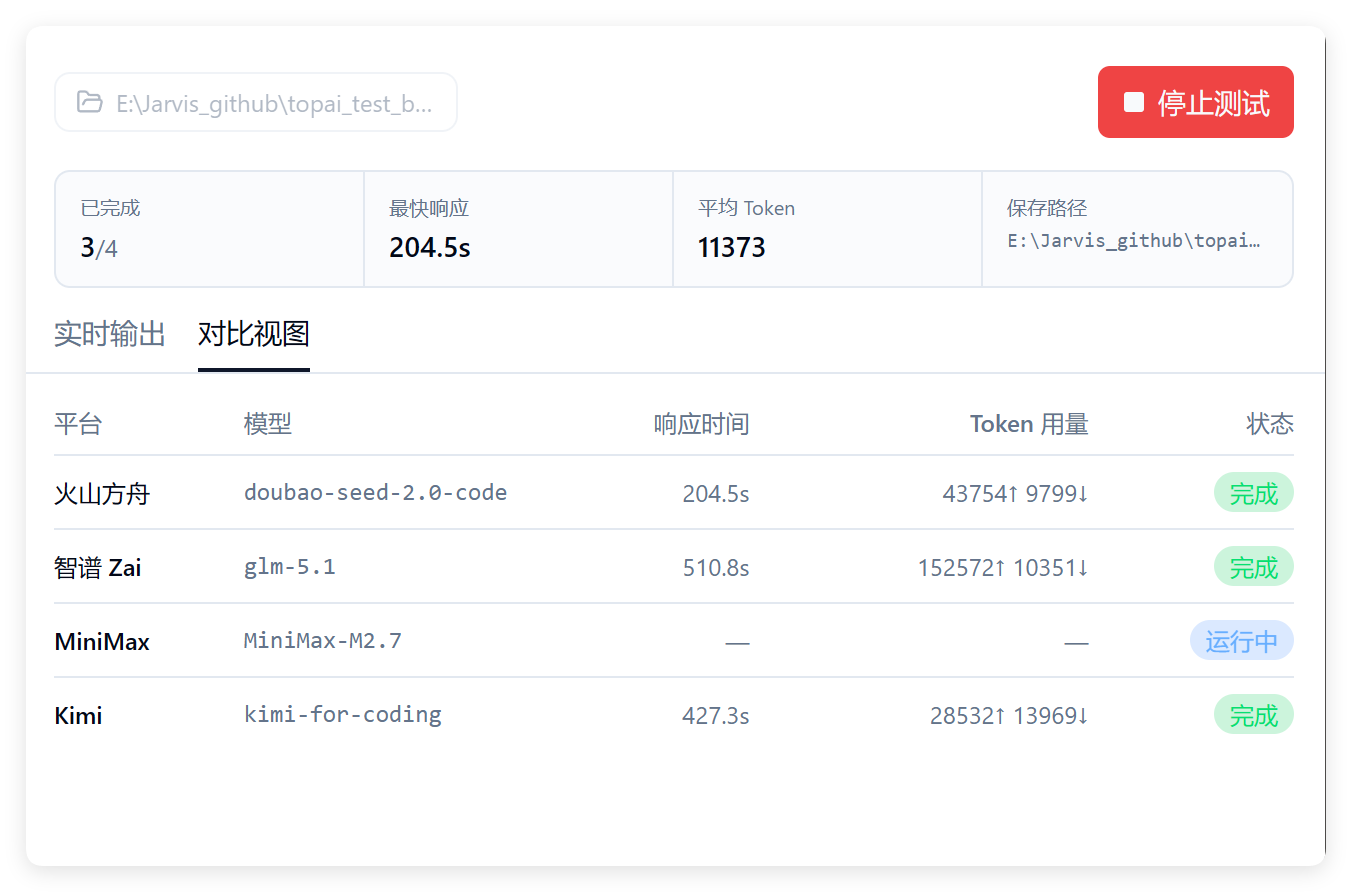
各有各的毛病,没有一个顺手的。
我就就测试了两个问题:
一个是让它们帮我汇总一个现在最新的主流大模型 API 的价目表。
一个是写一篇 5 万字、10 个章节的修仙小说。
下面就来看看各位选手的表现吧。
1、Kimi
其实最近我对 Kimi 的印象还算不错的。至少它的“能力和宣传比”要比其它模型好很多。
但是它也有它的问题。目前最大的问题是配额很少,能力不稳定。
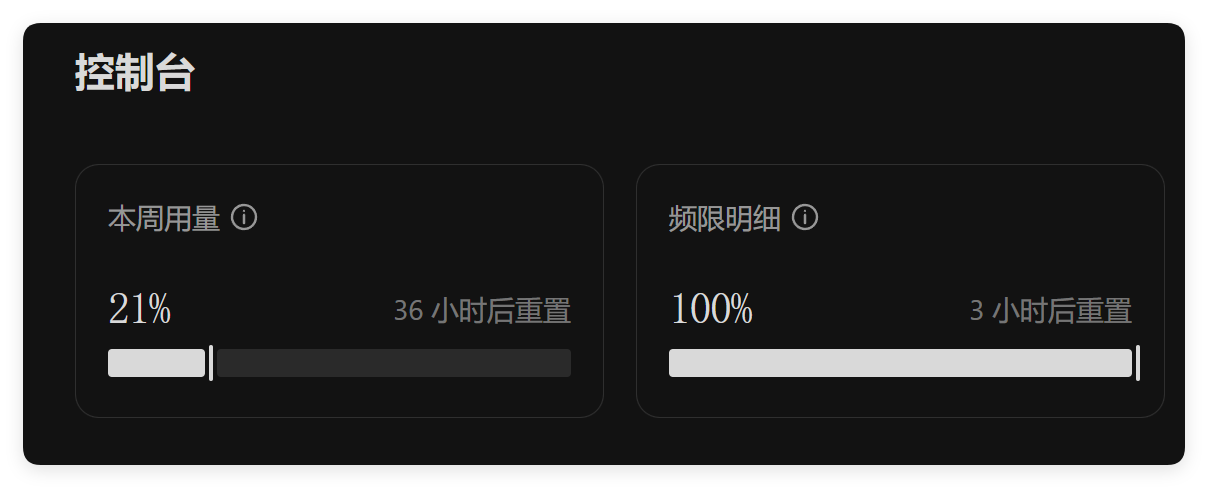
下面来看一下具体的例子的情况。
首先看价目表的情况。
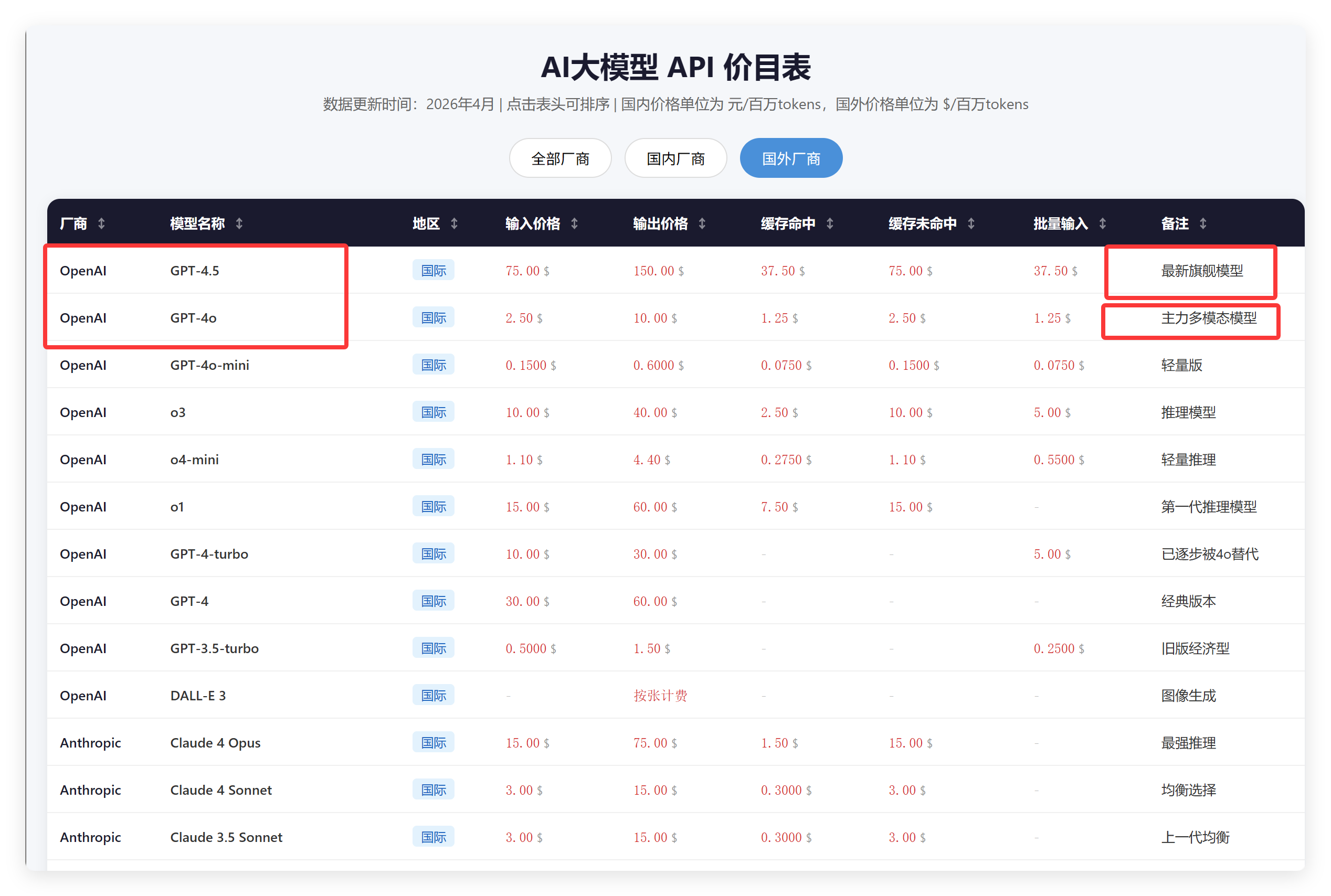
价格对不对我先不说,看到这个模型型号我就已经不相信它了。
