Wan2.2 动作同步和角色替换配置记录
接上一篇,ComfyUI 安装已经搞定了,Wan 的基础工作流也搞定了。今天我们来搞一搞 Wan2.2 animate。
这是阿里在 2024 年 9 月 19 日推出的模型,也是玩的人最多的模型。
Wan2.2 animate 采用了统一的角色动画和替换框架,可以实现精确的动作和表情复制。
模型亮点如下:
- 双模式功能:单一架构同时支持动画和替换功能,可轻松实现操作切换。
- 先进的身体运动控制:使用空间对齐的骨骼信号进行精确的身体运动复制。
- 精确的动作和表情:准确再现参考视频中的动作和面部表情。
- 自然环境融合:将替换的角色与原始视频环境无缝融合。
- 流畅的长视频生成:迭代生成确保长视频中运动和视觉流畅一致。
它的主要功能是动作同步和角色替换。
这两个概念听着可能有点迷糊,我做一个简单的解释:
| 模式 | 输入 | 输出 | 主要用途 |
|---|---|---|---|
| 动画/动作同步(Animate) | 静态角色图片 + 驱动视频(含动作/表情/镜头) | 生成一个新视频:你的角色根据驱动视频里的动作/表情 “演” 出来 | 当你已有一个角色形象(例如你设计好的人物、游戏角色、品牌吉祥物)想让其 “表演” 某个动作/镜头逻辑时用 |
