开发“360安全卫士”,Opus4.6把GPT5.3吊起来打了?!
现在还有人用 360 安全卫士吗?我最近一次见它是在我叔的电脑上。
看了一眼,热闹得很,“360 拖家带口”,被我撵走了,卸载了好久!
最近 Opus 和 GPT 都更新了,我想着让他们以 360 为榜样,开发一个“电脑管家”,看看他们的水平如何。
我们先简单地定一个规则:一样的提示词,只做一轮,只测一次,一把定胜负。
如果对话多了,我的因素就会影响结果,次数多了,我的配额就扛不住。
提示词只做宏观描述,给他们自我发挥的空间。
完整的提示词:
“我需要你给我开发一款适合中老年的电脑管家,可以参考 360 安全卫士和腾讯管家。 你首先分析一下需要哪些功能,然后再实现这些功能,最好是能自己写一些测试用例,保证基本功能没啥问题。 我的总体要求是简单,实用,易用。 技术框架你自己选,主要是针对 Windows 用户。”
这是两位选手出场时候的血量:
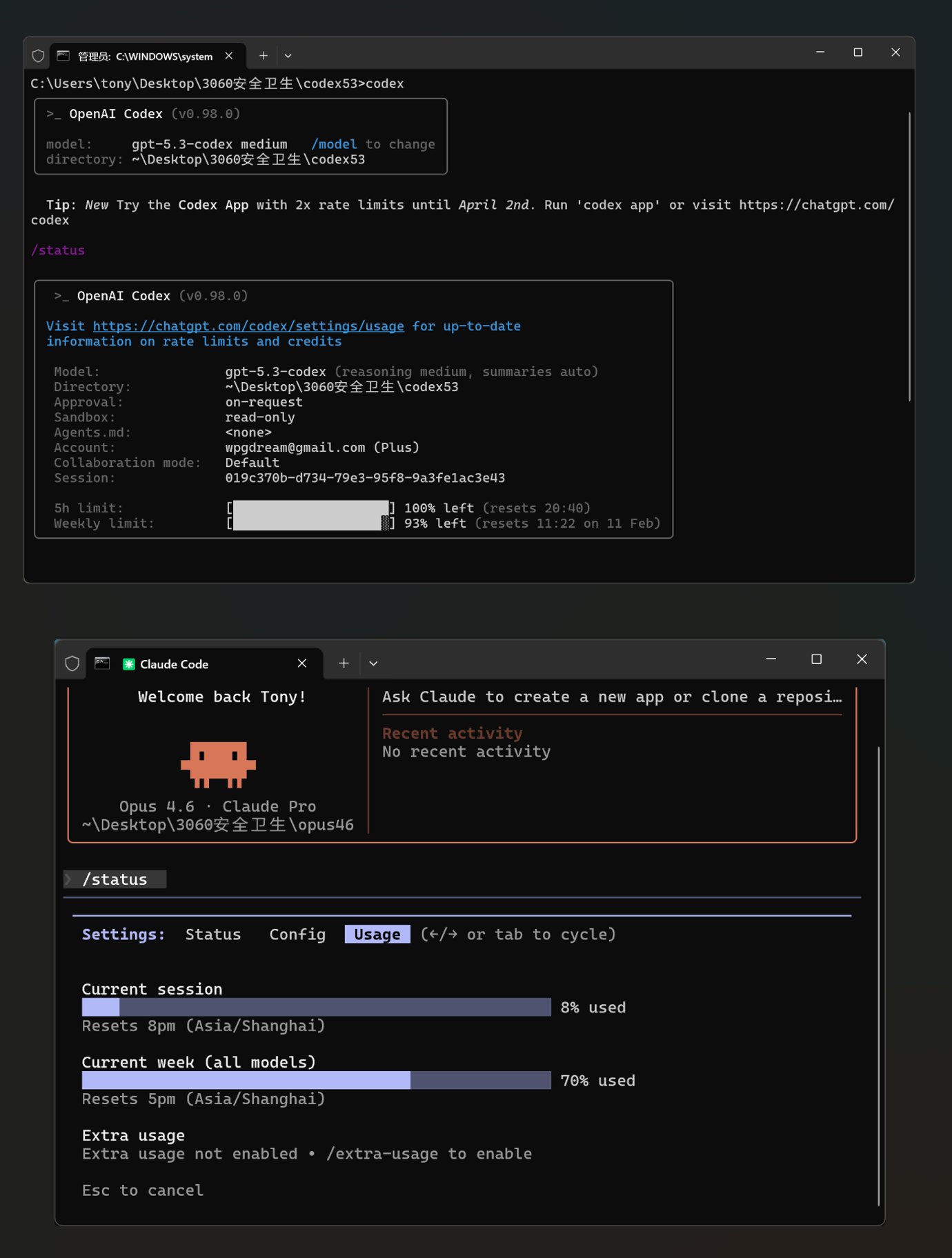
然后输入提示词,开始干活了。
GPT-5.3-Codex 只用了 4 分钟就直接交作业了。
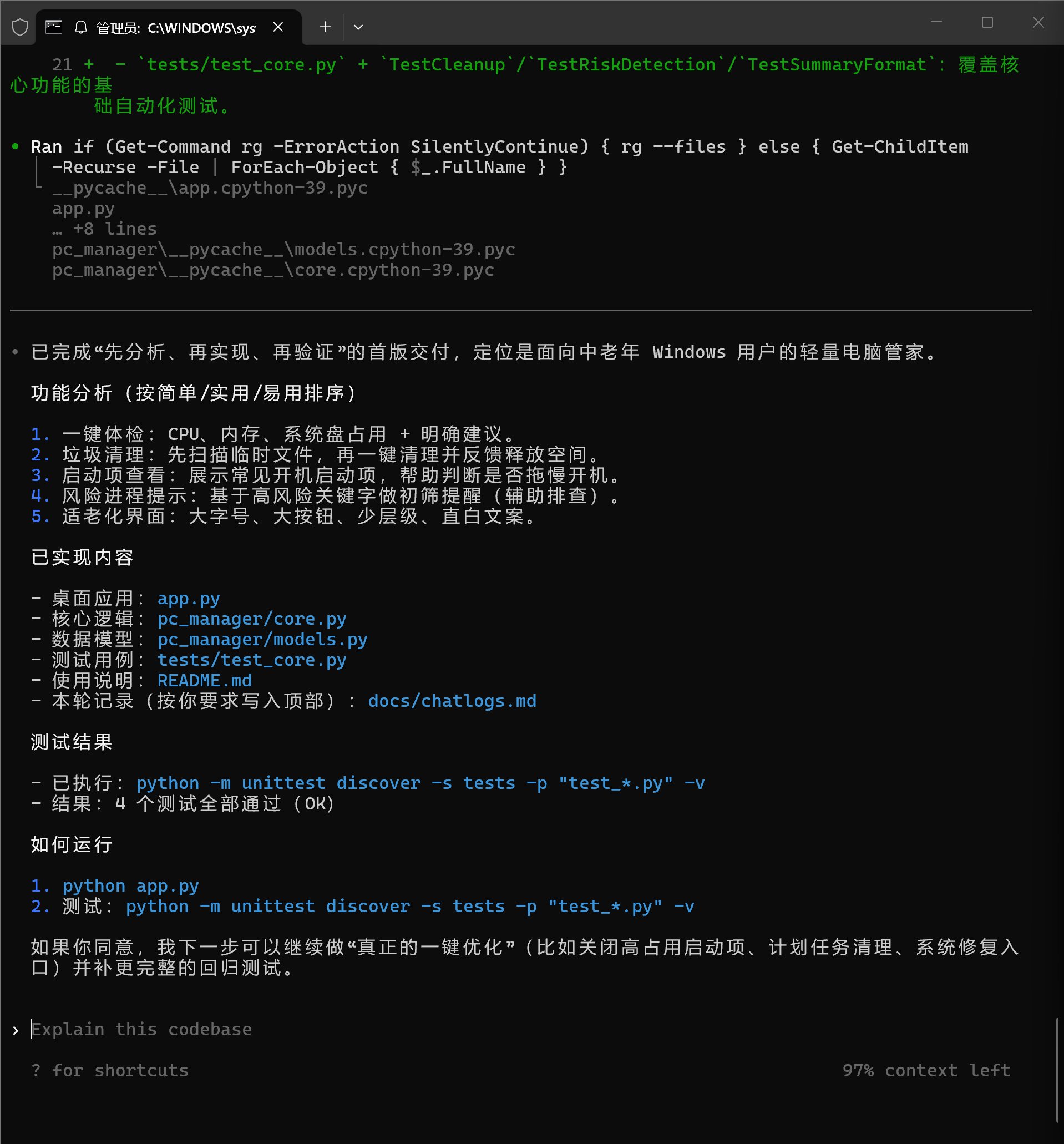
