Wan2.2 文生和图生视频本地配置记录!
我已经在网上刷了无数 Wan2.2 生成的热门视频了。
很有看点,尤其是角色替换和动作同步。
把两个视频放在一起对比,确实比较震撼。
另外,开源模型,还有一大优势,可以制作不适合在工作时间看的视频(拉到最后有惊喜!)。
在线的已经玩过好多次了,今天终于准备动手在本地部署了。
然后把过程记录一下并分享给大家。
先来说如何装,然后我出一键包。
Wan2.2简介
Wan2.2 是 Qwen 推出的开源模型,具备以下特点:
🎬 电影级美学控制:具备专业的摄影语言,支持光线、色彩、构图等多维视觉控制。 🕺 大规模复杂动作:可流畅还原各种复杂动作,增强动作的可控性与自然度。 🧠 精确语义一致性:具备复杂场景理解与多目标生成能力,更好地还原创作意图。 ⚙️ 高效压缩技术:5B 版本采用高压缩比 VAE,进行内存优化,支持混合训练。
Wan2.2 并不是一个模型,而是千问推出的一系列视频生成模型。
其中主要包括:
| 模型 | 描述 | |
|---|---|---|
| T2V-A14B | 文生视频,支持 480P & 720P | |
| I2V-A14B | 图生视频,支持 480P & 720P | |
| TI2V-5B | 混合模型,同时支持文生视频和图生视频,支持 720P | |
| S2V-14B | 语音驱动视频模型,支持 480P & 720P | |
| Animate-14B | 角色动画与替换 |
这里可控性强,可玩性高的是属于后面两个模型。前面的模型自由度大,抽卡空间大。