| 角色替换(Replace) | 目标视频(已有演员/角色在场) + 你想替换的角色图片 | 输出一个新视频:场景镜头、镜头运动、环境都保留,但主体角色被你的角色替换 | 当你想用你设计的角色 “替代” 现有视频中的角色(换脸、换角色、换品牌代言人)时用 |
简单来说,比如有一个唐尼演讲的视频。
动作同步,就是可以让照片中的你学习唐尼的口型和动作。
角色替换,就是直接把视频中的人换成你,你会同步唐尼的口型和动作。
第二种会比较好玩,第一种在某些场景会比较实用。
我目前主要关注角色替换,所以这篇文章还是讲角色替换。
ComfyUI 官方内置了 Wan2.2 animate 的工作流,并且有官方教程。所以今天就是根据官方教程把官方工作流跑起来。
概念讲完了,开干。
启动软件
首先点击 run 启动软件。
打开工作流
找到并打开工作流。
下载模型
打开工作流的时候会弹出提示信息,这里显示了所有需要而没有的模型。只要点击下载按钮下载即可。
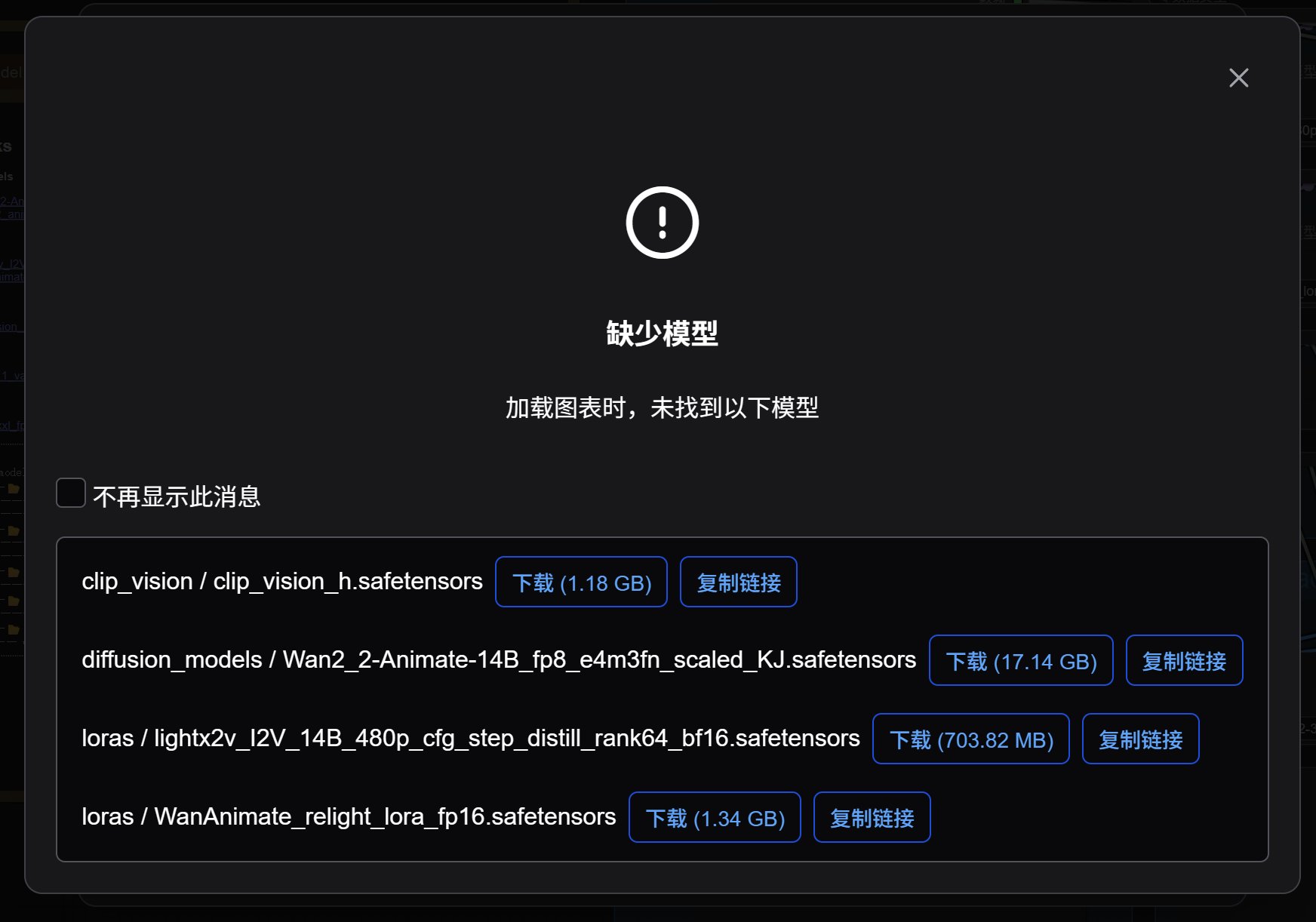
有一些模型我们已经在上一篇中下载了,这次主要用的是四个模型。下载的时候需要网络通畅,可以直接下载,也可以用迅雷等加速下载。