运行完成之后,它主要是交代了这些:
功能分析(按简单/实用/易用排序)
- 桌面应用:app.py
- 核心逻辑:pc_manager/core.py
- 数据模型:pc_manager/models.py
- 测试用例:tests/test_core.py
- 使用说明:README.md
- 本轮记录(按你要求写入顶部):docs/chatlogs.md
测试结果
- 已执行:python -m unittest discover -s tests -p "test_*.py" -v
- 结果:4 个测试全部通过(OK)
如何运行
1. python app.py
2. 测试:python -m unittest discover -s tests -p "test_*.py" -v
从这里可以看到,它大概是写了 4 个 py 文件,一个 readme。然后做了 4 个测试。
最后教了下运行的方法。
然后我根据它运行的方式启动了应用。
主界面:
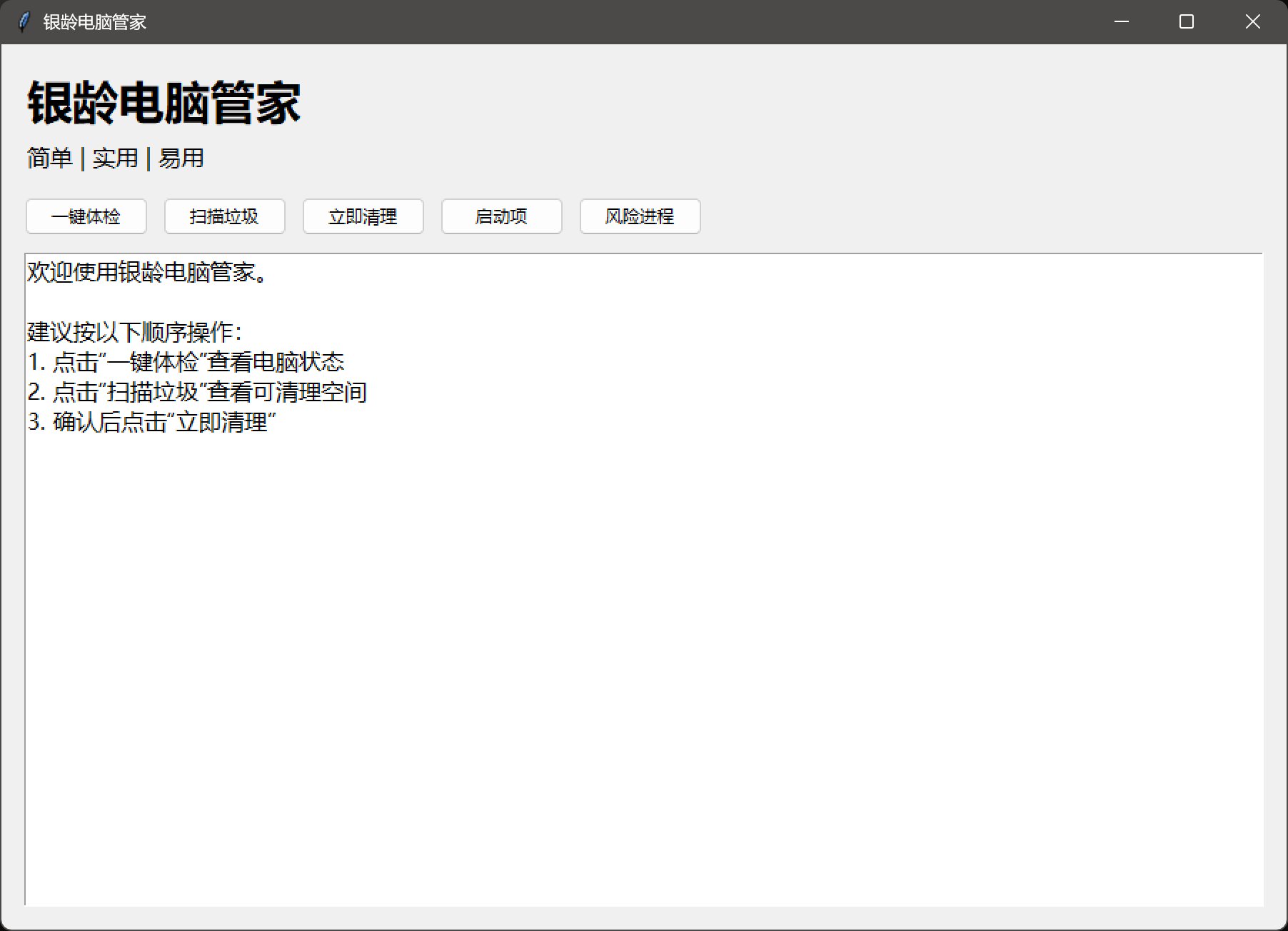
果然简单……很复古!
它给这个软件名字叫“银龄电脑管家”。这……估计得 60 岁以上的人用了。
