纯本地龙虾养殖搞起来!Qwen3.5 +Ollama+OpenClaw!
Qwen 3.5 来了,刚开始只发了 27B,我有点高攀不起。昨天,小尺寸的模型终于来了,我觉得我又可以了!
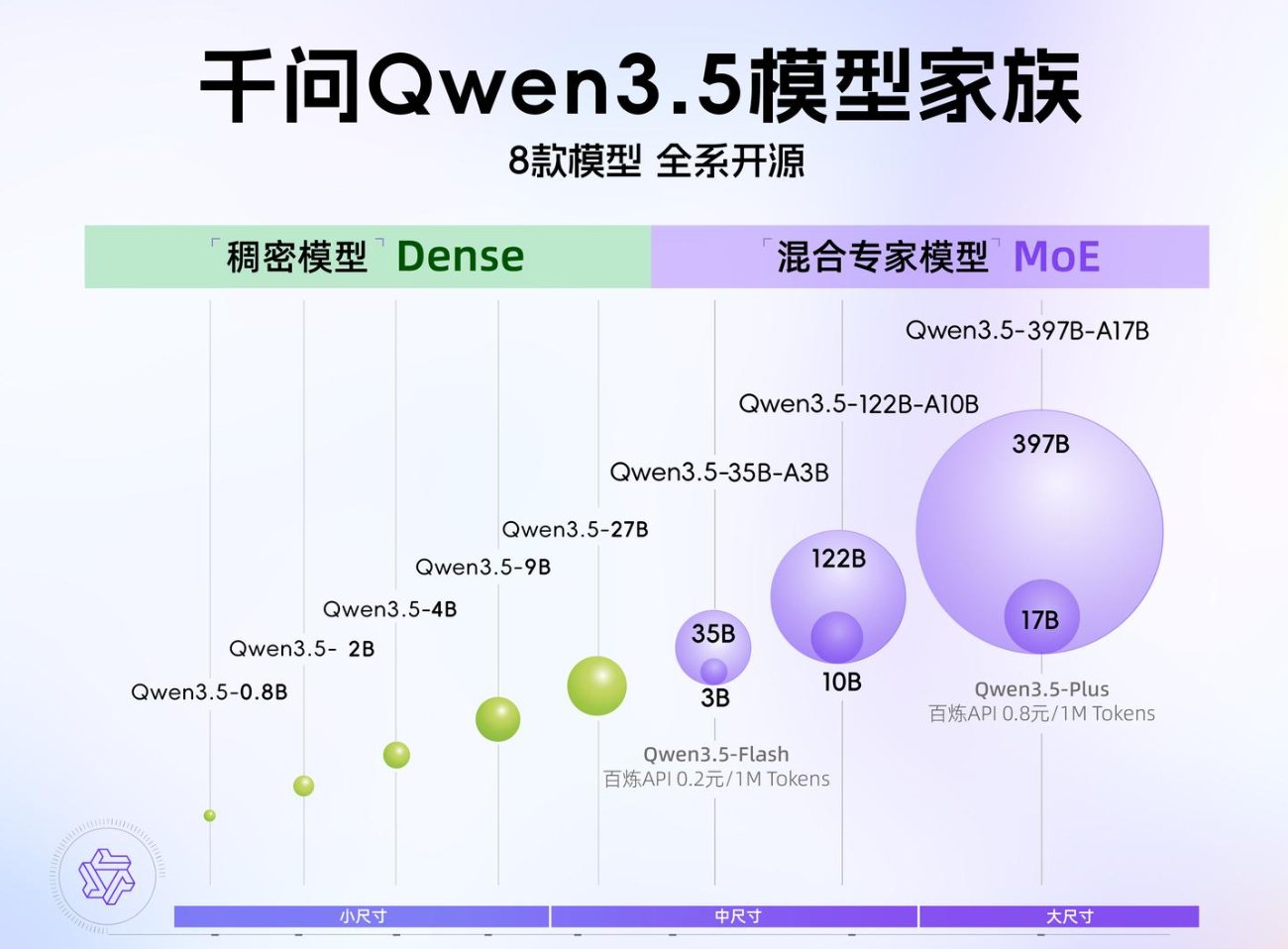
从 0.8B 到 9B的稠密模型,再从 35B 到 397B 的混合专家模型,各种尺寸任君选择。
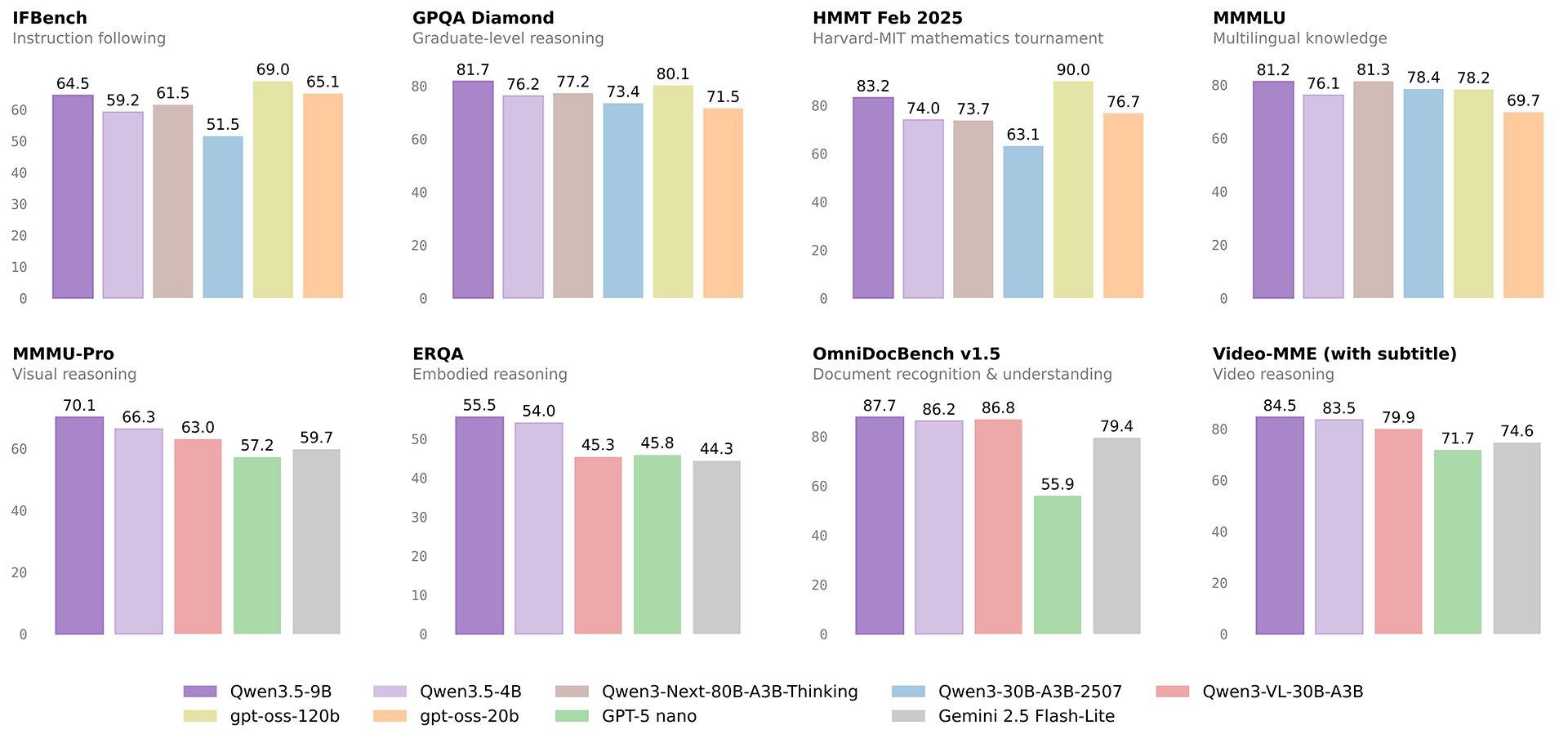
重要的是这些小模型也很强大,即便是 4B、9B 这种小尺寸的模型也非常能打,都是直接对标 30B、80B、120B,甚至是闭源的 GPT-5 nano、Gemini 2.5 Flash 这种,不光对边,还能小胜。
这一波更新直接把本地大模型的能力拉高了一个台阶,Qwen 真的是太棒了。
要知道 9B 以下模型,在普通消费级显卡上就能轻松运行哦!
