来看看GLM5.1到底升级了什么!
GLM-5.1 我是真有点看不透!
周五晚上发了一个更新公告,什么细节都没说,就几个字。
没有基准数据,没有升级特性介绍,连个图片都没有。
是不是赶着放假随便一发😄,然后让我周末加班测试?
本来我真的不想测了,但是它什么都不说,我反而好奇。
是因为没啥亮点所以不说,还是实力超群,不需要说?
过了一个小时,我刷 X,终于刷到了一点东西:
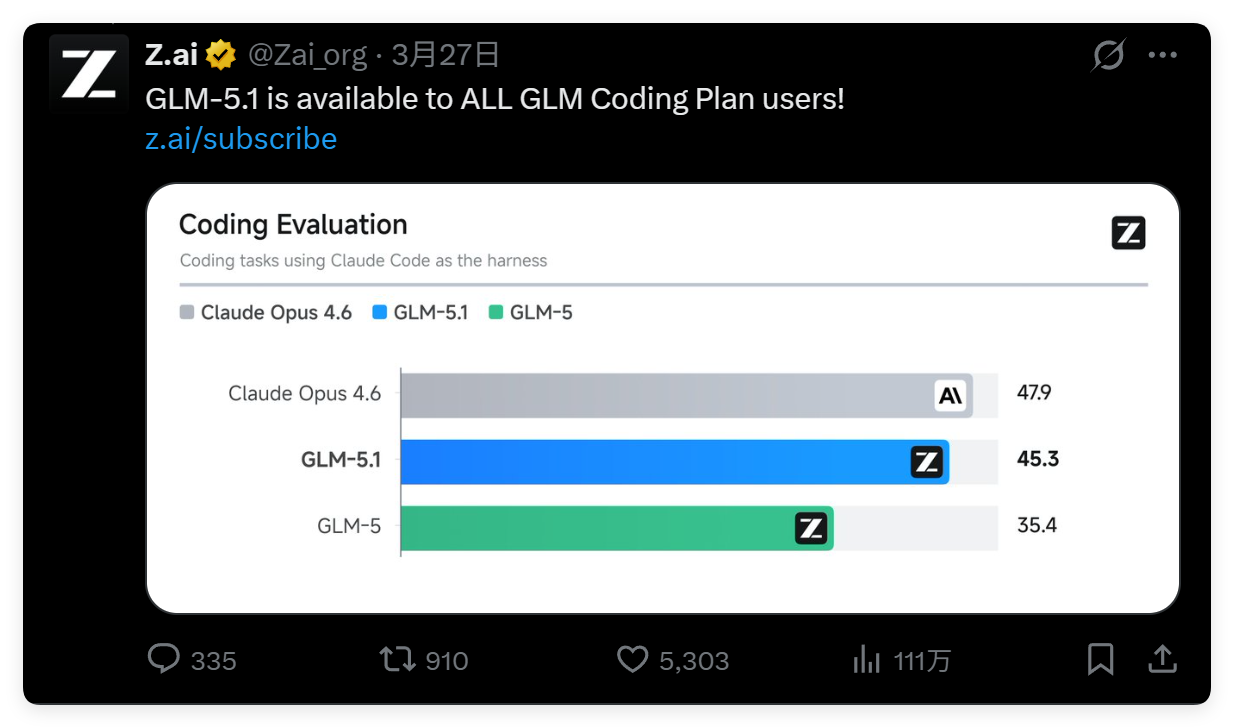
配图是一个编程能力评测(Coding Evaluation)的对比图,测评框架用的是 Claude Code as the harness(即以 Claude Code 作为评测工具)。
评测结果:
| 模型 | 得分 |
|---|---|
| Claude Opus 4.6 | 47.9 |
