去年初 DeepSeek 风光无限,把英伟达股价都干崩了,大有国产模型碾压一切的趋势!

一年多后 DeepSeek 却几乎销声匿迹了,苦等的 V4 也没来。
别人都是一路狂奔,一个月都能更新一个版本,它倒好,玩起了岁月静好。
最近用一个编程实例把国内外各种模型都测了个遍:
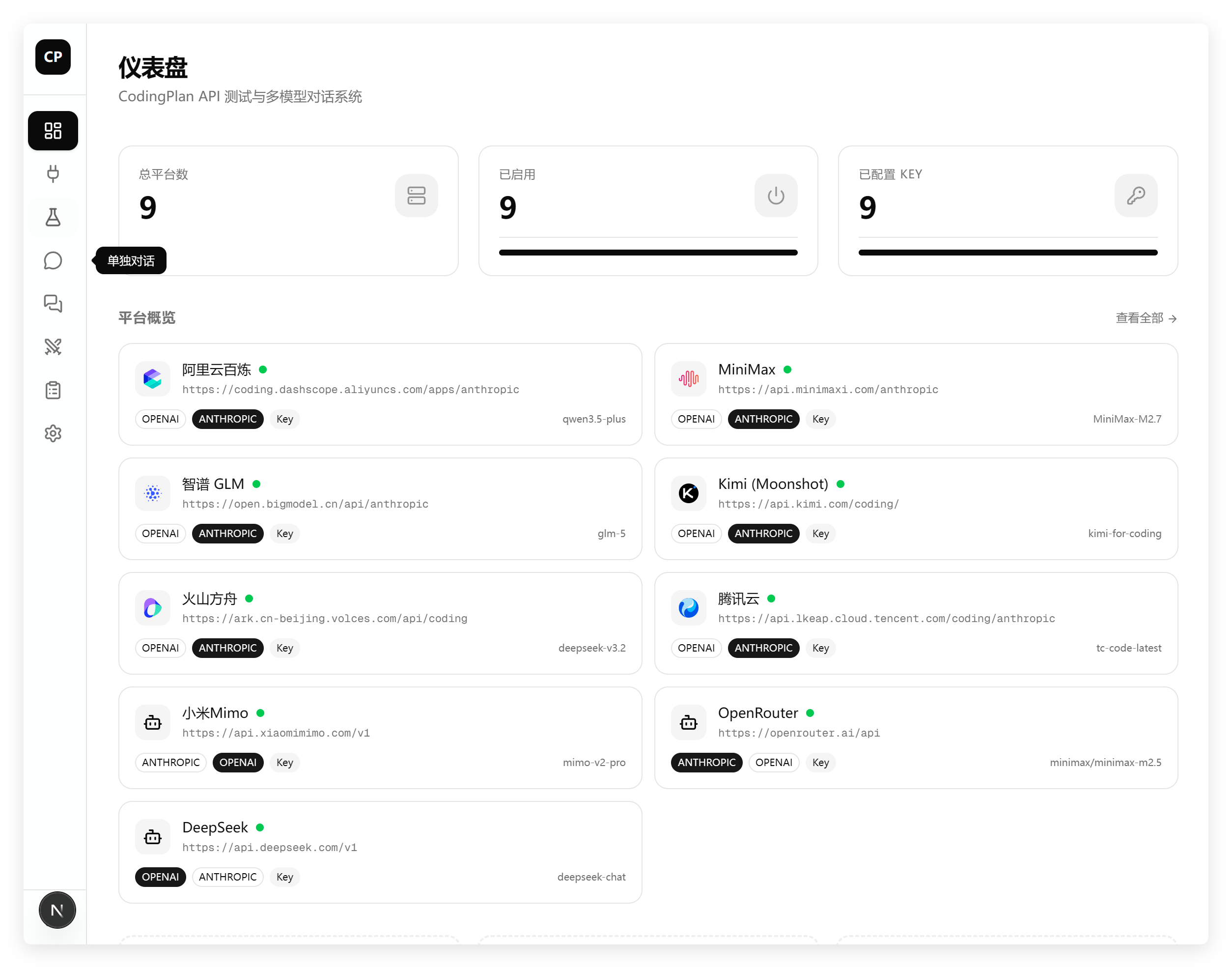
只有 DeepSeek V3.2 没测了。
我一直没有测试,我其实不太想测,因为我大致有数。
但是有朋友强烈要求测一下,好像很多人的心中 DeepSeek 还是世界最强的存在!
