GLM-5V 视觉模型又来“吊打” Opus4.6了!
不好意思,吊打只是我的口头禅,并不是我的结论!
今天主要来看一下新模型 GLM-5V-Turbo(视觉模型)的卖家秀!
看起来还不错。
我根据官方推特的信息,来给大家详细介绍一下主要卖点!
基准测试
首先我们来看一张“吊打” Opus 的基准图(Benchmark):
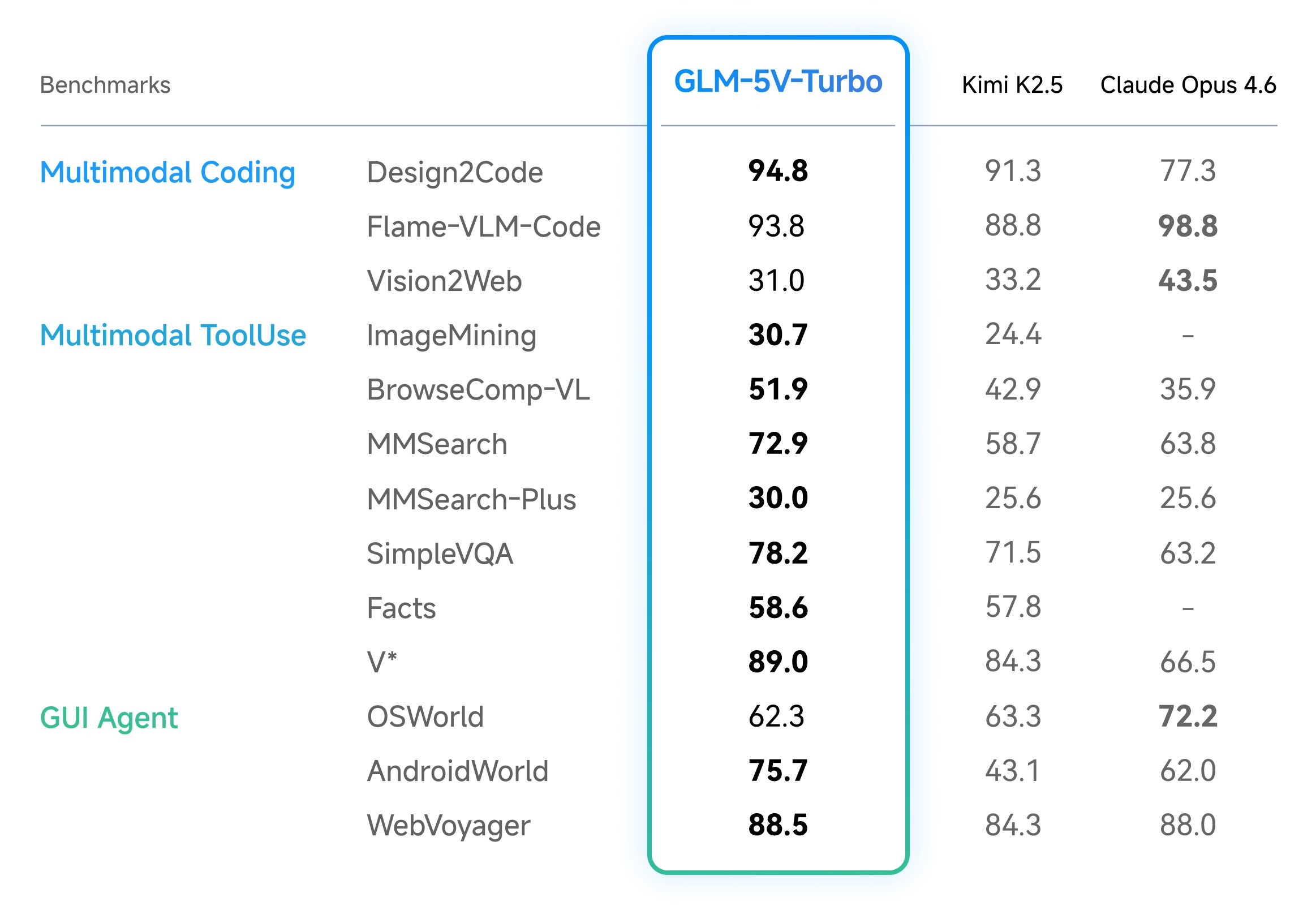
官方结论是:
在设计稿还原、视觉代码生成、多模态检索问答、视觉探索等评测上领先;
在真实 GUI 环境控制能力(AndroidWorld 和 WebVoyager)上表现突出。
单看这张图,领先的指标确实很多。
尤其是 Design2Code 以 94.8 小胜 Kimi2.5 的 91.3,吊打 Claude Opus 4.6 的 77.3。
我对这些基准不是很熟,所以我专门查了一下。
我主要是想知道:这些基准是野鸡标准,还是真的公认的权威基准。
权威和知名度汇总:
| 类别 | 基准 |
|---|---|
| 公认权威 | OSWorld、AndroidWorld、WebVoyager、Design2Code |
| 中等知名 | Vision2Web、MMSearch/MMSearch-Plus、BrowseComp-VL |
| 小众/存疑 | Flame-VLM-Code、ImageMining、SimpleVQA、Facts、V* |
因为我还没测试,所以我先不做评论,我只是提供一些参考数据。
我的经验是:基准是开卷考,拼的是节操,只能作为参考。
三大核心特点
看完基准,看一下首推的三大特点。
原生多模态编程:
原生理解图像、视频、设计稿、文档布局等多模态输入,能”看屏幕写代码”——理解设计稿、截图、网页界面后直接生成完整可运行代码。
视觉与编程能力均衡:
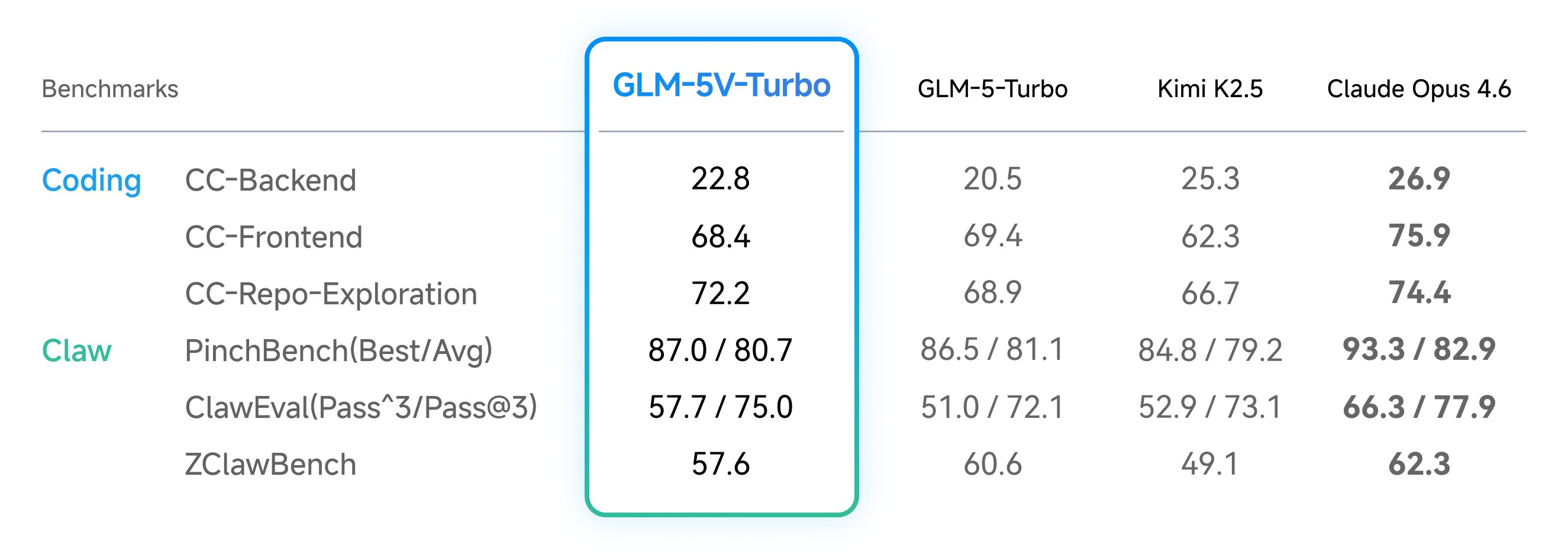
在多模态编程、工具调用、GUI Agent 等核心基准上取得领先成绩;
同时在 CC-Bench-V2 的三个纯文本编程评测(后端、前端、仓库探索)上保持稳定,证明引入视觉能力不会损害文本推理。
深度适配 Claude Code 和 Claw 场景:
与 Claude Code、OpenClaw 深度协同,支持完整任务闭环执行。
这都是很好的方向,如果真的有进步,将使 GLM 系列模型的实用性大大增强。
从第二张图来看,GLM5V,就完全被Claude Opus4.6压一头了。
毕竟它家的CC本身就是基准测试的Harness
四层系统升级
这一部分,可能看不太懂,但是懂得自然都懂,我觉得我还是要列一下。
原生多模态融合:
预训练阶段即做文本视觉深度融合,后训练阶段协同优化;
自研新一代 CogViT 视觉编码器,在通用目标识别、细粒度理解、几何空间感知上达到 SOTA;
设计推理友好的 MTP 结构保证效率。
30+ 任务协同 RL:
RL 阶段同时优化 30+ 类任务,覆盖 STEM、Grounding、视频、GUI Agent,提升感知推理能力,同时缓解单领域训练的不稳定性。
Agentic 数据与任务构建:
针对 Agent 数据稀缺问题,构建从元素感知到序列级动作预测的多层数据体系;
用合成环境生成可验证训练数据;
预训练阶段注入”Agentic 元能力”(如加入 GUI Agent PRM 数据以减少幻觉)。
多模态工具链扩展:
除文本工具外,支持多模态搜索、绘图、网页阅读,将感知-动作循环延伸至视觉交互;
强化与 Claude Code 和 OpenClaw 的协同。
视频演示
枯燥的文字部分终于看完了,我们来看看视频部分。
看看是否 make sense?