模型的放置路径:
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── Wan2_2-Animate-14B_fp8_e4m3fn_scaled_KJ.safetensors
│ │ └─── wan2.2_animate_14B_bf16.safetensors
│ ├───📂 loras/
│ │ └─── lightx2v_I2V_14B_480p_cfg_step_distill_rank64_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├───📂 clip_visions/
│ │ └─── clip_vision_h.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors
不同模型的作用如下:
| 模型路径 | 功能作用 | 说明 |
|---|---|---|
| clip_vision_h | 🔍 图像特征提取模型 | 负责读取你输入的图像(角色图、驱动视频帧等),把视觉内容编码成向量特征,用于后续生成模型理解。是 OpenCLIP 的高精度版本(h 代表 high quality)。几乎所有 Animate 流程都需要它。 |
| Wan2_2-Animate | 🧩 核心视频生成模型 | 这是 Wan 2.2 Animate 的主体 Diffusion 模型,14 Billion 参数量,负责从时序潜空间生成视频帧。fp8 表示 8 bit 浮点精度,节省显存。 |
| lightx2v | 🔦 动作同步辅助 | 专门用于动作驱动、时序平滑、减少”抖动感”。即让角色的动作更自然连贯。I2V = Image to Video。 |
| WanAnimate_relight_lora | 💡 光照匹配 | 主要用于”角色替换模式”下的光照与环境匹配。让替换后的角色皮肤、盔甲、阴影与原视频环境融合自然。fp16 代表 16 bit 精度。 |
放好模型之后,重启软件或者重新打开工作流。
安装节点
这个时候又会遇到另外的问题,也是一个非常常见的问题——节点丢失。
ComfyUI 是个开源工具,有各种各样的第三方节点。所以在使用复杂工作流的时候,安装节点是一个很头大的问题。
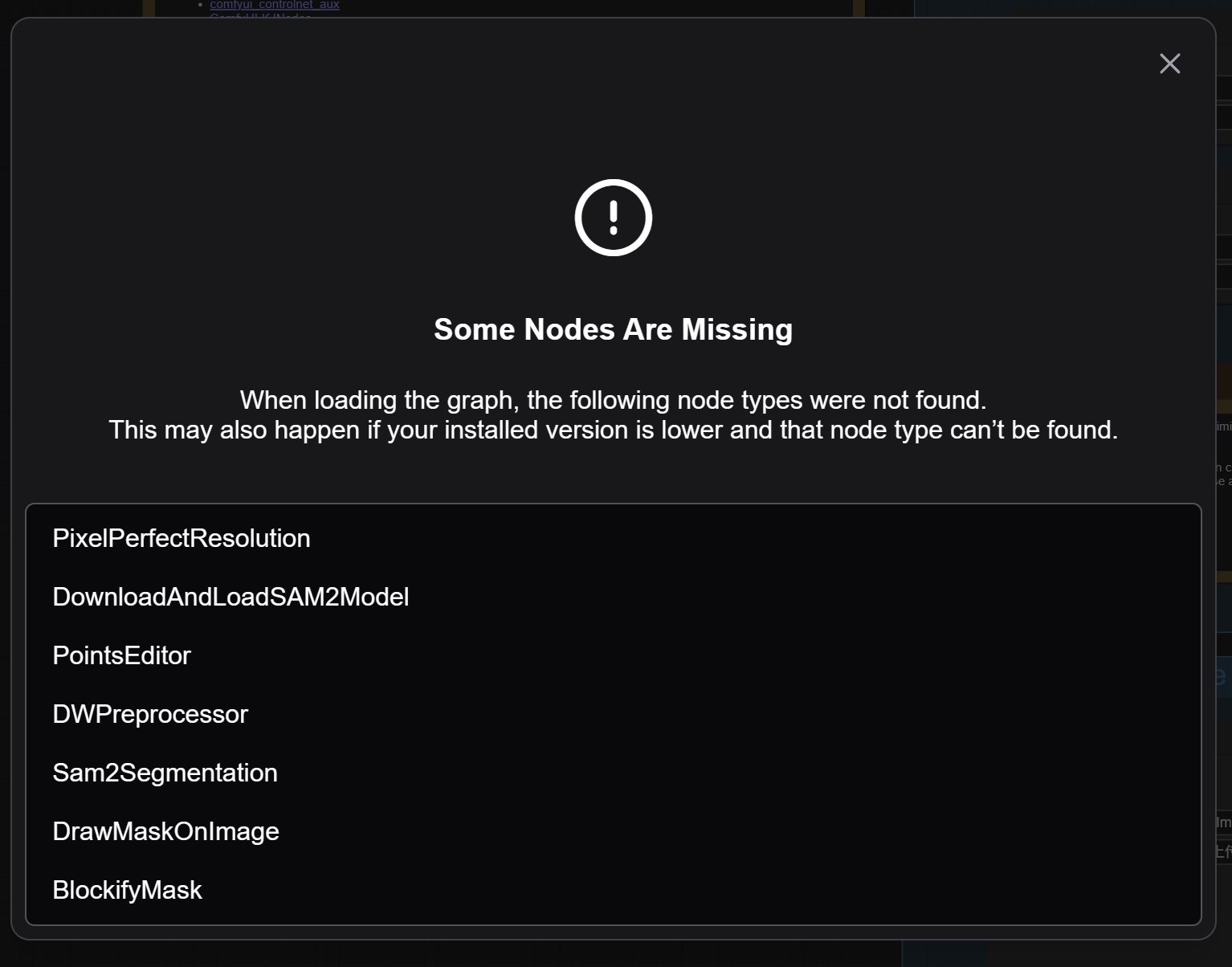