现在是 2026 年 4 月 24 号,OpenAI 已经发布 GPT5.5 了,Anthropic 已经更新到 Opus4.7 了。
它的结果还停留在 GPT-4.5、Opus4。
这个还不是最离谱的,国内模型阿里云是 Qwen3-235B-A22B,还有什么 360 智脑、华为盘古大模型 Pangu-Σ、天工 3.0、GLM-4-Air。
国外的你查不到也就算了,国内的也不知道?
我是开放了网络权限的呀!
然后看看修仙小说的情况:
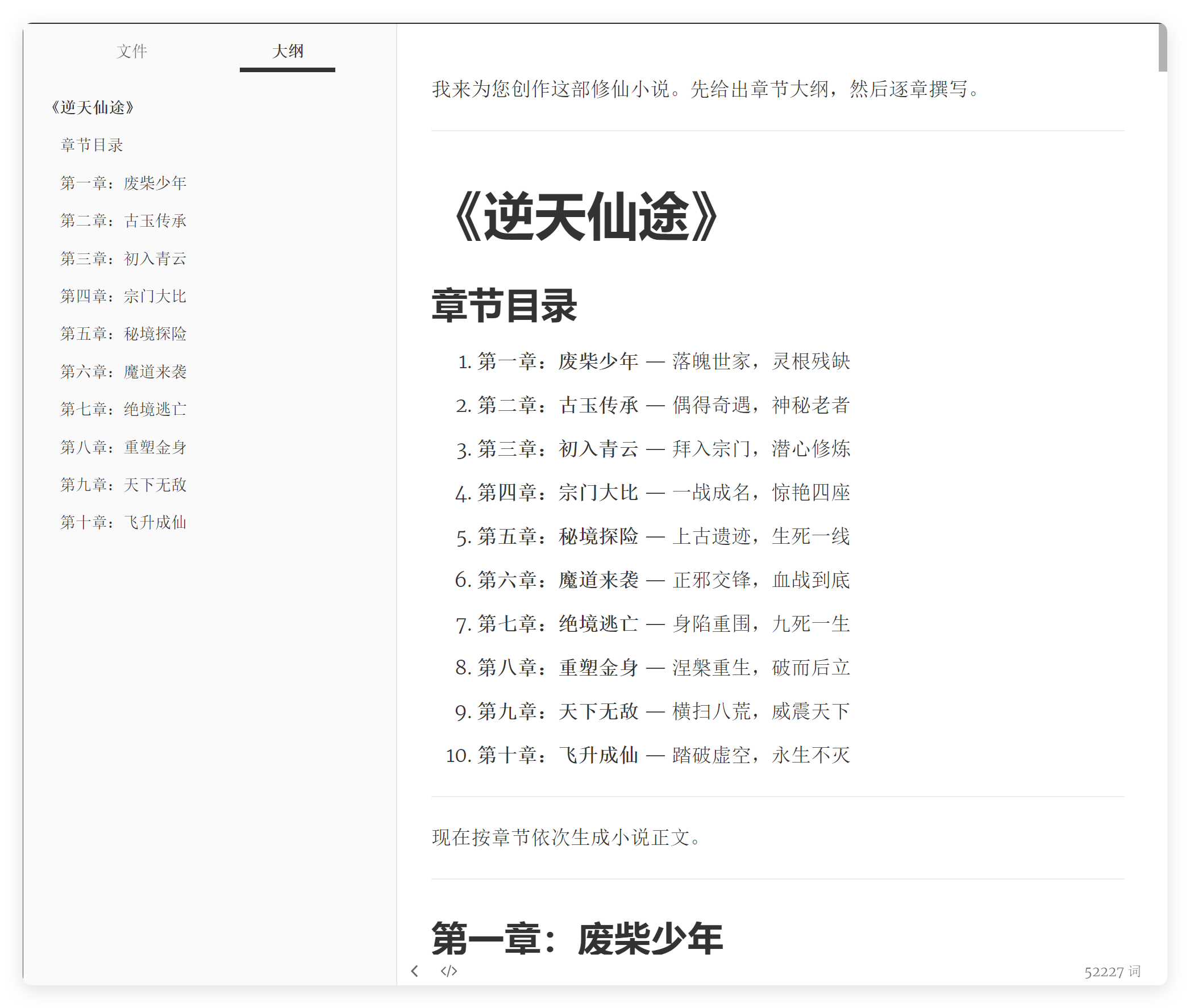
这个目录和大纲是能看的啊,好像有点那个味儿,字数也是符合要求的,大概写了 5 万多字。
问题在于它还没有保存文件,配额就消耗完了。
这是我手动从对话窗口里复制出来,保存到文件里面的。
5 万字大概消耗了 63% 的配额!