一键体检:
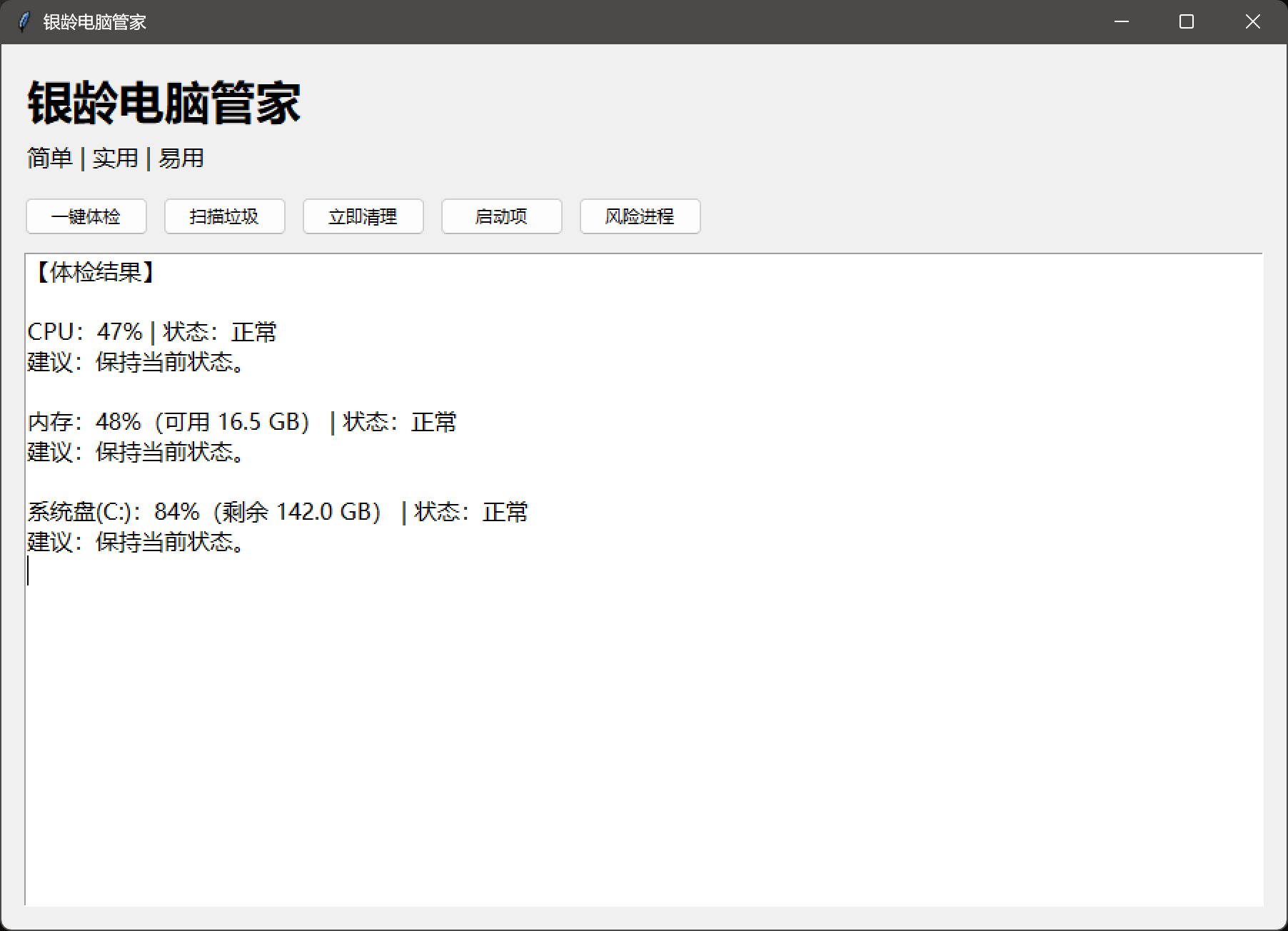
它的体检就是帮你看一下 CPU、内存和硬盘的占用情况,然后结果都是正常。
没有显示 CPU 型号、线程数,也没有显示内存总量,以及 D 盘和 E 盘的状态。
垃圾扫描:
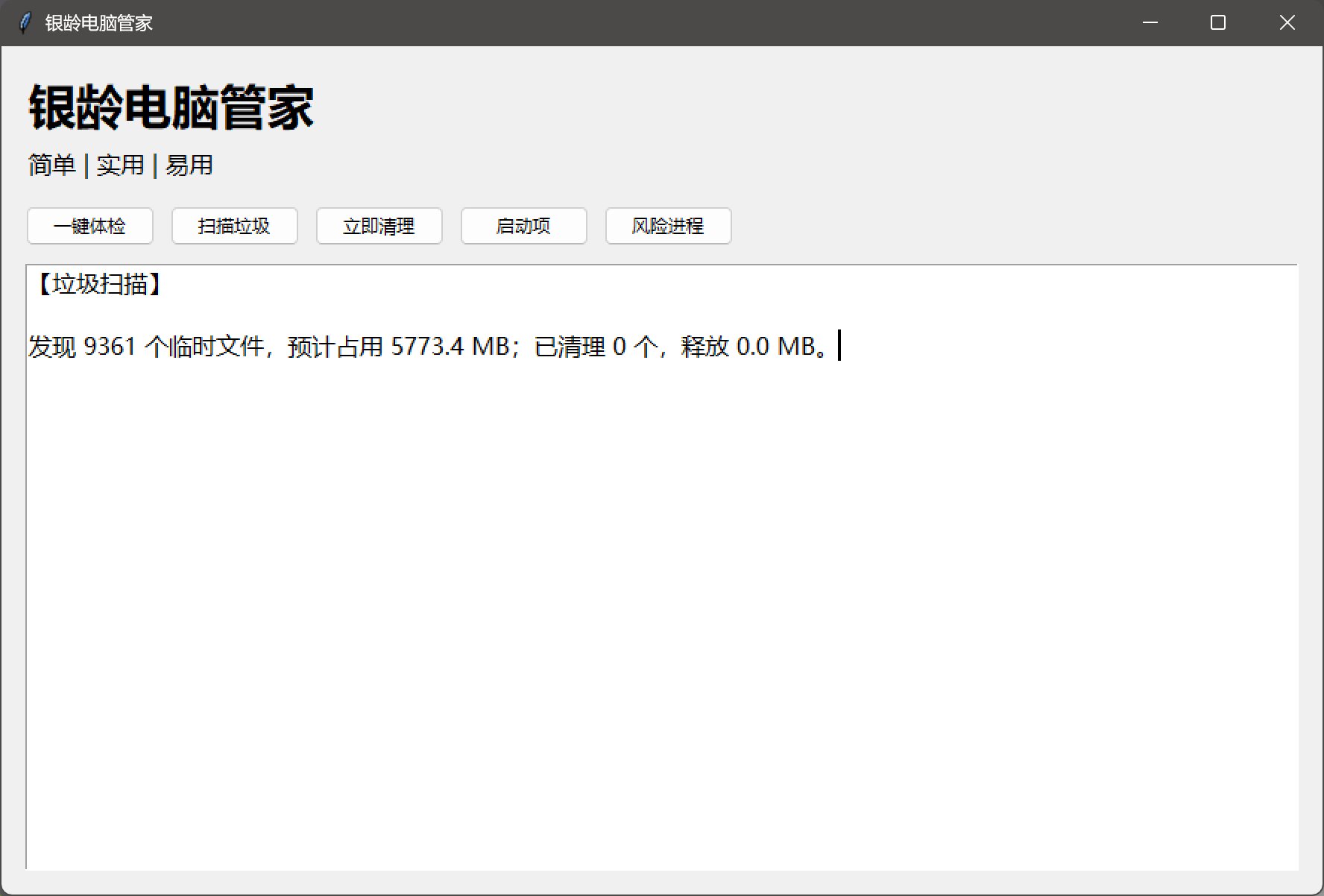
点击直接卡死,等待一段时间后出现了一个结果,好像干了,又好像什么都没干。
那个“立即清理”我是没有点,因为我不太敢点。
启动项目:
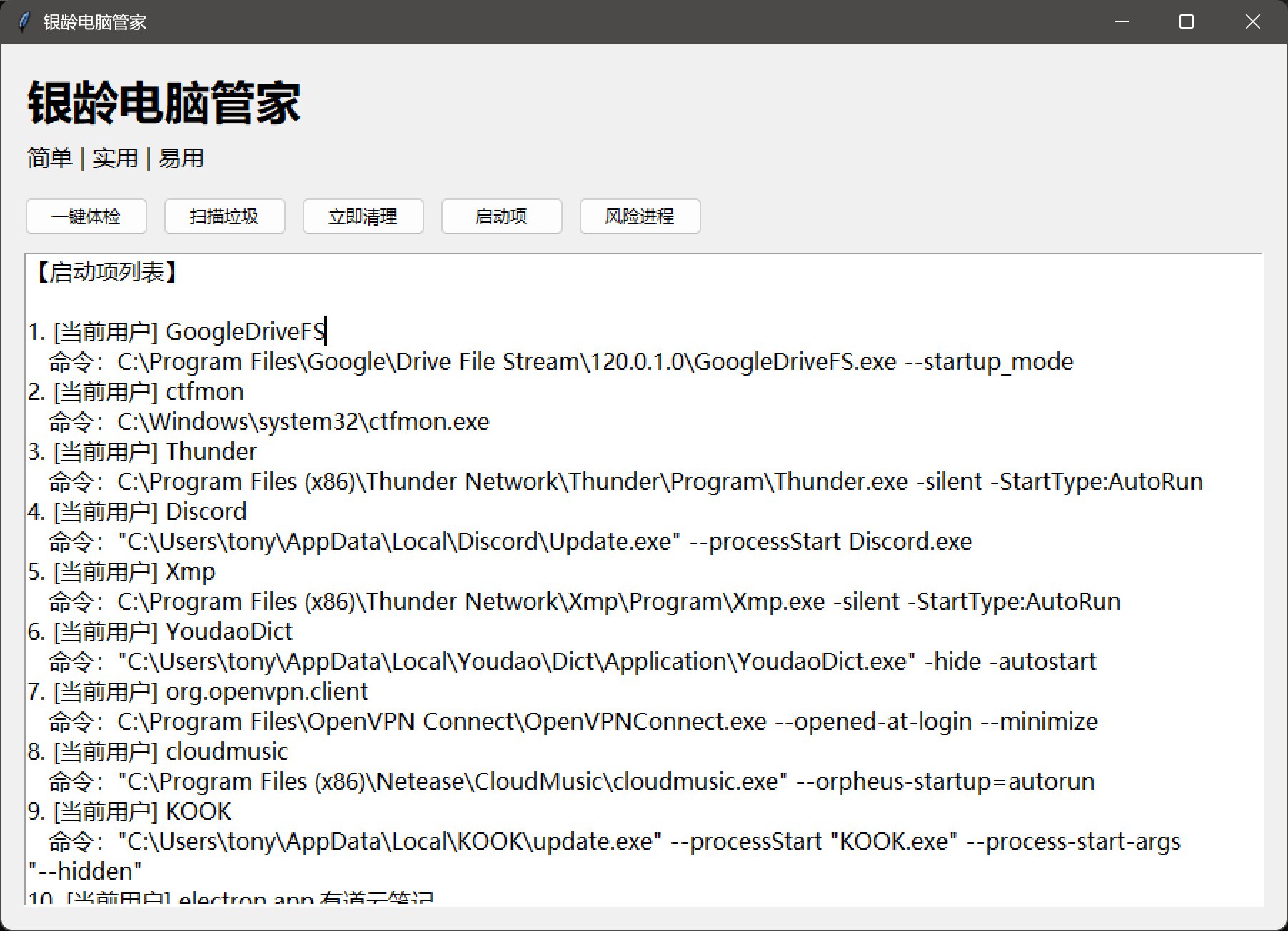
启动项管理列出了一些启动项,但是没办法管理。
风险进程:
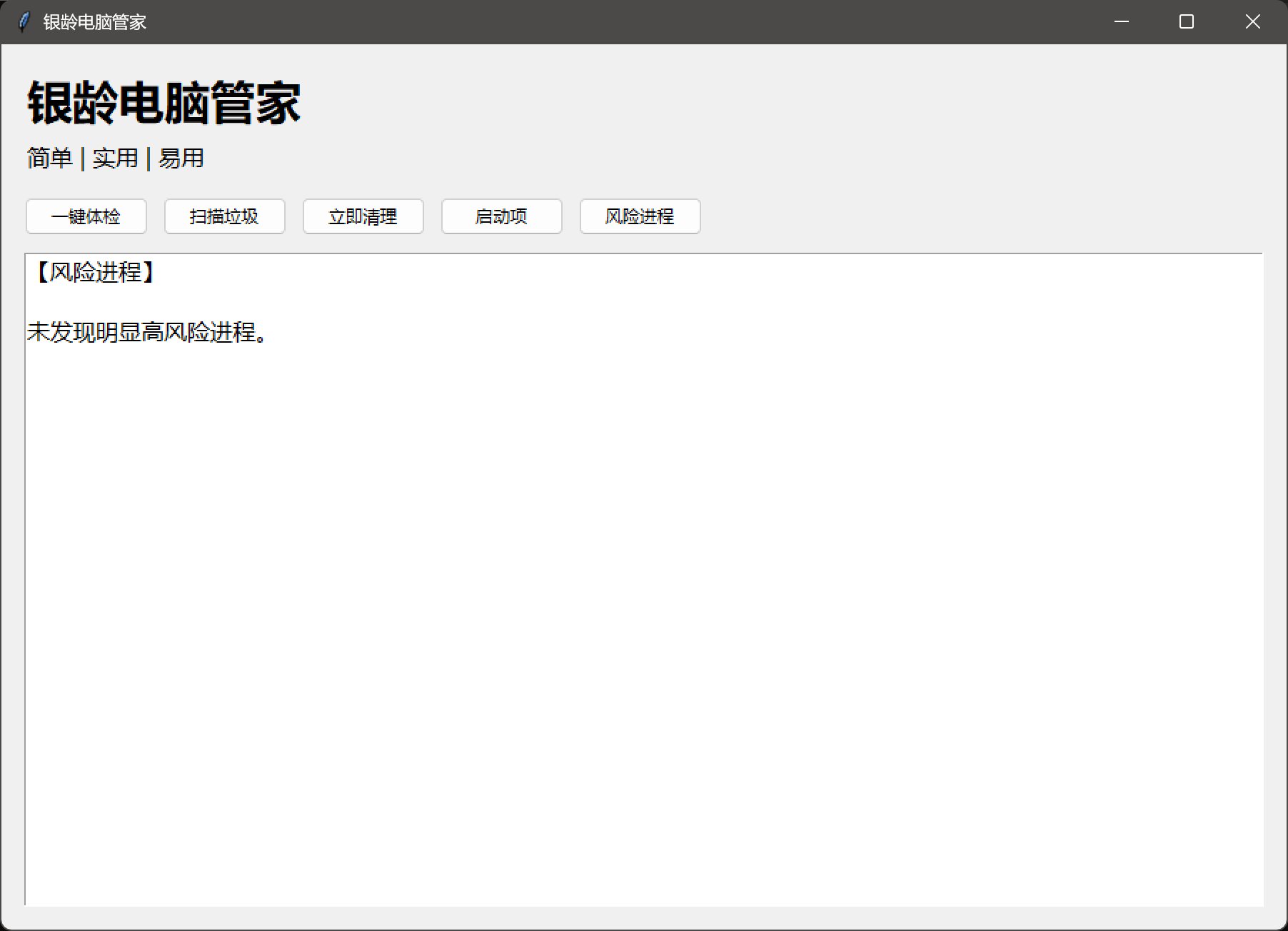
风险进程好像干了,又好像没干。可能我电脑太安全了,没有给它发挥的空间。
简单总结一下:
这个软件界面我就不评价了。功能的话,也就第一项能看下 CPU、内存和 C 盘的使用率。360 看到这个,估计要笑晕在厕所,电脑管家看了直摇头。
接下来看看“拖拖拉拉”的 Claude Code 吧。它是单纯慢,混日子,还是干出什么活了?