上面提示了好多节点,光看这些名字,可能无法直接关联到具体的节点插件。
根据 ComfyUI 官方教程的提示,主要涉及下面的两个节点插件:
然后我们只需要去 ComfyUI Manager 里面搜索并安装这些插件就可以了,更加简单的方式是直接使用 ComfyUI Manager 的安装丢失节点功能。
ComfyUI 默认不带节点管理器 ComfyUI Manager,需要自己安装。
安装命令如下:
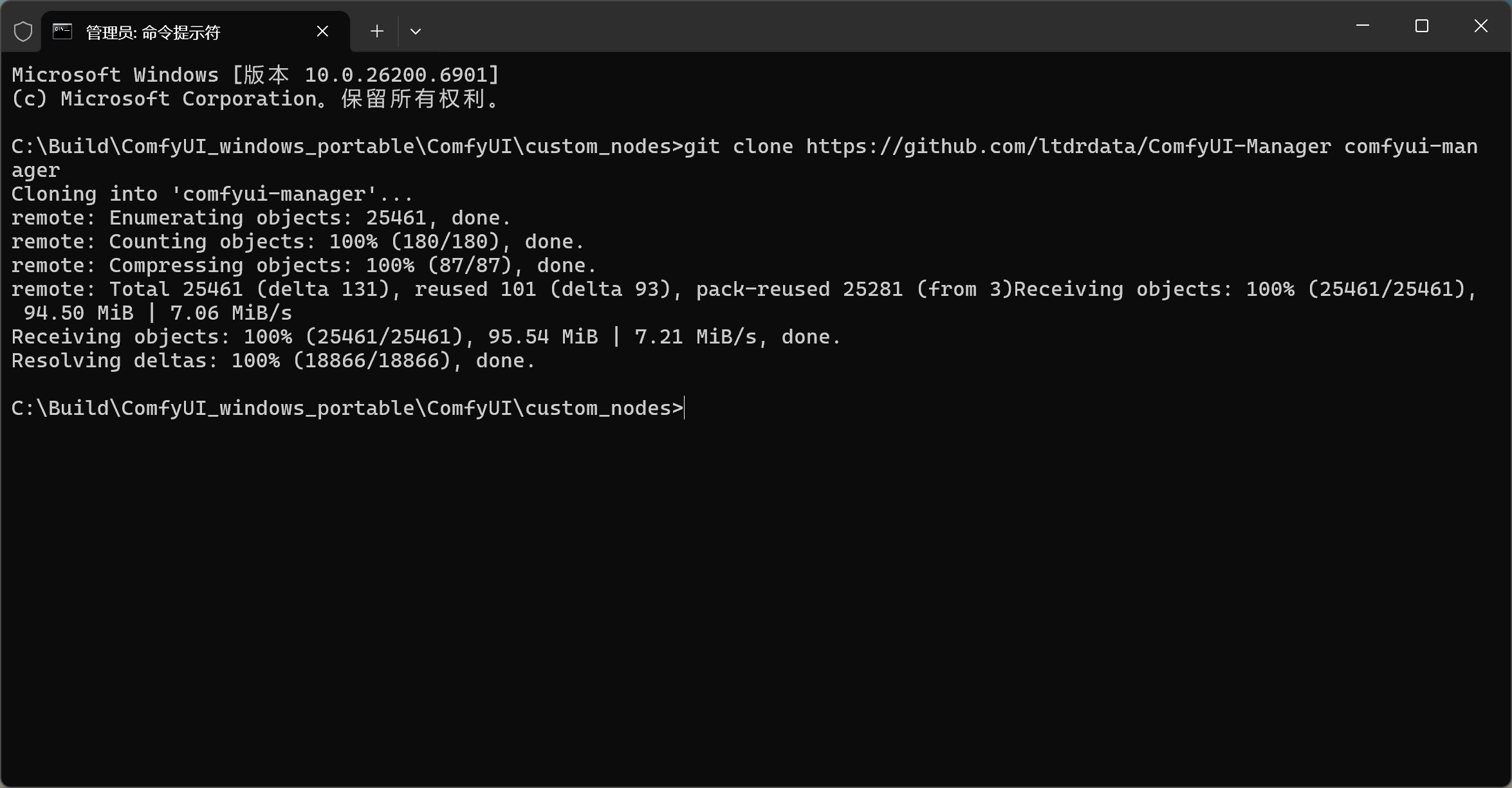
安装方法大致是,打开自定义节点文件夹->右键在终端中打开->输入 Git 命令。
等命令执行完成,重新启动 ComfyUI 就可以了,启动过程中会自动安装依赖并载入管理器。
启动成功之后,就可以在界面上看到节点管理器的工具条了。
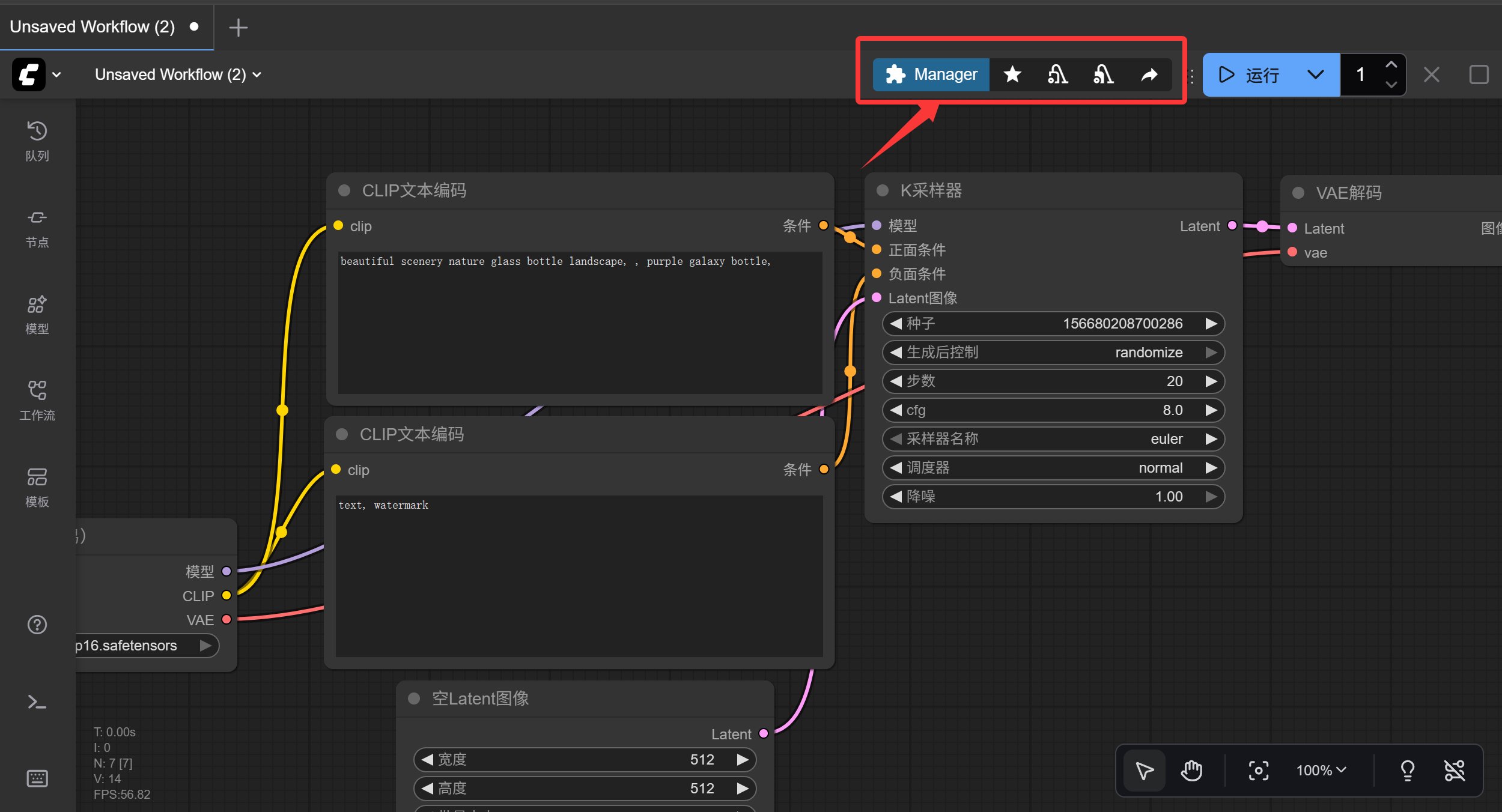
点击 Manager 就可以管理各种自定义节点了。
弹出窗口中选择自定义节点管理或者安装丢失自定义节点。
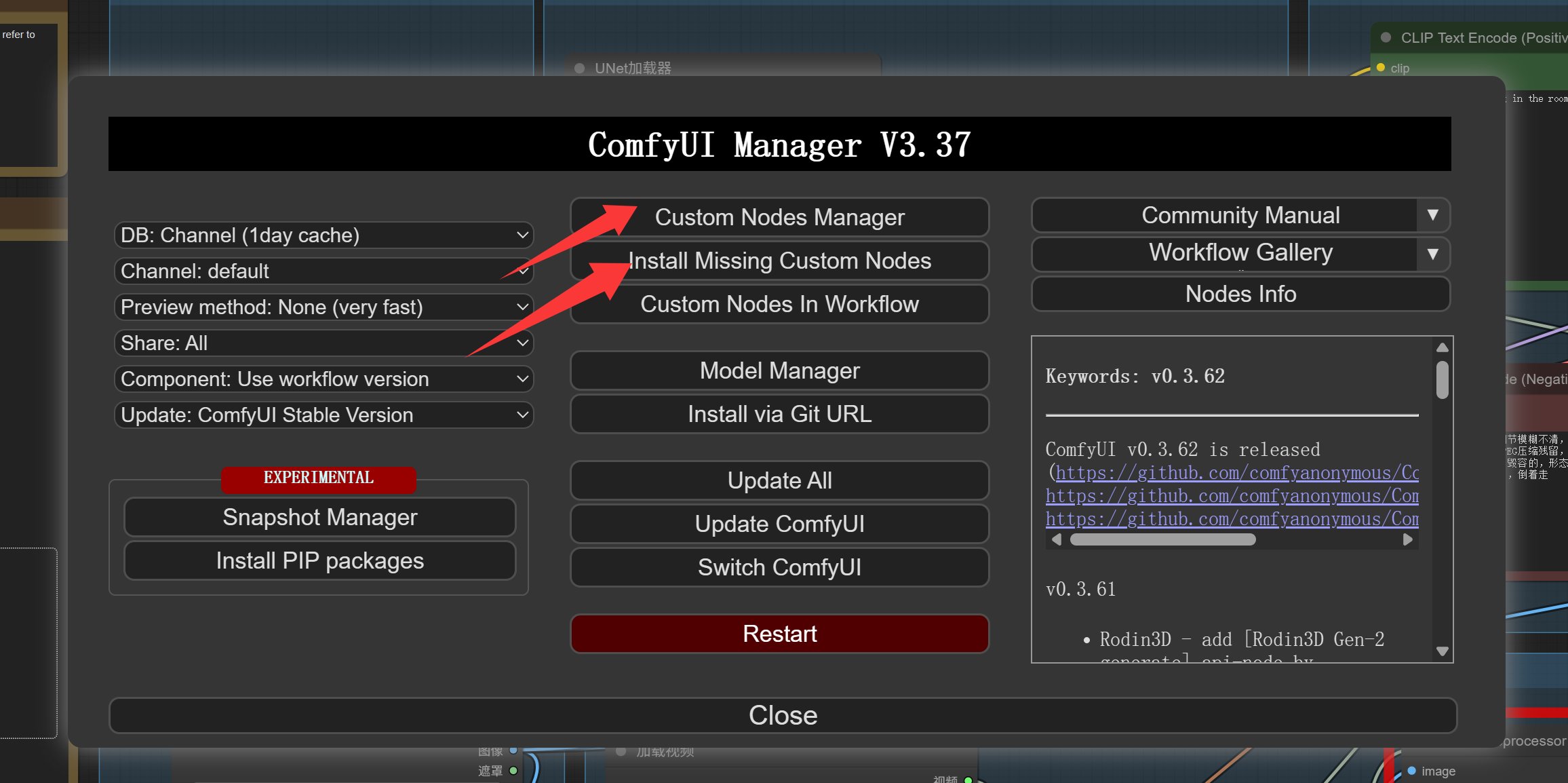
找到下图中节点,逐个安装。也可以勾选之后一次安装。
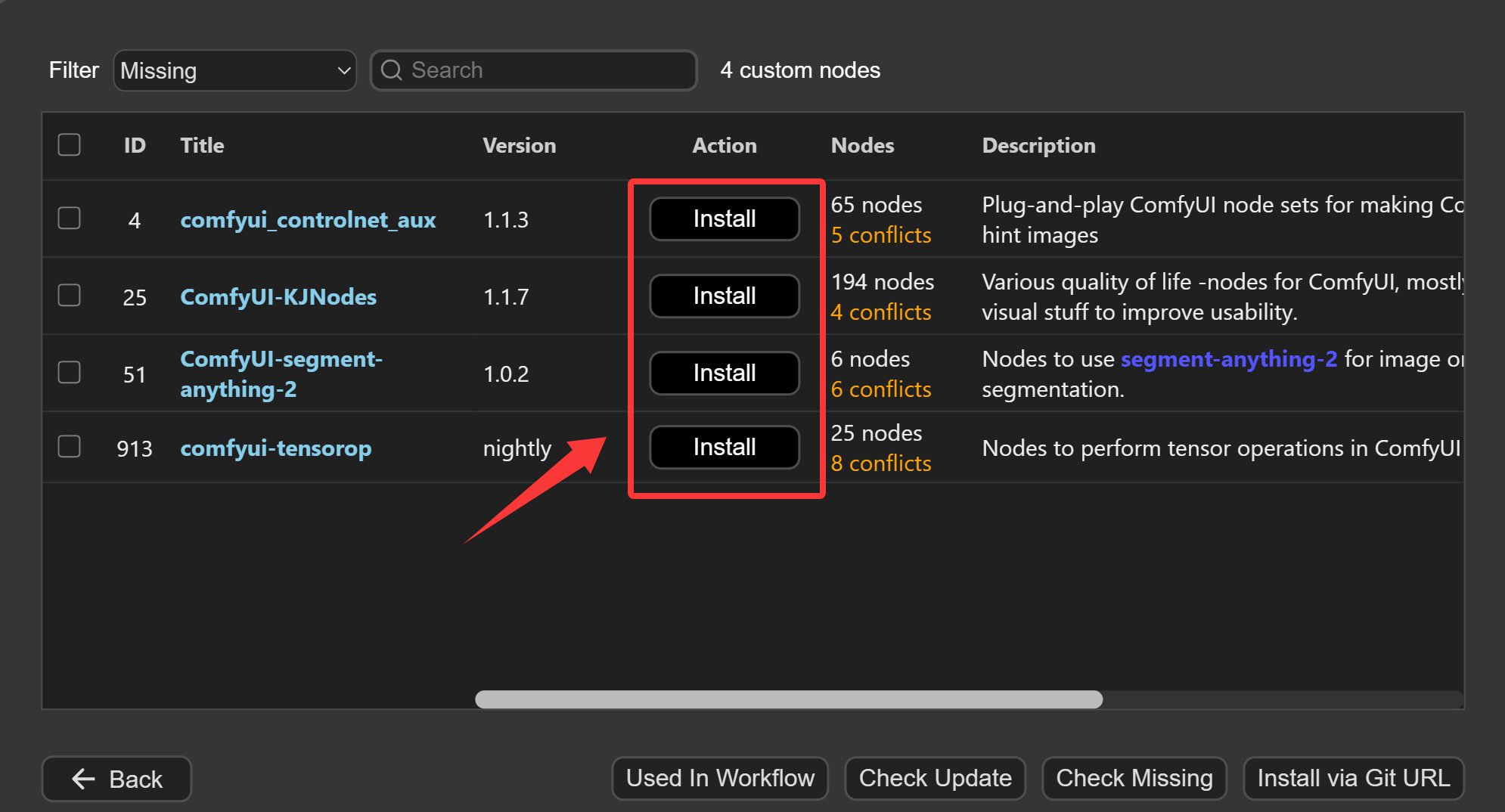