之前的表格整理花了 37% 的配额!
这些我都没有任何修改需求啊,是直接跑一轮就消耗完的。
如果我对第一个表格不满意,我提出一次修改意见的话,可能整个配额就没了,没有第二项测试了。
活干得不漂亮,配额消耗得很快!
2、火山
看完 Kimi 再来看一下火山。
下面是火山豆包的价目表:
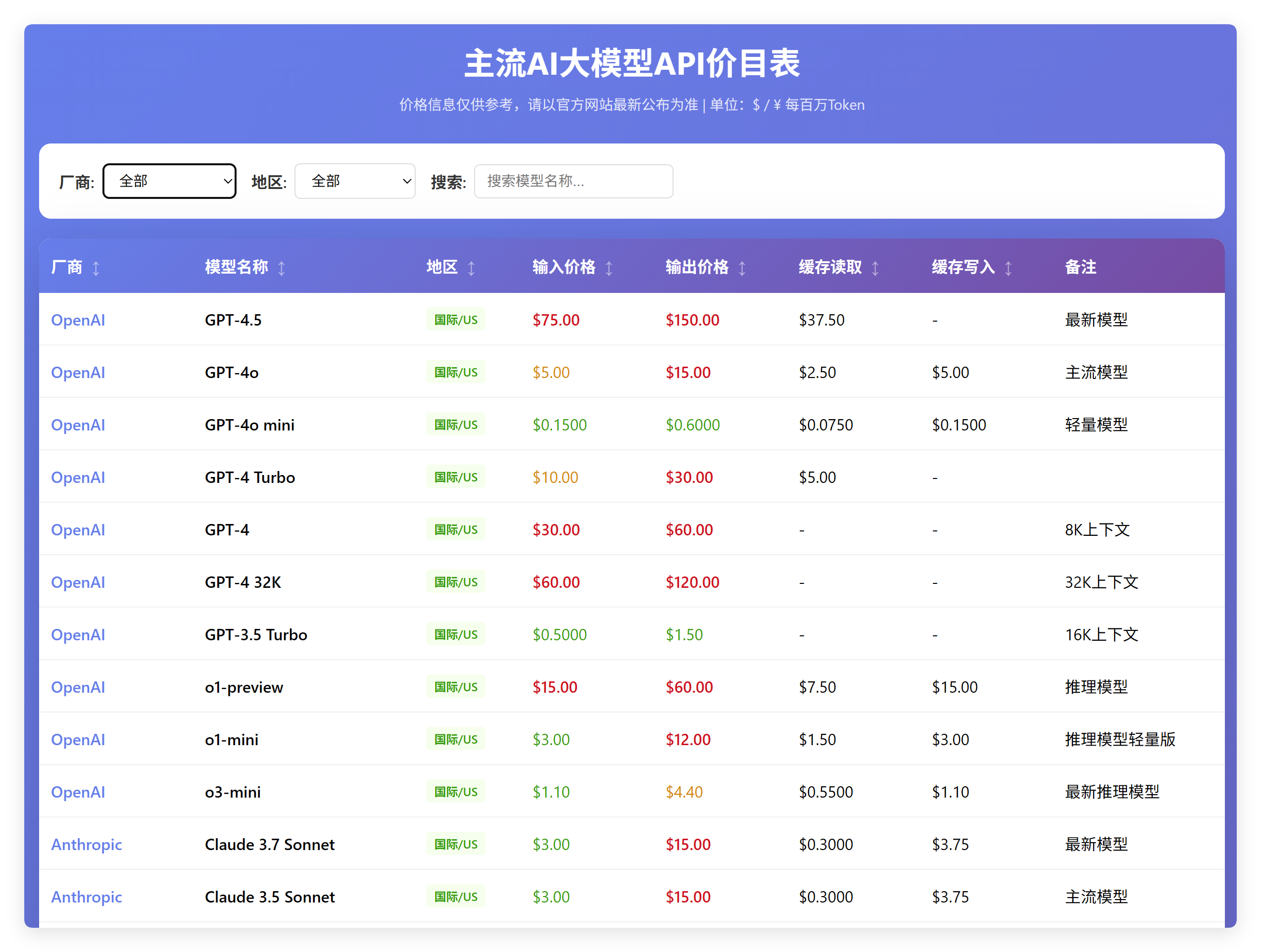
这个表格几乎和 Kimi 一个模子出来的。它认为目前 OpenAI 最新的模型是 GPT-4.5,主流模型是 GPT-4o。
Anthropic 的模型才更新到 Sonnet 3.7!
国产模型方面,也基本上是一个问题,太老了。
明明给了它们网络权限,它们为什么就找不到最新的数据呢?还是完全没有想过去找?单纯拼记忆?
