声音克隆:IndexTTS2离线运行包和使用方法!
上一篇已经讲了IndexTTS2的本地安装方法。说实话,这个配置起来,还是有一点点困难的。所以我说过会出一键运行的离线包,也可以叫懒人包。 其实我一直不太喜欢叫懒人包,这样会让人变懒哈。
IndexTTS2涉及到的模型有点多。官方分享的模型如下:
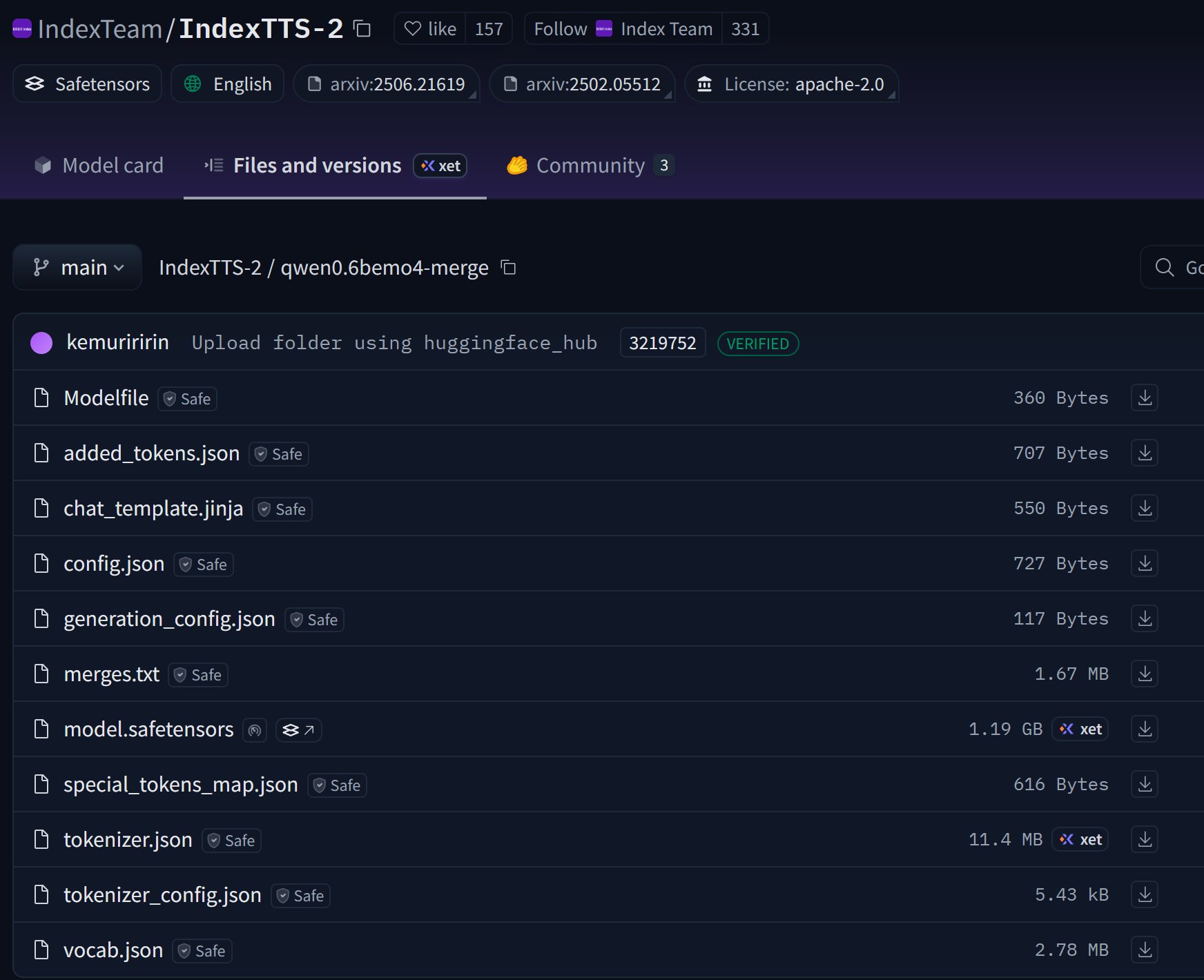
除了这些模型之外,还有好几个模型是通过代码运行过程中下载的。这样就会有一个问题,不管你是否已经下载了,它都会先去Hugging Face上检查一下,导致没有魔法就会无法运行。还有,它默认是下载到C盘的,也是一个烦人的事情。