【视频】
视频的第一幕叫:See It Code It

我翻译一下:Like It , Copy It。
这是一个大家都不好意思说,但是很想要的功能。
天下文章一大抄,代码也是如此,重点是能不能快速出活。
我们一般叫“调用”和“复现”,程序员怎么可以说抄袭。
我还是挺喜欢这个黑白配色,网格,和字体的,决定拿它做封面了。
草图转代码
视频中的第一个例子是 Sketch = Code,翻译一下就是草图转代码。
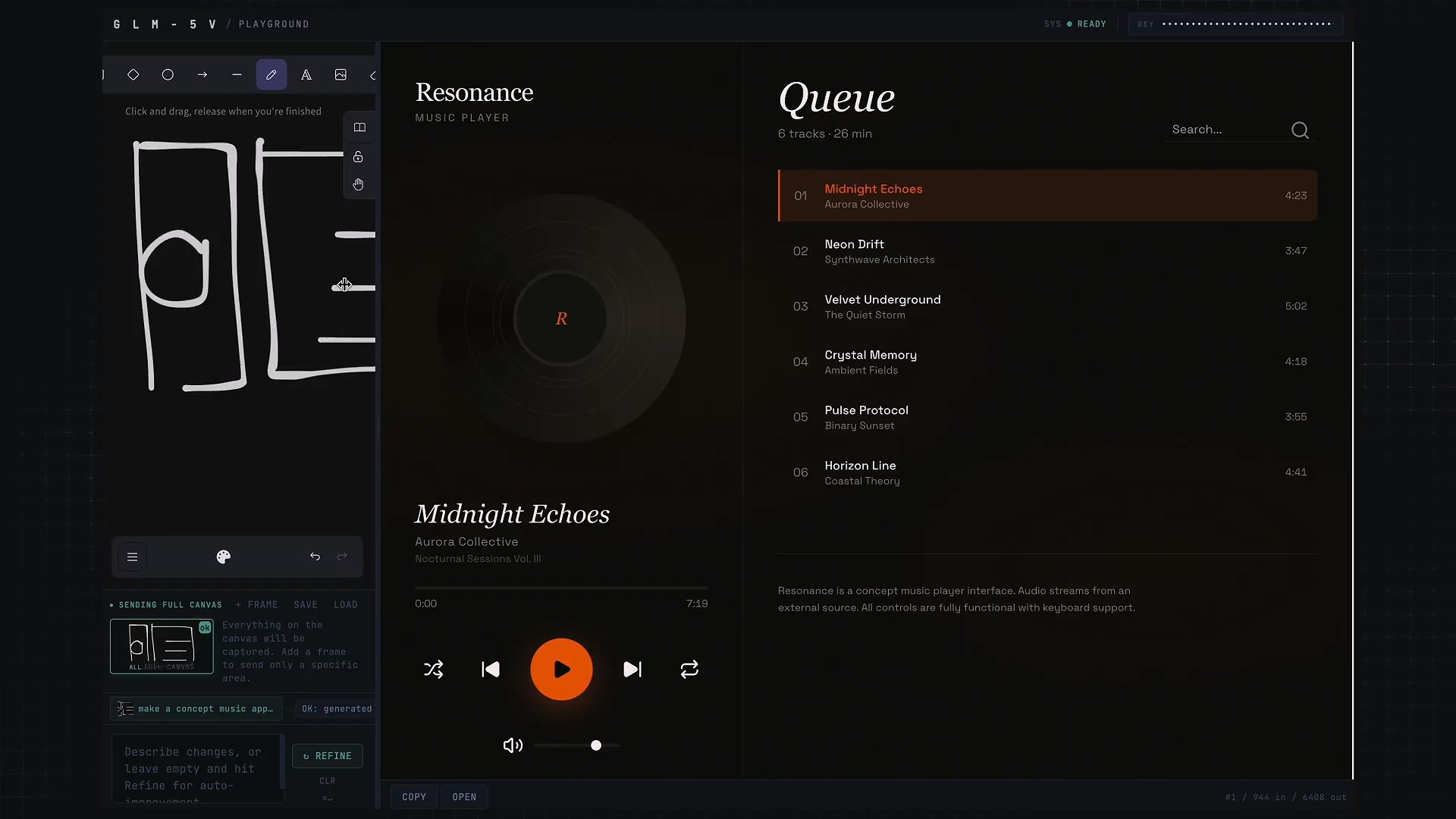
直接在左边画一个草图,然后底下写一句:
make a concept music app that plays https://lab.design/music.mp3 by default.