好吧,那就测一下,专门去官网充值了 API,然后配置到 Claude Code 中测试。

然后,试试就逝世了:
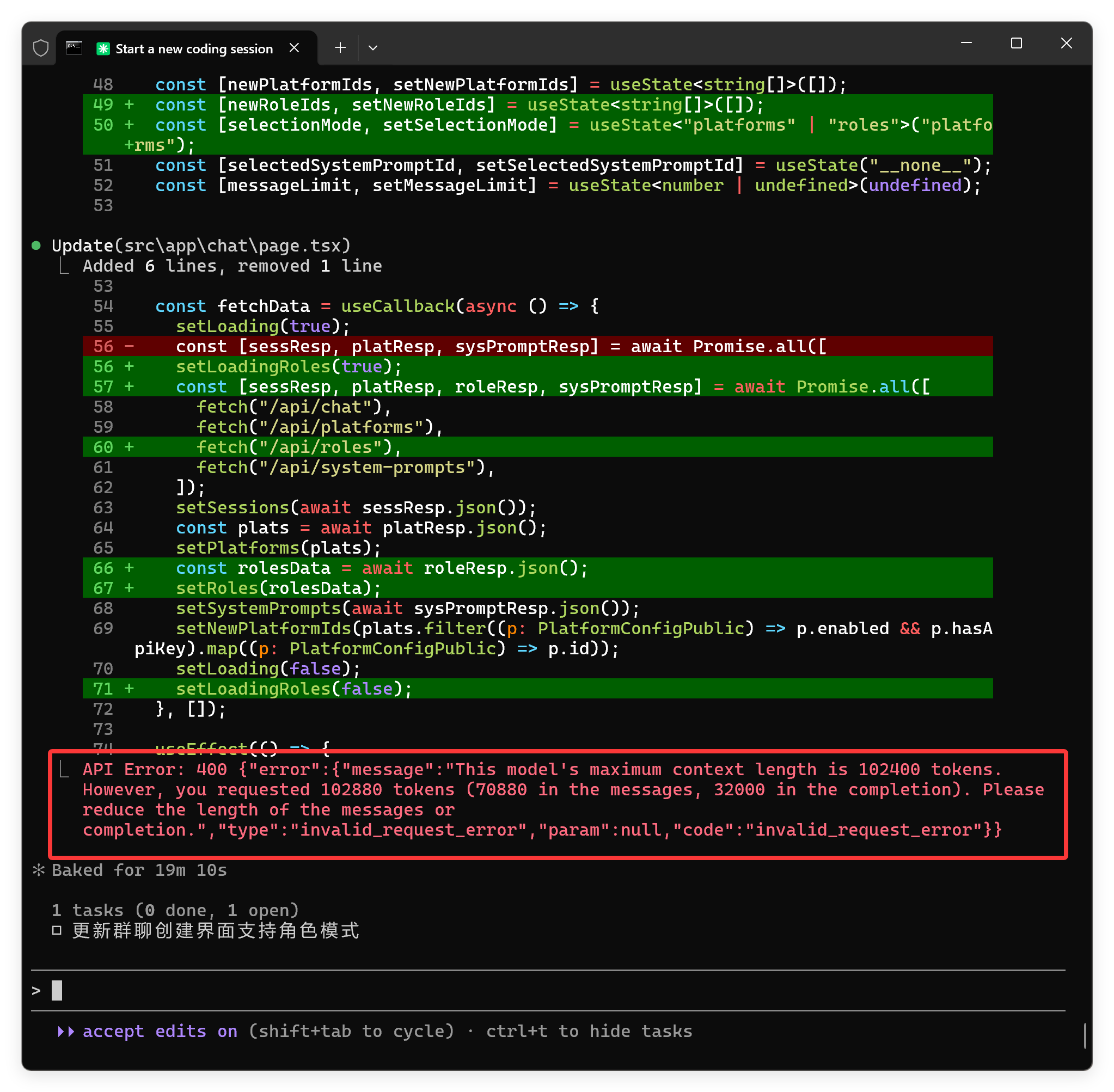
项目写到一半直接蹦了!
继续了几次都不行,就卡在这里了!