为了把这些问题解决掉,可以在本地离线一键运行,还是花了一些时间。
整体文件有十几个G,所以压缩、复制测试、上传都花了一些时间。
最后终于把所有东西集齐了。
文件已经上传到网盘,只要根据文末提示下载即可。
下面说一下如何使用。
下载之后放到一个比较大的硬盘上,右键解压到当前目录就可以了。
解压的时候不要用很辣鸡的RAR,它会占用C盘。
推荐使用免费、绿色的7z。
解压之后,打开文件夹,找到运行.bat
双击启动。
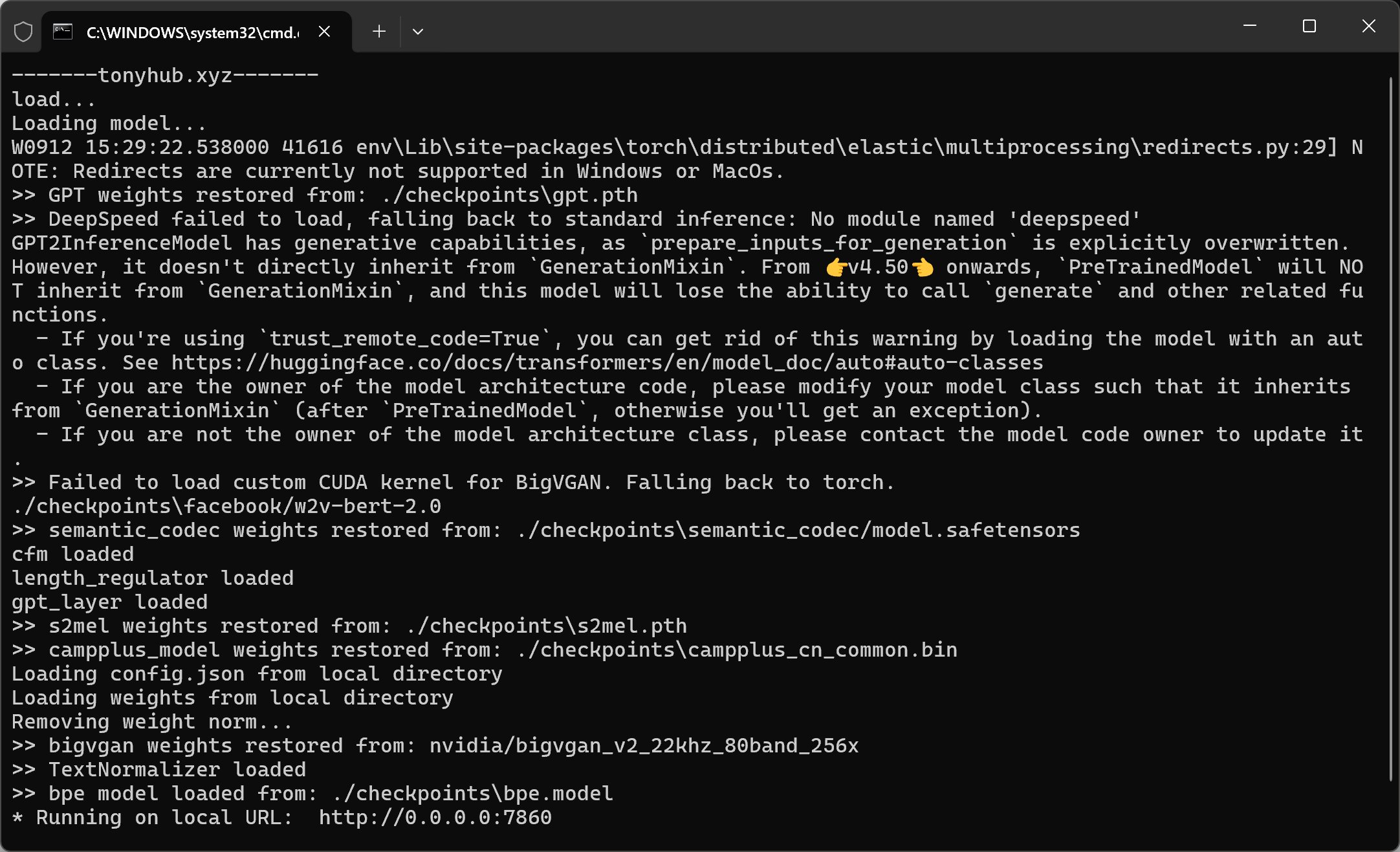
启动之后,会先显示一个load…这个时候开始载入Python。
然后会显示Loading model…这个时候开始载入相关模型。
