声音克隆集成包!20秒克隆太保守,3秒即可!
上次介绍了一个叫TTS的声音克隆项目。
我当时说是要20秒克隆声音,其实比较保守,官方介绍仅需三秒。
ⓍTTS 是一种超酷的文本转语音模型,让您只需使用 3 秒的音频剪辑即可克隆不同语言的声音。建立在 🐢Tortoise 之上, ⓍTTS 进行了重要的模型更改,使跨语言语音克隆和多语言语音生成变得超级容易。不需要跨越无数个小时的大量训练数据。
TTS是项目的名称,也是它主推的一种模型的名称。
特定很明显,短,快,多。
短,指的是被克隆人的音频只要短短几秒即可。
快,指克隆过程,也是秒级别的时间。
多,支持16中语言,多语言,跨语言,跨语音克隆。
这个项目其实整合了大量语音合成和声音克隆的技术。上次只演示了两个模型,除了直接用之外也支持各种模型的训练和微调。
作为一个开源项目,确实已经非常给了。
所以,一直有人催我出一个本地可以一键运行的离线软件包。
本想着直接出一个命令行版本的包,但是考虑到,没有界面的话,对多数人来说,用起来可能不是很方便。
所以我就整了个界面,主打一个“朴实无华”!
因为对tkinter不是太熟悉,所以用了一些时间。
接下来,我就详细介绍一下这个软件包的使用方法!
先根据文末提示获取软件包。然后找一个英文路径解压。比如解压在D盘根目录。
英文和根目录这个东西,以后就不强调了。开源软件bug多,不要因为这种基础问题把自己搞崩溃了,养成好习惯,问题就可以少很多。
解压之后只要双击exe启动即可。使用前最好准备一些音频素材。因为官方给的示例是wav格式,所以就准备这种格式的素材。
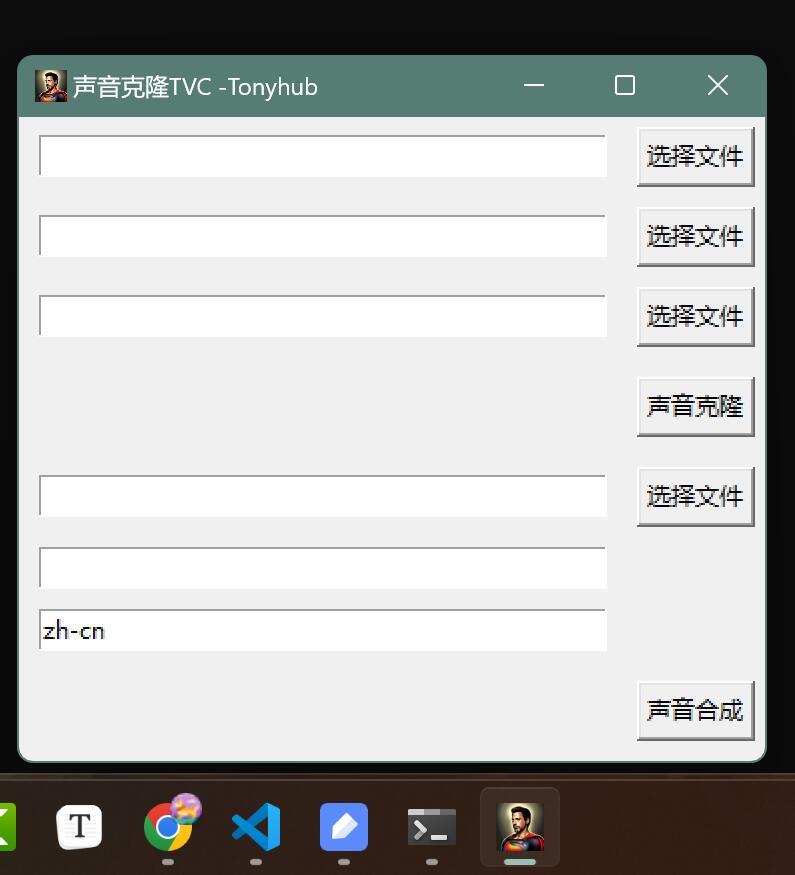
从界面上说,软件分成了两大块。我把上面部分称为“声音克隆” ,下面部分称为“声音合成” 。
其实两个都克隆声音,差别是,上面的克隆类似变声器的效果。能完美保留语速语调。但是必须要提供一个原始音频,在实际使用中,就是必须要有一个人录音,然后对这个录音进行处理。
下边的就是克隆声音之后,用文本转语音的方式来合成音频。这个在实际应用中,就是只要指定一个声音,然后提供文案,就能用这个人的声音读文案了。
