腾讯云 deepseek 工作流功能详解!
这些本文有点硬核,需要一定耐心!
就因为白嫖了腾讯云的无限♾️畅玩 API,为了在有效期内,充分使用,我把 LKE 功能全部玩了个遍。
已经讲过的有:
获取 DeepSeek R1 的API在本地使用
基于LKE 和 DeepSeekR1 实现大模型搜索功能
基于LKE 和 DeepSeekR1 创建大模型知识库
今天来说说“基于于LKE 和 DeepSeekR1 的工作流”。
工作流,可以让你用可视化的方法,完成各种流程类的工作。
工作流的玩法非常多,可以说是千变万化。通过节点和连线,可以组合出各种各样的应用。尤其是加入大语言模型这个节点类型之后,工作流就变得更加智能了。
下面就以图书馆借书服务为例。演示下如何创建工作流,如何制作工作流,如何调试工作流,如何使用工作流。
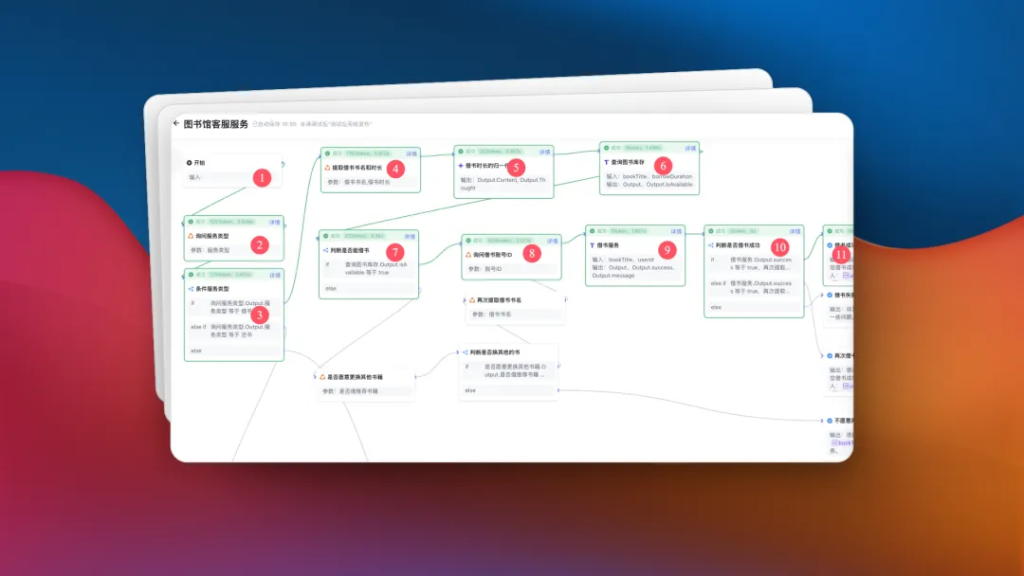
工作流预览
可以先来预览一下工作流:
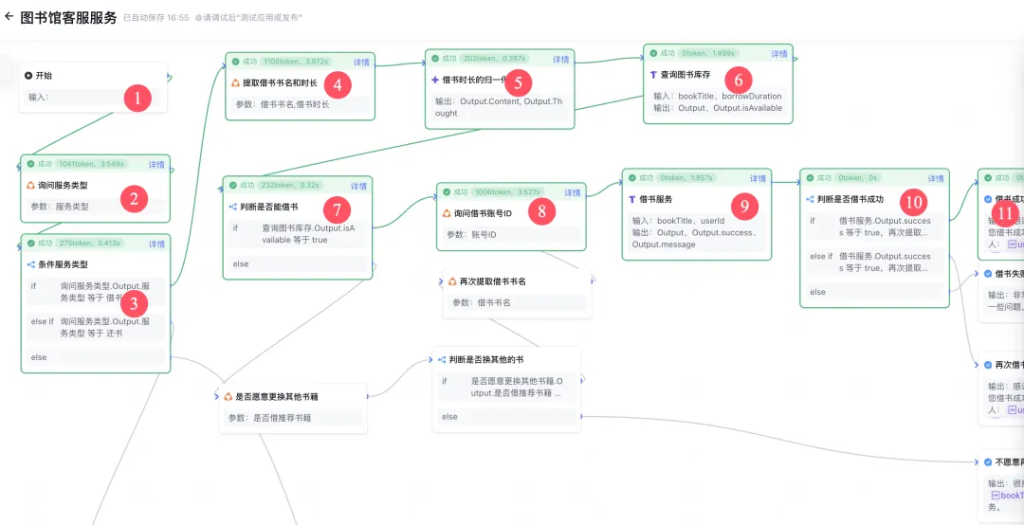
预览一下调试过程:
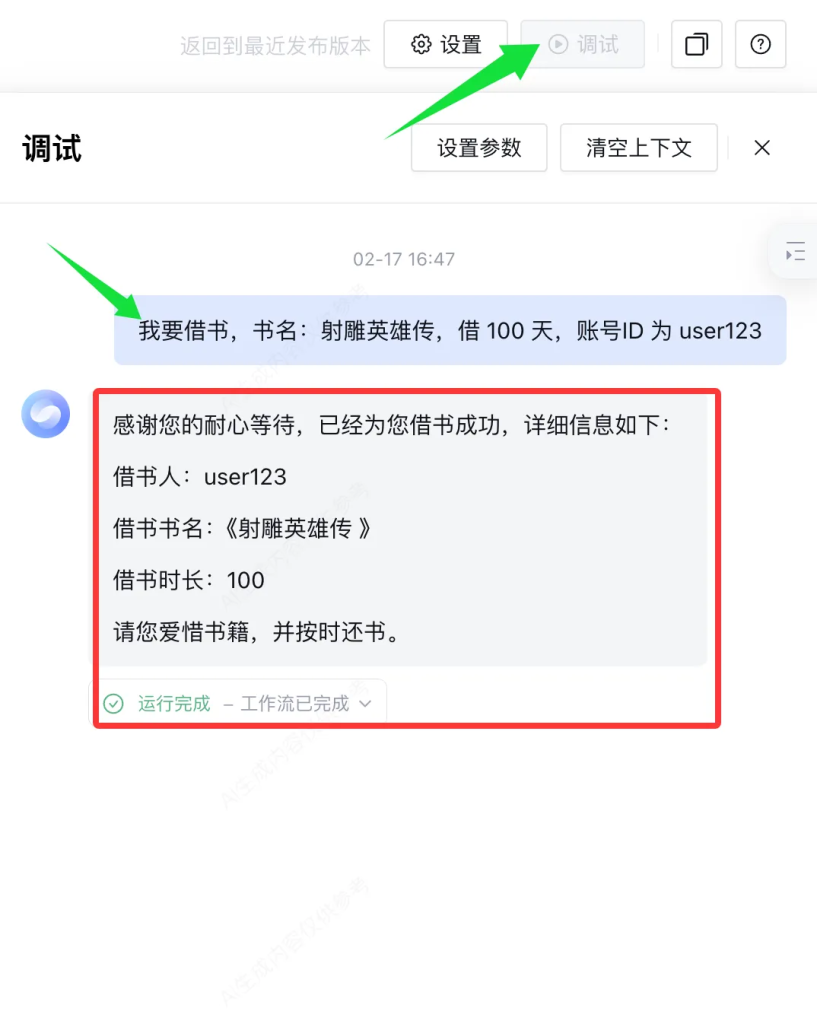