安装完成之后记得重启。
限于篇幅,我这里只贴出了核心操作。
手把手安装教程参考:
https://www.tonyisstark.com/3924.html
如果一切顺利,打开之后就可以看到一个巨大的工作流了。
这个工作流节点和连线非常多,刚开始玩的人看了都会望而却步。
但是,不要被吓到,只要抓重点就可以了。
我们要做的只是准备一张参考图片和一个参考视频就可以了。
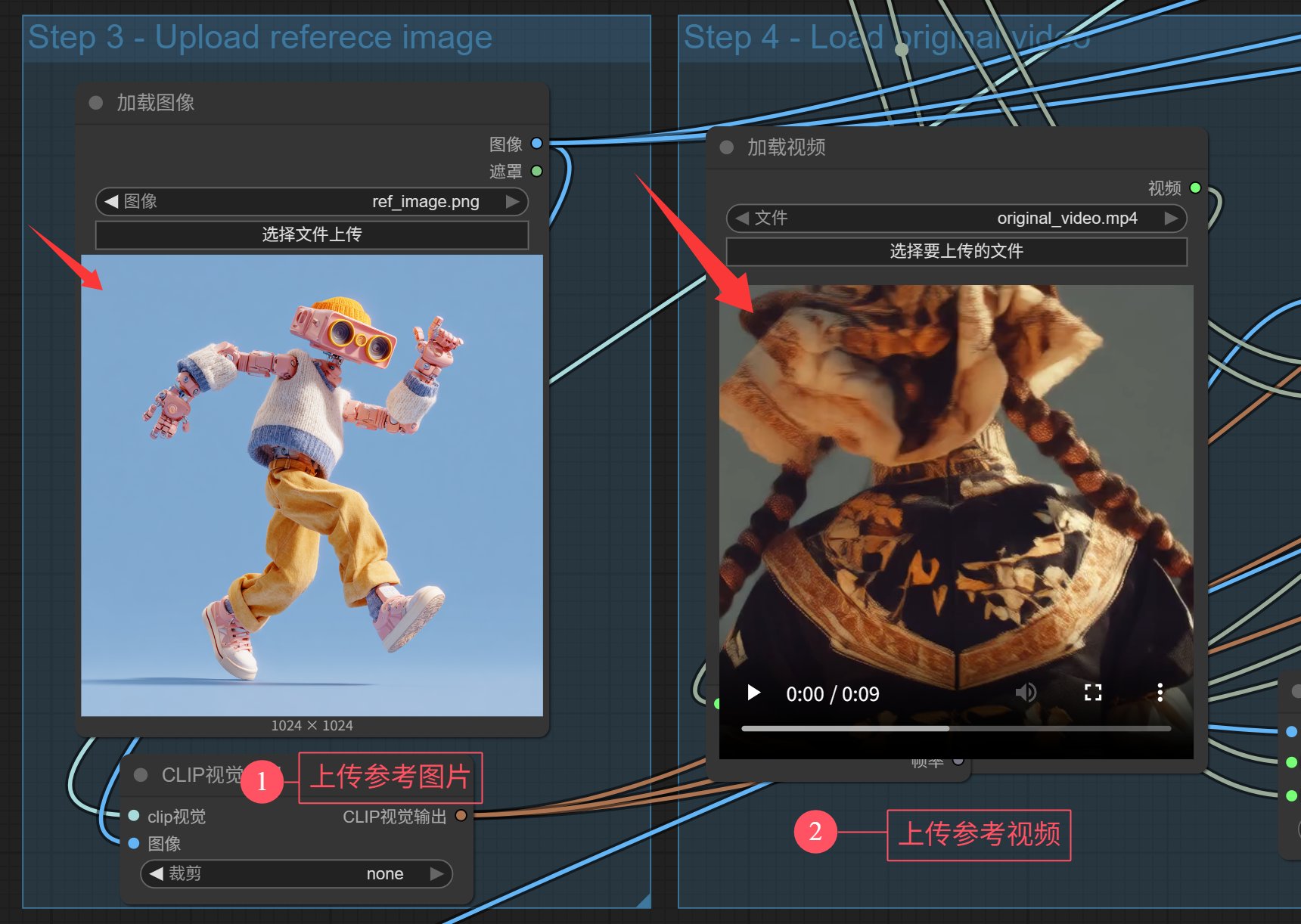
参考图片是一张包含人物的图片,参考视频是一个人物的动态视频。
准备好之后,点击选择文件上传,上传图片和视频即可。
运行并测试
上传之后,直接点击运行按钮,来运行这个工作流。
在 RTX 5060 Ti 上大概十几分钟之后,就会跑完。
我同样的素材跑了三次,第一次 1166 秒,第二次 719 秒,第三次 696 秒。
最终结果会显示在这里:
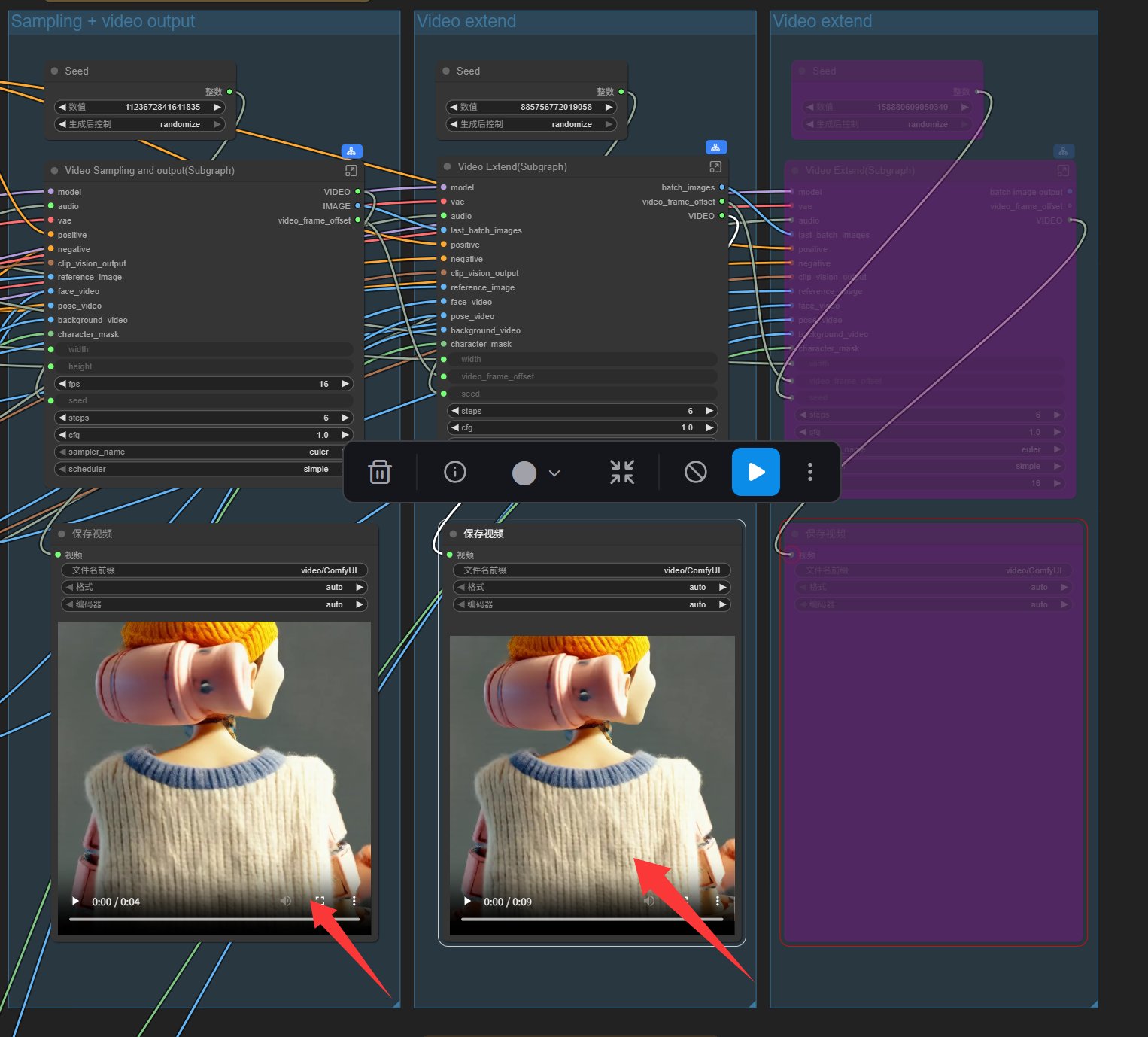
鼠标移到上面,点击播放按钮,可以直接播放预览,同时视频已经保存在 ComfyUI 的 output 文件夹里面了。