省去了真人录制大段语音的步骤,这是优点。缺点是,合成的声音会有一点点不自然,有时候读音不太准,有口音。
声音克隆步骤:
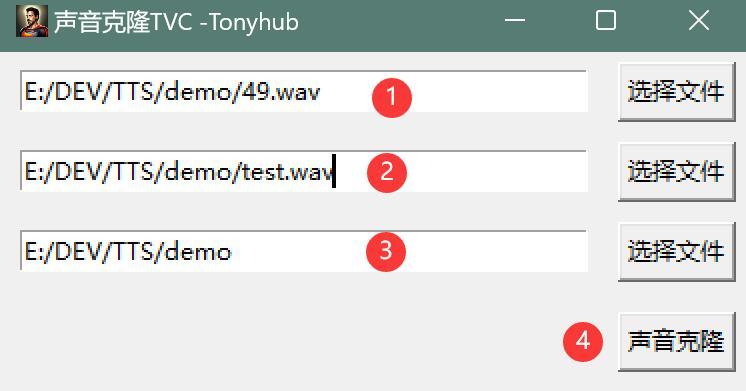
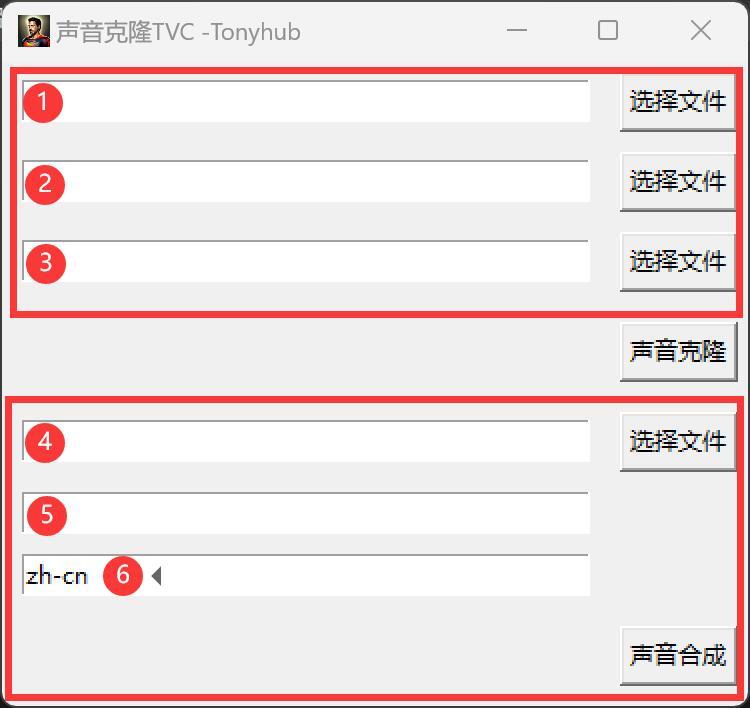
①点击选择文件,选择一个原始声音,即音色提供者。
②点击选择文件,选择一个目标声音,即声音提供者。
③点击选择文件夹,设置合成后的声音保存路径。
④点击“声音克隆”。
点击之后,按钮变灰色。
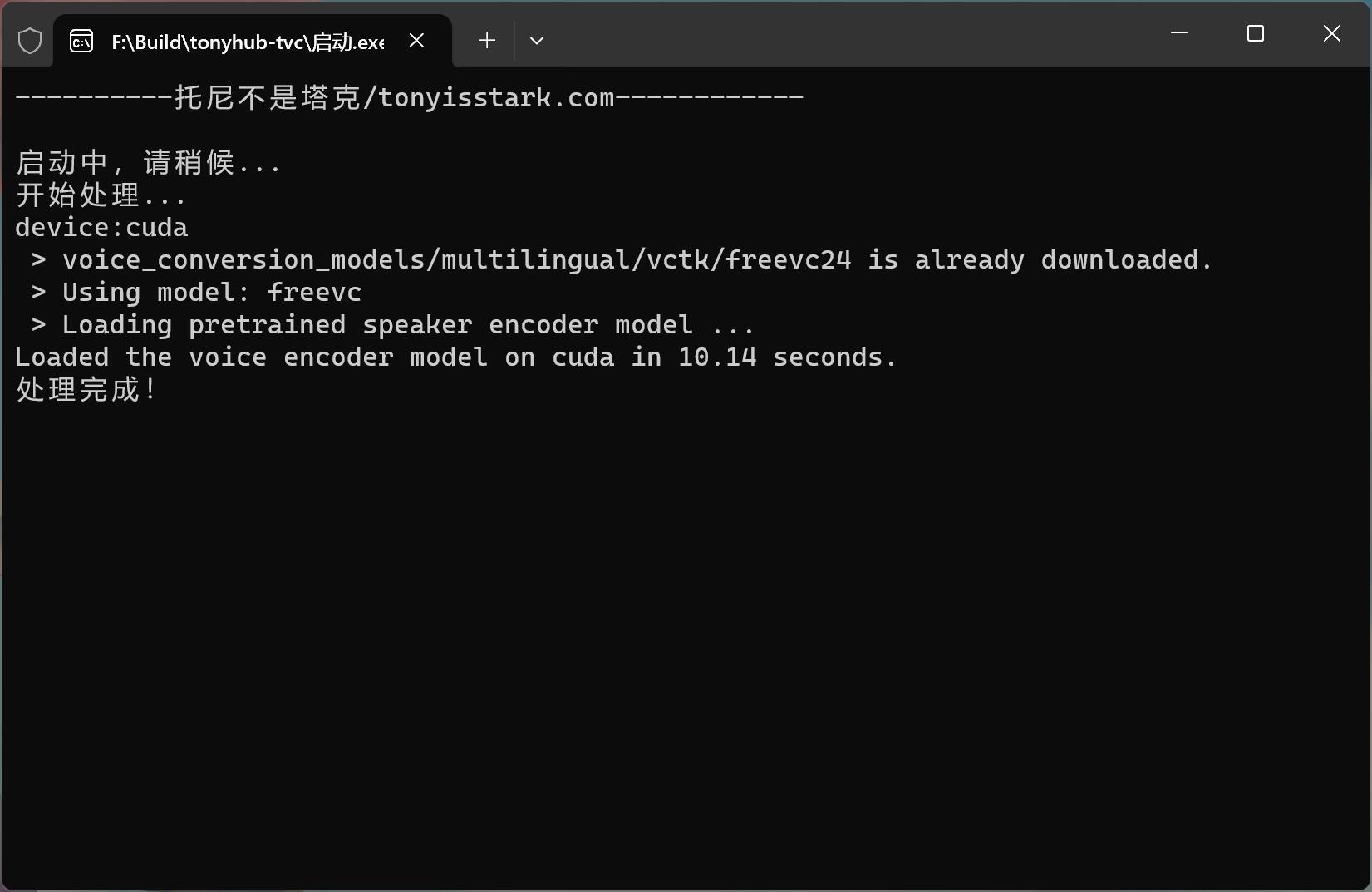
软件开始加载模型,处理声音,合成声音。几秒钟的音频,大概在几秒钟内就可以全部完成。除去加载模型的时间,实际使用的时间要短很多。
声音合成的步骤:
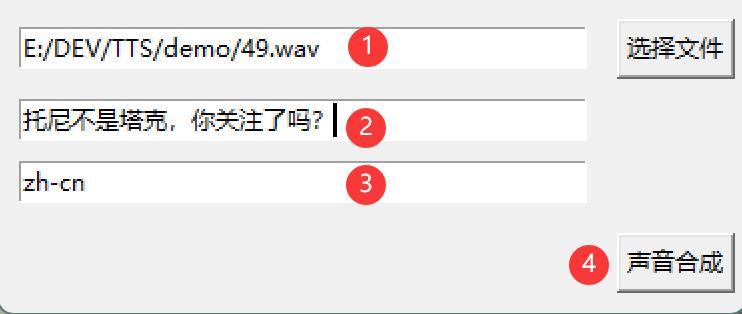
①点击选择文件,选择需要克隆的声音。