这些关键信息可以一次性输入,也可以根据提示逐个输入。整个工作流会保证准确搜集到这些信息,最终完成借书和还书的操作。
下面就开始具体的操作了。
创建工作流应用
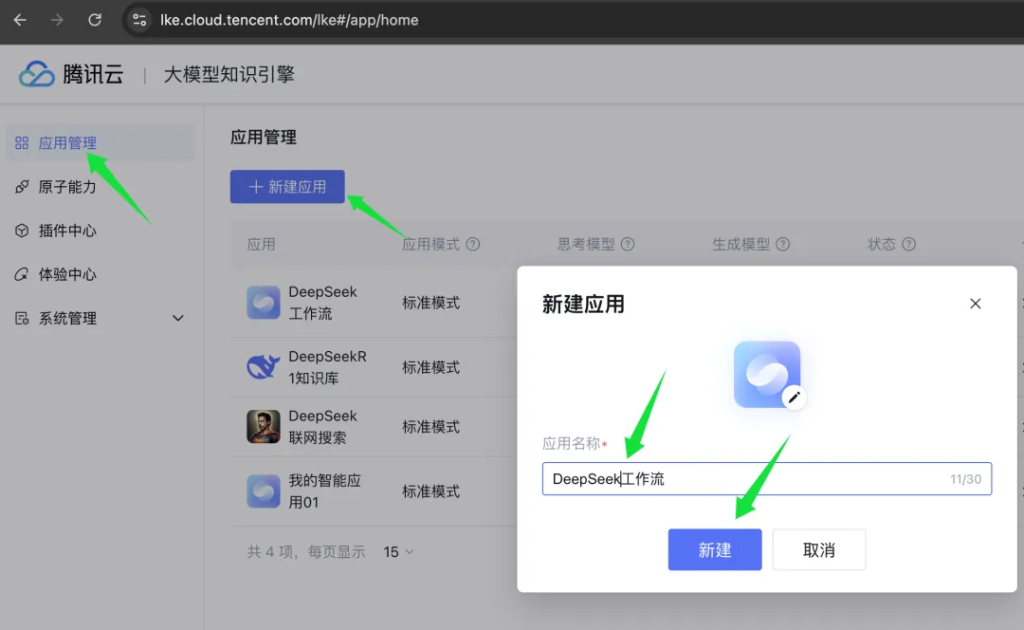
首先还是需要先打开腾讯云的 LKE 控制台。
网址:
https://lke.cloud.tencent.com/lke
打开控制台之后,点击应用管理->新建应用->输入名称设置图标->点击新建。
创建完成之后,就来到了应用配置界面,在这个界面直接点击工作流管理。
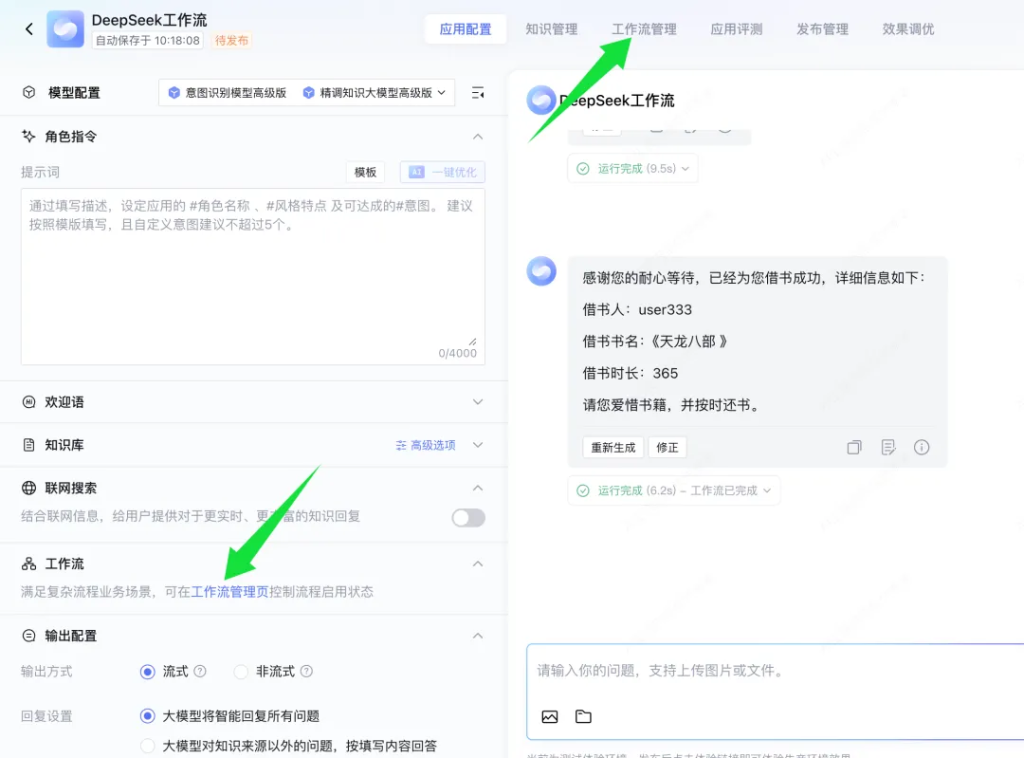
进入工作流创建界面。工作流是这个应用的一部分。我们可以同时启用基于 DeepSeek的搜索,知识库,工作流。
创建工作流
点击新建开始创建工作流。
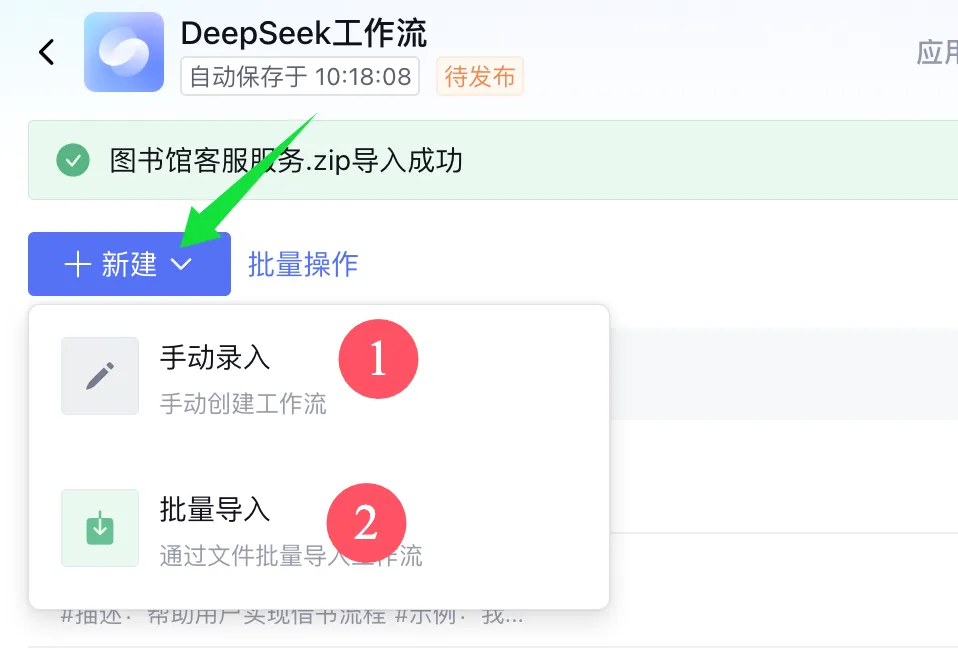
工作流的创建分了两种类型:手动录入和批量导入。
从零开始创建工作流肯定是选择手动录入。
输入工作流名称和工作流描述,点击确定。
创建成功之后,就来到了工作流的主界面。
