TonyHub-FaceFusion 软件,教程,更新!
FaceFusion是一款功能强大的单图AI换脸软件,包含图片换脸,视频换脸,实时换脸,人脸增强,唇形同步等功能。
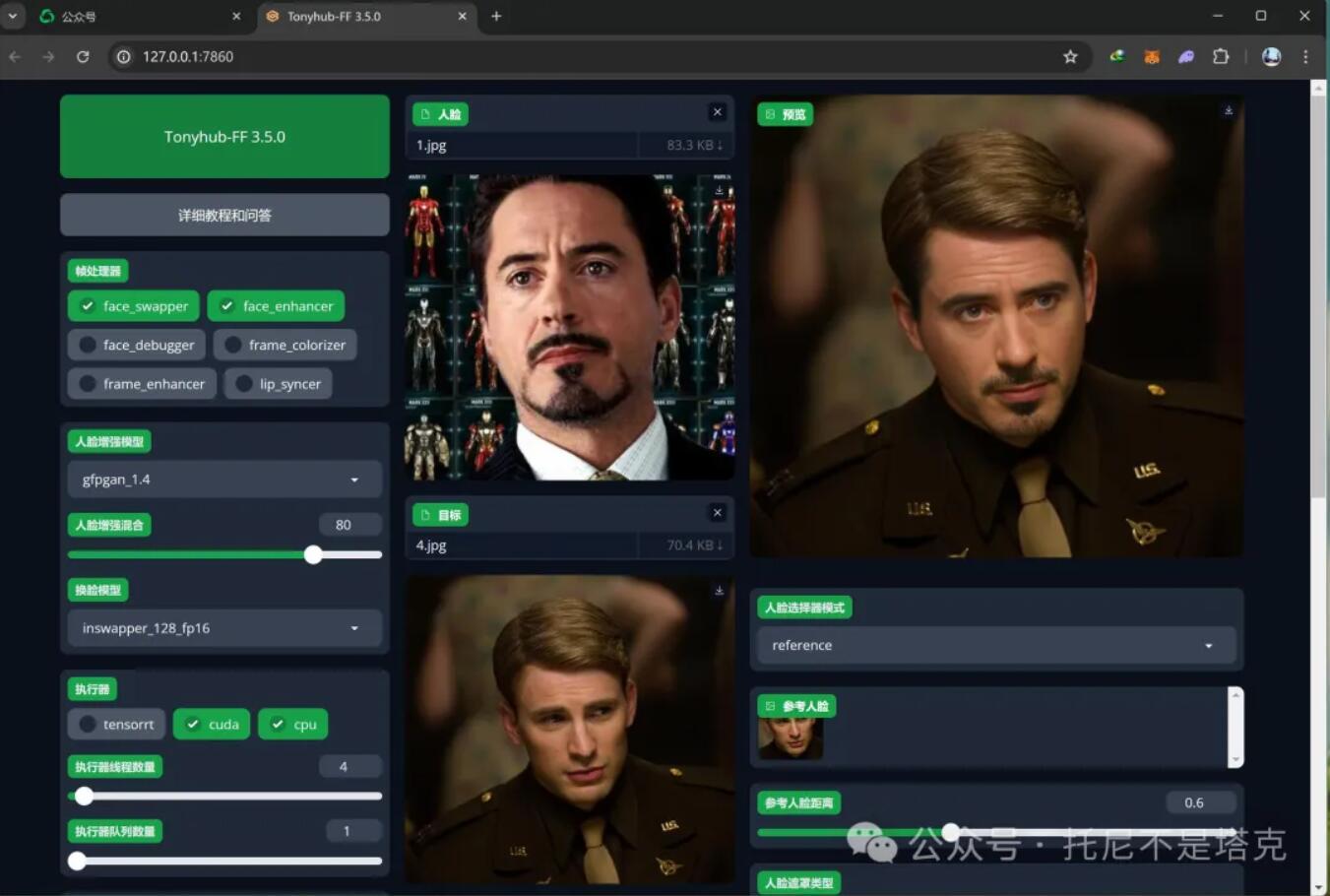
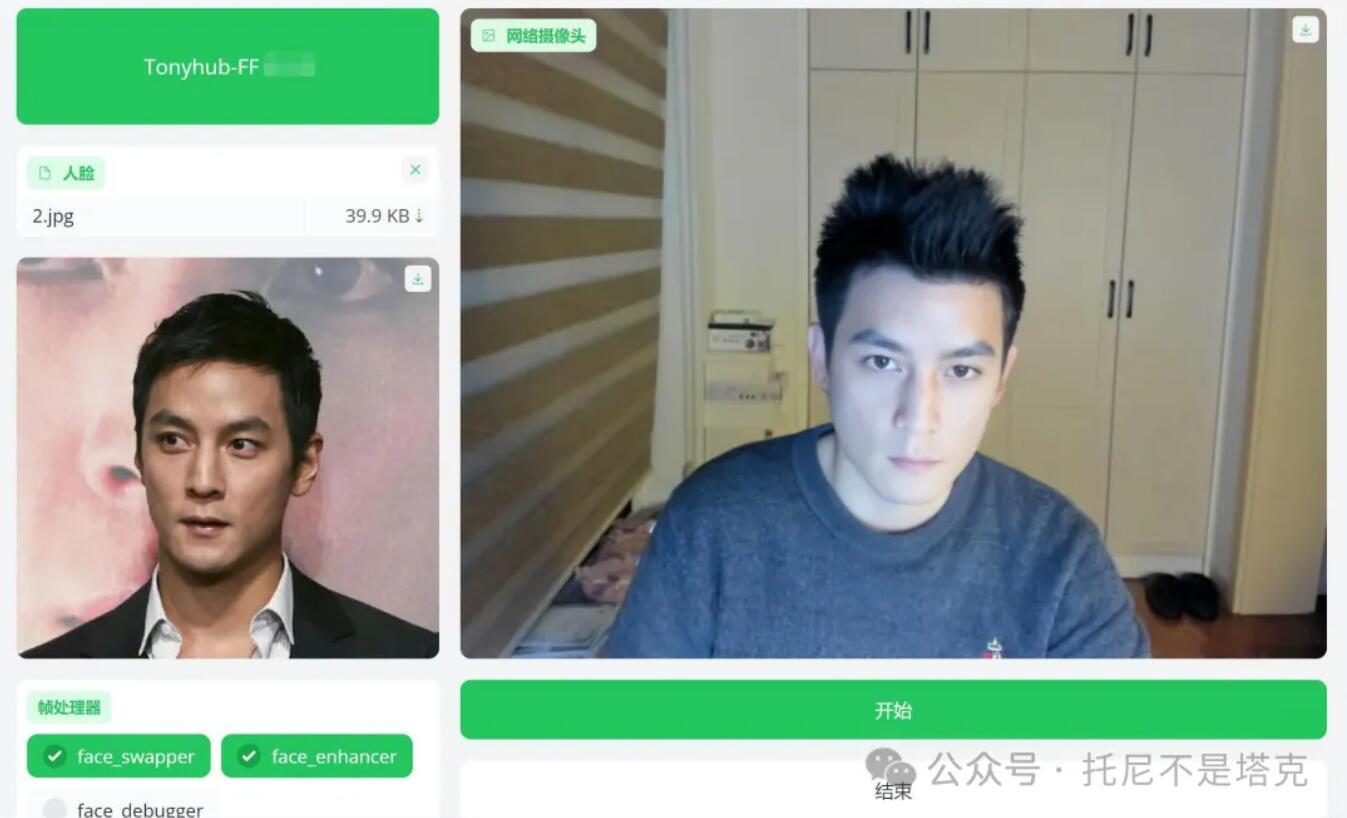
免费共享版,关注公众号“托尼不是塔克” ,发送facefu即可获取。
知识星球版,加入知识星球tonyhub获取,里面包含最新软件,全面的使用教程,常见问题问答,激活码获取。
更新记录
3.5.3
– 禁用 Gradio 分析功能
3.5.2
– 引入动态帧色彩器尺寸
– 验证 `facefusion.ini` 的覆盖设置以防止崩溃
– 移除 GPU 架构查找以支持过时的 `nvidia-smi`
– 移除 `hwaccel`,意外地提高了 FFmpeg 的性能
– 修复 DirectML 的线程和预览崩溃问题
– 修复未应用的 `–output-video-resolution` 参数
3.5.1
– 向帧色彩器中添加缺失的 `deoldify` 模型
– 修复语音提取器在背景音频中的过度校正问题
– 修复语音提取器的过度 VRAM 消耗
– 修复在模型移除时 `conditional_download` 中的异常
– 修复使用 FFmpeg 7 时的处理卡顿问题
3.5.0
– 修复模型加载的问题
– 优化启动速度
– 重新制作了运行环境
– 彻底离线运行
– 帧着色器:使用来自 `ddcolor` 和 `deoldify` 的先进模型,为黑白或低色彩素材添加色彩。这些模型利用深度学习技术生成逼真且美观的着色效果。
– 改善唇同步效果:从音频中更清晰、更准确地提取语音。增强的语音提取可让您的深度伪造视频中的唇形同步更加自然逼真。
– 实验性 5 到 68 个关键点识别: 尝试用于识别 5 到 68 个面部关键点的模型。这些关键点可精准定位关键面部特征,从而实现更准确、细致的深度伪造效果。
– 使用尖端模型进行面部增强: 结合强大的 `gpen_bfr_1024` 和 `gpen_bfr_2048` 模型,在保持自然外观的前提下,微妙地改善面部特征,提升深度伪造视频的质量。