不用 5090,也不用 5080,甚至不需什么 50 系列、40 系列、30 系列,随便掏出一张上古时代的 1070 也可以运行。
这门槛一下子就下来了。
下面分别看一下不同尺寸的模型适合哪些场景。
📌 0.8B / 2B:极致轻量,端侧首选
特点:体积极小,推理速度极快。
场景:非常适合移动设备、IoT 边缘设备部署,以及低延时的实时交互场景。
📌 4B:轻量级 Agent 的强劲基座
特点:性能强劲,多模态基座模型,适合 Agent。
场景:适合作为轻量级智能体的核心大脑,完美平衡了性能与资源消耗。
📌 9B:紧凑尺寸,越级性能
特点:结构紧凑,但性能媲美 gpt-oss-120B,让人惊艳。场景:适合需要较高智力水平但受限显存资源的服务器端部署,是性价比极高的通用模型选择。
虽然我还没有用,但是看了一眼都感觉香的不行了。
马斯克看了都忍不住来评论一下:“令人印象深刻的智能密度”。
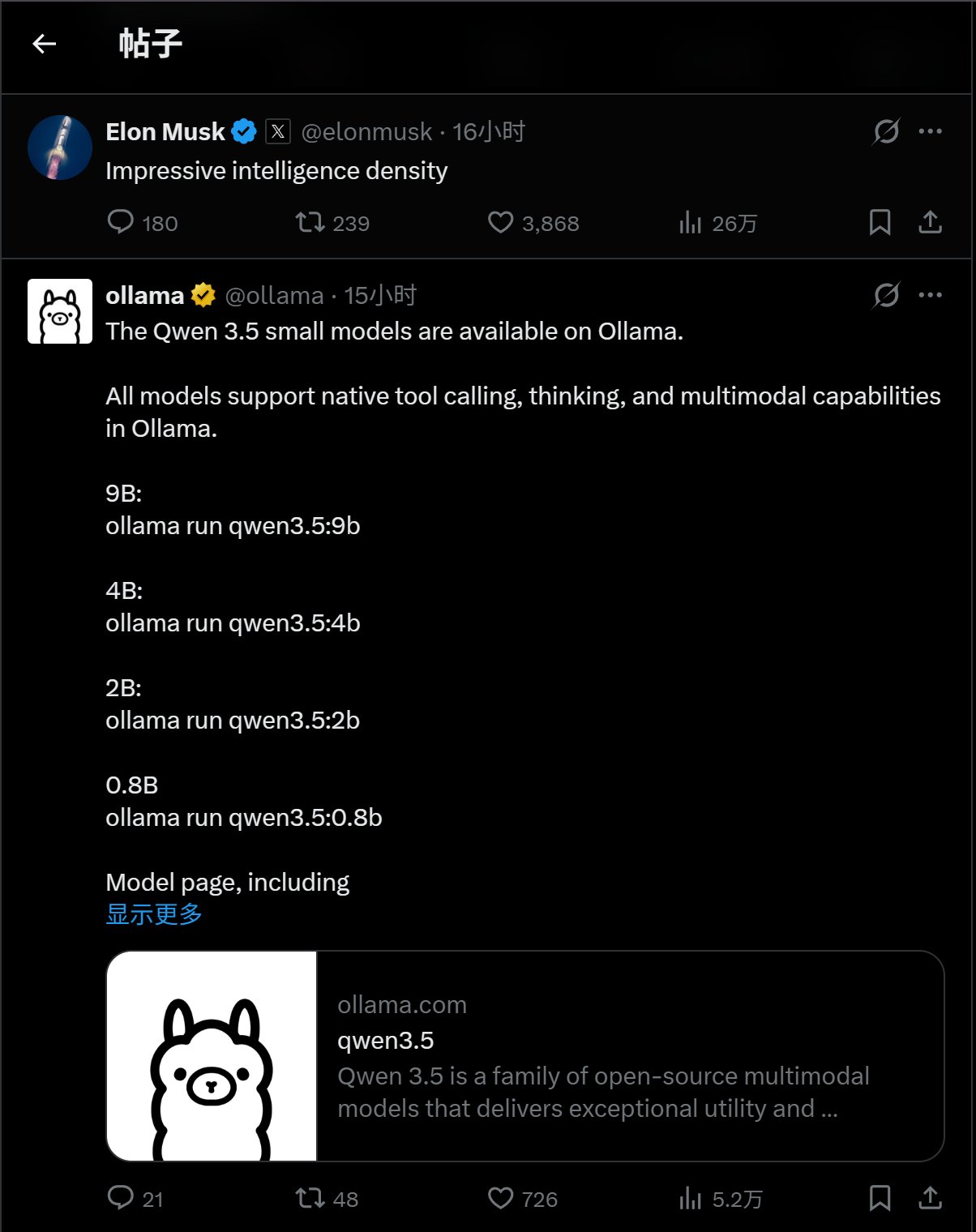
所以 Qwen 3.5 的推特的榜一被推特老板马斯克拿去了。
而榜二就是小羊驼了。Ollama 第一时间支持了 Qwen 3.5 各种尺寸的模型。
我们来捋一捋,Qwen 3.5 4B 就可以作为 Agent 基座,支持多模态,速度又快,配置要求又低。这感觉就是为了 OpenClaw 这种个人 AI 助手准备的啊。
OpenClaw 出来有一段日子了,但是热度不减,大家玩的不亦乐乎。
目前限制大家使用 OpenClaw 一大阻力就是 token 消耗不起。除非你开一个在线模型的API,否则你就玩不转小龙虾。现在好了,Qwen 3.5 来了,官方已经明示了,这个模型支持 Agent。
那么,我先来帮大家尝尝鲜!然后把烹饪方法完完整整的分享给大家。
方法其实也很简单,就是把一大堆动物聚集起来就可以了。
我们需要的动物有,小羊驼🦙,小龙虾🦞,还有熊大侠🐻!