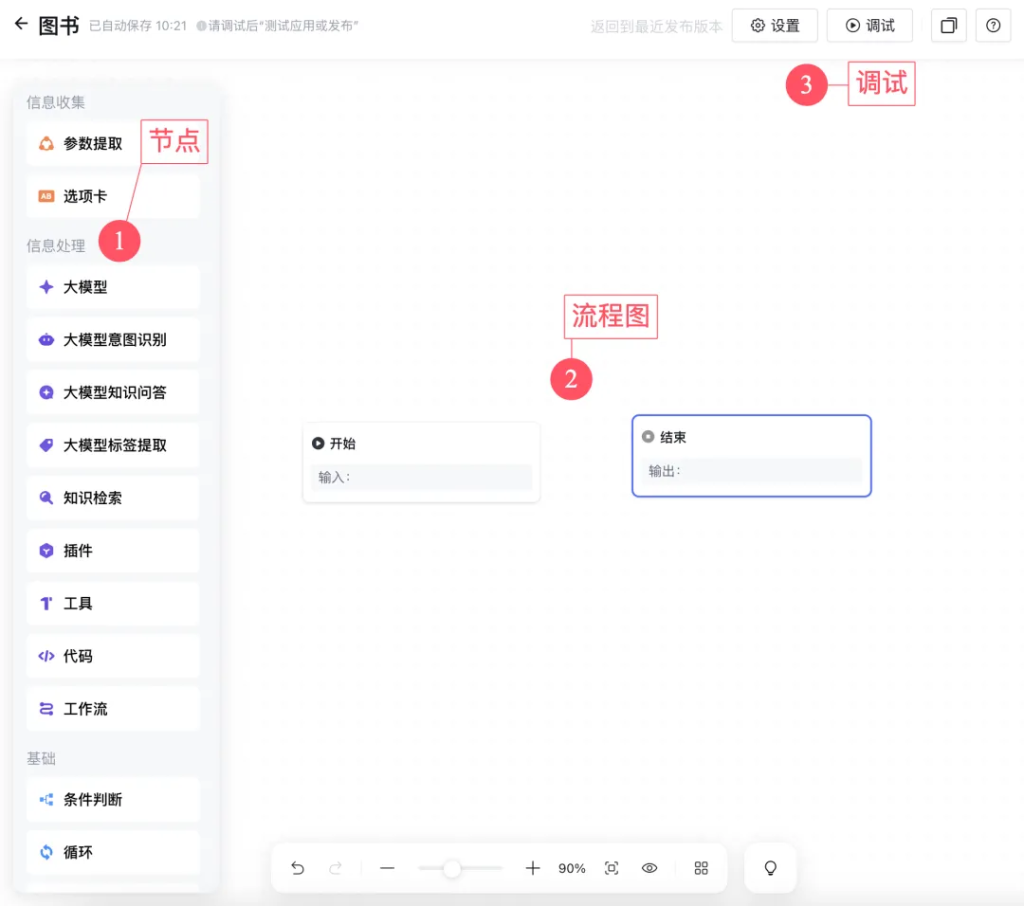
这个界面上主要关注三个部分:节点,流程图,调试。
左边是节点,节点分多种,有信息收集,信息处理,条件判断。
中间是流程图,默认的流程都只有两个节点,一个开始节点,一个结束节点。
鼠标移到上面,会出现一个➕号,可以拖出一条线,连接到其他节点。
点击这个节点,会展现节点所有设置项和信息,可以修改这些设置。
右上角是调试按钮,点击调试按钮,就会跳出一个对话框。
如果流程中参数有遗漏,点击调试后,会直接显示遗漏的项。
批量导入工作流
经过我的尝试,如果一上来就是自己配置每个节点,难度还挺大。所以如果是新手练手的话,最好是用一个已经制作好的工作流。然后直接批量导入工作流。
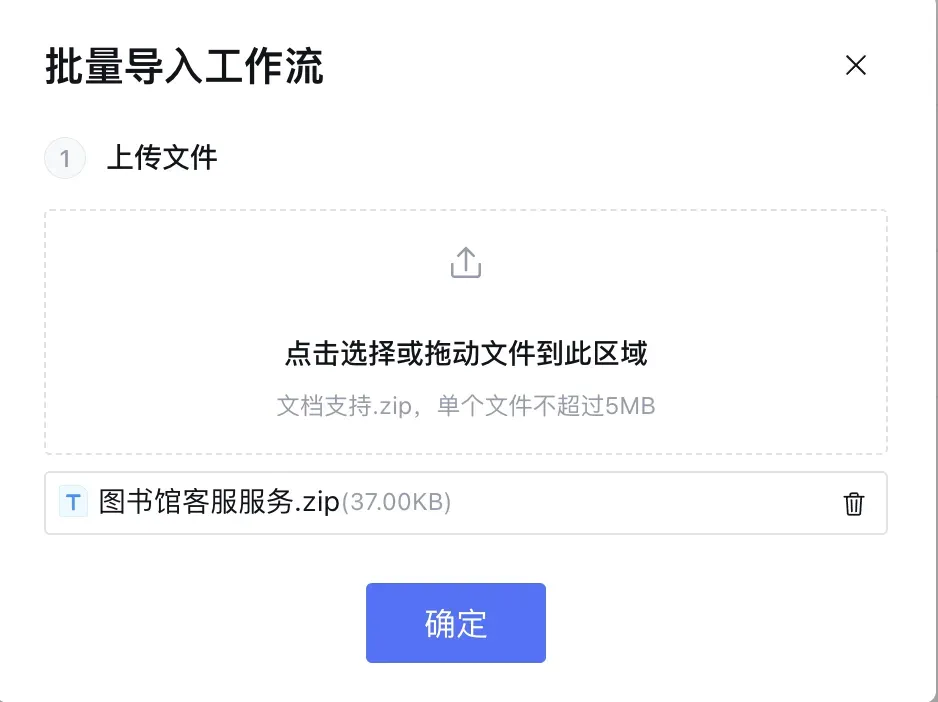
工作流是以 Zip 格式保存的压缩包文件。直接把这个压缩包上传,然后点击确定,就可以批量导入了。
核心工作流
导入之后,立马就可以看到完整的工作流了。
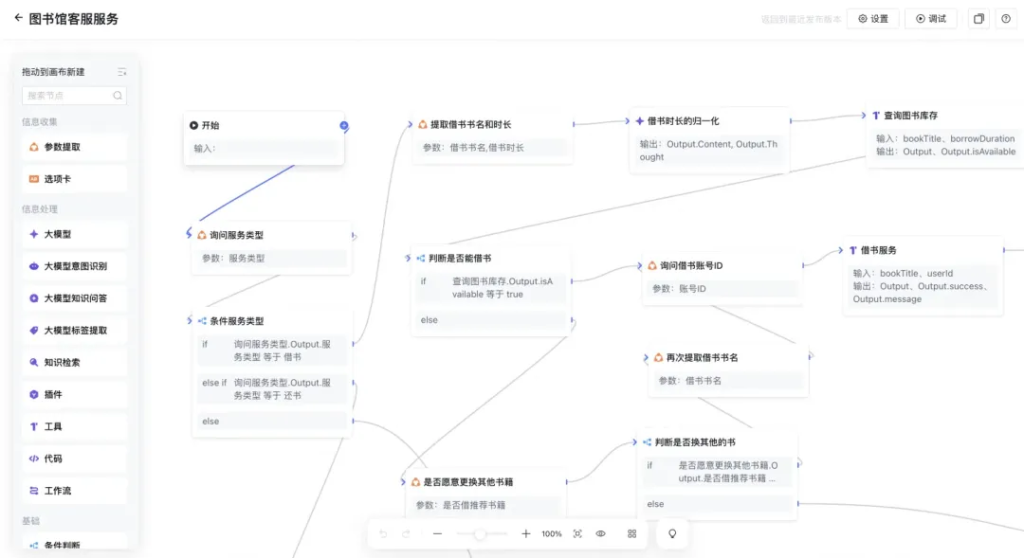
主流程如下:
