13秒极速出图 !FluxKontext安装和使用加速插件全过程
又是疯狂下载的一天!
为了搞这个 FLux Context,几天功夫已经下载了几百G的文件了!!!
讲完了Windows本地安装,Mac本地安装和测试,低显存运行。
今天来讲一讲提速!
我第一次在RTX5060ti上运行,出一张图片需要100多秒。而今天,P一张图片只用了13秒。
Prompt executed in 12.53 seconds
这速度简直飞起了!
毛估估提速七倍。
这个提速主要是依靠一个叫nunchaku的插件和一个Lora!
下面就来完整说一下安装配置过程。
首先基于我们上一篇的文章,已经安装和配置好了ComfyUI的基础运行环境。可以正常使用Flux Kontext模型。
然后我们就可以进入今天的主题了。
安装插件
安装插件本身很简单,直接ComfyUI Manager里面搜索安装就可以了,但是安装插件的依赖会有一点麻烦。
具体操作如下,首先点击Manager打开插件管理工具
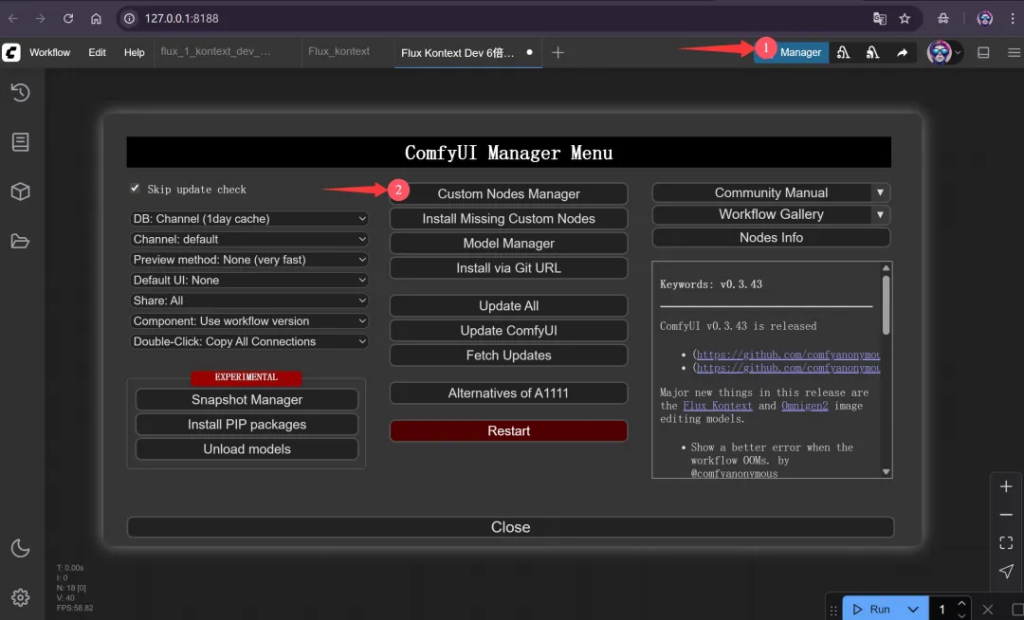