好了,下面我们要认真了。
小羊驼养起来
常看我文章的人应该对这个小羊驼很熟悉了。Ollama 就是一个本地运行大模型的启动器,可以非常方便的下载、启动、使用各种最新的 AI 大模型。
我们首先需要下载 Ollama 这个软件,下载和安装软件非常简单。
直接打开网址:
https://ollama.com/download/windows
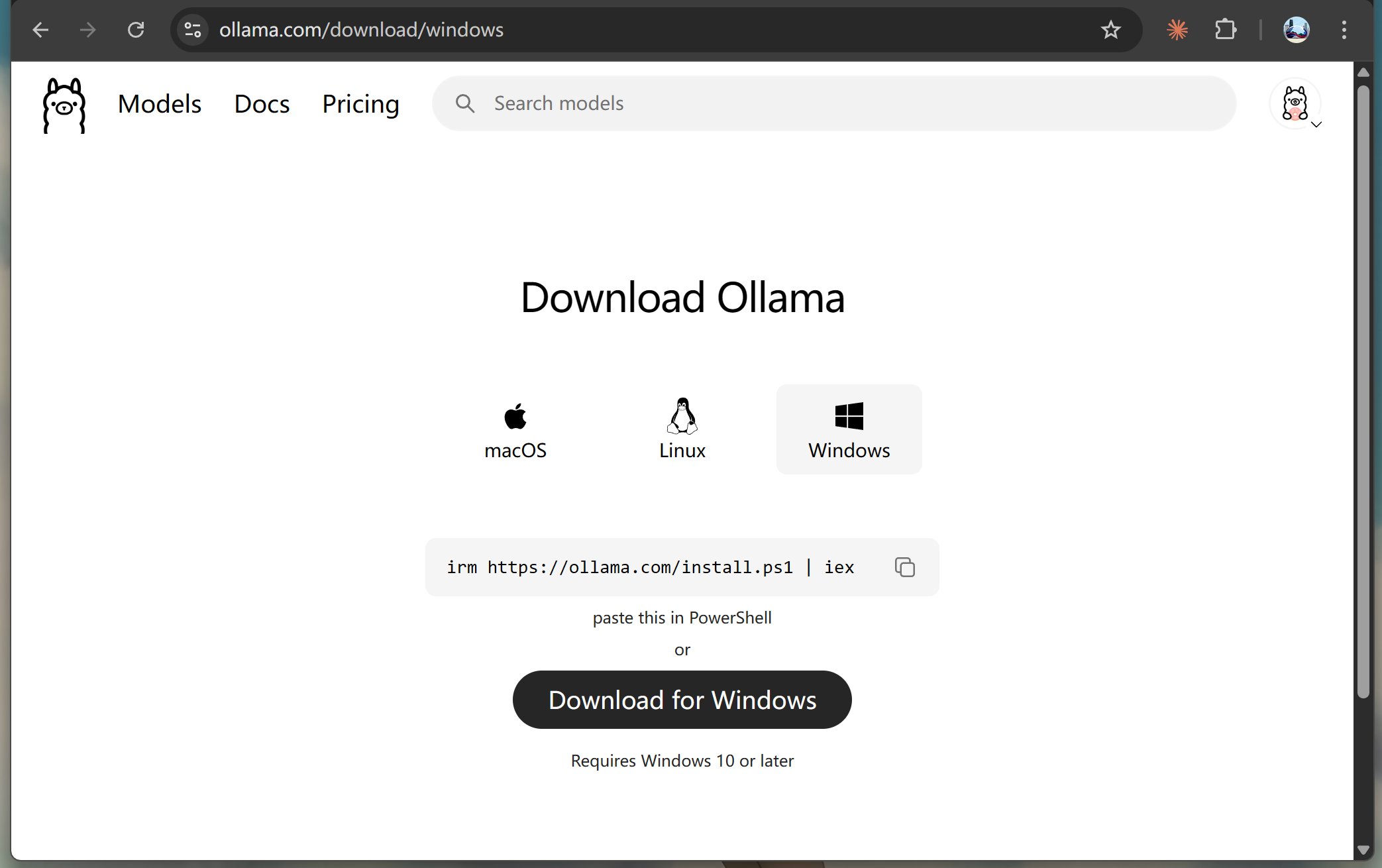
然后根据自己的操作系统进行选择,比如我当前使用的是 Windows 系统,所以默认选中了 Windows 版本,直接点击 Download 就可以了。
下载完成就是一个 Windows 下的 exe 应用软件,双击安装,是人都会。
当然,也可以打开 PowerShell 进行安装,命令如下:
irm https://ollama.com/install.ps1 | iex
一般安装完成之后都会自动启动,右下角托盘上会出现一只羊驼。
如果你之前就装了 Ollama,那么注意查看一下版本,最好是升级到最新版。
我当前使用的版本是 0.17.5,可以正常使用 Qwen 3.5 的各种模型。
熊大侠请进门
羊驼搞定了,就可以把熊大侠(Qwen 3.5)请进门了。
接下来我们就是下载模型Qwen3.5的模型了,打开 Ollama 的官网,找到 qwen3.5 的主页。