这篇文章先来讲前面三个模型的安装和使用。
安装配置有很多种方法,可以完全遵循官方 GitHub 的配置方式,使用代码和命令运行。
但是对大部分人来说不推荐这种方式。现在最佳的方式是使用 ComfyUI,这样就不需要自己进行复杂的依赖安装了。只需要下载模型,安装插件,然后一键运行工作流就可以了。
以 Wan2.2-TI2V-5B 为例,ComfyUI 官方已经原生支持。所以你只要下载好模型,获取工作流,直接运行即可。
不需要安装任何第三方插件。
1. 安装 ComfyUI
ComfyUI 现在的集成度已经非常高了,早就推出了 Windows 版和 Mac 的安装包。也可以使用开源社区的便携版。
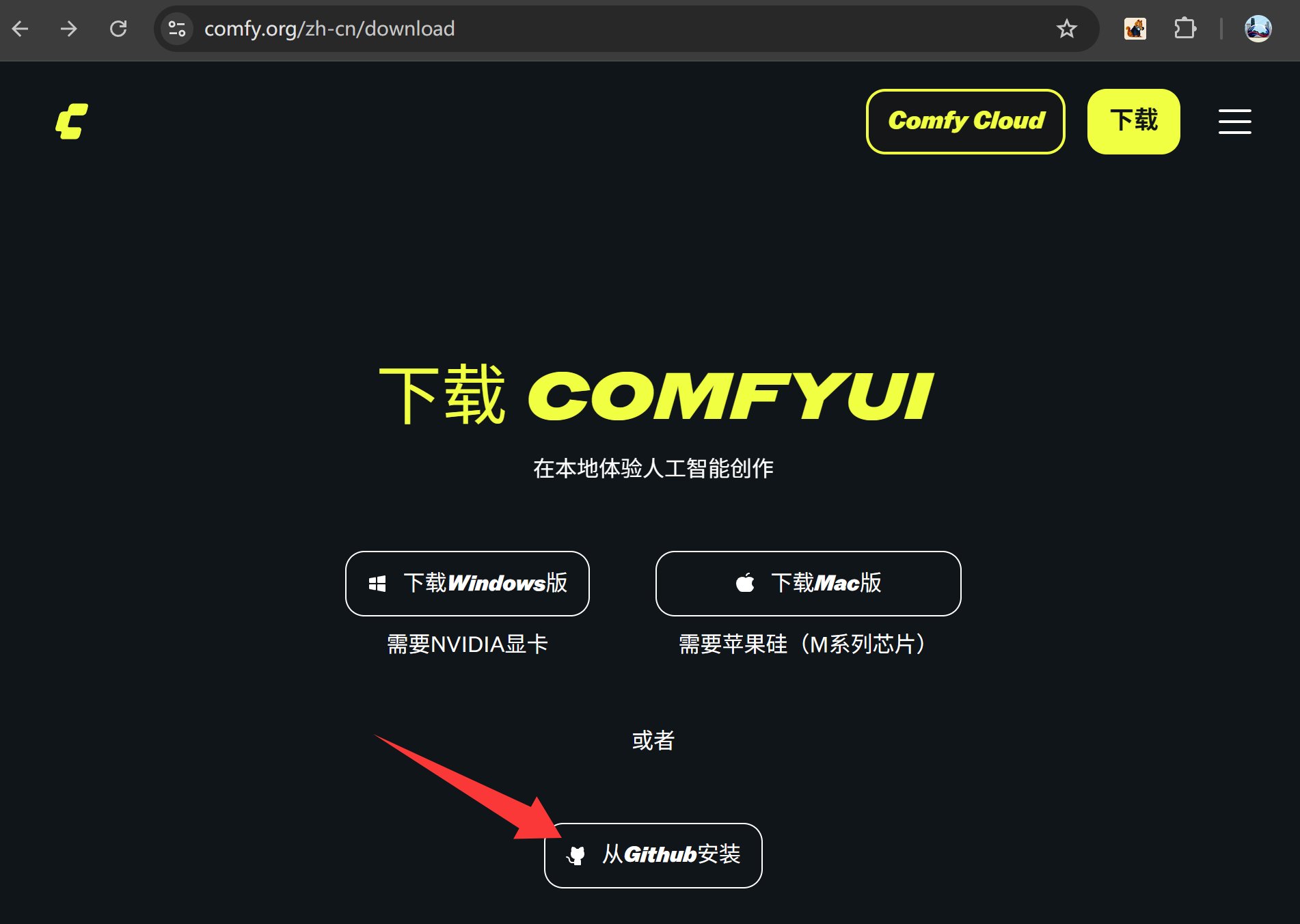
便携版可以理解为一键包,或者绿色版。我比较喜欢这个版本,所以以这个版本为例,完整记录配置运行 Wan2.2 的过程。
打开 ComfyUI 的 GitHub 主页,找到 Windows Portable,然后点击 Direct link to download 就可以下载到一个 zip 文件了。
也可以直接点击打开这个地址:
这个是一个 7z 格式的压缩包,只要使用任意解压软件,解压到文件夹就可以了。
下载到本地之后,把文件放到某个文件夹里面,我 C 盘是 1T 的 SSD,所以我为了图方便图快就直接放在 C 盘的 Build 文件夹里面了。推荐大家放在 D 盘根目录,或者某个英文文件夹,比如名为 AI 的文件夹里。
然后右键这个压缩文件进行解压。
Windows 系统自带解压功能,可以直接右键,全部解压,选择解压路径,然后提取。
