声音克隆:AI孙燕姿制作全过程记录!
关注我的老粉可能知道,我大概19年就开始研究“AI视频换脸”。当我第一次看到这项技术,就入迷了。扛着一张750ti就开干了。也深深地感受到,设备从来不是问题,热情才是最大的问题。



今天就来简单的给大家演示一下,如何用这项技术,克隆孙燕姿的声音,然后让她唱一首梁静茹的《勇气》, 我们来看看,一个五音不全,对音乐一窍不通的人,如何用最新的AI技术驾驭两个歌手。
梁静茹原版:
孙燕姿版本:
猜一猜:
这个用的是普通说话声音训练的,然后直接转歌声!
这里都是直接用的干声,配上音乐,用专业的工具润色一下应该会更好。仅做演示,就不搞太复杂了!
下面就说一下完整的流程。
环境配置:
制作这个声音克隆,需要自己训练AI模型,所以一台中高配的电脑是必需品。我的配置大概如下:
操作系统:Windows 11
显卡:RTX3060 12G
软件:一键运行集成包@羽毛布団。
操作流程:
1.收集素材
2.处理素材
3.训练模型
4.使用模型
因为有大佬已经制作了一键运行的软件包,所以安装配置这个环境就省了,可以省去好多时间,把门槛也降低了好多,软件包获取方式见文末。
下面就直接从素材处理开始讲了。
1.收集素材
所有的AI软件都需要模型,而所有的模型都需要用数据集来训练。要训练声音模型,自然需要用到很多声音素材。为了训练这个模型,我一一口气把孙燕姿所有的歌曲都找过来了。最终大概用了100+首歌曲,切出了几千个片段,最终筛选了2000+,初略看了一下估计有6个小时的时长。
现在找点东西也是不容易,最终还是花了点钱快速解决了。
我这个素材其实是搞得有点多了,刚开始没必要这么凶,搞个一小时左右就差不多了,核心原则还是保证数据集的质量。
2.处理素材
2.1 提取干净的声音
我们找到的都是歌曲,但是训练需要用干净的声音,所以需要进行预处理。我对音乐是一窍不通,什么配乐,和声,干声…现学现用啊。
提取分两步走,提取效果很不错。
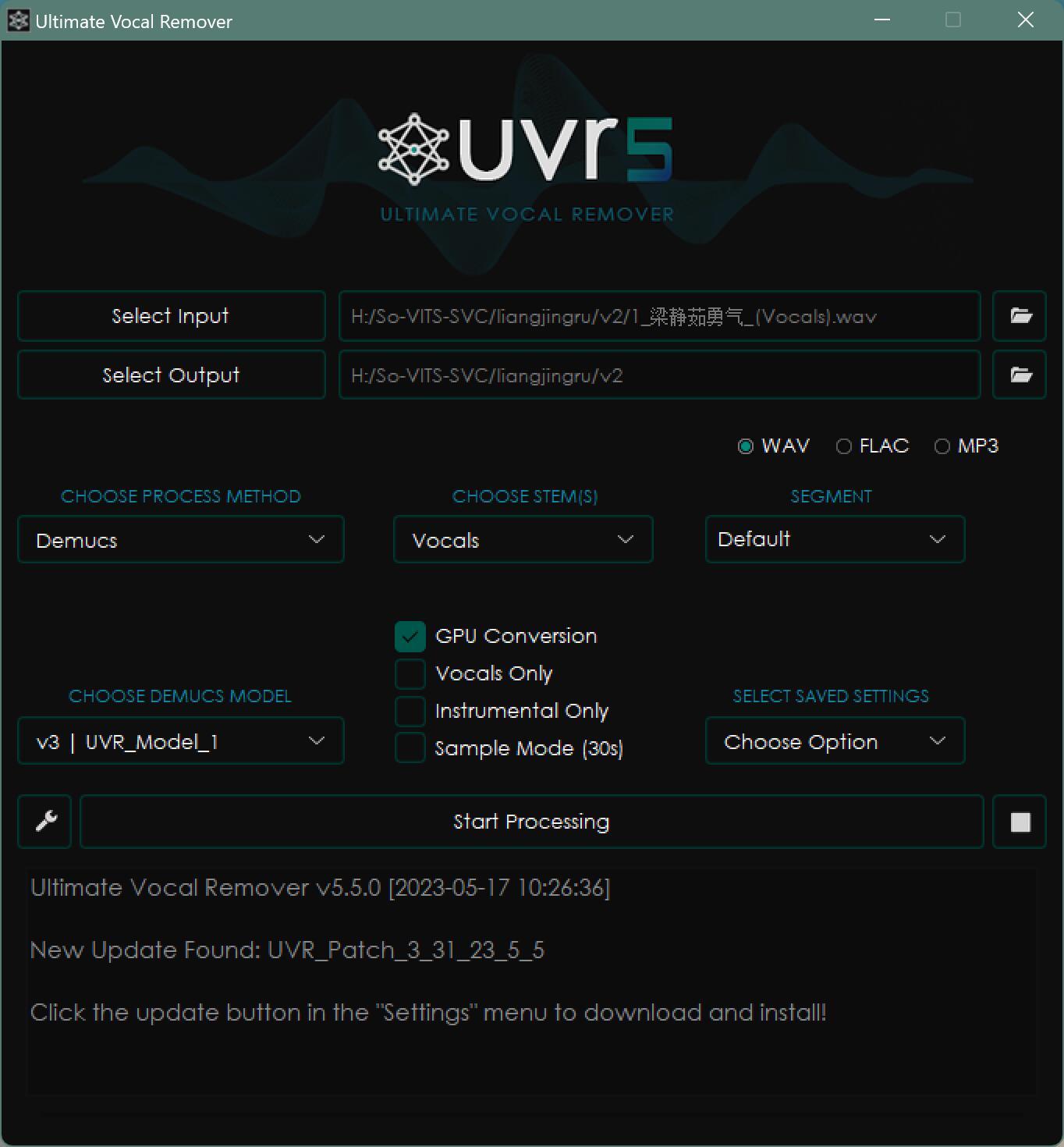
这一步使用的软件是UVR5(Ultimate Vocal Remover),看这软件的名字是“移除人声”,而我们偏偏它提取的人声,有意思!