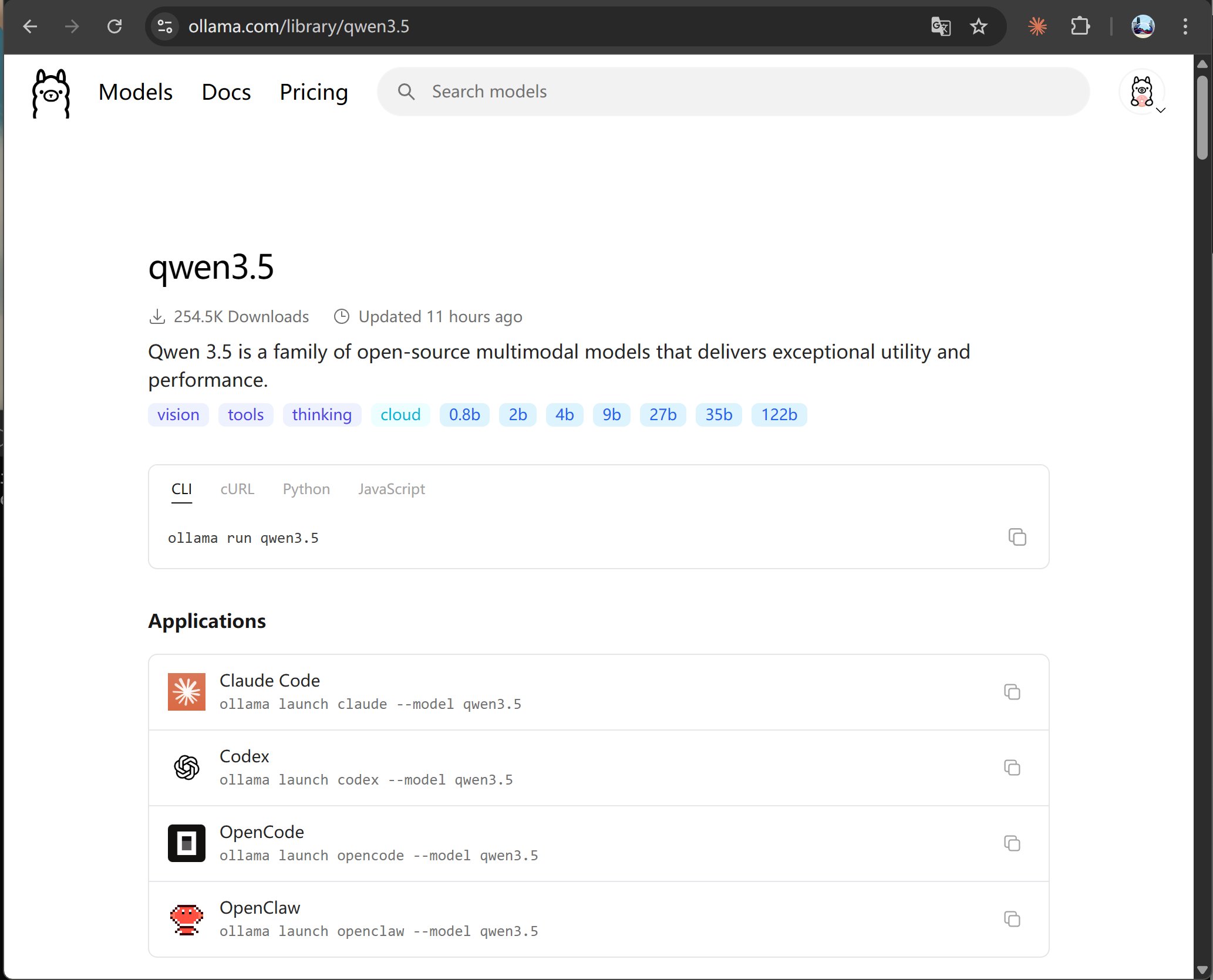
这个页面上有很多标签,比如视觉(vision),工具调用(tools),推理(thinking),还有0.8到122b的模型标签。
Cli里面有默认的下载和运行命令:
ollama run qwen3.5
这个命令安装的是 9B 的模型。
如果需要其他尺寸,可以点击下方的模型列表进行选择,然后复制命令。
比如下载 4B 的模型:
ollama run qwen3.5:4b
这个模型只有 3.4 G,理论上 6 GB+ 的显卡可以轻松运行。
我是先下载了 9B 的模型:
ollama run qwen3.5:9b
复制命令之后,在桌面空白处右键,选择在终端中打开。然后直接粘贴这行命令,回车就可以了。
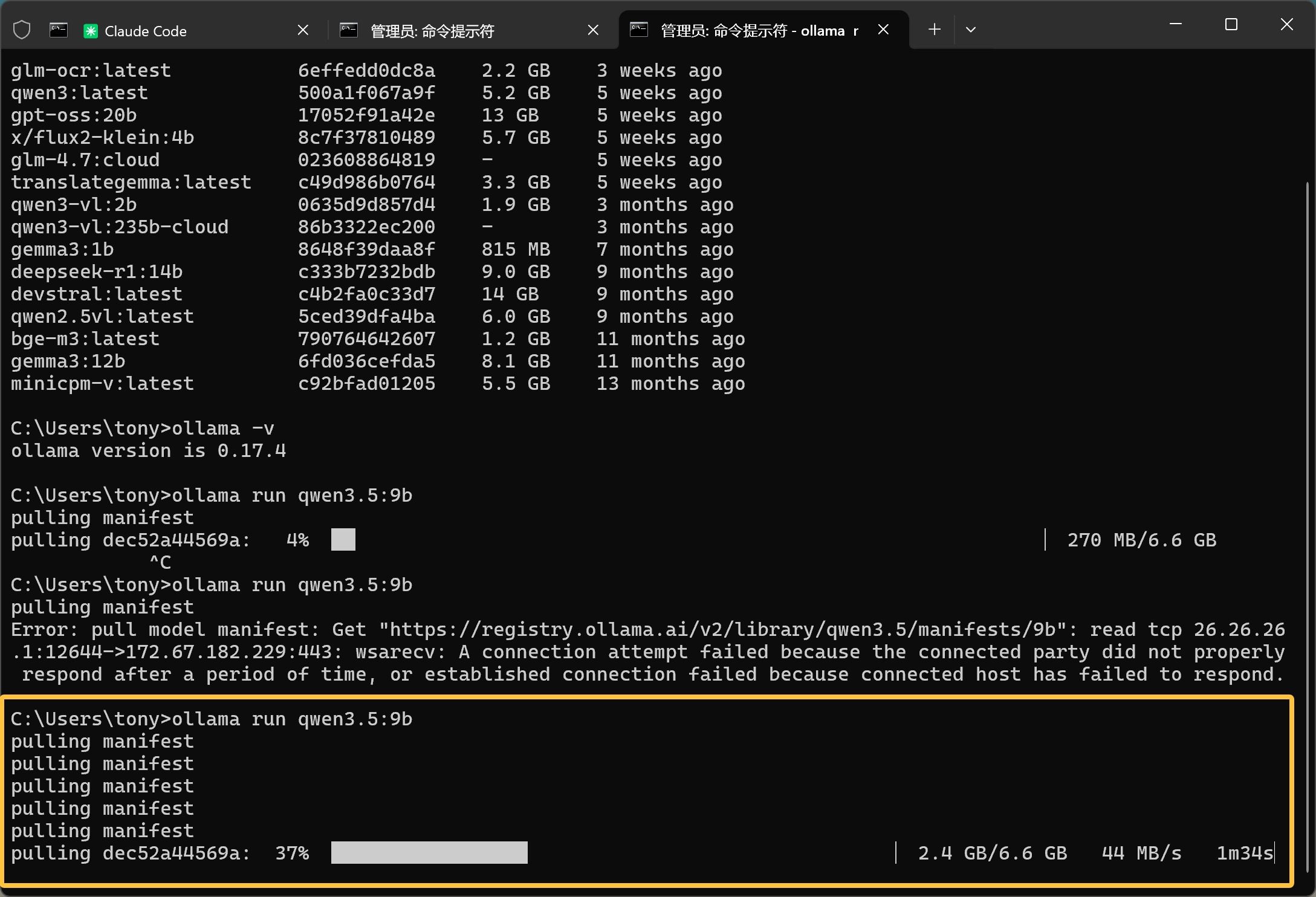
下载 Ollama 模型,不用科学工具,有的可以关了。我本地下载速度非常快,能达到 44 MB/s。
下载完成之后,会直接进入对话状态,可以聊天测试。
我们用–verbose参数来看看速度如何:
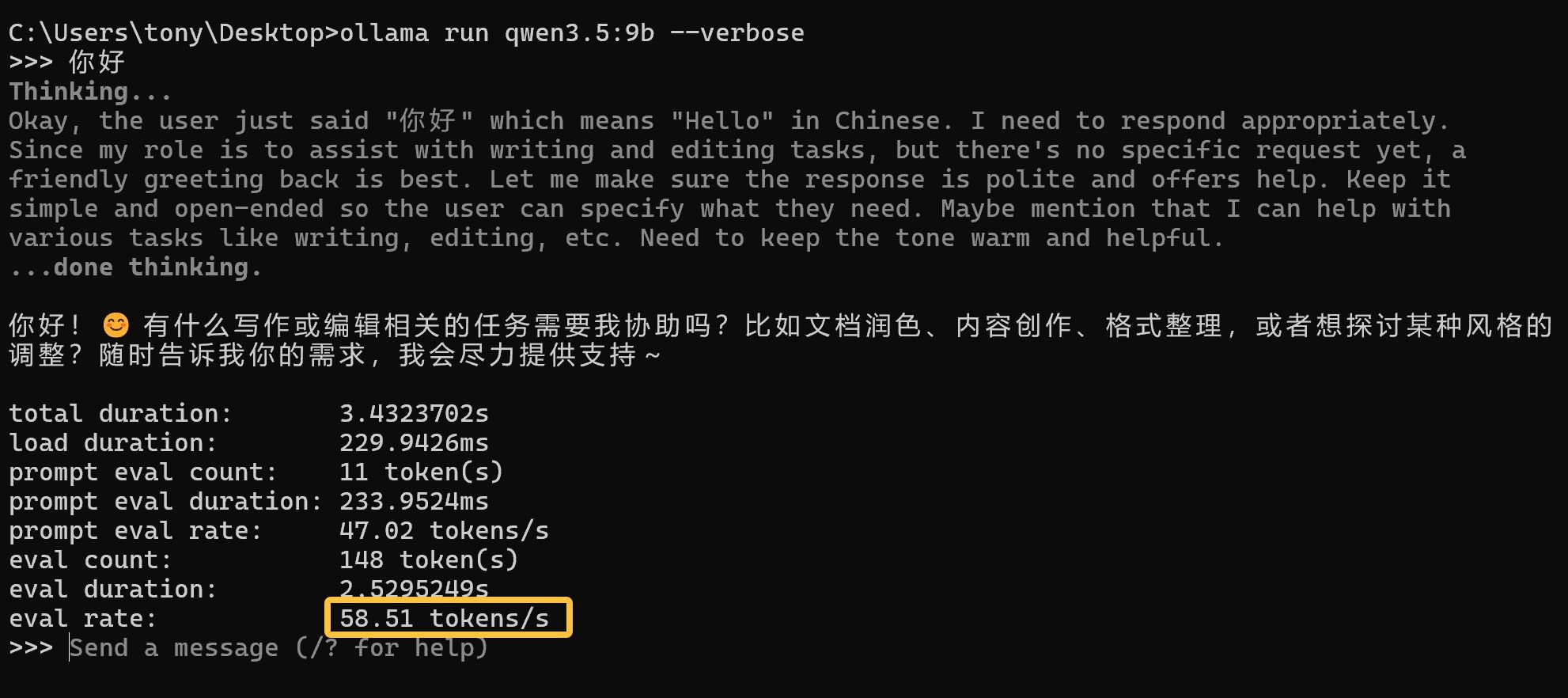
在 5060 Ti 上的速度可以高达 58 tokens/s,这个速度相当快,一般的在线 API 也差不多这个速度。
小龙虾养起来
上面两个步骤弄好了,就可以养小龙虾——OpenClaw 了。