选择自定义节点管理。然后搜索nunchaku,点击Install
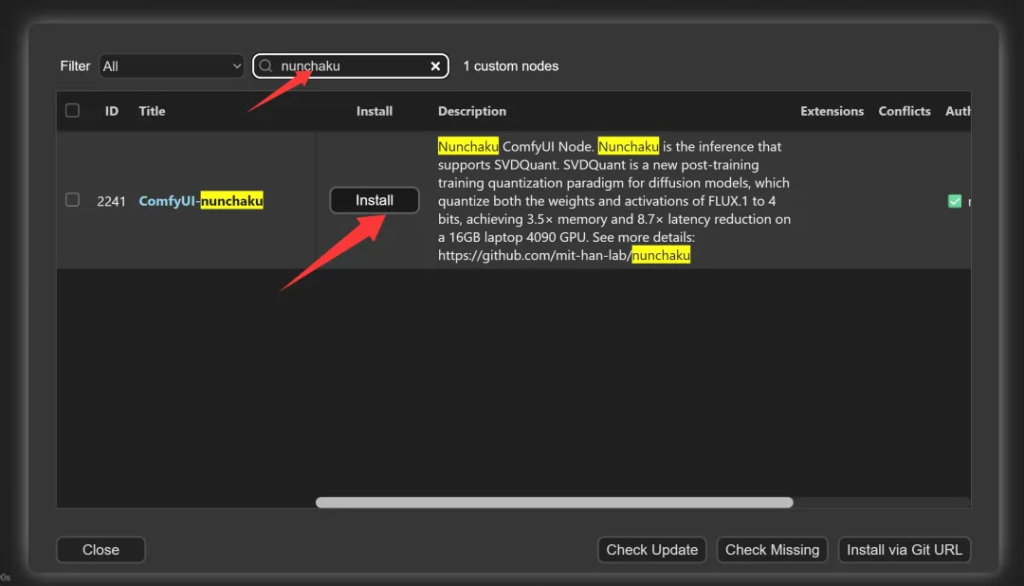
安装完成之后点击Restart
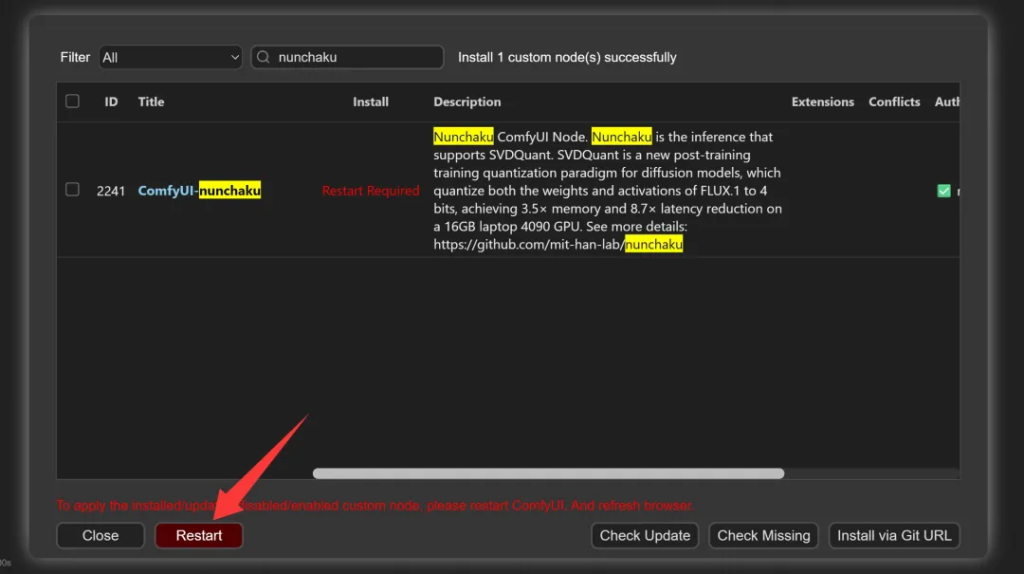
重启过程中,会自动安装依赖。但是似乎没有安装最重要的nunchaku包。
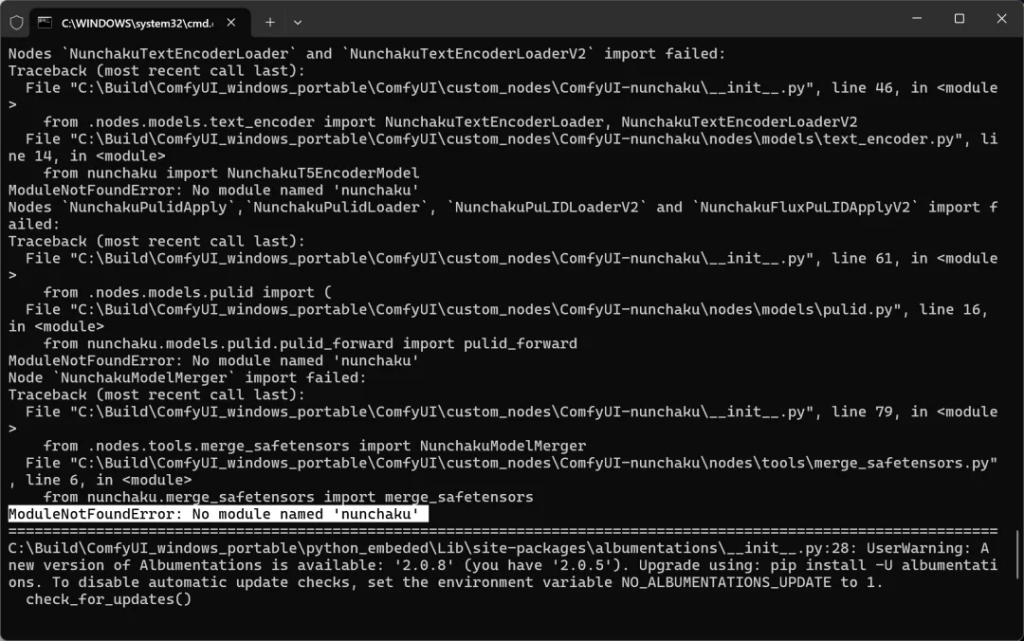
nunchaku插件的核心包是nunchaku包。这个包需要针对本地的Python环境,CUDA版本,Torch版本来进行编译。
编译环境相对难搞,所以官方提供了预编译版本!打开网址:
https://huggingface.co/mit-han-lab/nunchaku/tree/main
这里面有针对不同环境的预编译包
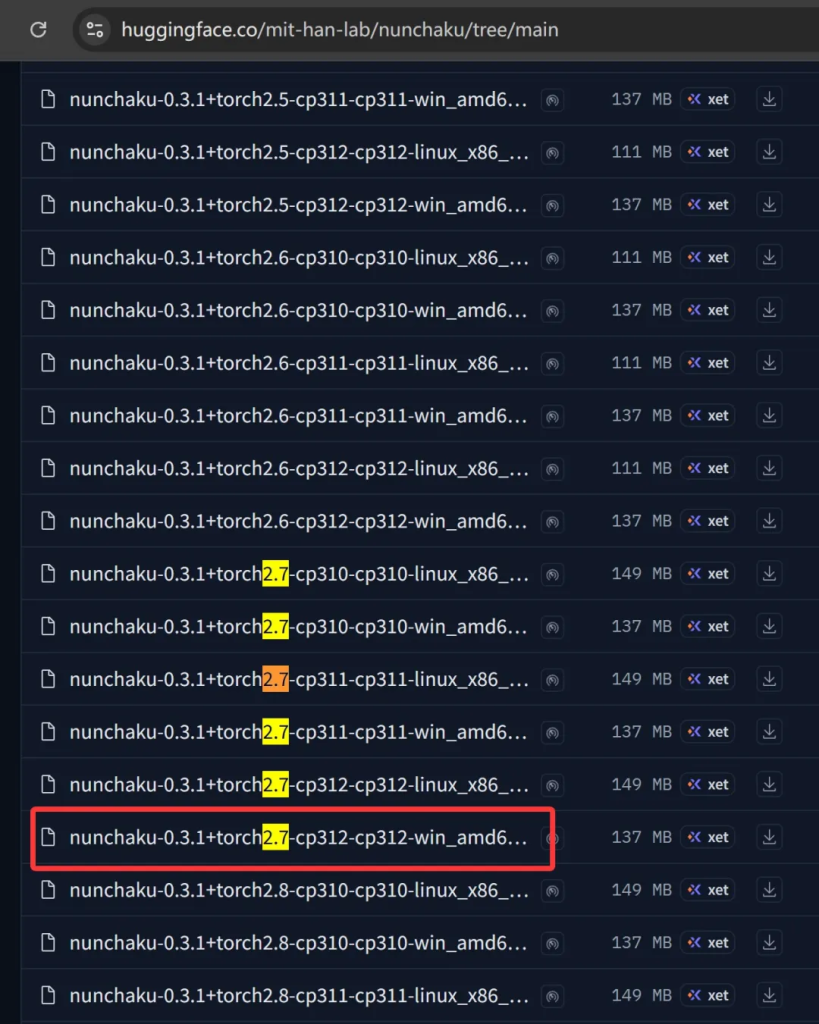
密密麻麻看起来可能有点困难。但是只要锁定几个变量,就可以定位到我们需要的包了。
首先linux排除,我们只要win的版本。