- 开始
- 询问服务类型(借书,还书)
- 判断服务类型(如果借书那么,如果还书那么,否则)
- 询问借书书名和时长(获取书名和借阅时间)
- 借书时长归一化(把各种时长的描述统一为多少天)
- 查询图书库存(通过接口查询返回结果)
- 判断是否能借书(根据上一步返回结果判断)
- 询问借书用户账号(获取账号信息)
- 借书操作(根据书名和用户信息完成借书操作)
- 判断是否借书成功(如果,那么,否则)
- 借书成功回复(输出相关信息)
- 结束
上面是主流成,当然还有很多分支。比如还书,比如你想借的书已经没有了,询问是否要换其他书。比如借书的时候用户ID 不存在借书失败。
当流程梳理完毕之后,就可以直接点击调试了。调试过程,会动态显示每一个节点的数据,如果出现错误,也会有错误信息。
节点详解
工作流有了之后,我们可以来重点分享一下节点。
参数提取节点
在整个工作流中,参数提取节点我们用到了三次。一次是问服务类型,然后是问书名和时长,最后问了用户 ID。
下面以服务类型为例,进行说明。
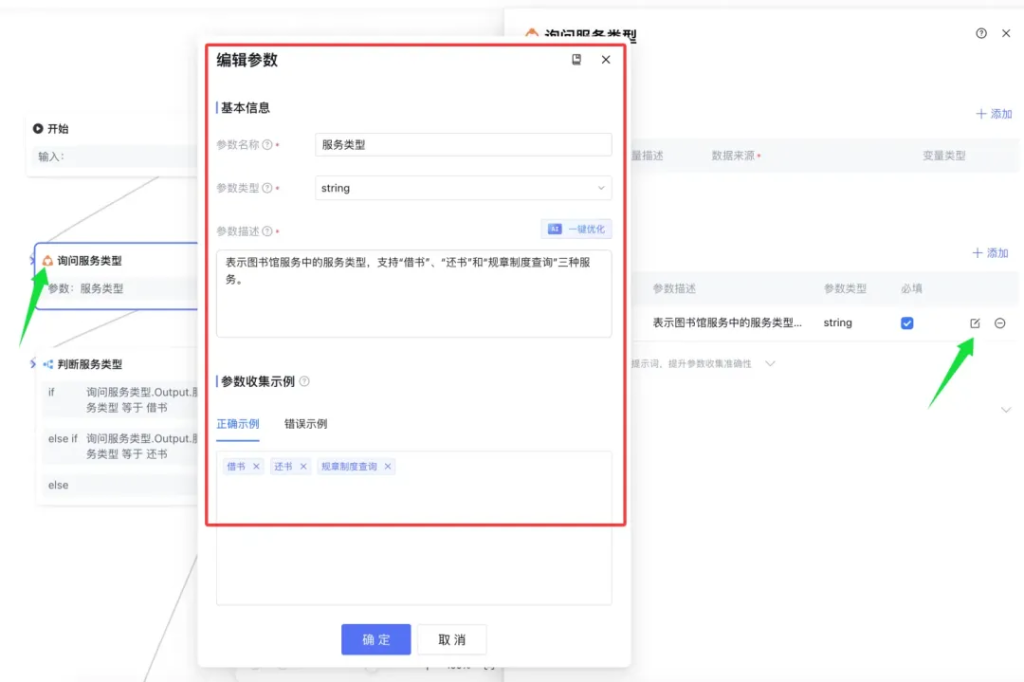