官网地址:https://openclaw.ai/
OpenClaw 的本地安装其实也非常简单,就是配置稍微复杂一丢丢,其实也不难啊。
因为我电脑常备 Node.js 环境,所以直接用 npm 命令安装。
命令如下:
npm install -g openclaw
运行过程如下:
现在官网比较推荐的方式是直接使用 PowerShell。
命令如下:
iwr -useb https://openclaw.ai/install.ps1 | iex
因为 PowerShell 是系统自带的工具,所以现在很多软件都使用这种方式安装了。
就是第一次使用 PowerShell 可能会有一点问题,大家 AI 一下应该能都轻松解决。
然后就可以使用 ollama launch 来直接运行 OpenClaw 了。
命令如下:
ollama launch openclaw
输入命令之后,就会让你选择模型了。
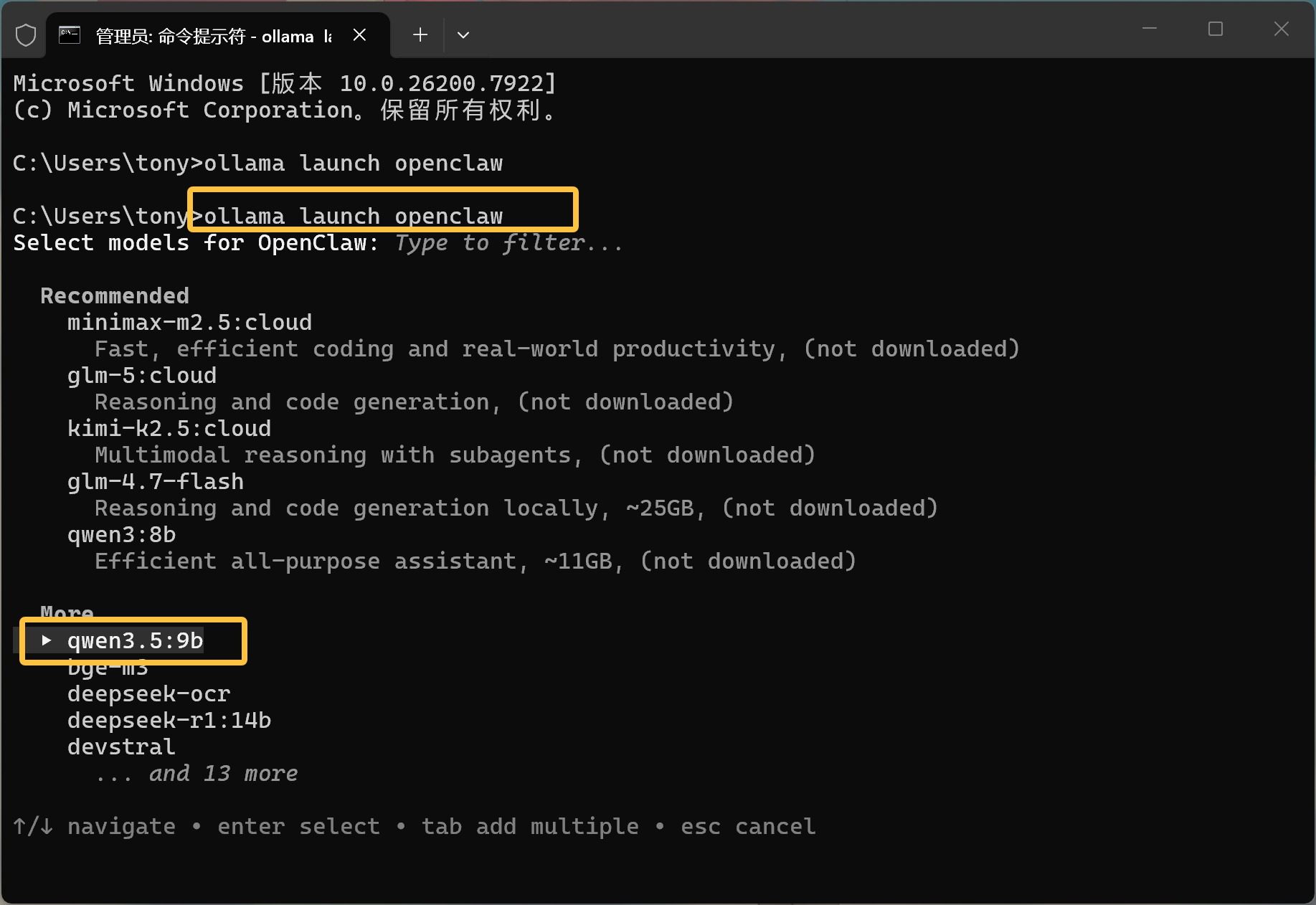
这里有一个推荐模型和更多模型。推荐模型最上面的是云端模型。
我们使用本地模型,在 More 这里往下找,按键盘上的⬇️箭头。
找到 Qwen 3.5:9b 模型,回车。
然后就是风险提示了。
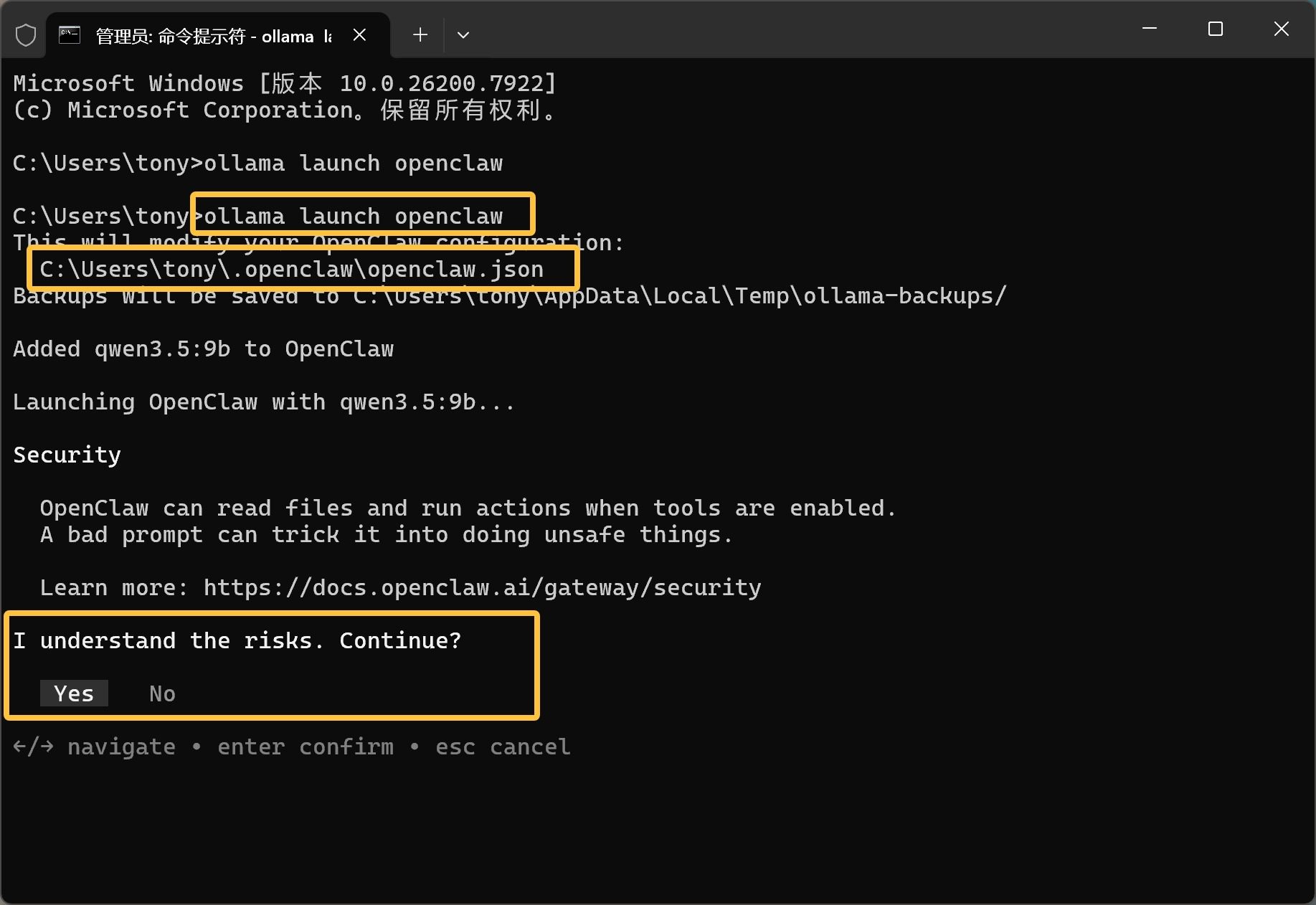
这个是常规提示,直接选择 yes 回车。