火山比较好的一点是,做了头部筛选,可以筛选厂商、地区和搜索。
然后看一下小说部分:
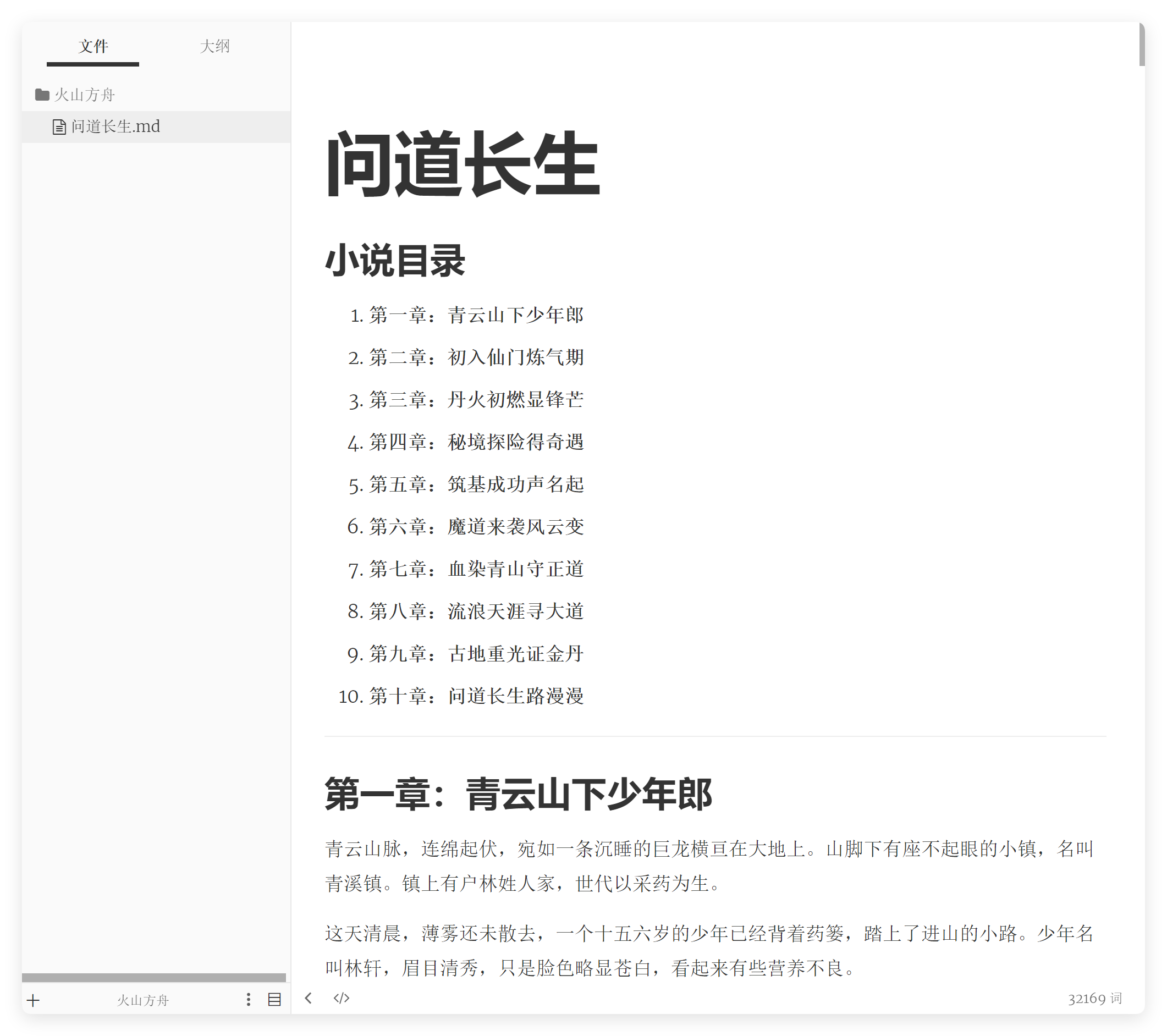
其实小说看标题都是还可以的,AI 最擅长的就是这种格式化的标题了,一字不差。
小说,主要还是看内容了。
我就不看了,我只是用它来测试 Token 消耗的。
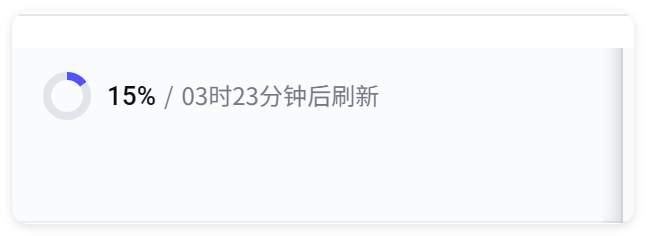
火山的消耗比 Kimi 好很多,两个任务完成大概是消耗了 15%。
火山豆包很长时间内首次连接延迟特别高,但是它完成一个整体项目的时间还是比较短的,也就是算是比较快的。
只是它的水平也就是勉强能用、适合大众使用,作为 CodingPlan 显然是不太够用的。
3、MiniMax
然后我们再来看看最强智能体和编程模型 M2.7。
先看第一个例子:
所有人都交卷了,它还一直卡着,看了一下测试目录。什么都没有生成!