其次根据电脑上的Python版本和Torch版本来锁定最终文件。找到ComfyUI自带的Python环境。

默认这个文件夹叫Python_embeded
打开这个文件夹,直接在文件资源管理器地址栏,输入CMD回车,就会自动定打开CMD并定位到这个文件夹。
然后输出命令 python 回车,就可以看到Python版本了。
我这里显示为3.12.7 转换一下就是312。然后按CTRL+Z 回车,退出Python。
接下来查看torch版本,输入命令:
python.exe -m pip show torch
通过这个命令可以快速查看pytorch的版本。
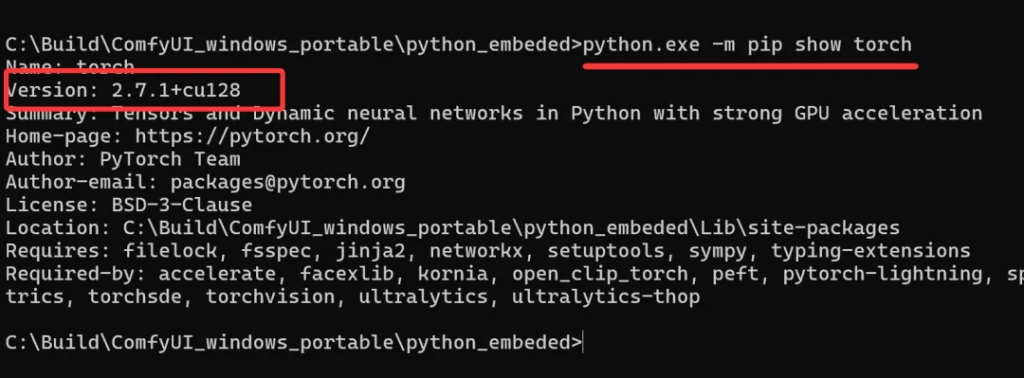
如上图,我们的版本为2.7.1+cu128。
转换一下就是torch2.7。
通过这两个版本就可以锁定预编译文件了。
因为我们在使用Kontext的时候就升级了环境,所以大部分情况应该都是获取这个版本的预编译包。
nunchaku-0.3.1%2Btorch2.7-cp312-cp312-win_amd64.whl
有了这个包之后,继续执行命令:
python.exe -m pip install nunchaku-0.3.1%2Btorch2.7-cp312-cp312-win_amd64.whl
这里需要注意,nunchaku的路径。如果按上面的命令执行,需要先把nunchaku的预编译包放到Python_embeded文件里面。
如果你放在其他路径下,就要在install后面跟上完整的路径。
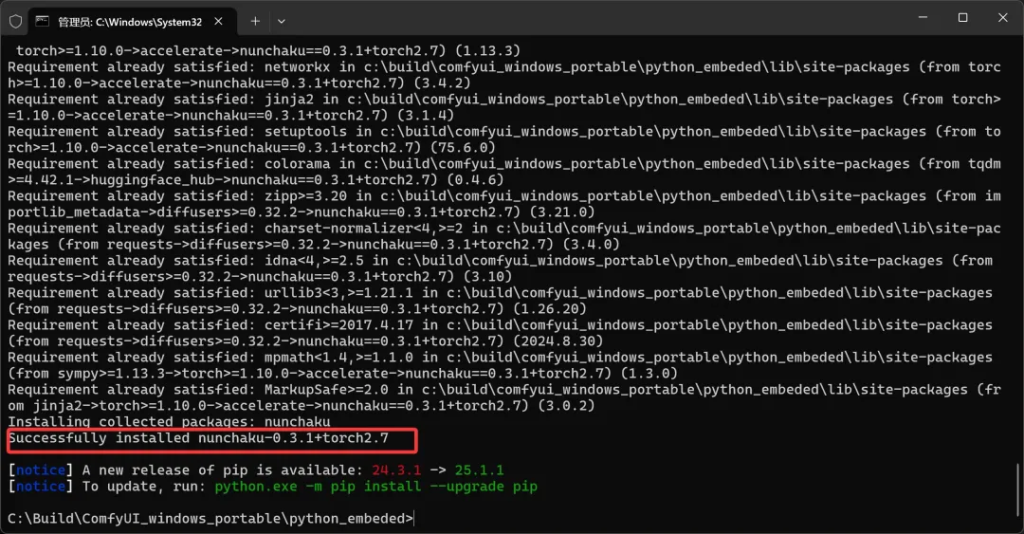
当出现Successfully,就证明安装成功了。这个安装会非常快速!安装完nunchaku包之后,启动ComfyUI并载入插件的时候可能还会有错误。
通过如下命令可以解决:
python.exe -m pip install -U peft
这样,插件就装好了。这一步会花一点时间,但是坑我已经帮你踩了,所以会简单很多。
下载模型
下载两类模型,一个是基础模型,一个是lora模型。
模型地址:
https://huggingface.co/mit-han-lab/nunchaku-flux.1-dev/tree/main