我上面说了,我这是官方正版 API,特地充值的,而且采用了它家最强的推理模型!
国内的主流模型我都试了,没有一个中途撂挑子的。即便是 MiniMax 也不会卡在这个环节。
仔细看了一下错误提示大概是上下文超了。
最大上下文 102400?这是什么鬼!
查了一下资料大概是这么说的:
deepseek-chat(非思考模式,基于 DeepSeek-V3.2) 上下文长度:128K tokens(131,072 tokens)
deepseek-reasoner(思考模式 / 推理模型,基于 DeepSeek-V3.2) 上下文长度:128K tokens(131,072 tokens)
首先,128K 不是也还没到啊。
其次,都 2026 年了还有旗舰模型上下文是 128K?
这么小的上下文够干什么?
GLM5、Kimi、MiniMax 都 200K+ 了。
Opus 和 Sonnet 都 1M(1024K)上下文了。
便宜是真的便宜,但是这东西根本没法用啊!!!
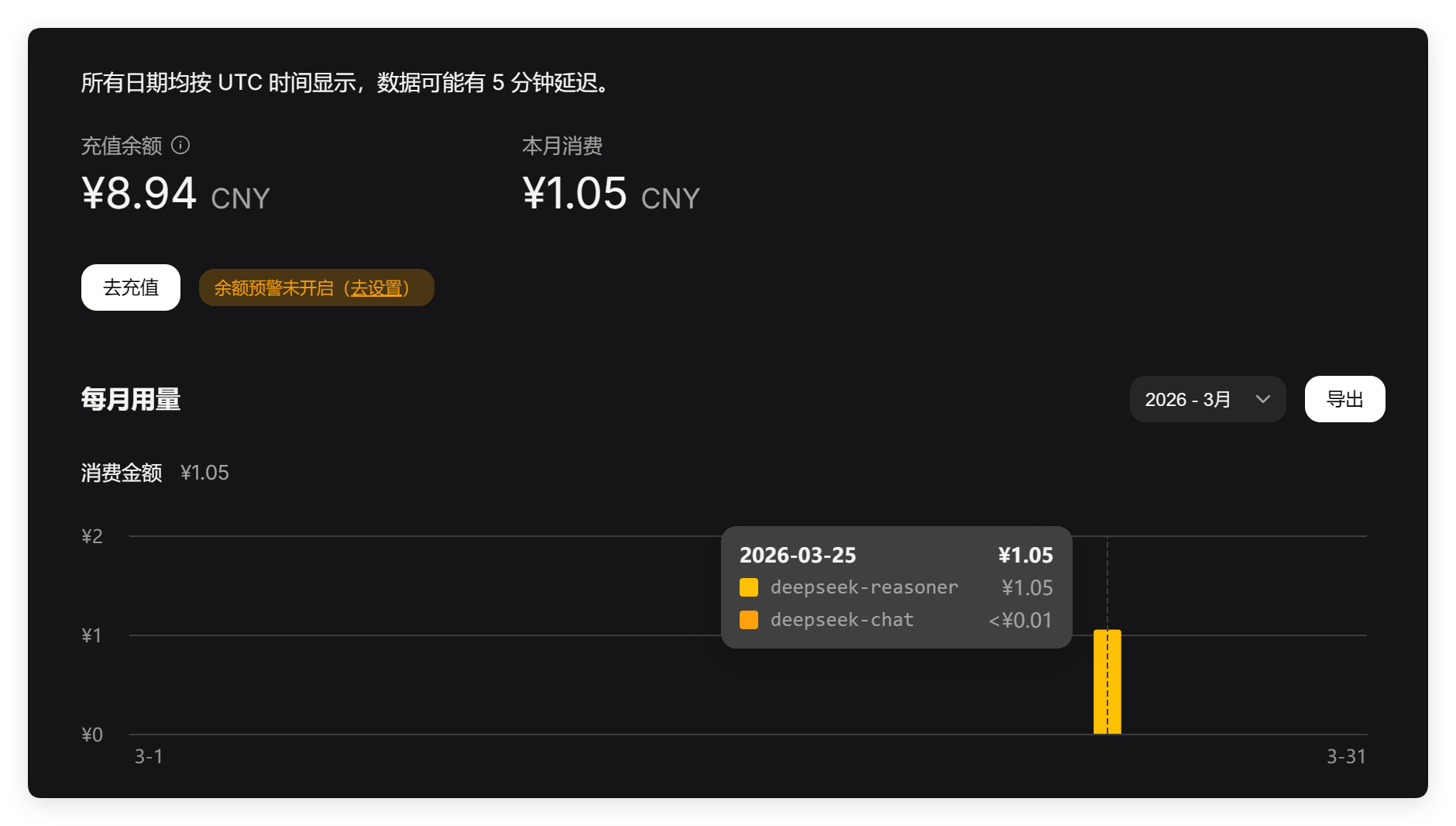
基于真实项目的编程题太难?那么来个简单的智力测试题:
有 5 个人排成一排,每人帽子颜色为红或蓝。他们可以看到前面的人的帽子,但看不到自己的。