点击训服务类型节点,右侧会跳出详情,在参数信息中有一条记录,叫服务类型。
点击编辑图标,打开参数编辑界面。
主要填写项目有:
参数名称:服务类型
参数类型:string(字符串)
参数描述:表示图书馆服务中的服务类型,支持“借书”、“还书”和“规章制度查询”三种服务。
参数收集示例:借书,还书,规则制度查询。
服务名称根据需求写,服务类型一般选 string 就可以了。除非你有精确的类型需求。
这里的参数描述和示例比较重要,填写的内容相当于提示词,会交给大模型去理解。然后我们才能从对话中提取参数。如果按传统的应用模式,一般需要创建一个用户表单来收集。
条件判断节点
条件判断节点主要是做逻辑分支。不同情况,用不同的流程。
比如第一个服务类型判断节点。
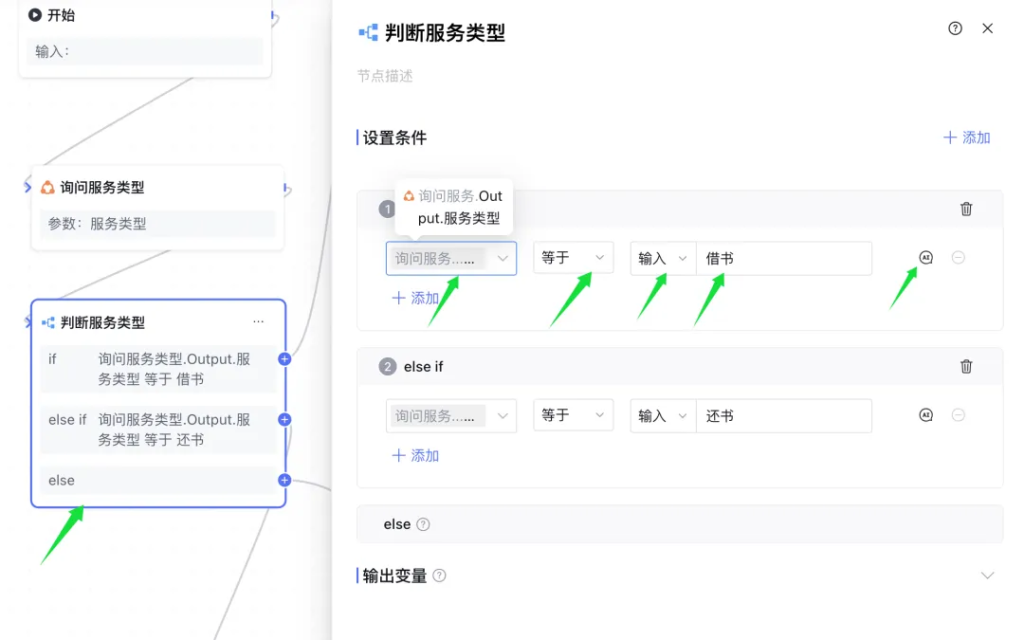
当询问服务类型节点运行完毕之后,就会收集到到具体的服务类型,比如“借书” 。借书这个值会保存在服务类型.output.服务类型中。
后面在服务类型判断这个节点中,就可以使用这个变量。
当这个节点
变量,等于,借书,那么…..
变量,等于,还书,那么….
如果都不是,那么….