下载模型的时候需要注意,这里有两个数据类型的模型。
svdq-fp4_r32-flux.1-dev.safetensors svdq-int4_r32-flux.1-dev.safetensors
不同系列的N卡,需要选择不同的文件了。我刚开始随便下载了一个,就出错了。
提示信息为:
NunchakuFluxDiTLoader Please use "fp4" quantization for Blackwell GPUs.
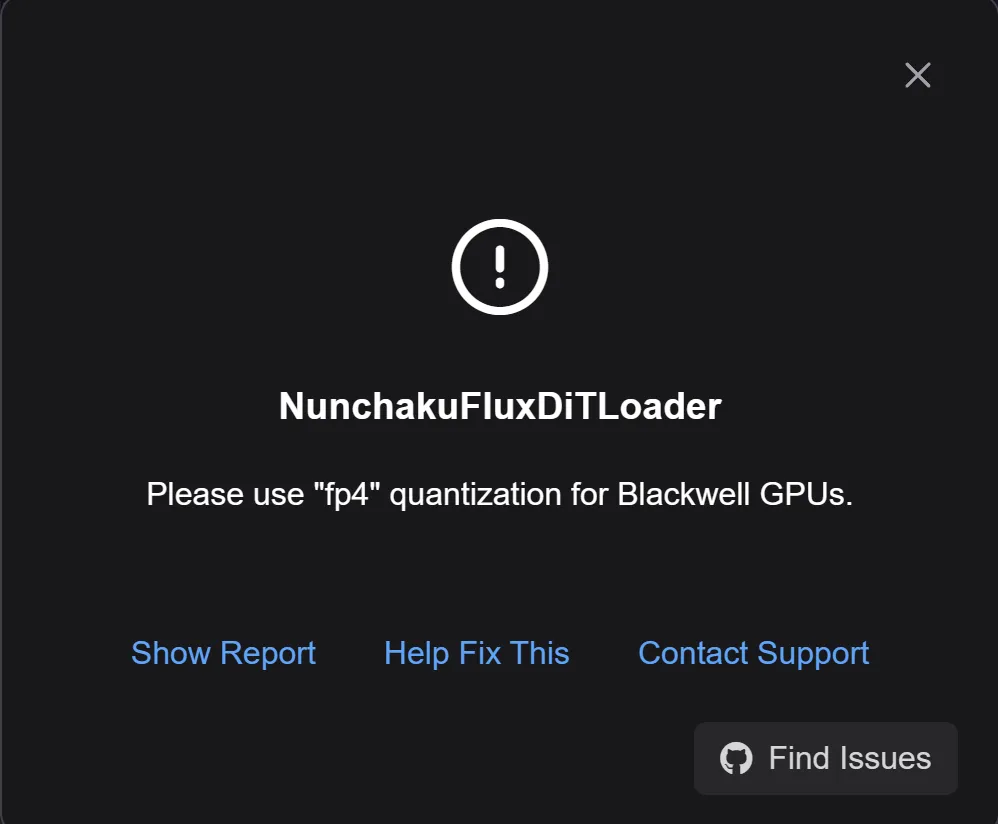
翻译一下大概就i是 Blackwell GPUs 需要使用fp4。
5090,5080,5070,5060等都是基于这个架构,所以这些显卡需要选择fp4。
int4和fp4主要是浮点和整数的差别,fp4精度会高一些。
这里问题不大,稍微记一下就好了,如果是50系列显卡就用fp4,之前的系列用int4。
下载完成之后,把文件放到:
ComfyUI_windows_portable\ComfyUI\models\diffusion_models