主持人宣布:“至少有一顶红帽子。”从最后一人开始,每人依次说“是”或“否”(表示是否知道自己帽子的颜色)。如果第 5 人说“否”,第 4 人说“是”,求所有可能的帽子颜色分布。
结果如下:
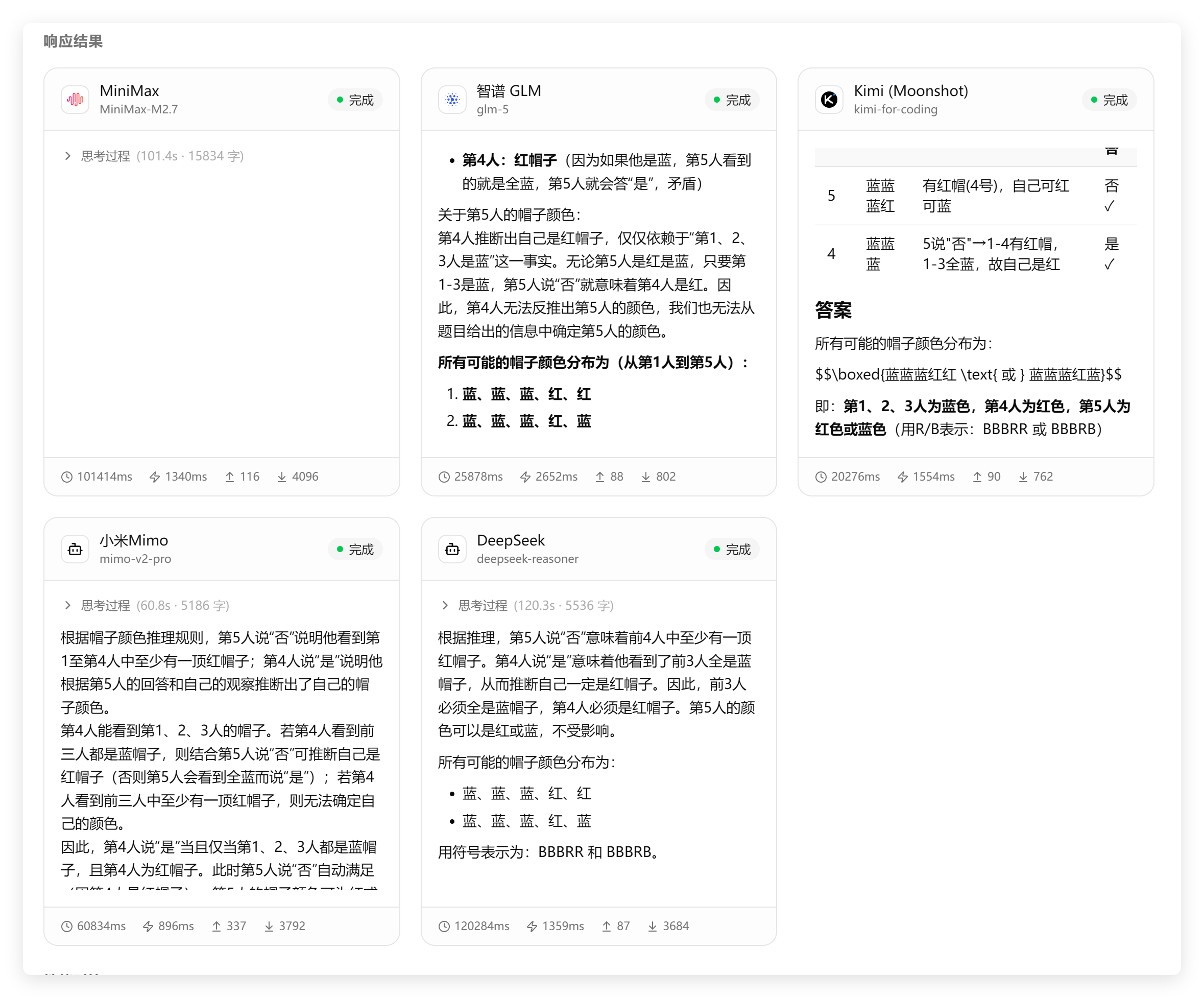
消耗时间如下:
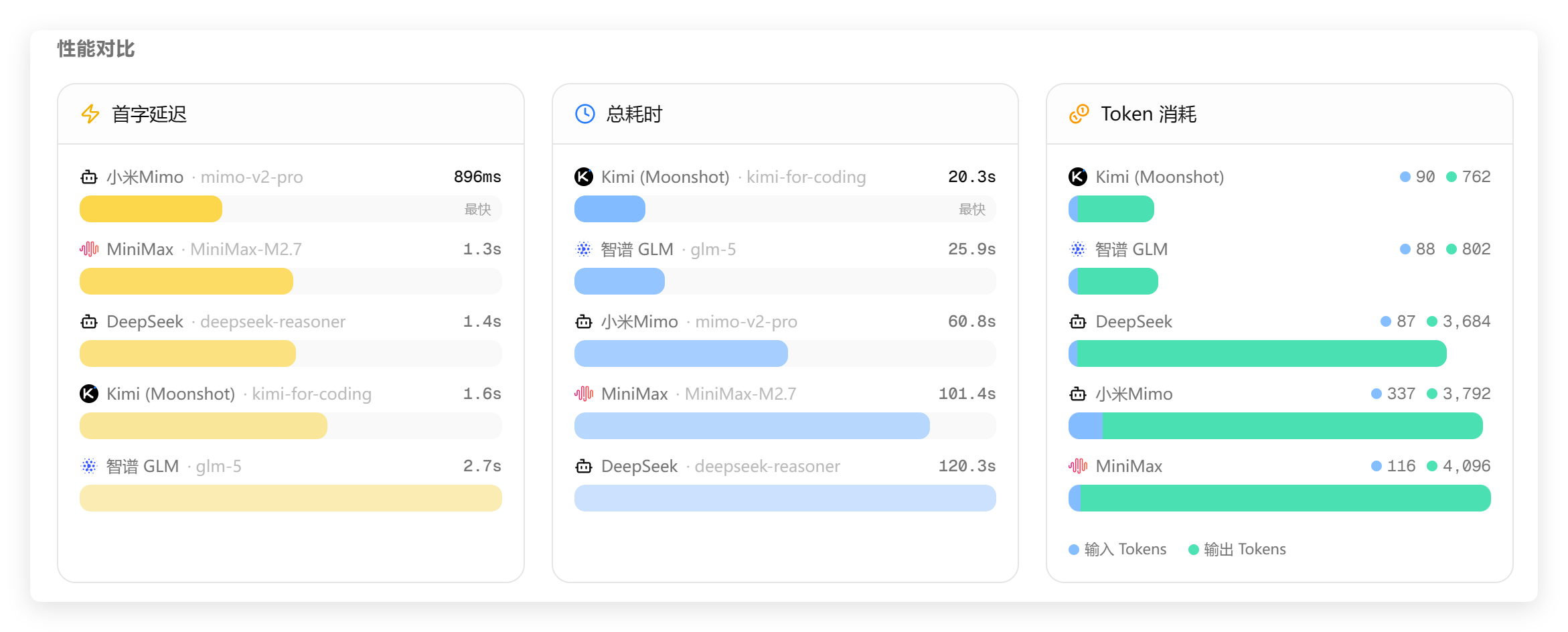
题目是回答出来了,但是耗时 120 秒,太久了。Kimi 只花了 20 秒,GLM 只花了 25 秒。
目前在时间和消耗方面,Kimi 和 GLM 确实都不错,基本上每次测试他们都是靠前的!