制作一款播放概念音乐的应用程序
参考转代码
第二个例子叫 Reference = Code。
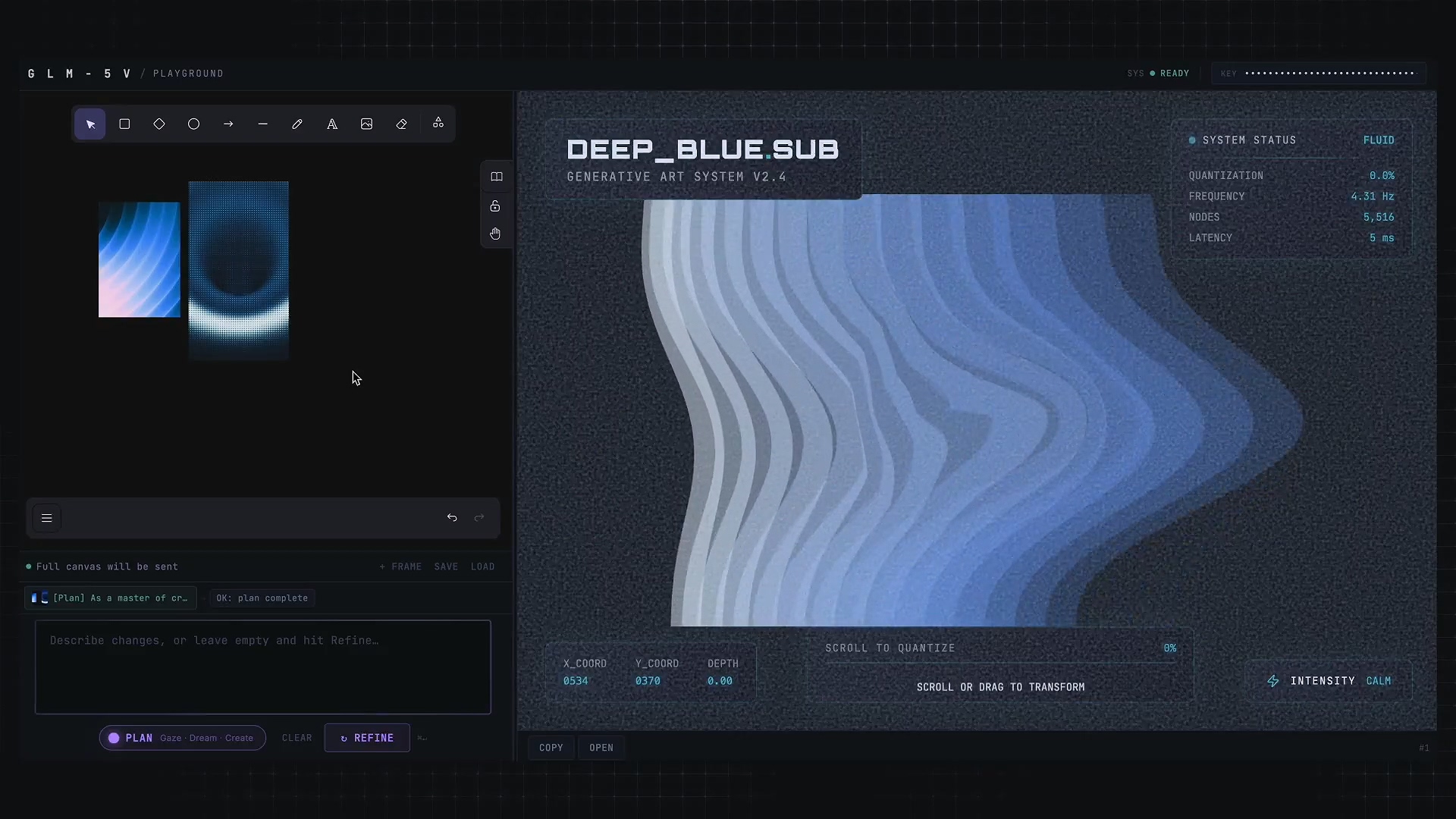
给定两张参考图,然后编写以下提示词:
As a master of creative programming, create an interactive generative art piece with given reference image as direction/inspiration. You may use canvas2d, shader, p5.js or similar. 