推荐使用第三方软件 7z。免费开源绿色无广告,解压过程不占用 C 盘空间。
7z 解压的步骤大概是,文件上右键->(显示更多选项)->7-zip->提取到当前位置。
解压完成之后就会得到一个 ComfyUI_windows_portable 的文件夹,文件夹里面的内容如下。
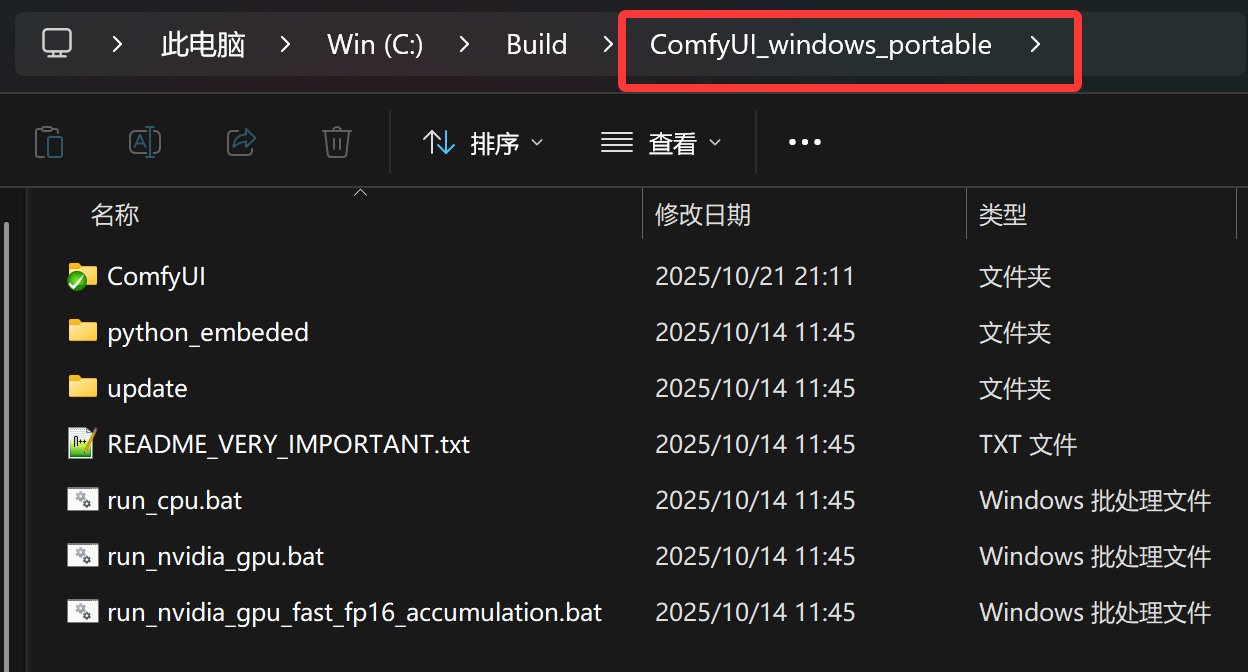
点击 Run_nvidia_gpu.bat 就可以启动了。
如果你之前玩过 ComfyUI,那么只要直接升级一下即可。
升级脚本在 update 下面。
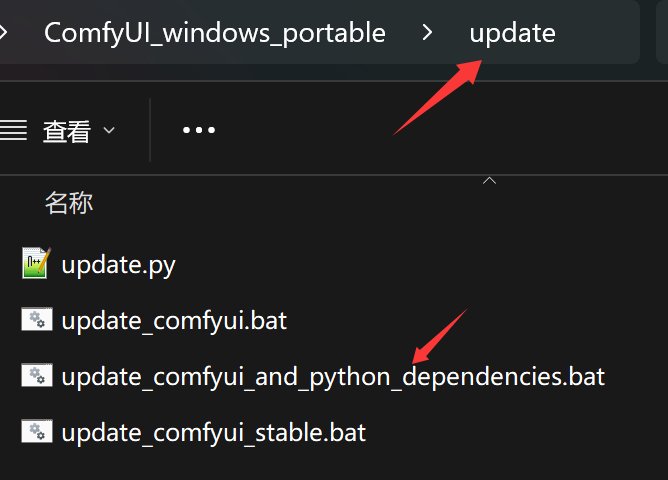
保持网络通畅,点击红色箭头所指的 bat 脚本,就可以一键升级了。
2. 下载模型
软件安装或者升级完成之后,就可以运行软件了。
我们可以直接运行软件,打开官方自带工作流,然后下载模型,运行工作流。也可以先手动把模型下载好之后再打开工作流。
我们需要用到的模型主要有三个:
Diffusion Model:wan2.2_ti2v_5B_fp16.safetensors
Text Encoder:umt5_xxl_fp8_e4m3fn_scaled.safetensors
模型下载完后存放路径如下:
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ └───wan2.2_ti2v_5B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan2.2_vae.safetensors