把 DeepSeek 模型换成 chat 模型,按理说聊天模型会比推理模型快很多。
结果如下:
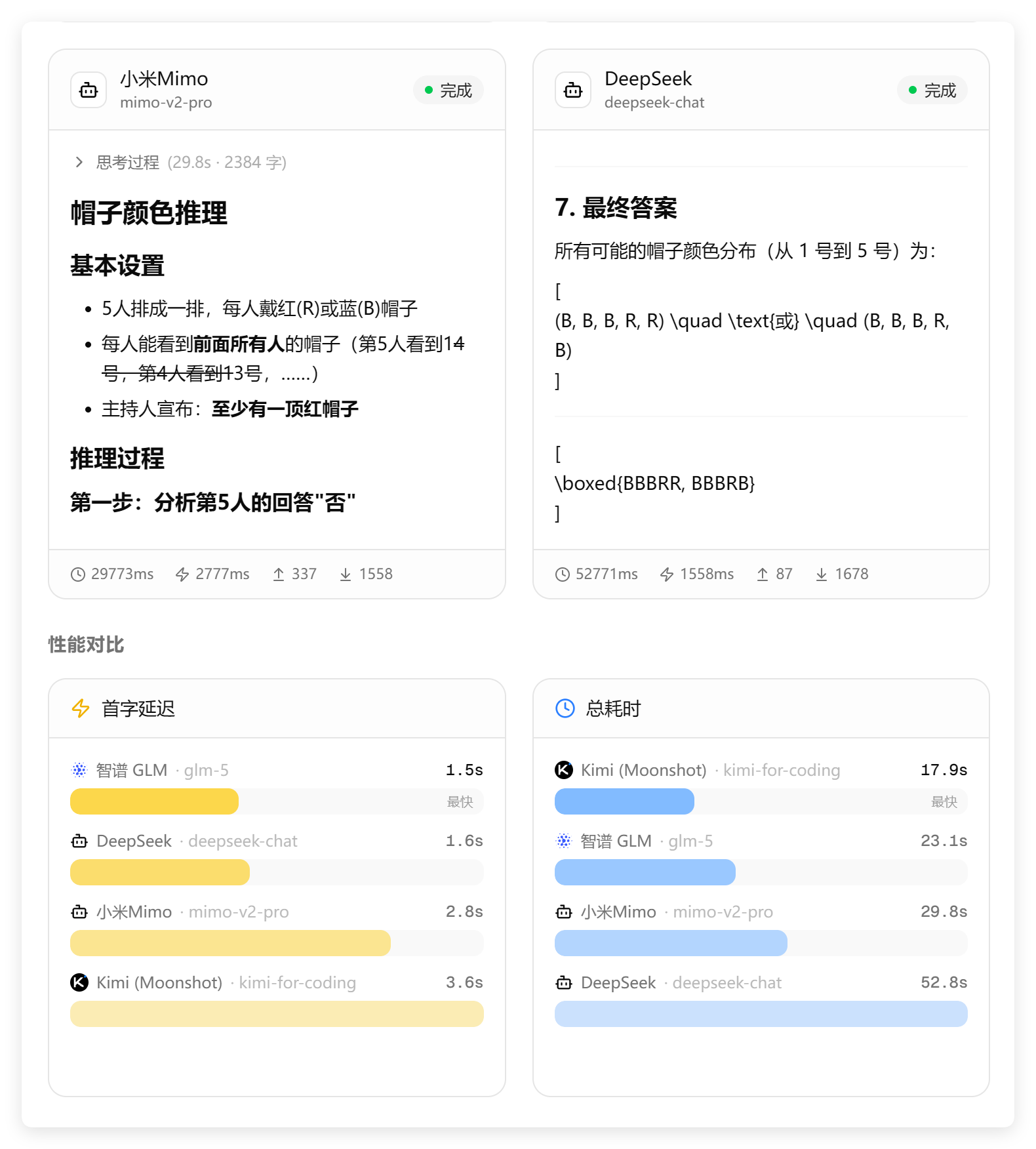
答案结构混乱,时间消耗还是特别长!
这么一比,小米都变得“眉清目秀”了。
这是要上下文没上下文,要速度没速度啊!