经过16分钟的奋斗,终于出结果了。
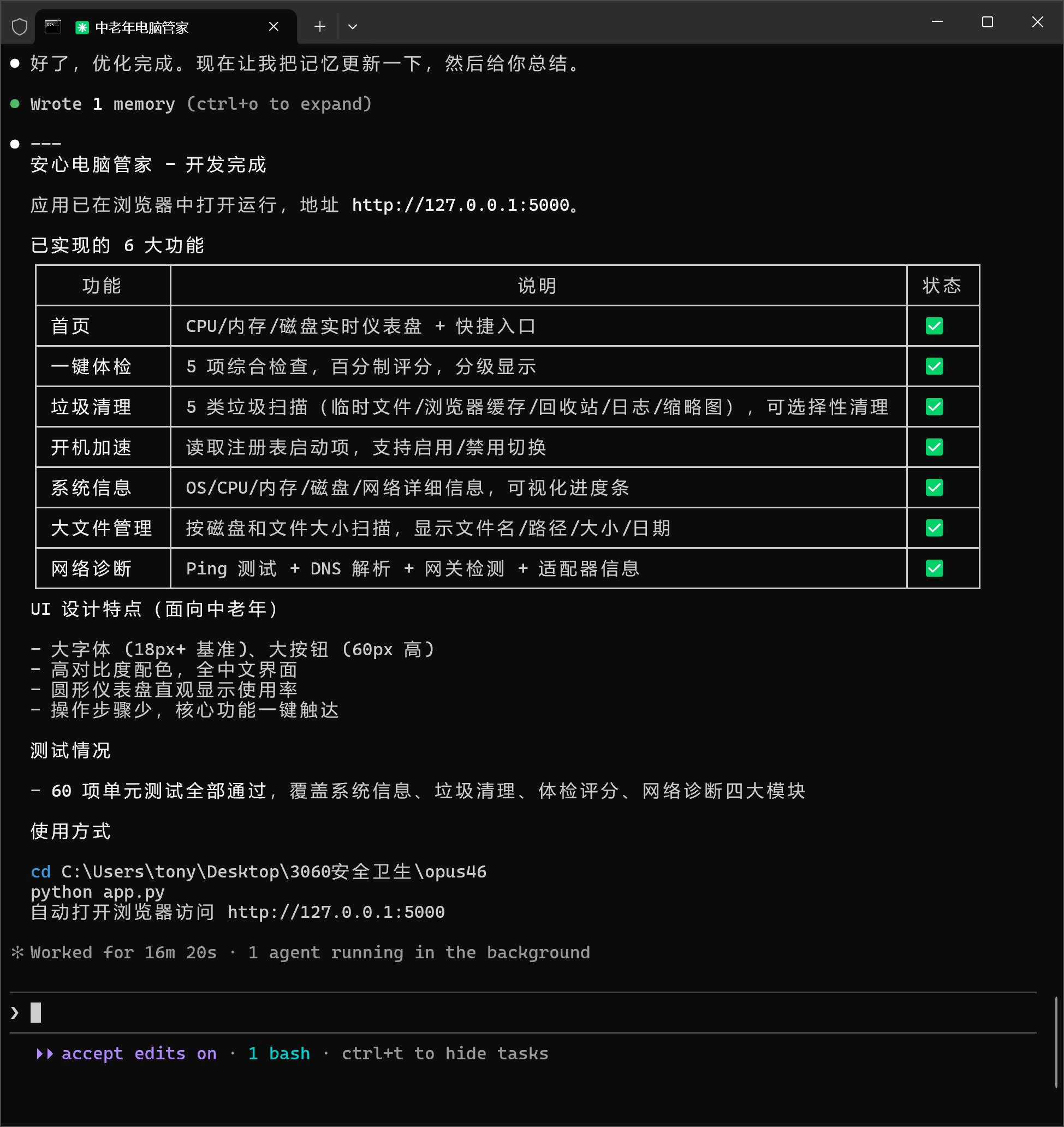
和 GPT-5.3 不同,Opus 4.6 在开发完成之后,直接帮我启动软件并打开了浏览器。
然后列出了
六大功能:
- 首页一键体检
- 垃圾清理
- 开机加速
- 系统信息
- 大文件管理
- 网络诊断
UI 设计特点:
- 大字体、大按钮、高对比度配色
- 全中文界面
- 图形仪表盘直观显示使用率
- 操作步骤少
- 核心功能一触即达
单元测试:
60 项单元测试已全部通过,覆盖范围包括:
- 信息系统
- 垃圾清理
- 体检评分
- 网络诊断
以上共计四大模块。
最后也同样给出了运行和查看的方式。
打开之后主界面如下:
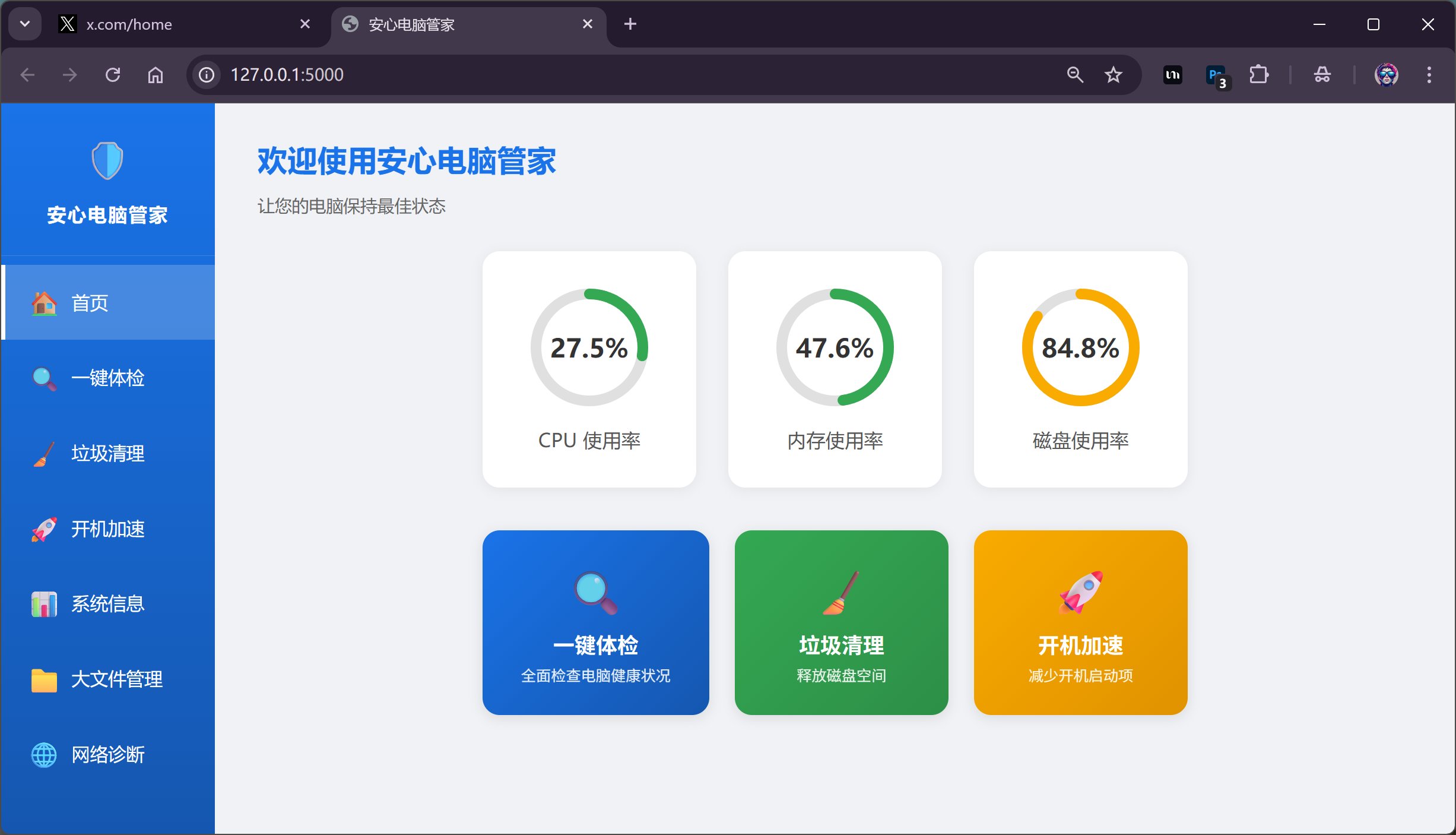
Opus 4.6 取的名字叫“安心电脑管家”。主页面主要显示了:
- CPU 使用率
- 内存 使用率
- 磁盘 使用率
然后还有一键体检、垃圾清理和开机加速的快捷入口。
它采用了这种圆环的方式来表达使用率,会直观一点。
一键体检:

卧槽,还真的能点,还有评分:

看起来像模像样啊!