第一步参数:
第二步参数:
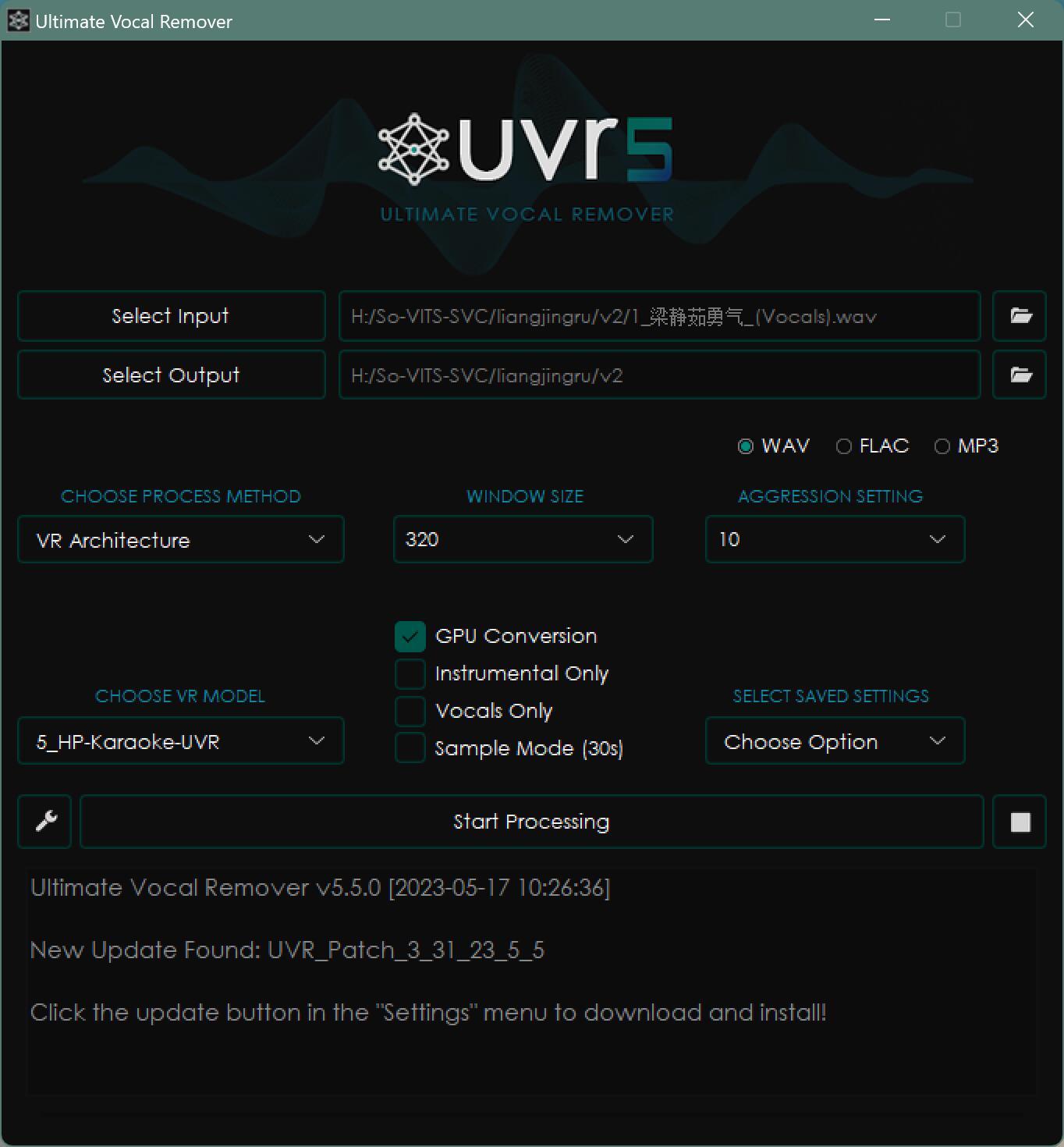
参数都在上面了,只要在软件里设置好输入(Select Input)的歌曲,和输出(Select Output)的路径,设置好参数,然后点开始处理(Start Processing)就可以了。
处理时间也还可以,大概在几分钟到几十分的样子,具体时间和素材数量有关。
这个软件的效果真是非常给力。可以比较完美的分离出人声和配乐,而且免费开源。
2.2 对声音进行切片
除了要干净的声音外,还要对声音进行切片。单个音频太长了,机器就会搞不动。
对声音进行切片,使用的工具是slicer-gui。这个软件可以根据停顿来切割音频,把没有声音的内容直接删除,也是一个很不错的工具。