在我们软件的解压文件中找到 ComfyUI 这个文件夹,然后找到它的子文件夹 models。
我们下载的文件都是放在这个文件夹下面的特定文件夹里。
上面写得很清楚,分别放到 diffusion_models,text_encoders,vae 这三个文件夹下面。
3. 打开工作流
模型下载完成之后,就可以打开工作流了。工作流是 ComfyUI 的核心内容,使用工作流可以快速复用别人的成果,也可以自己构建复杂且可以快速重复执行的流程。
ComfyUI 对 Wan2.2 的支持非常迅速,早就内置了相关节点和工作流。
直接点击 run_nvidia_gpu.bat 启动程序。

一般是点击 GPU 这个,需要你的电脑拥有大显存的英伟达显卡。
点击之后就会出现黑色窗口,并且输出如下内容:
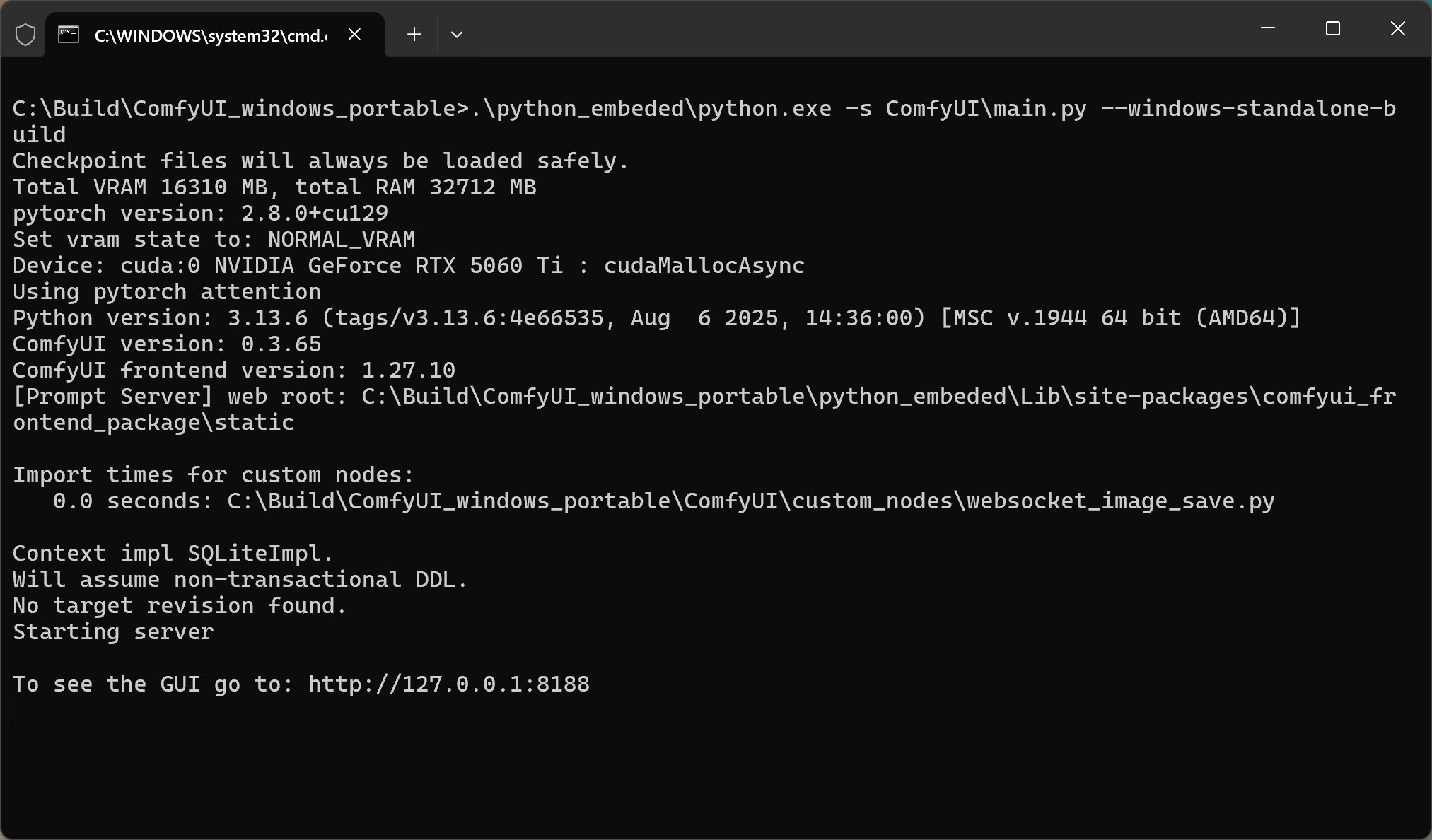
当出现 Starting server 之后,就会自动调用浏览器,打开本地网址。
然后就可以通过模板功能打开今天需要运行的工作流了。
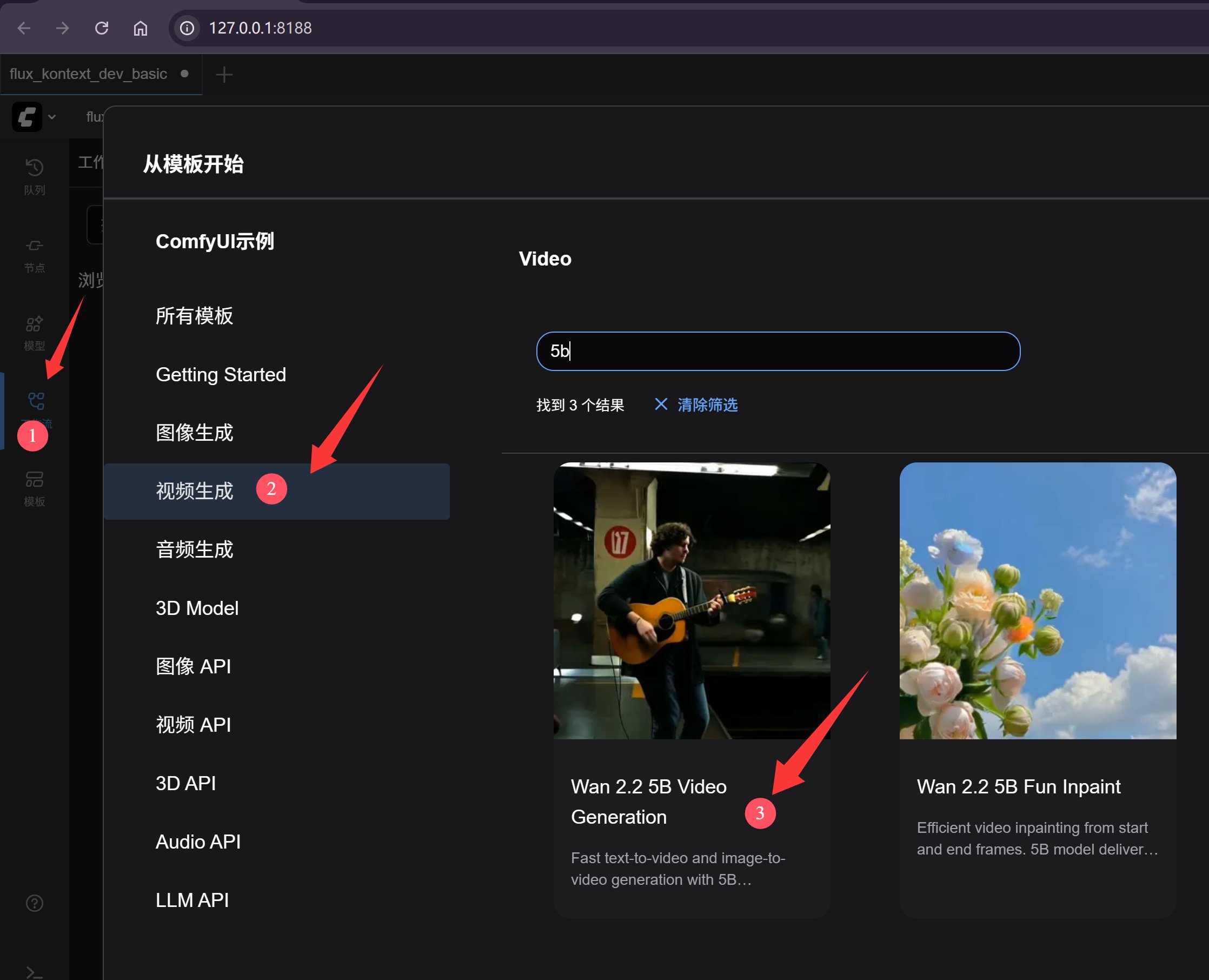
点击模板->视频生成->wan2.2 5b Video Generation。
这里的模板工作流比较多,不好找的话,可以搜索 5b。
如果之前没有事先下载好模型,就会出现下面的提示:
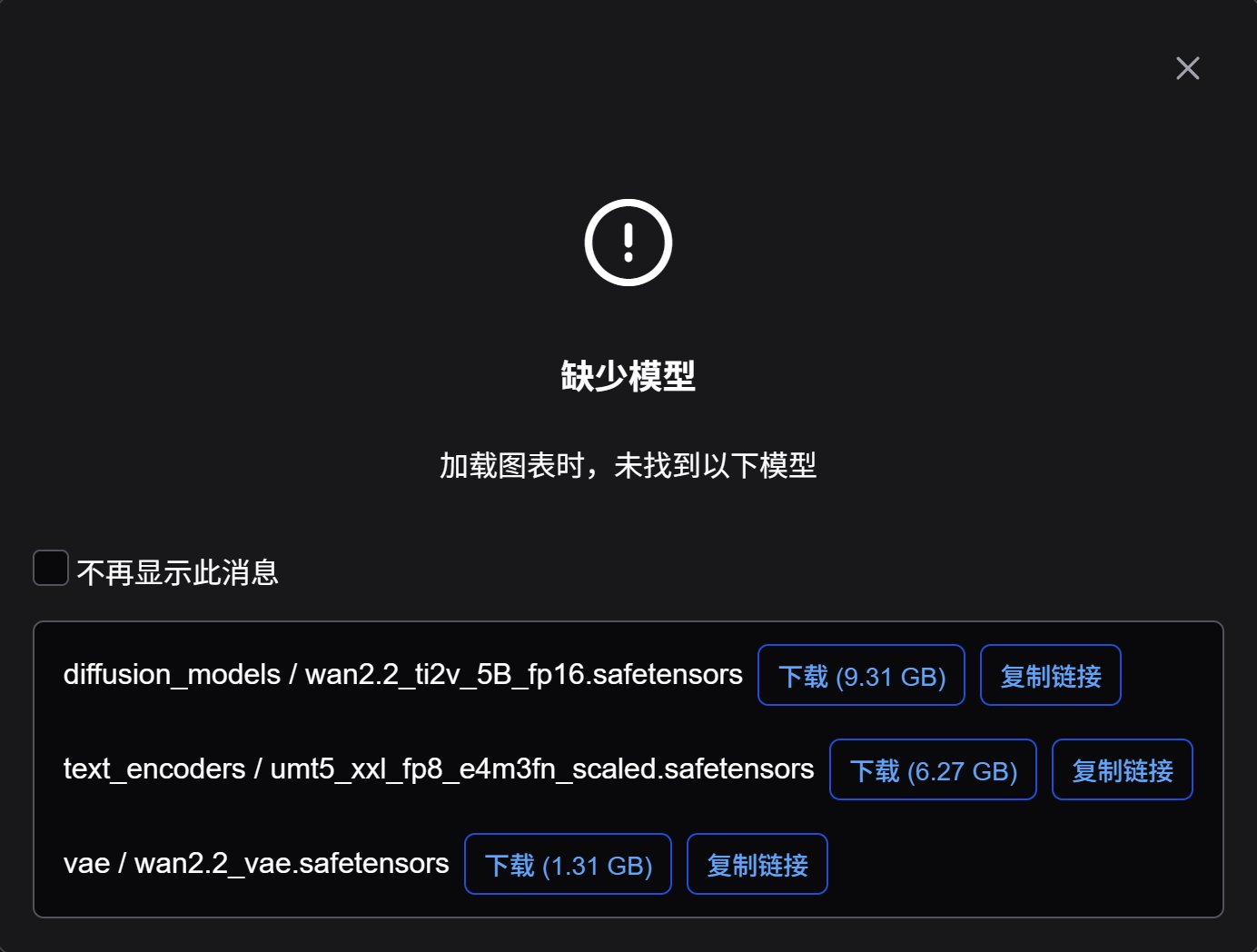
可以通过这里的下载按钮来下载匹配的模型。