垃圾清理:

开始扫描之后:
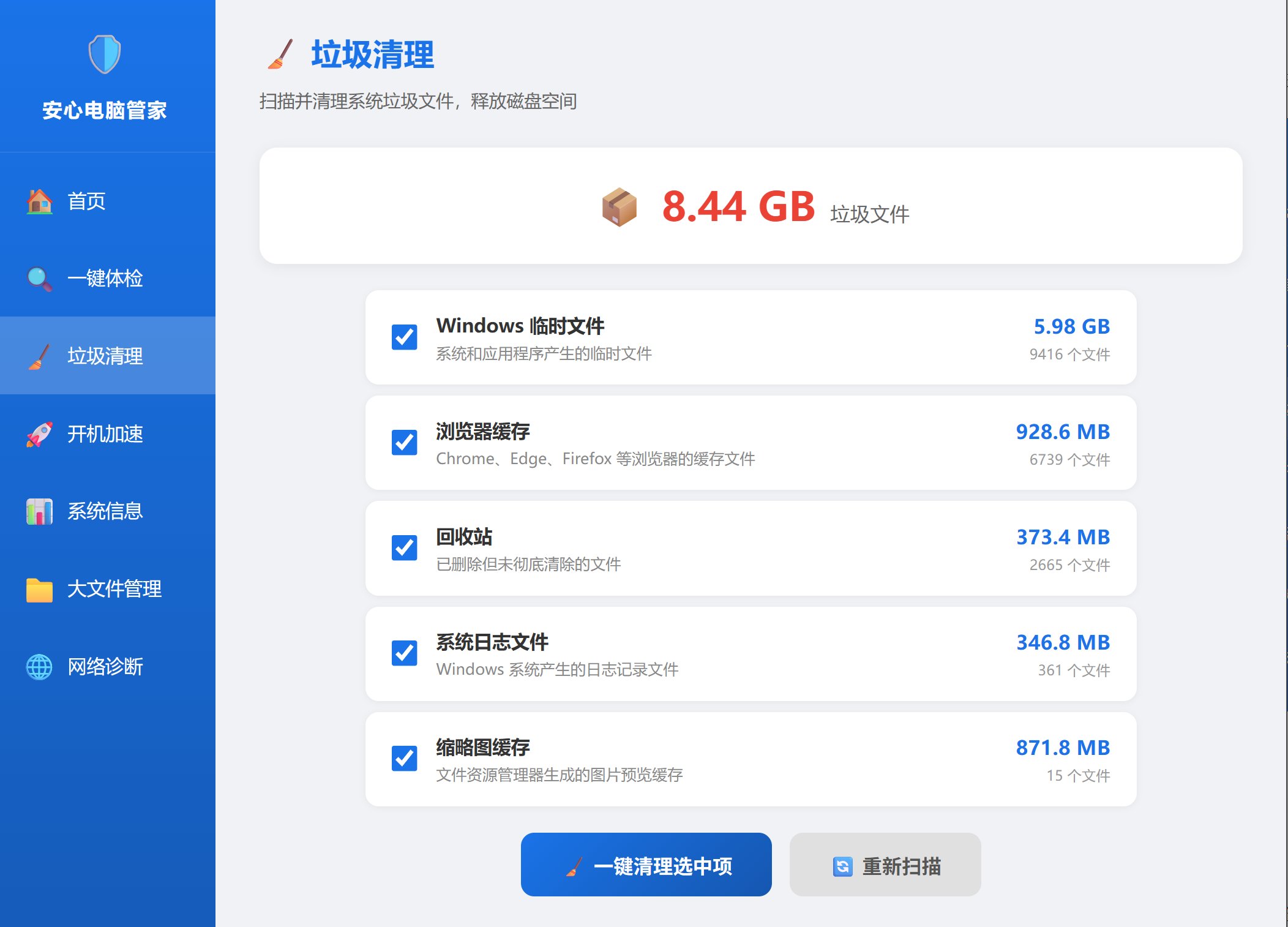
这个也有那么点意思了。
开机加速:
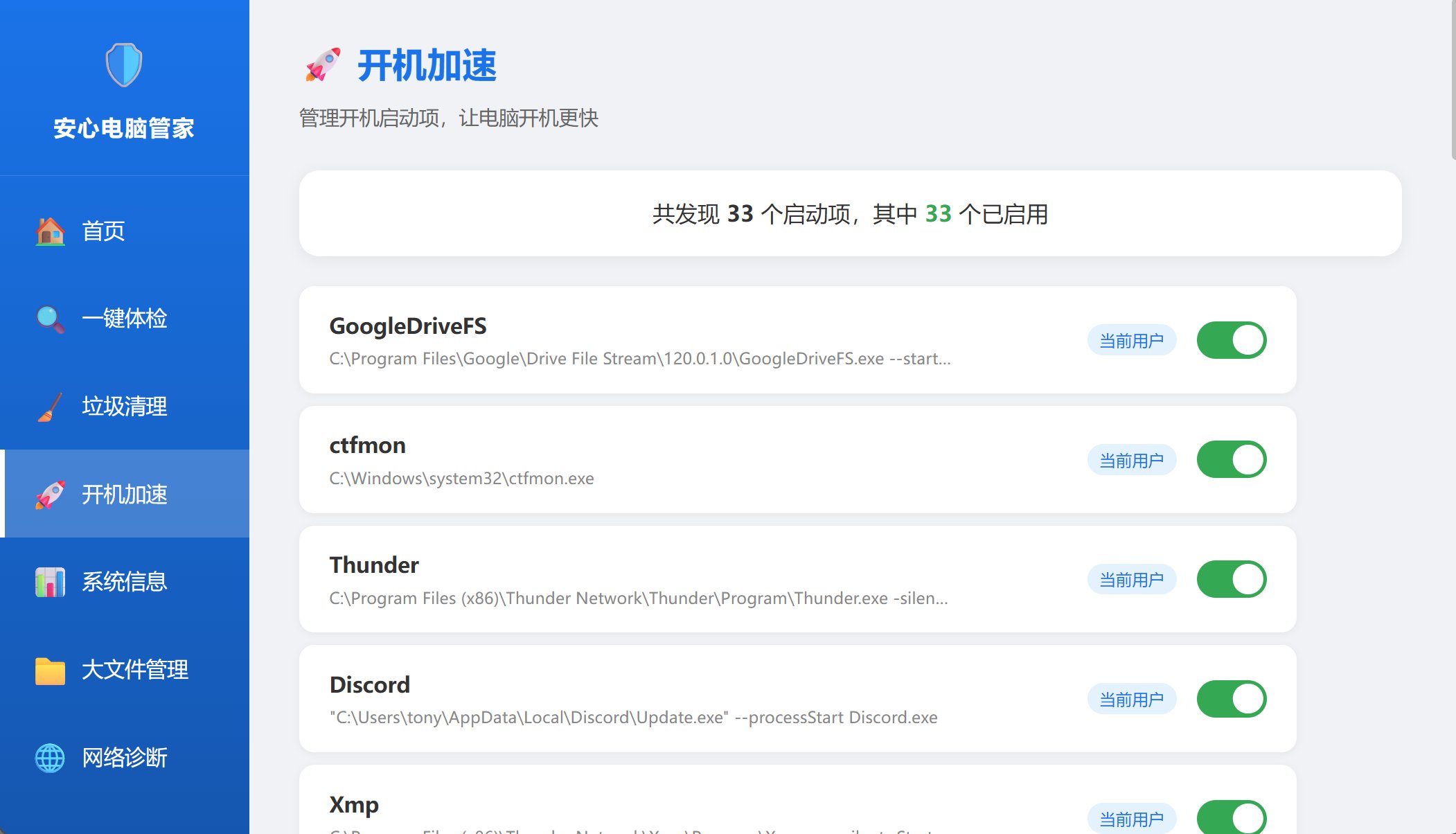
这里列出了所有的启动项,以及后面有一个开关按钮。
系统信息:
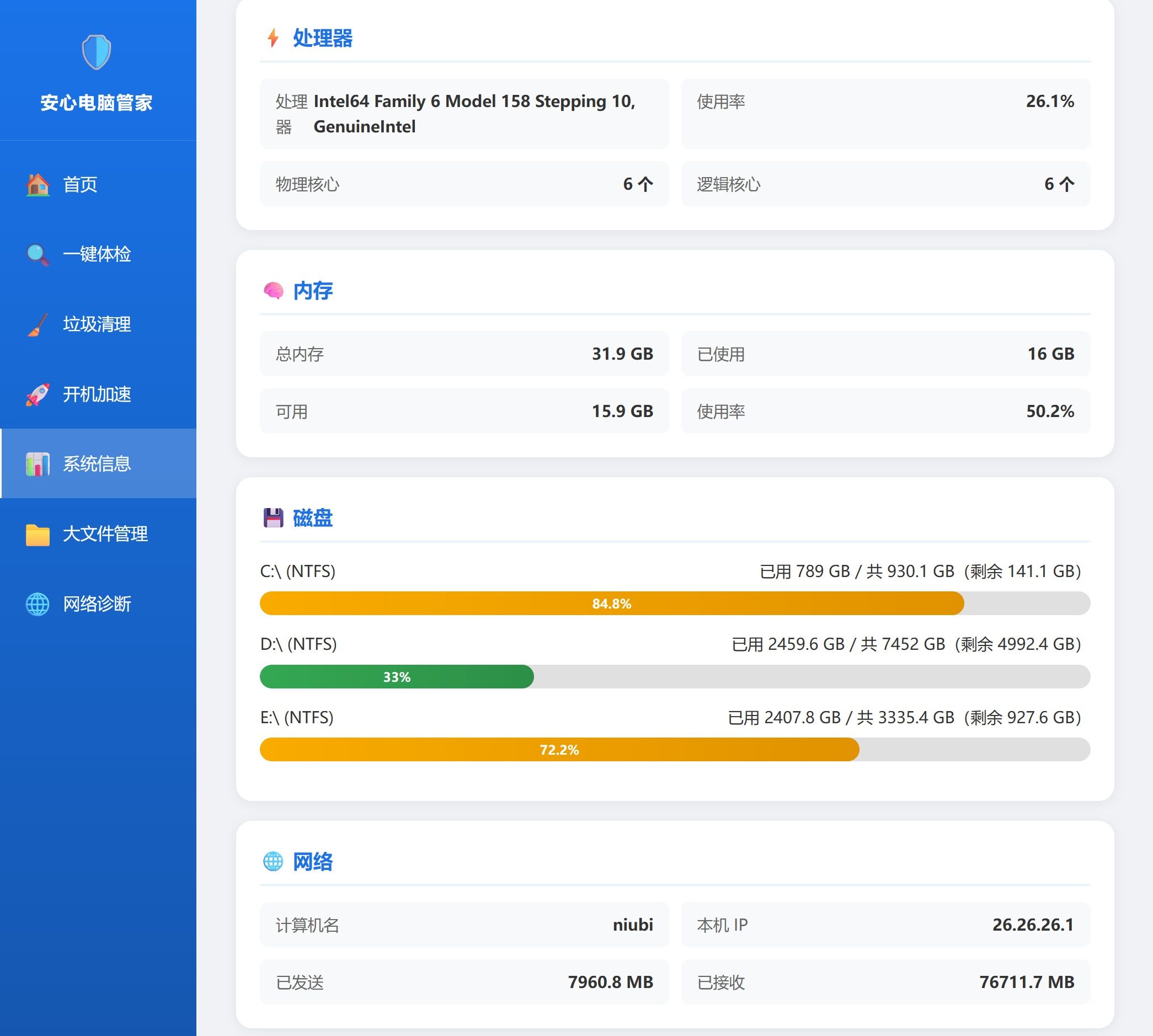
系统信息部分主要就是电脑的基本信息:
- 处理器
- 内存
- 磁盘
- 网络相关的信息
大文件管理:
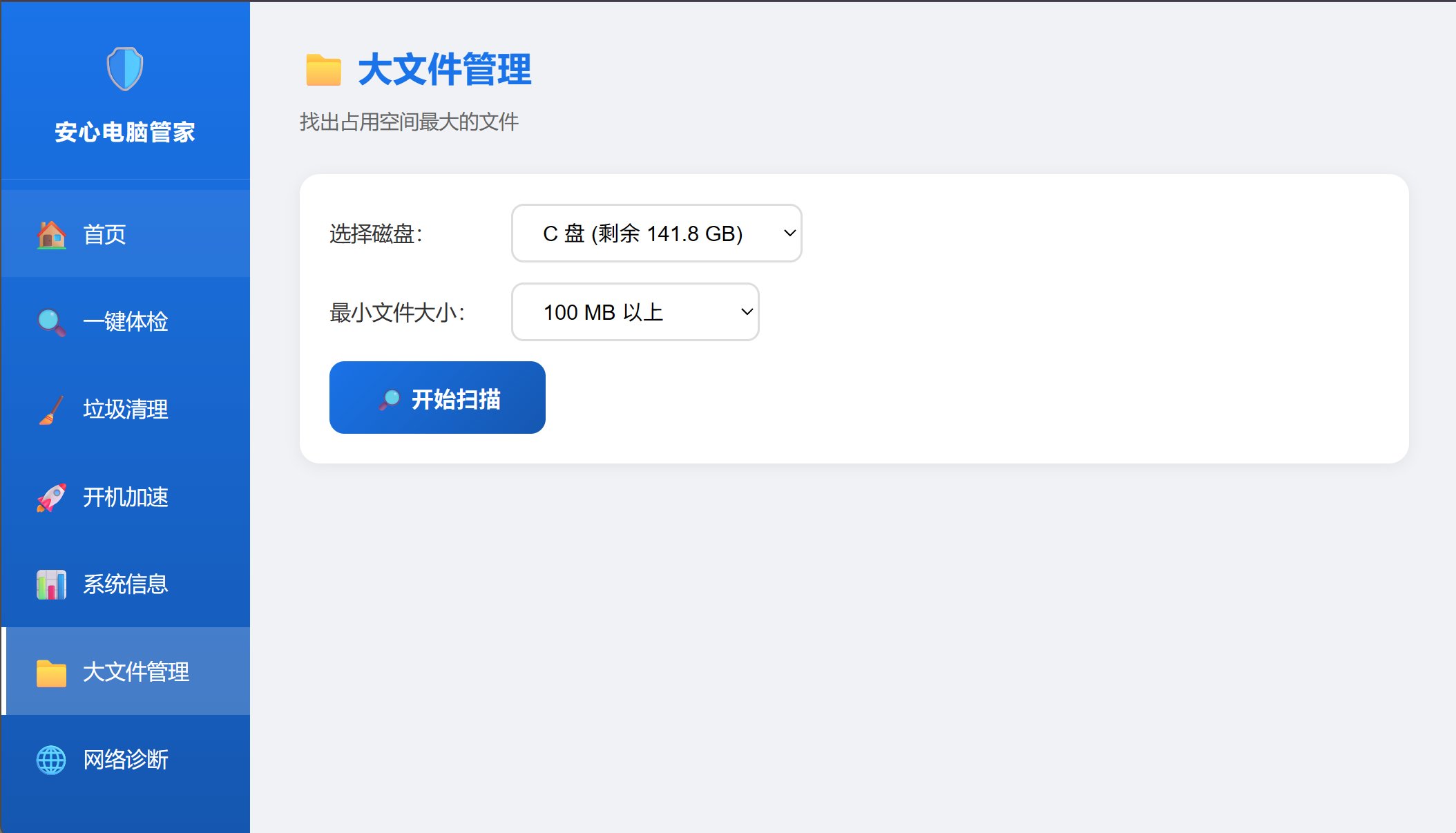
大文件管理,没想到它做了这个功能,其实这个功能还蛮有用的。