接下来就什么都不用干了,直接等着全自动完成就好了。
最后会看到 Starting gateway… 等信息。
中间可能会弹出好几个窗口,主要就是这个界面:
这里是网关的日志信息。这个窗口不用管,只要开着就行了。
然后我们看回主窗口:
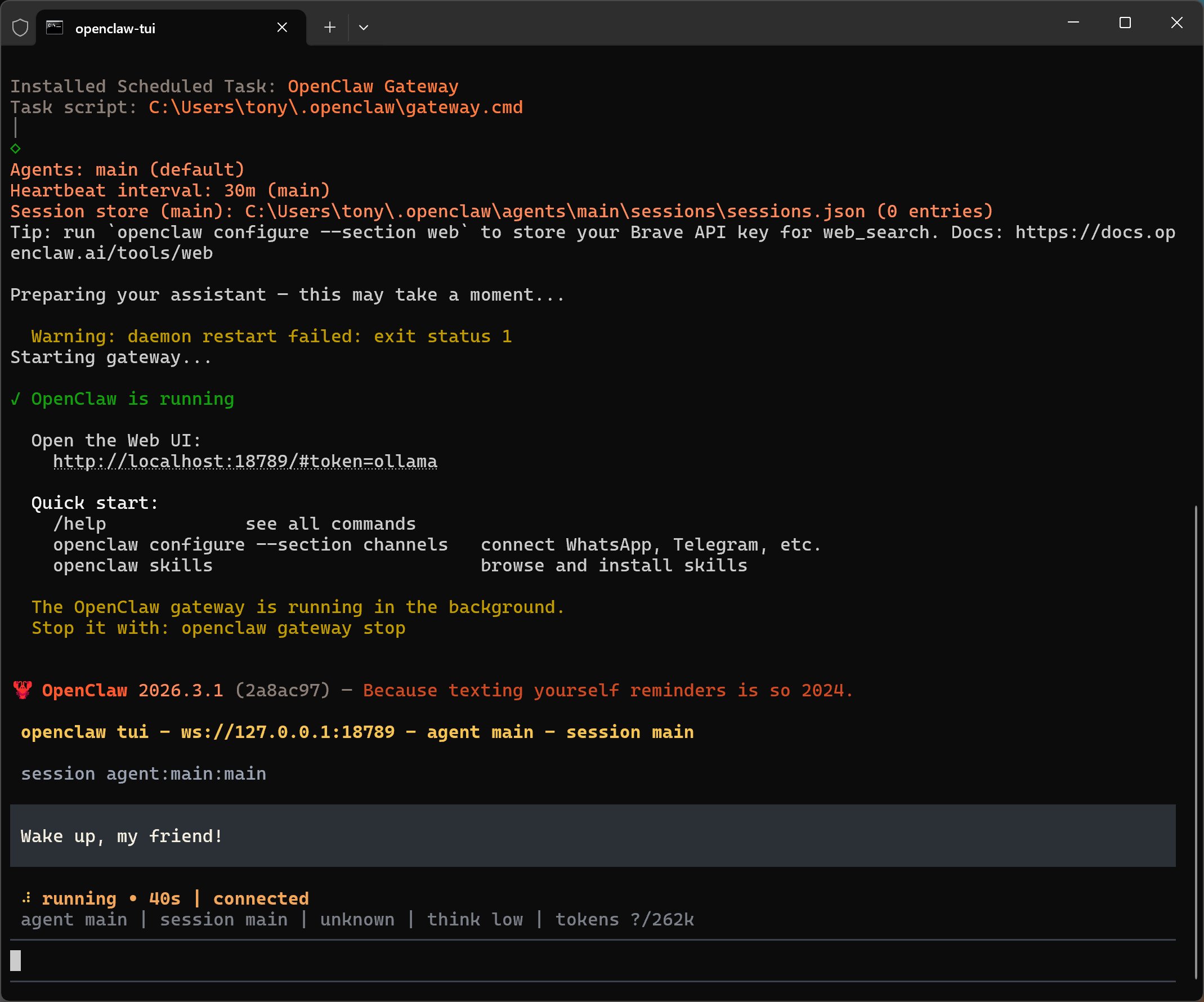
看到绿色的 OpenClaw is running,就是龙虾已经启动成功了。
启动成功之后,系统会自动唤醒你的龙虾:
Wake up, my friend!
这句话的意思,就是“醒来吧,我的朋友”。非常有仪式感啊!
经过漫长的等待,你的AI助手终于被唤醒了,并且给你发送了一段内容:
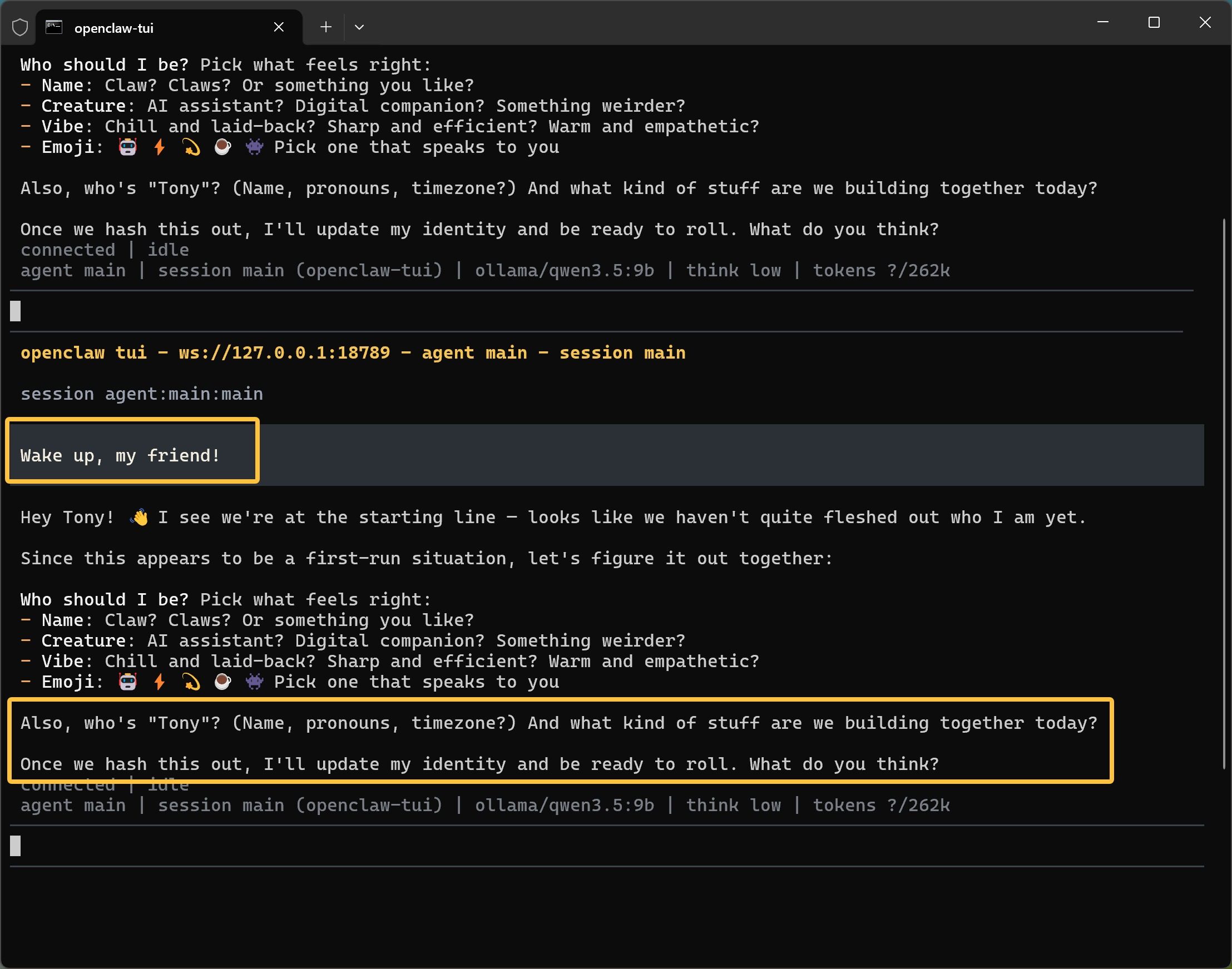
中文意思大致如下:
嘿,Tony!👋 看起来我们刚到起跑线——好像我还没真正确定“我是谁”。
既然这是第一次运行,我们一起来把它设定好:
我应该是什么样的?选一个你觉得合适的:
名字:Claw?Claws?还是你喜欢的别的名字?
角色:AI 助手?数字伙伴?还是更奇怪一点的?
风格:轻松随意?干脆高效?温暖体贴?
表情符号:🤖 ⚡ 💫 🛸 👾 选一个最能代表我的
另外,“Tony”是谁?(名字、代称、时区?)我们今天准备一起做些什么?
等我们聊清楚这些,我就会更新我的身份,然后准备开干。你觉得怎么样?