由于我们事先下载了模型,所以就不会有这个提示了,而是直接显示工作流。
工作流如下:
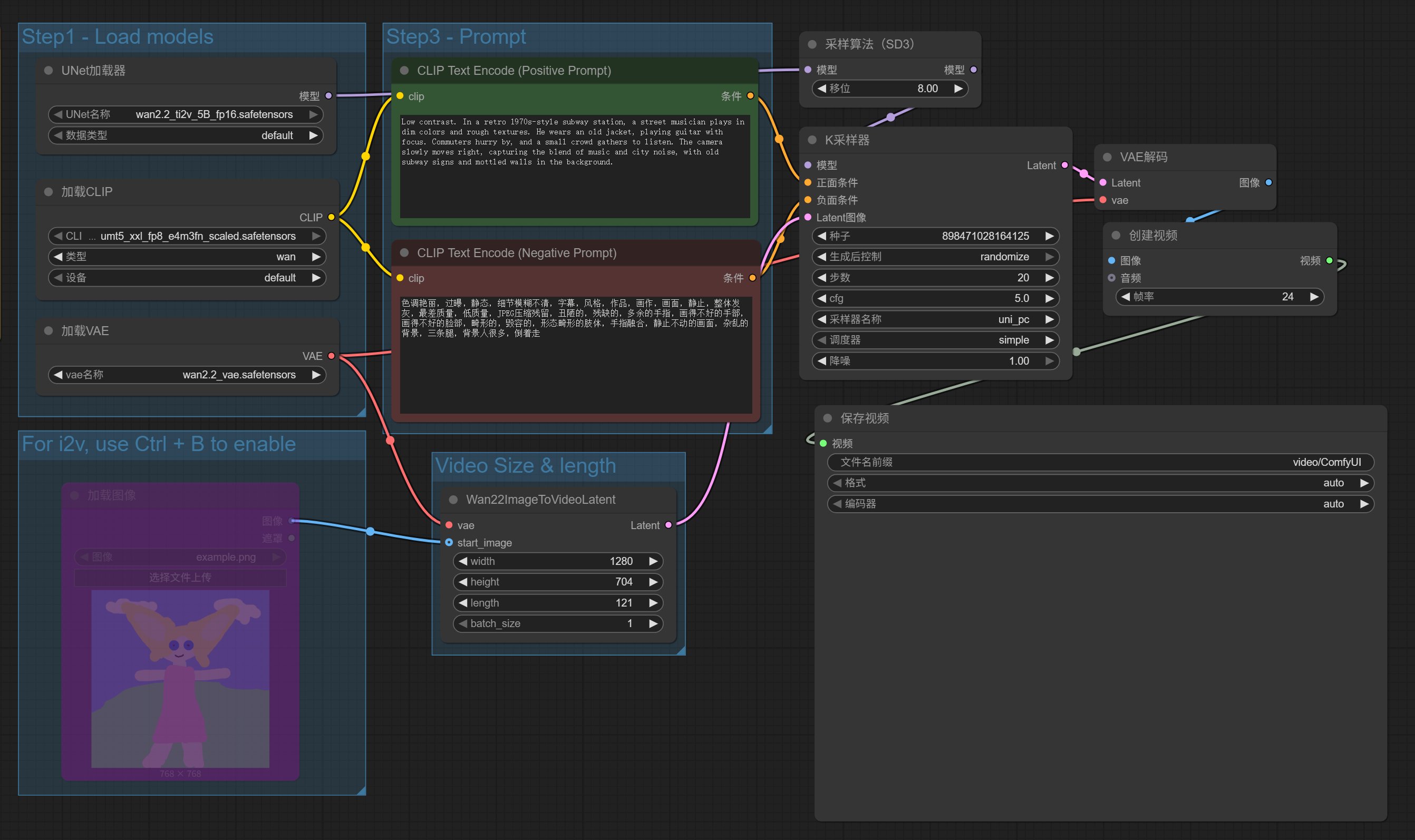
这个工作流很简单。我们只要关注输入部分,参数可以全部默认。
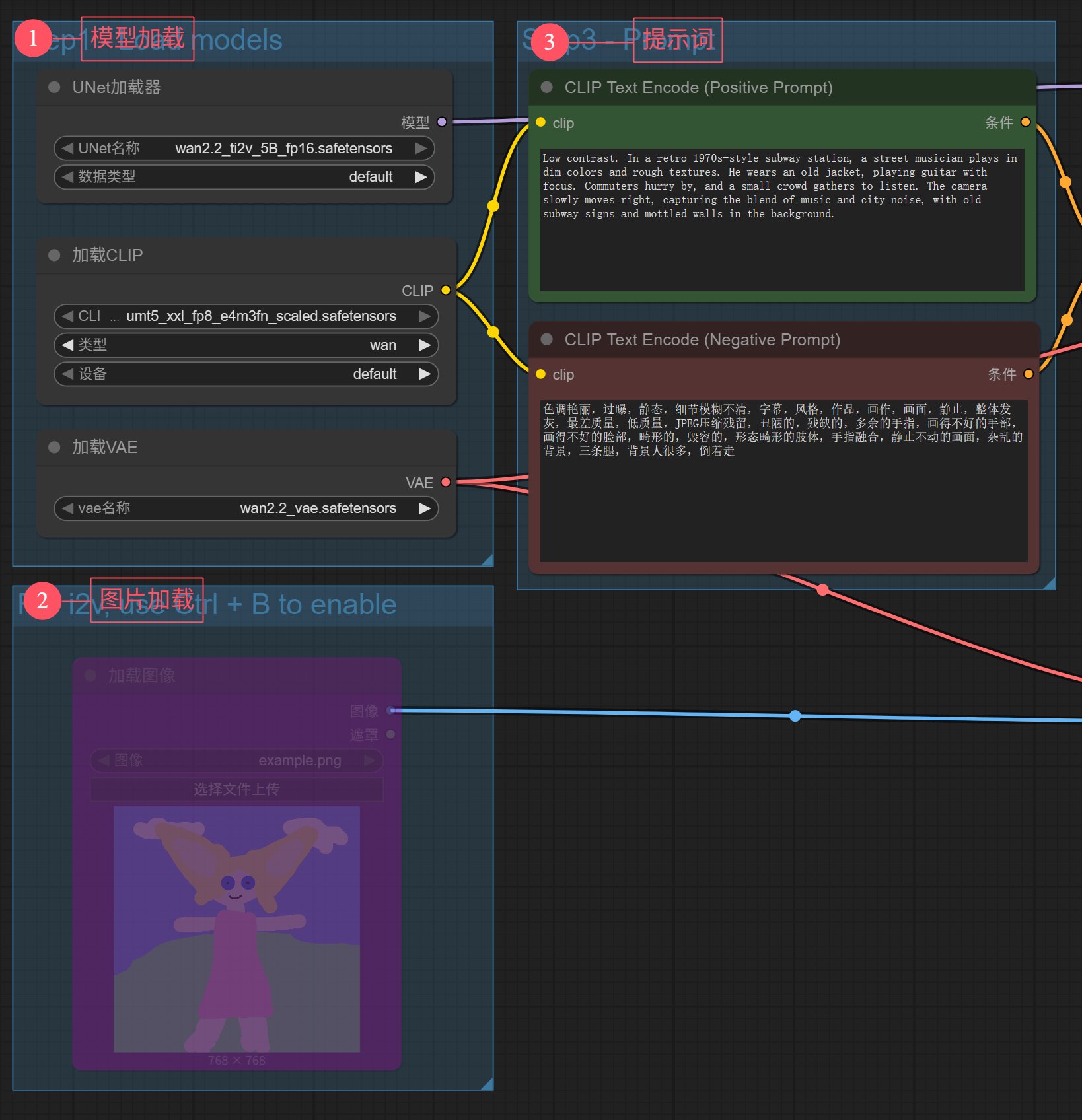
工作流的输入主要分了三个部分。
1️⃣主要负责加载模型
2️⃣用来上传参考图片
3️⃣用来输入提示词。
工作流打开之后,已经设置好了模型和提示词,参考图片默认不可用,我们也不用。 图生视频,会在后面讲到。
4. 运行和查看结果
当打开工作流,并设置好输入内容之后,就可以执行这个工作流了。在界面中找到一个叫运行的工具,点击运行。
然后工作流就开始工作了,工作过程中 GPU 的负载情况如下:
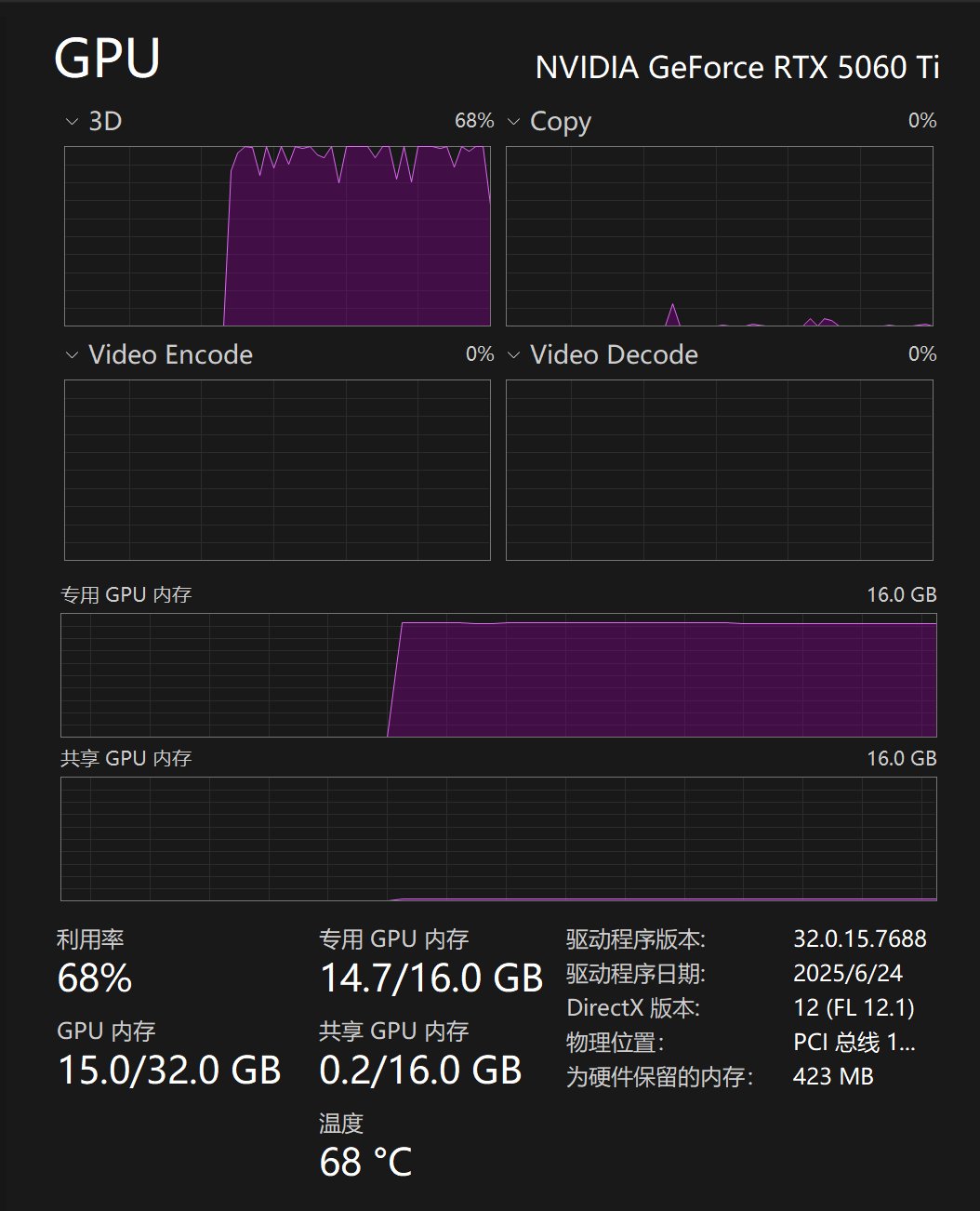
RTX5060 ti 16G 可以正常运行,消耗时间大概在 10 分钟左右。
默认的提示词,会生成一个弹吉他的男人。
我看了下效果一般,就尝试了另外的提示词。
不会写提示词,没关系,可以参考这个网址:
https://alidocs.dingtalk.com/i/nodes/EpGBa2Lm8aZxe5myC99MelA2WgN7R35y
我实测的结果如下:
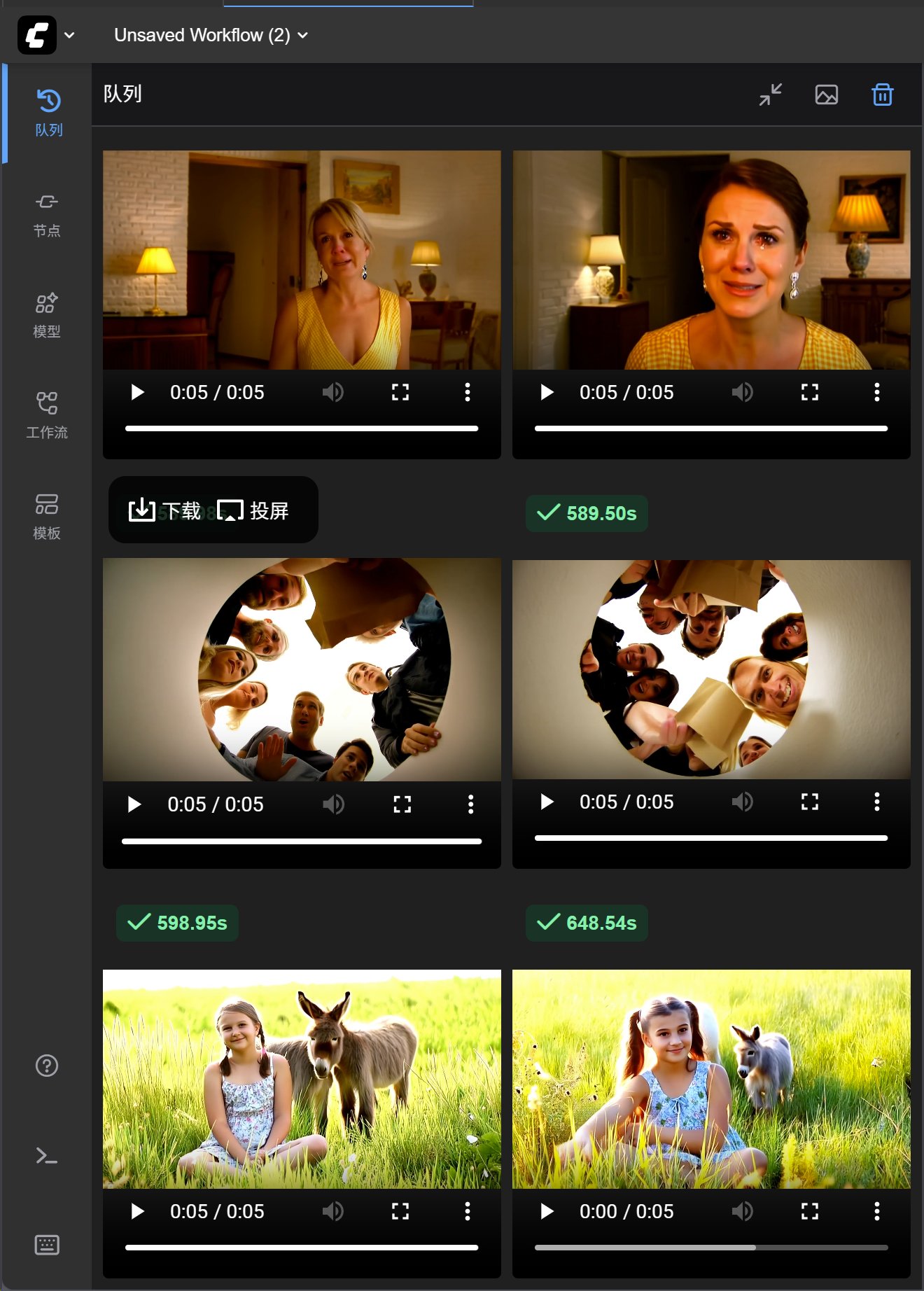
5B 的画质,有点一言难尽。
虽然它既可以文生视频,又可以图生视频,但是效果真的不咋地。一个那么小的模型,既要又要肯定不会太好。
相比而言,后面 14B 的工作流会有巨大的提升!