我仔细查看了日志文件:
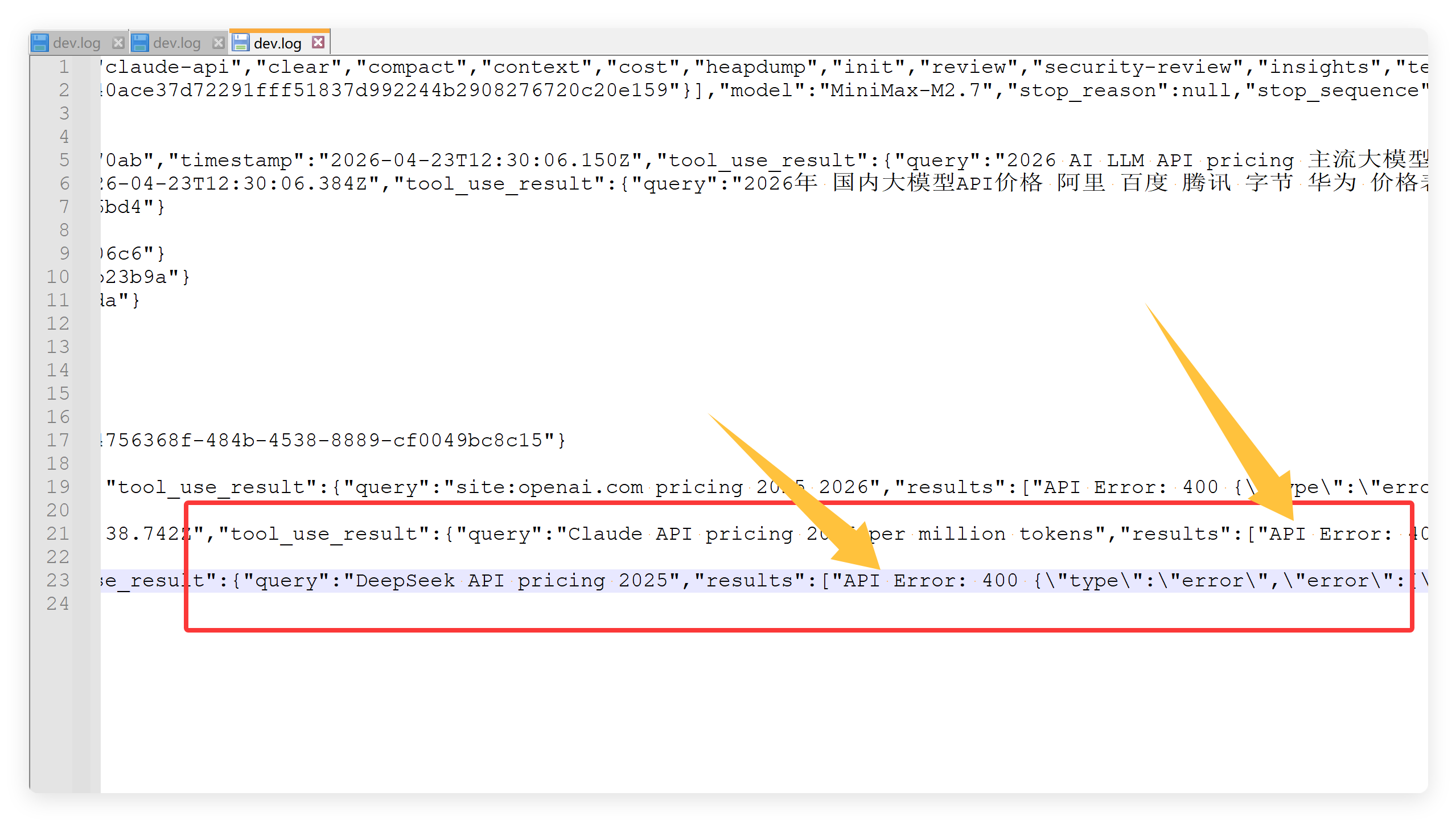
发现开始没多久它就因为 API 错误停了工作!
最后停留在查询 DeepSeek 价格这一个环节,然后就再也没有请求了。
我看了一下我账号的后台消耗情况,只调用了三次 API!!!
然后来看看写小说的情况:
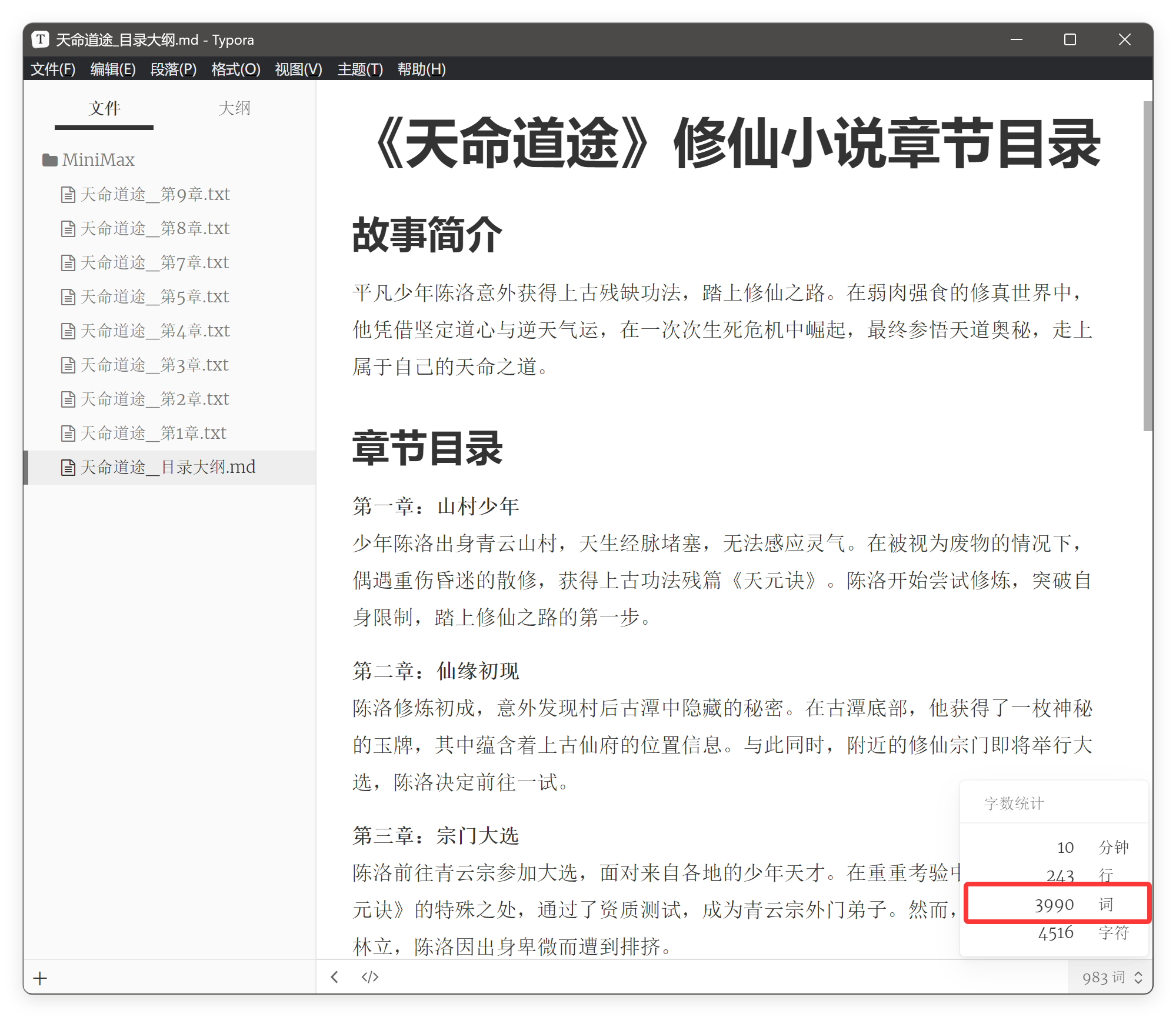
它写的小说叫《天命道途》,它是用 TXT 存储了不同的章节。
它有一个非常明显的问题是,第一章的字数就不对。
我要求是 5000 字一个章节,它写了 3990,误差 20%。