最后出现Running on,说明服务已经启动成功!
原项目需要手动复制http://0.0.0.0:7860到浏览器打开,而且得把0.0.0.0改成localhost才可以。
我已经修改了,添加自动打开浏览器的参数。
打开页面之后,就可以进行声音克隆和合成了。
主要流程如下图:
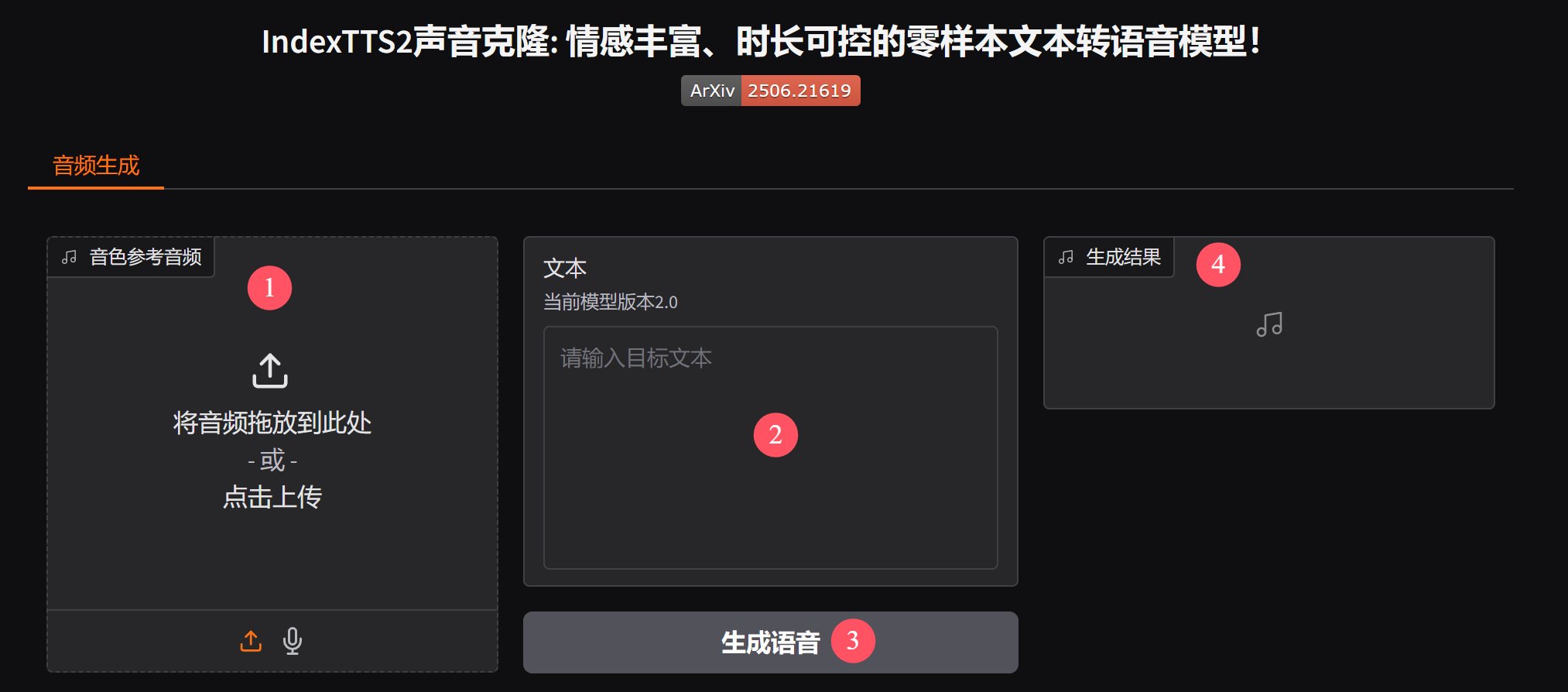
准备一个几秒钟的声音,最好是剔除背景音乐、背景声音、其他噪声。要剔除杂音提取人声,可以使用开源软件,也可以使用剪映。
然后就可以点击上传,或者直接把声音拖到1️⃣处了。
然后再2️⃣处输入你要它合成的内容。
然后再点击3️⃣开始生成语音。
最后在4️⃣处查看结果。