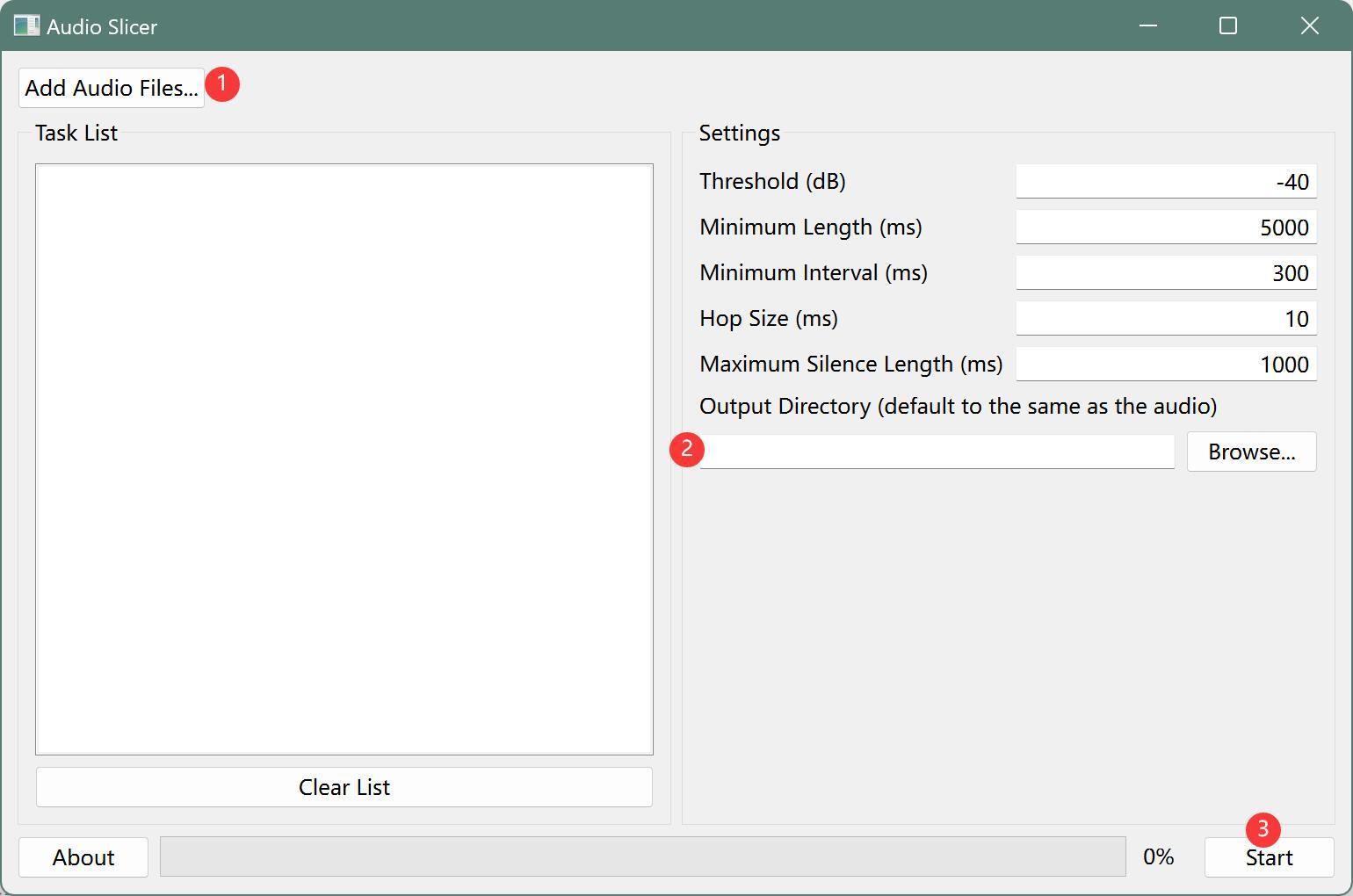
界面很简单,操作也很简单,处理速度也很快。
只要三步:
① 添加音频文件,点Add Audio Files
② 设置输出路径,点Browse…
③ 开始处理,点Start
切完之后,可以根据时长排序,筛选出3-15秒内的音频,然后把整个文件拷贝到软件里面的dataset_raw文件里。
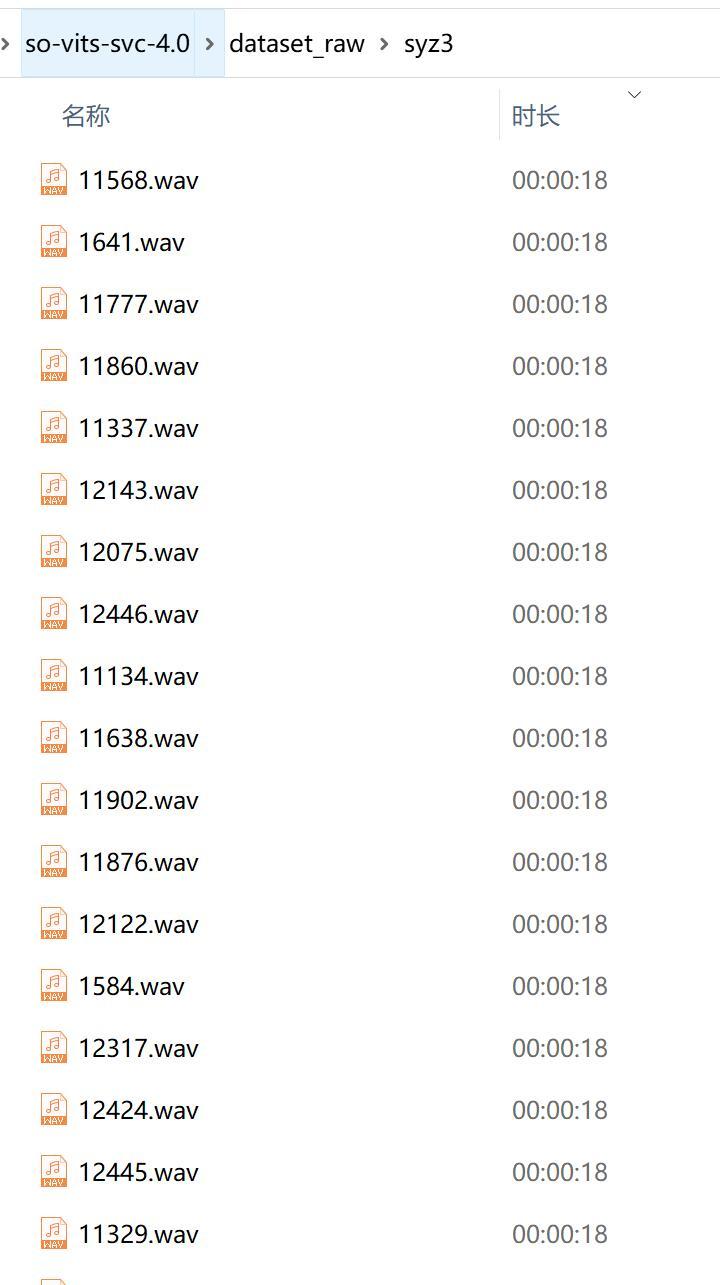
对于小于3秒的可以直接丢弃,对于大于15秒的可以二次切割。二次切割的时候改一下Mininum Interval 的数值,比如改成100ms。