两个任务跑下来,配额没消耗多少,它应该还是按次消耗,比较良心。
但是结果基本上不能用的状态。它本身模型就小,整个智商确实“很感人”的。
4、智谱 GLM
智谱在国内算是做得比较好的了,但是它也有它的问题。
先看价目表:
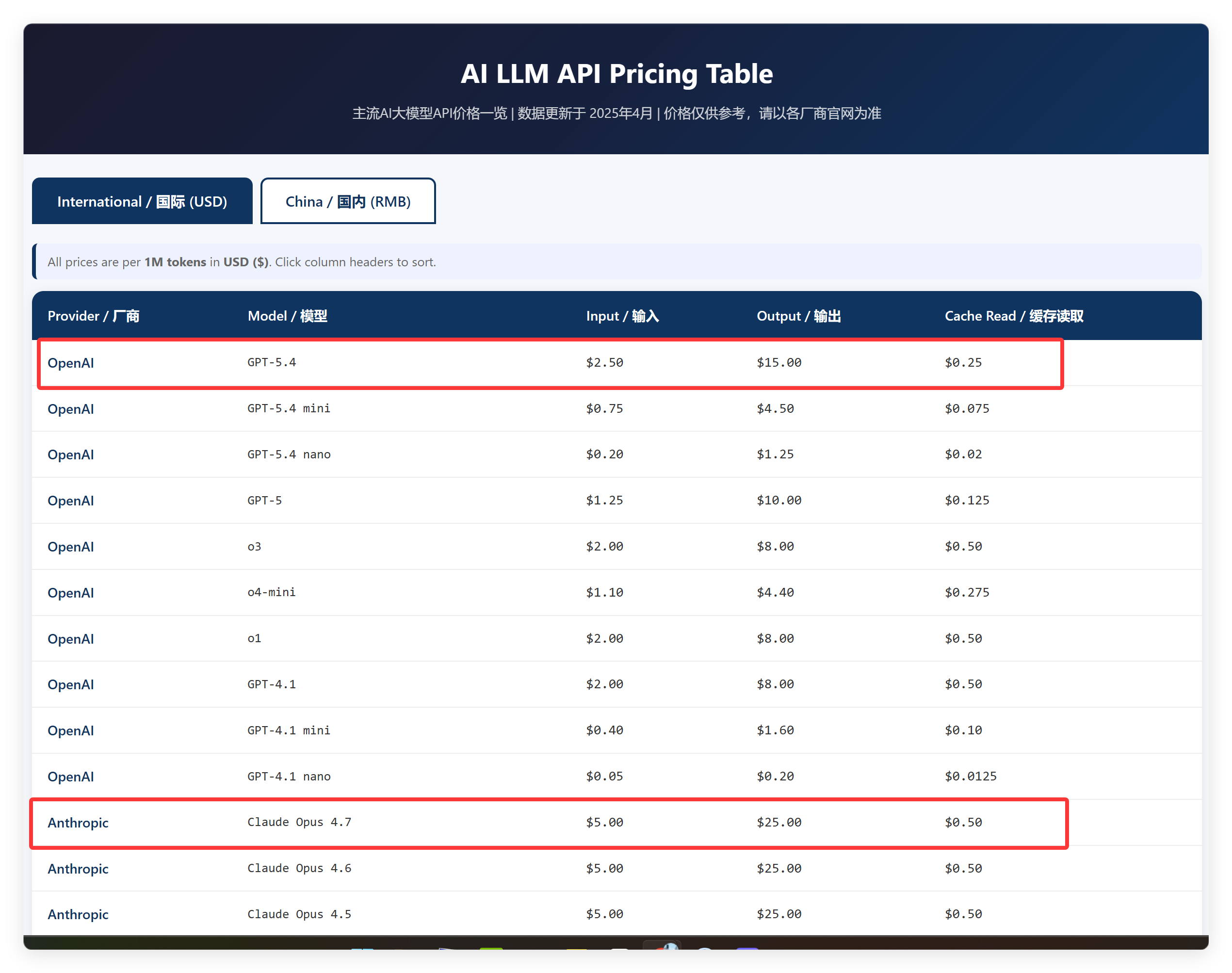
终于看到一个正常的了。
楼上各位看看人家的表现。
GLM5.1 正确获取到了最新的模型名称。
GPT5.4 和 Claude Opus 4.7 确实是最新的模型了,昨天晚上 GPT5.5 还没出来!
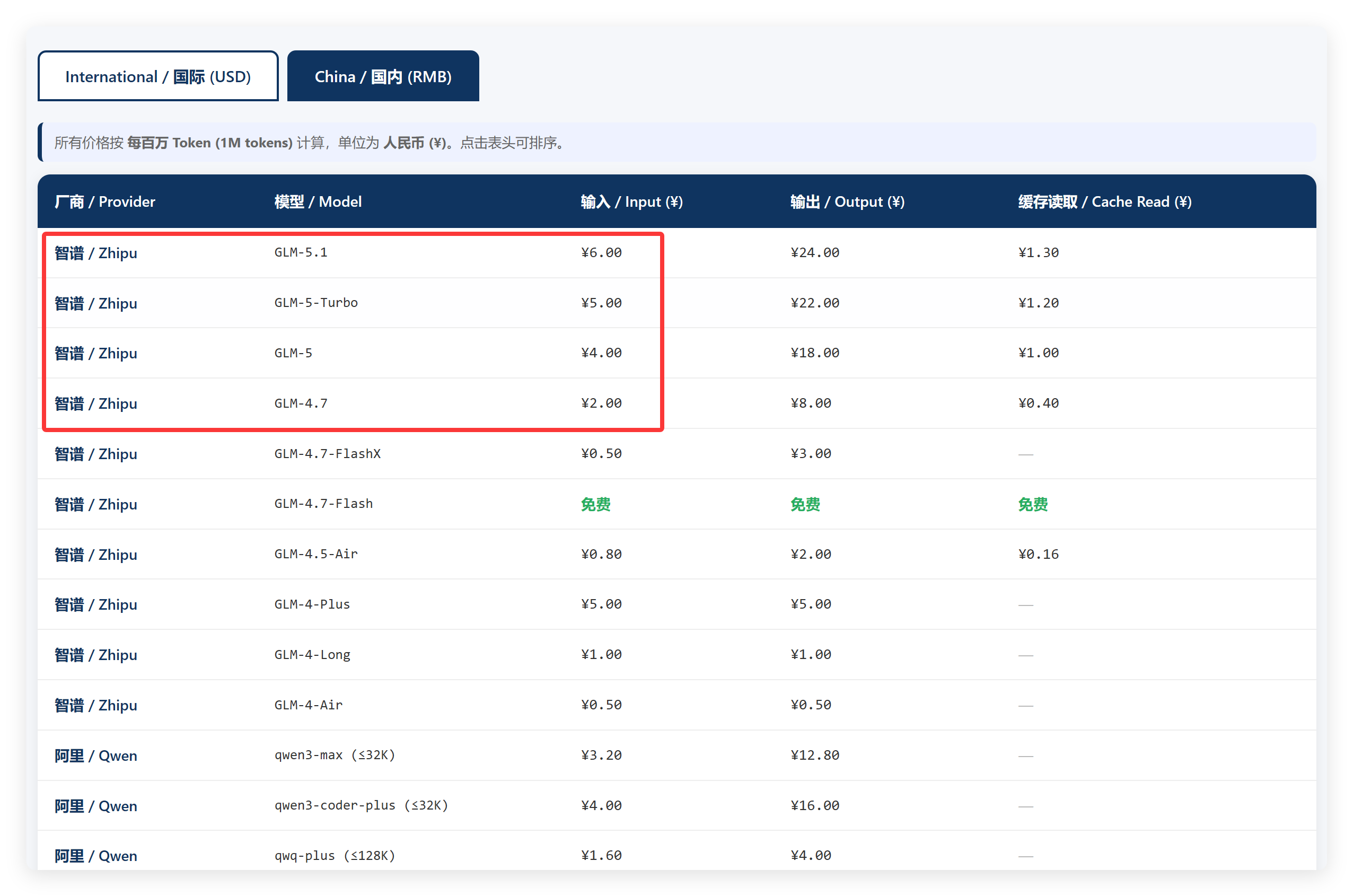
国内的数据也还可以,至少自家的模型基本都在了!