作为创意编程大师,以给定的参考图像为方向/灵感,创作一件交互式生成艺术作品。你可以使用 canvas2d、着色器、p5.js 或类似工具。
一个衍生例子:
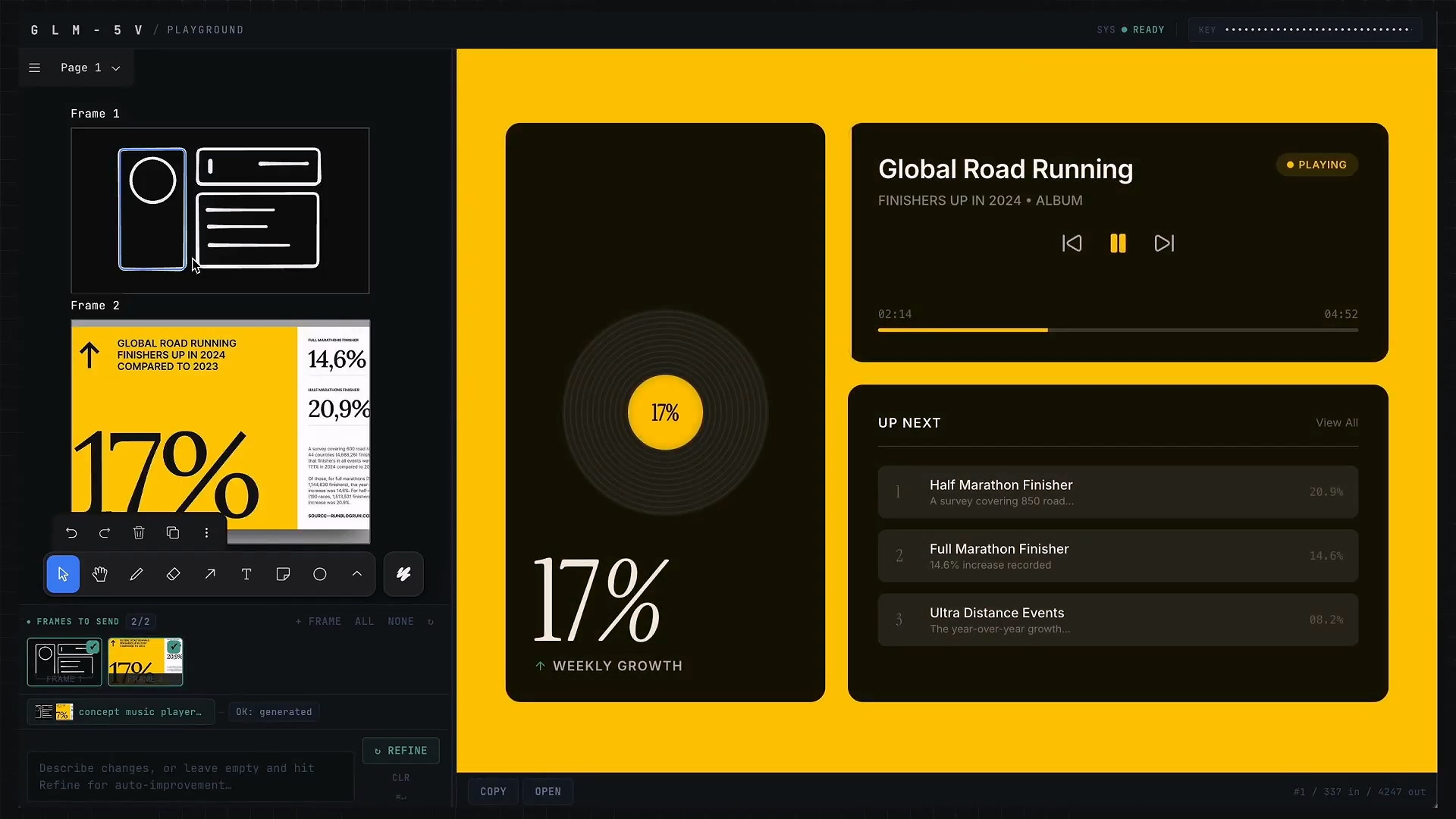
通过草图和参考图,以及提示词生成一个指定风格的音乐播放器。
截图转代码
第三个例子叫 Screenshot = Code。
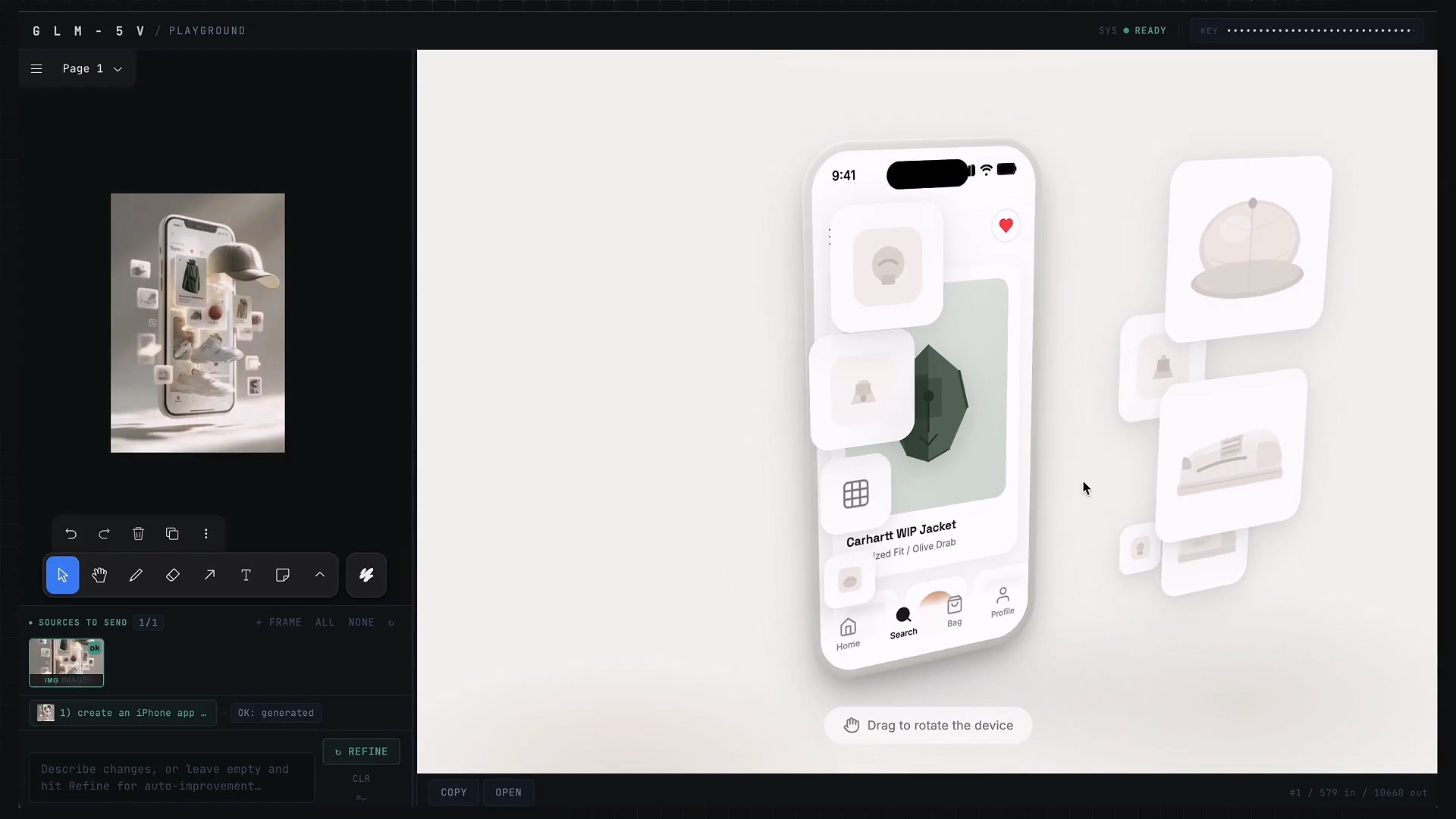
这个例子是根据一张极具 3D 感的图片,生成一个可以拖动的 3D 版网页。