这样素材就处理好了。素材是非常非常非常重要的一部分,这里不搞好,后面都白干。一定要用高品质的声音,而且要没有伴奏,没有和声,没有噪音,没有环境音,没有其他人的声音。
3.训练模型
素材处理完成之后,就可以进入“炼丹”环节了。模型训练里面还需要对素材进行预处理,然后设置好配置文件,然后就可以真的点火,炼丹了。
首先,点击软件里的 “启动webUi.bat” 脚本,BAT文件可以和EXE文件一样使用。

启动过程大致如下:
当看到 “URL: http://127.0.0.1:7860”就证明启动成功了,复制这个网址到浏览器打开,就可以看到界面了。
打开网页之后,先点击”训练“ ,然后点击识别数据集。
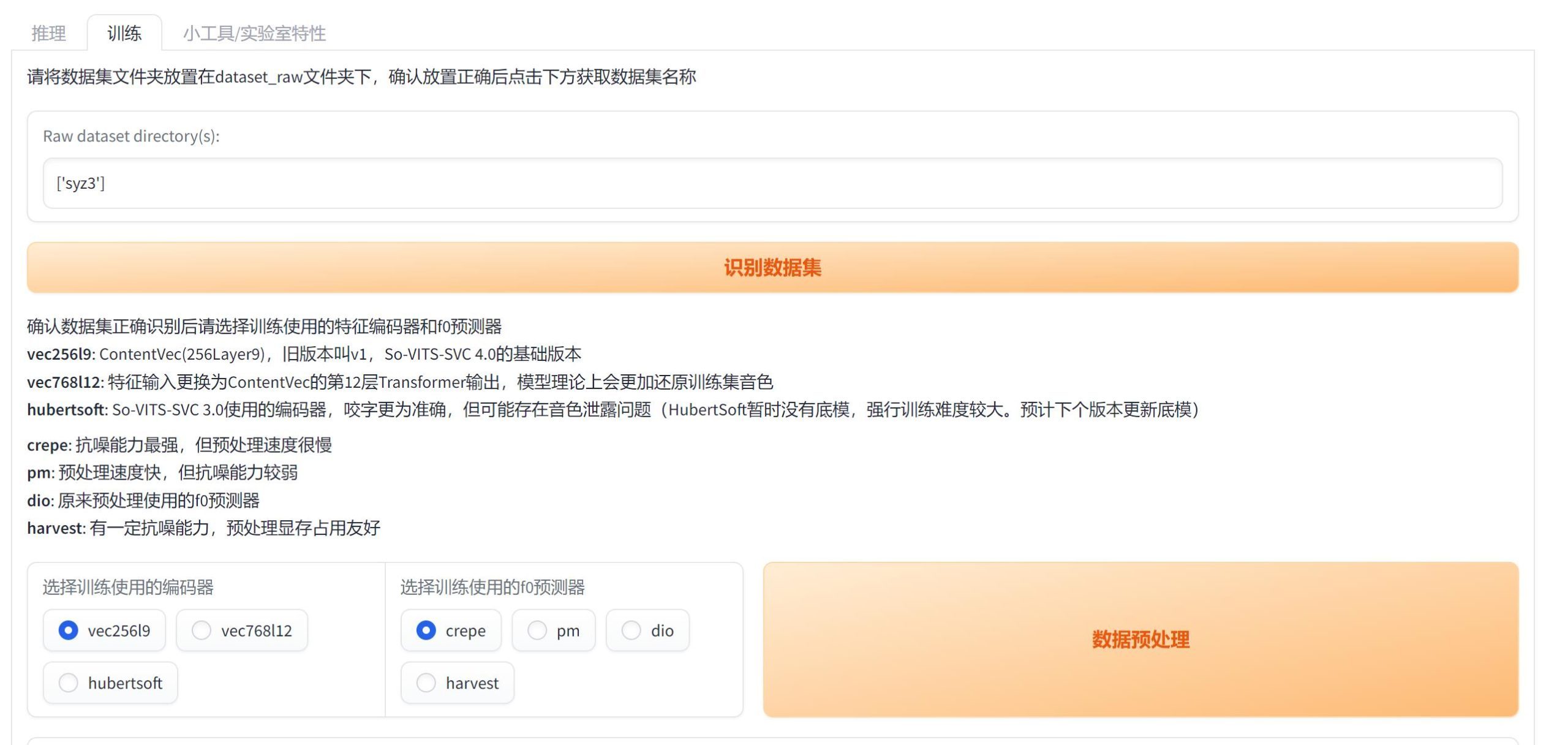
然后设置好“编码器”和“f0预测器”,关于如何选择上面有非常详细的中文提示。