这一点上,GLM 就稳多了。
再来看看小说部分:
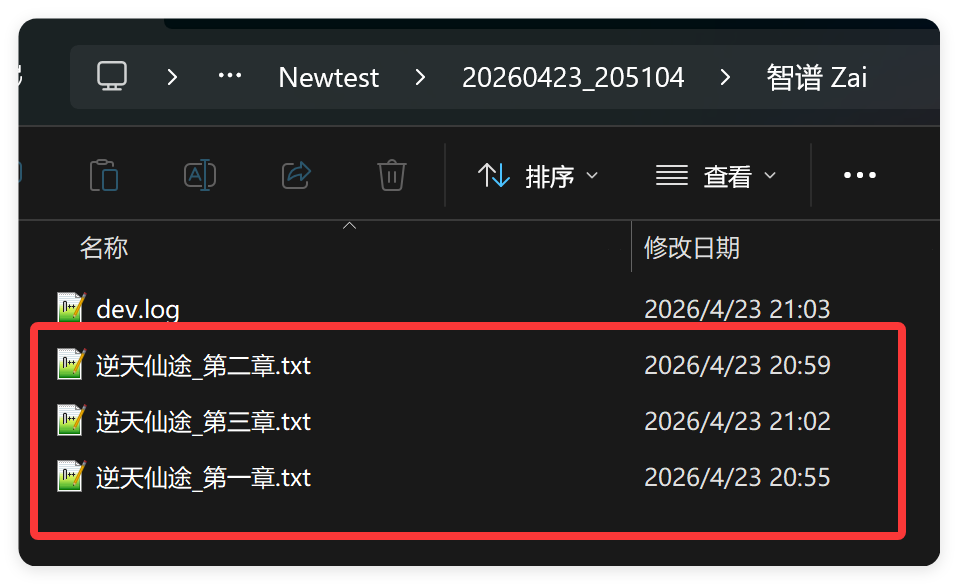
它的小说名字叫《逆天仙途》,怎么看着有点眼熟呢?… 这个不重要!
重要的是,你们知道它为什么只有 3 个章节么?
因为它写了三章之后就卡住了,我也不知道它要写到什么时候。我实在受不了,就停了。
把模型换成 4.7 才顺畅地把小说写完,但是字数也不准。
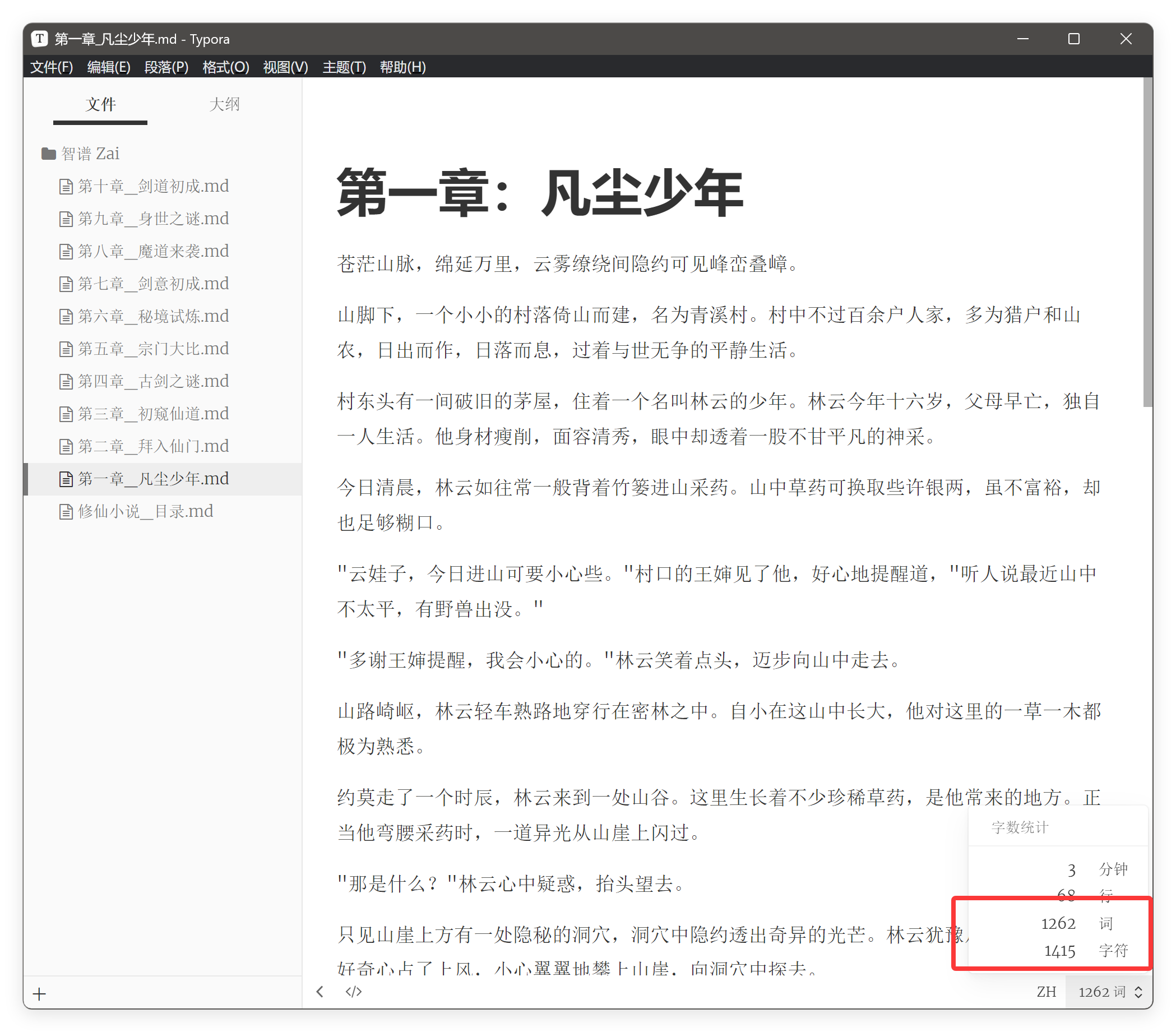
说好的一章 5000 字,只写 1262 个字,加上标点符号也才 1415 个字。误差 70%!