从结果中已经可以看到,主角已经被换成了机器人,而机器人做的动作是参考了我们上传的视频。
从图片中可以看到,我们生成视频是 1:1 的正方形。实际情况下,我们往往需要的是横屏或者竖屏。
可以通过修改 Video Size 部分的参数实现我们需求。
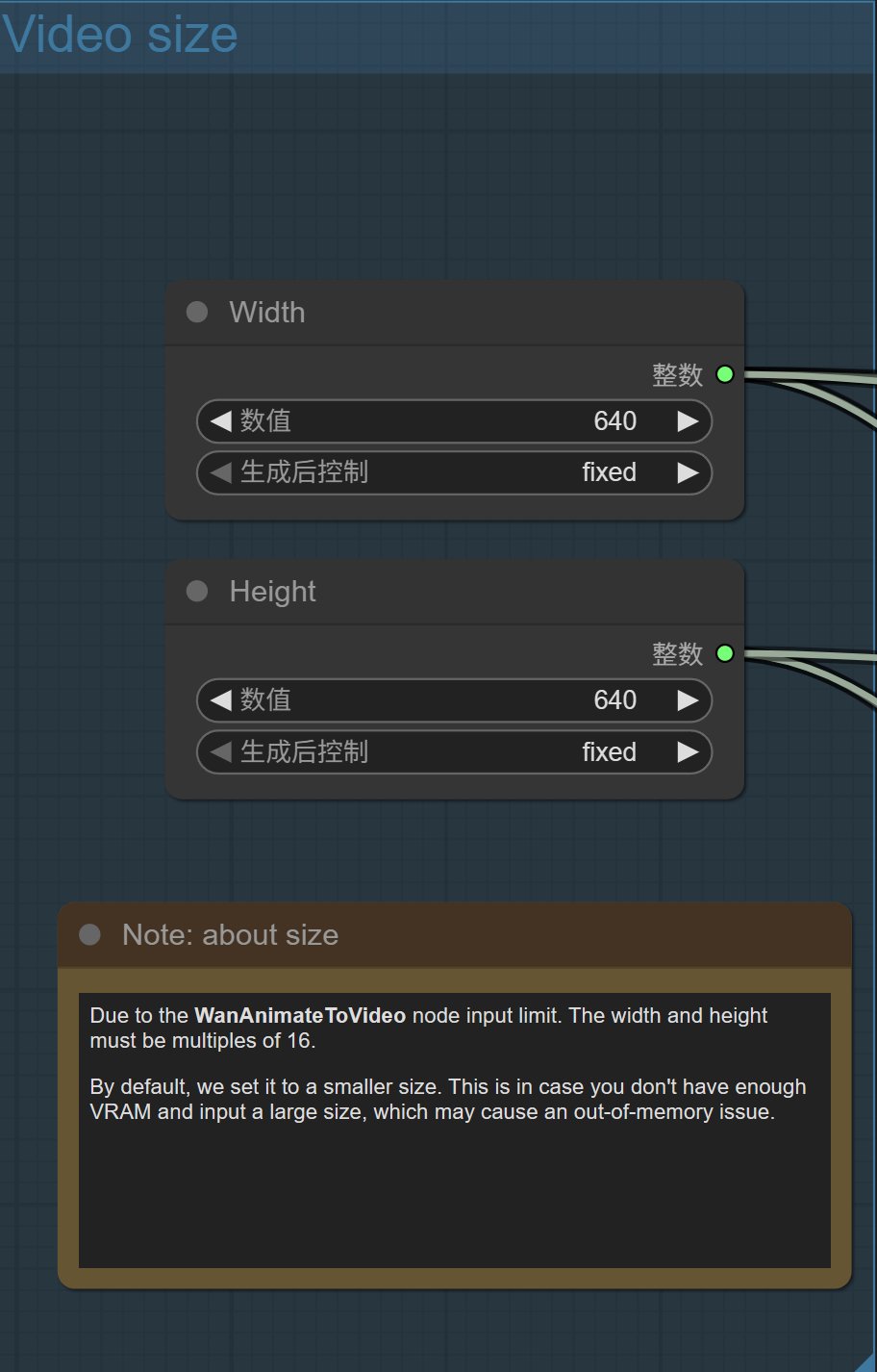
直接修改高度和宽度的数值就可以了,分辨率越高系统资源要求越高。
设置的时候需要注意一点:
由于 WanAnimateToVideo 节点的输入限制,宽度和高度必须是 16 的倍数。
默认情况下,我们将其设置为较小的尺寸。这是为了防止在您的显存不足时输入较大尺寸,从而可能导致内存不足的问题。
可以考虑设置成 720 × 480 或者 720 × 576。这样显存稍微大点就能跑。
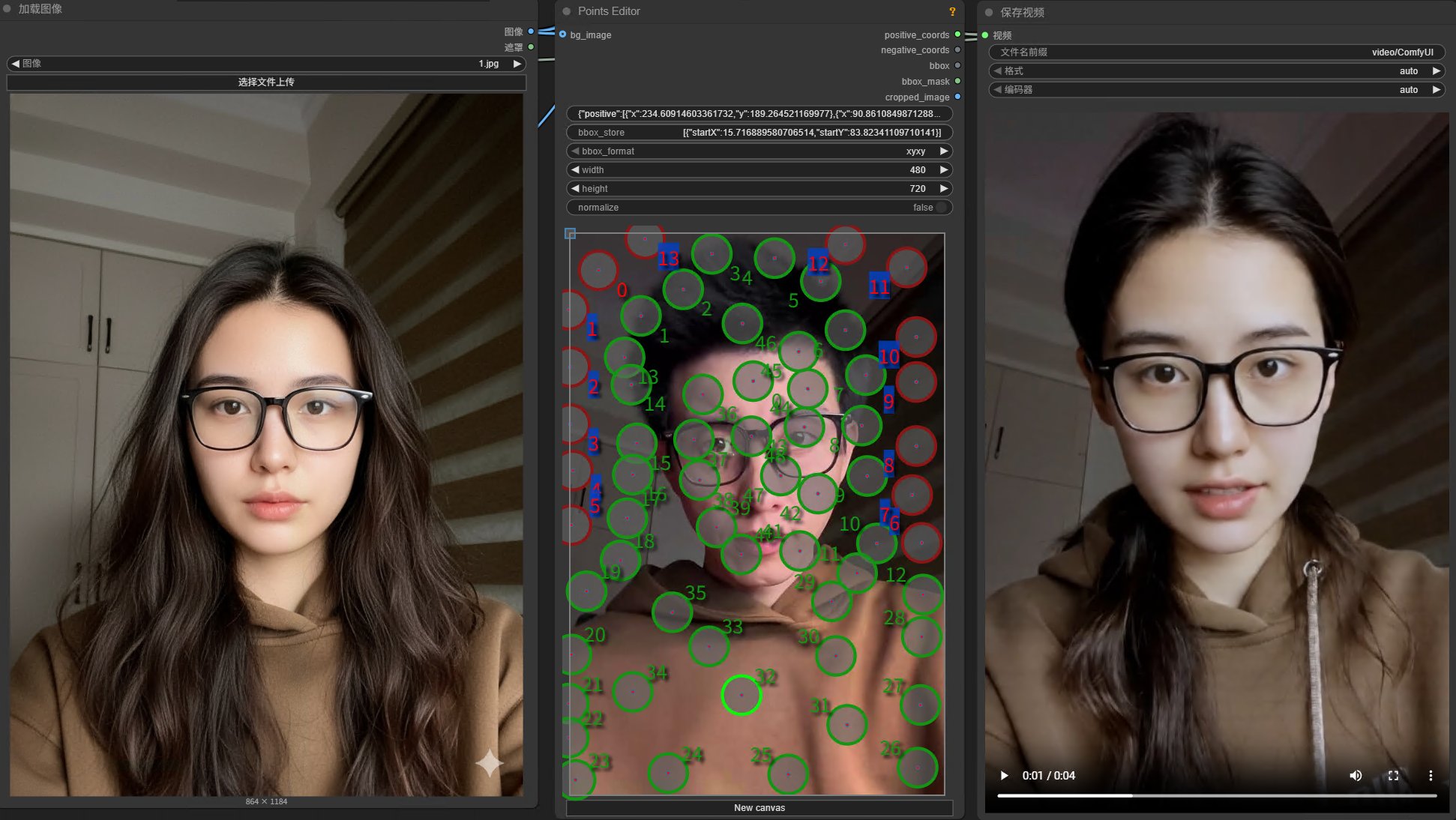
另外这里还有一个 Points Editor 节点。
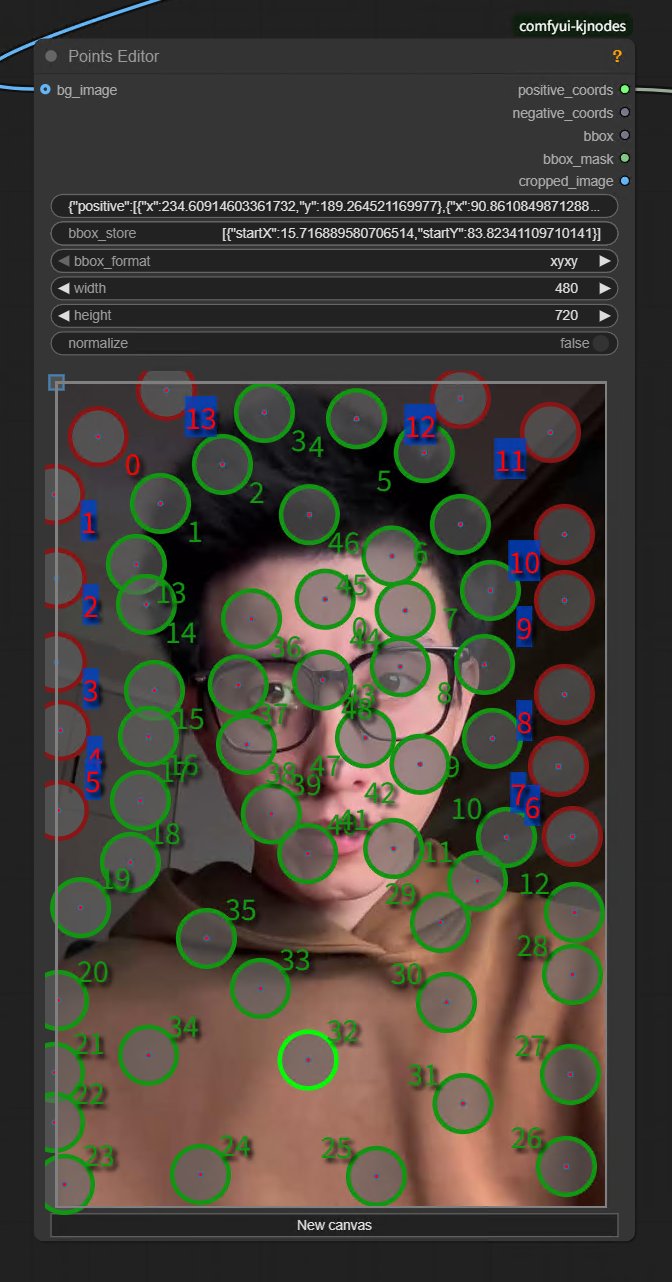
它提供了一个可视化标注界面,允许你在画布上选择图像区域。绿色点代表你想选中的部分,红色点代表排除的部分。比如我想更换其中的人物,就是给人物打上绿色点,给背景打上红色点。