经过这个节点之后,出现了三个分支。
这里还有一个 AI 的图标,不启用的时候,使用精准判断,启用之后可以用 AI 进行智能的模糊匹配。默认推荐使用 AI 来匹配,除非你有自己的需求。
大模型节点
利用大模型强大的理解能力,对节点数据进行基于语意的处理。
这个流程中用于借书时长归一化处理。

所谓归一化处理,就是把时间用统一的标准描述。由于人的不可控性,导致输入的时间会千奇百怪,在以往的系统中,程序员需要写无数的代码来保证用户不犯错。
现在有了大语言模型,可以让他来做这些事情。用户的表达空间大了,工作流也能获取自己想要的东西,继续往下走。
这一步创建了一个叫 borrowTime的变量,这个变量,就是来自于前面参数提取节点提取到的参数。之前的输入内容可能是:两周,一个月,一年。经过大模型转换,就全部会变成天数,14 天,30 天,365 天。
工具节点
工具节点,可以调用各种 API 完成特定功能。
在我们的工作流中也用到了好几次,其中一次就是查询图书库存。
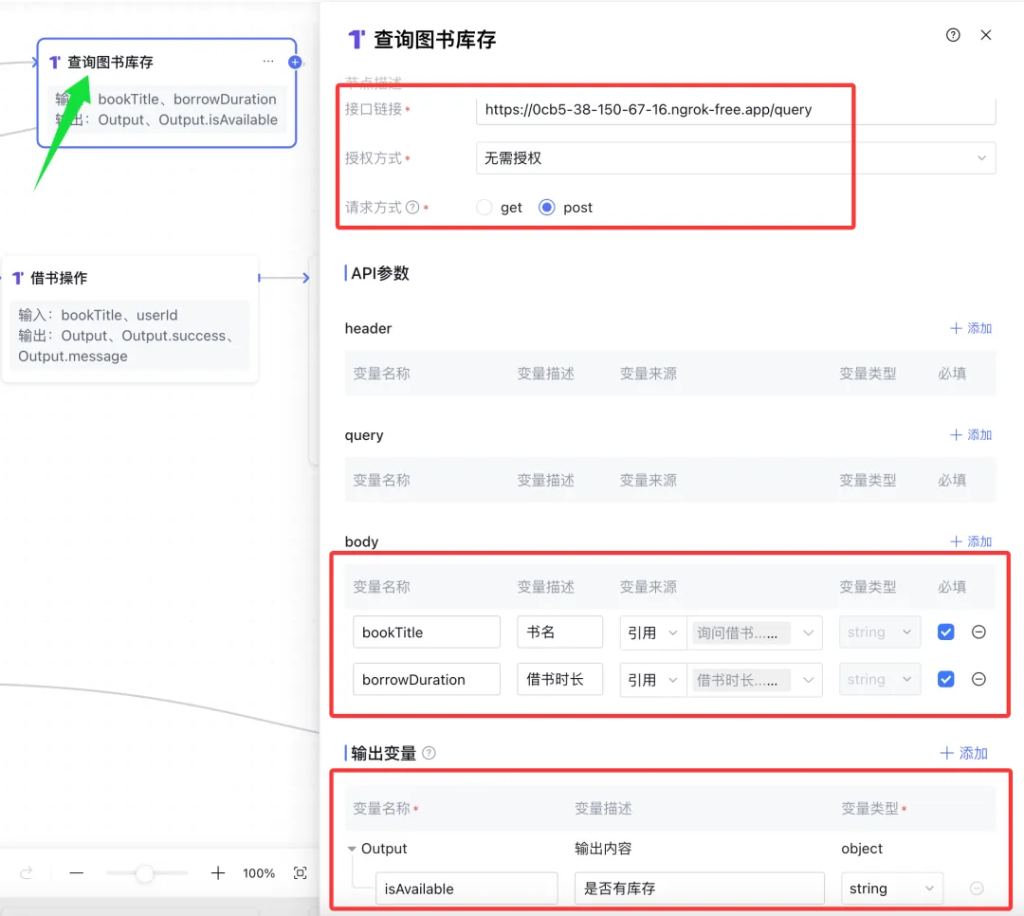
点击图书库存,可以打开详细信息。
这个节点,其实就是构建一个 Http 请求,并接收返回内容。
首先是指定接口地址,授权方式,请求方式。
然后是构建API参数,参数可以放在 header,query,body 里面。
然后是接收输出变量。
这个节点在整个工作流中非常关键。官方给的流程图,并没有实现这个接口。所以直接运行工作流,就会出错。
针对这种情况,可以直接编写一个简单的接口。