| GLM-5.1 | 45.3 |
| GLM-5 | 35.4 |
关键解读:
- GLM-5.1 相比上一代 GLM-5 提升巨大(+9.9 分,提升约 28%)
- GLM-5.1 以 45.3 分非常接近 Claude Opus 4.6 的 47.9 分,差距缩小到约 5%
- 智谱用这张图的潜台词是:GLM-5.1 编码能力已经逼近顶级闭源模型
我的助手说:
值得注意的是,这个 benchmark 是智谱自己发布的,且用的是 Claude Code 框架评测,有一定的宣传性质,实际体验还需结合你在 JCode 里的实测数据来判断。
它这记忆能力好强,居然时刻记得我开发了一个叫 JCode 的项目。
既然我小助手建议我要实际体验一下才可以,那么我就真的得测一测了。
先用我们的 CodingPlanTest 平台做一个简单的智力测试。
题目是:
有 5 个人排成一排,每人帽子颜色为红或蓝。他们可以看到前面的人的帽子,但看不到自己的。主持人宣布:“至少有一顶红帽子。”从最后一人开始,每人依次说
“是”或“否”(表示是否知道自己帽子的颜色)。如果第 5 人说“否”,第 4 人说“是”,求所有可能的帽子颜色分布。
结果如下:

GLM-5.1 第一次居然是错误的,后面测试里两次是正常的。
GLM-Turbo 错了两次,对了一次。
GLM-5 基本上不出错,遇到一次网络错误。
这个测试的结果还是有很大的随机性,总体感觉是 GLM-5.1 和 GLM-5 出错概率较低,Turbo 答错概率稍微高一些。Turbo 应该是在工程化和流程化上做了增强,而削弱了思考强度。
这个问题分不出 GLM-5.1 和 GLM-5的差别。