5. 文生视频 14B
我们上面说了 5B 的安装和使用方法,接下来说一下 14B 的文生视频和图生视频。
软件安装,模型下载,工作流的载入这些都讲了,接下来理解起来就会简单很多。
我们直接打开官方自带的 14B 文生视频。

具体的操作方法是:模板->视频生成->Wan2.2 14B Text to Video。
根据如下提示信息下载模型。
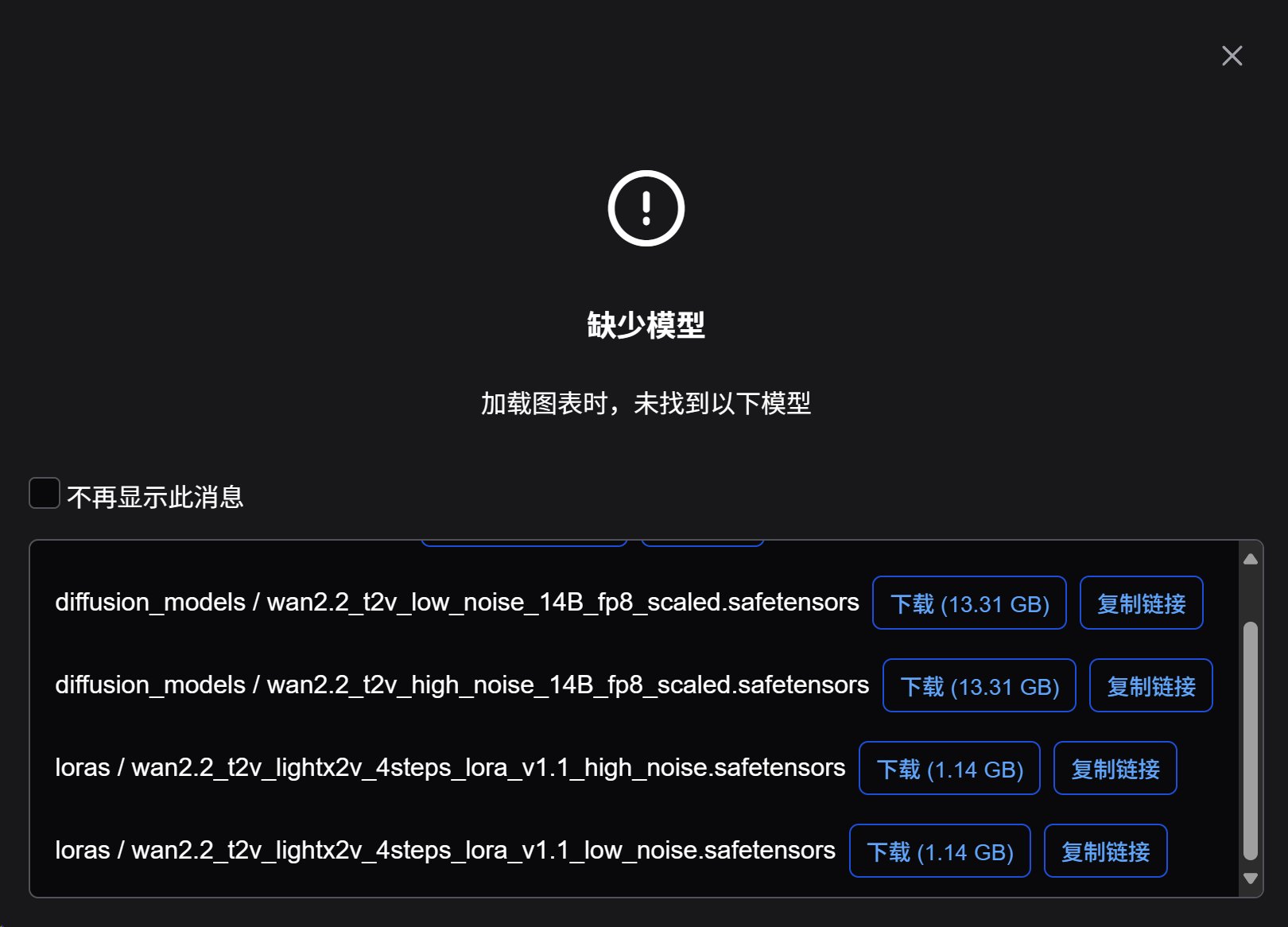
这里列出来 5 个模型,依次下载,然后放到对应的文件夹里面就好了。
每个下载链接里面都有说明所在文件夹,这些文件夹都是放在 ComfyUI/models/ 下面。
关于模型,这里 有个low noise和high noise。我本来以为只要选一个就好了,实际上两个都要用的!
关于他们的技术区别和使用场景可以参考这篇:
https://www.tonyisstark.com/3855.html
模型下载完成之后,刷新一下节点定义,就能识别到模型了。
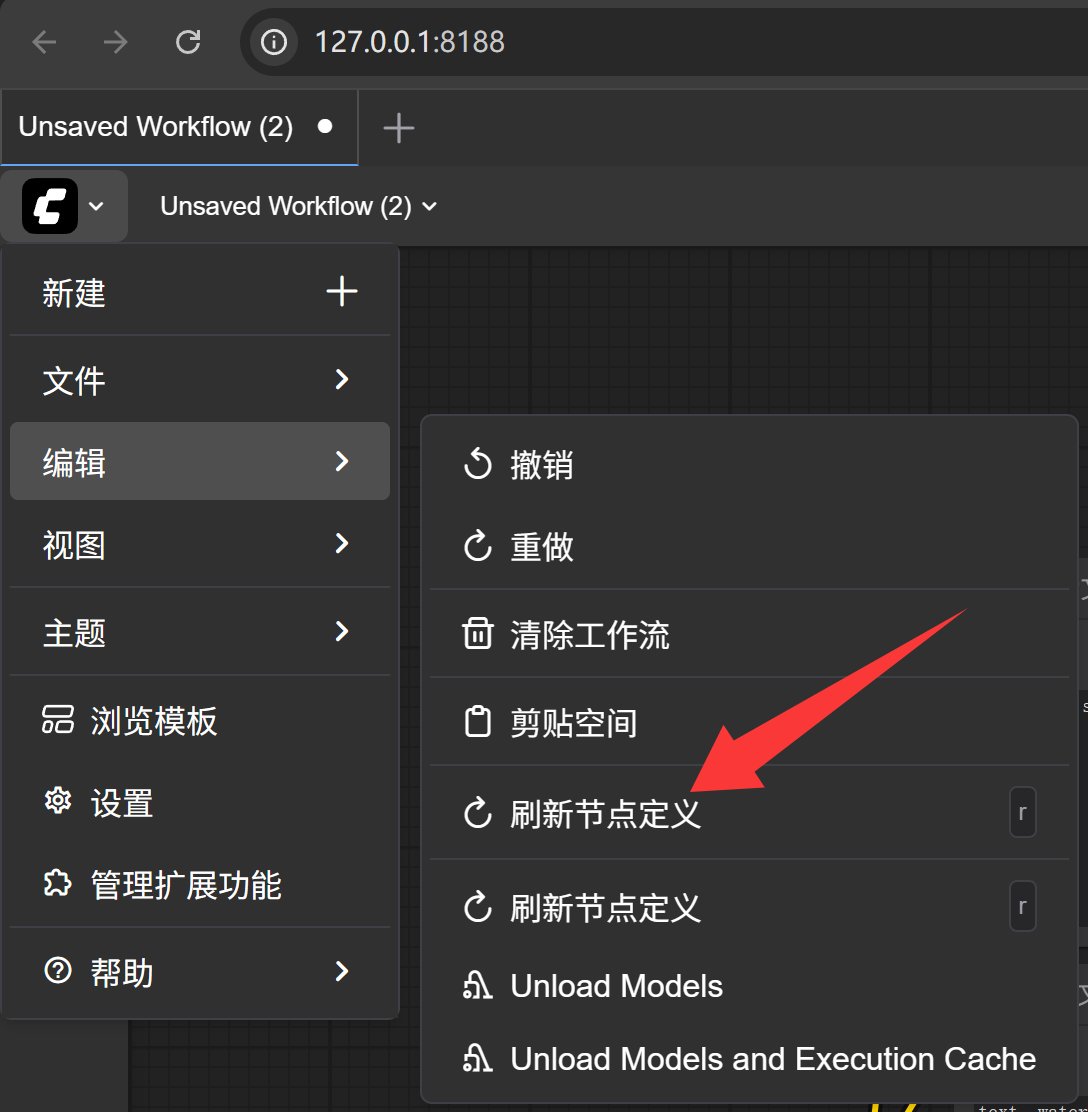
当然,重新启动软件也是可以的。
接下来就可以看到工作流了:
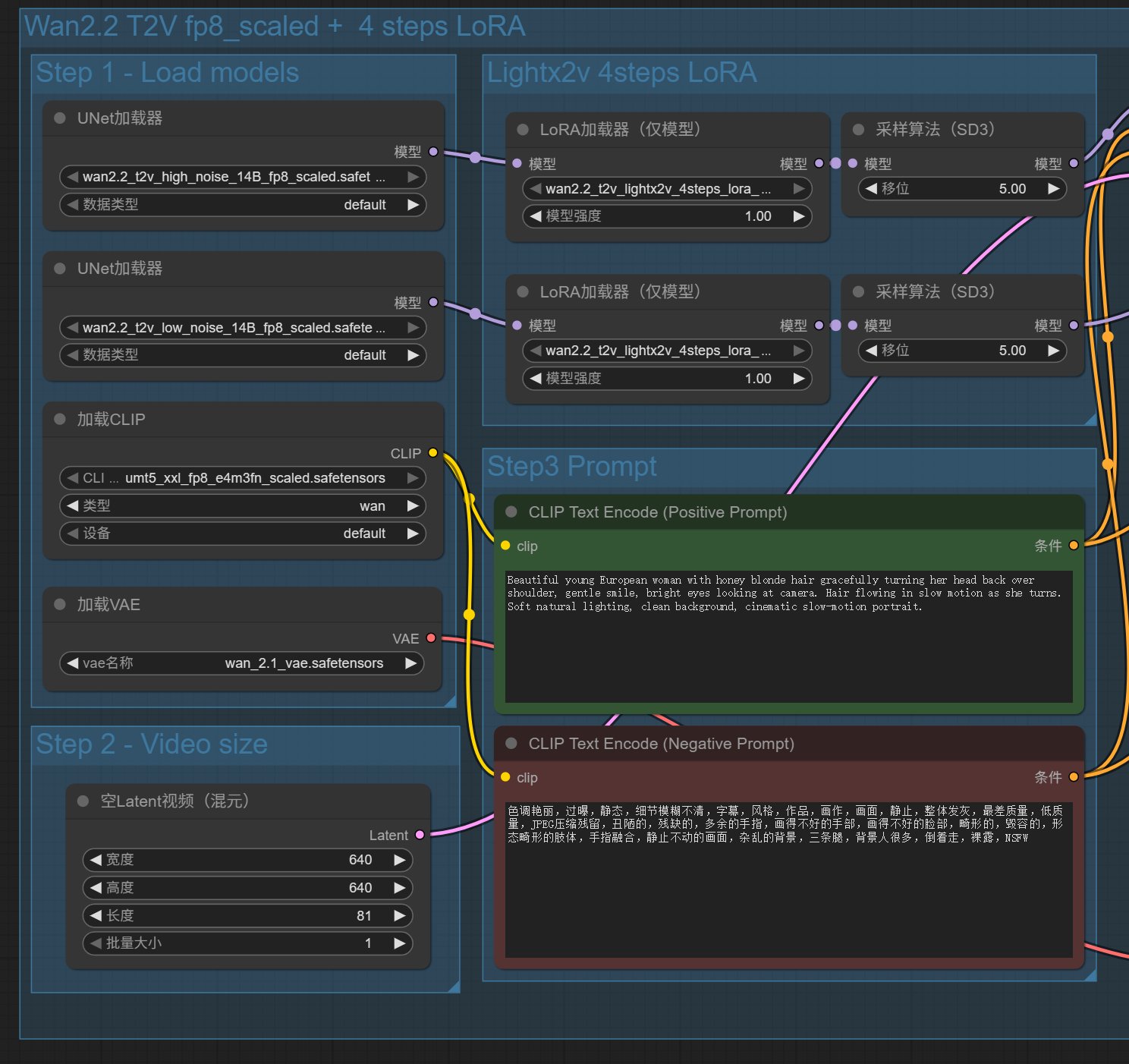
这个工作流分了两大块,一个是 4 步 lora,一个没有加 lora。默认只启用了 4 步 lora 这个工作流,我们也只使用这个工作流。
拿到这个工作流之后可以不做任何设置,直接一键运行。
默认的提示词是:
Beautiful young European woman with honey blonde hair gracefully turning her head back over shoulder, gentle smile, bright eyes looking at camera. Hair flowing in slow motion as she turns. Soft natural lighting, clean background, cinematic slow-motion portrait.