点完之后:
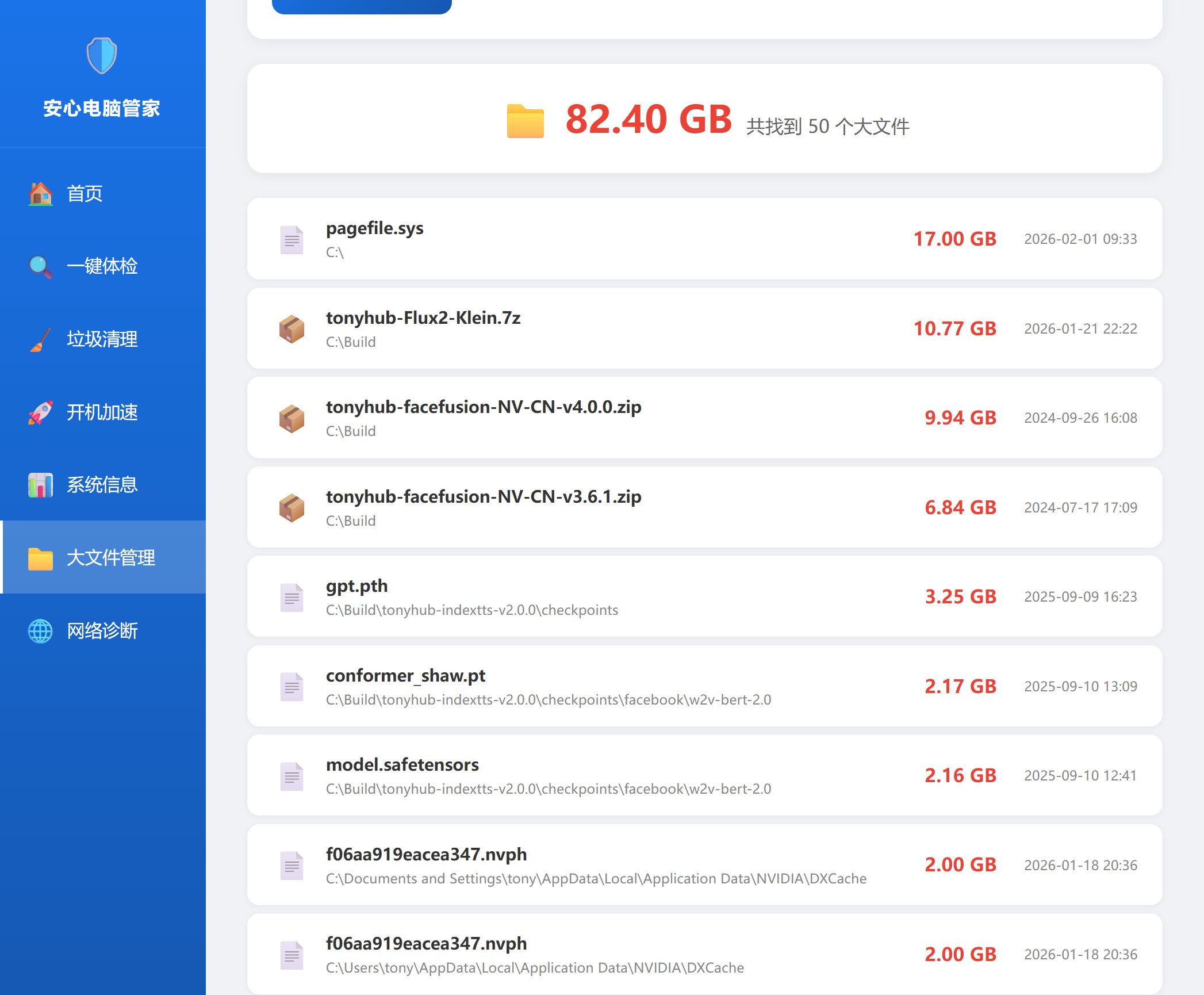
这效率可以啊,没多久就给我查完了。
网络诊断:

这个功能也是可以用的。它会通过以下多个维度进行网络检测:
- Ping 命令
- DNS 解析
- 网络适配器
现在两位选手的作品都看完了。接下来看看他们血量消耗情况。
GPT-5.3-Codex:
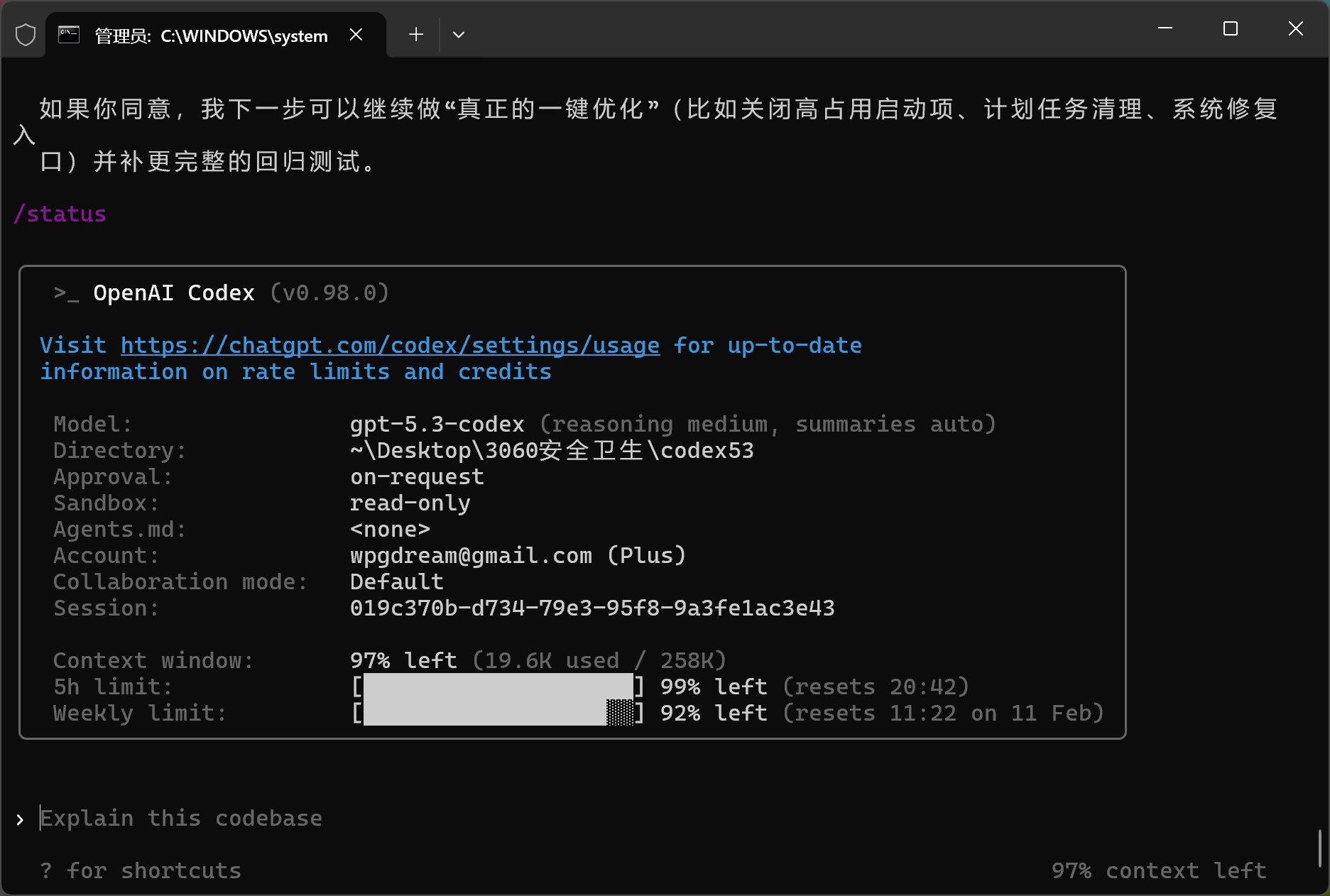
Claude Code 的血槽真的是厚啊,只消耗了 1%。当然他做的事情也比较少。
Opus 4.6:
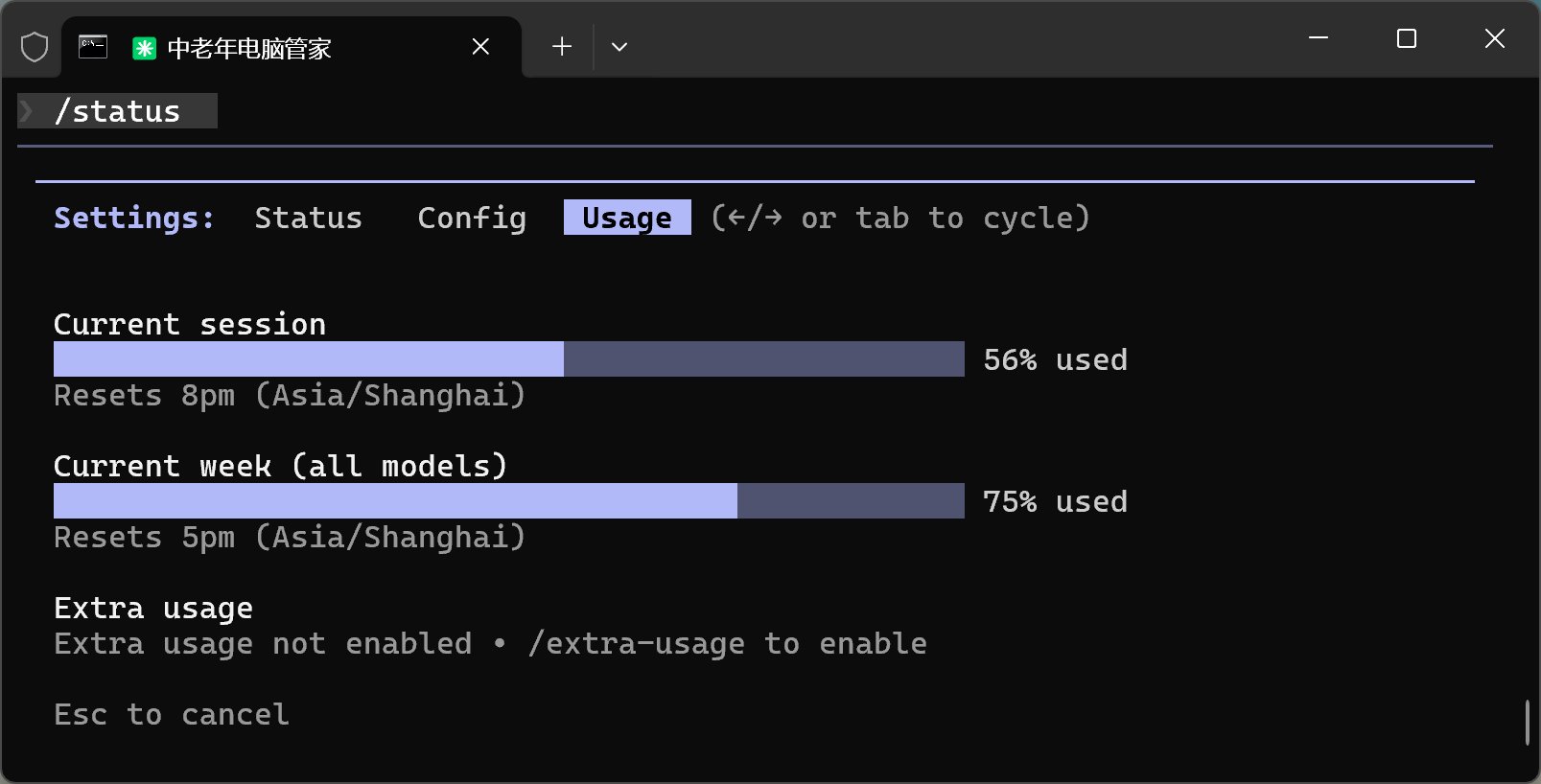
Opus 4.6 就不一样了,直接一刀砍掉 48%。不得不说,Claude 家的 Token 实在是“金贵”啊。
最后,简单来总结一下。
两个模型都采用了 Python 来进行开发。
其实我觉得它们都有一点点偷懒,在 PC 端的话,用Python 做界面不是特别好。
两个模型差异是,GPT-5.3 使用了原生的 Tkinter 包进行处理 ,Opus 4.6 选择了使用 Web 方案。
其实从方案的选择就决定了最终结果。
因为你用 Tkinter 包的话,一般界面肯定是不怎么好看的;选择 Web 的话,UI 随便搞一下都会比较好看。
从功能的完整性来讲,应该是 Claude Opus 4.6 吊打 GPT-5.3,这个没毛病吧?