声音同时也会保存在outputs文件夹里面。
短句的合成时间一般不会太久,大概在几秒钟到十几秒的样子。
如果你显存比较小,可能就会爆显存,或者合成很慢。
还有一种快速体验的方式,就是使用自带的Example例子。
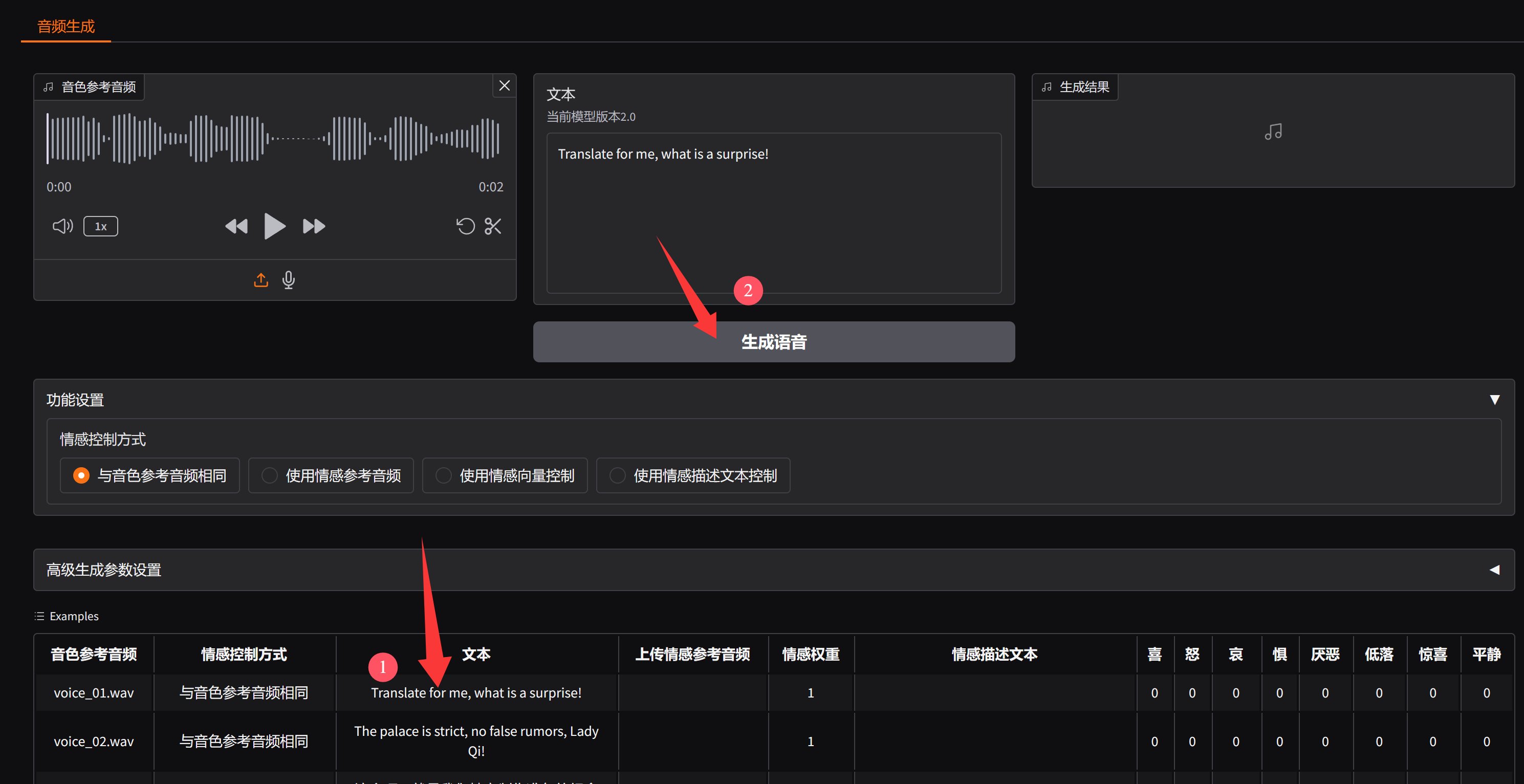
这个网页下方,自带了12个例子,通过这种方式,你就不需要急着去抠自己的声音了。
只需要点两次1️⃣2️⃣,就可以查看克隆效果了。
功能设置
除了直接生成之外,也可以通过功能设置来调整生成参数。
因为这个版本主打情感控制,所以功能设置主要就是针对情感控制,另外一个高级生成参数,不建议修改。
情感控制方式分为四种:
- 与音色参考音频相同