先不管它说了什么,重点是它说话了。
很多人可能不习惯在这个黑漆漆的界面里说话,这个时候可以根据上面的提示,直接打开网页版。
上面截图中有一个地方写了一句 Open Web UI,然后下面有一个网址:
http://localhost:18789/#token=ollama
把这个网址复制到浏览器,就可以看到界面了。
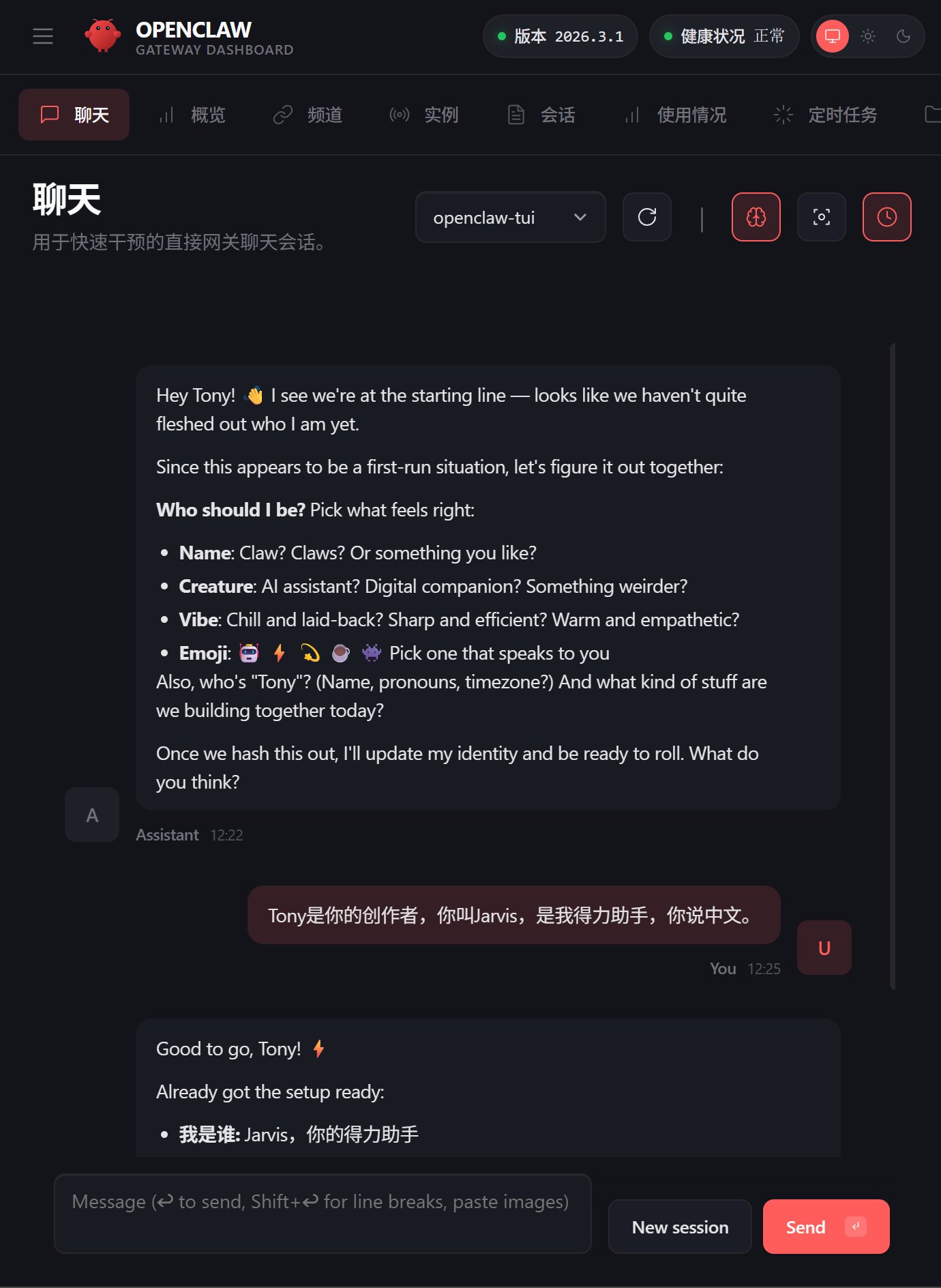
界面中的聊天内容,和我们终端中的内容是同步的。在这个界面可以和我们的定制小龙虾对话,当然对话并没有什么了不起的。OpenClaw 和以往的 AI 最大的区别就是,它不仅仅能对话,它能访问和操作你的电脑。
接下来进行两个简单的电脑操作,读取和写入文件。
第一个要求是让他帮我读取一下电脑桌面中的图片文件,列出文件名。
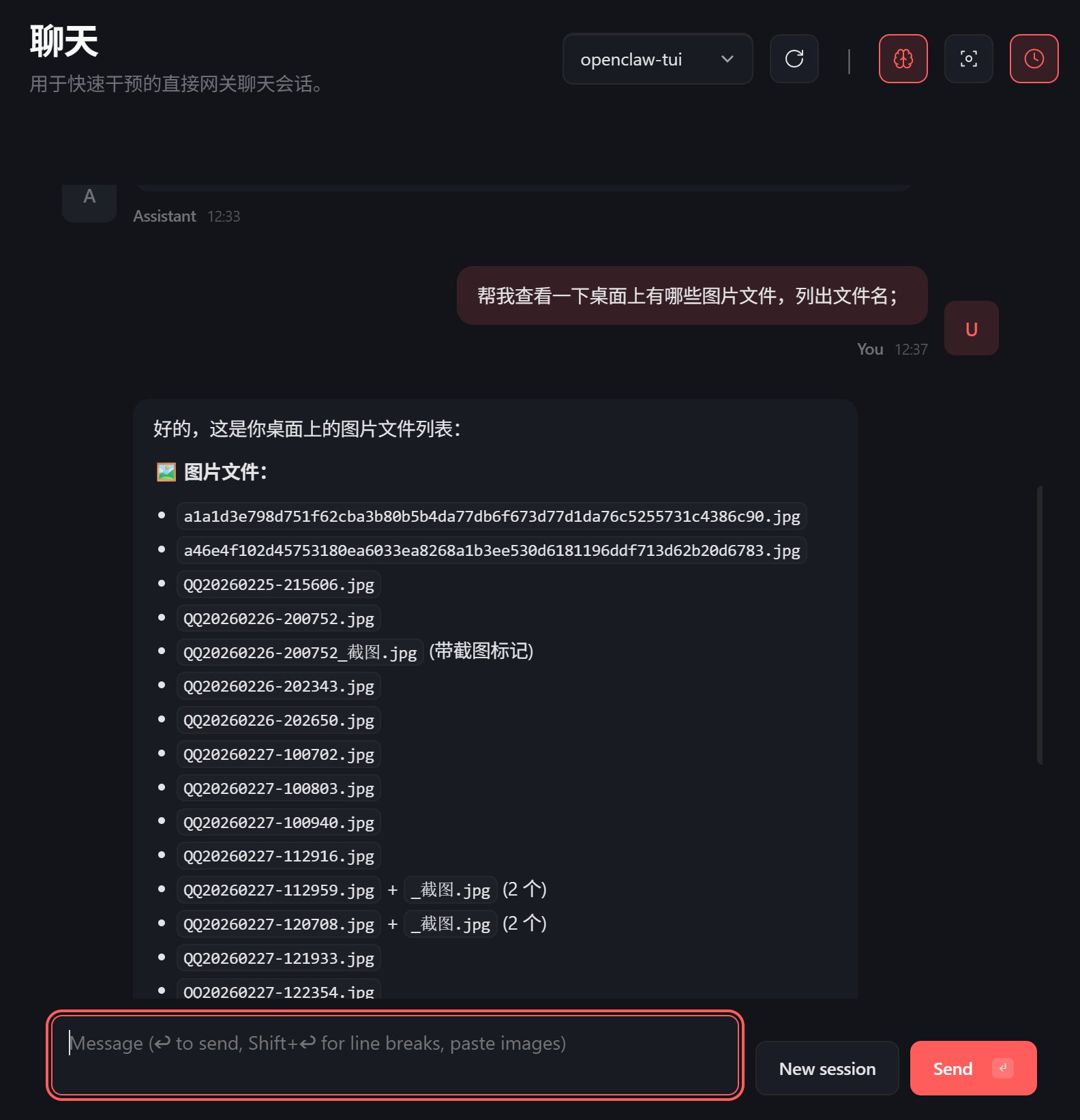
轻松搞定。
另外一个问题是,帮我创建一个文件,并写入内容。
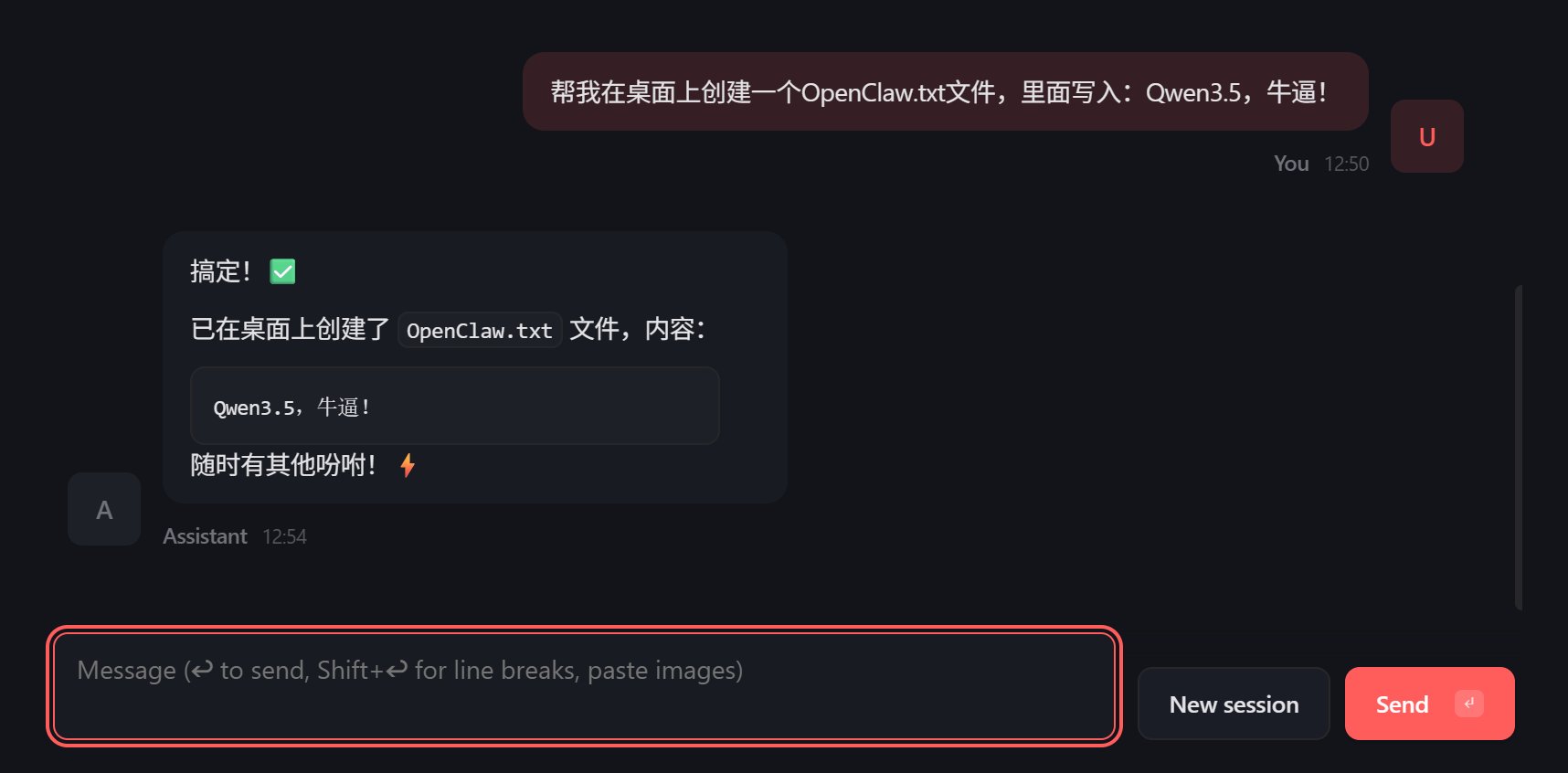