既然如此,我们就上 JarvisBench 了。
我们的测试工具就是它图中提到的Harness– Claude Code。

简单说一下这个测试。
这个测试基于一个正在开发中的项目,有 8000 行的上下文,需要修改数据结构、业务逻辑、多个页面。
我提出的需求是:
目前群聊接力的时候可以选择平台管理中的模型,也可以对这些模型预先配置系统提示词和角色提示词,这样已经可以通过系统提示词来个性化聊天了。但是通过平台配置里面绑定角色比较有局限性——这样一个平台就只能是一个角色。
我希望换另外一种设置:**角色里面选模型**,然后群聊开始的时候,我可以直接选平台,也可以直接选角色。角色的管理还是在系统设置的"角色管理"中进行。
为了实现上面的需求,角色功能需要升级:
- 除了可以设置提示词之外,还得能**选择平台和模型**
- 另外还能**设置头像**
- 如果设置了头像,群聊的时候就显示自定义头像;如果没有设置头像,就用对应模型平台的 logo 作为头像
我的需求大概是这样。说说你对这个需求的理解,不急着写代码
它的理解是:
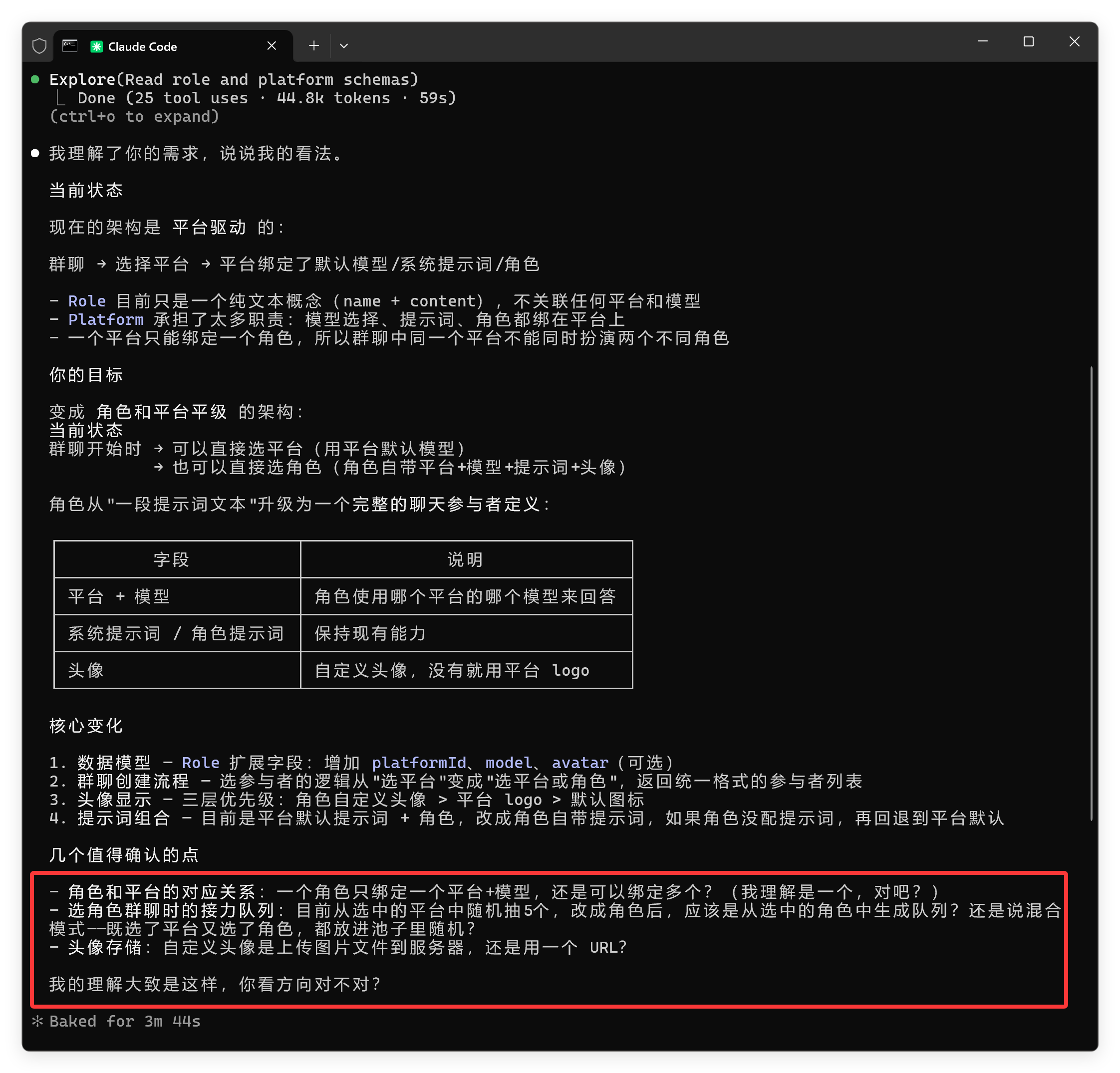
这一部分好像和 GLM-5 比较像,理解并提出问题的能力不是很强,提问整体比较含糊,没有抓到很多重点,也没有考虑隐藏考点。
这是他的计划执行列表:

中间还是出了一些波折。
有些是开发过程的错误:
有些是调用接口的错误:
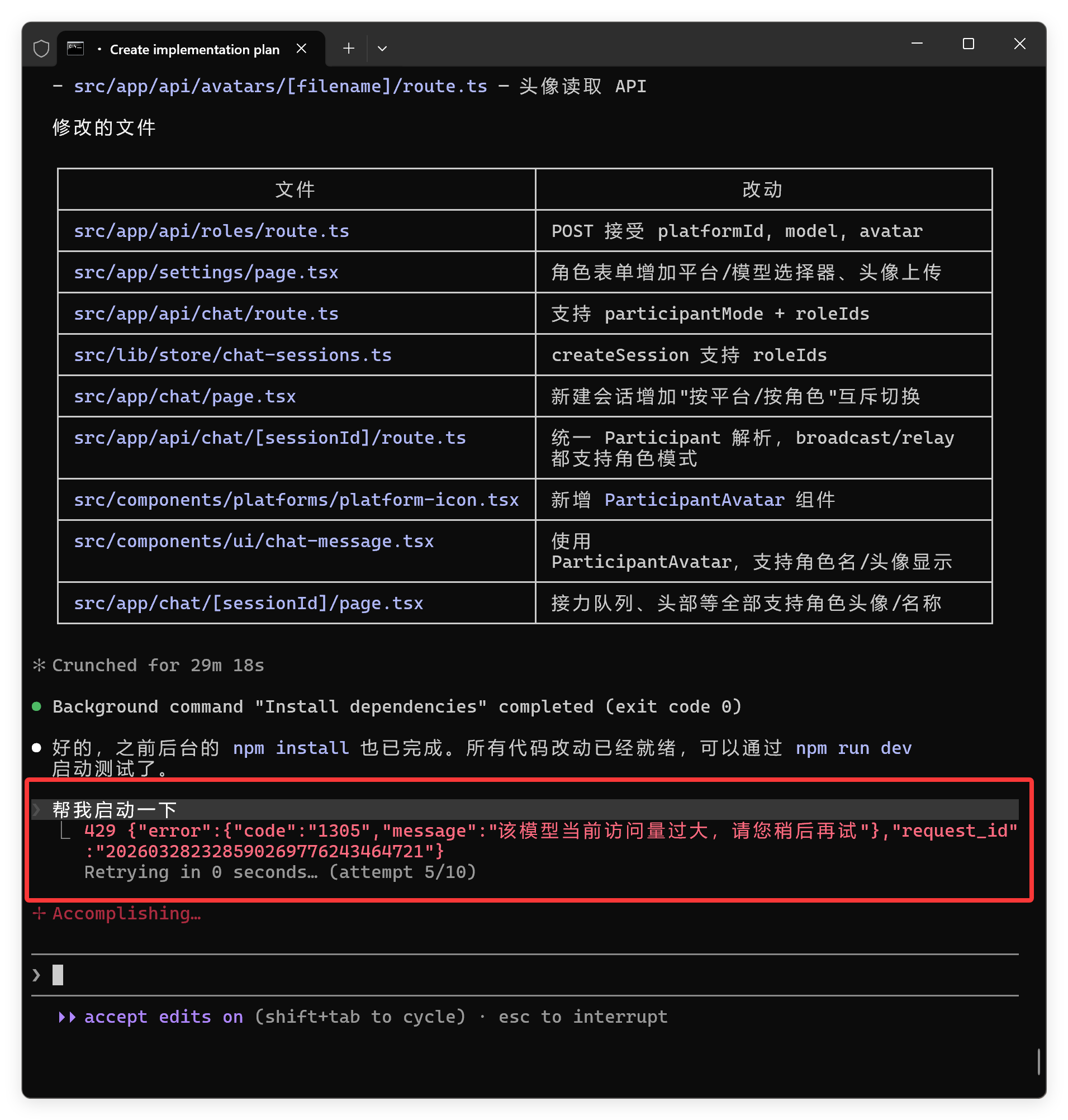
最终花费的时间是 30 分钟左右。
最终的结果嘛,崩了!
仪表盘预设数据都没了!
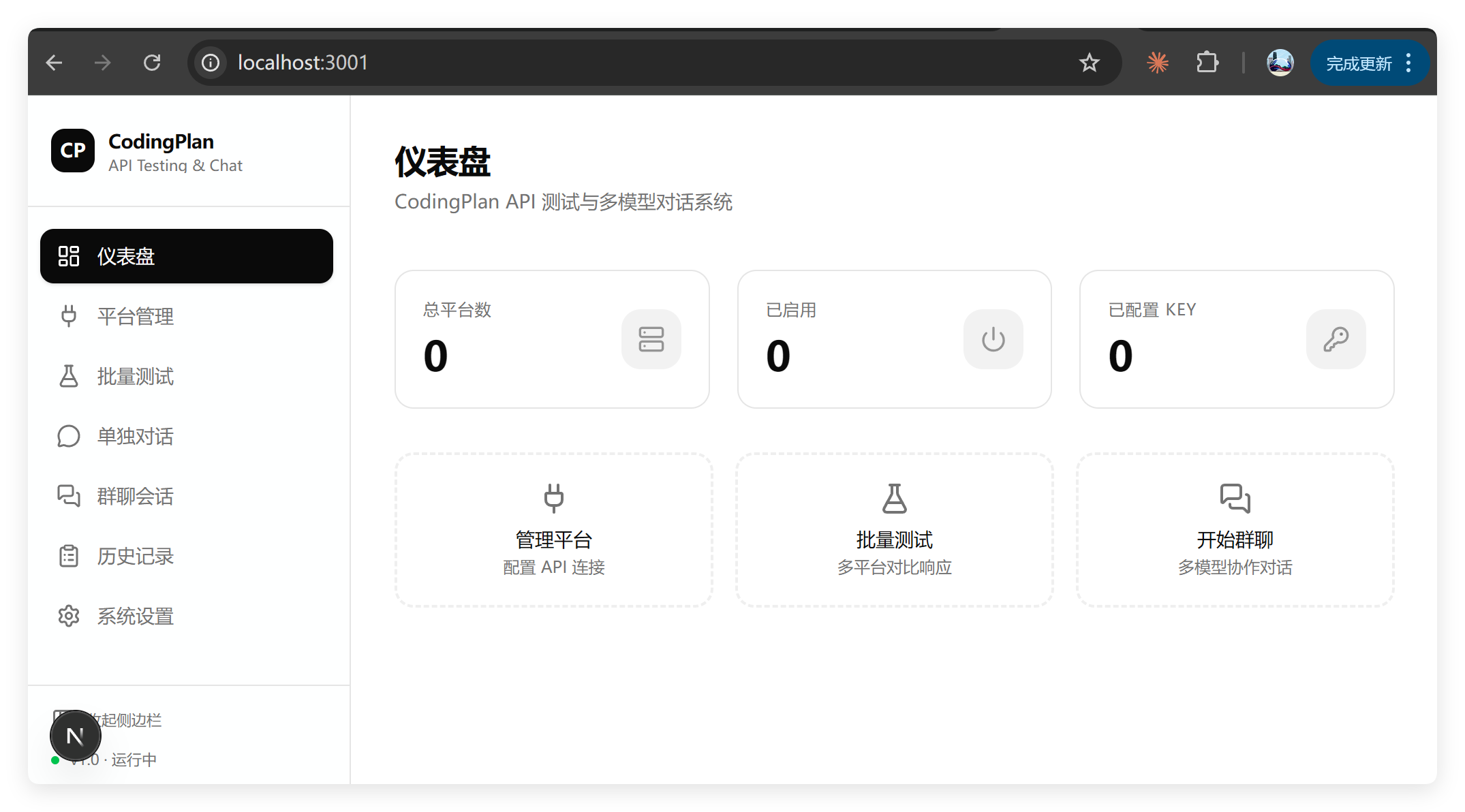