一位年轻漂亮的欧洲女性,有着蜜金色的头发,优雅地回头看向肩膀后方,笑容温柔,明亮的眼睛注视着镜头。她转头时,头发在慢动作中飘动。柔和的自然光,干净的背景,电影般的慢动作肖像。
生成成功之后,可以尝试修改 Video size 的高度和宽度,以及 Step3 中的提示词(PositivePrompt 部分)。这里的分辨率默认为 640×640,最大支持 1280×720。长度默认是 81,大概五秒的样子,也可以把这个数字改小。
我生成的两个视频,效果如下:

14B 使用默认的提示词生成视频,虽然还是有点 AI 感,但是整体完整清晰,人物的颜值也不错。
接下来用同样的提示词,对比一下 5B 工作流和 14B 工作流的效果:

提示词为:
Sunny lighting, edge lighting, low-contrast, medium close-up shot, left-heavy composition, clean single shot, warm colors, soft lighting, side lighting, day time.A young girl sits in a field of tall grass with two fluffy donkeys standing behind her. The girl, about eleven or twelve years old, is wearing a simple floral dress and has her hair in two pigtails, with an innocent smile on her face. She sits cross-legged, gently touching the wildflowers beside her. The small donkeys are sturdy, their ears perked up as they look curiously toward the camera. Sunlight bathes the field, creating a warm and natural scene.
对比之下,14B 这个工作流的生成质量实在是太好了。光照、人物、清晰度、画面感,都是质的飞跃。
6. 图生视频 14B
文生视频讲完了,来讲一讲图生视频。工作流的打开方式同上。
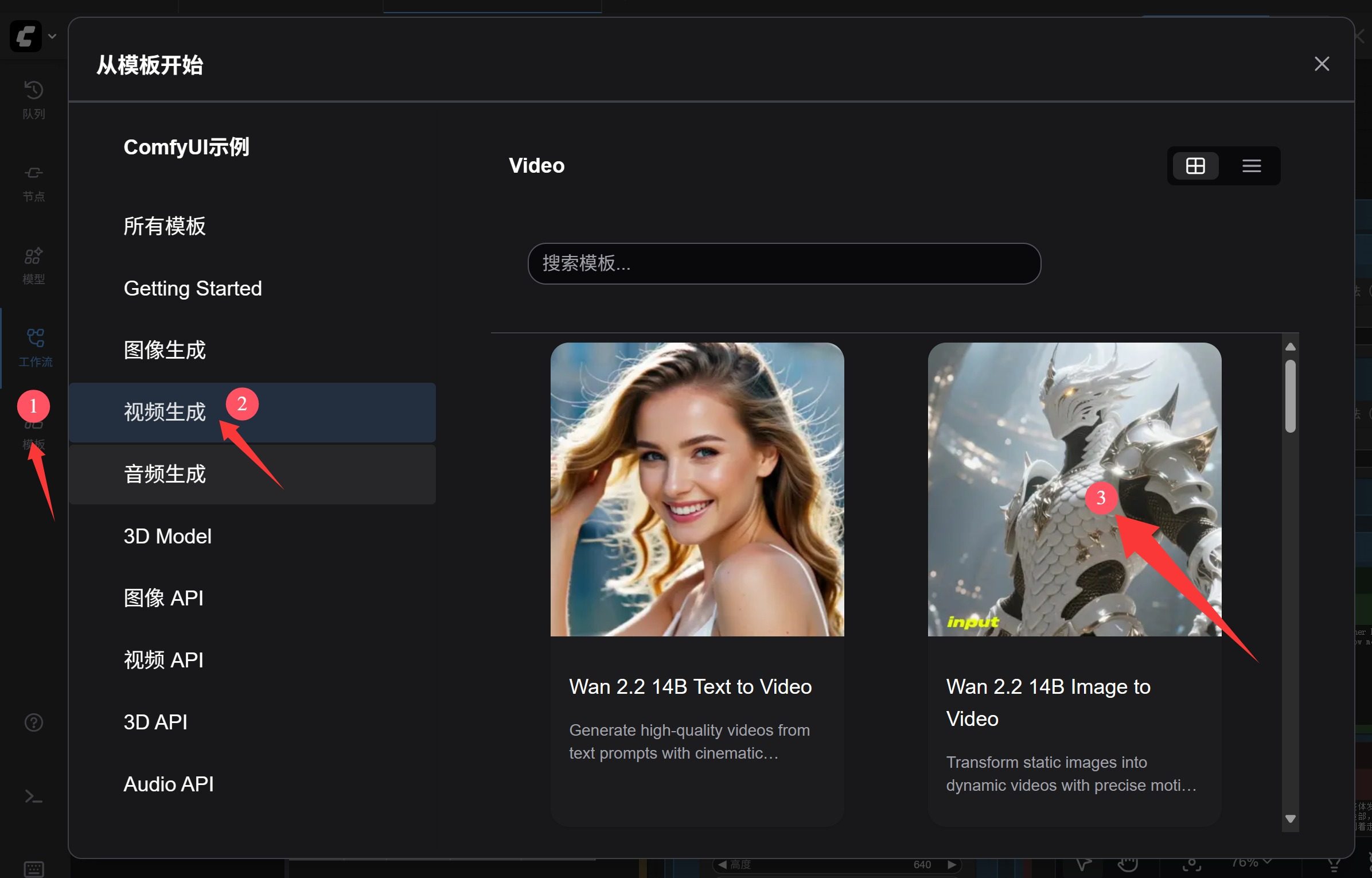