设置好之后,点击”数据预处理”按钮,开始进行预处理。
这个过程大概几十分钟,具体要看你素材的多少和选择的参数。这里提一句,文件名最好是全数字字母,不要有“中文”,“()” 这些。系统自带的重命名工具会出(),可以找一个第三方的工具,我用的ReNamer。
接下来设置训练参数。如果没有特殊情况,你可以直接使用默认参数,点击写入配置文件。
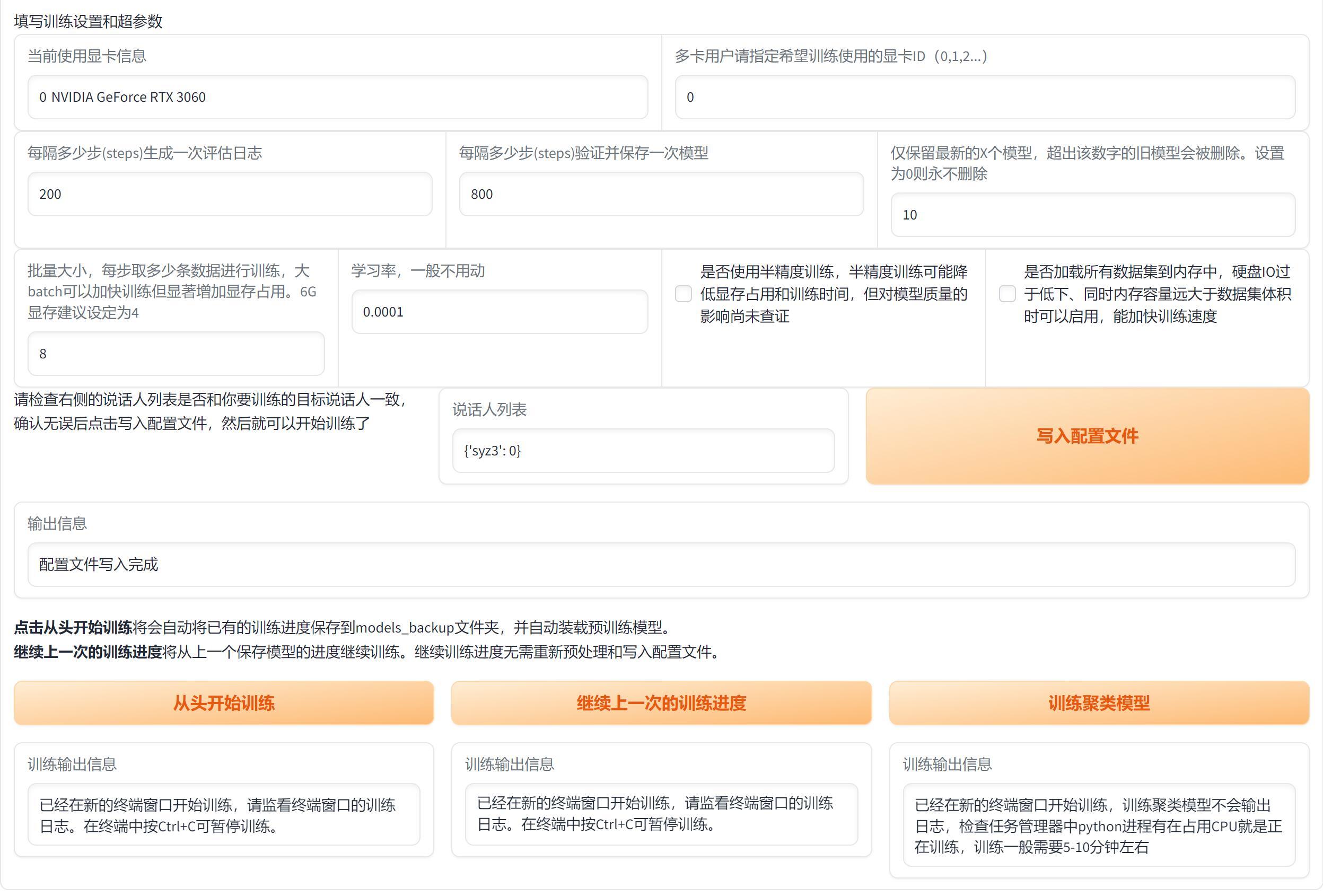
然后点击”从头开始训练“ ,会跳出一个单独的窗口,显示信息大致如下:
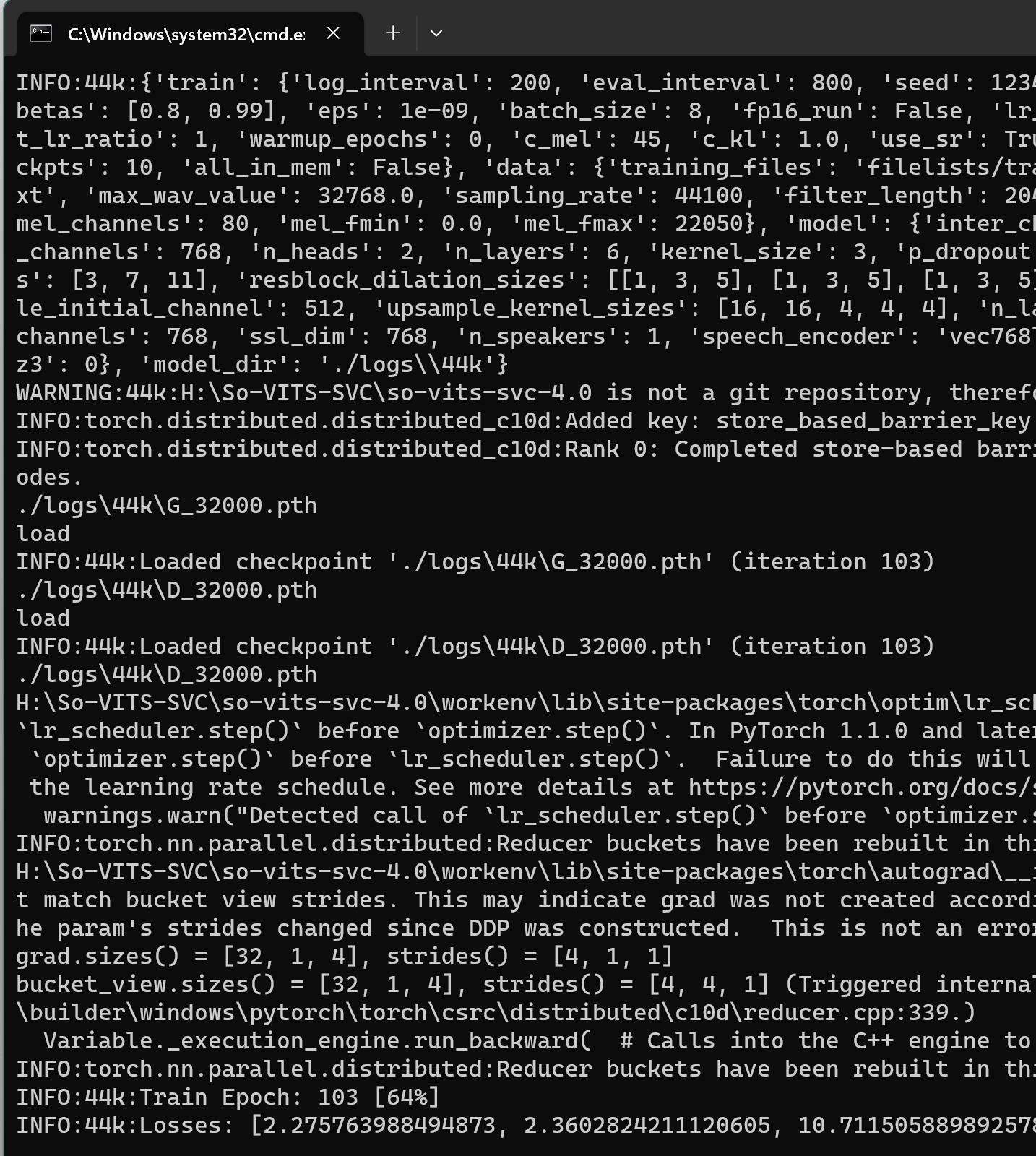
正常启动的话会写载入预训练模型,然后出现Epoch,Losses这些信息。