录屏转代码
第四个例子是 Screencast = Code,相比截屏又提升了一个难度。
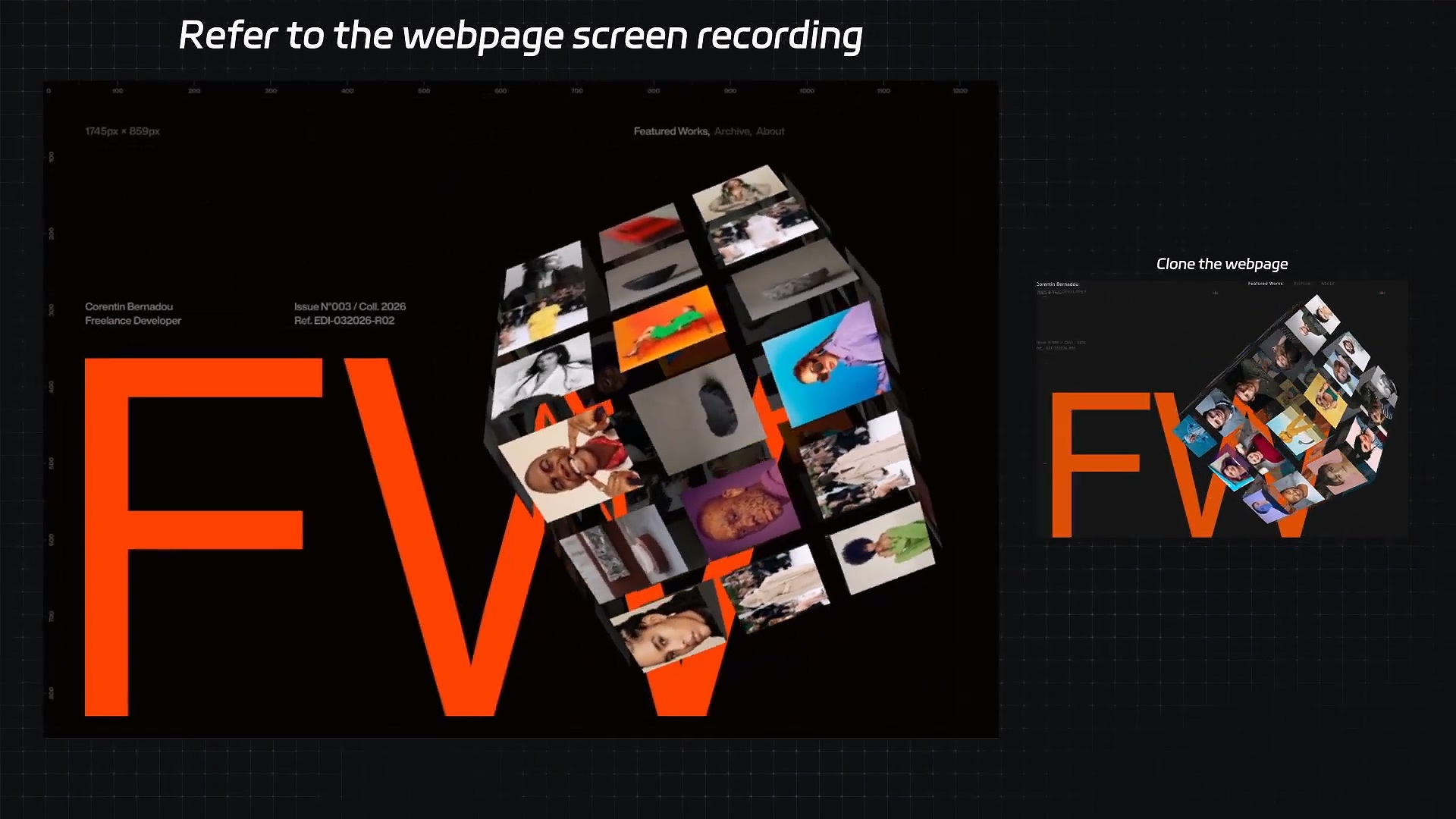
就是直接给它一个动态视频(可以想象成抄袭一个动态网页),然后它直接把这个动态视频转换成动态的网页代码。
最后还展示了 Image -> Code -> Music 例子。这个有点抽象,有点创意,我就不讲了。
这个视频还是做的挺好的。
一句话,你给我什么我就立马帮你复现。想着是不是无比美好。