– 帧增强选项:利用 `real_esrgan_x2` 和 `real_hatgan_x4` 等先进视频增强模型,可以将低分辨率视频进行上采样或增强细节,打造更精美的视觉效果。
– 简化模型管理:使用新的 `–force-download` 参数可以轻松一次下载所有必需的模型。这消除了每次运行应用程序时等待单个模型下载的麻烦。
– 简化环境管理:将文档和安装程序从虚拟环境 (venv) 迁移到 conda 环境。Conda 提供了更健壮的依赖项管理,简化了设置和维护流程。
– 增强 CUDA 12 兼容性: 得益于对 `inswapper_128_fp16` 模型的修复,该项目实现了与 NVIDIA CUDA 12 工具包的无缝兼容。即使您使用最新版本的 CUDA,也能确保程序顺畅运行。
– 解决视频合并过程中帧率波动的问题,提供更一致的用户体验。
– 修复了使用 `–skip-download` 参数且部分模型缺失时程序崩溃的问题,可以优雅地处理缺失模型的情况。
– 修正了 `h264_nvenc` 和 `hevc_nvenc` 预设的映射,确保准确的编码。
3.4.1
– 条下载人脸分析模型
– 防止远程下载循环
– 动态的concurrency_count以获得理想的Gradio性能
– 为Gradio打补丁以加速预览和流渲染
– 修复音频到图片的预览问题
– 同时运行多个人脸检测器
– 在低置信度下防止68至5标记点的转换
– 添加高性能的scrfd人脸检测模型
– 优雅地开始和停止处理
– 迁移到ONNX支持的帧增强器
– 引入–face-landmarker-score参数
– 在使用多个UI布局时渲染标签页
– 引入–output-image-resolution参数
– 添加更多人脸调试项并优化其颜色主题
– 当启用–log-level debug时打印内部统计信息
– 一旦启用唇部同步器,保持视频全程的唇部覆盖
– 添加对h264_amf和hevc_amf视频编码器的支持
– 限制临时资源的分辨率提升和fps增强
– 更改–output-path行为和规范化
– 移除–temp-frame-quality参数
– 修复使用非均匀像素目标时出现的绿线问题
– 修复使用–trim-frame-start时唇部同步器预览的问题
– 修复Geforce GTX 16系列的空白输出问题
3.3.0
– 引入使用wave2lip的唇形同步帧处理器