接口可以接收 bookTitile 和 borrowDuration 两个参数,然后根据这个参数到数据库里去查询,是否还有这本图书,如果有的话就返回true,如果没有的话就返回false。
如果你没有数据库,那么可以直接返回 true,让这个流程走下去。
如果你代码不会写,我给你一个参考代码。
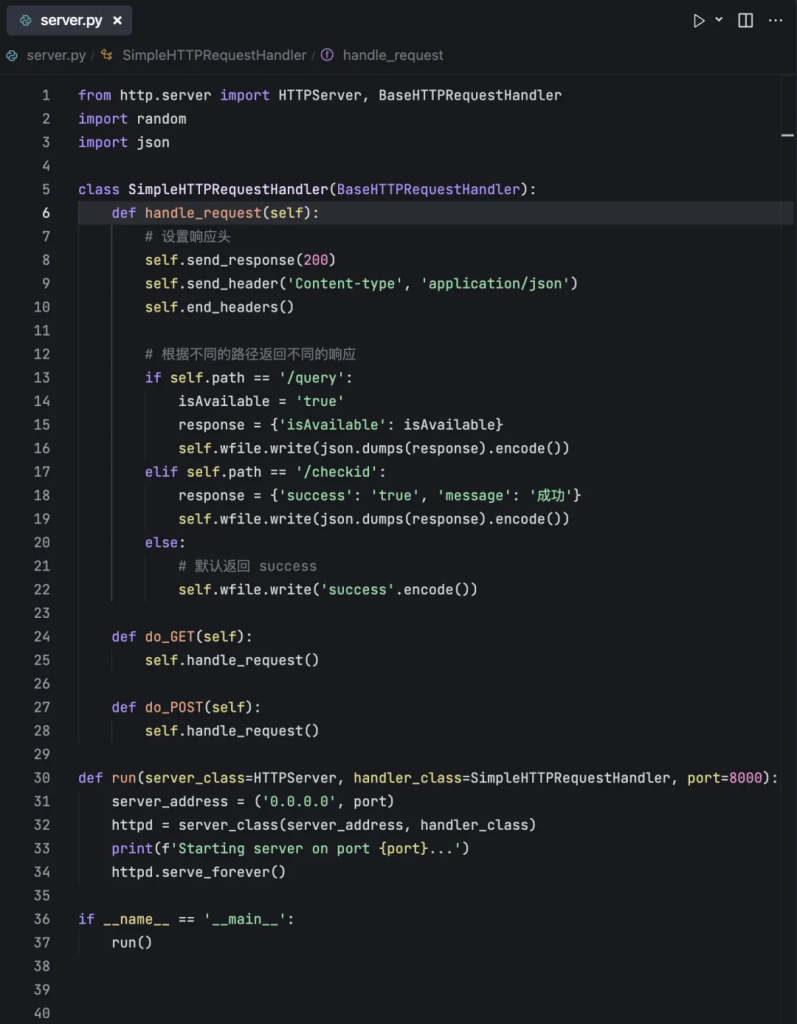
上面的代码已经完成了工作流中需要的两个接口。一个是查询接口,一个是验证接口。
只要在任意一个服务器上安装 Python。
然后运行命令:python3 server.py
然后就可以把 ip:8000/query ip:8000/checkid,配置到查询图书库存和借书操作的接口选项里面了。
当访问这些接口的时候,会按数据格式要求返回数据。数据以 JSON 格式返回。
response = {‘isAvailable’: isAvailable}
response = {‘success’: ‘true’, ‘message’: ‘成功’}
如果没有服务器,可以通过之前讲的 ngrok 内网穿透到自己的电脑上。
当理清楚上面的各类节点,配置好工具节点之后。
就可以开始调试了。
工作流调试
点击右上角的调试按钮。
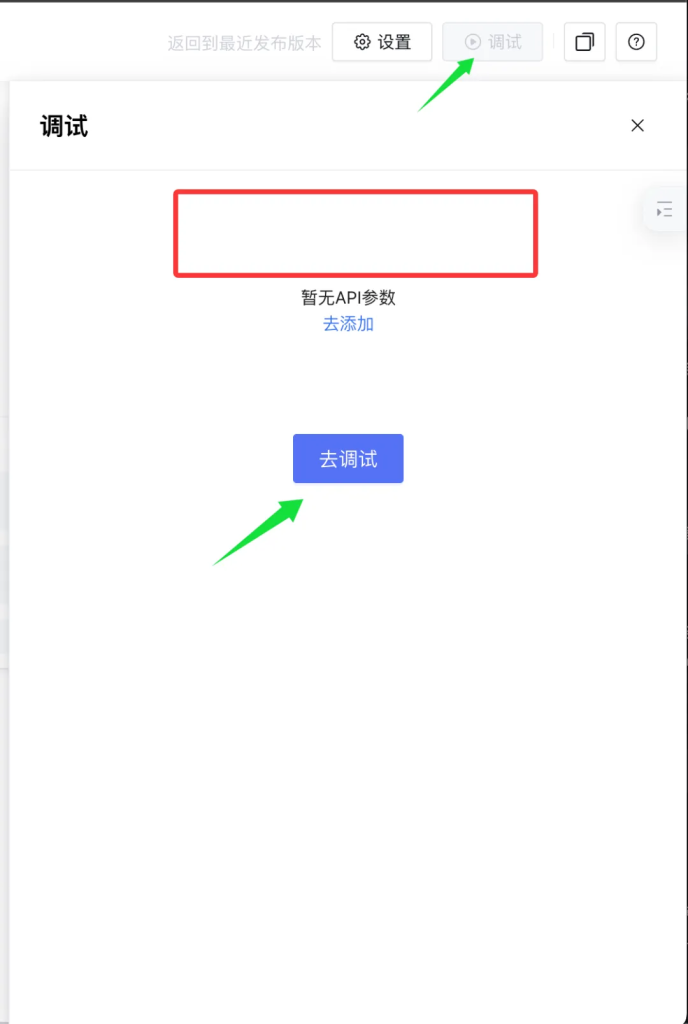
在弹出的界面中,如果发现流程图有问题,就会把问题显示在上面,如果没问题,就可以直接点击去调试了。
调试过程中,可以按步骤输入需要的内容,也可以一次性输入。
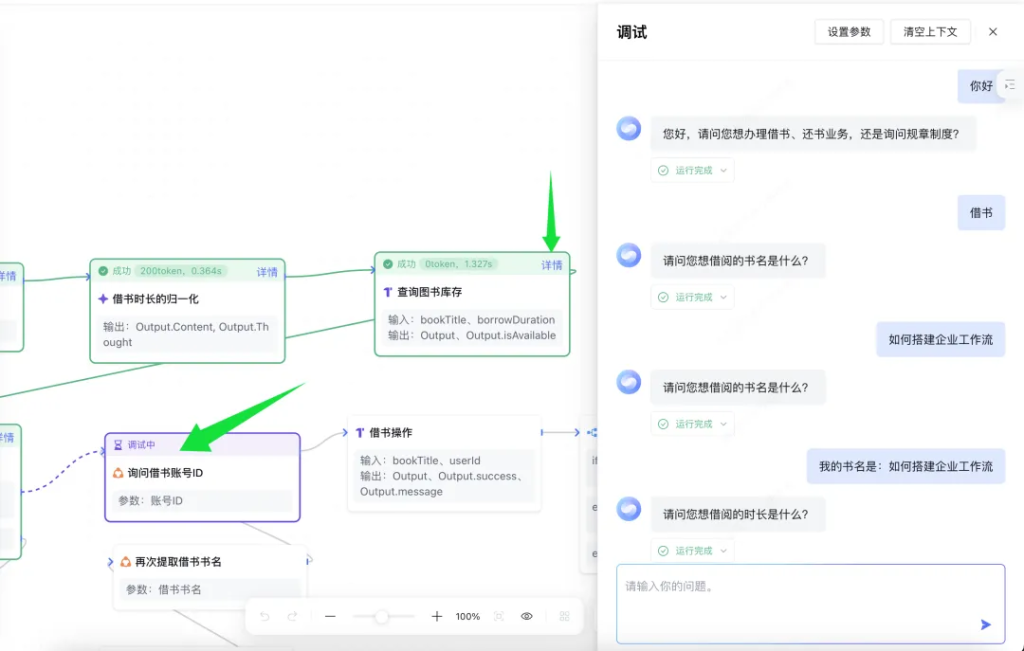