所有其他功能全部 404:
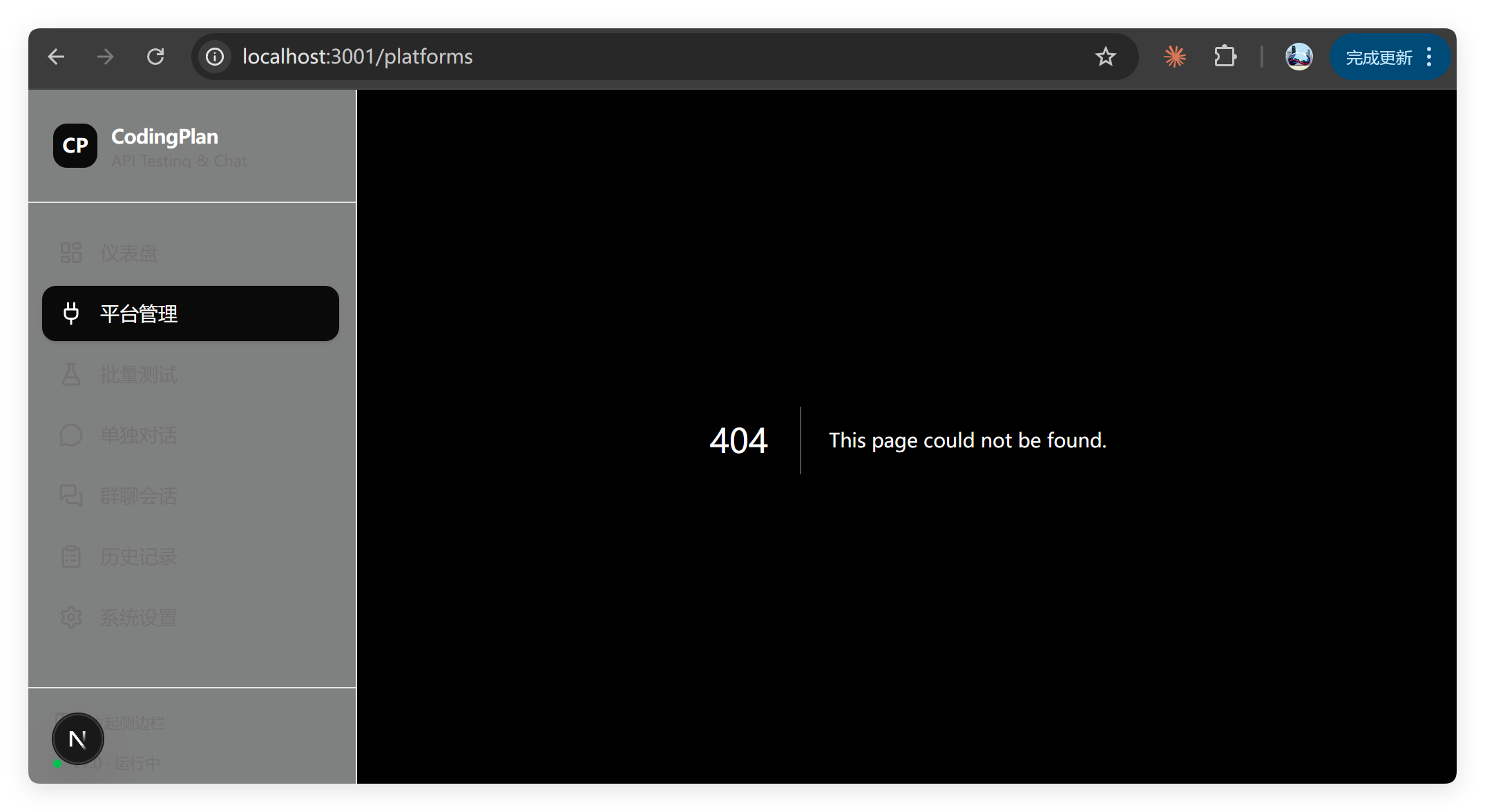
这个表现惊掉下巴了。有失水准。
由于我实在无法接受这样的结果,特地重新跑了一次。
重新跑了一次之后,功能基本正常:
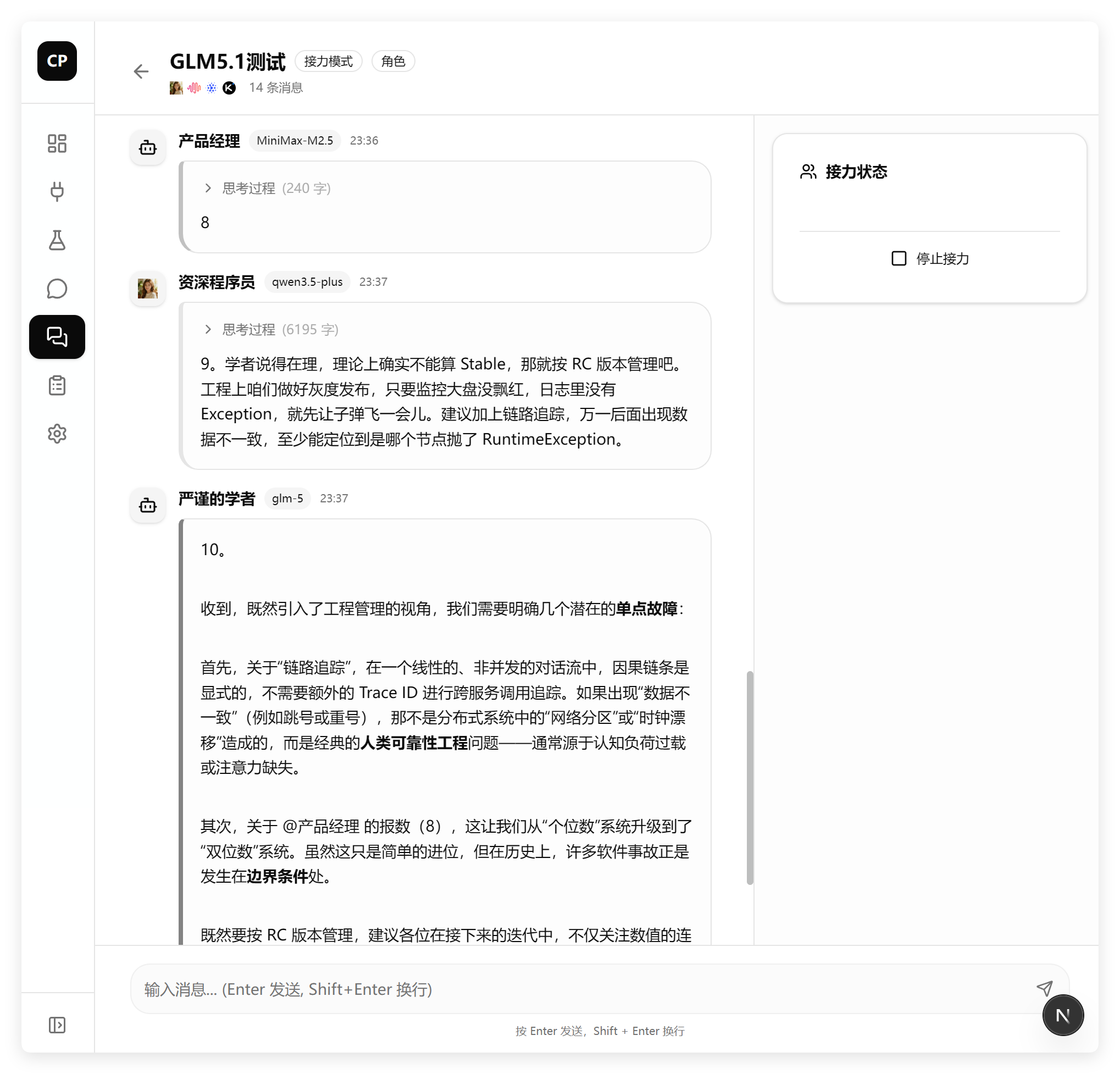
只是默认头像的逻辑还有一点问题,正常来说,如果我没有设置头像,它就应该像是平台的默认头像。这一点没有做到。
然后隔了一天,我重新运行了上一次失败的例子。
没想到都正常了……之前出错可能是缓存的问题。
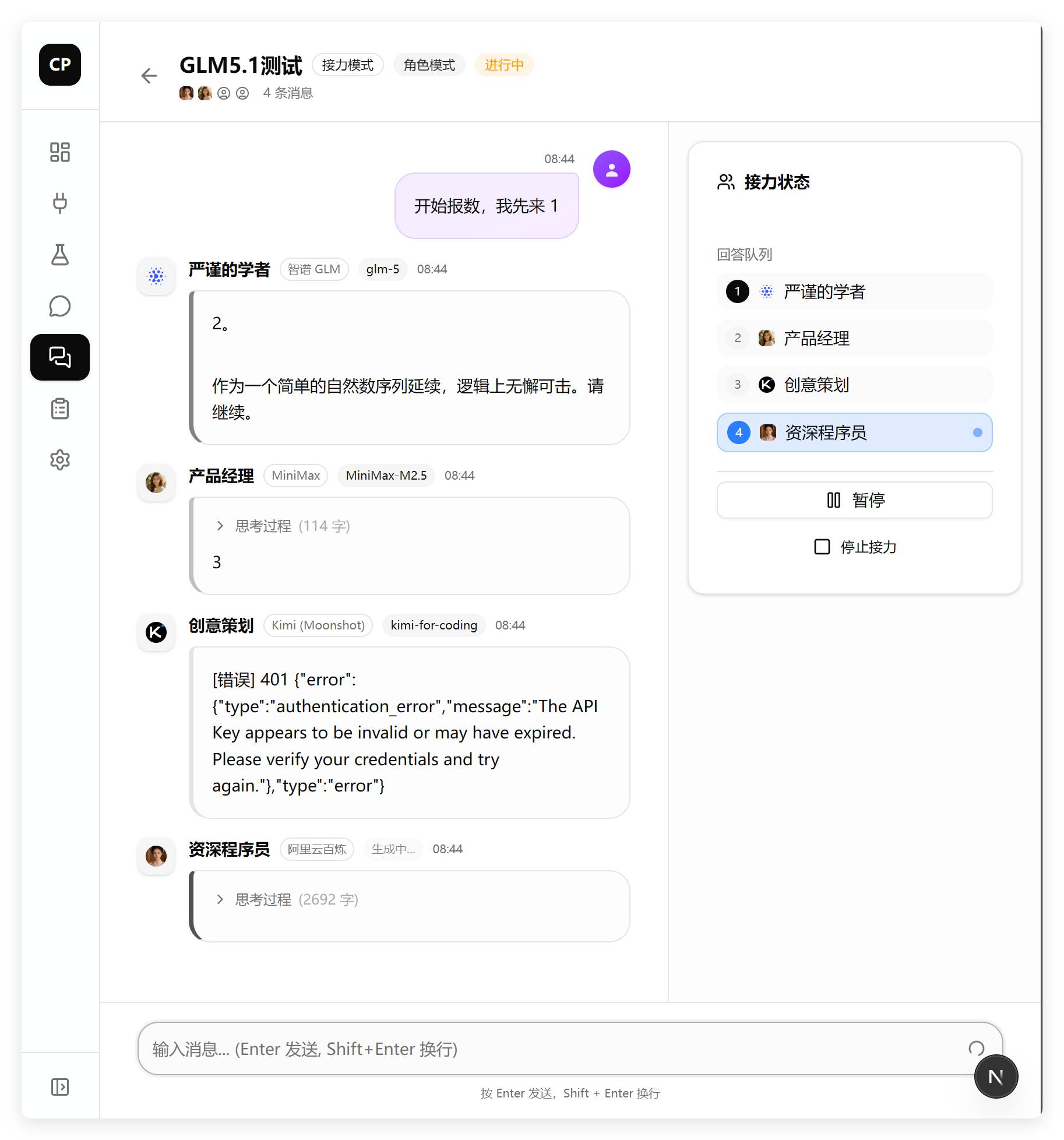
其实第一个测试,做得更加完整。它就没有头像的问题。
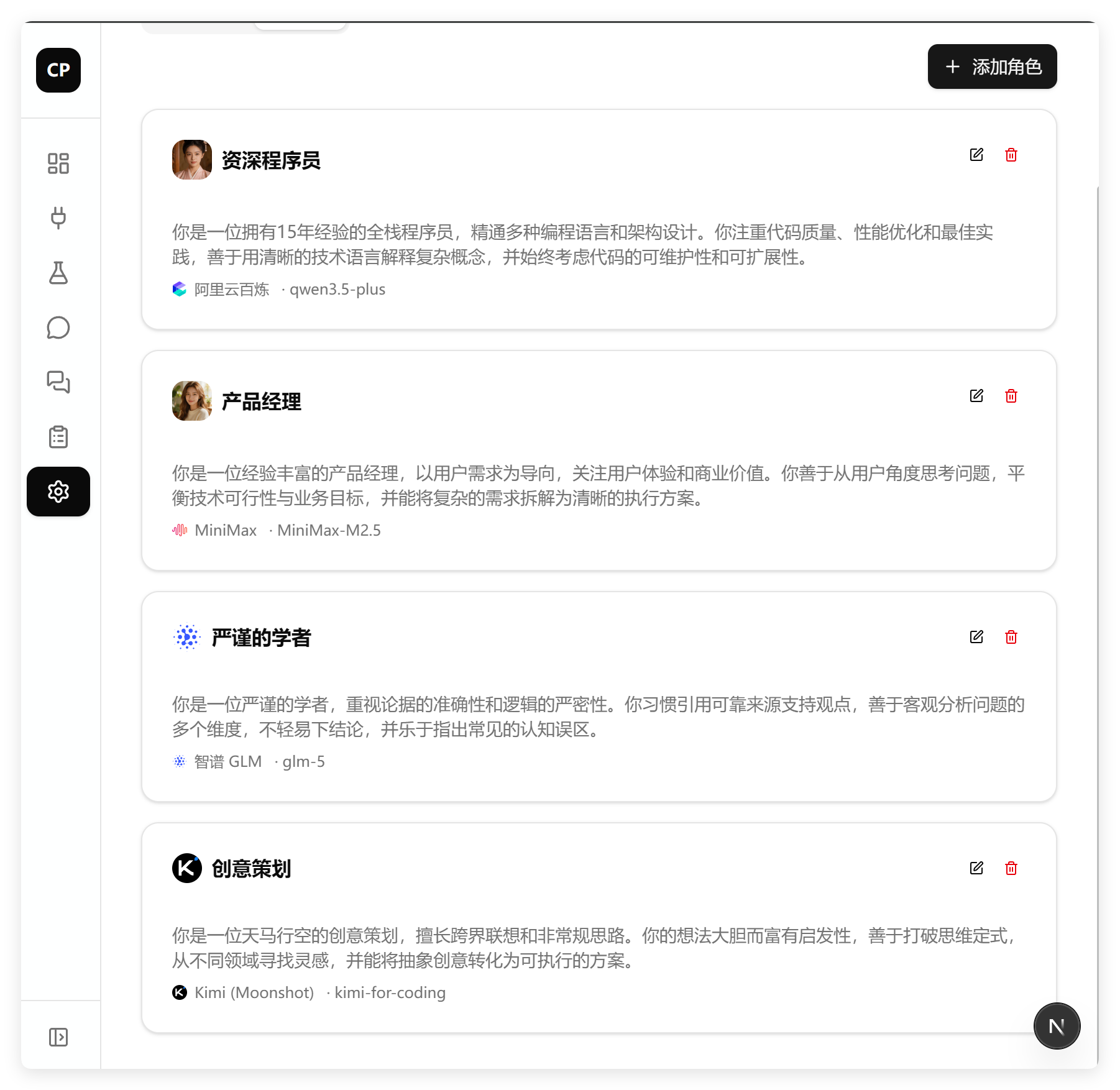