这个文件和原始的Kontext模型放在同一个路径下面。
Lora地址:
https://huggingface.co/alimama-creative/FLUX.1-Turbo-Alpha/tree/main
Lora就简单很多了,打开之后直接下载这个文件就可以了。
下载之后最好是修改一下名字,比如改成:
FLUX.1-Turbo-Alpha .safetensors
然后把这个文件放到:
ComfyUI_windows_portable\ComfyUI\models\loras
修改工作流
安装和模型下载都做完之后,就非常简单了。
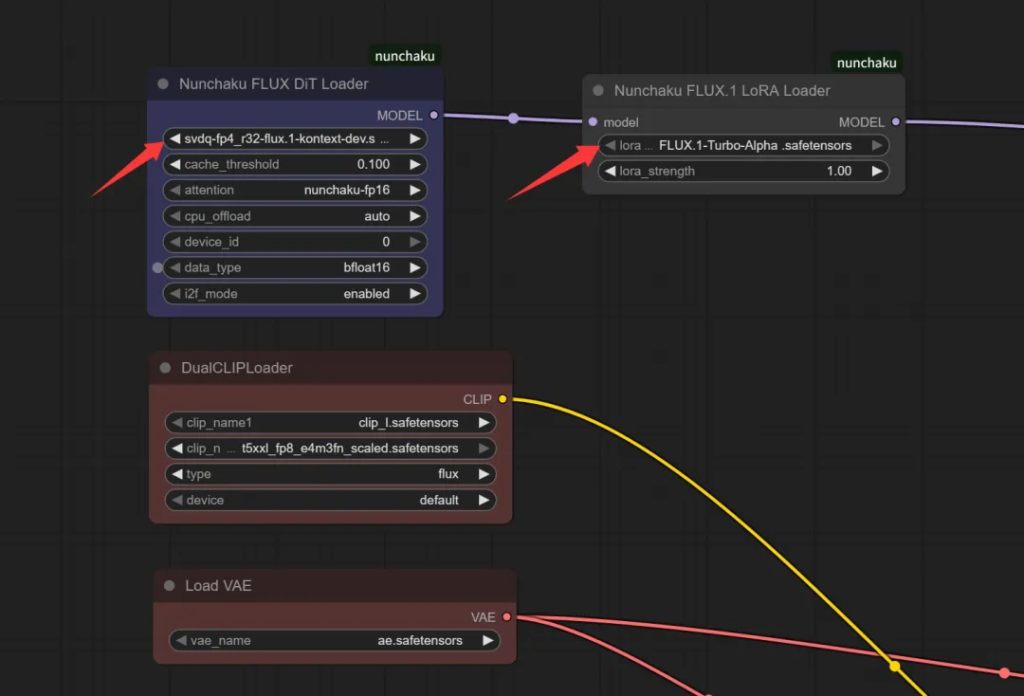
只要打开官方的FLux Kontext基础工作流,删除原来的Diffusion模型加载器删除,添加一个Nunchaku加载器,添加一个Nunchaku lora就可以了。
这两个节点添加之后,记得选择具体的模型。然后上传图片,填写修改提示词就可以运行了。
运行工作流
万事俱备,就等验证了。
这一步只要点一下运行(RUN)按钮即可。