具体操作是:
Shift + 左键添加绿点
Shift + 右键添加红点
圆圈上右键直接删除
点击 NewCanvas 清除全部。
这里的图片刚开始是没有的,只有运行过一次才会出现。
需要调整的大概就是这两个地方了。
最终跑完就是这个效果:
这是ComfyUI 的官方工作流啊,但是效果实在是很难恭维。
实际跑完发现很多问题。
大方向是对的,角色也在替换,表情动作也在同步。
但是角色一致性比较差,嘴型同步也对不上,超过 5 秒的视频中间不连贯。
我要的是这种效果啊!

为此我又折腾了好久!
网上各种工作流非常多,但是要本地跑起来就会有各种各样的问题。
最后终于找到一个能跑,且效果能还原 90% Wan 官方效果的工作流。
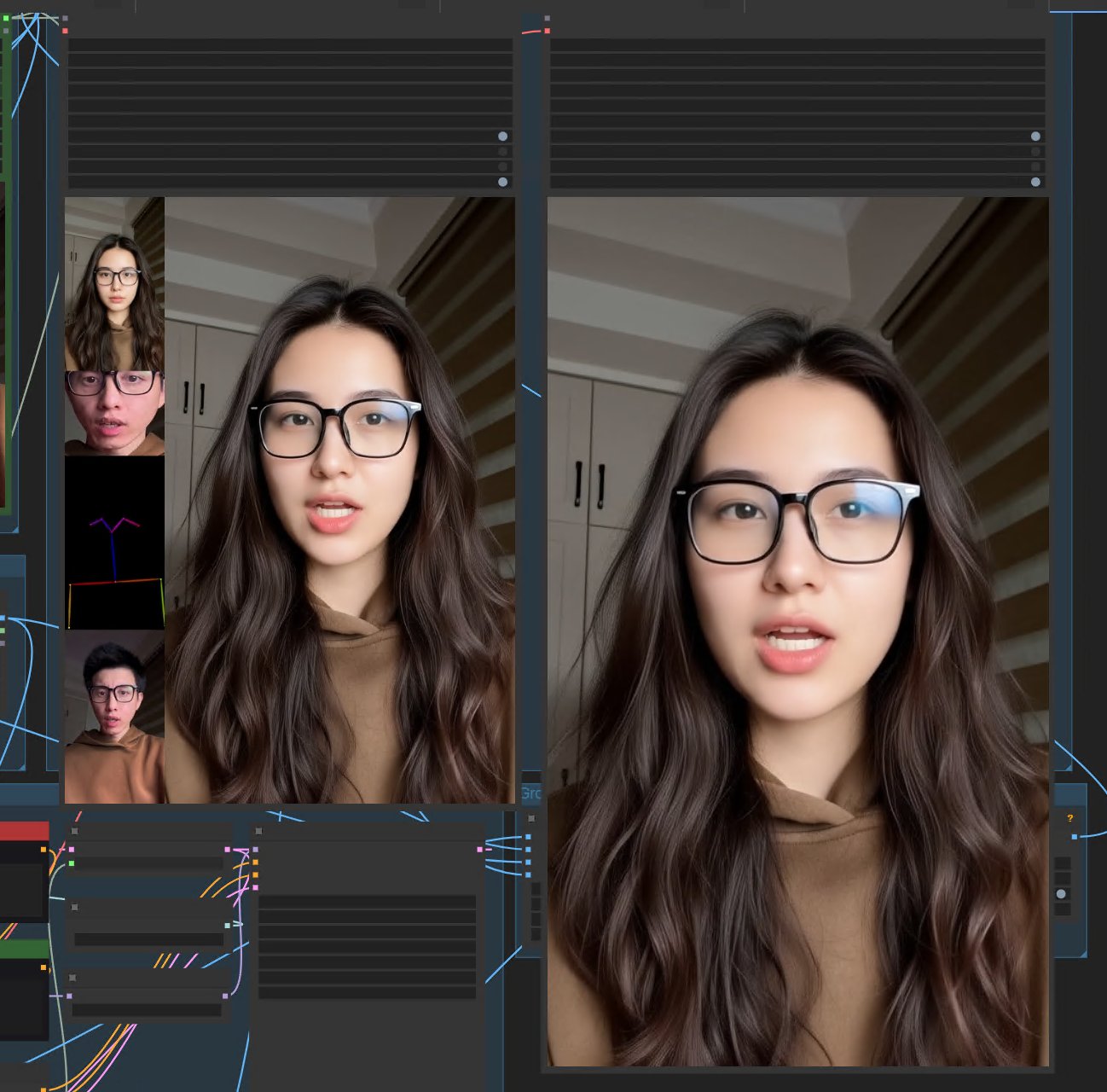
在色彩方面,似乎比 Wan 官方的效果还要好。
Wan 官方效果生成的色彩会偏淡很多,我必须用后期工具去调色。而这个工作流生成色彩比较正常。
动作和嘴型方面也实现了精准同步!
为了把这个工作流跑起来,又折腾了好久,下了一堆模型,装了一堆节点,都给我整失眠了!
本地已经完全搞定,但是要把这个过程理清楚,还需要一点时间,下一篇见!


关于作者
tony
某人