如果出现OOM,可以降低“批量大小” ,我的12G显存,跑默认批量大小会爆掉,所以就改成了8。
训练是一个漫长的过程,我前前后后训练了好几天了。这个算法其实还是很不错的,你训练的少点也能出效果,训练的长点自然效果更好。我大概每次训练几万个Step,感觉还有很大的提示空间,正在训练继续训练中…
下面说一下,如何结束训练,继续训练,训练聚类模型。
结束训练,如果你觉得训练的差不多了,可以按Ctrl+C 中断训练。
继续训练,下次要继续训练可以点击“继续上一次训练” 。
聚类模型, 这个东西目前来看可有可无。后面有些参数需要有这个模型才能启用。
4.使用模型
模型训练结束之后,就可以尝试使用一下,看看效果了。
点击“推理”选项卡。
选择“模型“和 ”配置文件“,其他会自动出现。如果没有候选项,可以点击一下”刷新选项“ 。
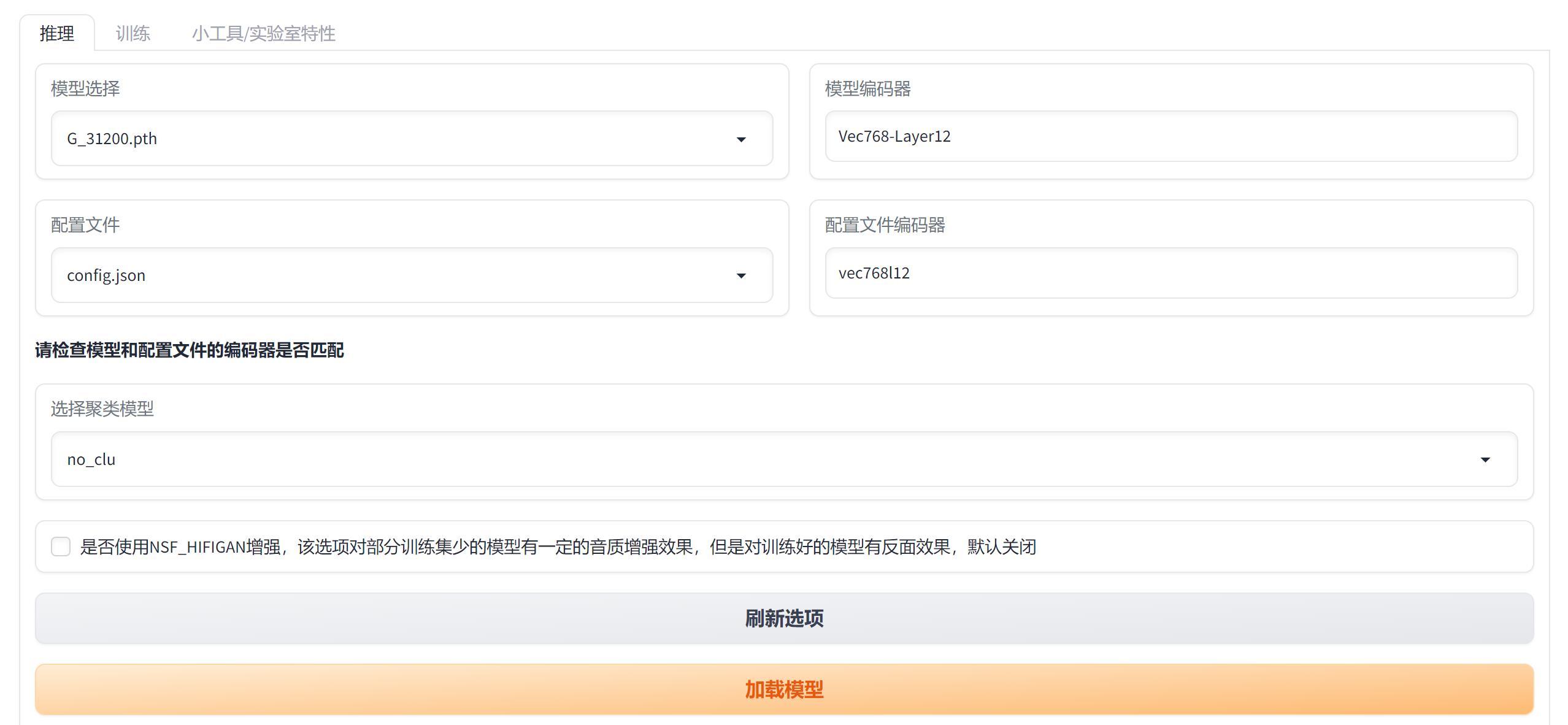
设置完成之后,点击“加载模型” 。
加载成功后会显示“音色”和 提示“模型加载成功” 。然后就可以上传音频开始测试了。
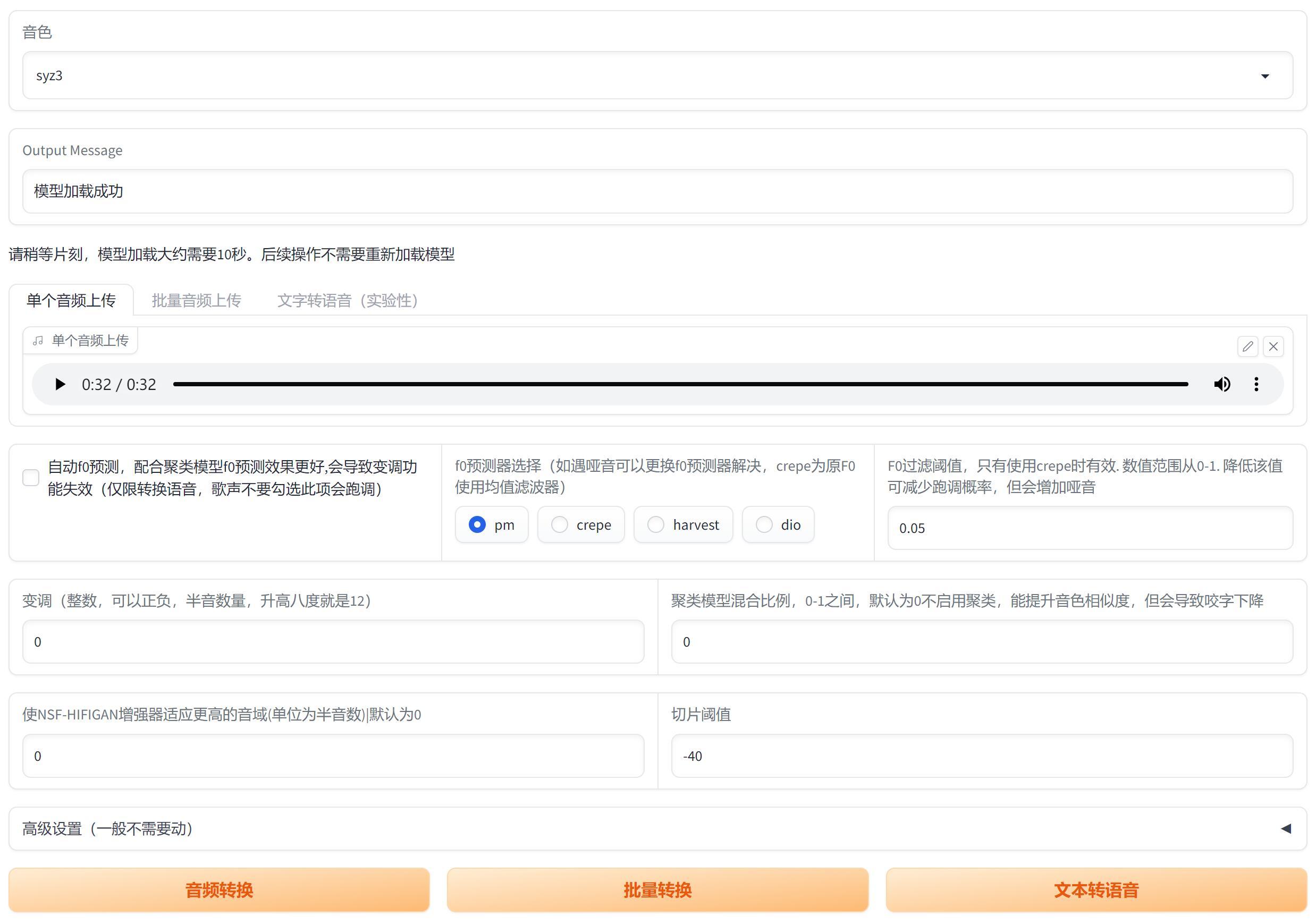
点击单个音频上传的区域,找到一个长度适中,已经处理的干声。上传完成后可以点击播放按钮,预览一下声音。
这里也有一些参数,还是那句话,如果你不是专业人士,默认设置就是最佳设置。不是唱歌,是正常说话的情况,可以勾选“自动fo预测”。
默认所有参数不动,直接点击音频转换,很快就能得到转换后的声音了。

同样点击播放按钮,就可以听到最终效果了。
我试了各种参数,各种步数,整体来说这个方案是真不错,大部分情况下都可以得到不错的效果。但是如果你特别有追求,那么永远都还有提升的空间,我第一次感觉不错,听着听着就总想去提升它…
核心的步骤和操作,都在这里了。细节,永远是说不完的。因为这次用的是集成包,所以那些Python,git,conda都不用搞了,对小白来说会比较友好,这得感谢各路大佬们的努力。
如果需要文中的训练数据和训练好的模型(仅供学习研究),可以考虑加入我的知识星球“TonyHub”,有啥问题我也会尽量回答。
当然,也欢迎加入我们的交流群相互交流。
一键启动的懒人包和里面涉及到所有处理工具,我都会直接发出来,只要在公众号“托尼不是塔克”发“孙燕姿” 就可以获取。

关于作者
tony
某人
hello nobody !