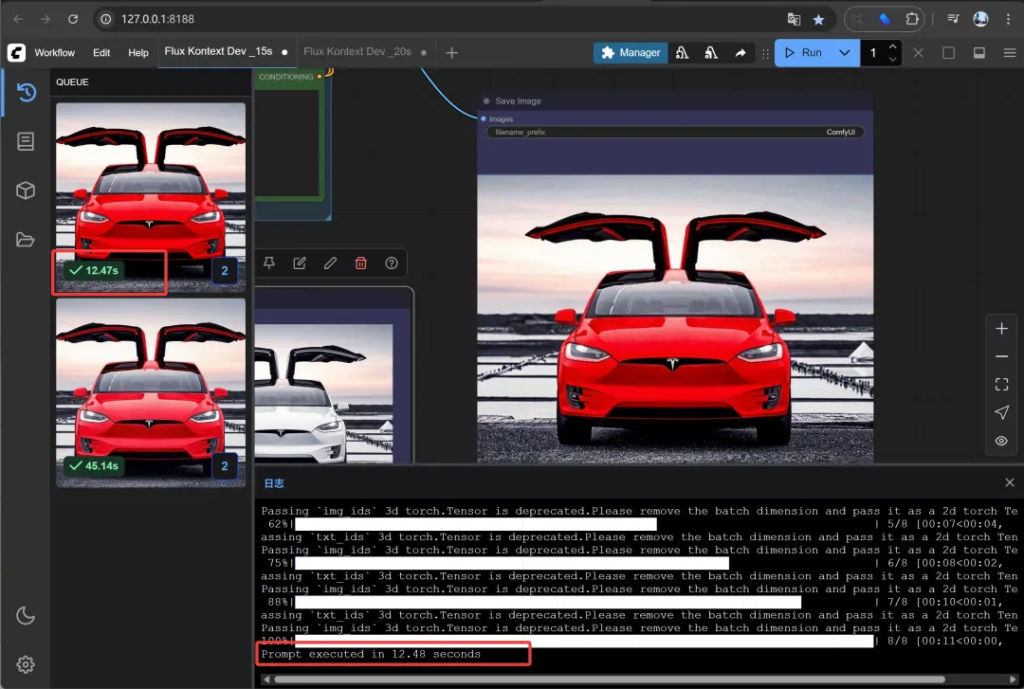
点一下,没一会儿,结果就出来了。难以置信!
结果对比:

在细节上肯定有些差异,但是不明显。主要是这个太快了,以至于对它充满了包容性。
实际操作的时候,可以用这个快速工作流预览出图,如果不错的话,再用官方的工作流慢慢生成高质量的图片。
在50系列的入门卡中就有这个速度了,可玩性就相当高了!
有留言反馈说,本地实在跑不起来,单独租服务器又有点难搞。那可以使用一些在线平台,工作流和软件都是一样的,只是他们提供了在线运行的环境。
我自己试了一下这个:
https://www.runninghub.cn/?inviteCode=potspaer
目前更新比较快,支持也不错。大概是有邀请码的的话注册完送1000个积分,然后每天会送一些。很多人在上面分享工作流,免费领积分,直接用工作流是挺好的!当然,天下没有永远免费的午餐,有条件自己搞个好点的硬件。
最后!
文中相关的软件,模型,工作流都放在网盘了。
给公众号发送 kontext 即可获取!



关于作者
tony
某人