- 使用情感参考音频
- 使用情感向量控制
- 使用情感描述文本控制
与音色参考音频相同
这种模式最简单、最直观。只要上传参考音频就可以了。情绪从参考音频中获取。比如你上传的音频是高兴的,那么合成的声音也是高兴的。
这种应该是效果最好的。
使用情感参考音频
这种方式是让你提供另外一个声音,来做情绪的控制。
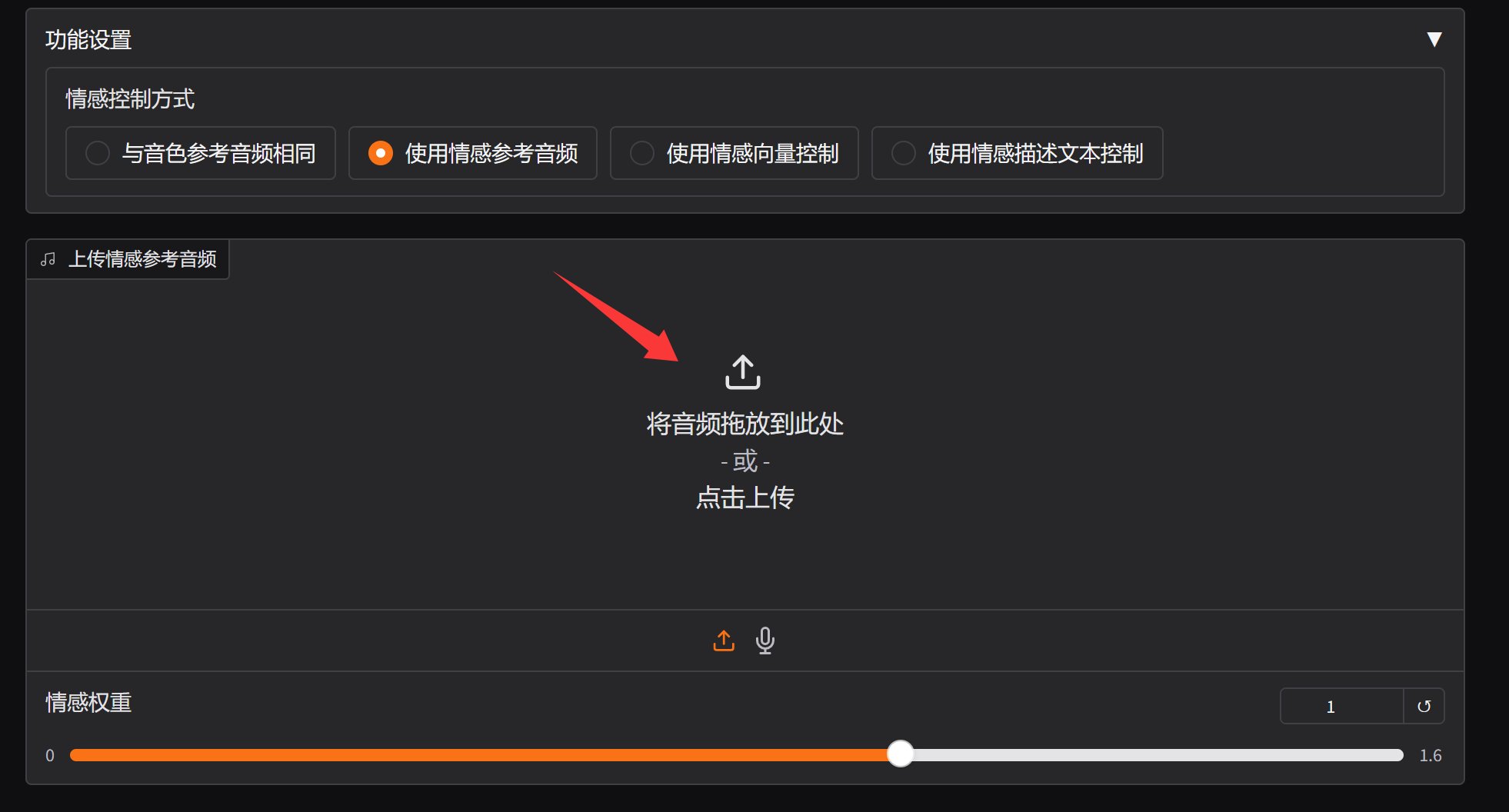
情感权重一般不动,粗略测试,应该数值越大影响越大,数值越小影响越小。
使用情感向量控制
这种方式就是可以多维度来控制情绪。

你想要愤怒,就把愤怒值拉大,你要是开心的情绪,就把喜的数值拉大。应该也很直观。建议同时只调整一种情绪。
使用情感描述文本控制
这是一种开放式的控制。既不参考声音,也不参考向量,而是靠你的描述。
这种方式发挥空间更大。
比如:
声音里既有压抑的痛苦,又夹杂着微弱的希望;开头带着些许悲伤和无奈,中段逐渐变得激动甚至有些愤怒,但在结尾又透出释然与温柔的安慰。整体表现出一种矛盾交织、内心挣扎但又逐步放下的复杂情感。
比如:
冷漠中带着讽刺
激动中掺杂焦虑
喜悦里透着怀疑
上面的内容,仅供参考,主要就是说这个发挥空间大。
此刻,我脑子里一直在想”五彩斑斓的黑”
IndexTTS可以说是把情绪控制玩出了花,这个很好。目前加了情绪控制之后,相似度会减弱,但是情绪还比较饱满的,用来做各种配音应该挺好的!



关于作者
tony
某人