上图中显示了对话过程,和工作流的运行进程。当我输入书名和时长之后,查询图书库存的操作已经完成,目前正在等待我输入用户 ID,然后继续后面的流程。
点击查询图书库存的详情链接。会跳出具体的数据。

这个数据在调试过程中很重要,如果出现错误,这里会有错误信息。
当我们输入了用户 ID 之后,整个流程就很快走完成了。
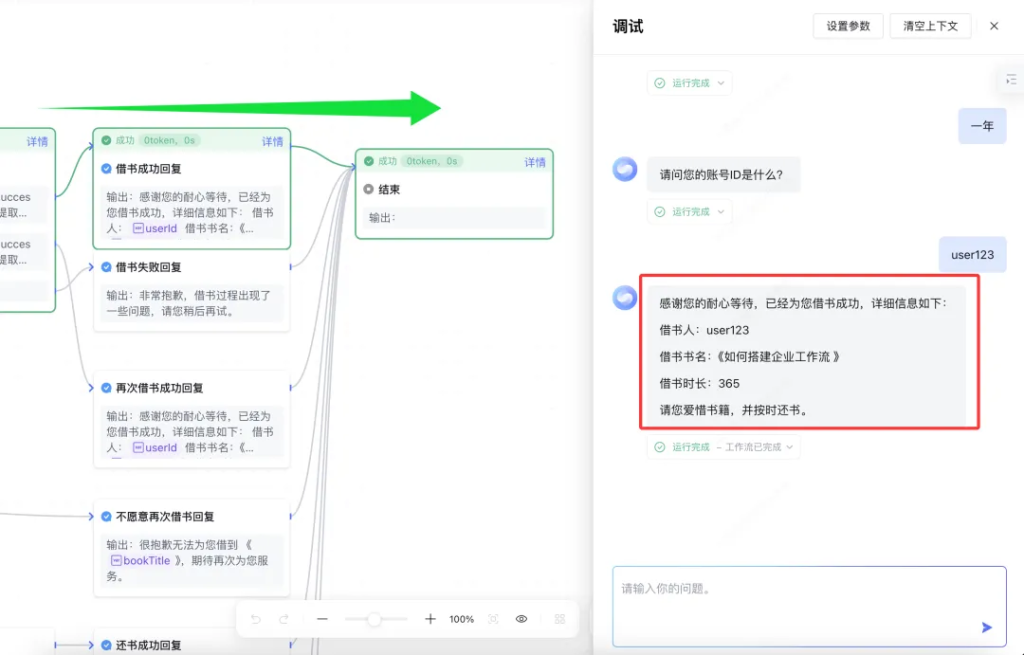
调试成功之后,就可以去应用里面进行测试了。
应用里面测试的时候,并不会一上来就问你要借书还是还书。
需要你触发关键词才会进入工作流程。
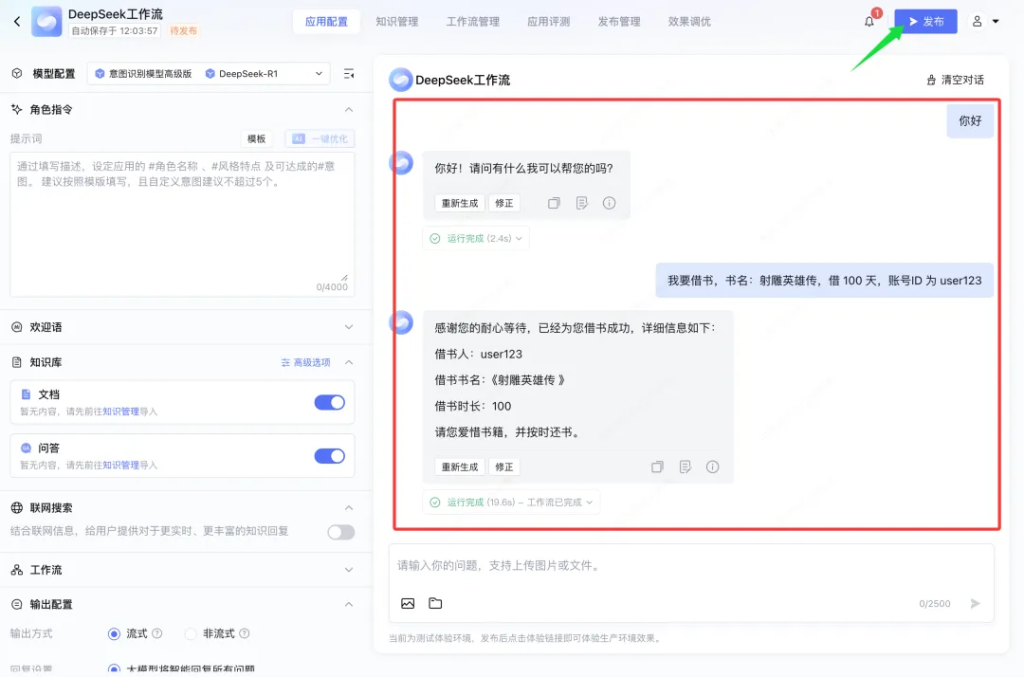
也就是说一个应用里面可以插入无数工作流,一个工作流又可以有很多节点和流程。最终可以做到,在一个对话窗口里完成各种各样的工作。如果把对话形式换成语音…那就更上一层楼了。
发布应用
一切测试 OK 之后,就可以进行发布。然后通过API 集成到各种系统里面了。企业内部系统,或者独立的个人网站,手机 APP,电脑客户端。
如果有更新需求,你都不需要修改终端软件,只要修改工作流就可以了。一旦这套系统走通了,开发效率可以大幅提升。完了,又有几个岗位的几个员工可以下岗了😄。
还好人类的需求永远都在变,比如有人的需求就是,不能用AI辅助,必须手搓代码。那么大家又可以愉快的摸鱼了。
我只用几分钟,就明白了这个流程,但是把这些写清楚却花了好几天。
看到这里的人,是否可以动动小手,点个关注,在看,转发~~
关于作者
tony
某人