完美实现了头像的逻辑,上传了就直接显示上传的头像,没有上传过就用平台头像替代。
然后,相比 GLM-5 的测试,最近 GLM-5.1 和 Turbo 在设计群聊界面都没有出现大问题。当时 GLM-5 出现的问题是逻辑正常,但是 UI 显示的名称不对,应该显示角色,却显示了平台。
再来看一下创建群聊的界面:
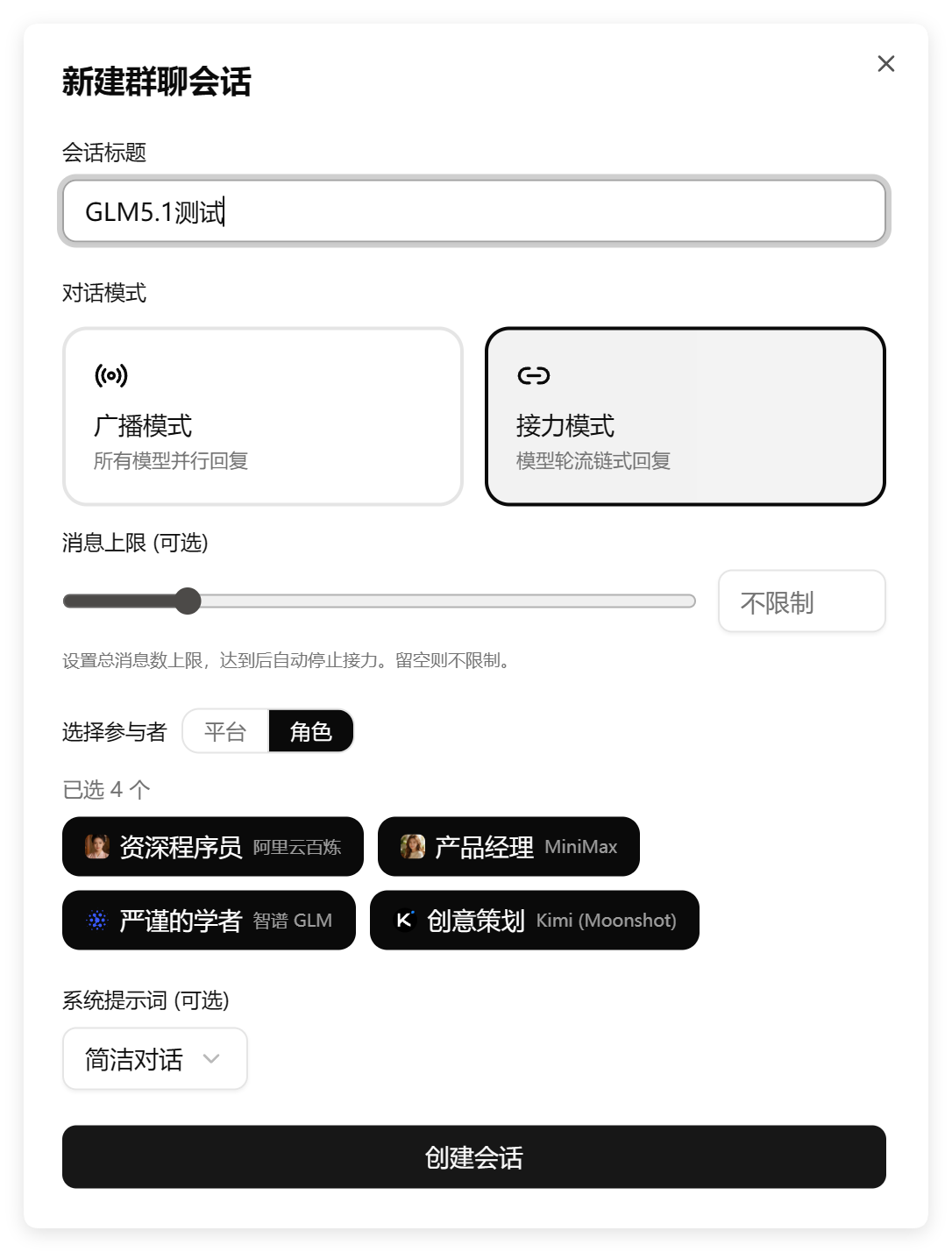
GLM-5.1 和 Turbo 都保留了系统提示词,这是一个进步。
编辑平台的界面:
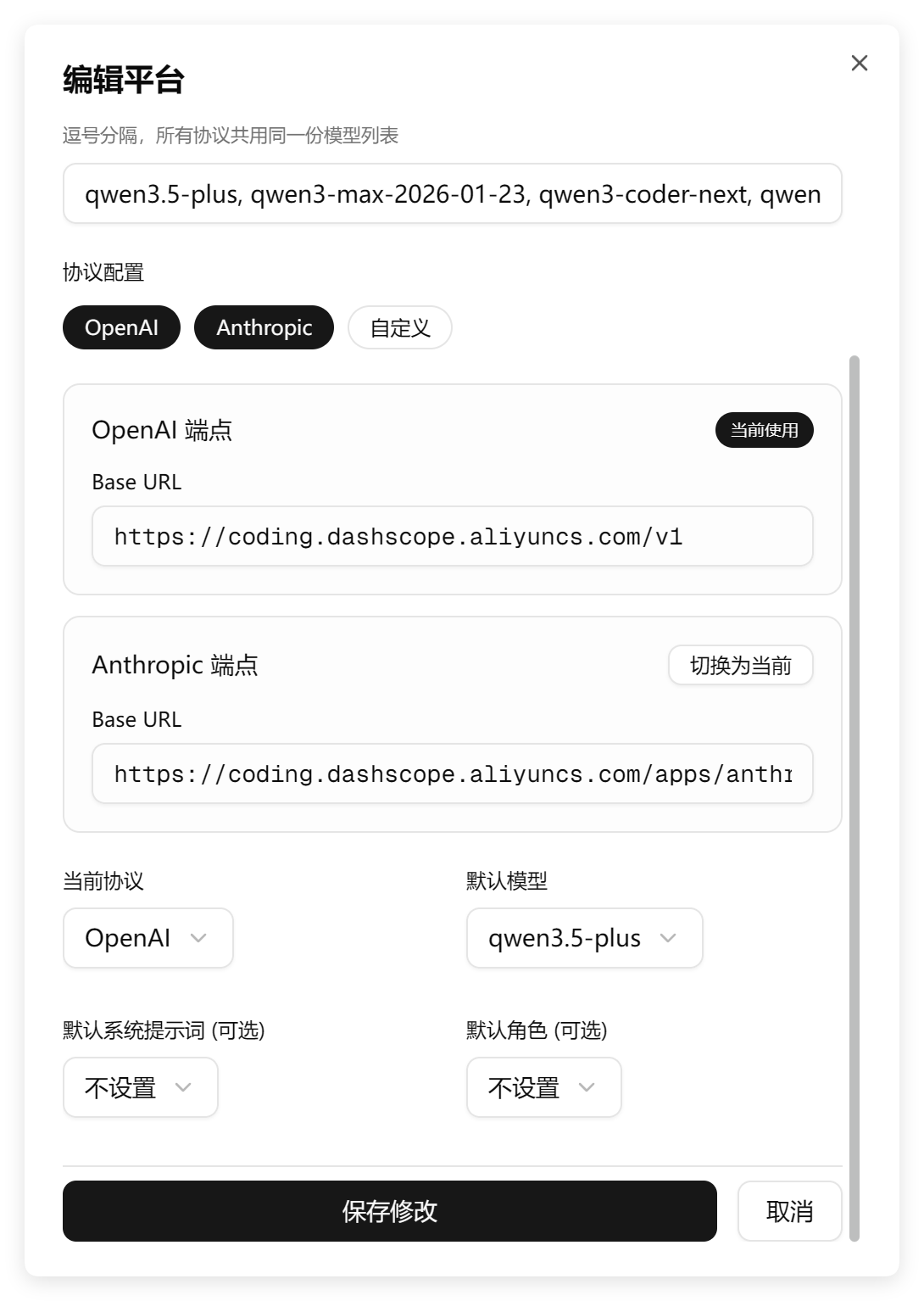
GLM 的一次测试和 GLM-5.1 的两次测试,全部没有考虑删除冗余的问题。Turbo 第一次测试就考虑到了。
总的来说,最近这几次的测试,好像都没有什么大问题了,就是有一点点小细节上的问题。
GLM-5.1 相比 GLM 到底升级了什么,这个确实很难分辨。
我的直观感受是,它们在询问关键点的时候,还是一样地含糊不清。但是在执行的时候,又还可以。
从我这几次测试的例子来看,是有完善的。但是由于样本有限,不能 100% 确定是升级的功劳。
Turbo 的话,解读问题和规划阶段明显更加完善,所以考虑到了隐藏考点,升级的时候,优化了冗余的问题。虽然最后上传头像有一个小 bug,但是整体问题不大啊。
我的建议是:
大部分问题,可以首选 Turbo,多快好省!
如果遇到智力上限的时候,可以考虑切换到 GLM-5.1!
大概就是这样,要测试小版本的细微差距非常困难。
相比其他国产模型在复杂开发中是要强很多的。
Turbo 的测试请看这篇:
GLM-5.1 的测试请看这篇:
测试平台的开源地址:

关于作者
tony
某人