但是,我们也要认识到“卖家秀”永远都是卖家秀。哪次模型发布,都是炫得不行,一上手又是另外一种感觉了。
所以,我们还是得实测一下才知道。
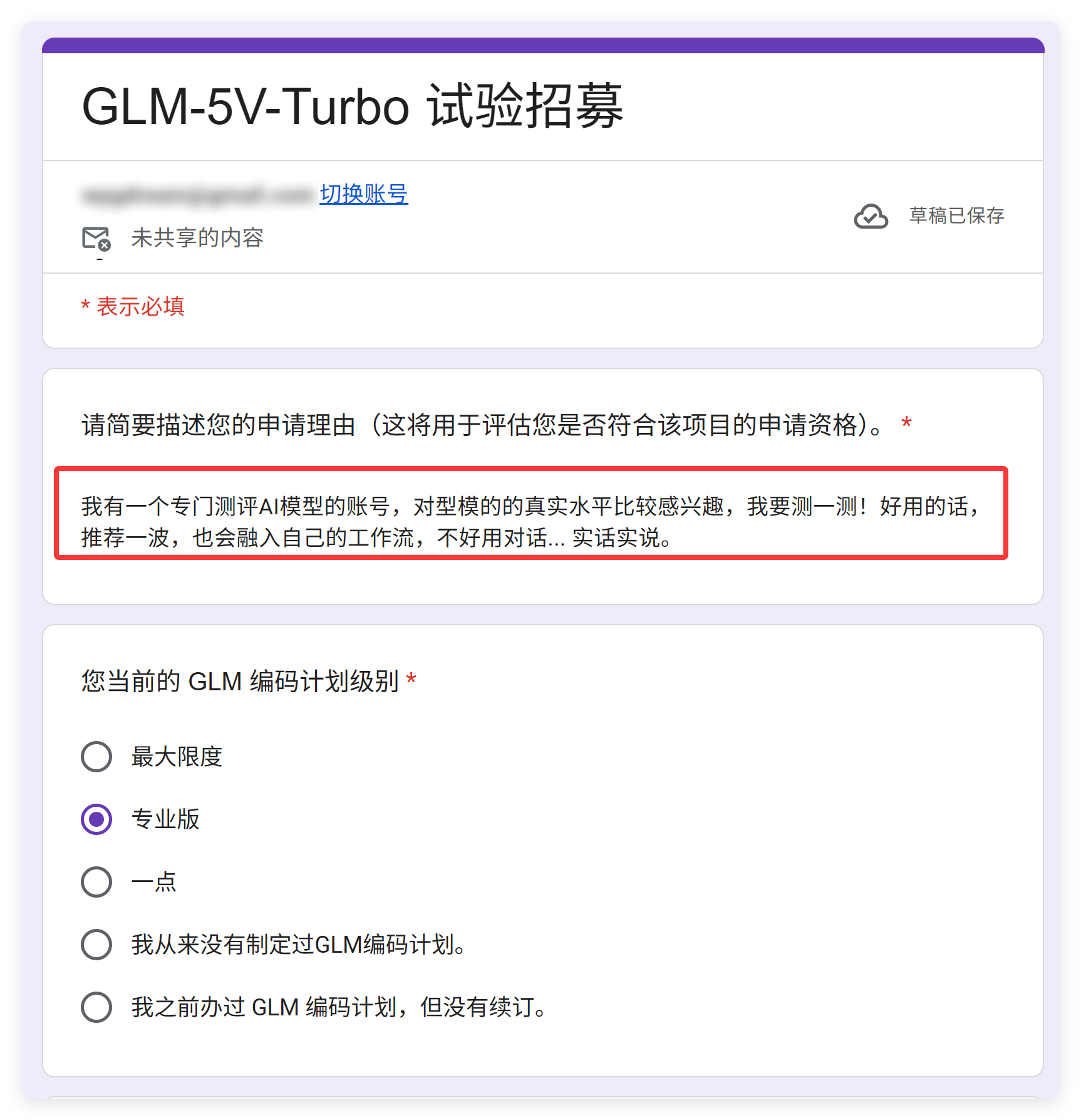
CodingPlan的内测申请我已经提交了,给不给我用,就看智谱了。
目前看起来还是很不错的,发力点都是对的,原生多模态是必经之路。
这个方向,国外的模型已经玩了很久了。
我记得 2024 年 5 月 GPT-4o 的时候开始作为宣传重点了,Gemini 也是强得很,Claude 不算很强,但是也早就默默支持了。
而之前的国产编程模型基本上还是在卷文字部分,很少有原生多模态模型。
大部分编程模型无法直接理解图片,有些是直接调用第三方服务来做图片识别。
比如 DeepSeek 就完全不理解图片,GLM5 就是靠调用 MCP 来识别的。只有 Doubao 比较早地引入了多模态。
我曾经做个一个基准数据采集、分析、汇总、制作网页的例子,就需要结合多模态来做图片识别,当时一堆国产大模型全躺了。
现在 GLM 也往这个方向发力了,好事情!
最后一句:事情肯定是个好事情,就看做得怎么样了!
参考链接
免费在线尝试:
接口文档:
CodingPlan申请入口:

关于作者
tony
某人