– 通过68到5的标志点转换改善面部对齐
– 添加面部交换模型uniface_256
– 将yoloface添加为默认的面部检测模型
– 在处理前清除临时资源
– 在面部调试项中添加年龄和性别
– 更新安装程序以适应特定版本的CUDA和ROCM条目
– 改进CLI参数的描述
– 在放大后强制执行–output-video-resolution
– 在处理时减少终端输出噪音
3.1.3
解决了一些关键性问题
2.1.2
一大波实用更新
1.3.1
优化安装程序的默认值和 CPU 选择
1.3.0
为换脸器添加高性能 FP16 版本
将 ONNX 支持的 CodeFormer、GFPGAN 和 GPEN 添加到面部增强器
将 RealESRGAN_x2plus 和 RealESRNet_x4plus 添加到帧增强器
实现面部增强器和帧增强器的混合
使帧处理器具有选项和 CLI 参数
将 UI 主题细化为简约扁平化设计
通过参数分组增强 –help 和文档
将默认图像和视频质量降低至 80%
向安装程序引入新的 –torch 参数
使用最新的 onnxruntime 提高 Apple Silicon 性能
将视频质量修复为压缩标准化
修复 Windows 防火墙导致的下载卡住问题
v1.2.1
每个处理步骤后执行 VRAM 清理
将 TensorFlow 内存消耗限制为 512 MB
在帧处理之前验证模型文件
引入 –skip-download 来跳过自动下载
升级到最新的onnxruntime版本
v1.2.0
建立实时网络摄像头性能
通过缓存人脸分析器结果来优化重新运行
通过缓存优化图像读取性能
恢复中断的资产和模型下载
允许传递 –onnxruntime 到 install.py
引入官方facefusion-colab仓库
删除每个 UI 组件的对齐方式
引入设置的复选框组
在 UI 中设置网络摄像头分辨率和 fps
禁止 UI 中的空执行提供程序
修复带音频的视频的帧范围处理
修复 CUDA 和 ROCM Dockerfile 以利用 GPU
修复临时帧路径的排序
v1.1.2
1.根据完善的汉化
2.去掉XX限制!
v1.1.1
机器翻译!
常见依赖项和加速依赖项的安装程序
内置网络摄像头套件,支持 udp 和 v4l2 流媒体
专用–无头模式
添加对 ROCM 的 Docker 支持
允许通过 UI 调整 –output-path
增强输出路径标准化
启动基准测试套件之前的一次预热
能够选择基准测试套件的运行
通过部分更新启用基准测试
实现完全事件驱动的 UI 以实现超级响应能力
添加最大内存滑块以选择可用 RAM
根据目标媒体类型实现条件 UI
为图像输出引入 –output-image-quality 选项
修复 libvpx 视频编码器的 crf 范围
修复 detector_fps 以使用不同的编码
Installer for common and acceleration dependencies
Built-in webcam suite that supports udp and v4l2 streaming
Dedicated –headless mode
Add Docker support for ROCM
Allow adjustment of –output-path via the UI
Enhance output path normalization
Single warm-up before starting the benchmark suite
Ability to select runs for the benchmark suite
Enable benchmarking with partial updates
Implement a fully event-driven UI for super responsiveness
Add a max memory slider to select free RAM
Implement conditional UI based on target media type
Introduce –output-image-quality option for image output
Fix crf range for libvpx video encoder
Fix detect_fps to work with different encoding
v1.0.2:修复了增强下面视频无法合成的问题!
—————————————–
教程,问答,新版!
见知识星球tonyhub:
https://t.zsxq.com/vFuzRNr