我也让它写了几个网页例子,奇怪得很,明明是国产模型,中文提示词,结果全是英文网页。
写了个五子棋,布局没啥问题,但是它写的 AI 对手非常弱,最高难度都是傻乎乎的。
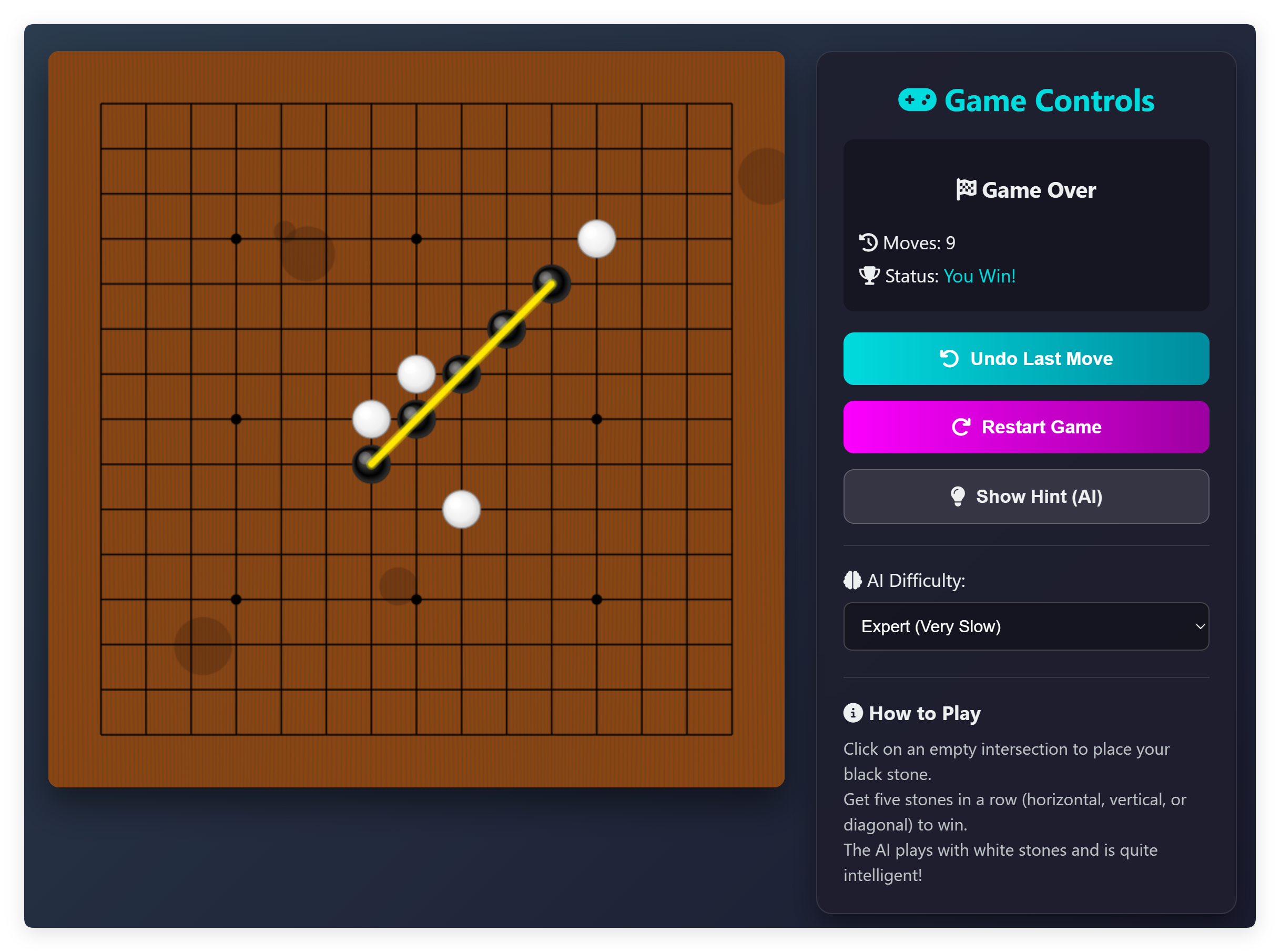
提示词里专门提了,对战的 AI 要有一定智力程度,它写的这个几乎是“弱智”!
一年前,勉强可以用首图,一年后,只能用这张图了!

这么看来 DeepSeek 没人提起也是正常的,毕竟别人进步太快了,而它却一直止步不前!
我记得 DS 好像和遥遥领先的华为强强联合了吧,结果……停更了?!
群组升级开发测试系列:
MiniMax 2.5 和 Kimi 2.5 的测试过程和结果
测试的项目地址:


关于作者
tony
某人