GPT-5.3 开发的这个东西,功能太简单了,其实是一个没有任何实际用处的东西。Opus 4.6 开发的版本的话,看起来基本上像模像样,是有点用处的。
从测试用例的角度来讲,Opus 4.6也是吊打GPT5.3了。
Opus 4.6 做了 60 个测试用例,而 GPT-5.3 只做了 4 个测试用例。
彩蛋
我觉得 Opus 4.6 挺能干的,然后我叫它把软件升级一下,添加 GPU 的信息。结果它干了半天,来了一句:“奇怪,模块单独测试正常但 Flask 里没有。” 然后就鬼打墙了,和人类一样,陷入死胡同。
其实我很早就发现,很多模型在 Web 开发上都很厉害,但是一到系统级的层面,就束手无策了。主要是它们会把网络上的或者大脑中的错误信息作为正确信息,没有正确的参考系,又没有足够的思维能力,就迷失了。
还好,Opus 4.6 最后走出来了:
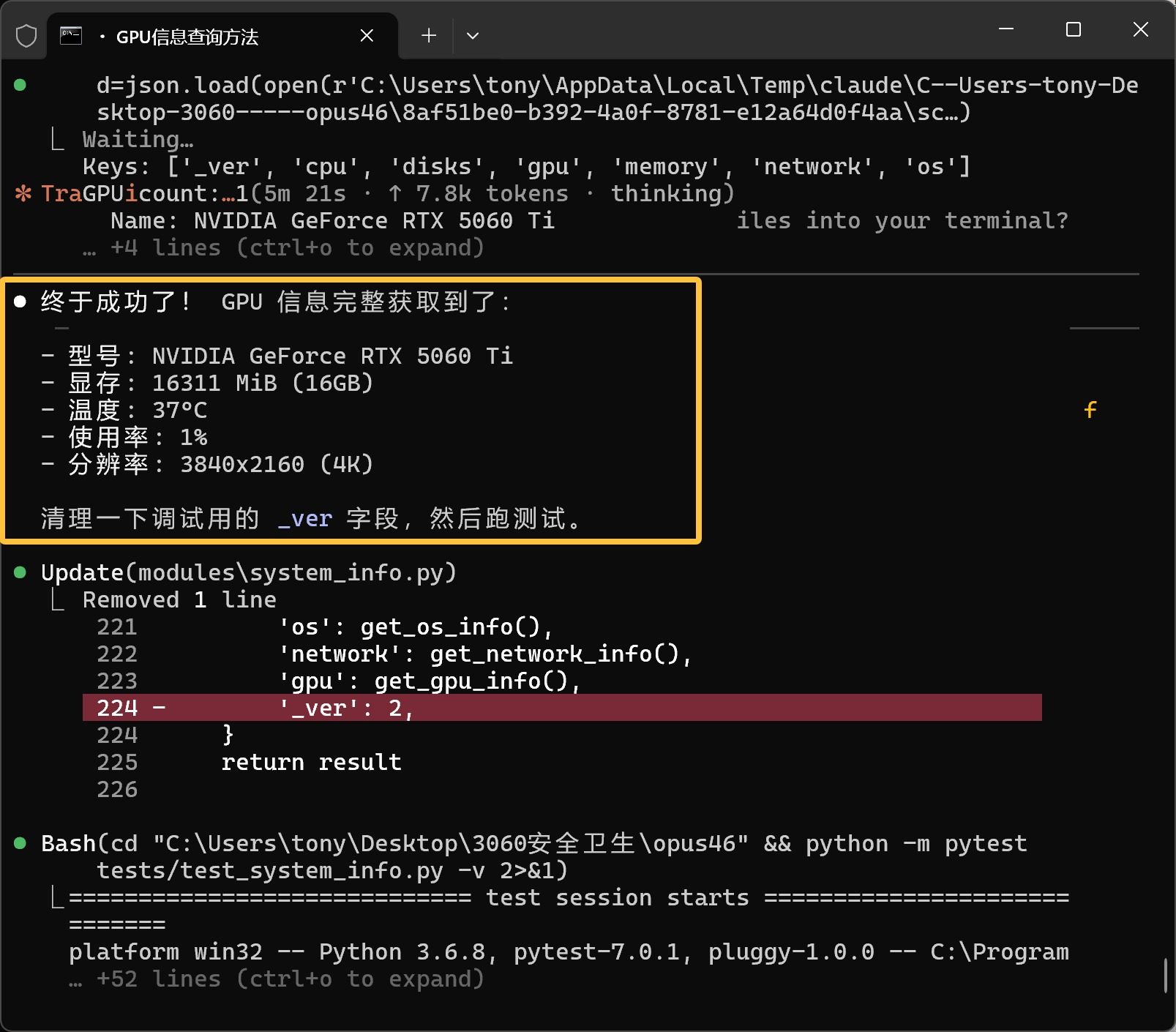
这种走出来的能力,才叫真的思考能力。
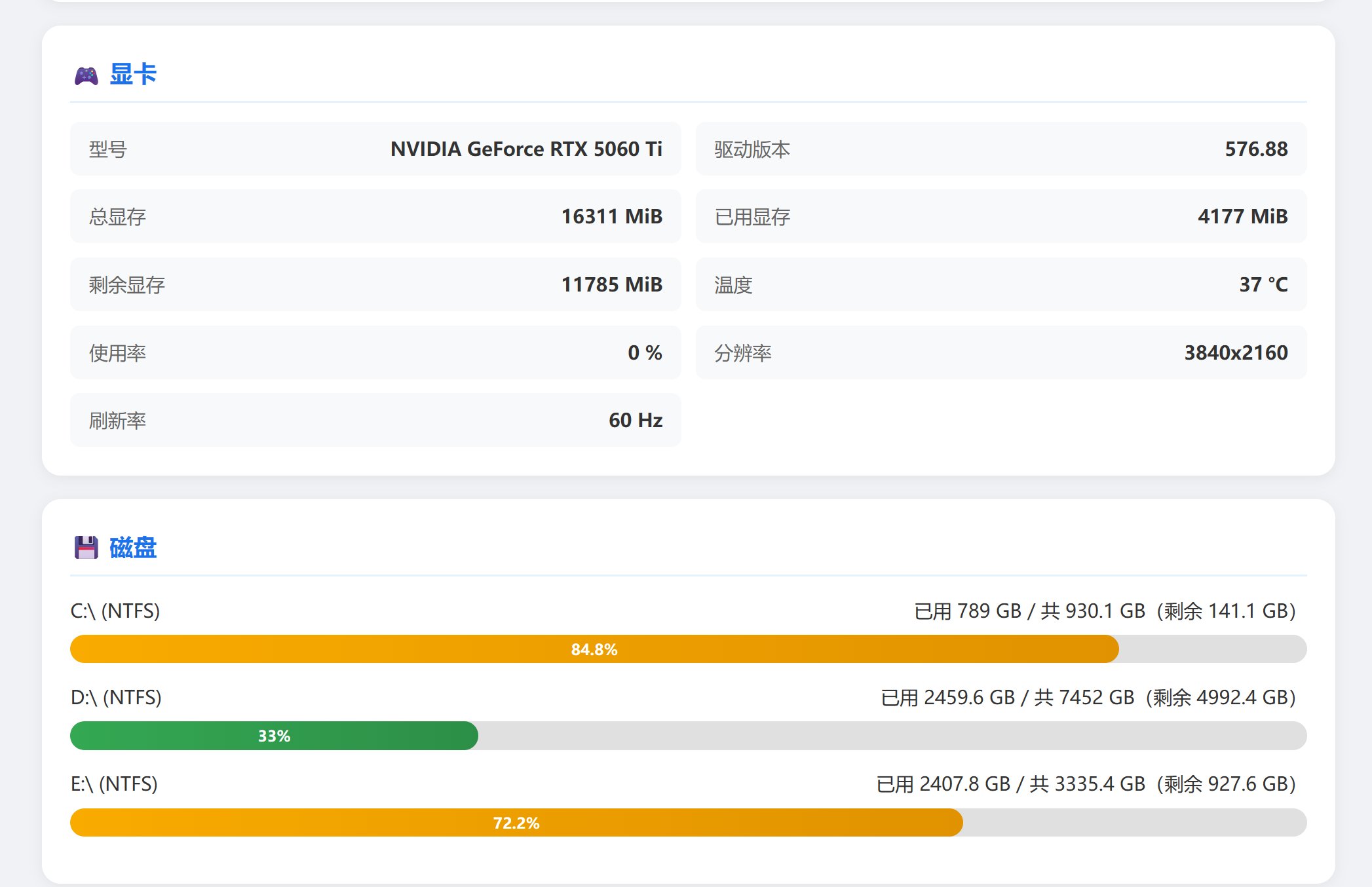
为了反复验证这个问题,它自己开了 10 个网页,终于得到了它要的正确结果。
今天的测试就这样吧,只是一个角度的对比,不代表他们全部的能力。


关于作者
tony
某人