这个问题,也没有难倒它。
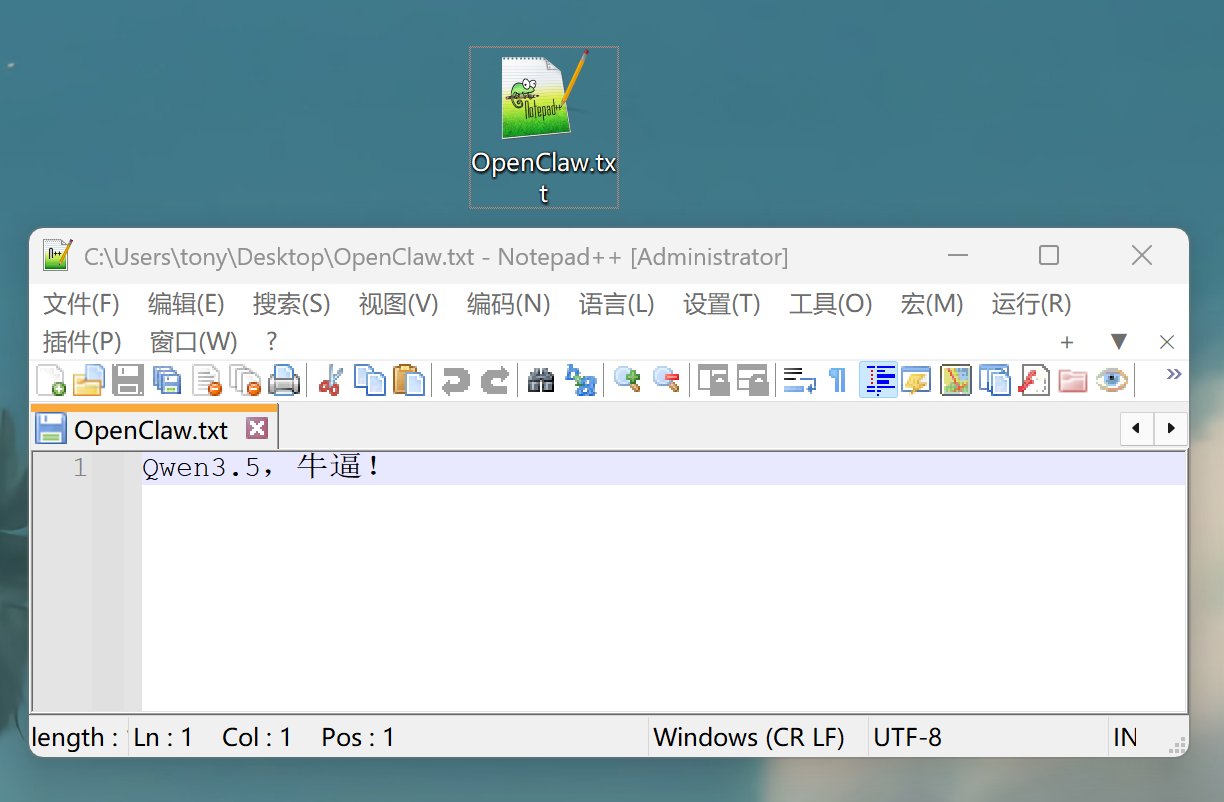
成功在桌面上创建了指定的文件,并且在文件里面写入了指定的文字。
通过这两个简单的例子,充分验证了 Qwen 3.5 9B 的可用性。别小看这两个简单的操作,以往的开源模型都不行。以前的模型是这样的,你和它说话可以,但是叫它干活,就立马歇菜了,就是完完全全的动口不动手。
这次是真的能干活了,也就是整个本地化的链路打通了!
但是这里还是有一个问题,就是模型的思考时间太久了。按理说,每秒 50 多个 tokens 处理起来会很快,但是由于思考时间比较长,导致整个小龙虾反应迟钝。
其实很多操作是不需要深度思考的,所以下一步,是要找一个方法把 Ollama 的思考模式关闭掉。
Qwen3.5的这个速度和能力,确实是很不错了!直接就是从不能用到能了的跨越了。
如果你们Ollama搞不到,也可以给公众号发:“Ollama” 直接获取!


关于作者
tony
某人