②输入想要说的话。
③选择语言,支持16中,默认是中文,如果英文就用en。
④点击声音合成。
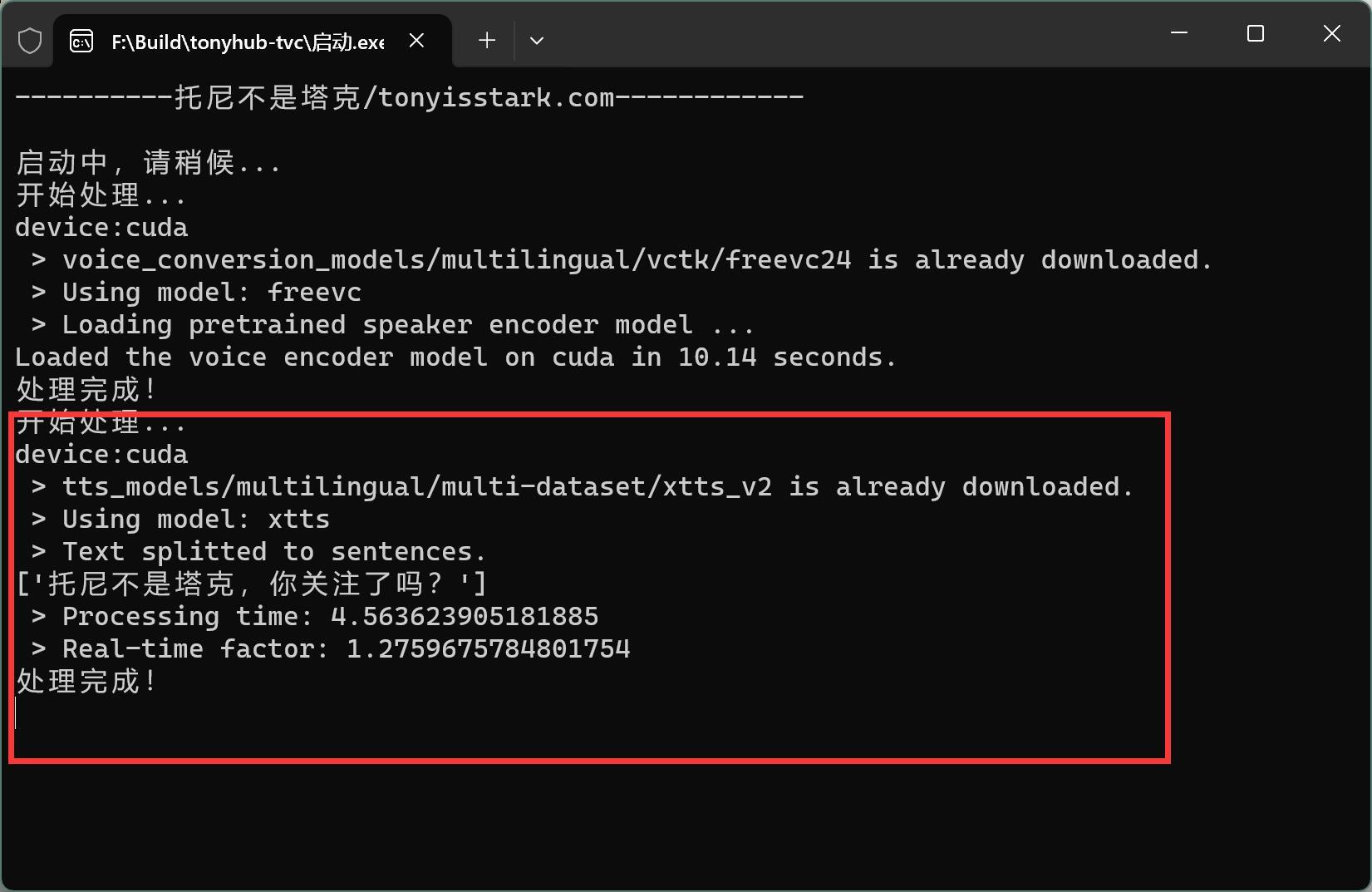
同样,按钮变灰色,防止误点和多点。完成之后就可以继续使用了!
相对一些视频类的项目,动不动就是几十分钟几个小时。这个语音项目处理效率还是非常高的。
这个项目也支持实时克隆,200ms延迟。
这些暂时就不展开了,立太多flag,容易把自己搞死。
这个软件的操作非常简单,我的目的也很简单,就是让关注我的人都可以很方便地搞起来!
软件肯定还有很多完善和扩展的空间。
如果有后续更新,我会分享在知识星球里面。
另外,这个软件支持显卡上跑,也支持CPU上跑。默认的逻辑是,有支持的N卡就在N卡上,没有就用CPU跑。
也就是大部分电脑都支持,有N卡的自然能跑得更快。
其他就不多说了,都在软件里了!搞起!
天太冷了,脑子快冻住了!显卡取暖!
获取方式,给公众号“托尼不是塔克”发“tvc” 就可以了!



关于作者
tony
某人