点击模板->视频生成-> Wan2.2 14B Image to Video。
这个工作流和文生视频的工作流基本一样,只是多了一个图片输入的节点。
打开之后,同样会提示你下载模型:

点击下载按钮开始下载,下载完成之后,重启软件,或者重新打开工作流,或者刷新节点,就会直接进入工作流了。
工作流和运行结果如下:
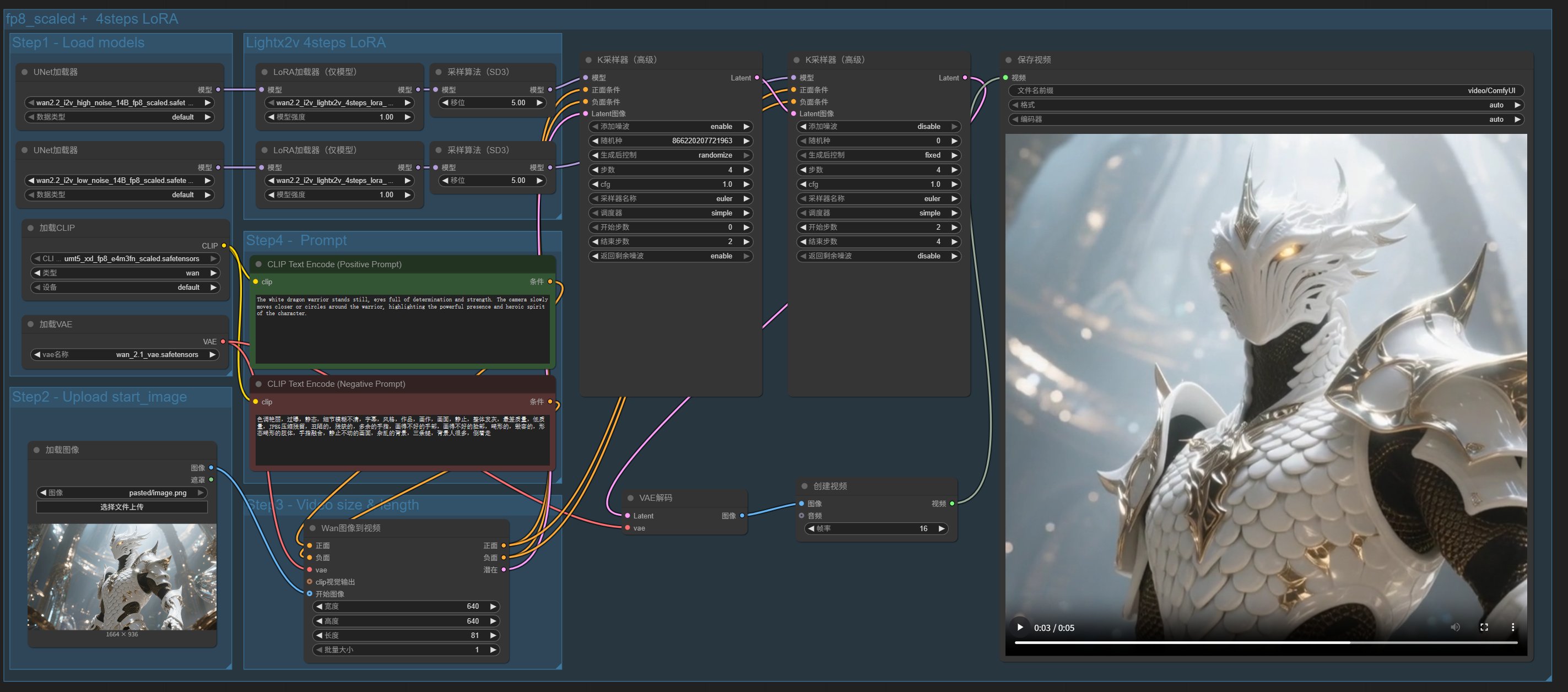
这个例子中提供了一张白龙勇士的图片。
提示词为:
The white dragon warrior stands still, eyes full of determination and strength. The camera slowly moves closer or circles around the warrior, highlighting the powerful presence and heroic spirit of the character.
白龙勇士静立不动,眼中充满了决心与力量。镜头缓缓靠近或环绕勇士,凸显出这个角色强大的气场与英雄气概。
最终生成的视频,确实如提示词一般,有靠近和运镜,指令遵循能力还不错哦!
只是,官方例子多少有点无趣,我们都是成年人,应该试试它能不能做点成年人的绿色视频!
换图片!
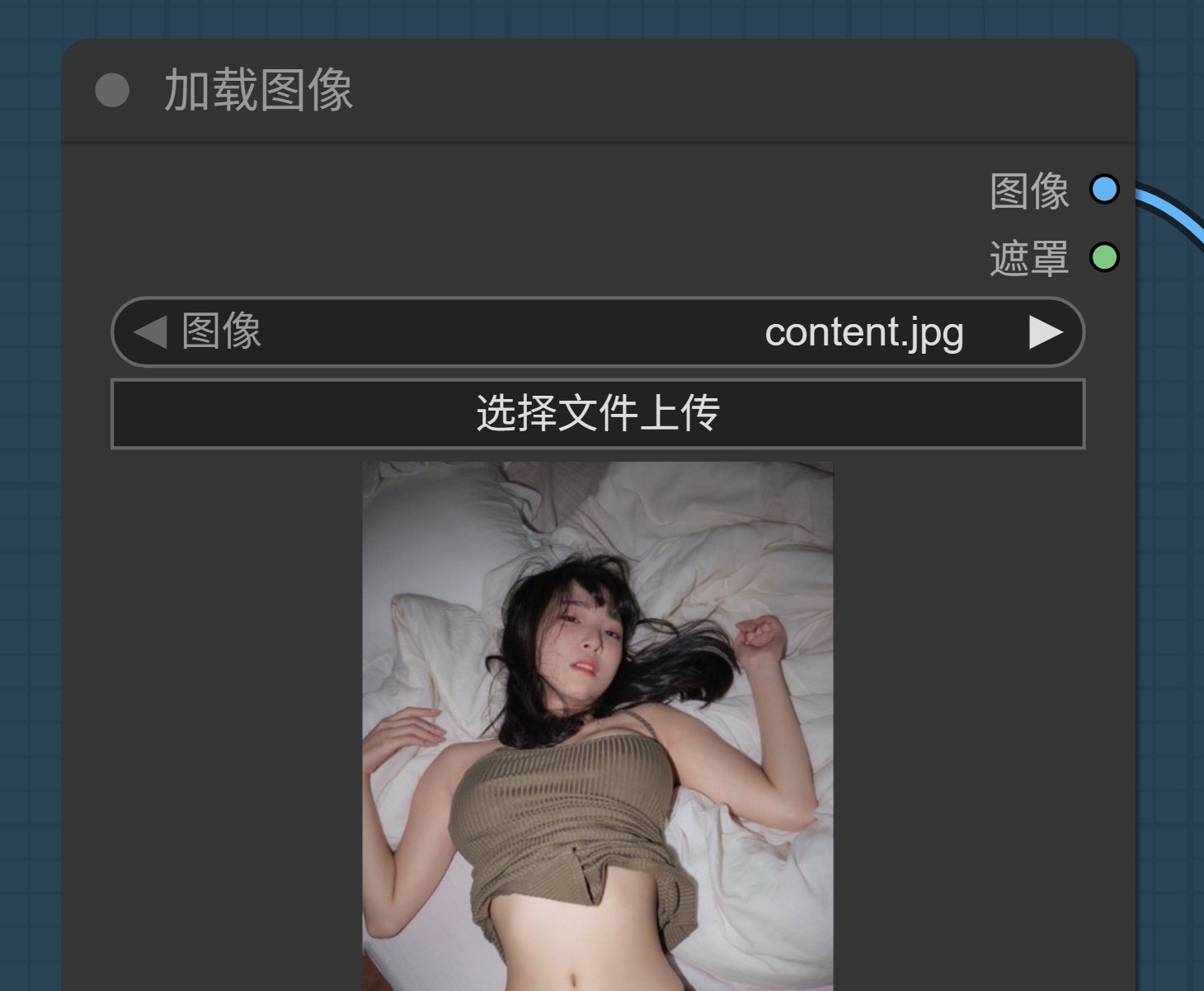
我随便找了一张图片,把它扔给 Wan,然后写一段简单文明的提示词:
以卧室场景为背景,一位穿着橄榄绿针织吊带与黑色蕾丝边内裤的女性,慵懒地躺于凌乱的白色床品上。视频呈现细腻的动态效果:发丝随呼吸轻拂,布料因细微动作产生自然褶皱,光影模拟柔和的室内漫射光,营造慵懒松弛的氛围。镜头采用缓慢的俯拍视角,配合轻微的景深变化,展现从整体姿态到肌肤纹理、蕾丝细节的渐进式清晰,风格偏向情绪感写真视频,画面质感细腻且富有呼吸感。
如果这个图片给豆包或者其他在线平台,99.9% 会拒绝生成,顺便劝你好好学习天天向上。这个时候 Wan2.2 的优势就体现出来了。
【视频】
还可以吧,指哪打哪,这个效果快要赶上 Grok 了。
今天的内容大概就是这样了,主要是先把 ComfyUI 装起来,然后把 Wan2.2 的基础工作流跑起来,最后,发挥想象!
接下来会讲一下 Wan2.2 animate 的工作流!
这个工作流中的模型,在万象官网被分到了数字人分类,可以实现角色替换和动作同步。
这个模型的效果很好,可控性强,可玩性高。

关于作者
tony
某人