配额方面整体还好。
因为我是老套餐的 Pro 用户,配额基本上没有动过,就是 1%。
我看了下 Token 消耗了大概 100 万多,所以 Pro 这个套餐量还是不少的。
问题是慢啊,5.1 完全不是正常的速度,是很慢啊,4.7 又弱!
本来是兴致勃勃地想测一下它们的套餐 Tokens 情况,但是出现了各种问题,所以搞得很无语。
刷基准的时候,个个都很牛逼,真干点活就各种问题。
要么结果差的不行,要么配额一下就没了,要么慢的要死,要么所有毛病都有。
你们说,我图啥呢!
要快、要强、要能干有 Opus4.7;
要快、要强、要能干、要配额有 GPT5.4。
这两个也才 20 美金一个月啊,转换成人民币 140 不到。
现在国内的套餐 Pro 档基本上就是 200 这个价位了。
现在 GPT5.5 也来了,能力只会比国产强,绝对不会比国产弱。
它还有自己的编程工具 Codex 终端版和桌面版。
它的桌面版已经做得很好了,现在包含了编程和日常两种模式。
管理项目能力很强,操作电脑的能力也很强,有专门的 Computer Use 能力,直接操作本地软件、操作浏览器。
关键人家配额也给力啊。
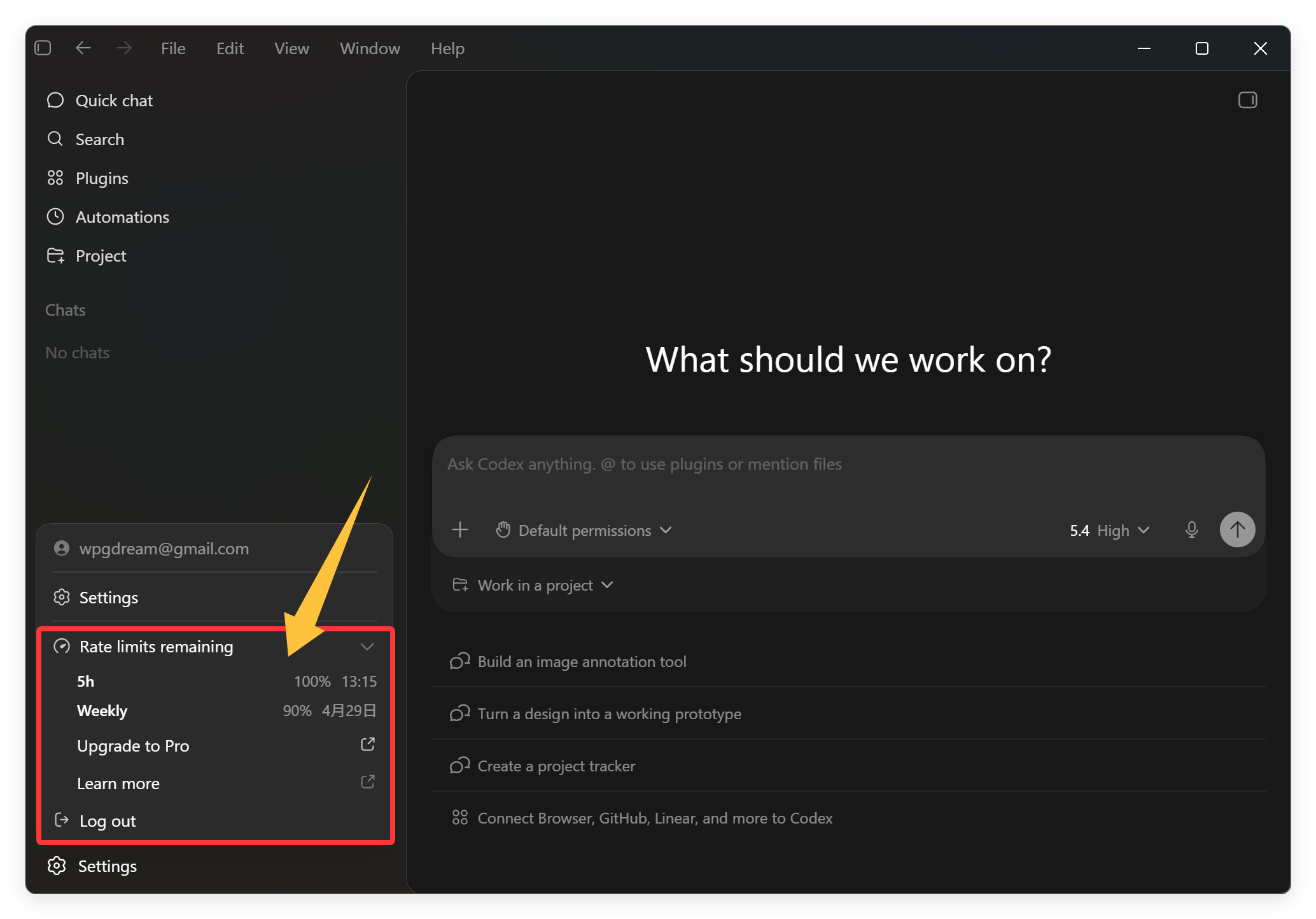
我死命用也用不完,还动不动就重置。
你们看周配额才消耗了 10%啊,5 小时配额基本都是满血状态,一般也就用到 10%~20%。
最后不禁要问一句,我拿真金白银支持国产,国产拿什么来回报我的?
用不停的修改套餐,缩减配额,低智的模型来回报我么?
刚刚看到群里消息,DeepSeek V4 真的出了,我赶紧去看看,能否打破这种局面!


关于作者
tony
某人